Neural Combinatorial Optimization with Reinforcement Learning
This paper presents a framework to tackle combinatorial optimization problems using neural networks and reinforcement learning. We focus on the traveling salesman problem (TSP) and train a recurrent network that, given a set of city coordinates, pred…
Authors: Irwan Bello, Hieu Pham, Quoc V. Le
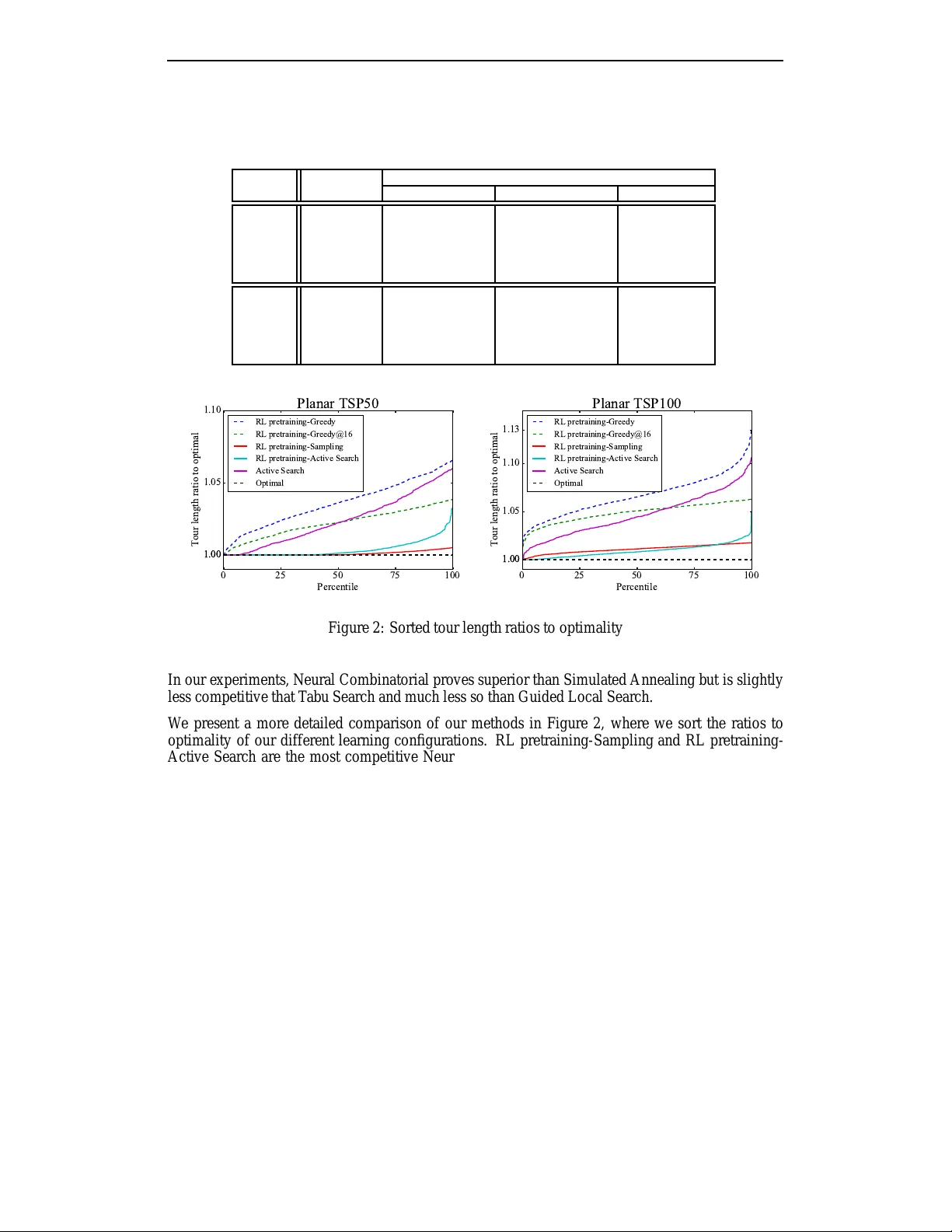
Under revie w as a conference paper at ICLR 2017 N E U R A L C O M B I NA T O R I A L O P T I M I Z A T I O N W I T H R E I N F O R C E M E N T L E A R N I N G Irwan Bello ∗ , Hieu Pham ∗ , Quoc V . Le, Mohammad Norouzi, S amy Bengio Google Brain { ibello,hy hieu,qvl,mnorouzi,ben gi o } @google.com A B S T R AC T This paper presents a framework to tackle combin atorial optimization problem s using neural network s and reinfor cement learning . W e f ocus o n th e traveling salesman pr oblem (T SP ) and train a recurren t neural network that, giv en a set of city coor dinates , pred icts a distribution ov er different city permutations. Using negativ e tour length as th e reward signal, we op timize the parameters of the r e- current neu ral network using a policy grad ient method. W e compare learning the network parameters on a set o f training gra phs against learning them on indi vid- ual test graphs. Despite th e computation al expense, with out mu ch engineer ing and heuristic designing, Neural Combinator ial Optimization achiev es close to optimal results on 2D Eu clidean grap hs with up to 10 0 nodes. Ap plied to the KnapSack, another NP-har d proble m, the same method ob tains op timal solutio ns for instances with up to 200 items. 1 I N T RO D U C T I O N Combinatorial optimization is a fundam ental problem in comp uter science. A can onical example is the traveling salesman pr oblem (TSP) , where given a graph, one need s to searc h the space o f permutatio ns to find an op timal sequence of node s with minim al total edge weights (tour len gth). The TSP and its variants h a ve myriad applications in plan ning, ma nufacturing, ge netics, etc. (see (Applegate et al., 2011) for an o verview). Finding the optimal TSP solution is NP-hard, ev en in the two-dimensional E uclidean case (Papadimitriou, 1 977 ), whe re the nod es are 2D points and edge weigh ts are Euclidean dis- tances between pairs of points. In pr actice, TSP solvers rely on handcraf ted heuristics that guide their searc h proce dures to find c ompetiti ve tours efficiently . Even thoug h these heur isti cs work well on TSP , once the p roblem statem ent chang es slightly , th e y need to be revised. In contrast, machine learn ing m ethods hav e the poten tial to be ap plicable across many optimizatio n tasks by automatically d isco vering th eir own heuristics based o n the training data, thus req uiring less hand- engineer ing th an solvers that are optimized for one task only . While most successfu l m achine learn ing techniq ues fall into the family of superv is ed learning , whe re a mapping from training inputs to outputs is learned, superv ised learning is not applicable to most combinato rial o ptimization problem s b ecause one does not ha ve access to optimal labels. Howe ver , one c an comp are the quality o f a set of so lutions using a verifier, and provide som e reward feedback s to a learning algorithm . Hence, we follow the reinf orcement learning (RL) paradig m to tac kle combinato rial optimiz ation. W e empirically demonstrate that, ev en when using optimal solutions as labeled data to optimize a super vised mapping , th e generalization is rather poor compared to an RL agent that explores dif feren t tou rs and observes their correspon ding rewards. W e propose Neural Co mbinatorial Optimization, a framew ork to tack le combinato rial optimization problem s u sing reinforcem ent lear ning and neural networks. W e con sider tw o app roaches based on policy gradients (W illiam s , 199 2 ). The first appro ach, called R L pretr aining , uses a train ing set to optimize a r ecurrent neural network (RNN) tha t p arameterizes a stochastic po lic y over so lutions, using the expected re ward as objective. At test time, the policy is fixed, and one performs inference by g reedy decodin g or sampling. The secon d approach , called active searc h , inv o lv es no pretraining . ∗ Equal contribution s. Members of the Google Brain Residency program ( g.co/brainres idency ). 1 Under revie w as a conference paper at ICLR 2017 It starts from a ran dom policy and iter ati vely optimizes th e RNN parameters on a single test instan ce, again using the exp ected re ward ob jecti ve, wh ile keeping track of the best solu tion sampled dur ing the search. W e find that combinin g RL p retraining and acti ve search works best in practice. On 2D Eu clidean graphs with up to 10 0 nodes, Neur al Combinator ial Optimizatio n sign ificantly outperf orms the sup ervised le arning approach to the TSP (V inyals et al., 2015 b ) and o btains close to optim al results wh en a llo we d m ore computation time. W e illustrate its flexibility by testing the same method on the KnapSack pro blem, f or wh ich we get op timal r esults fo r instances with up to 200 items. These results give insights into how neural n etw orks can be u sed as a gene ral to ol for tackling combinato rial op timization problems, especially those that are difficult to design heuristics for . 2 P R E V I O U S W O R K The T raveling Salesm an Problem is a well studied combinator ial op timization problem an d many exact or approximate algorithms ha ve been proposed for both Euclidean and non-Euclid ean grap hs. Christofides (1976) p roposes a heu ristic algorithm tha t in volves computing a minimu m-spanning tree and a minimum -weight pe rfect matching. The algo rithm has po lynomial runn ing time and returns solutions that ar e guaran teed to be within a factor of 1 . 5 × to optimality in the metric instance of the TSP . The best known exact dyna mic program ming algo rithm for TSP has a complexity of Θ(2 n n 2 ) , mak- ing it infe asible to scale up to large instances, say with 40 po ints. Nevertheless, state of the art TSP solvers, th anks to carefu lly handcr afted heuristics that d escribe how to navigate th e spac e of feasi- ble solutions in an efficient m anner , can solve symmetric TSP instances with thousands of nodes. Concorde (Applegate et al., 2006), widely accepted as one of the best exact TSP solvers, makes use of cutting p lane algorithms (Dantzig et al., 19 54 ; Padberg & Rinaldi, 1990; Applegate et al., 200 3 ), iterativ ely solvin g linear pro gramming r elaxations of th e TSP , in co njunction with a branch -and- bound approach th at prun es parts of the search space that p rov ably will not contain an optimal solution. Similarly , the Lin-Kernighan -Helsgaun heuristic (Helsgaun, 200 0 ), inspired fr om the Lin- Kernighan h euristic (Lin & Kernighan, 1973), is a state of th e ar t ap proximate sear ch h euristic fo r the symmetric TSP and has been shown to solve instances with hundred s of no des to optimality . More generic solvers, such as Goo gle’ s vehicle rou ting problem so lv er (Google, 20 16 ) that tack les a superset of the TSP , ty pically rely on a combination o f local search algo rithms and metaheuris- tics. Local search algorith ms apply a specified set o f local move operators on candidate solutions, based on han d-engineered heuristics such as 2- opt (Johnson, 1 990), to navigate f rom solution to solution in the search spa ce. A me taheuristic is then applied to propose u phill moves and escape local optima. A p opular choice of metaheuristic f or the TSP an d its variants is guided local sear ch (V oud ouris & Tsang, 1999), which moves out of a local minimum by pe nalizing particular solution features that it considers should not occur in a good solution. The difficulty in apply ing existing search heuristics to n e wly e ncountered problems - or e ven new instances of a similar problem - is a well-known challenge that stems from the N o F r ee Lunch theo- r em (W olpert & Macread y , 1 997 ). Because all sear ch algorithms have the same perform ance when av eraged over all pro blems, one m ust approp riately rely on a p rior over problems wh en selecting a search algo rithm to gu arantee performan ce. Th is challenge has f ostered interest in raising the le vel of generality at which optimization systems operate (Burke et al., 2003) and is the underlying moti- vation behind hyper-heuristics, defined as ”search method[s] or learning mechanism[ s] for selecting or gener ating he uristics to solve computation search pro blems”. Hyper-heuristics aim to be easier to use than problem s pecific metho ds by partially abstracting a way the kno wledge intensi ve process of selecting heuristics gi ven a combinatorial prob lem and have been sho wn to s uccessfu lly combine human- defined heu ristics in sup erior ways across many tasks (see (Burke et al., 2013) for a survey). Howe ver , hyper-heuristics operate on th e search sp ace of heu ristics , rather than th e search space of solutions, therefore still initially relying on human created heuristics. The application of neural networks to combinatorial optimization has a distinguished history , where the major ity of research focuses on th e T raveling Salesman Problem (Smith, 1999). One of the ear- liest propo sals is the use of Hopfield networks ( Hopfield & T an k, 198 5 ) for the TSP . T he au thors modify the network’ s energy fu nction to make it equi valent to TSP objective and use Lagrang e mul- 2 Under revie w as a conference paper at ICLR 2017 tipliers to p enalize the violations of the problem ’ s co nstraints. A limitation of th is appro ach is that it is sen siti ve to h yperparameter s and p arameter initializatio n as analyzed by (Wilson & Pa wley , 1988). Overcoming this limitation is central to the su bsequent work in the field, especially by (Aiyer et al., 1990; Gee, 19 93 ). P arallel to the dev elopm ent o f Ho pfield networks is the work on using deforma ble template models to solve TSP . Perhaps most prominen t is the invention o f Elastic Nets as a means to solve TSP (Durbin, 1987), and the application of Self Organizing Map to TSP ( F ort, 1988; Ang eniol et al., 1988; Kohonen , 1990). A ddressing the limitations of deform able template mo dels is cen tral to the following work in this ar ea (Burke, 1994; Fa vata & W alker, 1991; V akhutinsky & Golden, 1995). Even though these neural networks have many appealing properties, they are still limited as research work. When bein g c arefully benchmarked, they have n ot yielded satisfying results compared to algorithmic methods (Sarwar & Bhatti, 2012; La Maire & Mladen o v, 2012). Perhaps due to th e negative results, this resear ch directio n is largely overloo k ed since the turn of the century . Motiv ated by the recent advancements in sequ ence-to-sequence learning (Sutskev er et al., 2014), neural networks are again the sub ject of study for optimization in various dom ains (Y utian et al., 2016), including discrete o nes (Zoph & Le, 2016). In pa rticular , the TSP is revisited in the intro- duction of Pointer Networks (V inyals et al., 2015b ), where a recurren t ne tw ork with non-p arametric softmaxes is tra ined in a superv is ed manner to predict the sequence of visited cities. Despite arch ite- cural improvements, their models were trained using superv ised signals given by an ap proximate solver . 3 N E U R A L N E T W O R K A R C H I T E C T U R E F O R T S P W e focus on the 2D E uclidean TSP in this paper . Given an input graph, represented a s a sequen ce of n cities in a two dimensional space s = { x i } n i =1 where each x i ∈ R 2 , we ar e concerned with finding a permu tation of the points π , termed a tour , that visits each city once and has the minimum total length. W e define the length of a tour defined by a permutation π as L ( π | s ) = x π ( n ) − x π (1) 2 + n − 1 X i =1 x π ( i ) − x π ( i +1) 2 , (1) where k·k 2 denotes ℓ 2 norm. W e aim to learn the parame ters o f a stochastic policy p ( π | s ) that giv en an input set of po ints s , assigns h igh pro babilities to short tours and low probabilities to long tours. Our ne ural network architecture uses the chain rule to factorize the probability of a tour as p ( π | s ) = n Y i =1 p ( π ( i ) | π ( < i ) , s ) , (2) and then uses individual softmax mod ules to represent each term on the RHS of (2). W e are inspired by p re vious work (Sutskever et al., 2014) tha t makes use of th e same factorization based on the cha in rule to addr ess sequen ce to seque nce pro blems like machine translation. One can use a vanilla sequen ce to sequence model to address the TSP where th e ou tput vocabulary is { 1 , 2 , . . . , n } . Howev er, there are two major issues with this approach : (1) networks trained in this fashion cannot generalize to inputs with more than n cities. ( 2) one needs to have access to ground - truth o utput permu tations to optim ize the pa rameters with conditional log -likelihood. W e address both isssues in this paper . For ge neralization beyond a pr e-specified grap h size, we f ollo w the ap proach of (V inyals et al., 2015b), which ma k es use of a set of non-p arameteric softmax m odules, resem bling the attention mechanism from (Bahda nau et al., 2015). This approach, named pointer network , allows the model to effecti vely point to a specific position in the inp ut s eque nce rather t han pr edicting an index value from a fixed-size vocabulary . W e employ the pointer network a rchitecture, depicted in Figure 1, as our policy model to parameterize p ( π | s ) . 3 . 1 A R C H I T E C T U R E D E TA I L S Our pointer network comprises tw o recurrent neural netw ork (RNN) modules, encoder and decoder , both of which consist of L ong Short- T erm Mem ory (LSTM) cells (H ochreiter & Schmidhub er , 3 Under revie w as a conference paper at ICLR 2017 h g i x 2 x 1 x 5 x 4 x 4 x 3 x 2 x 1 x 5 Figure 1: A p ointer network architecture introduced by (V inyals et al., 2015b). 1997). The encoder network re ads the inp ut sequence s , one city at a time, an d transforms it into a sequence of latent memo ry states { enc i } n i =1 where enc i ∈ R d . T he input to the encod er network at time step i is a d -dimension al emb edding of a 2D p oint x i , which is o btained via a linear tr ansforma- tion of x i shared across all input steps. The decoder network also maintains its latent memory states { dec i } n i =1 where dec i ∈ R d and, at each step i , uses a pointing mechanism to produce a distribution over the next city to visit in the tour . Once the next city is selected, it is passed as the input to the next decoder step. The input of the fir st d ecoder step (denoted by h g i in Figure 1 ) is a d-dimensional vector treated as a trainable parameter of our neural network. Our attention fun ction, formally defined in Ap pendix A.1, takes as input a quer y vector q = dec i ∈ R d and a set o f referen ce vectors r ef = { enc 1 , . . . , enc k } where enc i ∈ R d , and pr edicts a distri- bution A ( r e f , q ) over the set of k references. Th is prob ability distrib ution r epresents the degree to which the model is pointing to reference r i upon seeing query q . V inyals et al. (2015 a ) also suggest including some additiona l compu tation steps, named glimpses , to aggregate the contributions of different parts of th e inp ut seq uence, very much like (Bahdanau et al., 2015). W e discuss this appro ach in details in Ap pendix A.1. In ou r experiments, we fin d that utilizing o ne glimpse in the poin ting mechanism yield s perform ance g ains at an insignificant cost latency . 4 O P T I M I Z A T I O N W I T H P O L I C Y G R A D I E N T S V inyals et al. (2015b) proposes training a po inter network using a supervised loss function compris- ing co nditional log-likelihood, which factors in to a cross en tropy ob jecti ve b etween the network’ s output prob abilities and th e targets provided by a TSP solver . L earning fro m examples in such a way is u ndesirable for NP-hard problem s b ecause (1) the perfor mance of th e model is tied to the quality of the supervised labels, (2) getting high-qu ality labeled data is expensi ve and may be infea- sible for ne w problem statements, (3) on e cares more about finding a competiti ve solution more th an replicating the results of another algorithm. By contrast, we b elie ve Reinforcem ent Learning (RL) provides an appro priate p aradigm fo r train ing neural network s for com binatorial op timization, especially because these problems have relatively simple reward mecha nisms th at co uld be e ven used at test time. W e hence propose to use model-f ree policy-based Reinforce ment Learning to optim ize the par ameters of a pointer network den oted θ . Our training objective is the expected tour l eng th which, given an input graph s , is defined as J ( θ | s ) = E π ∼ p θ ( . | s ) L ( π | s ) . (3) During training, our graphs are drawn f rom a distribution S , and the total training o bjecti ve inv olves sampling from the distribution of graph s, i.e. J ( θ ) = E s ∼S J ( θ | s ) . W e resort to po lic y gradie nt method s and stoch astic g radient d escent to optimize the p arameters. The gradien t of (3) is formulated using the well-known REI NFOR CE algo rithm (W illiams, 1992): ∇ θ J ( θ | s ) = E π ∼ p θ ( . | s ) h L ( π | s ) − b ( s ) ∇ θ log p θ ( π | s ) i , (4) 4 Under revie w as a conference paper at ICLR 2017 Algorithm 1 Actor-critic t rainin g 1: procedure T R A I N (training set S , number of training steps T , ba tch si ze B ) 2: Initialize pointer network params θ 3: Initialize critic network params θ v 4: fo r t = 1 to T do 5: s i ∼ S A M P L E I N P U T ( S ) for i ∈ { 1 , . . . , B } 6: π i ∼ S A M P L E S O L U T I O N ( p θ ( . | s i )) for i ∈ { 1 , . . . , B } 7: b i ← b θ v ( s i ) for i ∈ { 1 , . . . , B } 8: g θ ← 1 B P B i =1 ( L ( π i | s i ) − b i ) ∇ θ log p θ ( π i | s i ) 9: L v ← 1 B P B i =1 k b i − L ( π i ) k 2 2 10: θ ← A DA M ( θ , g θ ) 11: θ v ← A DA M ( θ v , ∇ θ v L v ) 12: end for 13: return θ 14: end procedure where b ( s ) denotes a ba seli ne fu nction th at does not dep end o n π and estimates the expected tour length to reduce the variance of the gradients. By drawing B i.i.d. sample gr aphs s 1 , s 2 , . . . , s B ∼ S and sampling a single tour p er grap h, i.e. π i ∼ p θ ( . | s i ) , the gradient in (4) is appro ximated with Monte C arlo samplin g as follows: ∇ θ J ( θ ) ≈ 1 B B X i =1 L ( π i | s i ) − b ( s i ) ∇ θ log p θ ( π i | s i ) . (5) A simple and popular choice of the baseline b ( s ) is an exponential moving average o f the rewards obtained by the network over time to acco unt f or th e fact that the po lic y impr o ves with training. While this cho ice o f ba s eline proved su f ficien t to improve upon the Chr istofides alg orithm, it suffers from no t being able to differentiate b etween different input graphs. In p articular , the optimal tour π ∗ for a difficult gr aph s may be still discourag ed if L ( π ∗ | s ) > b because b is shared acro ss all instances in the batch. Using a parametric b aseline to estimate the expec ted to ur length E π ∼ p θ ( . | s ) L ( π | s ) typically im - proves learn ing. Therefore, w e in troduce an auxiliary network, called a c ri tic and param eterized by θ v , to le arn the expected tour length found by ou r cur rent po lic y p θ giv en an in put sequ ence s . The cr itic is trained with stochastic gr adient descent o n a me an squared e rror objective between its prediction s b θ v ( s ) and the actu al tour lengths sampled b y the most recent policy . The add itional objective is formulated as L ( θ v ) = 1 B B X i =1 b θ v ( s i ) − L ( π i | s i ) 2 2 . (6) Critic’ s architecture for TSP . W e now explain how our critic maps an input sequence s in to a baseline pred iction b θ v ( s ) . Our critic comprises three neur al network mod ules: 1) an L STM encoder, 2) an LSTM process block and 3) a 2-layer ReLU neural netw ork decod er . Its encoder has the same architecture as that of o ur p ointer network ’ s enco der and encodes an inpu t sequen ce s into a sequence of latent mem ory states and a hidden state h . T he p rocess b lock, similar ly to (V inyals et al., 2015a), then perfo rms P steps o f com putation over the hidden state h . Eac h pr ocessing step upd ates this hidden state by glimpsing at th e memo ry states as describ ed in Appendix A .1 and feeds th e outp ut of the g limpse functio n as input to the next pro cessing step. At the end of the pr ocess block, the obtained h idden state is then decode d into a baseline pr ediction (i.e a single scalar ) by two fully connected layers with respectively d and 1 unit(s). Our tra ining algo rithm, de s cribe d in Algorithm 1, is closely relate d to the asynch ronous advan- tage ac tor -critic ( A3C) prop osed in (Mnih et al., 2016), a s the difference between th e sampled to ur lengths and the critic’ s predictions is an unb iased estimate o f th e ad v antage function. W e perform our updates asynch ronously across mu ltiple workers, but each worker also handles a min i-batch of graphs for better gradient estimates. 5 Under revie w as a conference paper at ICLR 2017 Algorithm 2 Activ e Search 1: procedure A C T I V E S E A R C H (input s, θ , number of candidates K, B, α ) 2: π ← R A N D O M S O L U T I O N ( ) 3: L π ← L ( π | s ) 4: n ← ⌈ K B ⌉ 5: fo r t = 1 . . . n do 6: π i ∼ S A M P L E S O L U T I O N ( p θ ( . | s ) ) for i ∈ { 1 , . . . , B } 7: j ← A R G M I N ( L ( π 1 | s ) . . . L ( π B | s )) 8: L j ← L ( π j | s ) 9: if L j < L π then 10: π ← π j 11: L π ← L j 12: end if 13: g θ ← 1 B P B i =1 ( L ( π i | s ) − b ) ∇ θ log p θ ( π i | s ) 14: θ ← A DA M ( θ , g θ ) 15: b ← α × b + (1 − α ) × ( 1 B P B i =1 b i ) 16: end for 17: return π 18: end procedure 4 . 1 S E A R C H S T R A T E G I E S As ev aluating a tour length is inexpensive, our T SP agent can easily simulate a search proc edure at inference time b y consider ing multiple cand idate solutions per g raph and selecting the best. Th is inference pr ocess resembles how solvers search over a large set of feasible solutions. In th is paper , we consider two search strategies detailed belo w , which we refer to as sampling and active sear ch . Sampling. Our first appro ach is simply to samp le m ultiple candidate to urs from our stoch astic p ol- icy p θ ( . | s ) and select the shortest one. In co ntrast to heuristic solvers, we do not enf orce our mod el to sample d if ferent tou rs during the process. Ho wever , we c an con trol the d i versity of th e sampled tours with a temperatur e hy perparameter when sampling from our non-parametric softmax (see Ap- pendix A.2). This sampling process yields significant improvements over greed y decodin g, which always selects the ind e x with th e largest pr obability . W e also considere d pertur bing the po inting mechanism with random n oise and greed ily decodin g from the obtained m odified po lic y , similarly to (Cho, 2016), but this proves less effective th an sampling in our experiments. Active Search. Rather than sampling with a fixed mod el and ignor ing the rew ard in formation obtained f rom the sampled solutions, one can r efine the parameters of th e stochastic policy p θ during inference to min imize E π ∼ p θ ( . | s ) L ( π | s ) on a sing le test input s . This a pproach proves especially competitive when starting from a trained model. Remar kably , it also pr oduces satisfying solution s when starting from an u ntrained model. W e ref er to these two a pproaches as RL pr etraining- Active Sear ch and Active Sea r ch b ecause the mo del acti vely updates its parameter s wh ile searchin g for candidate solutions on a single test instance. Activ e Search ap plies policy g radients similarly to Algorithm 1 but draws Mon te Carlo samples over candidate solutions π 1 . . . π B ∼ p θ ( ·| s ) for a single test input. It resor ts to an exponential moving av erage baseline, rather than a critic, as th ere is no need to differentiate between inputs. Our Acti ve Search tra ining algorithm is pr esented in Alg orithm 2. W e n ote that wh ile RL training do es not require superv isi on, it still requir es train ing da ta and hence generalizatio n dep ends on th e training data d istrib ution. In co ntrast, Activ e Search is distribution ind ependent. Finally , since we enc ode a set of cities as a sequence, we ran domly shuffle the input sequence b efore feed ing it to o ur pointe r network. This increases the stochasticity o f the sampling pro cedure and leads to large improvements in Acti ve Search. 6 Under revie w as a conference paper at ICLR 2017 T able 1: Different learning configurations . Configuration Learn on Sampling Refining training data on test set on test set RL pretraining-Greedy Y es No No Activ e Search (AS) No Y es Y es RL pretraining-Sampling Y es Y es No RL pretraining-Acti ve Search Y es Y es Y es 5 E X P E R I M E N T S W e cond uct experiments to in vestigate the behavior o f the propo sed Neu ral Combinato rial Opti- mization methods. W e consider th ree b enchmark tasks, Euclidean TSP20, 50 and 100, for which we generate a test set of 1 , 000 gra phs. Points are drawn uniformly at rando m in th e unit s quar e [0 , 1] 2 . 5 . 1 E X P E R I M E N TA L D E TA I L S Across all experiments, w e use m ini-batches of 12 8 sequences, L STM cells w ith 128 hidden un its , and embed the two coordinates of each point in a 128 -dimensional space. W e tr ain our models with the Adam optimizer (Kin gma & Ba, 2 014 ) an d use an initial learnin g rate of 10 − 3 for TSP20 and TSP50 and 10 − 4 for TSP100 that we decay every 500 0 steps by a factor of 0 . 96 . W e in itialize our parameter s u niformly at rando m within [ − 0 . 08 , 0 . 0 8] an d clip the L 2 norm of our gradien ts to 1 . 0 . W e use up to on e attention glimpse. When search ing, the min i-batches either co nsist of replications of t he test sequence or its permutatio ns. The baseline decay i s set to α = 0 . 9 9 in Active Search. Our model and training code in T ensorflow (Abadi et al., 2016) will be made a vailabe soon. T able 1 summ arizes the con figurations and different search stra te gies u sed in th e experiments. The variations of our method, experimenta l pro cedure and results are as follows. Supervised Learning. In ad dition to the de scribed b aselines, we implement and train a poin ter network with superv ised learning , similarly to (V inyals et al., 2015b). While our superv ised data consists of one million optimal tours, we find that our supervised learning results are not as good as those reported in by (V inyals et al., 20 15b ). W e suspect that learning from o ptimal tours is harder for supervised po inter networks due to subtle f eatures that the model canno t figure out o nly by looking at g i ven supe rvised targets. W e th us refer to the results in (V inyals et al., 201 5b ) for T SP20 and TSP50 and report our results on TSP100, all of which are suboptim al co mpared to other approach es. RL pretraining. For th e RL exp eriments, we generate training mini-batches of inputs on the fly and update the model p arameters with the Actor Critic Algorithm 1 . W e use a validation set of 10 , 000 randomly generated instances for hyper-parameters tuning. Our critic consists of an encoder network which has the same architecture as that of the policy n etw ork, but followed by 3 proce ss - ing steps and 2 fu lly con nected layers. W e find that clipping the logits to [ − 10 , 10] with a tanh( · ) activ a tion functio n, as describe d in Appendix A.2, helps with explo ration and yields marginal per- forman ce gains. The simplest search stra te gy using an RL pretrained mod el is greedy decoding, i.e. selecting the cit y with the largest p robability at each decod ing step. W e also e xpe riment with de- coding greedily from a set of 16 pretrained models at inference time. For each graph, the tour found by e ach individual model is collected and the shortest tour is chosen. W e refer to those ap proaches as RL pr etraining-g r eedy and RL pr etraining-greedy@16 . RL pretraining-Sa mpli ng. For each test in stance, we sam ple 1 , 2 80 , 000 cand idate solu tions from a pre trained mo del and keep track of the sho rtest tour . A grid search over the temp erature hyperp arameter foun d respective tem peratures of 2 . 0 , 2 . 2 and 1 . 5 to yield th e best results for TSP20, TSP50 and TSP100. W e ref er to the tuned temper ature hyperpar ameter as T ∗ . Sin ce sampling do es not require par ameter udpates a nd is e ntirely parallelizable, we use a larger batch size for speed purpo ses. RL pretraining-Active Search. For eac h test instance, we initialize the m odel p arameters fro m a p retrained RL mode l an d r un Activ e Sear ch f or up to 10 , 0 00 train ing steps with a batch size of 128 , sampling a to tal of 1 , 280 , 000 candida te solutions. W e set the learning rate to a hundred th of 7 Under revie w as a conference paper at ICLR 2017 T able 2: A verage tour lengths (lower is be tter). Results marked ( † ) are from (V inyals et al., 2015b). T ask Supervised Learning RL pretraining AS Christo OR T ools’ Optimal greedy greedy@16 sampling AS -fides local search TSP20 3 . 88 ( † ) 3.89 − 3.82 3.82 3.96 4.30 3.85 3.82 TSP50 6 . 09 ( † ) 5.95 5.80 5.70 5.70 5.87 6.62 5.80 5.68 TSP100 10.81 8.30 7.97 7.88 7.83 8.19 9.18 7.99 7.77 T able 3: Running t imes in seconds (s) of greedy methods compared to OR T ool’ s local search and solvers that find the optimal solutions. T i me is measured over the entire test set and av eraged. T ask RL pretraining OR-T ools’ Optimal greedy greedy@16 local search Concorde LK-H TSP50 0 . 003 s 0 . 04 s 0 . 02 s 0 . 0 5 s 0 . 14 s TSP100 0 . 01 s 0 . 15 s 0 . 10 s 0 . 2 2 s 0 . 88 s the initial learning rate the TSP ag ent was trained on (i.e. 10 − 5 for TSP2 0/TSP50 and 10 − 6 for TSP100). Active Search. W e allow the model to train much longer to accoun t for the fact that it starts from scratch. For each test graph, we run Activ e Search for 100 , 000 tr aining s teps on TSP20/TSP50 and 200 , 000 tra ining steps on TSP100. 5 . 2 R E S U LT S A N D A N A L Y S E S W e comp are ou r methods again st 3 different baselin es of incr easing perfor mance and complex- ity: 1) Christofide s, 2 ) the vehicle r outing solver from OR-T ools (Goo gle , 2016) and 3) o ptimal- ity . Christofide s solutio ns are obtain ed in po lynomial time and guaranteed to be within a 1 . 5 r atio of op timality . OR-T ools impr o ves over Christofides’ solutions with simple local sear ch o perators, including 2-opt (Johnson, 1990) an d a version of the L in-K ernigh an he uristic (Lin & Kernighan , 1973), stoppin g when it rea ches a loc al minim um. I n o rder to escap e po or local optima, OR- T oo ls’ local search can also b e ru n in co njunction with different metah euristics, su ch as simu- lated an nealing (Kirkpatrick et al., 19 83 ), tabu search (Glover & Laguna, 20 13 ) or guid ed lo cal search (V ou douris & Tsang, 1999). OR-T ools’ vehicle routing solver c an tack le a superset of th e TSP an d op erates at a higher level o f generality tha n solvers th at a re highly specific to th e TSP . While not state-of-the ar t for the T SP , it is a commo n choice f or genera l routing p roblems and provides a reasonable baseline between the simplicity of th e most basic local search operators and the sophisti- cation of the strongest solvers. Optimal solutions are obtained via Concorde (Applegate et al. , 2006) and LK-H’ s lo cal search (Helsgaun, 2 012; 2000). While only Con corde provably solves instanc es to optimality , we empirically find that LK-H also achieves o ptimal solutions on all of our tes t sets. W e rep ort the av erage tour lengths of o ur approa ches on TSP20, TSP50, an d TSP100 in T able 2. Notably , results demo nstrate that training with RL significantly improves over supervised learning (V inyals et al., 2015b). All our methods comfortab ly surpass Christofides’ heuristic, includ ing RL pretrainin g-Greedy which also does not rely o n search. T able 3 co mpares the runn ing times o f our greedy methods to the aforementioned baselines, with our methods running on a single Nvidia T esla K80 GPU, Concorde and LK-H running on an Intel Xeon CP U E5-16 50 v3 3.50 GHz CPU and OR- T oo l on an Intel Haswell C PU. W e find that b oth greedy appro aches are time-efficient and just a few percents worse than optimality . Searching at inf erence time pr o ves cruc ial to get closer to o ptimality b ut comes at the expense of longer runn ing times. F ortunate ly , the search fro m RL pretrainin g-Sampling and RL pretrainin g- Activ e Search can be stopped early with a small perform ance tradeoff in terms of th e final objective. This can be seen in T able 4, where we sho w their performanc es and correspond ing runn ing times as a functio n o f how many solutions they consider . W e also find th at many of our RL pretraining methods outperfo rm OR-T ools’ local s earch , includin g RL pretrainin g-Greedy@16 which runs similarly fast. T able 6 in App endix A.3 presents the perfor- mance of the metaheuristics as they co nsider m ore solu tions and the corr esponding runn ing times. 8 Under revie w as a conference paper at ICLR 2017 T able 4: A verage tour lengths of RL pretraining-Sampling and RL pretraining-Acti ve Search as they sample more solutions. Correspon ding running times on a single T esla K80 GPU are in parantheses . T ask # Solutions RL pretraining Sampling T = 1 Sampling T = T ∗ Activ e Search TSP50 128 5.80 (3.4s) 5.80 (3.4s ) 5.80 (0.5s) 1,280 5.77 (3.4s) 5.75 (3.4s ) 5.76 (5s) 12,800 5.75 (13.8s) 5.73 (13.8s) 5.74 (50s) 128,000 5.73 (110s) 5.71 (110s) 5.72 (500s) 1,280,000 5.72 (1080s) 5.70 (1080s) 5.70 (5000 s) TSP100 128 8.05 (10.3s) 8.09 (10.3s) 8.04 ( 1.2 s) 1,280 8.00 (10.3s) 8.00 (10.3s) 7.98 (12s) 12,800 7.95 (31s) 7.95 (31s) 7.92 (120s) 128,000 7.92 (265s) 7.91 (265s) 7.87 (1200s) 1,280,000 7.89 (2640s) 7.88 (2640s) 7.83 (12000 s) 0 25 50 75 100 P e rc e nt i l e 1.00 1.00 1.05 1.10 T ou r l e ngt h ra t i o t o opt i m a l P l a na r T S P 5 0 RL pre t ra i ni ng-G re e dy RL pre t ra i ni ng-G re e dy@ 16 RL pre t ra i ni ng-S a m pl i ng RL pre t ra i ni ng-A c t i ve S e a rc h A c t i ve S e a rc h O pt i m a l 0 25 50 75 100 P e rc e nt i l e 1.00 1.00 1.05 1.10 1.13 T our l e ngt h ra t i o t o opt i m a l P l a na r T S P 1 00 RL pre t ra i ni ng-G re e dy RL pre t ra i ni ng-G re e dy@ 16 RL pre t ra i ni ng-S a m pl i ng RL pre t ra i ni ng-A c t i ve Se a rc h A c t i ve S e a rc h O pt i m a l Figure 2: Sor ted tour length ratios to optimality In our experiments, Neural Combinato rial proves superior than Simu lated Annealing but is slightly less competitive that T abu Search and much less so than Guided Local Search. W e p resent a more detailed comparison of our methods in Figure 2, where w e sort the ratios to optimality of our different learn ing configu rations. RL pretraining-Sam pling an d RL pr etraining- Activ e Search are the most co mpetiti ve Neu ral Com binatorial Op timization methods and recover the optimal solution in a significant number of our test cases. W e find that for small solution spaces, RL pretraining -Sampling, with a finetuned softmax tem perature, ou tperforms RL pretrain ing-Acti ve Search with the la tter sometimes orientin g the search towards suboptim al regions of the solution space (see T SP50 results in T able 4 and Figu re 2). Furthermo re, RL p retraining-Sampling benefits from being fully parallelizable and run s faster th an RL pretrain ing-Acti ve Search. Ho wever , for larger solution spaces, RL-pretrainin g Acti ve Search pr o ves superio r both when con trolling for the number of sampled solutions or the run ning time. Interestingly , Active Search - wh ich starts from an untraine d model - also pr oduces co mpetiti ve tou rs but requires a consider able amount of time (respectively 7 and 25 hours per instance o f TSP50 /TSP100). Finally , we show ran domly picked example tours found by our methods in Figure 3 in Appendix A.4.make 6 G E N E R A L I Z A T I O N TO O T H E R P R O B L E M S In this section , we discuss how to apply Neura l Combinator ial Optimization to other prob lems than the TSP . In Neural Combinato rial Optimization, th e m odel architecture is tied to the given co mbi- natorial o ptimization problem. Examp les of useful networks include the pointer network, wh en the output is a permutatio n or a truncated permutatio n or a subset of the input, and the classical s eq2 s eq model for other k inds of structured outputs. For combinatorial problems that require to assign labels to elements of the input, such as graph coloring, it is also possible to combine a pointer module and a softmax module to simultaneously point and ass ign at decod ing time. Given a model that encodes an instance of a given co mbinatorial optimization task and repeatedly branches into subtrees to con- 9 Under revie w as a conference paper at ICLR 2017 struct a solutio n, the training procedures described in Section 4 can then be applied by adap ting the rew ard function depen ding o n t he optim ization problem being consider ed. Additionally , o ne also needs to ensure the feasibility of the obtained solutions. For ce rtain combi- natorial problems, it is straightfo rw ard to know exactly wh ich br anches do not lead to any feasib le solutions at d ecoding time. W e can then simply manually assign th em a zero probability wh en de- coding, similar ly to how we enf orce o ur model to no t po int at the same city twice in our pointin g mechanism (see Appendix A.1 ). Ho wever , for many co mbinatorial problems, coming up with a fea- sible solutio n can be a challenge in itself. Con sider , f or example, the Tra velling Salesman Pr oblem with Time W indows, where the trav elling salesman has the ad ditional constraint of visiting eac h city during a specific time window . It might be that most branch es being consider ed early in the tour do n ot lead to any solution th at respects all time win do ws. In such cases, k no wing exactly which branch es are feasible requires searching their subtrees, a time-consuming process that is not much easier than directly searching for the optimal solution unless using problem -specific heuristics. Rather than exp licitly constrainin g the mode l to only sample feasible solutions, one ca n also let the model learn to respect the p roblem’ s c onstraints. A simple approach , to be verified experim entally in future w ork, consists in augmenting th e ob jecti ve functio n with a term th at pe nalizes solu tions for violating the pr oblem’ s constraints, s imilarly to penalty methods in constrain ed optimization. While this does not guarantee that the model consistently samples feasible solutions at inference time, this is not necessarily p roblematic as we can simply ignor e infeasible solu tions an d resample from the model (for RL pretraining -Sampling an d RL-pretr aining Active Search). It is also co ncei vable to combine both approach es by assigning zero prob abilities to branches that are easily identifiable as infeasible while still penalizing infeasible solutions once they are entirely constructed. 6 . 1 K N A P S AC K E X A M P L E As a n example o f the flexibility of Neural Combinatorial Op timization, we consider th e KnapSack problem , an other inten si vely studied problem in computer science. Gi ven a set of n items i = 1 ...n , each with weigh t w i and value v i and a max imum weight capacity of W , the 0-1 KnapSack pro blem consists in maximizing the sum of the v alues of it ems present in the knapsack so that the sum of the weights is less than or equal to the knapsack capacity: max S ⊆{ 1 , 2 ,...,n } X i ∈ S v i subject to X i ∈ S w i ≤ W (7) W ith w i , v i and W taking real values, the proble m is NP-h ard (Kellerer et al., 200 4 ). A simple yet strong h euristic is to take the items o rdered by their weight-to-value ratios until th e y fill u p the weight capacity . W e a pply the pointer network and encode each knapsack instance as a s equ ence of 2D vectors ( w i , v i ) . At decoding time, the p ointer network p oints to items to include in the knapsack and stops when the total weight of the items collected so far exceeds the weight capacity . W e generate three datasets, KNAP50, KNAP100 an d KN AP200, of a thousand instances with item s’ weights and v alues d rawn u niformly at rando m in [0 , 1 ] . W ithou t loss of gen erality ( si nce we can scale th e items’ weights), we set the capacities to 12 . 5 for KNAP50 and 2 5 for KNAP100 and KN AP200. W e pr esent the p erformances o f RL pretraining- Greedy and A cti ve Sear ch (which we run for 5 , 000 training steps) in T able 5 and compare them to two simple baselines: th e first baseline is the greedy we ight-to-value r atio heur is tic; the second baseline is rando m search , where we sample as many fea si ble solutions as s een by Acti ve Search. RL pretraining-Gre edy yields solutions that, in av erage, are just 1% less than optimal and Activ e Search solves all instances to optimality . T able 5: Results of RL pretraining-Greedy and Active Search on K n apSack (higher is better). T ask RL pretraining Activ e Search Ran dom Search Greedy Optimal greedy KN AP50 19.86 20.07 17.91 19.24 20.07 KN AP100 40.27 40.50 33.23 38.53 40.50 KN AP200 57.10 57.45 35.95 55.42 57.45 10 Under revie w as a conference paper at ICLR 2017 7 C O N C L U S I O N This paper presents Neu ral Combin atorial Optimization, a framework to tackle combinatorial o p- timization with r einforcement learnin g and ne ural n etw orks. W e focus on th e traveling salesman problem (TSP) and presen t a set of results for each variation of the framew ork. Experimen ts de mon- strate th at N eural Combinator ial Optimizatio n ach ie ves close to op timal results on 2D Euclid ean graphs with up to 100 nodes. A C K N O W L E D G M E N T S The autho rs would like to thank V in cent Fur non, Oriol V inyals, Barr et Z oph, Lukasz Kaiser, Mustafa Ispir and the Google Brain team for insightful commen ts an d discussion. R E F E R E N C E S Mart´ ın Abadi, Paul Barha m, Jianmin Chen , Zhifen g Chen, Andy Da vis, Jeffrey Dean , Matthieu Devin, Sanjay Ghemawat, Geof frey Irving, Michae l Isard, et al. T en sorflo w: A system for large- scale machine learning . arXiv p r eprint arXiv:16 05.08695 , 20 16. Sreeram V . B. Aiyer, Mahesan Nira njan, and Fra nk Fallside. A theoretical inv estigation into the perfor mance of the Hop field model. IEEE T ransactions on Neural Networks , 1(2):204–2 15, 1990. Bernard Angenio l, Gael De La Croix V aubois, an d Jean-Yves Le T exier . Self- organizing feature maps and the Travelling Salesman Problem. Neural Netw orks , 1( 4):289–29 3, 19 88. David Applegate, Rob ert Bixby , V a ˇ sek Chv ´ atal, an d Wil liam Cook. Imp lementing the dantzig- fulkerson-jo hnson algor ithm f or large traveling salesman problems. Mathematica l pr ogramming , 2003. David L Applegate, Rober t E Bixby , V asek Chvatal, and W illiam J Cook. Concor de tsp so lv er, 2006. URL www.math.uw aterloo.ca/tsp/conco rde . David L Applegate, Ro bert E Bixby , V a sek Chvatal, an d W illiam J Cook . The traveling salesman pr o blem: a computation al study . Princeton university press, 2011 . Dzmitry Bahdan au, Kyunghyun Cho, and Y oshu a Bengio. Neur al mach ine translation b y join tly learning to align and translate. In ICLR , 2015. Edmun d Burke, Graham Kendall, Jim N e wall, E mma Hart, Peter Ross, and Son ia Schulen b urg. Hyperheuristics: An emerging dir ection in modern sear ch technology . Springer, 2003. Edmun d K. Burke, Michel Gendreau, Matthew R. Hyde, Graham K end all, Gab riela Ocho a, E nder zcan, and Rong Qu. Hyper-heuristics: a su rve y of th e state of th e art. JORS , 6 4(12):1695 –1724, 2013. Laura I. Burke. Neural meth ods fo r the Traveling Salesman Prob lem: insights from operation s research. Neural N etworks , 7 (4):681–69 0, 1 994. Kyunghyun Cho. Noisy parallel approxima te decod ing for cond itional recurrent language mod el. arXiv pr eprint arXiv:160 5.03835 , 2 016. Nicos Christofides. W orst-case an alysis of a new heuristic for the Trav elling Salesman Problem. In Report 388 . Graduate School of Industrial Administration , CMU, 1 976. George Dantzig, Ray Fulkerson, and Selmer Jo hnson. Solution of a large-scale traveling-salesman problem . Journal of the operations r esearc h society of America , 1954. Richard Durbin . An a nalogue appro ach to th e Tra velling Salesman. Nature , 326:1 6, 1 987. Fa vio Fa vata and Richard W alker . A stu dy of the application of Kohonen-type n eural n etw ork s to the trav elling salesman problem . Biological Cybernetics , 64(6):463– 468, 1991. 11 Under revie w as a conference paper at ICLR 2017 J. C. Fort. Solving a c ombinatorial pr oblem via self-o r ganizin g process: an application o f the Ko- honen algorithm to the traveling salesman problem. B iological Cybernetics , 59(1):3 3–40, 1 988. Andrew Howard Gee. Pr o blem s olving with optimizatio n networks . Ph D thesis, Citeseer , 19 93. Fred Glover and Manuel Lagun a. T abu Sea r ch . Springer, 2013. Google. Or-tools, google optimization too ls, 201 6. URL https://deve lopers.google.com/op tim ization/routing . Keld Helsgaun. An ef fective im plementation of the Lin-Kernighan tr a veling salesman. Eur opea n Journal of Operational Resear ch , 126:106–1 30, 2000 . Keld Helsgaun. LK-H, 2012 . URL http ://akira.ruc.dk/ ˜ keld/researc h/LKH/ . Sepp Hochreiter and Jurgen Schmidhuber . Long short-term memory . Neu r al Computation s , 1997. John J. Hopfield and David W . T ank. ”Neural” co mputation of decisions in o ptimization problems. Biological Cybernetics , 52(3):14 1–152, 198 5. DS Johnson. Local search and the traveling salesman prob lem. In Pr oceeding s o f 17th In ter - nationa l Colloquium on Automata Languages an d Pr ogramming, Lectur e Notes in Computer Science,(Sprin g er-V erlag, Berlin, 1990) , pp. 443–460, 1990. Hans Kellerer , Ulrich Pferschy , and David Pisinger . Knapsack Pr o blems . Spring er -V erlag Berlin Heidelberg, 2004. Diederik Kingma and Jimmy Ba. Adam: A metho d for stochastic optimization . In ICLR , 2 014. S. Kir kpatrick, C. D. Gelatt, and M. P . V ecchi. Optimization by simulated annealing. SCIENCE , 220, 1983. T euvo K ohon en. The self-organizing map. Pr oceed ings of the IEEE , 78(9) :1464–1480 , 1990 . Bert F . J. La Maire and V aler i M. Mladenov . Compar ison o f neural networks for solving the T ravel- ling Salesman Problem. In NEUREL , pp. 21–2 4. I EEE, 2012 . S. Lin and B. W . Kernigha n. An effecti ve heuristic algor ithm fo r th e tr a veling -salesman p roblem. Operations Resear ch , 21(2):4 98–516, 19 73. V olody myr Mnih, Adri Puigdomnech Badia, Mehdi Mirza, Alex Grav es, T imo thy P . Lillicrap, Tim Harley , Da vid Silver , a nd Koray Kavukcuoglu. Asynchro nous me thods for d eep reinfor cement learning. arXiv pr eprint arXiv:160 5.03835 , 2 016. Manfred Padberg and G io vanni Rinaldi. A b ranch-and-cu t algorithm for the resolutio n of large- scale sym metric tra veling salesman problems. Society for Ind ustrial a nd Applied Mathematics , 33:60– 100, 1990. Christos H. Papadimitriou . The Euclidean T ravelling Salesman Problem is NP-complete. Theor eti- cal Computer Science , 4(3):23 7–244, 1977. Farah Sarwar and Abdu l Aziz Bhatti. Critical analy si s of Hop field’ s n eural network model for TSP and its compar is on with heuristic algorithm for shortest path computation . In IBCAS T , 2012. Kate A. Smith. Neural networks for combin atorial optimization: a re view of more than a dec ade of research. INFORMS J ourn al on Computing , 1999. Ilya Sutsk ever , Oriol V inyals, and Quoc V . Le. Sequence to sequenc e lear ning with neural networks. In Advanc es in Neural Information Pr ocessing Systems , pp. 3104 –3112, 2 014. Andrew I. V akhu tinsky and Bruce L. Golden. A hierarchical strategy for solving tra veling salesman problem s u sing elastic nets. Journal of Heuristics , 1( 1):67–76, 1995. Oriol V inyals, Samy Bengio, and Manjunath K udlur . Ord er matters: Sequen ce to sequence for sets. arXiv pr eprint arXiv:151 1.06391 , 2 015a. 12 Under revie w as a conference paper at ICLR 2017 Oriol V inyals, Meire Fortunato, and Navdeep Jaitly . Pointer networks. In Advances in Neural Information Pr ocessing Systems , p p. 2692– 2700, 2 015b. Christos V ou douris an d Ed w ard Tsang . Guided loc al sear ch an d its application to th e tra veling salesman problem . Eur opea n journal of operational r esearc h , 1999. Ronald W illiams. Simple statistical grad ient following algorithms for connection nist reinf orcement learning. In Machine Learning , 1992. G. V . W ilson and G. S. Pa wley . On the stability o f the travelling salesman pr oblem algorith m of hopfield and tank. Biological Cybernetics , 58(1):63– 70, 1988 . D. H. W o lpert and W . G. Macr eady . No free lu nch theorems for op timization. T ransaction s o n Evolution ary Comp utation , 1(1):6 7–82, April 1997. Chen Y u tian, Hoffman M atthe w W ., Colmenarejo Sergio Gomez, Denil Misha, Lillicrap T imothy P ., and d e Freitas Na ndo. L earning to learn for global o ptimization of black box functions. arXiv pr eprint arXiv:16 11.03824 , 2 016. Barret Zoph and Qu oc Le. Neural architecture search with reinf orcement learnin g. arXiv pr eprint arXiv:161 1.01578 , 2 016. 13 Under revie w as a conference paper at ICLR 2017 A A P P E N D I X A . 1 P O I N T I N G A N D A T T E N D I N G Pointing mechanism: Its compu tations are parameterized by two attention matr ices W r e f , W q ∈ R d × d and an attention vector v ∈ R d as follows: u i = v ⊤ · tanh ( W r e f · r i + W q · q ) if i 6 = π ( j ) for all j < i −∞ otherwise for i = 1 , 2 , ..., k (8) A ( ref , q ; W r e f , W q , v ) def = sof tmax ( u ) . (9) Our pointer network, at decod er step j , then assigns the probab ility of visiting the next point π ( j ) of the tour as follows: p ( π ( j ) | π ( < j ) , s ) def = A ( enc 1: n , dec j ) . (10) Setting the logits of cities that already appeared in the tour to −∞ , as shown in Equation 8, ensures that our model only points at cities that have yet to be visited and hence outputs valid TSP tours. Attending mechanism: Specifically , our glimpse function G ( ref , q ) takes the same inputs as the attention f unction A and is pa rameterized by W g r e f , W g q ∈ R d × d and v g ∈ R d . It p erforms the following computations: p = A ( ref , q ; W g r e f , W g q , v g ) (11) G ( ref , q ; W g r e f , W g q , v g ) def = k X i =1 r i p i . (12) The glimpse function G essentially computes a linear combination of th e referen ce vectors weig hted by the attention probab iliti es. It can also be applied multiple times on the same refer ence set ref : g 0 def = q (13) g l def = G ( r ef , g l − 1 ; W g r e f , W g q , v g ) (14) Finally , the ultimate g l vector is passed to the attention functio n A ( re f , g l ; W r e f , W q , v ) to produce the probabilities o f the poin ting m echanism. W e observed empirically that glimpsing more th an once with the same parameters made the model less likely to learn and barely improved th e results. A . 2 I M P RO V I N G E X P L O R AT I O N Softmax temperature: W e modify Equation 9 as follo ws: A ( ref , q , T ; W r e f , W q , v ) def = sof tmax ( u/T ) , (15) where T is a temperatur e hy perparameter set to T = 1 durin g training. When T > 1 , th e distribution represented by A ( ref , q ) becomes less steep, hence pre venting the model from being overconfid ent. Logit clipping: W e mo dify Equation 9 as follows: A ( ref , q ; W r e f , W q , v ) def = sof tmax ( C tanh( u )) , (16) where C is a hyperparameter that controls the range of th e logits and hence t he entropy o f A ( re f , q ) . 14 Under revie w as a conference paper at ICLR 2017 A . 3 O R T O O L ’ S M E TA H E U R I S T I C S B A S E L I N E S F O R T S P T able 6: P erforma nce of OR-T ools’ metaheuristics as the y consider more solutions. Corresponding running times in seconds (s) on a single Intel Haswell CPU are in parantheses . T ask #Solutions S imulated Ann ealing T abu Search Guided Local Search TSP50 1 6.62 (0.03s) 6.62 (0.03s) 6.62 (0.03s) 128 5.81 (0.24s) 5.79 (3.4s) 5.76 (0.5s) 1,280 5.81 (4.2s) 5.73 (36s) 5.69 (5s) 12,800 5.81 (44s) 5.69 (330s) 5.68 (48s) 128,000 5 .81 (460s) 5.68 (3200s) 5.68 (450s) 1,280,000 5.81 (3960s) 5.68 (29650s) 5.68 (4530s) TSP100 1 9.18 (0.07s) 9.18 (0.07s) 9.18 (0.07s) 128 8.00 (0.67s) 7.99 (15.3s) 7.94 (1.44s) 1,280 7.99 (15.7s) 7.93 (255s) 7.84 (18.4s) 12,800 7.99 (166s) 7.84 (2460s) 7.77 (182s) 128,000 7.99 ( 16 50s) 7.79 (22740s) 7.77 (1740s) 1,280,000 7.99 (15810 s) 7.78 (2 08230s) 7.77 (16150 s) A . 4 S A M P L E T O U R S (5.934) RL pre t ra i ni ng -G re e dy (5.734) RL pre t ra i ni ng -S a m pl i ng (5.688) RL pre t ra i ni ng -A c t i v e S e a rc h (5.827) A c t i v e S e a rc h (5.688) O pt i m a l (7.558) RL pre t ra i ni ng -G re e dy (7.467) RL pre t ra i ni ng -S a m pl i ng (7.384) RL pre t ra i ni ng -A c t i v e S e a rc h (7.507) A c t i v e S e a rc h (7.260) O pt i m a l Figure 3: Samp le tours. T op: TSP5 0; Bottom: T SP100. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment