Capacity and Trainability in Recurrent Neural Networks
Two potential bottlenecks on the expressiveness of recurrent neural networks (RNNs) are their ability to store information about the task in their parameters, and to store information about the input history in their units. We show experimentally tha…
Authors: Jasmine Collins, Jascha Sohl-Dickstein, David Sussillo
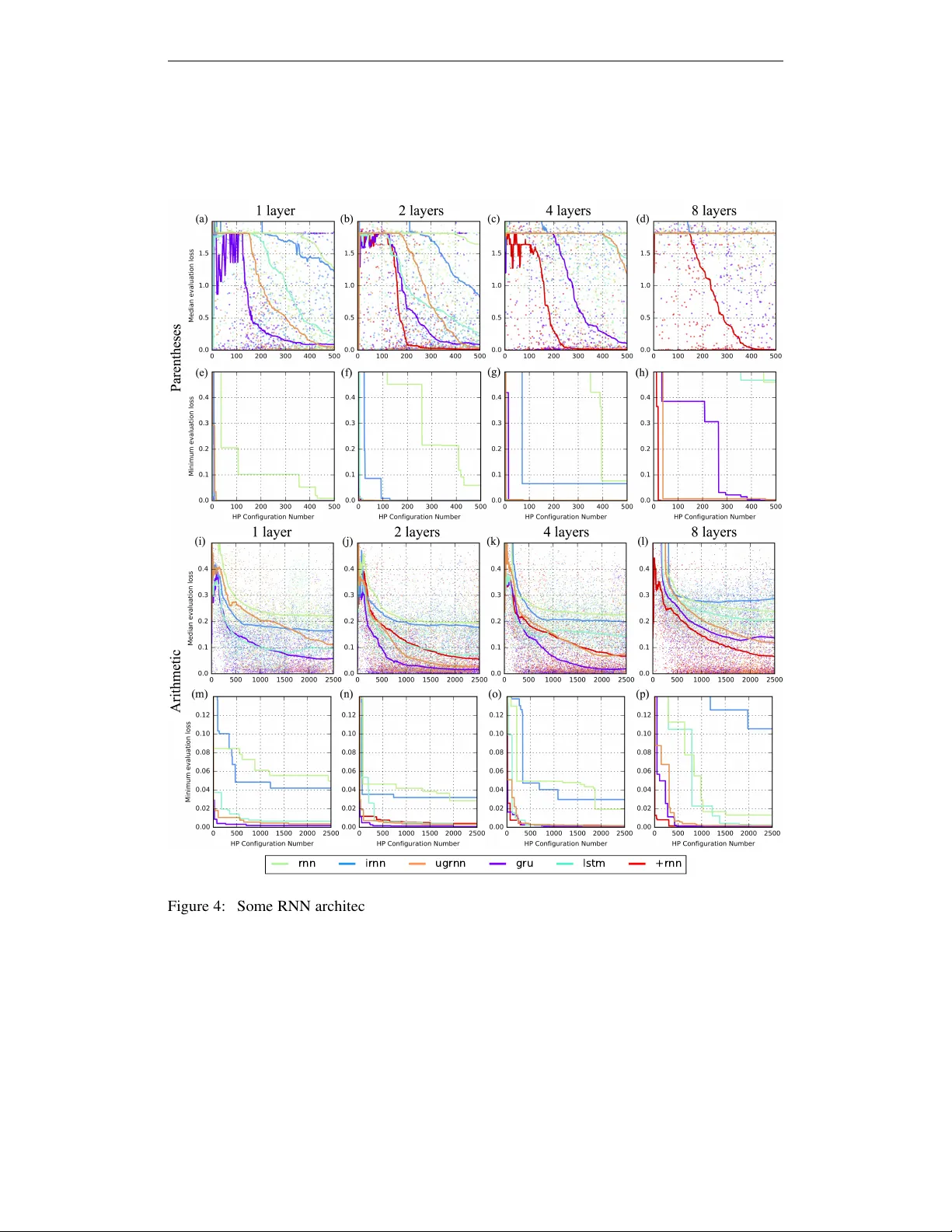
Published as a conference paper at ICLR 2017 C A P A C I T Y A N D T R A I N A B I L I T Y I N R E C U R R E N T N E U R A L N E T W O R K S Jasmine Collins ∗ , Jascha Sohl-Dickstein & David Sussillo Google Brain Google Inc. Mountain V ie w , CA 94043, USA {jlcollins, jaschasd, sussillo}@google.com A B S T R AC T T wo potential bottlenecks on the expressi veness of recurrent neural networks (RNNs) are their ability to store information about the task in their parameters, and to store information about the input history in their units. W e show e xperimentally that all common RNN architectures achie ve nearly the same per-task and per -unit capacity bounds with careful training, for a variety of tasks and stacking depths. They can store an amount of task information which is linear in the number of parameters, and is approximately 5 bits per parameter . The y can additionally store approximately one real number from their input history per hidden unit. W e further find that for several tasks it is the per-task parameter capacity bound that determines performance. These results suggest that many previous results comparing RNN architectures are driven primarily by dif ferences in training effecti veness, rather than differences in capacity . Supporting this observation, we compare training difficulty for se veral architectures, and show that vanilla RNNs are far more difficult to train, yet have slightly higher capacity . Finally , we propose two novel RNN architectures, one of which is easier to train than the LSTM or GRU for deeply stacked architectures. 1 I N T RO D U C T I O N Research and application of recurrent neural networks (RNNs) hav e seen explosi ve gro wth o ver the last few years, (Martens & Sutskev er, 2011; Graves et al., 2009), and RNNs have become the central component for some very successful model classes and application domains in deep learning (speech recognition (Amodei et al., 2015), seq2seq (Sutske ver et al., 2014), neural machine translation (Bahdanau et al., 2014), the DRA W model (Gregor et al., 2015), educational applications (Piech et al., 2015), and scientific discovery (Mante et al., 2013)). Despite these recent successes, it is widely ackno wledged that designing and training the RNN components in complex models can be extremely tricky . Painfully acquired RNN e xpertise is still crucial to the success of most projects. One of the main strategies in volved in the deployment of RNN models is the use of the Long Short T erm Memory (LSTM) networks (Hochreiter & Schmidhuber, 1997), and more recently the Gated Recurrent Unit (GR U) proposed by Cho et al. (2014); Chung et al. (2014) (we refer to these as gated architectures). The resulting models are perceiv ed as being more easily trained, and achieving lower error . While it is widely appreciated that RNNs are univ ersal approximators (Doya, 1993), an unresolved question is the degree to which g ated models are more computationally po werful in practice, as opposed to simply being easier to train. Here we provide evidence that the observ ed superiority of gated models o ver v anilla RNN models is almost exclusi vely driven by trainability . First we describe two types of capacity bottlenecks that various RNN architectures might be expected to suffer from: parameter efficiency related to learning the task, and the ability to remember input history . Next, we describe our experimental setup where we disentangle the ef fects of these tw o bottlenecks, including training with e xtremely thorough hyperparameter (HP) optimization. Finally , we describe our capacity e xperiment results ∗ W ork done as a member of the Google Brain Residency program ( g.co/brainresidency ). 1 Published as a conference paper at ICLR 2017 (per-parameter and per -unit), as well as the results of trainability experiments (training on extremely hard tasks where gated models might reasonably be expected to perform better). 1 . 1 C A PAC I T Y B O T T L E N E C K S There are sev eral potential bottlenecks for RNNs, for example: How much information about the task can they store in their parameters? How much information about the input history can the y store in their units? These first two bottlenecks can both be seen as memory capacities (one for the task, one for the inputs), for different types of memory . Another , dif ferent kind of capacity stems from the set of computational primitives an RNN is able to perform. For example, maybe one wants to multiply two numbers. In terms of number of units and time steps, this task may be very straight-forward using some specific computational primitiv es and dynamics, but with others it may be extremely resource heavy . One might expect that differences in computational capacity due to different computational primitives would play a large role in performance. Ho wev er, despite the fact that the gated architectures are outfitted with a multiplicati ve primitiv e between hidden units, while the vanilla RNN is not, we found no evidence of a computational bottleneck in our experiments. W e therefore will focus only on the per-parameter capacity of an RNN to learn about its task during training, and on the per-unit memory capacity of an RNN to remember its inputs. 1 . 2 E X P E R I M E N TA L S E T U P RNNs hav e many HPs, such as the scalings of matrices and biases, and the functional form of certain nonlinearities. There are additionally many HPs in volv ed in training, such as the choice of optimizer, and the learning rate schedule. In order to train our models we employed a HP tuner that uses a Gaussian Process model similar to Spearmint (see Appendix, section on HP tuning and Desautels et al. (2014); Snoek et al. (2012) for related work). The basic idea is that one requests HP v alues from the tuner , runs the optimization to completion using those values, and then returns the validation loss. This loss is then used by the tuner , in combination with previously reported losses, to choose new HP v alues such that over man y experiments, the v alidation loss is minimized with respect to the HPs. For our experiments, we report the e v aluation loss (separate from the validation loss returned to the HP optimizer , except where otherwise noted) after the HP tuner has highly optimized the task (hundreds to many thousands of e xperiments for each architecture and task). In our studies we used a variety of well-known RNN architectures: standard RNNs such as the vanilla RNN and the newer IRNN (Le et al., 2015), as well as gated RNN architectures such as the GRU and LSTM. W e rounded out our set of models by innovating two novel (to our knowledge) RNN architectures (see Section 1.4) we call the Update Gate RNN (UGRNN), and the Intersection RNN (+RNN). The UGRNN is a ‘minimally gated’ RNN architecture that has only a coupled gate between the recurrent hidden state, and the update to the hidden state. The +RNN uses coupled gates to gate both the recurrent and depth dimensions in a straightforward way . T o further explore the various strengths and weaknesses of each RNN architecture, we also used a variety of netw ork depths: 1, 2, 4, 8, in our experiments. 1 In most experiments, we held the number of parameters fixed across different architectures and dif ferent depths. More precisely , for a giv en experiment, a maximum number of parameters was set, along with an input and output dimension. The number of hidden units per layer was then chosen such that the number of parameters, summed across all layers of the network, was as lar ge as possible without exceeding the allo wed maximum. For each of our 6 tasks, 6 RNN v ariants, 4 depths, and 6+ model sizes, we ran the HP tuner in order to optimize the relev ant loss function. T ypically this resulted in many hundreds to sev eral thousands of HP ev aluations, each of which was a full training run up to millions of training steps. T aken together, this amounted to CPU-millennia worth of computation. 1 . 3 R E L A T E D W O R K While it is well known that RNNs are univ ersal approximators of arbitrary dynamical systems (Doya, 1993), there is little theoretical work on the task-capacity of RNNs. Koiran & Sontag (1998) studied 1 Not all experiments used a depth of 8, due to limits on computational resources. 2 Published as a conference paper at ICLR 2017 the VC dimension of RNNs, which pro vides an upper bound on their task-capacity (defined in Section 2.1). These upper bounds are not a close match to our experimental results. For instance, we find that performance saturates rapidly in terms of the number of unrolling steps (Figure 2b), while the relev ant bound increases linearly with the number of unrolling steps. "Unrolling" refers to recurrent computation through time. Empirically , Karpathy et al. (2015) have studied ho w LSTMs encode information in character-based text modeling tasks. Further , Sussillo & Barak (2013) hav e reverse-engineered the v anilla RNN trained on simple tasks, using the tools and language of nonlinear dynamical systems theory . In Foerster et al. (2016) the beha vior of switched affine recurrent netw orks is carefully examined. The ability of RNNs to store information about their input has been better studied, in both the context of machine learning and theoretical neuroscience. Previous work on short term memory traces explores the tradeof fs between memory fidelity and duration, for the case that a new input is presented to the RNN at ev ery time step (Jaeger & Haas, 2004; Maass et al., 2002; White et al., 2004; Ganguli et al., 2008; Charles et al., 2014). W e use a simpler capacity measure consisting only of the ability of an RNN to store a single input vector . Our results suggest that, contrary to common belief, the capacity of RNNs to remember their input history is not a practical limiting factor on their performance. The precise details of what makes an RNN architecture perform well is an extremely activ e research field (e.g. Jozefowicz et al. (2015)). A highly related article is Greff et al. (2015), in which the authors used random search of HPs, along with systematic remov al of pieces of the LSTM architecture to determine which pieces of the LSTM were more important than the others. Our UGRNN architecture is directly inspired by the large impact of remo ving the forget gate from the LSTM (Gers et al., 1999). Zhou et al. (2016) introduced an architecture with minimal gating that is similar to the UGRNN, but is directly inspired by the GRU. An in-depth comparison between RNNs and GR Us in the conte xt of end-to-end speech recognition and a limited computational b udget was conducted in Amodei et al. (2015). Further, ideas from RNN architectures that improve ease of training, such as forget gates (Gers et al., 1999), and copying recurrent state from one time step to another, are making their way into deep feed-forward networks as highway networks (Sriv astav a et al., 2015) and residual connections (He et al., 2015), respectiv ely . Indeed, the +RNN was inspired in part by the coupled depth gate of Sri vasta va et al. (2015). 1 . 4 R E C U R R E N T N E U R A L N E T W O R K A R C H I T E C T U R E S Belo w we briefly define the RNN architectures used in this study . Unless otherwise stated W denotes a matrix, b denotes a vector of biases. The symbol x t is the input at time t , and h t is the hidden state at time t . Remaining vector v ariables represent intermediate values. The function σ ( · ) denotes the logistic sigmoid function and s ( · ) is either tanh or ReLU , set as a HP (see Appendix, Section RNN HPs for the complete list of HPs). Initial conditions for the networks were set to a learned bias. Finally , it is a well-known trick of the trade to initialize the gates of an LSTM or GR U with a large bias to induce better gradient flo w . W e included this parameter , denoted as b f g , and tuned it along with all other HPs. R N N , I R N N ( L E E T A L . , 2 0 1 5 ) h t = s W h h t − 1 + W x x t + b h (1) Note the IRNN is identical in structure to the vanilla RNN, but with an identity initialization for W h , zero initialization for the biases, and s = ReLU only . U G R N N - U P DAT E G AT E R N N Based on Greff et al. (2015), where they noticed the forget gate “was crucial” to LSTM performance, we tried an RNN variant where we began with a vanilla RNN and added a single gate. This gate determines whether the hidden state is carried ov er from the previous time step, or updated – hence, it is an update gate. An alternati ve way to vie w the UGRNN is a highway layer gated through time 3 Published as a conference paper at ICLR 2017 (Sriv asta va et al., 2015). c t = s W c h h t − 1 + W cx x t + b c (2) g t = σ W gh h t − 1 + W gx x t + b g + b f g (3) h t = g t · h t − 1 + ( 1 − g t ) · c t (4) G R U - G AT E D R E C U R R E N T U N I T ( C H O E T A L . , 2 0 1 4 ) r t = σ W rh h t − 1 + W rx x t + b r (5) u t = σ W uh h t − 1 + W ux x t + b u + b f g (6) c t = s W c h ( r t · h t − 1 ) + W cx x t + b c (7) h t = u t · h t − 1 + ( 1 − u t ) · c t (8) L S T M - L O N G S H O RT T E R M M E M O RY ( H O C H R E I T E R & S C H M I D H U B E R , 1 9 9 7 ) i t = σ W ih h t − 1 + W ix x t + b i (9) f t = σ W fh h t − 1 + W fx x t + b f + b f g (10) c in t = s W c h h t − 1 + W cx x t + b c (11) c t = f t · c t − 1 + i t · c in t (12) o t = σ W oh h t − 1 + W ox x t + b o (13) h t = o t · tanh( c t ) (14) + R N N - I N T E R S E C T I O N R N N Due to the success of the UGRNN for shallo wer architectures in this study (see later figures on trainability), as well as some of the observed trainability problems for both the LSTM and GRU for deeper architectures (e.g. Figure 4h) we developed the Intersection RNN (denoted with a ‘+’) architecture with a coupled depth gate in addition to a coupled recurrent gate. Additional influences for this architecture were the recurrent gating of the LSTM and GR U, and the depth gating from the highway network (Sriv astav a et al., 2015). This architecture has recurrent input, h t − 1 , and depth input, x t . It also has recurrent output, h t , and depth output, y t . Note that this architecture only applies between layers where x t and y t hav e the same dimension, and is not appropriate for networks with a depth of 1 (we exclude depth one +RNNs in our e xperiments). y in t = s1 ( W yh h t − 1 + W yx x t + b y ) (15) h in t = s2 ( W hh h t − 1 + W hx x t + b h ) (16) g y t = σ W g y h h t − 1 + W g y x x t + b g y + b f g ,y (17) g h t = σ W g h h h t − 1 + W g h x x t + b g h + b f g ,h (18) y t = g y t · x t + (1 − g y t ) · y in t (19) h t = g h t · h t − 1 + (1 − g h t ) · h in t (20) In practice we used ReLU for s1 and tanh for s2. 2 C A P A C I T Y E X P E R I M E N T S 2 . 1 P E R - PA R A M E T E R C A PAC I T Y A foundational result in machine learning is that a single-layer perceptron with N 2 parameters can store at least 2 bits of information per parameter (Cover, 1965; Gardner, 1988; Baldi & V enkatesh, 1987). More precisely , a perceptron can implement a mapping from 2 N , N -dimensional, input vectors to arbitrary N -dimensional binary output vectors, subject only to the extremely weak restriction that the input vectors be in general position. RNNs provide a f ar more complex input-output mapping, with hidden units, recurrent dynamics, and a div ersity of nonlinearities. Nonetheless, we wondered if there were analogous capacity results for RNNs that we might be able to observe empirically . 4 Published as a conference paper at ICLR 2017 2 . 1 . 1 E X P E R I M E N TA L S E T U P As we will sho w in Section 3, tasks with comple x temporal dynamics, such as language modeling, exhibit a per -parameter capacity bottleneck that explains the performance of RNNs f ar better than a per-unit bottleneck. T o make the experimental design as simple as possible, and to remov e potential confounds stemming from the choice of temporal dynamics, we study per-parameter capacity using a task inspired by Gardner (1988). Specifically , to measure how much task-related information can be stored in the parameters of an RNN, we use a memorization task, where a random static input is injected into an RNN, and a random static output is read out some number of time steps later . W e emphasize that the same per -parameter bottleneck that we find in this simplified task also arises in more temporally complex tasks, such as language modeling. At a high le vel, we draw a fixed set of random inputs and random labels, and train the RNN to map random inputs to randomly chosen labels via cross-entropy error . Howe ver , rather than returning the cross-entropy error to the HP tuner (as is normally done), we instead return the mutual information between the RNN outputs and the true labels. In this w ay , we can treat the number of input-output mappings as a HP, and the tuner will select for us the correct number of mappings so as to maximize the mutual information between the RNN outputs and the labels. From this mutual information we compute bits per parameter , which pro vides a normalized measurement of how much the RNN learned about the task. More precisely , we draw datasets of binary inputs X and target binary labels Y at uniform from the set of all binary datasets, X ∼ X = { 0 , 1 } n in × b , Y ∼ Y = { 0 , 1 } 1 × b , where b is the number of samples, and n in is the dimensionality of the inputs. Number of samples, b , is treated as a HP and in practice the optimal dataset size is v ery close to the bits of mutual information between true and predicted labels. This trend is demonstrated in Figure App.1 in the Appendix. For each v alue of b the RNN is trained to minimize the cross entropy of the network output with the true labels. W e write the output of the RNN for all inputs as ˆ Y = f ( X ) , with corresponding random variable ˆ Y . W e are interested in the mutual information I Y ; ˆ Y between the true class labels and the class labels predicted by the RNN. This is the amount of (directly recoverable) information that the RNN has stored about the task. In this setting, it is calculated as I Y ; ˆ Y = H ( Y ) − H Y | ˆ Y (21) = b + b ( p log 2 p + (1 − p ) log 2 (1 − p )) , (22) where p is the fraction of correctly classified samples. The number b is then adjusted, along with all the other HPs, so as to maximize the mutual information I Y ; ˆ Y . In practice p is computed using only a single draw of { X , Y } ∼ X × Y . W e performed this optimization of I Y ; ˆ Y for various RNN architectures, depths, and numbers of parameters. W e plot the best value of I Y ; ˆ Y vs. number of parameters in Figure 1a. This captures the amount of information stored in the parameters about the mapping between X and Y . T o get an estimate of bits per parameter , we divide by the number of parameters, as sho wn in Figure 1e. 2 . 1 . 2 R E S U L T S Five Bits per Parameter Examining the results of Figure 1, we find the capacity of all architectures is roughly linear in the number of parameters, across several orders of magnitude of parameter count. W e further find that the capacity is between 3 and 6 bits per parameter , once again across all architectures, depths 1, 2 and 4, and across several orders of magnitude in terms of number of parameters. Given the possibility of small size ef fects, and a larger portion of weights used as biases at a small number of parameters, we believe our estimates for larger networks are more reliable. This leads us to a bits per parameter estimate of approximately 5, av eraging over all architectures and all depths. Finally , we note that the per-parameter task capacity increases as a function of the number of unrollings, though with diminishing gains (Figure 2b). The finding that our results are consistent across di verse architectures and scales is ev en more surprising, since prior to these e xperiments it was not clear that capacity would ev en scale linearly 5 Published as a conference paper at ICLR 2017 with the number of parameters. For instance, pre vious results on model compression – by reducing the number of parameters (Y ang et al., 2015), or by reducing the bit depth of parameters (Hubara et al., 2016) – might lead one to predict that different architectures use parameters with vastly dif ferent efficiencies, and that task capacity increases only sublinearly with parameter count. Gating Slightly Reduces Capacity While overall, the different architectures performed very similarly , there are some capacity differences between architectures that appear to hold up across most depths and parameter counts. T o quantify these differences we constructed a table showing the change in the number of parameters one would need to switch from one architecture to another, while maintaining equi valent capacity (Figure 1i). One trend that emerged from our capacity e xperiments is a slightly reduced capacity as a function of "gatedness". Putting aside the IRNN, which performed the worst and is discussed belo w , we noticed that across all depths and all model sizes, the performance was on average RNN > UGRNN > GR U > LSTM > +RNN. The v anilla RNN has no gates, the UGRNN has one, while the remaining three hav e two or more. (a) (b) (c) (d) (e) (f) (g) (h) All depths 1 layer 2 layers 4 layers (i) Figure 1: All neural network architectures can store approximately fi ve bits per parameter about a task, with only small variations across architectures. (a) Stored bits as a function of network size. These numbers represent the maximum stored bits across 1000+ HP optimizations with 5 time steps unrolled at each network size for all lev els of depth. (b-d) Same as (a), but each le vel of depth shown separately . (e-h) Same as (a-d) b ut showing bits per parameter as a function of network size. (i) The value in cell ( x, y ) is the multiplier for the number of parameters needed to gi ve the architecture on the x -axis the same capacity as the architecture on the y -axis. Capacities are measured by averaging the maximum stored bits per parameter for each architecture across all sizes and lev els of depth. ReLUs Reduce Capacity In our capacity tasks, the IRNN performed noticeably worse than all other architectures, reaching a maximum bits per parameter of roughly 3.5. T o determine if this performance drop was due to the ReLU nonlinearity of the IRNN, or its identity initialization, we sorted through the RNN and UGRNN results (which both have ReLU and tanh as choices for the nonlinearity HP) and look ed at the maximum bits per parameter when only optimizations using ReLU 6 Published as a conference paper at ICLR 2017 (c) (a) (b) 1 layer 1 layer All depths rnn relu rnn ugrnn relu ugrnn irnn gru +rnn lstm Figure 2: Additional RNN capacity analysis. (a) The ef fect of the ReLU nonlinearity on capacity . Solid lines indicate bits per parameter for 1-layer architectures (same as Figure 1b), where both tanh and ReLU are nonlinearity choices for the HP tuner . Dashed lines show the maximum bits per parameter for each architecture when only results achieved by the ReLU nonlinearity are considered. (b) Bits per parameter as a function of the number of time steps unrolled. (c) L2 error curv e for all architectures of all depths on the memory throughput task. The curve shows the error plotted as a function of the number of units for a random input of dimension 64 (black v ertical line). All networks with with less than 64 units have error in reconstruction, while all networks with number of units greater than 64 nearly perfectly reconstruct the random input. are considered. Indeed, both the RNN and UGRNN bits per parameter dropped dramatically to the 3.5 range (Figure 2a) when those architectures exclusi vely used ReLU , providing strong e vidence that the ReLU activ ation function is problematic for this capacity task. 2 . 2 P E R - U N I T C A P A C I T Y T O R E M E M B E R I N P U T S An additional capacity bottleneck in RNNs is their ability to store information about their inputs over time. It may be plainly obvious that an IRNN, which is essentially an integrator , can achiev e perfect memory of its inputs if the number of inputs is less than or equal to the number of hidden units, but it is not so clear for some of the more complex architectures. So we measured the per-unit input memory empirically . Figure 2c shows the intuiti ve result that ev ery RNN architecture (at ev ery depth and number of parameters) we studied can reconstruct a random n in dimensional input at some time in the future, if and only if the number of hidden units per layer in the network, n h , is greater than or equal to n in Moreov er , regardless of RNN architecture, the error in reconstructing the input follo ws the same curve as a function of the number of hidden units for all RNN variants, corresponding to reconstructing an n h dimensional subspace of the n in dimensional input. W e highlight this per -unit capacity to make the point that a per-parameter task capacity appears to be the limiting factor in our experiments (e.g. Figure 1 and Figure 3), and not a per-unit capacity , such as the per -unit capacity to remember previous inputs. Thus when comparing results between architectures, one should normalize different architectures by the number of parameters, and not the number of units, as is frequently done in the literature (e.g. when comparing vanilla RNNs to LSTMs). This makes further sense as, for all common RNN architectures, the computational cost of processing a single sample is linear in the number of parameters, and quadratic in the number of units per layer . As we show in Figure 3d, plotting the capacity results by numbers of units gives v ery misleading results. 3 A D D I T I O NA L TA S K S W H E R E A R C H I T E C T U R E S A C H I E V E V E RY S I M I L A R L O S S W e studied additional tasks that we believed to be easy enough to train that the ev aluation loss of different architectures w ould reveal v ariations in capacity rather than trainability . A critical aspect of these tasks is that they could not be learned perfectly by any of the model sizes in our e xperiments. As we change model size, we therefore expect performance on the task to also change. The tasks are (see Appendix, section T ask Definitions for further elaboration of these tasks): 7 Published as a conference paper at ICLR 2017 • text8 - 1-step ahead character -based prediction on the text8 W ikipedia dataset (100 million characters) (Mahoney, 2011). • Random Continuous Functions (RCF) - A task similar to the per -parameter capacity task abov e, except the target outputs are real numbers (not categorical), and the number of training samples is held fixed. The performance on these two tasks is sho wn in Figure 3. The evaluation loss as a function of the number of parameters is plotted in panels a-c and e-g, for the te xt8 task, and RCF task, respectiv ely . For all tasks in this section, the number of parameters rather than the number of units pro vided the bottleneck on performance, and all architectures performed e xtremely closely for the same number of parameters. By close performance we mean that, for one model to achiev e the same loss as another the model, the number of parameters w ould hav e to be adjusted by only a small f actor (ex emplified in Figure 1i for the per-parameter capacity task). 1 layer text8 (a) (e) RCF (f) 2 layers (b) (g) 4 layers (c) (d) 1 layer Figure 3: All RNN architectures achieved near identical performance giv en the same number of parameters, on a language modeling and random function fitting task. (a-c) text8 W ikipedia number of parameters vs bits per character for all RNN architectures. From left to right: 1 layer, 2 layer, 4 layer models. (d) text8 number of hidden units vs bits per character for 1 layer architectures. W e note that this is almost always a misleading way to compare architectures as the more hea vily gated architectures appear to do better when compared per -unit. (e-g) Same as (a-c), except sho wing square error for different model sizes trained on RCFs. 4 T A S K S T H A T A R E V E RY H A R D T O L E A R N In practice it is widely appreciated that there is often a significant g ap in performance between, for example, the LSTM and the vanilla RNN, with the LSTM nearly al ways outperforming the v anilla RNN. Our per-parameter capacity results pro vide evidence for a rough equi valence among a v ariety of RNN architectures, with slightly higher capacity in the vanilla RNN (Figure 1). T o reconcile our per -parameter capacity results with widely held experience, we provide evidence that gated architectures, such as the LSTM, are far easier to train than the v anilla RNN (and often the IRNN). W e study two tasks that are difficult to learn: parallel parentheses counting of independent input streams, and mathematical addition of integers encoded in a character string (see Appendix, section T ask Definitions). The parentheses task is moderately dif ficult to learn, while the arithmetic task is quite hard. The results of the HP optimizations are sho wn in Figure 4a-4h for the parentheses task, and in Figure 4i-4p for the arithmetic task. These tasks show that, while it is possible for a v anilla RNN to learn these tasks reasonably well, it is far more difficult than for a gated architecture. Note that the best achiev ed loss on the arithmetic task is still significantly decreasing, even after 2500 HP ev aluations (2500 full complete optimizations ov er the training set), for the RNN and IRNN. There are three note worthy trends in these trainability e xperiments. First, across both tasks, and all depths (1, 2, 4 and 8), the RNN and IRNN performed most poorly , and took the longest to learn the task. Note, ho we ver that both the RNN and IRNN always solved the tasks ev entually , at least for depth 1. Second, as the stacking depth increased, the gated architectures became the only architectures that 8 Published as a conference paper at ICLR 2017 could solve the tasks. Third, the most trainable architecture for depth 1 was the GR U, and the most trainable architecture for depth 8 was the +RNN (which performed the best on both of our metrics for trainability , on both tasks). rnn irnn ugrnn gru lstm +rnn Figure 4: Some RNN architectures are far easier to train than others. Results of HP searches on extremely dif ficult tasks. (a) Median ev aluation error as a function of HP optimization iteration for 1 layer architectures on the parentheses task. Dots indicate e valuation loss achie ved on that HP iteration. (b-d) Same as (a), but for 2, 4 and 8 layer architectures. (e-h) Minimum e valuation error as a function of HP optimization iteration for parentheses task. Same depth order as (a-d). (i-p) Same as (a-h), except for the arithmetic task. W e note that the best loss for the vanilla RNN is still decreasing after 2400+ HP ev aluations. T o achiev e our results on capacity and trainability , we relied hea vily on a HP tuner . Most practitioners do not hav e the time or resources to make use of such a tuner , typically only adjusting the HPs a few times themselves. So we wondered how the various architectures would perform if we set HPs randomly , within the ranges specified (see Appendix for ranges). W e tried this 1000 times on the parentheses task, for all 200k parameter architectures at depths 1 and 8 (Figure 5 and T able 1). The noticeable trends are that the IRNN returned an infeasible error nearly half of the time, and the LSTM 9 Published as a conference paper at ICLR 2017 (depth 1) and GR U (depth 8) were infeasible the least number of times, where infeasibility means that the training loss diver ged. F or depth 1, the GR U gave the smallest error , and the smallest median error , and for depth 8, the +RNN deliv ered the smallest error and smallest median error . 1 layer 8 layers (a) (b) Parentheses Figure 5: For randomly generated hyperparameters, GR U and +RNN are the most easily trainable architectures. Evaluation losses from 1000 iterations of randomly chosen HP sets for 1 and 8 layer, 200k parameter models on the parentheses task. Statistics from a W elch’ s t -test for equality of means on all pairs of architectures are presented in T able App.2. (a) Box and whisker plot of ev aluation losses for the 1 layer model. (b) Same as (a) but for 8 layers. Architecture % Infeasible (1 layer) % Infeasible (8 layer) +RNN - 8.8 % GR U 15.5 % 3.2 % IRNN 56.7 % 44.6 % LSTM 12.0 % 4.0 % RNN 21.5 % 18.7 % UGRNN 20.2 % 11.5 % T able 1: Fraction infeasible trials as a result of 1000 iterations of randomly chosen HP sets for 1 and 8 layer , 200k parameter models trained on the parentheses task. 5 D I S C U S S I O N Here we report that a number of RNN v ariants can hold between 3-6 bits per parameter about their task, and that these v ariants can remember a number of random inputs that is nearly equal to the number of hidden units in the RNN. The quantification of the number of bits per parameter an RNN can store about a task is particularly important, as it was not previously kno wn whether the amount of information about a task that could be stored was e ven linear in the number of parameters. While our results point to empirical capacity limits for both task memorization, and input memoriza- tion, apparently the requirement to remember features of the input through time is not a practical bottleneck. If it were, then the vanilla RNN and IRNN would perform better than the gated archi- tectures in proportion to the ratio of the number of units, which the y do not. Based on widespread results in the literature, and our own results on our dif ficult tasks, the loss of some memory capacity (and possibly a small amount of per-parameter storage capacity) for improved trainability seems a worthwhile trade off. Indeed, the input memory capacity did not obviously impact any task not explicitly designed to measure it, as the error curv es – for instance for the language modeling task – ov erlapped across architectures for the same number of parameters, but not the same number of units. Our result on per-parameter task capacity , about 5 bits per parameter averaged ov er architectures, is in surprising agreement with recently published results on the capacity of synapses in biological neurons. This number was recently calculated to be about 4.7 bits per synapse, based on biological synapses in the hippocampus having roughly 26 measurable discrete sizes (Bartol et al., 2016). Our capacity results hav e implications for compressed networks that employ quantization techniques. In 10 Published as a conference paper at ICLR 2017 particular , they provide an estimate of the number of bits which a weight may be compressed without loss in task performance. Coincidentally , in Han et al. (2015), the authors used 5 bits per weight in the fully connected layers. An additional observ ation about per-parameter task capacity in our experiments is that it increases for a fe w time steps beyond one (Figure 2b), and then appears to saturate. W e interpret this to suggest that recurrence endows additional capacity to a network with shared parameters, but that there are diminishing returns, and the total capacity remains bounded even as the number of time steps increases. W e also note that performance is nearly constant across RNN architectures if the number of parameters is held fixed. This may motiv ate the design and use of architectures with small compute per parameter ratios, such as mixture of experts RNNs (Shazeer et al., 2017), and RNNs with large embedding dictionaries on input and output (Józefowicz et al., 2016). Despite our best efforts, we cannot claim that we perfectly trained any of the models. Potential problems in HP optimization could be local minima, as well as stochastic behavior in the HP optimization as a result of the stochasticity of batching or random draws for weight matrices. W e tried to uncover these ef fects by running the best performing HPs 100 times, and did not observe any serious de viations from the best results (see T able App.1 in Appendix). Another form of validation comes from the fact that in our capacity task, essentially 3 independent experiments (one for each lev el of depth) yielded a clustering by architecture (Figure 1e). Do our results yield a frame work for choosing a recurrent architecture? In total, we believ e yes. As explored in Amodei et al. (2015), a practical concern for recurrent models is speed of e xecution in a production environment. Our results suggest that if one has a large resource budget for training and confined resource b udget for inference, one should choose the v anilla RNN. Con versely , if the training resource budget is small, but the inference b udget large, one should choose a g ated model. Another serious concern relates to task complexity . If the task is easy to learn, a vanilla RNN should yield good results. Ho wev er if the task is ev en moderately dif ficult to learn, a gated architecture is the right choice. Our results point to the GR U as being the most learnable of gated RNNs for shallow architectures, follo wed by the UGRNN. The +RNN typically performed best for deeper architectures. Our results on trainability confirm the widely held view that the LSTM is an extremely reliable architecture, but it was almost ne ver the best performer in our experiments. Of course further experiments will be required to fully vet the UGRNN and +RNN. All things considered, in an uncertain training en vironment, our results suggest using the GR U or +RNN. 6 A C K N O W L E D G E M E N T S W e would like to thank Geoffre y Irving, Alex Alemi, Quoc Le, Navdeep Jaitly , and T aco Cohen for helpful feedback. R E F E R E N C E S Dario Amodei, Rishita Anubhai, Eric Battenberg, Carl Case, Jared Casper , Bryan C. Catanzaro, Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Erich Elsen, Jesse Engel, Linxi Fan, Christopher Fougner , T ony Han, A wni Y . Hannun, Billy Jun, Patrick LeGresley , Libby Lin, Sharan Narang, Andre w Y . Ng, Sherjil Ozair, Ryan Prenger , Jonathan Raiman, Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Y i W ang, Zhiqian W ang, Chong W ang, Bo Xiao, Dani Y ogatama, Jun Zhan, and Zhenyao Zhu. Deep speech 2: End-to-end speech recognition in english and mandarin. CoRR , abs/1512.02595, 2015. URL http://arxiv.org/abs/1512.02595 . Dzmitry Bahdanau, Kyunghyun Cho, and Y oshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv pr eprint arXiv:1409.0473 , 2014. Pierre Baldi and Santosh S V enkatesh. Number of stable points for spin-glasses and neural netw orks of higher orders. Physical Re view Letters , 58(9):913, 1987. Thomas M Bartol, Cailey Bromer , Justin Kinney , Michael A Chirillo, Jennifer N Bourne, Kristen M Harris, and T errence J Sejnowski. Nanoconnectomic upper bound on the variability of synaptic plasticity . eLife , 4: e10778, 2016. 11 Published as a conference paper at ICLR 2017 Adam S Charles, Han Lun Y ap, and Christopher J Rozell. Short-term memory capacity in networks via the restricted isometry property . Neural computation , 26(6):1198–1235, 2014. Kyungh yun Cho, Bart V an Merriënboer , Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Y oshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv pr eprint arXiv:1406.1078 , 2014. Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Y oshua Bengio. Empirical e valuation of gated recurrent neural networks on sequence modeling. arXiv preprint , 2014. Thomas M Cov er . Geometrical and statistical properties of systems of linear inequalities with applications in pattern recognition. IEEE tr ansactions on electronic computer s , (3):326–334, 1965. Thomas Desautels, Andreas Krause, and Joel W Burdick. Parallelizing exploration-e xploitation tradeoffs in gaussian process bandit optimization. The Journal of Machine Learning Resear ch , 15(1):3873–3923, 2014. Kenji Doya. Univ ersality of fully connected recurrent neural networks. Dept. of Biology , UCSD, T ech. Rep , 1993. Jakob Foerster , Justin Gilmer, Jan Choro wski, Jascha Sohl-Dickstein, and David Sussillo. Intelligible language modeling with input switched affine netw orks. ICLR 2017 submission , 2016. Surya Ganguli, Dongsung Huh, and Haim Sompolinsky . Memory traces in dynamical systems. Proceedings of the National Academy of Sciences , 105(48):18970–18975, 2008. Elizabeth Gardner . The space of interactions in neural network models. Journal of physics A: Mathematical and general , 21(1):257, 1988. Felix A. Gers, Jurgen Schmidhuber , and Fred Cummins. Learning to forget: Continual prediction with lstm. Artificial Neural Networks, ICANN 99. Ninth International Confer ence on (Conf. Publ. No. 470) , 2:850–855, 1999. Alex Gra ves, Marcus Liwicki, Santiago Fernández, Roman Bertolami, Horst Bunke, and Jür gen Schmidhuber . A novel connectionist system for unconstrained handwriting recognition. P attern Analysis and Machine Intelligence, IEEE T ransactions on , 31(5):855–868, 2009. Klaus Greff, Rupesh Kumar Sri vasta va, Jan K outník, Bas R Steunebrink, and Jürgen Schmidhuber . Lstm: A search space odyssey . arXiv pr eprint arXiv:1503.04069 , 2015. Karol Gregor , Ivo Danihelka, Ale x Graves, and Daan W ierstra. Draw: A recurrent neural network for image generation. arXiv pr eprint arXiv:1502.04623 , 2015. Song Han, Huizi Mao, and W illiam J Dally . Deep compression: Compressing deep neural netw orks with pruning, trained quantization and huffman coding. arXiv pr eprint arXiv:1510.00149 , 2015. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. arXiv pr eprint arXiv:1512.03385 , 2015. Sepp Hochreiter and Jürgen Schmidhuber . Long short-term memory . Neural computation , 9(8):1735–1780, 1997. Itay Hubara, Daniel Soudry , and Ran El Y aniv . Binarized neural networks. arXiv pr eprint arXiv:1602.02505 , 2016. Herbert Jaeger and Harald Haas. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. science , 304(5667):78–80, 2004. Rafal Jozefowicz, W ojciech Zaremba, and Ilya Sutske ver . An empirical exploration of recurrent network architectures. In Proceedings of the 32nd International Conference on Machine Learning (ICML-15) , pp. 2342–2350, 2015. Rafal Józefowicz, Oriol V inyals, Mike Schuster , Noam Shazeer, and Y onghui W u. Exploring the limits of language modeling. CoRR , abs/1602.02410, 2016. URL . Andrej Karpathy , Justin Johnson, and Fei-Fei Li. V isualizing and understanding recurrent networks. arXiv pr eprint arXiv:1506.02078 , 2015. Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR , abs/1412.6980, 2014. URL . 12 Published as a conference paper at ICLR 2017 Pascal K oiran and Eduardo D Sontag. V apnik-chervonenkis dimension of recurrent neural networks. Discr ete Applied Mathematics , 86(1):63–79, 1998. Quoc V Le, Na vdeep Jaitly , and Geof frey E Hinton. A simple way to initialize recurrent netw orks of rectified linear units. arXiv pr eprint arXiv:1504.00941 , 2015. W olfgang Maass, Thomas Natschläger , and Henry Markram. Real-time computing without stable states: A new framew ork for neural computation based on perturbations. Neural computation , 14(11):2531–2560, 2002. Matt Mahoney . Large text compression benchmark: About the test data, 2011. URL http://mattmahoney. net/dc/textdata . [Online; accessed 15-No vember-2016]. V alerio Mante, David Sussillo, Krishna V Shenoy , and William T Ne wsome. Context-dependent computation by recurrent dynamics in prefrontal cortex. Nature , 503(7474):78–84, 2013. James Martens and Ilya Sutskever . Learning recurrent neural networks with hessian-free optimization. In Pr oceedings of the 28th International Confer ence on Machine Learning (ICML-11) , pp. 1033–1040, 2011. Chris Piech, Jonathan Bassen, Jonathan Huang, Surya Ganguli, Mehran Sahami, Leonidas J Guibas, and Jascha Sohl-Dickstein. Deep knowledge tracing. In Advances in Neural Information Pr ocessing Systems , pp. 505–513, 2015. Noam Shazeer , Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffre y E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer . CoRR , abs/1701.06538, 2017. URL . Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms. In Advances in neur al information processing systems , pp. 2951–2959, 2012. Rupesh Kumar Srivasta va, Klaus Greff, and Jürgen Schmidhuber . Highway networks. arXiv pr eprint arXiv:1505.00387 , 2015. David Sussillo and Omri Barak. Opening the black box: low-dimensional dynamics in high-dimensional recurrent neural networks. Neural computation , 25(3):626–649, 2013. Ilya Sutske ver , Oriol V inyals, and Quoc V Le. Sequence to sequence learning with neural networks. In Advances in neural information pr ocessing systems , pp. 3104–3112, 2014. T ijmen Tieleman and Geoffrey . Hinton. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neur al Networks for Machine Learning , 4, 2012. Olivia L White, Daniel D Lee, and Haim Sompolinsky . Short-term memory in orthogonal neural networks. Physical r eview letter s , 92(14):148102, 2004. Zichao Y ang, Marcin Moczulski, Misha Denil, Nando de Freitas, Alex Smola, Le Song, and Ziyu W ang. Deep fried con vnets. In Pr oceedings of the IEEE International Confer ence on Computer V ision , pp. 1476–1483, 2015. Guo-Bing Zhou, Jianxin W u, Chen-Lin Zhang, and Zhi-Hua Zhou. Minimal gated unit for recurrent neural networks. International Journal of Automation and Computing , 13(3):226–234, 2016. ISSN 1751-8520. doi: 10.1007/s11633- 016- 1006- 2. URL http://dx.doi.org/10.1007/s11633- 016- 1006- 2 . 13 Published as a conference paper at ICLR 2017 A ppendix A R N N H P S S E T B Y T H E H P T U N E R W e used a HP tuner that uses a Gaussian Process (GP) Bandits approach for HP optimization. Our setting of the tuner’ s internal parameters was such that it uses Batched GP Bandits with an expected improv ement acquisition function and a Matern 5/2 Kernel with feature scaling and automatic relev ance determination performed by optimizing over k ernel HPs. Please see Desautels et al. (2014) and Snoek et al. (2012) for closely related work. For all our tasks, we requested HPs from the tuner , and reported loss on a v alidation dataset. For the per-parameter capacity task, the ev aluation, validation and training datasets were identical. For text8, the v alidation and ev aluation sets consisted of dif ferent sections of held out data. For all other tasks, ev aluation, v alidation, and training sets were randomly drawn from the same distribution. The performance we plot in all cases is on the ev aluation dataset. Below is the list of all tunable HPs that were generically applied to all models. In total, each RNN v ariant had between 10 and 27 HP dimensions relating to the architecture, optimization, and regularization. • s () - as used in the follo wing RNN definitions, a nonlinearity determined by the HP tuner, { ReLU, tanh } . The only exception was the IRNN, which used ReLU e xclusively . • For an y matrix that is inherently square, e.g. W h , there were three possible initializations: identity , orthogonal, or random normal distribution scaled by 1 / √ n h , with n h the number of recurrent units. The sole exception was the RNN, which was limited to either orthogonal or random normal initializations, to differentiate it from the IRNN. For any matrix that is inherently rectangular , e.g. W x , we initialized with a random normal distribution scaled by 1 / √ n in , with n in the number of inputs. • For all matrix initializations except the identity initialization, there was a multiplicativ e scalar used to set the scale of matrix. The scalar was exponentially distrib uted in [0 . 01 , 2 . 0] for recurrent matrices and [0 . 001 , 2 . 0] for rectangular matrices. • Biases could hav e two possible distributions: all biases set to a constant value, or drawn from a standard normal distribution. • For all bias initializations, a multiplicativ e scalar was drawn, uniformly distributed in [ − 2 . 0 , 2 . 0] and applied to bias initialization. • W e included a scalar bias HP b f g for architectures that contain forget or update gates, as is commonly employed in practice, which was uniformly distrib uted in [0 . 0 , 6 . 0] . Additionally , the HP tuner was used to optimize HPs associated with learning: • The number of training steps - The e xact range varied between tasks, but always fell between 50K and 20M. • One of four optimization algorithms could be chosen: vanilla SGD, SGD with momentum, RMSProp (T ieleman & Hinton, 2012), or AD AM (Kingma & Ba, 2014). • learning rate initial value, exponentially distrib uted in [1e − 4 , 1e − 1] • learning rate decay - exponentially distributed in [1e − 3 , 1] . The learning rate exponentially decays by this factor ov er the number of training steps chosen by the tuner • optimizer momentum-like parameter - expressed as a logit, and uniformly distributed in [1 . 0 , 7 . 0] • gradient clipping value - exponentially distrib uted in [1 , 100] • l2 decay - exponentially distributed in [1e − 8 , 1e − 3] . The perceptron capacity task also had associated HPs: • The number of samples in the dataset, b - between 0.1x and 10x the number of model parameters 14 Published as a conference paper at ICLR 2017 • A HP determined whether the input v ector X · j was presented to the RNN only at the first time step, or whether it was presented at e very time step. Some optimization algorithms had additional parameters such as AD AM’ s second order decay rate, or epsilon parameter . These were set to their default v alues and not optimized. The batch size was set individually by hand for all experiments. The same seed was used to initialize the random number generator for all task parameters, whereas the generator was randomly seeded for network parameters (e.g. initializations). Note that for each network, the initial condition w as set to a learned vector . Figure App.1: In the capacity task, the optimal dataset size found by the HP tuner was only slightly larger than the mutual information in bits reported in Figure 1a, for all architectures at all sizes and depths. B T A S K D E FI N I T I O N S P E R C E P T R O N C A PAC I T Y While at a high-lev el, for the perceptron capacity task, we wanted to optimize the amount of information the RNN carried about true random labels, in practice, the training objectiv e was standard cross-entropy . Howe ver , when returning a validation loss to the HP tuner, we returned the mutual information I Y ; ˆ Y | X . Conceptually , this is as if there is one nested optimization inside another . The inner loop optimizes the RNN for the set of HPs, training cross entropy , but returning mutual information. The outer loop then chooses the HPs, in particular , the number of samples b , in equation (21), so as to maximize the amount of mutual information. This implementation is necessitated because there is no straightforward way to dif ferentiate mutual information with respect to number of samples. During training, cross entropy error is ev aluated beginning after 5 time steps. M E M O RY C A P A C I T Y In the Memory Capacity task, we w anted to know ho w much information an RNN can reconstruct about its inputs at some later time point. W e picked an input dimension, 64, and varied the number of parameters in the networks such that the number of hidden units was roughly centered around 64. After 12 time steps the target of the network was exact reconstruction of the input, with a square error loss. The inputs were random values drawn from a uniform distrib ution between − √ 3 and √ 3 (corresponding to a variance of 1). R A N D O M C O N T I N U O U S F U N C T I O N A dataset was constructed consisting of N = 10 6 random unit norm Gaussian input vectors x , with size d = 50 . T arget scalar outputs y were generated for each input vector , and were also drawn from a unit norm Gaussian. Each sample i was assigned a po wer law weighting β i = ( i + τ ) − 1 Z , where Z was a normalization constant such that the weightings summed to 1, and the characteristic time constant τ = 5000 . The loss function for training was calculated after 50 time steps and was weighted square error on the y i , with the β i acting as the weighting terms. 15 Published as a conference paper at ICLR 2017 T E X T 8 In the text8 task, the task was to predict one character ahead in the text8 dataset (1e8 characters of W ikipedia) (Mahoney, 2011). Input was a hot-one encoded sequence, as was the output. The loss was cross-entropy loss on a softmax output layer . Rather than use partial unrolling as is common in language modeling, we generated random pointers into the text. The first 13 time steps (where T = 50 ) were used to initialize the RNN into a normal operating mode, and remaining steps were used for training or inference. P A R E N T H E S E S C O U N T I N G T A S K The parentheses counting task independently counts the number of opened ‘parens’, e.g. ‘(’, without the closing ‘)’. Here parens is used to mean an y of 10 parens type pairs, e.g. ‘<>’ or ‘[]’. Additionally , there were 10 noise characters, ‘a’ to ‘j’. For each paren type, there was a 20 D + 10 D = 30 D hot-one encoding of all paren and noise symbols, for a total of 300 inputs. The output for each paren type was a hot-one encoding of the digits 0-9, which represented the count of the opened parens of that type. If the count e xceeded 9, the the network k ept the count at 9, if the paren w as closed, the count decreased. The loss was the sum of cross-entropy losses, one for each paren type. Finally , for each paren input stream, 50% random noise characters were drawn, and 50% random paren characters were drawn, e.g. 10 streams like ‘(a[[[)’. Parens of other types were treated as noise for the current type, e.g. for the abov e string if the paren type w as ‘<>’, the answer is ‘1’ at the end. The loss was defined only at the final time point, T , and T = 175 . A R I T H M E T I C T A S K In the arithmetic task, a hot-one encoded character sequence of an addition problem was presented as input to the network, e.g., ‘-343243+93851= ’, and the output was the hot-one encoded answer , including the correct amount of left padded spaces, ‘-249392’. An additional HP for this task w as the number of compute steps (1-6) between the input of the ‘=’ and the first non-space character in the target output sequence. The two numbers in the input were randomly , uniformly selected in [ − 1e7 , 1e7] . After 36 time steps, cross-entropy loss was calculated. W e found this task to be extremely dif ficult for the networks to learn, but when the task was learned, certain of the network architectures could perform the task nearly perfectly . C H P R O B U S T N E S S W e wondered how rob ust the HPs are to the variability of both random batching of data, and random initialization of parameters. So we identified the best HPs from the parentheses experiments of 100k parameter , 1 layer architectures, and reran the parameter optimization 100 times. W e measured the number of infeasible experiments, as well as a number of statistics of the loss for the reruns (T able App.1). These results sho w that the best HPs yielded a distribution of losses very close to the originally reported loss value. Architecture Original Infeasible Min Mean Max S.D. S.D./Mean RNN 1.16e-2 0 % 1.41e-2 8.21e-2 0.294 5.22e-2 0.636 IRNN 4.20e-4 48 % 2.24e-4 5.02e-4 8.69e-4 1.35e-4 0.269 UGRNN 1.02e-4 0 % 3.66e-5 2.71e-4 6.06e-3 7.12e-4 2.63 GR U 2.80e-4 1 % 7.66e-5 1.89e-4 5.48e-4 9.08e-5 0.480 LSTM 7.96e-4 0 % 8.10e-4 2.02e-3 0.0145 2.31e-3 1.14 T able App.1: Results of 100 runs on the parentheses task using the best HPs for each architecture, at depth 1. HPs were chosen to be the set which achieved the minimum loss. T able shows original loss achiev ed by the HP tuner , amount of infeasible trials, minimum loss from running 100 iterations of the same HPs, mean loss, maximum loss, standard deviation, and standard de viation di vided by the mean. 16 Published as a conference paper at ICLR 2017 1 layer 8 layer t -stat df p -value t -stat df p -value +RNN/GR U - - - -23.6 1080 < 0.001 +RNN/IRNN - - - -25.7 954 < 0.001 +RNN/LSTM - - - -26.1 941 < 0.001 +RNN/RNN - - - -25.8 946 < 0.001 +RNN/UGRNN - - - -24.3 1050 < 0.001 GR U/IRNN -7.74 696 < 0.001 -3.51 1360 < 0.001 GR U/LSTM -6.65 1750 < 0.001 -4.84 1290 < 0.001 GR U/RNN -26.5 1340 < 0.001 -3.93 1330 < 0.001 GR U/UGRNN -4.11 1620 < 0.001 -1.13 1840 0.261 IRNN/LSTM 2.23 652 0.0264 -2.04 1250 0.0420 IRNN/RNN -12.7 426 < 0.001 -0.571 1250 0.568 IRNN/UGRNN 4.03 719 < 0.001 2.37 1320 0.0178 LSTM/RNN -19.6 1500 < 0.001 1.53 1730 0.125 LSTM/UGRNN 2.25 1640 0.0247 3.81 1260 < 0.001 RNN/UGRNN 20.7 1210 < 0.001 2.81 1300 0.00498 T able App.2: Results of W elch’ s t -test for equality of means on e valuation losses of architecture pairs trained on the parentheses task with randomly sampled HPs. 8 layer GR U and UGRNN, IRNN and RNN, and LSTM and RNN pairs have loss distrib utions that are different with statistical significance ( p > 0.05). Negati ve t -statistic indicates that the mean of the second architecture in the pair is larger than the first. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment