앵커 없이 상관 토픽 모델링 식별성과 효율적 알고리즘
본 논문은 기존의 앵커 워드 가정에 의존하던 토픽 모델링 방법을 탈피하여, 두 번째 차수 통계만을 이용해 토픽을 식별할 수 있는 새로운 프레임워크를 제안한다. 충분히 퍼진(sufficiently scattered) 조건 하에서 토픽-단어 행렬과 토픽 상관 행렬을 고유값 분해와 소규모 선형 프로그램 몇 개로 복구함으로써, 높은 확장성과 강인성을 확보한다. 실험 결과 TDT2와 Reuters-21578 데이터셋에서 일관성, 유사도, 군집 정확도 측…
저자: Kejun Huang, Xiao Fu, Nicholas D. Sidiropoulos
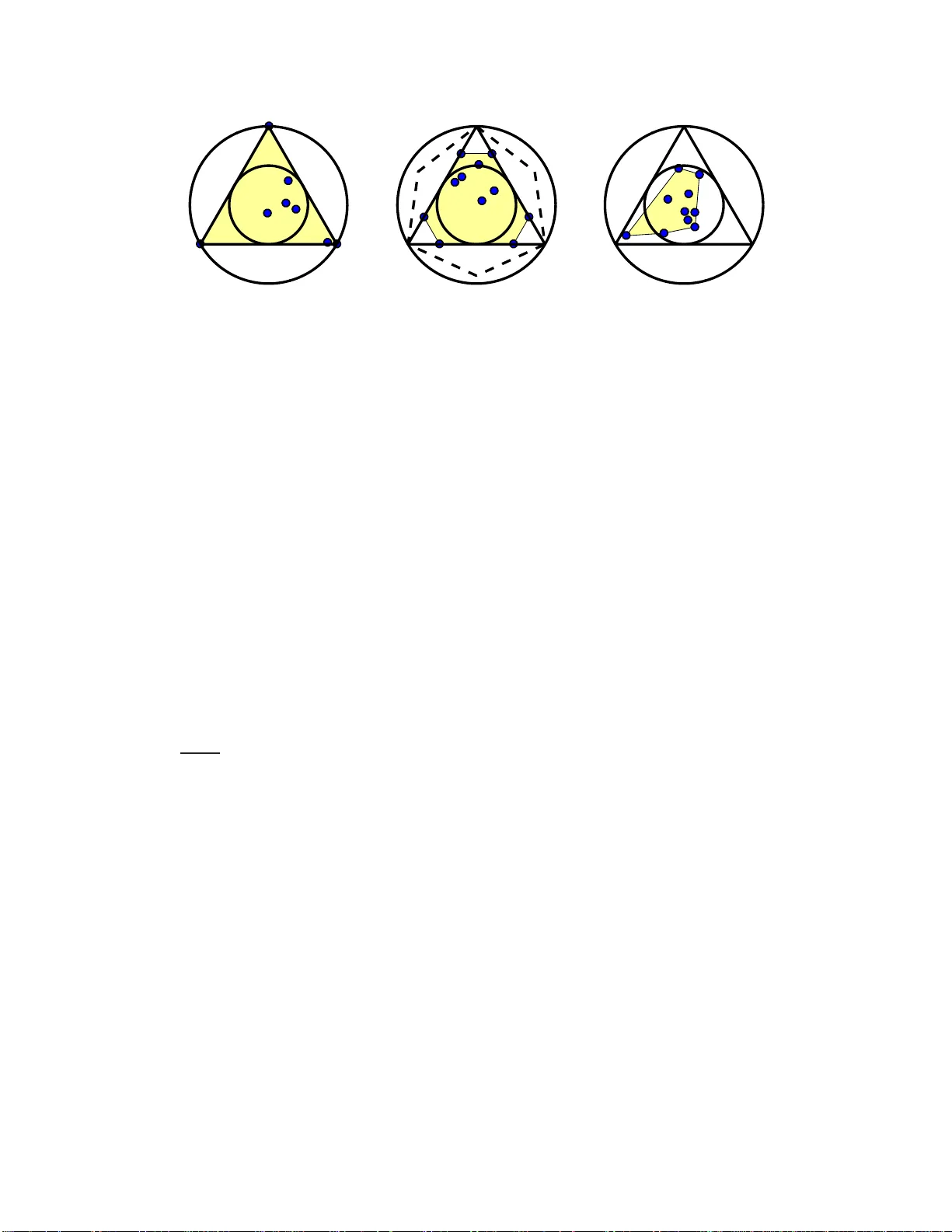
본 논문은 텍스트 마이닝에서 토픽 모델링의 핵심 과제인 토픽 식별성을 기존의 앵커 워드(Anchor Word) 가정 없이 달성하고자 한다. 전통적인 LDA 기반 방법은 비음수 행렬 분해(NMF)를 이용하지만, 식별성을 보장하려면 ‘분리 가능성(separability)’ 즉, 각 토픽마다 해당 토픽에만 등장하는 단어가 존재한다는 가정이 필요하다. 이 가정은 실제 데이터에서 자주 깨지며, 특히 토픽 간 단어가 겹치는 경우에 적용이 어렵다. 이를 보완하기 위해 최근 연구들은 3차원 이상 텐서 통계에 의존했지만, 고차원 통계는 샘플 요구량이 크고 계산 비용이 높으며, 토픽이 서로 상관될 경우 추가적인 희소성 가정이 필요했다.
저자들은 이러한 문제점을 해결하기 위해 단어-단어 상관 행렬 \(P = \mathbb{E}\{DD^{\top}\} = CEC^{\top}\) 를 핵심 모델로 채택한다. 여기서 \(C\in\mathbb{R}^{V\times F}\)는 토픽-단어 확률 질량 함수 행렬, \(E\in\mathbb{R}^{F\times F}\)는 토픽 간 상관 행렬이다. \(P\)는 문서 수가 많아질수록 샘플 평균에 의해 잡음이 크게 억제되며, 어휘 크기 \(V\)에만 의존하므로 대규모 코퍼스에 적합하다.
식별성을 확보하기 위해 저자들은 다음 최적화 문제를 제시한다.
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기