게이트 기반 메모리 네트워크로 강화된 질문응답 및 대화 모델
본 논문은 기존 End‑to‑End Memory Network(MemN2N)의 메모리 접근을 동적으로 조절하기 위해 Highway/Residual 구조에서 영감을 얻은 게이트 메커니즘을 도입한 Gated MemN2N(GMemN2N)을 제안한다. 추가 감독 없이 전역적으로 학습되며, 20개의 bAbI QA 작업과 Dialog bAbI·DSTC‑2 대화 데이터셋에서 기존 모델을 크게 능가하는 성능을 기록한다.
저자: Julien Perez, Fei Liu
1. 서론
딥러닝 모델은 깊어질수록 학습이 어려워지는 vanishing/exploding gradient 문제에 직면한다. 특히 메모리‑강화 신경망은 컨트롤러와 메모리 블록 사이의 접근을 어떻게 조절하느냐가 성능에 큰 영향을 미친다. 기존 MemN2N은 고정된 hop 수와 softmax 기반 어텐션으로 메모리를 읽지만, 복잡한 추론이나 대화에서는 메모리 접근을 동적으로 제어할 필요가 있다. 저자들은 컴퓨터 비전 분야에서 성공한 Residual 및 Highway 네트워크의 스킵 연결 아이디어를 차용해, 메모리 접근 자체에 게이트를 삽입하는 방식을 제안한다.
2. 관련 연구
- MemN2N: 입력·출력 메모리 임베딩(A, C)과 질문 임베딩(B)으로 어텐션 가중치 p_i를 계산하고, 여러 hop을 쌓아 최종 답을 예측한다.
- Shortcut Connections: Residual Network는 y=H(x)+x 형태의 고정 스킵을, Highway Network는 변형 가능한 게이트 T(x)와 1−T(x)를 도입해 정보 흐름을 조절한다.
- Memory Dynamics: 기존 연구는 메모리 접근 횟수를 하드 슈퍼비전하거나 사전에 고정했지만, 자동화된 동적 제어는 부족했다.
3. Gated End‑to‑End Memory Network 설계
기존 hop 업데이트 u_{k+1}=o_k+u_k 를 다음과 같이 변형한다.
T_k(u_k)=σ(W_k^T u_k + b_k^T)
u_{k+1}=o_k ⊙ T_k(u_k) + u_k ⊙ (1−T_k(u_k))
여기서 ⊙는 원소별 곱이며, T_k는 현재 컨트롤러 상태에 따라 메모리 읽기(o_k)의 비중을 조절한다. 두 가지 가중치 공유 옵션을 실험한다. (1) Global: 모든 hop이 동일한 W^T, b^T를 공유, (2) Hop‑specific: 각 hop마다 독립적인 파라미터를 학습. 이 구조는 MemN2N의 residual 성질을 유지하면서, Highway와 유사한 학습 가능한 스킵 비율을 제공한다.
4. 실험 설정
- 데이터: bAbI 20개 QA 작업(v1.2)과 Dialog bAbI·DSTC‑2 대화 데이터. 각각 1k와 10k 학습 샘플을 사용.
- 전처리: 위치 인코딩, 인접 가중치 공유, 시간 인코딩, 10% 노이즈 추가.
- 하이퍼파라미터: embedding 차원 d=20, hop 수=3, 배치 32, 학습률 0.005 → 0.5배 감소(25 epoch마다), gradient clipping L2 norm 40, linear start(softmax 20 epoch 후 적용).
- 평가: 각 task별 정확도, 전체 평균, 100번(10k는 30번) 재시도 후 최고 모델 선택.
5. 결과
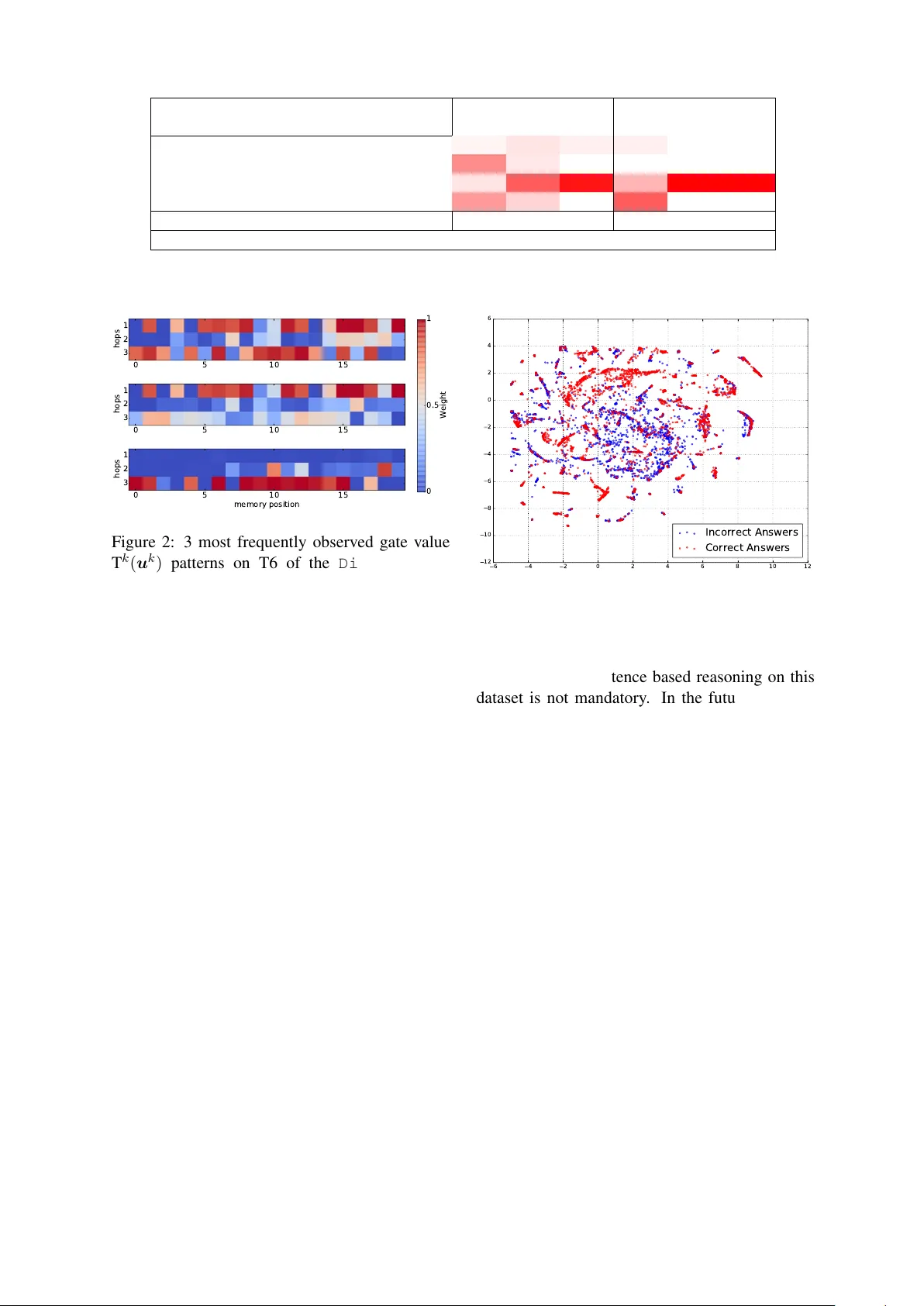
bAbI QA에서는 GMemN2N이 특히 어려운 task 5(3‑argument relation), task 17(positional reasoning), task 19(path finding)에서 기존 MemN2N 대비 10~20% 절대 정확도 상승을 보였다. 전체 평균 정확도는 1k 설정에서 87.3% (전역 가중치) → 87.3% (hop‑specific), 10k에서는 96.3% (hop‑specific)로, 기존 MemN2N(embedding 20)보다 우수하고, embedding 100을 사용한 원 논문보다도 앞선다.
Dialog bAbI와 DSTC‑2에서도 GMemN2N이 기존 MemN2N을 능가했으며, 특히 대화 상태 추적(task 6)에서 현저한 개선을 기록했다. hop‑specific 가중치가 전역 공유보다 일관적으로 더 높은 성능을 보였으며, 이는 각 hop이 다른 추론 단계에 맞춰 다른 게이트 전략을 학습함을 의미한다.
6. 논의 및 의의
- 동적 게이트는 메모리 접근을 필요에 따라 억제하거나 강화함으로써, 불필요한 연산을 줄이고 핵심 정보에 집중하게 만든다.
- Highway‑style 게이트는 gradient 흐름을 방해하지 않아 깊은 hop 구조에서도 학습이 안정적이다.
- 전역 vs. hop‑specific 가중치 비교를 통해, 복잡한 추론에서는 단계별 맞춤형 제어가 유리함을 확인했다.
- 모델 크기는 기존 MemN2N과 비슷하지만, 성능은 크게 향상돼 메모리 기반 신경망의 확장성을 보여준다. 앞으로 더 깊은 메모리 스택이나 멀티‑모달 입력에 적용할 여지가 크다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기