Gated End-to-End Memory Networks
Machine reading using differentiable reasoning models has recently shown remarkable progress. In this context, End-to-End trainable Memory Networks, MemN2N, have demonstrated promising performance on simple natural language based reasoning tasks such…
Authors: Julien Perez, Fei Liu
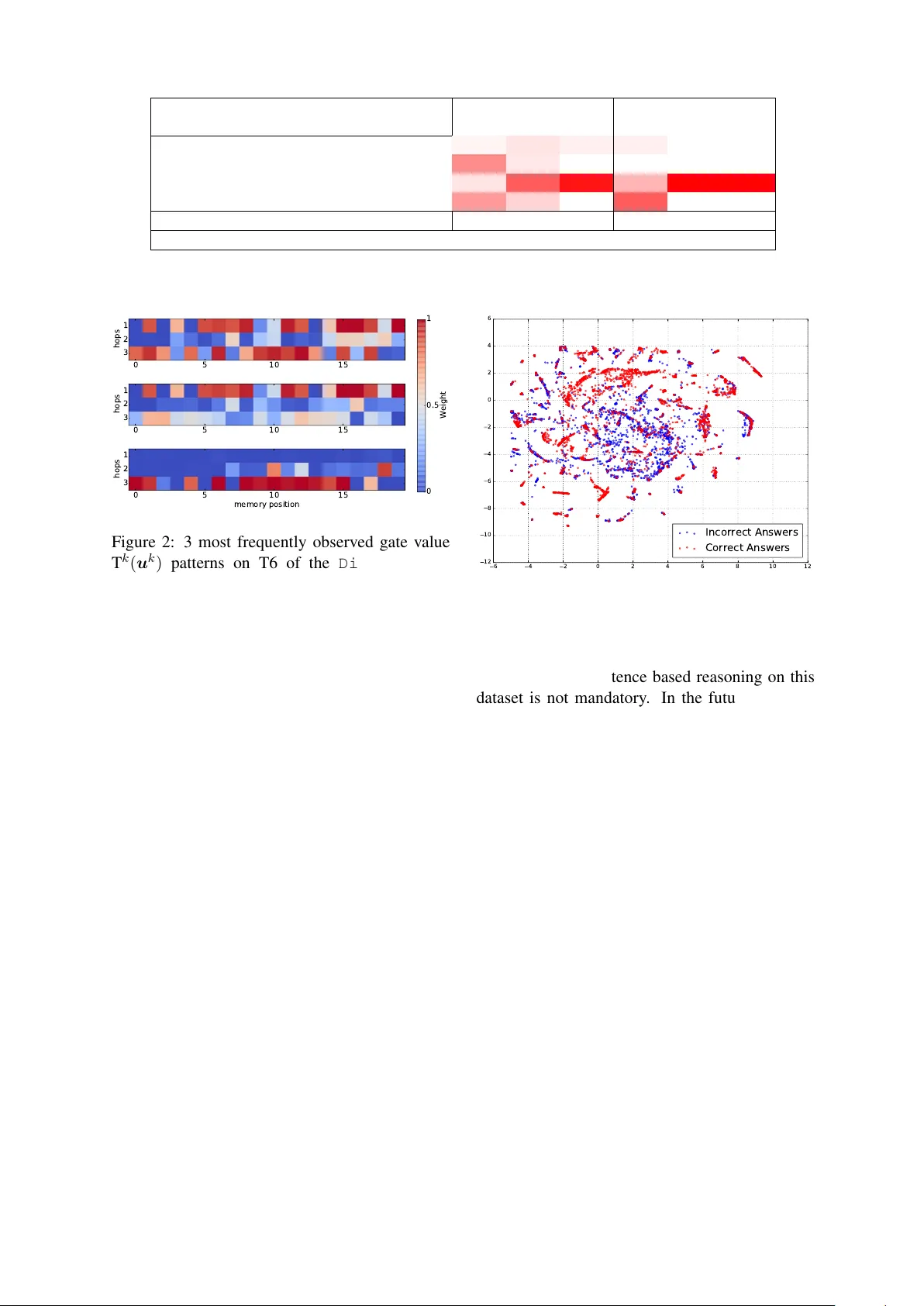
Gated End-to-End Memory Networks F ei Liu ∗ The Uni versity of Melbourne V ictoria, Australia fliu3@student.unimelb.edu.au Julien P er ez Xerox Research Centre Europe Grenoble, France julien.perez@xrce.xerox.com Abstract Machine reading using dif ferentiable rea- soning models has recently sho wn re- markable progress. In this context, End-to-End trainable Memory Networks ( MemN2N ) hav e demonstrated promising performance on simple natural language based reasoning tasks such as factual rea- soning and basic deduction. Ho wev er , other tasks, namely multi-fact question- answering, positional reasoning or dialog related tasks, remain challenging particu- larly due to the necessity of more com- plex interactions between the memory and controller modules composing this f amily of models. In this paper , we introduce a nov el end-to-end memory access regu- lation mechanism inspired by the current progress on the connection short-cutting principle in the field of computer vision. Concretely , we develop a Gated End-to- End trainable Memory Network architec- ture ( GMemN2N ). From the machine learn- ing perspecti ve, this ne w capability is learned in an end-to-end fashion without the use of any additional supervision sig- nal which is, as far as our knowledge goes, the first of its kind. Our experi- ments sho w significant improv ements on the most challenging tasks in the 20 bAbI dataset, without the use of any domain kno wledge. Then, we sho w impro vements on the Dialog bAbI tasks including the real human-bot con version-based Di- alog State T racking Challenge ( DSTC-2 ) dataset. On these two datasets, our model sets the ne w state of the art. ∗ work done as an Intern at Xerox Research Centre Europe 1 Introduction Deeper Neural Network models are more diffi- cult to train and recurrency tends to complex- ify this optimization problem (Sriv asta v a et al., 2015b). While Deep Neural Network architec- tures hav e shown superior performance in numer- ous areas, such as image, speech recognition and more recently text, the complexity of optimiz- ing such large and non-con vex parameter sets re- mains a challenge. Indeed, the so-called v anish- ing/exploding gradient problem has been mainly addressed using: 1. algorithmical responses, e.g., normalized initialization stategies (LeCun et al., 1998; Glorot and Bengio, 2010); 2. architec- tural ones, e.g., intermediate normalization layers which facilitate the con vergence of netw orks com- posed of tens of hidden layers (He et al., 2015; Saxe et al., 2014). Another problem of memory- enhanced neural models is the necessity of regulat- ing memory access at the controller le vel. Mem- ory access operations can be supervised (Kumar et al., 2016) and the number of times they are per- formed tends to be fix ed apriori (Sukhbaatar et al., 2015), a design choice which tends to be based on the presumed degree of difficulty of the task in question. Inspired by the recent success of object recognition in the field of computer vision (Sriv as- tav a et al., 2015a; Sriv asta v a et al., 2015b), we in- vestigate the use of a gating mechanism in the con- text of End-to-End Memory Networks ( MemN2N ) (Sukhbaatar et al., 2015) in order to regulate the access to the memory blocks in a differentiable fashion. The formulation is realized by gated con- nections between the memory access layers and the controller stack of a MemN2N . As a result, the model is able to dynamically determine how and when to skip its memory-based reasoning process. Roadmap: Section 2 revie ws state-of-the- art Memory Network models, connection short- cutting in neural networks and memory dynamics. In Section 3, we propose a differentiable gating mechanism in MemN2N . Section 4 and 5 present a set of experiments on the 20 bAbI reasoning tasks and the Dialog bAbI dataset. W e report ne w state-of-the-art results on sev eral of the most challenging tasks of the set, namely positional rea- soning, 3 -argument relation and the DSTC-2 task while maintaining equally competitive results on the rest. 2 Related W ork This section starts with an introduction of the pri- mary elements of MemN2N . Then, we revie w two ke y elements relev ant to this work, namely short- cut connections in neural networks in and memory dynamics in such models. 2.1 End-to-End Memory Networks The MemN2N architecture, introduced by Sukhbaatar et al. (2015), consists of two main components: supporting memories and final an- swer prediction. Supporting memories are in turn comprised of a set of input and output memory representations with memory cells. The input and output memory cells, denoted by m i and c i , are obtained by transforming the input context x 1 , . . . , x n (or stories) using two embedding matrices A and C (both of size d × | V | where d is the embedding size and | V | the vocab ulary size) such that m i = A Φ( x i ) and c i = C Φ( x i ) where Φ( · ) is a function that maps the input into a bag of dimension | V | . Similarly , the question q is encoded using another embedding matrix B ∈ R d ×| V | , resulting in a question embedding u = B Φ( q ) . The input memories { m i } , together with the embedding of the question u , are utilized to determine the rele v ance of each of the stories in the context, yielding a v ector of attention weights p i = softmax ( u > m i ) (1) where softmax ( a i ) = e a i P j ∈ [1 ,n ] e a j . Subse- quently , the response o from the output memory is constructed by the weighted sum: o = X i p i c i (2) For more difficult tasks requiring multiple sup- porting memories, the model can be extended to include more than one set of input/output memo- ries by stacking a number of memory layers. In this setting, each memory layer is named a hop and the ( k + 1) th hop takes as input the output of the k th hop: u k +1 = o k + u k (3) Lastly , the final step, the prediction of the an- swer to the question q , is performed by ˆ a = softmax ( W ( o K + u K )) (4) where ˆ a is the predicted answer distribution, W ∈ R | V |× d is a parameter matrix for the model to learn and K the total number of hops. 2.2 Shortcut Connections Shortcut connections ha ve been studied from both the theoretical and practical point of view in the general context of neural network architectures (Bishop, 1995; Riple y , 2007). More recently Residual Networks (He et al., 2016) and Highway Networks (Sri v astav a et al., 2015a; Sriv asta v a et al., 2015b) have been almost simultaneously pro- posed. While the former utilizes a residual cal- culus, the latter formulates a differentiable gate- way mechanism as proposed in Long-Short T erms Memory Networks in order to cope with long- term dependency issues in the dataset in an end- to-end trainable manner . These two mechanisms were proposed as a structural solution to the so- called v anishing gradient problem by allo wing the model to shortcut its layered transformation struc- ture when necessary . 2.3 Memory Dynamics The necessity of dynamically regulating the in- teraction between the so-called controller and the memory blocks of a Memory Network model has been study in (Kumar et al., 2016; Xiong et al., 2016). In these works, the number of exchanges between the controller stack and the memory mod- ule of the network is either monitored in a hard supervised manner in the former or fixed apriori in the latter . In this paper , we propose an end-to-end super- vised model, with an automatically learned gat- ing mechanism, to perform dynamic regulation of memory interaction. The next section presents the formulation of this new Gated End-to-End Mem- ory Networks ( GMemN2N ). This contrib ution can be placed in parallel to the recent transition from Memory Networks with hard attention mechanism (W eston et al., 2015) to MemN2N with attention v alues obtained by a softmax function and end-to- end supervised (Sukhbaatar et al., 2015). 3 Gated End-to-End Memory Network In this section, the elements behind residual learn- ing and highway neural models are given. Then, we introduce the proposed model of memory ac- cess gating in a MemN2N . 3.1 Highway and Residual Networks Highway Networks, first introduced by Sriv astav a et al. (2015a), include a transform gate T and a carry gate C, allowing the network to learn how much information it should transform or carry to form the input to the next layer . Suppose the orig- inal network is a plain feed-forward neural net- work: y = H ( x ) (5) where H ( x ) is a non-linear transformation of its input x . The generic form of Highway Networks is formulated as: y = H ( x ) T ( x ) + x C ( x ) (6) where the transform and carry gates, T ( x ) and C ( x ) , are defined as non-linear transformation functions of the input x and the Hadamard product. As suggested in (Sriv astav a et al., 2015a; Sri vasta v a et al., 2015b), we choose to focus, in the follo wing of this paper , on a simplified v ersion of Highway Networks where the carry gate is re- placed by 1 − T ( x ) : y = H ( x ) T ( x ) + x (1 − T ( x )) (7) where T ( x ) = σ ( W T x + b T ) and σ is the sig- moid function. In fact, Residual Networks can be viewed as a special case of Highway Networks where both the transform and carry gates are sub- stituted by the identity mapping function: y = H ( x ) + x (8) thereby forming a hard-wired shortcut connection x . 3.2 Gated End-to-End Memory Networks Arguably , Equation (3) can be considered as a form of residuality with o k working as the residual function and u k the shortcut connection. Ho w- e ver , as discussed in (Sriv astava et al., 2015b), in contrast to the hard-wired skip connection in Residual Networks, one of the advantages of Highway Networks is the adaptiv e gating mech- anism, capable of learning to dynamically control the information flow based on the current input. Therefore, we adopt the idea of the adapti ve gating mechanism of Highway Networks and integrate it into MemN2N . The resulting model, named Gated End-to-End Memory Networks ( GMemN2N ) and il- lustrated in Figure 1, is capable of dynamically conditioning the memory reading operation on the controller state u k at each hop. Concretely , we re- formulate Equation (3) into: T k ( u k ) = σ ( W k T u k + b k T ) (9) u k +1 = o k T k ( u k ) + u k (1 − T k ( u k )) (10) where W k T and b k are the hop-specific parameter matrix and bias term for the k th hop and T k ( x ) the transform gate for the k th hop. Similar to the two weight tying schemes of the embedding matrices introduced in (Sukhbaatar et al., 2015), we also explore tw o types of constraints on W k T and b k T : 1. Global: all the weight matrices W k T and bias terms b k T are shared across different hops, i.e., W 1 T = W 2 T = . . . = W K T and b 1 T = b 2 T = . . . = b K T . 2. Hop-specific: each hop has its specific weight matrix W k T and bias term b k T for k ∈ [1 , K ] and the y are optimized independently . 4 QA bAbI Experiments In this section, we first describe the natural lan- guage reasoning dataset we use in our experi- ments. Then, the experimental setup is detailed. Lastly , we present the results and analyses. 4.1 Dataset and Data Preprocessing The 20 bAbI tasks (W eston et al., 2016) have been employed for the experiments (using v1.2 of the dataset). In this dataset, a gi ven QA task con- sists of a set of statements, followed by a ques- tion whose answer is typically a single word (in a fe w tasks, answers are a set of w ords). The answer is av ailable to the model at training time but must be predicted at test time. The dataset consists of 20 different tasks with various emphases on dif- ferent forms of reasoning. For each question, only a certain subset of the statements contains infor- mation needed for the answer , and the rest are es- sentially irrelev ant distractors. As in (Sukhbaatar { x i } Sentences Question q T 1 Σ B A 1 C 1 u 1 u 1 1 − T 1 ( u 1 ) T 1 ( u 1 ) o 1 T 2 Σ A 2 C 2 u 2 u 2 1 − T 2 ( u 2 ) T 2 ( u 2 ) o 2 T 3 Σ A 3 C 3 u 3 u 3 1 − T 3 ( u 3 ) T 3 ( u 3 ) o 3 W ˆ a Predicted Answer Figure 1: Illustration of the proposed GMemN2N model with 3 hops. et al., 2015), our model is fully end-to-end trained without any additional supervision other than the answers themselves. Formally , for one of the 20 QA tasks, we are giv en example problems, each having a set of I sentences { x i } (where I ≤ 320 ), a question sentence q and answer a . Let the j th word of sentence i be x ij , represented by a one- hot vector of length | V | . The same representation is used for the question q and answer a . T wo ver - sions of the data are used, one that has 1,000 train- ing problems per task and the other with 10,000 per task. 4.2 T raining Details As suggested in (Sukhbaatar et al., 2015), 10% of the bAbI training set was held-out to form a v alidation set for hyperparameter tuning. More- ov er , we use the so-called position encoding, ad- jacent weight tying, and temporal encoding with 10% random noise. Learning rate η is initially as- signed a v alue of 0 . 005 with exponential decay ap- plied e very 25 epochs by η / 2 until 100 epochs are reached. Linear start is used in all our experiments as proposed by Sukhbaatar et al. (2015). W ith lin- ear start, the softmax in each memory layer is re- mov ed and re-inserted after 20 epochs. Batch size is set to 32 and gradients with an ` 2 norm larger than 40 are divided by a scalar to have norm 40 . All weights are initialized randomly from a Gaus- sian distribution with zero mean and σ = 0 . 1 ex- cept for the transform gate bias b k T which we em- pirically set the mean to 0 . 5 . Only the most recent 50 sentences are fed into the model as the memory and the number of memory hops is 3 . In all our experiments, we use the embedding size d = 20 . As a large variance in the performance of the model can be observed on some tasks, we follo w (Sukhbaatar et al., 2015) and repeat each train- ing 100 times with dif ferent random initializations and select the best system based on the valida- tion performance. On the 10k dataset, we repeat each training 30 times due to time constraints. Concerning the models implementation, there are minor dif ferences between the results of our im- plementation of MemN2N and those reported in (Sukhbaatar et al., 2015), the overall performance is equally competitive and, in some cases, better . It should be noted that v1.1 of the dataset was used whereas in this work, we employ the latest v1.2. It is therefore deemed necessary that we present the performance results of our implemen- tation of MemN2N on the v1.2 dataset. T o facilitate fair comparison, we select our implementation of MemN2N as the baseline as we believ e that it is indicati ve of the true performance of MemN2N on v1.2 of the dataset. 4.3 Results Performance results on the 20 bAbI QA dataset are presented in T able 1. For comparison pur- poses, we still present MemN2N (Sukhbaatar et al., 2015) in T able 1 but accompany it with the accu- racy obtained by our implementation of the same model with the same experimental setup on v1.2 of the dataset in the column “Our MemN2N ” for both the 1k and 10k versions of the dataset. In contrast, we also list the results achieved by GMemN2N with global and hop-specific weight constraints in the T ask 1k 10k MemN2N Our GMemN2N MemN2N Our GMemN2N MemN2N +global +hop MemN2N +global +hop 1: 1 supporting fact 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 2: 2 supporting facts 91.7 89.9 88.7 91.9 99.7 99.7 100.0 100.0 3: 3 supporting facts 59.7 58.5 53.2 61.2 90.7 89.1 94.7 95.5 4: 2 argument relations 97.2 99.0 99.3 99.6 100.0 100.0 100.0 100.0 5: 3 argument relations 86.9 86.6 98.1 99.0 99.4 99.4 99.9 99.8 6: yes/no questions 92.4 92.1 92.0 91.6 100.0 100.0 96.7 100.0 7: counting 82.7 83.3 83.8 82.2 96.3 96.8 96.7 98.2 8: lists/sets 90.0 89.0 87.8 87.5 99.2 98.1 99.9 99.7 9: simple negation 86.8 90.3 88.2 89.3 99.2 99.1 100.0 100.0 10: indefinite knowledge 84.9 84.6 80.1 83.5 97.6 98.0 99.9 99.8 11: basic coreference 99.1 99.7 99.8 100.0 100.0 100.0 100.0 100.0 12: conjunction 99.8 100.0 100.0 100.0 100.0 100.0 100.0 100.0 13: compound coreference 99.6 100.0 100.0 100.0 100.0 100.0 100.0 100.0 14: time reasoning 98.3 99.6 98.5 98.8 100.0 100.0 100.0 100.0 15: basic deduction 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 16: basic induction 98.7 99.9 99.8 99.9 99.6 100.0 100.0 100.0 17: positional reasoning 49.0 48.1 60.2 58.3 59.3 62.1 68.8 72.2 18: size reasoning 88.9 89.7 91.8 90.8 93.3 93.4 92.0 91.5 19: path finding 17.2 11.3 10.3 11.5 33.5 47.2 54.8 69.0 20: agent’ s moti v ation 100.0 100.0 100.0 100.0 100.0 100.0 100.0 100.0 A verage 86.1 86.1 86.6 87.3 93.4 94.1 95.2 96.3 T able 1: Accuracy (%) on the 20 QA tasks for models using 1k and 10k training examples. MemN2N :(Sukhbaatar et al., 2015). Our MemN2N : our implementation of MemN2N . GMemN2N +gol- bal: GMemN2N with global weight tying. GMemN2N +hop: GMemN2N with hop-specific weight tying. Bold highlights best performance. Note that in (Sukhbaatar et al., 2015), v1.1 of the dataset was used. GMemN2N columns. GMemN2N achieves substantial improv ements on task 5 and 17. The performance of GMemN2N is greatly improved, a substantial gain of more than 10 in absolute accuracy . Global vs. hop-specific weight tying. Com- pared with the global weight tying scheme on the weight matrices of the gating mechanism, apply- ing weight constraints in a hop-specific fashion generates a further boost in performance consis- tently on both the 1k and 10k datasets. State-of-the-art performance on both the 1k and 10k dataset. The best performing GMemN2N model achie ves state-of-the-art performance, an av erage accuracy of 87.3 on the 1k dataset and 96.3 on the 10k variant. This is a solid improve- ment compared to MemN2N and a step closer to the strongly supervised models described in (W e- ston et al., 2015). Notice that the highest aver - age accuracy of the original MemN2N model on the 10k dataset is 95 . 8 . Howe ver , it was attained by a model with layer-wise weight tying, not ad- jacent weight tying as adopted in this work, and, more importantly , a much lar ger embedding size d = 100 (therefore not shown in T able 1). In comparison, it is worth noting that the proposed GMemN2N model, a much smaller model with em- beddings of size 20 , is capable of achieving better accuracy . 5 Dialog bAbI Experiments In addition to the text understanding and reason- ing tasks presented in Section 4, we further ex- amine the ef fectiveness of the proposed GMemN2N model on a collection of goal-oriented dialog tasks (Bordes and W eston, 2016). First, we briefly de- scribe the dataset. Next, we outline the training details. Finally , experimental results are presented with analyses. 5.1 Dataset and Data Preprocessing In this work, we adopt the goal-oriented dialog dataset dev eloped by Bordes and W eston (2016) org anized as a set of tasks. The tasks in this dataset can be divided into 6 categories with each group focusing on a specific objecti ve: 1. issuing API calls, 2. updating API calls, 3. displaying options, 4. providing extra-information, 5. conducting full dialogs (the aggregation of the first 4 tasks) 6. Dia- log State T racking Challenge 2 corpus ( DSTC-2 ). The first 5 tasks are synthetically generated based on a kno wledge base consisting of f acts which de- fine all the restaurants and their associated prop- erties (7 types, such as location and price range). The generated texts are in the form of conv ersa- tion between a user and a bot, each of which is designed with a clear yet different objective (all in- volv ed in a restaurant reservation scenario). This dataset essentially tests the capacity of end-to- end dialog systems to conduct dialog with various goals. Each dialog starts with a user request with subsequent alternating user-bot utterances and it is the duty of a model to understand the intention of the user and respond accordingly . In order to test the capability of a system to cope with enti- ties not appearing in the training set, a dif ferent set of test sets, named out-of-vocab ulary (OO V) test sets, are constructed separately . In addition, a supplementary dataset, task 6, is provided with real human-bot con versations, also in the restau- rant domain, which is deri v ed from the second Di- alog State T racking Challenge (Henderson et al., 2014). It is important to notice that the answers in this dataset may no longer be a single word but can be comprised of multiple ones. 5.2 T raining Details At a certain gi ven time t , a memory-based model takes the sequence of utterances c u 1 , c r 1 , c u 2 , c r 2 , . . . , c u t − 1 , c r t − 1 (alternating be- tween the user c u i and the system response c r i ) as the stories and c u t as the question. The goal of the model is to predict the response c r t . As answers may be composed of multiple words, following (Bordes and W eston, 2016), we replace the final prediction step in Equation (4) with: ˆ a = softmax ( u > W 0 Φ( y 1 ) , . . . , u > W 0 Φ( y | C | )) where W 0 ∈ R d ×| V | is the weight parameter ma- trix for the model to learn, u = o K + u K ( K is the total number of hops), y i is the i th response in the candidate set C such that y i ∈ C , | C | the size of the candidate set, and Φ( · ) a function which maps the input text into a bag of dimension | V | . As in (Bordes and W eston, 2016), we extend Φ by se veral key additional features. First, two features marking the identity of the speaker of a particular utterance (user or model) are added to each of the memory slots. Second, we expand the feature representation function Φ of candidate responses with 7 additional features, each, focus- ing on one of the 7 properties associated with any restaurants, indicating whether there are any exact matches between words occurring in the candidate and those in the question or memory . These 7 fea- tures are referred to as the match features. Apart from the modifications described above, we carry out the experiments using the same ex- perimental setup described in Section 4.2. W e also constrain ourselves to the hop-specific weight ty- ing scheme in all our e xperiments since GMemN2N benefits more from it than global weight tying as sho wn in Section 4.3. As in (Sukhbaatar et al., 2015), since the memory-based models are sen- siti ve to parameter initialization, we repeat each training 10 times and choose the best system based on the performance on the v alidation set. 5.3 Results Performance results on the Dialog bAbI dataset are shown in T able 2, measured using both per -response accuracy and per -dialog accu- racy (giv en in parentheses). While per-response accuracy calculates the percentage of correct re- sponses, per -dialog accuracy , where a dialog is considered to be correct if and only if every re- sponse within it is correct, counts the percentage of correct dialogs. T ask 1-5 are presented in the upper half of the table while the same tasks in the OO V setting are in the lo wer half with dialog state tracking task as task 6 at the bottom. W e choose (Bordes and W eston, 2016) as the baseline which achie ves the current state of the art on these tasks. GMemN2N with the match features sets a new state of the art on most of the tasks. Other than on task T2 (OO V) and T3 (OO V), GMemN2N with the match features scores the best per-response and per-dialog accuracy . Even on T2 (OO V) and T3 (OO V), the model generates rather competiti ve results and remains within 0.3% of the best perfor- mance. Overall, the best average per-response ac- curacy in both the OO V and non-OO V categories is attained by GMemN2N . GMemN2N with the match features significantly impro ves per -dialog accuracy on T5. A break- through in per-dialog accuracy on T5 from less T ask MemN2N GMemN2N MemN2N GMemN2N +match +match T1: Issuing API calls 99.9 (99.6) 100.0 (100.0) 100.0 (100.0) 100.0 (100.0) T2: Updating API calls 100.0 (100.0) 100.0 (100.0) 98.3 (83.9) 100.0 (100.0) T3: Displaying options 74.9 (2.0) 74.9 (0.0) 74.9 (0.0) 74.9 (0.0) T4: Providing information 59.5 (3.0) 57.2 (0.0) 100.0 (100.0) 100.0 (100.0) T5: Full dialogs 96.1 (49.4) 96.3 (52.5) 93.4 (19.7) 98.0 (72.5) A verage 86.1 (50.8) 85.7 (50.5) 93.3 (60.7) 94.6 (74.5) T1 (OO V): Issuing API calls 72.3 (0.0) 82.4 (0.0) 96.5 (82.7) 100.0 (100.0) T2 (OO V): Updating API calls 78.9 (0.0) 78.9 (0.0) 94.5 (48.4) 94.2 (47.1) T3 (OO V): Displaying options 74.4 (0.0) 75.3 (0.0) 75.2 (0.0) 75.1 (0.0) T4 (OO V): Providing information 57.6 (0.0) 57.0 (0.0) 100.0 (100.0) 100.0 (100.0) T5 (OO V): Full dialogs 65.5 (0.0) 66.7 (0.0) 77.7 (0.0) 79.4 (0.0) A verage 69.7 (0.0) 72.1 (0.0) 88.8 (46.2) 89.7 (49.4) T6: Dialog state tracking 2 41.1 (0.0) 47.4 (1.4) 41.0 (0.0) 48.7 (1.4) T able 2: Per-response accuracy and per-dialog accuracy (in parentheses) on the Dialog bAbI tasks. MemN2N : (Bordes and W eston, 2016). +match indicates the use of the match features in Section 5.2. than 20% to ov er 70%. GMemN2N succeeds in improving the perfor - mance on the more practical task T6. W ith or without the match features, GMemN2N achieves a substantial boost in per-response accuracy on T6. Given that T6 is deriv ed from a dataset based on real human-bot con v ersations, not syntheti- cally generated, the performance gain, although far from perfect, highlights the effecti veness of GMemN2N in practical scenarios and constitutes an encouraging starting point towards end-to-end di- alog system learning. The effectiveness of GMemN2N is more pro- nounced on the mor e challenging tasks. The performance gains on T5, T5 (OO V) and T6, com- pared with the rest of the tasks, are more pro- nounced. Regarding the performance of MemN2N , these tasks are relati vely more challenging than the rest, suggesting that the adapti ve gating mech- anism in GMemN2N is capable of managing com- plex information flow while doing little damage on easier tasks. 6 V isualization and Analysis In addition to the quantitati ve results, we fur- ther look into the memory regulation mechanism learned by the GMemN2N model. Figure 2 presents the three most frequently observed patterns of the T k ( u k ) vectors for each of the 3 hops in a model trained on T6 of the Dialog bAbI dataset with an embedding dimension of 20 . Each ro w corre- sponds to the gate v alues at a specific hop whereas each column represents a giv en embedding dimen- sion. The pattern on the top indicates that the model tends to only access memory in the first and third hop. In contrast, the middle and bottom pat- terns only focus on the memory in either the first or last hop respectively . Figure 3 is a t-SNE pro- jection (Maaten and Hinton, 2008) of the flattened [ T 1 ( u 1 ); T 2 ( u 2 ); T 3 ( u 3 )] vectors obtained on the test set of the same dialog task with points cor- responding to the correct and incorrect responses in red and blue respecti vely . Despite the relative uniform distribution of the wrong answer points, the correct ones tend to form clusters that suggest the frequently observed behavior of a successful inference. Lastly , T able 3 sho ws the comparison of the attention shifting process between MemN2N and GMemN2N on a story on bAbI task 5 (3 ar- gument relations). Not only does GMemN2N man- age to focus more accurately on the supporting fact than MemN2N , it has also learned to rely less in this case on hop 1 and 2 by assigning smaller transform gate v alues. In contrast, MemN2N carries false and misguiding information (caused by the distracting attention mechanism) accumulated from the previ- ous hops, which ev entually led to the wrong pre- diction of the answer . 7 Related Reading T asks Apart from the datasets adopted in our exper - iments, the CNN/Daily Mail (Hermann et al., 2015) has been used for the task of machine read- ing formalized as a problem of text extraction from Story Support MemN2N GMemN2N Hop 1 Hop 2 Hop 3 Hop 1 Hop 2 Hop 3 Fred took the football there. 0.05 0.10 0.07 0.06 0.00 0.00 Fred journeyed to the hallw ay . 0.45 0.09 0.01 0.00 0.00 0.00 Fred passed the football to Mary . yes 0.10 0.64 0.93 0.29 1.00 1.00 Mary dropped the football. 0.40 0.17 0.00 0.64 0.00 0.00 A vg. transform gate cell v alues, P i T k ( u k ) i /d N/A N/A N/A 0.22 0.23 0.45 Question: Who gav e the football? Answer: Fred, MemN2N : Mary , GMemN2N : Fred T able 3: MemN2N vs. GMemN2N - bAbI dataset - T ask 5 - 3 argument relations 0 5 10 15 1 2 3 hops 0 5 10 15 1 2 3 hops 0 5 10 15 memory position 1 2 3 hops 0 0.5 1 Weight Figure 2: 3 most frequently observed gate value T k ( u k ) patterns on T6 of the Dialog bAbI dataset a source conditioned on a gi ven question. How- e ver , as pointed out in (Chen et al., 2016), this dataset not only is noisy but also requires little reasoning and inference, which is e videnced by a manual analysis of a randomly selected subset of the questions, showing that only 2% of the exam- ples call for multi-sentence inference. Richardson et al. (2013) constructed an open-domain reading comprehension task, named MCT est. Although this corpus demands v arious reasoning capabili- ties from multiple sentences, its rather limited size (660 paragraphs, each associated with 4 questions) renders training statistical models infeasible (Chen et al., 2016). Children’ s Book T est (CBT) (Hill et al., 2015) was designed to measure the abil- ity of models to exploit a wide range of linguistic context. Despite the claim in (Sukhbaatar et al., 2015) that increasing the number of hops is cru- cial for the performance improv ements on some tasks, which can be seen as enabling MemN2N to accommodate more supporting facts, making such performance boost particularly more pronounced on those tasks requiring complex reasoning, Hill et al. (2015) admittedly reported little improvement in performance by stacking more hops and chose a single-hop MemN2N . This suggests that the ne- 6 4 2 0 2 4 6 8 10 12 12 10 8 6 4 2 0 2 4 6 Incorrect Answers Correct Answers Figure 3: t-SNE scatter plot of the flattened gate v alues cessity of multi-sentence based reasoning on this dataset is not mandatory . In the future, we plan to in vestig ate into larger dialog datasets such as (Lo we et al., 2015). 8 Conclusion and Future W ork In this paper , we hav e proposed and dev eloped what is, as far as our knowledge goes, the first attempt at incorporating an iterativ e memory ac- cess control to an end-to-end trainable memory- enhanced neural netw ork architecture. W e sho wed the added value of our proposition on a set of, natural language based, state-of-the-art reasoning tasks. Then, we offered a first interpretation of the resulting capability by analyzing the attention shifting mechanism and connection short-cutting behavior of the proposed model. In future work, we will in vestigate the use of such mechanism in the field of language modeling and more gener- ally on the paradigm of sequential prediction and predicti ve learning. Furthermore, we plan to look into the impact of this method on the recently in- troduced Ke y-V alue Memory Networks (Miller et al., 2016) on larger and semi-structured corpus. References Christopher M. Bishop. 1995. Neural Networks for P attern Recognition . Oxford Univ ersity Press. Antoine Bordes and Jason W eston. 2016. Learn- ing end-to-end goal-oriented dialog. arXiv pr eprint arXiv:1605.07683 . Danqi Chen, Jason Bolton, and Christopher D Man- ning. 2016. A thorough examination of the cnn/daily mail reading comprehension task. In Pr o- ceedings of the 54th Annual Meeting of the Asso- ciation for Computational Linguistics (A CL 2016) , pages 2358–2367, Berlin, Germany . Xavier Glorot and Y oshua Bengio. 2010. Understand- ing the dif ficulty of training deep feedforward neural networks. In Proceedings of the 13th International Confer ence on Artificial Intelligence and Statistics (AIST ATS 2010) , pages 249–256, Sardinia, Italy . Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving deep into rectifiers: Surpass- ing human-level performance on imagenet classifi- cation. In Proceedings of the IEEE International Confer ence on Computer V ision (ICCV 2015) , pages 1026–1034, Santiago, Chile. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recog- nition. In the 29th IEEE Confer ence on Computer V ision and P attern Recognition (CVPR 2016) , Las V egas, USA. Matthew Henderson, Blaise Thomson, and Jason D. W illiams. 2014. The second dialog state track- ing challenge. In Proceedings of the 15th An- nual Meeting of the Special Interest Gr oup on Dis- course and Dialogue (SIGDIAL 2014) , pages 263– 272, Philadelphia, USA. Karl Moritz Hermann, T omas Kocisk y , Edward Grefenstette, Lasse Espeholt, W ill Kay , Mustafa Su- leyman, and Phil Blunsom. 2015. T eaching ma- chines to read and comprehend. In Pr oceedings of Advances in Neur al Information Pr ocessing Systems (NIPS 2015) , pages 1684–1692, Barcelona, Spain. Felix Hill, Antoine Bordes, Sumit Chopra, and Jason W eston. 2015. The goldilocks principle: Reading children’ s books with explicit memory representa- tions. In Pr oceedings of the 4th International Con- fer ence on Learning Repr esentations (ICLR 2016) , San Juan, Puerto Rico. Ankit Kumar , Ozan Irsoy , Jonathan Su, James Brad- bury , Robert English, Brian Pierce, Peter Ondruska, Ishaan Gulrajani, and Richard Socher . 2016. Ask me anything: Dynamic memory networks for nat- ural language processing. In Pr oceedings of the 33r d International Confer ence on Machine Learn- ing (ICML 2016) , New Y ork, USA. Y ann LeCun, Leon Bottou, Genevie v e B. Orr , and Klaus Robert M ¨ uller . 1998. Efficient backprop. Neural Networks: T ricks of the T rade , pages 9–50. Ryan Lowe, Nissan Pow , Iulian Serban, and Joelle Pineau. 2015. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dia- logue systems. In Pr oceedings of the 16th Annual SIGdial Meeting on Discourse and Dialogue (SIG- DIAL 2015) , Prague, Czech Republic. Laurens van der Maaten and Geoffre y Hinton. 2008. V isualizing data using t-SNE. Journal of Machine Learning Resear ch , 9:2579–2605. Alexander Miller , Adam Fisch, Jesse Dodge, Amir- Hossein Karimi, Antoine Bordes, and Jason W e- ston. 2016. Ke y-v alue memory networks for di- rectly reading documents. In Pr oceedings of the 2016 Conference on Empirical Methods in Natural Language Pr ocessing (EMNLP 2016) , Austin, USA. Matthew Richardson, Christopher J.C. Burges, and Erin Renshaw . 2013. MCT est: A challenge dataset for the open-domain machine comprehension of text. In Pr oceedings of the 2013 Conference on Empirical Methods in Natural Langua ge Pr ocessing (EMNLP 2013) , pages 193–203, Seattle, USA. Brian D. Ripley . 2007. P attern reco gnition and neural networks . Cambridge univ ersity press. Andrew M Saxe, James L McClelland, and Surya Gan- guli. 2014. Exact solutions to the nonlinear dy- namics of learning in deep linear neural networks. In Pr oceedings of the 2nd International Confer ence on Learning Repr esentations (ICLR 2014) , Banf f, Canada. Rupesh Kumar Sriv asta va, Klaus Greff, and J ¨ urgen Schmidhuber . 2015a. Highway networks. arXiv pr eprint arXiv:1505.00387 . Rupesh Kumar Sriv asta va, Klaus Greff, and J ¨ urgen Schmidhuber . 2015b . T raining very deep networks. In Proceedings of Advances in Neural Information Pr ocessing Systems (NIPS 2015) , pages 2377–2385, Montr ´ eal, Canada. Sainbayar Sukhbaatar, Arthur Szlam, Jason W eston, and Rob Fergus. 2015. End-to-end memory net- works. In Proceedings of Advances in Neural In- formation Pr ocessing Systems (NIPS 2015) , pages 2440–2448, Montr ´ eal, Canada. Jason W eston, Sumit Chopra, and Antoine Bordes. 2015. Memory networks. In Pr oceedings of the 3rd International Conference on Learning Repr esenta- tions (ICLR 2015) , San Diego, USA. Jason W eston, Antoine Bordes, Sumit Chopra, Alexan- der M Rush, Bart van Merri ¨ enboer , Armand Joulin, and T omas Mikolov . 2016. T owards AI-complete question answering: A set of prerequisite toy tasks. In Pr oceedings of the 4th International Confer- ence on Learning Repr esentations (ICLR 2016) , San Juan, Puerto Rico. Caiming Xiong, Stephen Merity , and Richard Socher . 2016. Dynamic memory networks for visual and textual question answering. In Pr oceedings of the 33r d International Confer ence on Machine Learning (ICML 2016) , pages 2397–2406, New Y ork, USA.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment