강화학습 기반 신경망 조합 최적화
본 논문은 순환 신경망과 정책 그라디언트 강화학습을 결합해 2차원 유클리드 TSP와 배낭 문제를 해결하는 프레임워크를 제안한다. 포인터 네트워크를 확률 정책으로 사용하고, 투어 길이의 부정값을 보상으로 삼아 파라미터를 학습한다. 사전 학습(RL pre‑training)과 테스트 시 활성 탐색(active search)을 조합하면 100노드 TSP와 200아이템 배낭 문제에서 거의 최적에 근접한 해를 얻는다.
저자: Irwan Bello, Hieu Pham, Quoc V. Le
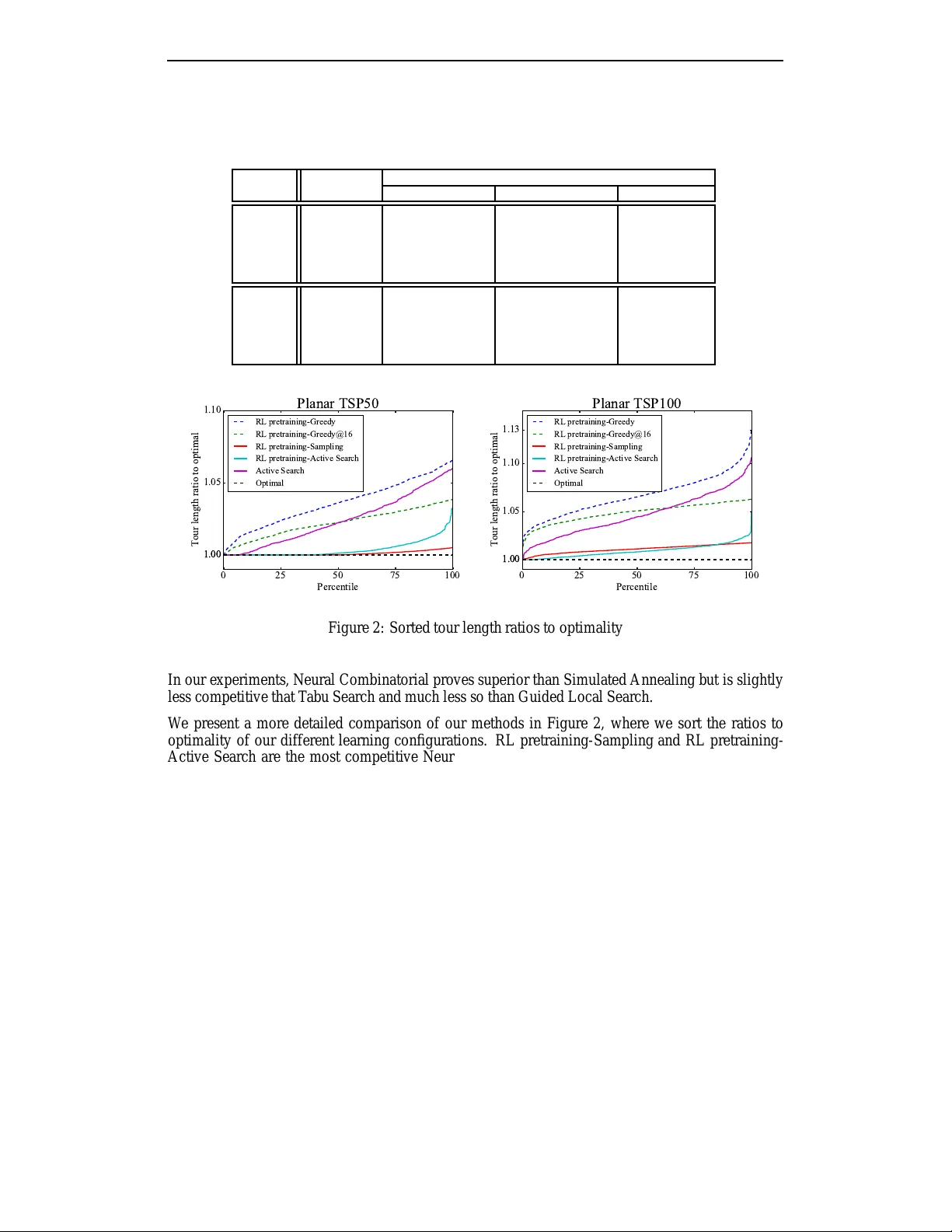
본 논문은 조합 최적화 문제, 특히 2차원 유클리드 TSP와 배낭 문제를 해결하기 위한 새로운 프레임워크인 Neural Combinatorial Optimization을 제안한다. 핵심 아이디어는 순환 신경망, 구체적으로 포인터 네트워크를 확률 정책으로 사용하고, 강화학습의 정책 그라디언트 기법을 통해 직접 보상을 최적화하는 것이다. 입력은 n개의 2차원 좌표 집합 s={x_i}이며, 목표는 모든 도시를 한 번씩 방문하는 최소 길이 투어 π를 찾는 것이다. 포인터 네트워크는 인코더‑디코더 LSTM 구조를 갖추고, 인코더는 각 좌표를 d‑차원 임베딩으로 변환해 은닉 상태 enc_i를 생성한다. 디코더는 현재까지 선택된 순서를 쿼리 벡터로 사용해 어텐션(포인팅) 메커니즘을 적용, 남은 도시들에 대한 확률 분포를 계산한다. 이 과정은 체인 룰에 따라 pθ(π|s)=∏_{i=1}^n pθ(π(i)|π(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기