통계적 기계번역을 위한 형태생성 딥러닝 접근
본 논문은 중국어‑스페인어 번역에서 형태변화를 효율적으로 처리하기 위해 번역 단계와 형태생성 단계를 분리한다. 성·수(성별·복수) 정보를 단순화한 후, 임베딩‑컨볼루션‑LSTM 구조의 신경망으로 성과 수를 각각 98%·93% 정확도로 분류한다. 최종 번역 품질은 METEOR 점수 0.7점 향상된다.
저자: Marta R. Costa-juss`a, Carlos Escolano
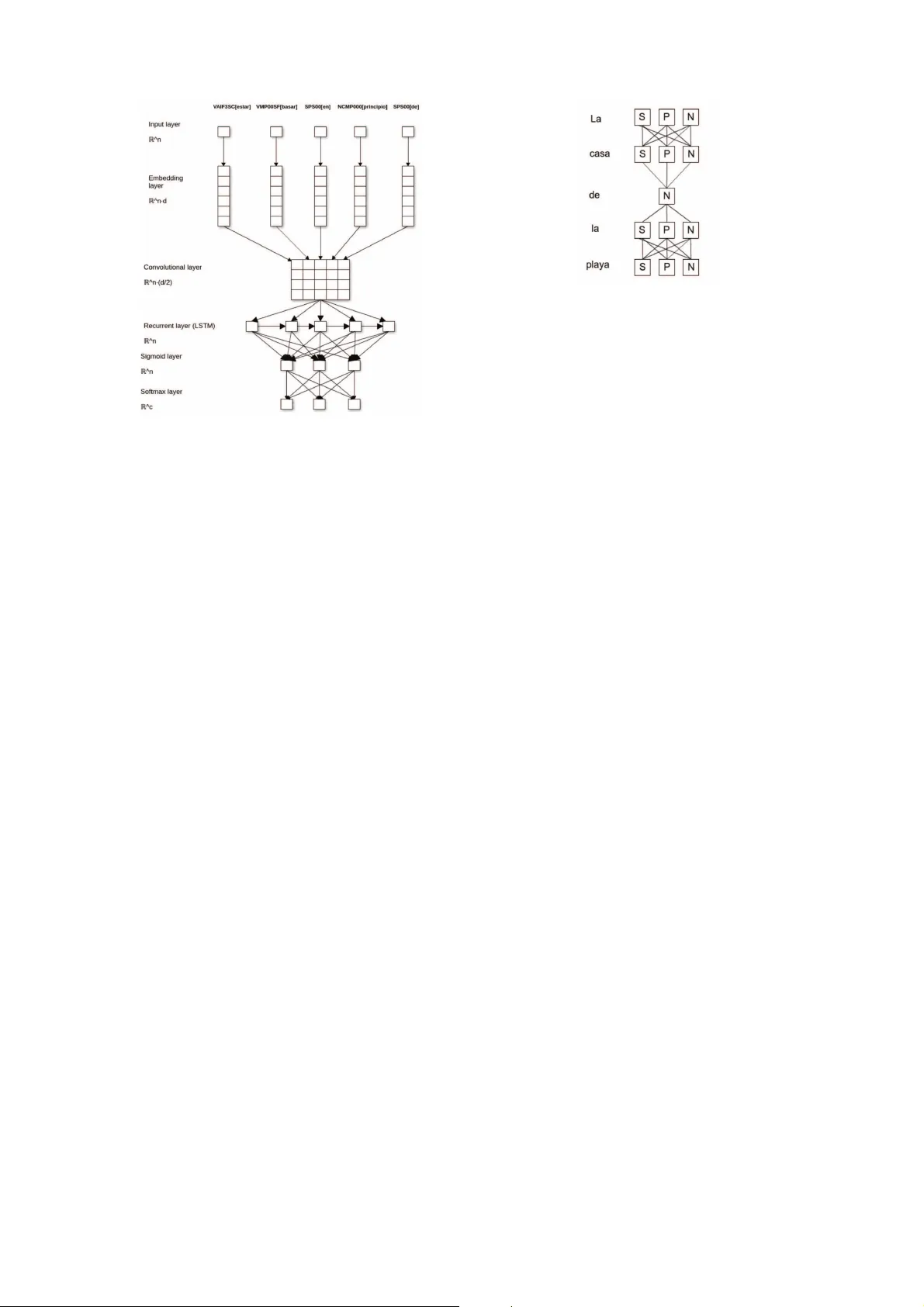
본 논문은 중국어‑스페인어 기계번역에서 형태학적 불균형 문제를 해결하기 위해 번역 단계와 형태생성 단계를 명확히 분리하는 새로운 파이프라인을 제안한다. 기존의 구문 기반 통계적 기계번역(SMT) 시스템은 소스와 타깃 언어 사이의 형태 차이를 충분히 반영하지 못해, 특히 스페인어와 같이 성·수 변화가 풍부한 언어에서 번역 품질이 저하되는 문제가 있었다. 이를 극복하기 위해 저자들은 먼저 번역 결과를 ‘형태가 단순화된’ 스페인어 텍스트로 변환한다. 형태 단순화는 성(gender)과 수(number) 정보를 제거하는 것으로, 이전 연구(Costa‑jussà, 2015)에서 이 두 요소만을 단순화하면 번역 이득과 생성 복잡도 사이의 최적 균형을 얻을 수 있음을 입증했다.
형태단순화된 텍스트를 기반으로 형태생성 모듈을 설계하였다. 이 모듈은 두 개의 독립적인 분류기로 구성되며, 각각 성과 수를 예측한다. 분류기의 입력 특징은 세 가지 유형의 윈도우를 사용한다. 첫 번째는 원문 중국어 단어 윈도우, 두 번째는 단순화된 스페인어 윈도우, 세 번째는 두 언어의 교차 정보를 포함한 윈도우(예: 대명사 여부, 문자 길이 등)이다. 이러한 윈도우 기반 접근은 단어 자체가 형태 정보를 거의 제공하지 못하는 상황에서 주변 컨텍스트를 활용하도록 설계되었다.
신경망 아키텍처는 다음과 같은 계층으로 이루어진다. (1) 임베딩 층: 각 단어를 고정 차원의 실수 벡터로 변환한다. (2) 컨볼루션 층: 1차원 필터를 적용해 지역 패턴을 추출하고, (3) Max‑Pooling 층으로 차원을 절반으로 축소한다. (4) LSTM 층: 윈도우 전체를 순차적으로 처리해 장기 의존성을 포착하고, 최종 은닉 상태 h를 얻는다. (5) 시그모이드 층: h를
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기