Morphology Generation for Statistical Machine Translation using Deep Learning Techniques
Morphology in unbalanced languages remains a big challenge in the context of machine translation. In this paper, we propose to de-couple machine translation from morphology generation in order to better deal with the problem. We investigate the morph…
Authors: Marta R. Costa-juss`a, Carlos Escolano
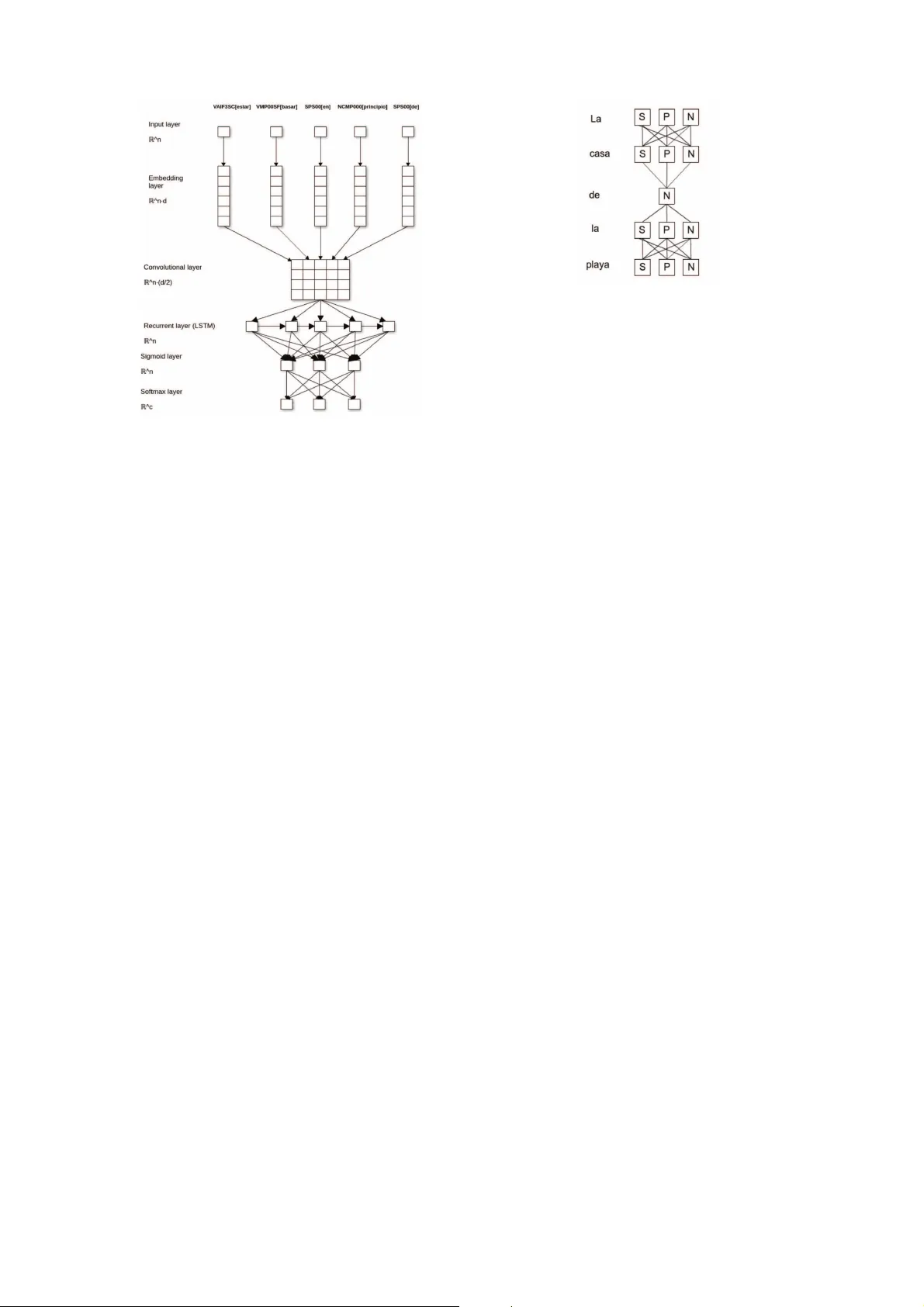
Morphology Generation f or Statistical Machine T ranslation using Deep Learn ing T echniqu es Marta R. Costa-juss ` a and Carlos Escolano T ALP Research Center Univ ersitat Polit ` ecnica de Catalun ya, Barcelona marta.ruiz @upc.edu, carlos.escolano@ts c.upc.edu Abstract Morphol ogy in un balanced languages re- mains a big challenge in the contex t of machine transla tion. In this paper , we propo se to de-cou ple machine translatio n from morp hology generation in or der to better d eal with the proble m. W e i n- ves tigate the morphol ogy simplificatio n with a reasona ble trade-of f betwee n ex- pected gain and gen eration complex ity . For the C hinese -S panish task, optimum morphol ogical simpli fication is in gend er and nu mber . For this pu rpose, we design a ne w classificat ion archite cture which, compared to other standa rd machine learn- ing techniqu es, obtains the best result s. This propo sed neural- based arch itectur e consis ts of se veral layers: an embeddin g, a con volu tional follo wed by a recurr ent neu - ral network and, fina lly , ends with sigmoid and softmax layer s. W e obt ain clas sifica- tion results ove r 98% accur acy in gender classifica tion, ove r 93% in number clas- sification , and an ov erall translati on im- pro vemen t of 0.7 MET EOR. 1 Intr oduction Machine T ranslation (MT ) is ev olving from dif- ferent perspecti ves. One of the most popular paradi gms is still Statis tical Machine T ranslation (SMT), w hich consists in fi nding the m ost proba - ble targe t senten ce gi ven the source sentence using probab ilistic mode ls based on co-ocurren ces. Re- cently , deep lea rning techniq ues applie d to natu ral langua ge processing , speech reco gnition and im- age p rocessing and e ven in MT h ave reache d quite succes sful result s. Early st ages of deep learning applie d to MT include using neural languag e mod- eling for rescoring (Schwenk et al., 2007). Later , deep learning has been integ rated in MT in many dif ferent steps (Zhand and Zong, 2015). No wa- days, deep learning has allo wed to dev elop an entire ne w paradigm, which within one-ye ar of de velopment has achiev ed state-of-th e-art results (Jean et al., 201 5) for some langua ge pairs. In this paper , w e are focusi ng on a challeng- ing translatio n task, which is Chinese-to -Spanish. This trans lation task has the chara cterist ic that we are going from an isolated langu age in terms of morpholog y (Chines e) to a fusional langu age (Spanish ). This means that for a si mple word in Chinese (e.g. 鼓 励 ), the co rrespon ding trans- lation has many dif ferent morpholog y inflexions (e.g. alenta r , alienta , alenta mos, alientan ... ), which dep end on the conte xt. It is still dif ficult for MT in gener al (no matter which paradigm) to ext ract information from the source conte xt to gi ve the corr ect transla tion. W e propo se to div ide the probl em of trans- lation into trans lation and then a postpr o- cessin g of morphol ogy genera tion. This has been done before, e.g. (T outanov a et al., 2008; Formiga e t al., 2013), as we will revie w i n the next sectio n. Ho wev er , the main contrib ution of our work is that we are u sing deep le arning technique s in morph ology generation. This giv es us sig nifi- cant impro vements in translatio n quality . The rest of the paper is or ganise d as follows. Section 2 describe s the related work both in mor- pholo gy generation approaches and in Chinese- Spanish translat ion. Section 3 ove rvie ws the phrase -based MT approach togeth er with an ex- planat ion of the di vide and conquer approach of transla ting an d generating morpholog y . Section 4 details the archite cture of the morphology genera- tion module and it repo rts the main classificatio n techni ques that are used for morpholo gy gener a- tion. Section 5 describes the experi mental frame- work. Section 6 rep orts and di scusse s both clas- sification and translatio n resul ts, which sho w sig- nificant impro vements. Finally , section 7 sum- marises the main conclu sions and further work. 2 Related W ork In this section we are rev iewing the pre vious re- lated works on morphology genera tion f or MT and on Chinese-Spa nish MT approac hes. Morpholog y generation There h a ve been many works in morpholog ical genera tion and some of them are in the co nte xt of the application of MT . In this cases , MT is faced in two-step s: first step where the source is translated to a simpli fied tar - get text that has less m orpho logy va riation than the origin al tar get; and then, second step, a postpro - cessin g module (morpholog y generator) adds the proper inflections. T o name a few of these works, for example, (T outano v a et al., 2008) b uild m ax- imum entropy mark ov m odels fo r inflection pre- dictio n of stems; (Clifto n and S arkar , 2011) and (Kholy and Habash, 2012) use conditiona l ra n- dom fields (CFR) to predict one or m ore mor- pholo gical fea tures; a nd (Formiga et al., 2013) use Support V ecto r Machine s (SVMs) to predict verb inflection s. Other relate d works are in the con- tex t of Part- of-Speech (PoS) tag ging generati on such as (Gim ´ enez and M ` arquez , 2004) in which a model is trained to predi ct each indi vidual frag- ment of a PoS tag by means of m achine learning algori thms. The main diffe rence is that in P oS tag- ging the word itself has informat ion abo ut mor - pholo gical inflection, wher eas in our task, we do not ha ve this information . In this paper , we use deep learn ing tech- niques to morphol ogy genera tion or classifica- tion. Based on the fact that Chinese does not ha ve numbe r and gen der inflection s and S panish does, (Costa-juss ` a, 2015) sho w that simplification in gender and number has the best trade-of f be- tween improv ing translatio n and keepin g the m or - pholo gy generat ion comple xity at a low le vel. Chinese-Spanish There are few works in Chinese- Spanish MT despite being two of the most spok en lang uages in the worl d. Most of these works are based on comparing dif - ferent piv ot strate gies like standard casc ade or pseud o-corp us (Costa-ju ss ` a et al., 2012). Also it is importa nt to mention that, in 2008, there were two tasks or ganised by the popular IWSL T e v aluation campa ign 1 (Intern ational W orksho p on Spoken Language Tran slation ) between these two langu ages (Paul, 2008). The first task was based on a direct translation for Chinese- Spanish. The second task pro vided corpus in Chine se-Englis h and E nglish -Spanish and ask ed particip ants to provide Chinese- Spanish transla tion thr ough pi vot technique s. The second task obtain ed bette r results than direct tran slation becaus e of the larg er corpus provid ed. Dif fer - ently , (Costa- juss ` a and Centelles, 2016) present the first rule-based MT system for Chinese to Spanish. Authors descri be a hybrid method for constru cting this system taking adv antage of av ailable resour ces such as parallel corpora that are used to ext ract dictio naries and lex i- cal and structural transfer rules. Fin ally , it is worth mentioning that nove l succes sful neur al approx imations (Jean et al., 2015), alre ady m en- tioned in the intro duction, hav e not yet achiev ed state-o f-the-art results for this langua ge pair (Costa-ju ss ` a et al., 2017). 3 Machine T ransla tion Ar chitectur e In this section, we re vie w the base line system which is a standard phrase-base d MT system and exp lain the arch itectur e that we are using by di vid- ing the problem of translat ion into: morpholog i- cally simplified translat ion and morphol ogy gen - eration . 3.1 P hrase-based MT baseline syste m The popular phrase -based MT system (K oehn et al., 2003) foc uses on finding the most probab le tar get text giv en a sou rce text. In the l ast 20 years, the phrase- based system has d ra- matically e vol ved intr oducin g ne w technique s and modifyin g the a rchitecture; for exampl e, repl acing the noisy-chan nel for the log-linear model which combine s a set of feature funct ions in the deco der , includ ing the translation and language model, the reorderi ng model and the lexical models. There is a widely used open-sourc e softwa re, Moses (K oehn et al., 2007), which englobes a lar ge co mmunity that helps in the progress of the system. As a consequen ce, ph rase-ba sed MT is a commoditiz ed tech nolog y used at the academic and commerc ial lev el. Howe ver , ther e are still many challen ges to solv e, such as morphology genera tion. 1 http://iwslt2010.fbk.eu 3.2 Divide a nd conquer MT ar chitecture: simplified transla tion and morphology generati on Morphol ogy genera tion is not alw ays achie ved in the standard phrase-bas ed system. This may be due to the fact that phra se-bas ed MT uses a limited sour ce context information to translate . Therefore , we are propo sing to follo w a similar strate gy to pre vious works (T outano v a et al., 2008; Formiga e t al., 2013), where authors do a first transla tion from source to a morphol ogy-ba sed simplified tar get and then, use the morpholog y genera tion module that tran sforms the simpli fied transla tion into the full form outpu t. 4 Morphological Generation Module In order to design the morphology genera tion module, w e ha ve to decid e the morphology simpli- fication w e are appl ying to the transla tion. Since we are focus ing on C hinese -to-Spani sh task and based on (Costa-juss ` a, 2015), the simplificati on which achi eve s the best trade-o ff among highest transla tion gain and lowest complexity of morp ho- logica l generation is the simplification in num- ber and gende r . T able 1 sho ws e xamples of this simplificati on. The main challen ge of this task is that number and gender are generated from words where this inflection info rmation (both number and gende r) has been remov ed beforehand. W ith these results at hand, we propose an ar - chitec ture of the morph ology gene ration m odule , which is langu age indep endent a nd it is easily gen- eraliza ble to other simplificati on schemes. The morpho logy generation procedu re is sum- marised as follo ws and further detailed in the nex t subsec tions. • Feature sele ction. W e ha ve in vestigat ed dif- ferent set of features including information from both source and tar get languag es. • Classification . W e prop ose a new deep learn- ing classification arch itectur e composed of dif ferent layers. • Rescoring and rules . W e generate dif ferent alterna tive s of the classification output and rerank the m usin g a langua ge model. After , we use hand-c rafted rules that allo w to solve some spec ific proble ms. This procedu re is d epicted in Figu re 1, in which we c an se e that each of the abo ve pro cesses gener - Figure 1: Block Diagram for Morpholog y Gene r - ation ates the nee ded input fo r the ne xt step. F igure also sho ws in red t he main subpr ocesse s that ha ve bee n de veloped on this work. 4.1 Featur e selectio n W e propose to compare se veral feat ures for reco v- ering morphologic al information . Giv en that both Chinese and simplified Spanish language s do no t contai n explic it morphology information, w e start by simply using windo ws of words as source of informat ion. W e follo w Collobert’ s approach in which each wor d is represent ed by a fixed size windo w of words in which the cent ral elemen t is the one to classi fy (Collobert et al., 2011). In our case, w e exper iment with three dif ferent inputs : (1) Chinese windo w ; (2) simplified Span- ish windo w; (3) Spanish window addin g infor - mation about its cor respon dant word in Chinese, i.e. informatio n about pro nouns and the number of characte rs in the word. T he main advan tage of the second on e is that it is not dependant on the alignmen t fi le gener ated during translation. Our classifiers did not ha ve to train all type s of wo rds. Some type s of words, such as prep o- sition s ( a, ante, cabo, de ... ), do not ha ve gende r or number . Therefore our syst em was trained using only determiners, adjecti ves, verbs, prono uns and nouns whi ch ar e the ones th at pre sent m orpho logy Es num decidir[VMIP3 N 0] examinar[VMN0000] el[D A0M N 0] c uesti ´ on[NCF N 000] en[SPS00] el[DA0M N 0] per ´ ıodo[NCM N 000] de[SPS00] sesi ´ on[NCF N 000] el[D A0M N 0] tema[NCM N 000] titular [A Q0M N 0] “[Fp] cuesti ´ on[NCF N 000] relativo[ AQ0F N 0] a[SPS00] el[D A0M N 0] derecho[NCM N 000] humano[A Q0M N 0] “[Fp] .[Fp] Es gen decidir[VMIP3S0] examinar[VMN0000] el[D A0 G S0] cuesti ´ on [NC G S000] en[SPS00] el[D A0 G S0] per ´ ıodo[NC G S000] de [SPS00] sesi ´ on[NC G S000] el[D A0 G S0] tema[NC G S000] titular [A Q0 G S0] “[Fp] cuesti ´ on[NC G S000] relativo[A Q0 G S0] a[SPS00] el[D A0 G S0] derecho[NC G S000] humano[A Q0 G S0] “[Fp] .[Fp] Es numgen decidir[VMIP3 N 0] examinar[VMN0000] el[D A0 GN 0 ] cuesti ´ on[NC GN 000] en[SPS00] el[D A0 GN 0] per´ ıodo[NC GN 000] de[SPS00] sesi ´ on[NC GN 000] el[D A0 GN 0] tema[NC GN 000] titular [A Q0 GN 0] “[Fp] cuesti ´ on[NC GN 000 ] relativ o[A Q0 GN 00 ] a[SPS00] el[DA0 GN 0] derecho[NC GN 000] humano[A Q0 GN 0] “[Fp] .[Fp] Es Decide examinar la cuesti ´ on en el per´ ıodo de sesiones el tema titulad o “ Cuestiones relati vas a los derechos hum anos ” . T able 1: Example of Spanish simplification into number , gender and both . v ariations in gender or number . Howe ver , note that all types of words are us ed in the windows. 4.2 Classifica tion architec ture Description W e pro pose to train two dif ferent models: one to retrie ve ge nder and another to re- trie ve number . Each model de cides among three dif ferent classes. Classes for gender classifier are masculin e ( M ), femenine ( F ) and none ( N ); and classe s for number classifier are singular ( S ), plu- ral ( P ) and none ( N ) 2 . Again, we inspire our ar- chitec ture in pr e vious Coll obert’ s proposa l and we modify it by adding a recurrent neural network. This recurrent neural network is rele v ant becau se it keeps informati on about pre vious ele m ents in a sequen ce an d, in our cla ssificatio n problem, con- tex t wo rds are ve ry relev ant. As a recu rrent neu- ral netw ork, we use a Long Short T erm Memory (LSTM) (Hochreit er and S chmidhu ber , 1997) that is pro ven ef ficient to deal with sequence NLP chal- lenges ( Sutsk e ver et al., 2014). This kind of re cur- rent neural networ k is able to maintain information for se veral element s in the sequence and to forget it when needed . Figure 2 s ho ws an ov ervie w of the dif ferent layers in volv ed in the final classi fication archite cture, which are detai led as follo ws: Embedding . W e repres ent each word as its in- dex in the vo cab ulary , i.e. ev ery word is repre- sented as one discr ete v alue: E ( w ) = W, W ∈ R d , w being the index of the word in the sorted v o- cab ulary and d the user chosen size of the array . Then, each w ord is rep resent ed as a nume ric array and each windo w is a matrix. Con voluti onal. W e add a con volut ional neu- ral network . This step allows the system to de- tect some common patterns between the dif ferent 2 None means t hat t here is no need to specify gender or number information because the word is in variant in these terms. T his happens for types of words (determiners, nouns, verbs, pronouns and adjectiv es) that can hav e gender and number in other cases. words . T his laye r’ s input con sists in W l matrix of multidimen sional arrays of size n · d , where n is the w indo w length (in words) and d is the size of the array created b y the pre vious emb edding layer . This layer’ s output is a matrix of the same size as the inpu t. Max P ooling . This layer allo ws to extract most rele van t features from the input dat a and reduces feature vec tors to half. LSTM. Each featur e array is treated indi vidu- ally , genera ting a fixed size repres entation h i of the i th word using information of all the pre vious words (in the sequence). This layer’ s output , h , is the r esult of the last e lement of the sequence using informat ion from all pre vious words. Sigmoid. This layer smooth es res ults obtained by pre vious layer an d compresses res ults t o the in- terv al [ − 1 , 1] . This layer’ s inp ut is a fixed size v ec- tor of shape 1 · n where n is the number o f neuro ns in the pre vious LS TM layer . T his layer’ s output is a vec tor of length c equal to the numbe r of class es to predi ct. Softmax. This layer allo ws to sho w results as probab ilities by ensurin g that the returned v alue of each class belon gs to the [0 , 1) interv al and all classe s add up 1. Motiv ation Our input data is PoS tagged and morphog ically simplified before the classification archite cture which lar gely reduces the informati on that can be extracte d from indi vidual words in the v ocabu lary . In addition , we can encoun ter out-of- v ocabu lary words for which no morpho logical in- formatio n can be extracte d. The main source of information av ailable is the conte xt in whic h the wo rd can be found in the se n- tence. Consider ing the window as a sequence en- forces the be haviou r a hu man would ha ve while readin g the sente nce. The info rmation of a word consis ts in itself and the words tha t surround it. Sometimes information preceeds the word and sometimes information is after the wor d. W ords Figure 2: Neural network ov ervie w . (lik e adj eti ves), which are modifyi ng or comple- menting another word, generally take informati on from preceedin g words. For exa m ple, in the se- quenc e c asa blanca , the word blanca could also be blanco , blancos or blanc as bu t because noun and adject i ve are required to ha ve gende r and number agreemen t, the femenine word casa forces the fe- menine for blanc a . While , for example , determin- ers u sually tak e informatio n from posteri or words. This fac t m oti vates tha t the word to c lassify has to be placed at the center of the windo w . Finally , gi ven that we rely only on th e conte xt informat ion since words themsel ves may not hav e any informa tion, makes the rec urrent neural net- work a key element in o ur arc hitecture. T he output h of the layer can be considered a contex t vector of the w hole w indo w maintaining informat ion of all the prev iously encounte red words (in the same windo w). 4.3 Rescori ng and rules At this poin t in the pipe line, we hav e two mod- els (gender and number) that allow us to generate the full Part-of-Speec h (PoS) tag by combining the best result s of both classifier s. Ho wev er , in order to impro ve th e o verall perfor - mance, we add a rescoring step followed by some hand-c rafted rules. T o generate the dif ferent al- ternati ves, we represen t e very sentence as a graph (see Figure 3), with the follo wing propert ies: • Each word is repr esente d as a lay er of the graph and each node represen ts a class of the Figure 3: Example of sen tence graph. S stands for singul ar , P for plural and N for none classifica tion model. • A node onl y ha s edges w ith all the nod es of the n ext layer . T his way we force the origin al senten ce order . • An edge’ s weight is the probability giv en by the classifica tion model. • Each accepted path in the graph starts in the first layer and ends in the last one. This acy clic structure fi nds the best path in linear time, due to the fact that it goes through all layers and it picks the node with the great est weight. One layer can hav e either 1 element (the word does not need to be classified, e.g. prepos itions) or 3 elements (the wor d needs to be classified among the three number or gende r catego ries). • Add the weight of a pre viously trained target langua ge model. W e use d Y en’ s algorith m (Y en, 197 1) to find the best path, which has an assoc iated cost of O ( K N 2 log N ) , being K the number of paths to find. See p seudo code in Algori thm 1, where A is the set paths chosen in the graph. The algorith m ends when this A set contains K pa ths or no further paths av ailable to expl ore. B contain s all subopti - mal paths that can be electe d in future itera tions. There are two special cases that the models were not able to treat and we apply specific rules: (1) conjun ctions y and o are replaced by e and u if the y are placed in front of vo wels. T his could not be generated dur ing tran slation bec ause both words share the same tag and lemma; (2) verbs with a prono un as a suffix, pr oducir se , second to last syllab e stretche d ( palab ras llanas ) and end- ing in a v owel are no t acc entuated. Howe ver , af- ter adding t he su ffix, th ese words should be a ccen- tuated bec ause they bec ome pala bra s esdr ´ ujulas , which happen to be alw ays accentua ted. Data : G Graph of the sentence, K Result : best k paths in G initialization; A[0] = bestPath(G,0,final); B = [] ; i = 0; for i < K do for i in range(0, len(A[K-1])-1) do spurNode = A[K-1][i]; root = A[K-1][0;i]; for path in A do if r oot = path[0:i] then remov e edge(i-1,i) from G; end end for node in r oot and node != spurNode do remov e s node node from G; end spurPath = bestPath(G,spurnode, final) totalP ath = root + spurPath; B.append(totalPath); restore edges from G; restore nodes from G; if B is empty then break; end B.sort(); A.append(B[0]); B.pop(); end end Algorithm 1: P seudo -code for k-best paths gen- eration . 5 Experimental framework In this section, we descri be the data used for exper - imentatio n together with the corr espon ding pre- proces sing. In addition , we detail chosen parame- ters for the MT sy stem and the classificati on algo- rithm. 5.1 Data and pr eproce ssing One of the main contri b utions of this work is using the C hinese -Spanish language pair . In the las t yea rs, there has appeared more and more resou rces for this language pair av ailabl e in L Set S W V ES Train Small 58.6K 2. 3M 22.5K Large 3.0M 51.7M 207.5K Developm ent 990 43.4K 5. 4k T est 1K 44.2K 5. 5K ZH Train Small 58.6K 1. 6M 17.8K Large 3.0M 43.9M 373.5K Developm ent 990 33K 3.7K T est 1K 33.7K 3. 8K T able 2: Corpus Statistic s. Number of sentences (S),words (W), voc ab ulary (V). M stands for mil- lions and K stands for thousan ds. (Ziemski et al., 2016) or fro m T A US corporation 3 . Therefore , dif ferently from pre vious w orks on this langua ge pair , we can test our approach in both a small and lar ge data sets. • A small trainin g corpus by using the United Nations Corpus (UN ) (Rafal ovi tch and Dale, 2009). • A large trai ning corpus by using, in ad- dition to the UN corp us, the T A US cor - pus, the Bibl e corpus (Che w et al., 2006) and the B TEC (Basic Tra velle r Expression s Cor- pus) (T akeza wa, 2006). The T A US corpus is around 2,890,000 senten ces, the B ible corpu s about 30,000 senten ces and the BTEC corpu s about 20,000 sentenc es. Corpus statistics are shown in T able 2. Dev el- opment and test sets are tak en from UN corpus. Corpus preprocessi ng consist ed in tokeni za- tion, filtering empty sentenc es and longer than 50 words , Chinese segmenta tion by means of the Zh- Seg (Dyer , 2016), Spanish lowercas ing, filtering pairs of sentences with more than 10% of no n- Chinese charac ters in th e Chinese side and m ore than 10% of non-Spanish charac ters in the S panish side. S panish PoS tagging was done using F r eel- ing (Pad r ´ o and S tanilo vsky , 2012). All chunkin g or name entity recognitio n was disable d to pre- serv e the original number of words. 5.2 MT Baseline Moses has been trained usin g defaul t parame- ters, which include : gro w-diag-final word align- ment sy m metrizati on, lexic alized reorder ing, rela- ti ve frequenc ies (conditio nal and posterior proba- bilitie s) with ph rase disco unting , lexic al weights , phrase bonu s, accepti ng ph rases up to len gth 10, 5-gram language model with knes er -ney smooth- ing, word bo nus and MER T optimisat ion. 5.3 C lassifica tion p arameter s T o g enerate the classifica tion architecture we used the library ke ras (Chol let, 2015) for creating and ensambli ng the dif ferent layers . Using NVIDIA GTX T itan X GPUs with 12GB of memory and 3072 CUD A Cores, each classifier is trained on aproxi mately 1h and 12h for th e small and lar ge corpus , respecti vely . 3 http://www .taus.net Regar ding classificati on paramet ers, ex peri- mentatio n has sho wn that number and gende r clas- sification tasks ha ve dif ferent requirements. T able 3 summarizes these paramete rs. The best w indo w size is 9 and 7 words for numb er and gender , re- specti vely . In both cases increasing this size low- ers the accurac y of the system. The voc abular y size is fixed as a trade-of f between gi ving enoug h informat ion to the system to perform the classi- fication while remov ing enough words to train the classifier for un known words. The embedding size of 128 results in stable train ing, while further in- creasin g this v alue augmente d the tra ining time and hardware cost. The fi lter size in the con- v olutional lay er reached best results when it was slight ly smaller than the windo w size, being 7 and 5 the best v alues for number and gender cl assifica- tion, respecti vely . Finally , incre asing LSTM nodes up to 70 improved significantly for both classifiers. T able 3: V alue s of the diffe rent paramet ers of the classifier s Parameter Small Large Num Ge n Num Gen Wind ow size 9 7 9 7 V oc abulary size 7000 90 00 15000 15000 Embedding 128 128 128 128 Filter size 7 5 7 5 LSTM nodes 70 70 70 70 For windo ws, we only used the simplified Span - ish translation. In T able 4 we can see that testing dif ferent sources of information with the classifier of number for the smal l cor pus. A dding Chinese has a neg ati ve effe ct in the classifier accurac y . 5.4 Rescori ng and Full form genera tion As a resc oring tool, we use the on e av ailable in Moses 4 . W e trai ned a stan dard n-gram lan guage model with the SRILM toolkit (Stolck e, 2002). In order to generate the final full form we use the full PoS tag, generated from the post- proces sing ste p, and the lemma, taken from the morphol ogy-si mplified translation output. Then, we use the v ocab ulary and conjugatio ns rules pro- 4 https://github .com/moses- smt/mosesdecode r/tree/master/scripts/nbest-rescore T able 4: A ccurac y of the classifier of number us- ing dif ferent sources of informat ion. Features Accuracy (%) Chinese window 72 Spanish window 93,4 Chinese + Spanish window 86 vided by F r eeling . F ree ling ’ s cov erage rais es the 99%. When a word is not found in the dictio- nary , we test all gender and/or number inflections in descend ant order of probab ility un til a match is found. If none matche d, the lemma is use d as transla tion, which usually happe ns only in the case of cities or demon yms. 6 Evaluation In this section we discuss th e results obtained bot h in class ification and in the final trans lation task. T able 5 sho ws results for the classification task both number and gende r and w ith the dif ferent corpus sets. W e ha ve contras ted our propo sed classifica tion architec ture based on neural netw orks with standard machine learning techni ques such as line ar , cuad ratic and sigmo id ker nels SVMs (Corte s and V apnik, 1995), random forests (Breiman, 2001), con volu tional( Fukushima, 1980) and LSTM(Hochreiter and Schmidhub er , 1997) neural networks (NN). All algori thms were tested using features and parameters descri bed in pre vious sections with the exc eption of random forests in which we ad ded the one hot encodi ng repres entatio n of the words to the feat ures. W e observ e that our propos ed archi tecture achie ves by lar ge the best resu lts in all tasks. It is also remarkable that the accuracy is lo wer us- ing the bigger corpus, this is due to the f act that the small s et consiste d in te xts of the same domain and the v ocab ulary had a bette r representat ion of specific word s such as country names. T able 5: Classification results. In bold , best re- sults. Num stands for Number and Gen, for Gen- der Algorithm Small Large Num Gen Num Gen Naive Bayes 61.3 53.5 61. 3 53.5 Lineal kernel SVM 68.1 71.7 65.8 69.3 Cuadratic kernel SVM 77.8 81.3 77.6 82. 7 Sigmoid kernel SVM 83, 1 87.4 81. 5 84.2 Random Forest 81.6 91.8 77.8 88.1 Conv olutional NN 81.3 93.9 83.9 94.2 LSTM NN 68.1 73.3 70.8 71.4 CNN + LSTM 93.7 98. 4 88.9 96. 1 T abla 6 s ho ws tra nslatio n results. W e s ho w both the Oracle and the result in terms of METE OR (Banerjee and Lav ie, 2005). W e observ e improv e- ment in most cases (when classif ying number , gende r , both and rescoring), b ut best results are obtain ed when cla ssifyin g number and gend er and rescor ing number in the large corpu s, obtaining a T able 6: MET EOR results. In bold, best results. Num stands for Number and Gen, for Gender Set System UN Oracle Res ult Small Baseline - 55.29 +Num 55.60 55.35 +Gen 55.45 55.39 +Num&Gen 56.81 55.48 +Num&Gen +Rescoring(Num&Gen) - 54.91 +Num&Gen +Rescoring(Num) - 55.56 Large Baseline - 56.98 +Num 58.87 57.51 +Gen 57.56 57.32 +Num&Gen 62.41 57.13 +Num&Gen Rescoring - 57.74 gain up to +0.7 METEOR . Rescorin g step improv es fi nal resu lts. Note that rescor ing was only applied to number clas sifica- tion because gen der class ifi cation model has a low classifica tion error (bel lo w 2%) which makes it harder to further decre ase it. Additionally , gen der and number classi fication scores are not be compa- rable and not easily inte grated in Y en’ s algori thm. 7 Conclusions Chinese- to-Spanis h translation task is challeng- ing, sp ecially becau se of Spani sh being morp ho- logica lly rich compared to C hinese . Main contri- b utions of this pa per i nclude c orrectly de-co upling the translation and morphol ogical gene ration tasks and proposin g a ne w classification architecture , based on deep learnin g, for number and gende r . Standard phrase-ba sed MT procedure is chang ed to first translatin g into a morpholog ically simplified tar get (in terms of number and gender); then, introducing the classificati on algor ithm, based on a ne w propo sed neural netwo rk-base d archite cture, that retrie ves the si mplified morphol- ogy; and composing the final full form by using the standa rd F r eeling dictiona ry . Results of the propos ed neural -netwo rk archi - tecture in the classification task compared to stan- dard algorithms (SVM or random forests) are sig- nificantly better and results in the translation task achie ve up to 0.7 METEOR impro vement. As fur - ther work, we intend to furthe r simplify morphol- ogy and ext end the scope of the classification . Acknowledgeme nts This work is suppor ted by the 7th Framew ork Pro- gram of the European Commission through the In- ternati onal Outgoing F ello wship Marie Curie Ac- tion (IMTra P -2011- 29951 ) and also by the Span- ish Ministeri o de Econom ´ ıa y Competiti vidad and Fondo Europ eo de Desarrollo Regional, through contra ct TEC2015-692 66-P (MINECO/FEDER , UE) and the postd octora l senior gran t Ram ´ on y Cajal . Refer ences [Banerjee and Lavie2005] Satanjeev Banerjee and Alon Lavie. 20 05. Meteor: An automatic metric for mt ev a luation with improved correlation with human judgmen ts. In Pr oce edings of the a cl workshop on intrinsic and extrinsic evaluatio n measur es for ma- chine translation and/or summarization , volume 29, pages 65–72. [Breiman20 01] Leo Breim an. 2001. Random forests. Machine learning , 45( 1):5–3 2. [Chew et al.2 006] Peter A Chew , Steve J V erzi, T ravis L Bauer , and Jonathan T McClain. 2006. Evaluation Of The Bible As A R esource For Cross-lan guage In- formatio n Retriev al. In Pr oce edings o f the W ork- shop on Multilingual Lang uage Resou r ces a nd In - ter operability , pages 68–74. [Chollet201 5] Fran c ¸ ois Chollet. 2 015. Keras, https://github.com/fchollet/keras. [Clifton and Sarkar201 1] An n Clifton and An oop Sarkar . 2 011. Com bining mor pheme- based m a- chine translation with po st-processing mor pheme prediction . In P r oceeding s of the 49th Annual Meeting of the Associa tion for Compu tational Lin - guistics: Hu man Language T echno logies - V olume 1 , HL T ’1 1, pages 32–4 2, Stro udsburg, P A, USA. Association for Computationa l Linguistics. [Collobert et al.2011 ] Ronan Collobert, Jason W e ston, L ´ eo n Bo ttou, Mich ael Karlen , Koray Kavukcuo glu, and Pa vel Kuksa. 2011. Natu ral languag e pr o- cessing (almost) from scratch . Journal of Machine Learning Resear ch , 12(Aug ):2493 –2537. [Cortes and V apnik1 995] Corin na Cor tes and Vladimir V apnik. 1995 . Supp ort-vector networks. Ma chine learning , 20(3):27 3–297 . [Costa-juss ` a and Cente lles2016] Marta R. Costa-ju ss ` a and Jord i Centelles. 2016 . Des cription o f the chinese-to- spanish rule- based machine translation system dev e loped using a hybrid combination o f human anno tation a nd statistical techniques. A CM T ransaction s on Asian and Low-Resour ce Language Information Pr ocessing , 15. [Costa-juss ` a et al.2 012] Marta R. Co sta-juss ` a, Carlos A. Henr´ ıquez Q., and Rafael E. Banchs. 2012. Eval- uating indirect strategies for chinese-spa nish statisti- cal m achine translation. Journal Of Artificia l I ntel- ligence Resear ch , 45:762–78 0. [Costa-juss ` a et al.2 017] Marta R. Costa-juss ` a, David Ald ´ on, and Jos ´ e A. R. Fonollosa. 2017 . Chinese- spanish neural mach ine translation en hanced with character and word bitmap fonts. Machine T rans- lation , page Accepted for publication. [Costa-juss ` a 2015] Marta R. Costa-ju ss ` a. 2015 . On- going study for enhancing chinese-span ish transla- tion with mo rpholo gy strategies. In Pr oc. of the AC L W o rkshop o n Hybrid Appr oaches to T ransla- tion , Beijing. [Dyer20 16] Christopher Dyer . 2016 . http://code.g oogle. com/p/zhseg/. [Formiga et al.2013] Llu´ ıs F o rmiga, Marta R. Costa- juss ` a, Jos ´ e A. R. Mari ˜ no, Jos ´ e B.and Fono llosa, Al- berto Barr ´ on-Cede ˜ no, an d Llu´ ıs M ` arquez. 2013. The T ALP-UPC ph rase-based translation systems for WMT13: System combin ation with morp hol- ogy gene ration, dom ain adaptation and corpus filter- ing. In Pr oceed ings of the Eighth W orkshop o n Sta- tistical Machine T ranslation , p ages 1 34–14 0, Sofia, Bulgaria, August. [Fukushim a1980] K u nihiko Fukushim a. 1980. Neocogn itron: A self-o rganizing neur al network model fo r a mecha nism of p attern recogn ition unaf- fected by shift in position . Bio logical cybernetics , 36(4) :193–2 02. [Gim ´ enez and M ` arqu ez2004 ] Jes ´ us Gim ´ enez an d Llu´ ıs M ` ar quez. 2004 . Svmtoo l: A gener al po s tagger generato r based on su pport vector mach ines. In In Pr oceedin gs of the 4th Inte rnational Co nfer en ce on Language Resour ces and Evaluation . Citeseer . [Hochreiter and Schmid huber1 997] Sepp Hoch reiter and J ¨ urgen Schmidh uber . 1 997. Long short-te rm memory . Neural computa tion , 9(8):1735– 1780. [Jean et al.201 5] Sebastien Jean, Orh an Firat, Kyunghun Cho, Roland Mem ˜ ise vic, and Y oshua Bengio. 2015. Montreal n eural ma chine translation systems for wmt1 5. In Pr oc. of the 10th W orkshop on Statistical Machine T ranslation , Lisbon. [Kholy and Habash20 12] Ahmed El Kho ly a nd Nizar Habash. 201 2. Rich morp hology genera tion using statistical m achine tran slation. In Pr oceedin gs of the Seventh Internatio nal Natural Language Generation Confer en ce , INLG ’12, page s 90 –94, Stroudsburg, P A, USA. Association for Computation al Linguis- tics. [K o ehn et al.2003] Philipp K oehn, Fran z Joseph Och, and Daniel Marcu. 2 003. Statistical Phr ase-Based T ra nslation. I n Pr oc. of the A CL . [K o ehn et al.2007] Philipp K oehn , Hie u Hoang, Alexandra Birch , Chris Callison-Burch , Marcello Federico, Nicola s Bertoldi, Brooke Cow an, W ade Shen, Christine Moran, Richar d Zens, Chris Dy er , Ondrej Bojar, Alexandra Constantin, and E van Herbst. 2007 . Moses: Open Sour ce T oo lkit for Statistical M achine T ranslation. In Pr oc. o f the 4 5th A nnual Meetin g o f th e Association fo r Computation al Lingu istics , pag es 177–180 . [Padr ´ o and Stanilovsky201 2] Llu´ ıs Padr ´ o and E vgeny Stanilovsky . 2012. Freeling 3. 0: T owards wider multilingua lity . I n Pr oceed ings of the Language Re- sour ces and Evalua tion Confer en ce (LREC 2012) , Istanbul, T urkey , May . ELRA. [Paul2008] Michael Paul. 2008 . Overview of the iwslt 2008 evaluation c ampaign. In Pr o c. of th e I nterna- tional W orkshop on Spoken La nguage T ranslation , pages 1–17, Haw aii, USA. [Rafalovitch and Dale200 9] Alexandre Rafalovitch and Robert Dale. 2009 . United Nations General A ssem- bly Resolutions: A Six -Langu age Parallel Corpus. In Pr oc. of the MT Su mmit XII , p ages 2 92–29 9, Ot- tawa. [Schwenk et al.200 7] Ho lger Schwenk , Marta R. Costa- juss ` a, and Jos ´ e A. R. Fonollosa. 2007. Smooth bilingual ngram translation. In Pr oc. of the EMNLP , Prague. [Stolcke2002 ] A. Stolcke. 2002. SRILM - an extensi- ble lang uage mod eling toolk it. In 7th Internation al Confer en ce on Spoken Langu age Pr ocessing , Den- ver . [Sutskev er et al.20 14] I lya Sutskever , Orio l V inyals, and Quoc V . Le. 2014. Seq uence to sequence learn- ing with neural networks. In CoRR . [T akezawa2006] T o shiyuki T akezawa. 2006. Multilin- gual spoken langu age cor pus development for co m- municatio n research . In Chinese Sp oken Langu age Pr ocessing, 5th Internation al Symposium, ISCSLP 2006, Sing apore , De cember 1 3-16, 200 6, Pr oceed- ings , pages 781–79 1. [T outanova et al.2008 ] Kr istina T o utanova, Hisami Suzuki, and Achim Ruo pp. 20 08. Applying m or- pholog y g eneration mo dels to machin e translation . In Pr oc. of the confer en ce o f th e Association for Computation al Lingu istics and Human Lang uage T echnology (ACL-HL T) , pages 514– 522, Columbus, Ohio. [Y en1 971] Jin Y Y en. 19 71. Find ing th e k sh ortest loopless p aths in a network. management Scien ce , 17(11 ):712– 716. [Zhand and Zong20 15] Jiajun Zhan d a nd Chengqing Zong. 2015. Deep neural networks in mach ine translation: An overview . I EEE Intelligent S ystems , pages 1541–1 672. [Ziemski et al.2016] Michał Ziemski, Marcin Junczys- Dowmunt, and Brun o Pou liquen. 2016. The un ited nations parallel co rpus v1.0. In Pr oceeding s of the T enth I nternationa l Conference on Langu age Re sour ces and Evalua tion (LREC 2016) , may . This figure "nn.png" is available in "png" format from: This figure "sentenceGraph.png" is available in "png" format from:
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment