Anchor-Free Correlated Topic Modeling: Identifiability and Algorithm
In topic modeling, many algorithms that guarantee identifiability of the topics have been developed under the premise that there exist anchor words -- i.e., words that only appear (with positive probability) in one topic. Follow-up work has resorted …
Authors: Kejun Huang, Xiao Fu, Nicholas D. Sidiropoulos
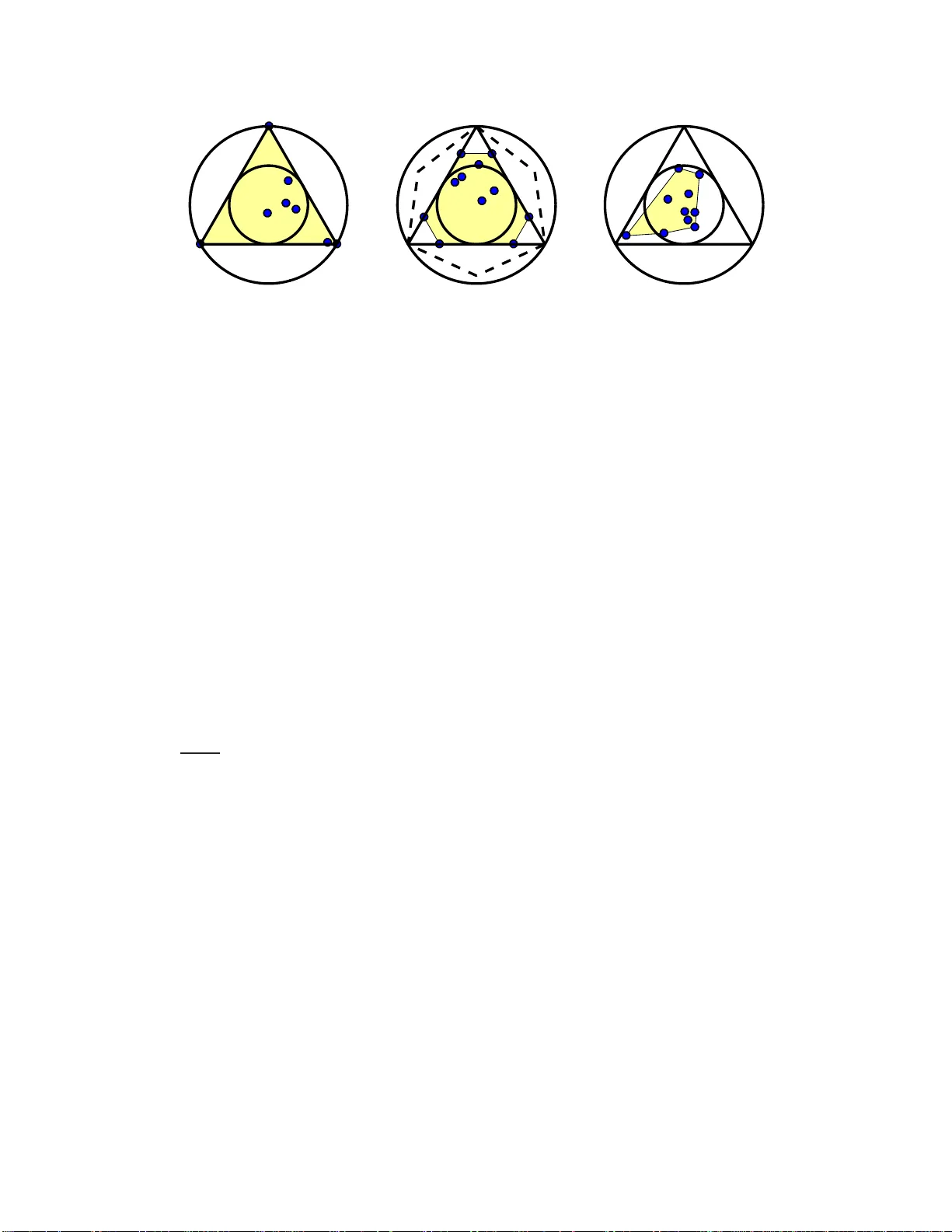
Anchor -Fr ee Corr elated T opic Modeling: Identifiabi lity and Algorithm Kejun Huang ∗ Xiao Fu ∗ Nicholas D . Sidiropoulos Departmen t of Electrical and Computer Engineer ing University of Minnesota Minneapo lis, MN 55455 , USA huang 663@um n.edu xfu@u mn.edu n ikos@ ece.u mn.edu Abstract In topic modeling, many algorithms that g uarantee identifiab ility of the topics have been de veloped under the premise that there exist anchor words – i.e., w ord s that only appear (with positive p robability ) in o ne topic. Follo w-up work has re- sorted to th ree or h igher-order statistics of the d ata corp us to relax the anchor word assumption. Reliable estimates of higher-order statistics are hard to ob tain, howe ver , and the identification of topics under those models hinges on uncorrelat- edness o f the topics, which can be unrealistic. This pap er revisits topic mo deling based on second-order moments, and proposes an anchor-free topic mining frame- work. The pro posed approach guarantees the identification of the top ics under a much milder condition compare d to the anchor-w ord assumption, thereby exhibit- ing much better rob ustness in p ractice. The ass ociated algorithm o nly inv olves one eigen-decom position and a fe w small li near prog rams. Th is makes it easy to im plement an d s cale up to v ery lar ge problem instances. Experim ents u sing the TDT2 and Reu ters-2157 8 corpu s demon strate that the pr oposed anchor-free approa ch exhibits very fav orab le p erforma nce (measured using coherence, simi- larity count, and clustering accuracy metrics) compared to the prior art. 1 Intr oduction Giv en a large collection of te xt d ata, e.g ., doc uments, tweets, or Facebook posts, a natural q uestion is what are the prom inent topics in these data. Mining topics from a text corpu s is motiv ated by a number o f applications, from commer cial design, news recomm endation , documen t classification, content summarization, and information retriev al, to national security . T opic mining , or topic model- ing , has attracted significant attentio n in the broader machine learning and data min ing community [1]. In 2003, Blei et al. proposed a Latent Dirichlet Allocation (LD A) model for topic mining [2], where the topics ar e modeled as probability mass fun ctions (PMFs) over a vocab ulary and ea ch docu ment is a mixture o f the PMFs. Therefore, a w ord -docum ent text data corpus can b e vie wed as a m atrix factorization model. Under this model, posterior inference-based methods and approx imations were propo sed [ 2, 3], but id entifiability issues – i.e., whether the matrix factors are unique – were not considered . Id entifiability , ho wever , is essential fo r topic modelin g since it prevents the mixin g of topics that confoun ds interpretatio n. In recent years, considerable effort has been invest ed in designing identifiable mo dels and estimation criteria as well a s polynomia l time solv able algorithm s for topic modeling [4, 5, 6, 7, 8, 9, 10, 11]. Essentially , these a lgorithms ar e ba sed o n th e so-ca lled separable no nnegative matrix factorization (NMF) model [ 12]. T he ke y assumption is that e very top ic has an ‘anchor w ord’ that only appear s ∗ These authors contributed equally . in that particular to pic. Based on this assum ption, two classes of algorithm s are usually employed, namely linear progr amming based methods [5, 7] and greedy pursuit approaches [11, 6, 8, 10]. Th e former class has a serious complexity issue, as it lifts the nu mber of variables to the square of the size of v ocabulary (or do cuments); the latter, althoug h computationa lly very efficient, usually suffers from error p ropag ation, if a t some point one anchor word is incor rectly iden tified. Furthermo re, since all the anch or word -based appr oaches essentially co n vert topic identification to th e p roblem of seekin g the vertices o f a simplex, most of t he above algorithms requir e norm alizing eac h data column (o r row) by its ℓ 1 norm. Howe ver , nor malization a t the f actorizatio n stag e is usually not desired, since it m ay destroy the good condition ing o f the d ata matrix brought by pre-processing and amplify noise [8]. Unlike ma ny NMF-b ased meth ods that work d irectly with the word-d ocumen t data, the ap proach propo sed by Arora et al. [9, 10] works with the pairwise w ord- word correlation matrix, which has the advantage of suppressing sampling n oise and also features better scalab ility . Howe ver , [9, 10] did not relax th e anchor-w ord assumptio n or the need for nor malization, and did not explore t he symmetric structure of the co-occurrenc e matrix – i.e., the algorithms in [9, 10] are essentially the same asymmetric separable NMF algorithms as in [4, 6, 8]. The an chor-word assumption is rea sonable in som e cases, but using m odels without it is m ore appea l- ing in more critical scenar ios, e.g., when some to pics are c losely related an d many key words overlap. Identifiable models withou t anchor words have bee n considered in the liter ature; e.g., [13, 14, 15] make use o f third or higher-order statistics of the data corpus to f ormulate the to pic mod eling prob - lem a s a tensor factorization pr oblem. There are two major drawbacks with this app roach: i) third- or higher-order statistics require a lot more samples for reliable estimation relati ve to their lo wer-order counterp arts ( e.g., second-order word correlation statistics); and ii) identifiability is guaranteed only when the topics are uncor related – where a super-symmetric parallel factor an alysis (P ARAF A C) model can b e obtained [1 3, 14]. Uncorrelatedness is a restrictive assumption [10]. Whe n the top ics are correlated , the model be comes a T u cker m odel which is not ide ntifiable in general; identifiability needs more assumptions, e.g., sparsity of topic PMFs [15]. Contributions. In this work , our interest lies i n top ic mining using word- word cor relation matrices like in [9, 10], because of its po tential scalability and noise robustness. W e propose an ancho r- free identifiable mod el and a pr actically imple mentable c ompanio n algo rithm. Our con tributions are two-fold: First, we propose an ancho r-free topic identification criterion. The criterion aims at factoring th e word-word correla tion matrix using a word-topic PMF m atrix and a topic-top ic correlation m atrix via min imizing th e d eterminan t of th e to pic-topic cor relation matrix . W e sho w that und er a so-called sufficiently scatter ed cond ition, which is mu ch milder than th e anchor-word assumption, the two matr ices can be u niquely identified b y the propo sed criterion. W e empha size that the p roposed ap proach does n ot n eed to resort to h igher-order statistics tensors to en sure topic identifiability , and it can n aturally deal with correlated topics, unlike wh at was previously a vailable in topic mo deling, to the b est of o ur knowledge. Seco nd, we p ropose a simple p rocedu re for han dling the p ropo sed criterion that o nly inv olves eigen -decom position of a large but sp arse matrix, plu s a few small linear pro grams – ther efore highly scalable and well-suited for topic mining . Un like greedy pu rsuit-based algorithm s, the pro posed algor ithm does not in v olve deflation an d is th us fr ee from error pro pagation; it also does not require normalization of the data columns / rows. Carefully designed experiments using the TDT2 and Reuters text c orpor a showcase the effectiv eness of th e propo sed approac h. 2 Backgr ound Consider a document corpus D ∈ R V × D , where each column of D correspo nds to a document and D ( v , d ) denotes a certain m easurement of word v in documen t d , e.g., the word-freque ncy of term v in document d or the term frequency–inverse documen t fr equency (tf-idf) measurement that is often used in topic mining. A co mmonly used model is D ≈ C W , (1) where C ∈ R V × F is th e word -topic matr ix, whose f -th column C (: , f ) represents the p robability mass fu nction (PMF) o f topic f over a v ocabulary o f words, and W ( f , d ) den otes the weig ht of topic f in d ocumen t d [2, 13, 10]. Since matrix C and W are both nonn egati ve, (1) be comes 2 a nonnegati ve matrix f actor ization (NMF) model – and many early w orks tried to use NMF and variants to deal with this problem [16]. However , NMF d oes not admit a uniqu e solution in general, unless both C and W satisfy some s parsity- related co nditions [17]. In recent years, much effort has b een pu t in devising p olynom ial time solvable algo rithms for NMF mode ls that admit uniqu e factorization. Su ch models and algorithms usu ally r ely on an assumption called “separability” in th e NMF literature [12]: Assumption 1 (Se parability / Anchor-W or d Ass umptio n) Ther e exists a set of indices Λ = { v 1 , . . . , v F } su ch that C (Λ , :) = Diag( c ) , where c ∈ R F . In top ic mo deling, it turns ou t that the separ ability con dition has a n ice ph ysical interp retation, i.e., ev ery topic f for f = 1 , . . . , F ha s a ‘ special’ word that h as n onzero p robability of ap pearing in topic f an d zero pr obability of app earing in other top ics. Th ese words ar e called ‘an chor words’ in the topic modelin g literature. Under Assumption 1, th e task of ma trix factorizatio n boils down to finding these an chor words v 1 , . . . , v F since D (Λ , :) = Diag( c ) W — which is already a scaled version of W — and then C can be estimated via (con strained) least squares. Algorithm 1: Successi ve Projection Algorithm [6] input : D ; F . Σ = 1 T D T X = D T Σ − 1 (norm alization); Λ = ∅ ; for f = 1 , . . . , F do ˆ v f ← ar g max v ∈ { 1 , ...,V } k X (: , v ) k 2 ; Λ ← [Λ , ˆ v f ] ; Θ ← arg min Θ k X − X (: , Λ) Θ k 2 F ; X ← X − X (: , Λ ) Θ ; end output : Λ Many algor ithms have been prop osed to tackle this index-pickin g problem in the context o f separable NMF , hyperspectra l unmix ing, and text minin g. The arguably simplest algor ithm is th e so-called su c- cessi ve proje ction algorithm (SP A) [6] that is pre- sented in Alg orithm 1. SP A-like alg orithms first define a n ormalized matrix X = D T Σ − 1 where Σ = Diag ( 1 T D T ) [11]. Note that X = GS where G (: , f ) = W T ( f , :) / k W ( f , :) k 1 and S ( f , v ) = C ( v ,f ) k W ( f , :) k 1 k C ( v , :) k 1 k D ( v , :) k 1 . Consequen tly , we ha ve 1 T S = 1 T if W ≥ 0 , meaning the columns of X all lie on the simplex spanned by the co lumns o f G , and the vertices o f th e simplex co rrespon d to the ancho r words. Also, the columns of S all li ve in the unit simplex. Af ter normalizatio n, SP A sequ entially iden- tifies the vertices of th e data simplex, in con junc- tion wit h a deflation pro cedure. The algorithm s in [8, 10, 11] can also be considered v ariants of SP A, with different deflation procedures and pre-/post- processing. In par ticular, the algorith m in [8] av oids no rmalization — for real-word data, norm al- ization at the factorizatio n stage may amp lify n oise and damag e th e good condition ing of th e data matrix b rough t by pre-pro cessing, e.g., the tf-id f proced ure [ 8]. T o p ick out vertices, there are also al- gorithms using linear programmin g and sparse optimization [7, 5 ], but these have serio us scalability issues and thus are less appealing. In pr actice D may con tain consid erable noise, and th is has b een noted in the literature. In [9, 10, 14, 15], the authors proposed t o use second and higher-order statistics for topic mining. Particularly , Arora et al. [9, 10] pro posed to work with the follo wing matrix: P = E { D D T } = C E C T , (2) where E = E { W W T } ca n b e inter preted a s a topic-to pic corr elation matr ix. The matr ix P is by definition a word- word correlation matrix, but also h as a nice inter pretation: if D ( v, d ) denotes th e frequen cy of word v occur ring in do cument d , P ( i, j ) is the likelihood that term i an d j co- occur in a d ocumen t [9, 10]. There are two advantages in using P : i) if th ere is zer o-mean white no ise, it will b e sign ificantly sup pressed thr ough the averaging process; and ii) the size of P doe s not grow with the size of th e data if the vocabulary is fixed. The latter is a d esired proper ty when the numbe r of do cuments is very large, and we pick a (po ssibly lim ited but) man ageable vocabulary to work with. Pro blems with similar stru cture to that of P also arise in the c ontext of g raph m odels, whe re commun ities and correlations appear as the underlying f actor s. The algorithm proposed in [10 ] also makes use o f Assum ption 1 and is conc eptually close to Algo rithm 1. T he work in [1 3, 14, 1 5] relaxed the anchor-word assump tion. The methods there make use of three or h igher-order statistics, e.g., P ∈ R V × V × V whose ( i, j, k ) th en try represents the co-occurr ence of three terms. The work in [ 13, 14] showed that P is a ten sor satisfying the p arallel factor an alysis ( P ARAF AC) mod el and thus C is un iquely identifiable, if the top ics are unc orr elated , which is a restricti ve assum ption 3 (a co unter exam ple would be politics and eco nomy) . Wh en th e top ics are correlated , addition al assumptions like sparsity are needed to restore identifiab ility [15]. Ano ther imp ortant con cern is that reliable estimates o f higher-order statistics require much larger data sizes, and tensor decompo sition is computatio nally cumbersome as well. Remark 1 Amon g all the afor emention ed me thods, th e defla tion-ba sed methods are seemingly more efficient. However , if the deflatio n pr ocedu r e in Algo rithm 1 (th e up date o f Θ ) h as co nstraints like in [8, 11], ther e is a serious co mplexity issue: solving a constrained least squa r es pr oblem with F V variab les is not an ea sy task. Data sp arsity is destr oyed after th e fi rst de flation step , and thus even first-or der methods or coordinate d escent as in [8, 11] d o no t r eally help. This po int will b e exemplified in our e xperiments. 3 Anchor -Free I dentifiable T opic Mining In this work , we are primarily interested in mining topics from the matrix P because of its noise robustness and scalability . W e will for mulate topic modeling as an optimization prob lem, and show that the word-topic matrix C can be iden tified under a much m ore relaxed cond ition, wh ich includes the relativ ely strict anchor-word assumption as a special case. 3.1 Problem Formulation Let us begin with the mod el P = C E C T , sub ject to th e constra int that each column of C r epresents the PM F of words app earing in a specific topic , such that C T 1 = 1 , C ≥ 0 . Such a sy mmetric matrix decom position is in gener al not identifiable, as we can always pick a n on-singu lar matrix A ∈ R F × F such that A T 1 = 1 , A ≥ 0 , and defin e ˜ C = C A , ˜ E = A − 1 C A − 1 , and th en P = ˜ C ˜ E ˜ C T with ˜ C T 1 = 1 , ˜ C ≥ 0 . W e wish to find an identification criterion such that under some mild condition s the correspo nding s olutio n can only be the ground- truth E and C up to some trivial am biguities such as a com mon column permu tation. T o this en d, we p ropo se the following criterion: minimize E ∈ R F × F , C ∈ R V × F | det E | , s ubject to P = C E C T , C T 1 = 1 , C ≥ 0 . (3) The first o bservation is that if the a nchor-word assumption is satisfied, the optimal solutions o f th e above identification criterio n are the gro und-tr uth C and E and their column -permu ted versions. Formally , we sh ow that: Proposition 1 Let ( C ⋆ , E ⋆ ) be an optimal solu tion of (3). If the separability / anchor-wor d a ssump- tion (cf. Assumptio n 1) is satisfied and rank( P ) = F , then C ⋆ = C Π an d E ⋆ = Π T E Π , wher e Π is a pe rmutation matrix. The pr oof of Proposition 1 c an be fo und in the su pplemen tary m aterial. Pro position 1 is mer ely a ‘sanity chec k’ of the identification criterion in (3 ): It shows that the cr iterion is at least a sou nd one under the anc hor-word assumption. Note tha t, whe n th e an chor-word assumption is satisfied, SP A- type algorithms ar e in fact preferab le over the identification criterion in (3), du e to their simplicity . The point of the no n-conve x fo rmulation in ( 3) is that it can g uarantee iden tifiability of C a nd E ev en when the anchor-w ord assumption is gr ossly violated. T o explain, we will need the following. Assumption 2 (sufficiently scatter ed) Let co ne( C T ) ∗ denote the polyhed ral cone { x : C x ≥ 0 } , and K deno te the second-or der cone { x : k x k 2 ≤ 1 T x } . Matrix C is called sufficiently scat tered if it s atisfies that: (i) cone( C T ) ∗ ⊆ K , and (ii) cone( C T ) ∗ ∩ b d K = { λ e f : λ ≥ 0 , f = 1 , . . . , F } , wher e b d K denote s the boundary of K , i.e., bd K = { x : k x k 2 = 1 T x } . Our main result is based on this assumption, whose first conseque nce is as follows: Lemma 1 If C ∈ R V × F is sufficiently scatter ed, then ra nk( C ) = F . In additio n, given rank( P ) = F , any feasible solution ˜ E ∈ R F × F of Pr oblem (3) has full r ank and thus | de t ˜ E | > 0 . Lemma 1 ensure s that any feasible so lution p air ( ˜ C , ˜ E ) of Pro blem (3) has full r ank F when the groun d-truth C is suffi ciently scattered, wh ich is impor tant f rom the op timization perspec ti ve – 4 (a) separable / anchor word (b) sufficiently scattered (c) not identifiable Figure 1 : A gr aphical view of rows of C ( blue d ots) a nd various co nes in R 3 , sliced at the plane 1 T x = 1 . The triang le indicates the non-n egati ve or thant, the enclosing circle is K , and the smaller circle is K ∗ . The s hade d r egion is cone( C T ) , and the polygo n with dashed sides is cone( C T ) ∗ . The matrix C can be iden tified u p to colum n p ermutation in the left two cases, and clear ly sep arability is more restricti ve than (and a special case of) sufficiently scattered. otherwise | det ˜ E | can a lways be zero which is a trivial optimal solution of (3). Based on Lemm a 1, we furthe r show that: Theorem 1 Let ( C ⋆ , E ⋆ ) be an optima l solution of (3). If the gr ound truth C is sufficien tly scat- ter ed (cf. Assumptio n 2) an d r ank( P ) = F , then C ⋆ = C Π and E ⋆ = Π T E Π , wher e Π is a permutation matrix. The proof of Th eorem 1 is relegated to the su pplementa ry mater ial. In words, f or a sufficiently scattered C and an arbitrary square matrix E , given P = C E C T , C and E can be identified up to permutatio n via solving (3). T o u nderstand the sufficiently scattered co ndition and Th eorem 2, it is better to look a t the dual cones. The notation co ne( C T ) ∗ = { x : C x ≥ 0 } c omes from t he fact th at it is the du al con e o f the conic hu ll of the row vector s of C , i.e., cone( C T ) = { C T θ : θ ≥ 0 } . A useful property of dual cone is that for tw o conv ex cones, if K 1 ⊆ K 2 , then K ∗ 2 ⊆ K ∗ 1 , which means the first requirem ent of Assumption 2 is equiv alent to K ∗ ⊆ cone( C T ) . (4) Note that the dual con e of K is ano ther secon d-ord er co ne [1 2], i.e., K ∗ = { x | x T 1 ≥ √ F − 1 k x k 2 } , which is tangen t to an d co ntained in the nonn egati ve orthant. Eq. (4) and the defi- nition of K ∗ in fact give a straightf orward com parison between th e propo sed sufficiently scattered condition an d the existing anchor-word assumption . An illustration o f Assumption s 1 and 2 is shown in Fig . 1 ( a)-(b) usin g an F = 3 case, wher e one can see that sufficiently scattered is much mo re relaxed co mpared to the anchor-word assump tion: if the rows o f the word-topic m atrix C are geo met- rically scattered enough s o that cone( C T ) con tains the inner circle (i.e., the s econ d-ord er con e K ∗ ), then the identifiability of the criterion in (3) is gua ranteed. Howe ver , the an chor-word assump tion requires that c o ne( C T ) fulfills th e en tire triangle, i.e., the nonnegative orthan t, wh ich is far m ore restrictiv e. Fig. 1(c) shows a c ase where r ows o f C are n ot “w ell scattered ” in the non-n egati ve orthant, and indeed such a matrix C cannot be identified via solving (3). Remark 2 A salien t featu r e o f the criterion in (3) is that it does not need to normalize the data columns to a simp lex — all the arguments in Theorem 1 ar e cone-b ased. The up shot is clear: ther e is no risk o f amplifying noise or chan ging the conditionin g of P at the factorization stage. Fu rther- mor e, matrix E can be any s ymmetric matrix; it can contain ne gative values, which may co ver mor e applicatio ns beyond topic modeling where E is always n onnegative and positive semid efinite. Th is shows the surprising effectiveness of the s ufficiently scatter ed cond ition. The sufficiently scattered assum ption appe ared in ide ntifiability pr oofs of several matrix factoriza- tion m odels [17, 18, 19] with different iden tification c riteria. Huang et al. [17] u sed this conditio n to show the identifiab ility o f p lain NMF , while Fu et a l. [19] related the sufficiently scatter ed c on- dition to the so-called volume-minimiza tion criterion for b lind sourc e separ ation. Note that volume 5 minimization also minimiz es a de terminant- related cost f unction . L ike th e SP A-type alg orithms, volume minimization works with da ta that live in a simp lex, therefore apply ing it still requ ires data normalizatio n, which is no t desired in p ractice. Theo rem 1 can be consid ered as a mor e natura l application of the sufficiently scattered condition to co-occur rence/cor relation based topic mod eling, which explores the symmetry of the model and a voids normalization. 3.2 AnchorFree: A Simple and Scala ble Algorithm The identification criterion in (3) imposes an interesting yet challenging optimization problem. One way to tackle it is to consider the following approxim ation: minimize E , C P − C E C T 2 F + µ | det E | , subject to C ≥ 0 , C T 1 = 1 , (5) where µ ≥ 0 balances the data fidelity and the minim al determin ant criterion. The difficulty is that th e term C E C T makes the prob lem tri-linear a nd no t easily decou pled. Plus, tu ning a good µ may a lso be difficult. In this work, we pro pose an easier proced ure o f h andling the determinant- minimization problem in (3), which is summarized in Algorithm 2, and referre d to as Anch orFree. T o explain the pr ocedur e, first notice that P is symmetric and p ositiv e semidefinite. T herefor e, one can app ly squar e roo t decom position to P = B B T , wh ere B ∈ R V × F . W e c an take advantage of well-established tools for eigen-d ecompo sition of spa rse matrices, and there is wid ely available software that can com pute this very efficiently . Now , we hav e B = C E 1 / 2 Q , Q T Q = QQ T = I , and E = E 1 / 2 E 1 / 2 ; i.e., th e representing co efficients of C E 1 / 2 in th e ran ge space of B mu st be orthon ormal because of the symmetry of P . W e also no tice that minimize E , C , Q | det E 1 / 2 Q | , subject to B = C E 1 / 2 Q , C T 1 = 1 , C ≥ 0 , Q T Q = I , (6) has th e same optimal so lutions as (3). Since Q is u nitary , it does n ot affect the deter minant, so we further let M = Q T E − 1 / 2 and obtain the following optimization problem maximize M | det M | , subject to M T B T 1 = 1 , B M ≥ 0 . (7) By o ur ref ormulatio n, C h as bee n marginalized and we have only F 2 variables left, which is sig- nificantly smaller co mpared to the variable size of the origin al pr oblem V F + F 2 , where V is th e vocab ulary size. Problem ( 7) is still non -conve x, but can b e ha ndled very efficiently . Her e, we pro- pose to em ploy the so lver prop osed in [ 18], wher e the same subprob lem (7 ) was u sed to solve a dynamica l system id entification p roblem. The idea is to ap ply the co-factor expansion to deal with the determinan t objective functio n, first pr oposed in the con text of non- negativ e blind source sepa- ration [20]: if we fix all th e colum ns of M except th e f th one, det M becomes a linear f unction with r espect to M (: , f ) , i.e ., det M = P F k =1 ( − 1) f + k M ( k , f ) det ¯ M k,f = a T M (: , f ) , whe re a = [ a 1 , . . . , a F ] T , a k = ( − 1) f + k det ¯ M k,f , ∀ k = 1 , ..., F , and ¯ M k,f is a matrix ob tained by removing the k th row an d f th column of M . Maxim izing | a T x | sub ject to linear constraints is s till a non- conv ex pro blem, but we can solve it via maximizing both a T x and − a T x , followed by pick- ing the solution that gives larger absolute objective. Then , cyclically up dating the column s of M results in an alternating optimization (A O) algorithm. The algorithm is computationally lightweig ht: each linear program only in volves F variables, leading t o a worst-case complexity of O ( F 3 . 5 ) flops ev en when the interior-point method is employed, and empirically it takes 5 or less A O iterations to conv erge. In the supplemen tary material, simulations on syn thetic d ata a re g iv en, showing that Al- gorithm 2 can indeed recover the ground truth matrix C and E even when matrix C gro ssly violates the separability / anchor-word assumption. 4 Experiments Data In th is section, we ap ply the p ropo sed algorithm and the baseline s to two po pular text mining datasets, namely , the NIST T opic Detection and Tracking (TDT2) and the Reuters-21 578 corpor a. W e use a subset of th e TDT 2 corpus consisting o f 9 ,394 docu ments which are single-categor y a r- ticles belon ging to the largest 30 categories. The Reuters-21 578 cor pus is th e ModAp te version where 8,29 3 single- category docu ments are kept. The or iginal vocabulary sizes o f the TDT2 an d the Reute rs dataset a re 3 6 , 77 1 and 18 , 933 , respectively , and stop words ar e re moved for each tria l 6 Algorithm 2: AnchorFree input : D , F . P ← Co-Oc curre nce ( D ) ; P = B B T , M ← I ; repeat for f = 1 , . . . , F do a k = ( − 1) f + k det ¯ M k,f , ∀ k = 1 , ..., F ; // remov e k -th row and f - th column of M t o obtain ¯ M k,f m max = arg max x a T x s.t. B x ≥ 0 , 1 T B x = 1 ; m min = arg min x a T x s.t. B x ≥ 0 , 1 T B x = 1 ; M (: , f ) = arg max m max , m min ( | a T m max | , | a T m min | ) ; end until conver gen ce ; C ⋆ = B M ; E ⋆ = ( C T ⋆ C ⋆ ) − 1 C T ⋆ P C ⋆ ( C T ⋆ C ⋆ ) − 1 ; output : C ⋆ , E ⋆ of the experiments. W e use the standar d tf-idf d ata as th e D matrix, and estimate the correlation matrix using the b iased estimator sug gested in [9]. A standard pr e-proce ssing technique, namely , normalized -cut weig hted (NCW) [21], is applied to D ; NCW is a well-known trick for handling the unbalan ced-cluster-size problem. For each trial o f our exper iment, we rand omly draw F categor ies of docum ents, form the P matrix, and apply the prop osed algorithm and the baselines. Baselines W e employ se veral popula r an chor word-based alg orithms as baselines. Specifically , the successi ve pr ojection alg orithm ( SP A) [6], the successi ve non negativ e projection algorithm (SNP A) [11 ], the XRA Y algorithm [8], and th e fast ancho r words ( FastAnchor) [ 10] algo rithm. Sinc e we are inter ested in word-word correlation/co-o ccurren ce based mining, all the algo rithms are com- bined with the fr amew ork p rovided in [1 0] an d the efficient Rec overL 2 process is employed for estimating the topics after the anchors are identified. Evaluation T o evaluate the results, we emp loy sev eral metrics. First, coher ence ( Coh ) is u sed to measure the single-topic quality . For a set o f words V , the coheren ce is d efined as Coh = P v 1 ,v 2 ∈V log ( freq( v 1 ,v 2 )+ ǫ / freq( v 2 ) ) , wher e v 1 and v 2 denote the indices of two w ords in the vocab- ulary , freq( v 2 ) and fr e q ( v 1 , v 2 ) denote the nu mbers o f documents in which v 1 appears and v 1 and v 2 co-occu r , respectively , and ǫ = 0 . 0 1 is u sed to prevent taking log o f zer o. Coherence is considered well-aligned to h uman judg ment when ev aluating a sing le topic — a higher cohe rence score means better qu ality of a mined top ic. Howe ver , coheren ce does not evaluate the relatio nship between dif- ferent mined topics; e.g., if the min ed F topics ar e identical, the co herence score can still be hig h but meaningless. T o alleviate this, we also use the similarity count ( Si mCoun t ) t hat was ado pted in [10] — for each topic, the s imilarity count is obtained si mply by adding up the overlapped word s of the topics within the leading N words, and a smaller Si mCoun t means the mined topics are mo re distinguishab le. When th e topics are very cor related (but different), the leading word s of the to pics may overlap with each other, and thus using SimC ount might still not be en ough to ev aluate the results. W e also inc lude clustering accu racy ( Clust Acc ), obtained by using th e mined C ⋆ matrix to estimate the weigh ts W of the docum ents, and ap plying k -means to W . Since th e gr ound -truth labels o f TD T2 and Reuters are known, clustering accuracy can be ca lculated, an d it serves a s a good indicator of topic mining results. T able 1 sh ows th e exper iment results on the T DT2 corpu s. From F = 3 to 25 , th e p roposed al- gorithm (Ancho rFree) gives very pro mising resu lts: for the three con sidered metrics, Anchor Free consistently gives b etter results comp ared to the baselin es. Particularly , the Cl ustAc c ’ s o btained by Anch orFree are at least 30% hig her compar ed to the baselines fo r all ca ses. In add ition, the single-topic qu ality o f th e top ics mine d b y An chorFree is the hig hest in terms of co herence score s; the overlaps between topics are the smallest except for F = 20 and 25 . T able 2 shows the results on th e Reuters-21578 c orpus. In this experiment, we can see that XRA Y is best in term s of sing le-topic qua lity , while Anch orFree is seco nd best wh en F > 6 . For Si mCoun t , 7 T able 1: Exp eriment results on the TDT2 corpus. Coh SimCount ClustAcc F FastAchor SP A SNP A XRA Y AnchorFree FastAchor SP A SNP A XRA Y AnchorFree FastAchor SP A SNP A XRA Y AnchorFree 3 -612.72 -613.43 -613.43 -597.16 -433.87 7.98 7.98 7.98 8.94 1.84 0.71 0.74 0.75 0.73 0.98 4 -648.20 -648.04 -648.04 -657.51 -430.07 10.60 11.18 11.18 13.70 2.88 0.70 0.69 0.69 0.69 0.94 5 -641.79 -643.91 -643.91 -665.20 -405.19 13.06 13.36 13.36 22.56 4.40 0.63 0.63 0.62 0.64 0.92 6 -654.18 -645.68 -645.68 -674.30 -432.96 18.94 18.10 18.10 31.56 7.18 0.65 0.58 0.59 0.60 0.91 7 -668.92 -665.55 -665.55 -664.38 -397.77 20.14 18.84 18.84 39.06 4.48 0.62 0.60 0.59 0.58 0.90 8 -681.35 -674.45 -674.45 -657.78 -450.63 24.82 25.14 25.14 40.30 9.12 0.57 0.56 0.58 0.57 0.87 9 -688.54 -671.81 -671.81 -690.39 -416.44 27.50 29.10 29.10 53.68 9.70 0.61 0.58 0.58 0.53 0.86 10 -732.39 -724.64 -724.64 -698.59 -421.25 31.08 29.86 29.86 53.16 13.02 0.59 0.55 0.54 0.49 0.85 15 -734.13 -730.19 -730.19 -773.17 -445.30 51.62 52.62 52.62 59.96 41.88 0.51 0.50 0.50 0.42 0.80 20 -756.90 -747.99 -747.99 -819.36 -461.64 66.26 65.00 65.00 82.92 79.60 0.47 0.47 0.47 0.38 0.77 25 -792.92 -792.29 -792.29 -876.28 -473.95 69.46 66.00 66.00 101.52 133.42 0.46 0.47 0.47 0.37 0.74 T able 2: Exp eriment results on the Reuters-21578 corpus. Coh SimCount ClustAc F FastAchor SP A SNP A XRA Y AnchorFree FastAchor SP A SNP A XRA Y AnchorFree FastAchor SP A SNP A XRA Y AnchorFree 3 -652.67 -647.28 -647.28 -574.72 -830.24 10.98 11.02 11.02 3.86 7.36 0.66 0.69 0.69 0.66 0.79 4 -633.69 -637.89 -637.89 -586.41 -741.35 16.74 16.92 16.92 9.92 1 2.66 0.51 0.61 0.61 0.60 0.73 5 -650.49 -652.53 -652.53 -581.73 -762.64 21.74 21.66 21.66 13.06 15.48 0.51 0.55 0.55 0.52 0.65 6 -654.74 -644.34 -644.34 -586.00 -705.60 39.9 39.54 39.54 27.42 1 9.98 0.47 0.49 0.50 0.46 0.64 7 -733.73 -732.01 -732.01 -612.97 -692.12 47.02 45.24 45.24 34.64 35.62 0.43 0.57 0.57 0.54 0.65 8 -735.23 -738.54 -738.54 -616.32 -726.37 85.04 83.86 83.86 82.52 62.02 0.40 0.53 0.54 0.47 0.61 9 -761.27 -755.46 -755.46 -640.36 -713.81 117.48 118.98 118.98 119.28 72.38 0.37 0.56 0.56 0.47 0.59 10 -764.18 -759.40 -759.40 -656.71 -709.48 119.54 121.74 121.74 130.82 86.02 0.35 0.52 0.52 0.42 0.59 15 -800.51 -801.17 -801.17 -585.18 -688.39 307.86 309.7 309.7 227.02 124.6 0.33 0.40 0.40 0.42 0.53 20 -859.48 -860.70 -860.70 -615.62 -683.64 539.58 538.54 538.54 502.82 225.6 0.31 0.36 0.36 0.38 0.52 25 -889.55 -890.16 -890.16 -633.75 -672.44 674.78 673 673 650.96 335.24 0.26 0.33 0.32 0.37 0.47 AnchorFr ee gives th e lowest values when F > 6 . In terms of clu stering ac curacy , the topics obtained by Anchor Free again lead to much higher clustering accuracies in all cases. In terms o f the r untime p erform ance, o ne c an see fro m Fig. 2(a) tha t FastAnchor, SNP A, XRA Y and Ancho rFree perfo rm similarly on the TDT2 dataset. SP A is the fastest algorithm since it has a recur si ve u pdate [6]. The SNP A and XRA Y bo th perfor m n onnegative l east squ ares-based defla- tion, which is co mputatio nally heavy when th e vocabulary size is large, as mentioned in Remark 1. AnchorFr ee uses A O and sma ll-scale linear programm ing, which is con ceptually more dif ficult com- pared to SNP A and XRA Y . Howev er, since the linear programs inv olved only hav e F variables and the numb er of A O iteration s is usually small (smaller than 5 in pr actice), the runtime per for- mance is q uite satisfactory and is close to tho se of SNP A and XRA Y wh ich a re g reedy algorithms. The ru ntime perform ance o n the Reuter s dataset is shown in Fig. 2 (b), where one can see that th e deflation-b ased m ethods are faster . The reason is that the vocab ulary size of the Reu ters corpus is much smaller compared to that of the TDT2 corpus (18,93 3 v .s. 36,77 1). T able 3 shows th e leading w ord s of the mined topics by F astAnchor and AnchorFr ee f rom an F = 5 case using the TDT2 co rpus. W e only p resent the resu lt of FastAnchor since it gives q ualitatively the b est ben chmark – the complete resu lt given by all b aselines can be f ound in the supplementar y material. W e see that the top ics given by AnchorFree show clear di versity: L ewinsk y scandal, Gen - eral Motors strike, Sp ace Sh uttle Colu mbia, 199 7 NBA fin als, and a scho ol shooting in Jon esboro, Arkansas. FastAnchor, on th e o ther ha nd, exhibit gr eat overlap on the first and the second mined topics. Lewinsky also shows up in the fif th topic mined by FastAnchor, which is mainly abo ut the 1997 NB A finals. This showcases th e clear advantage of our pro posed cr iterion in terms of giving more meaningfu l and interpretab le results, compa red to the anchor-word based approache s. 5 Conclusion In this p aper, we considered id entifiable an chor-free correlated topic m odeling. A to pic estimation criterion based o n th e word -word co-occurr ence/corr elation matr ix was prop osed and its id entifia- bility cond itions were proven. The pr oposed appro ach features topic identifiability gu arantee under much milder cond itions co mpared to the an chor-word assum ption, and thu s exhibits better ro bust- ness to model mismatch. A simple procedure t hat only in volves o ne eigen-decom position and a few small linear p rogram s was proposed to d eal with th e form ulated criterion . Exper iments on real text corpus data showcased the effecti veness of the prop osed approach. 8 5 10 15 20 25 F 10 0 10 1 10 2 10 3 Runtime (sec.) FastAnchor SPA SNPA XRAY AnchorFree (a) TDT2 5 10 15 20 25 F 10 0 10 1 10 2 10 3 Runtime (sec.) FastAnchor SPA SNPA XRAY AnchorFree (b) Reuters-21578 Figure 2: Runtim e performance of the algorithms under v ariou s setti ngs. T able 3: T wenty leadin g words of mined topics from an F = 5 case of the TDT2 experiment. FastAnchor AnchorFree anchor anchor predicts slipping cleansing strangled tenday allegations poll columbia gm bulls lewinsky gm shuttle bulls jonesboro lewinsk y cnnusa shuttle motors jazz monica motors space jazz arkansas clinton gallup space plants nba starr plants columbia nba school lady allegations crew workers utah grand flint astronauts chicago shooting white c linton astronauts michigan finals white workers nasa game boys hillary presidents nasa flint game jury mic higan crew utah teacher monica rating experiments strikes chicago house auto experiments finals students starr lewinsky mission auto jordan clinton plant rats jordan westside house president stories plant series counsel strik es mission malone middle husband approval fix strike malone intern gms nervous michael 11year dissipate starr repair gms michael independent strike brain series fire president white rats idled championship president union aboard championship girls intern monica unit production tonight in vestigation idled system karl mitchell affair house aboard walkouts lakers affair assembly weightlessness pippen shootings infidelity hurting brain north win lewinskys production earth basketball suspects grand slipping system union karl relationship north mice win funerals jury amer icans broken assembly lewinsk y sexual shut animals night children sexual public nervous talks games ken talks fish sixth killed justice se xual cleansing shut basketball former autoworkers neurological games 13year obstruction af fair dioxide striking night starrs walkouts sev en title johnson Acknowledgmen t This w ork is supported in part by th e National Science Foundation (NSF) under the pr oject numbers NSF-ECCS 160 8961 an d NSF IIS- 12476 32 and in part by the D igital T ec hnolog y Initiative (DT I) Seed Grant, University of Minnesota. Refer ences [1] D. M. Blei. Probabilistic topic models. Communica tions of the A CM , 55(4):7 7–84 , 201 2. [2] D. M. Blei, A. Y . Ng , and M. I. Jord an. Latent Dirichlet allo cation. Journal of Machine Learning Resear ch , 3:993–102 2, 20 03. [3] T . L. Gr iffiths and M. Ste yvers. Findin g scientific topics. Pr oceeding s of the Nation al Acad emy of Sciences , 101( suppl 1):5228 –5235 , 200 4. [4] S. Arora, R. Ge, R. Ka nnan, and A. Moitra. Compu ting a n onnegative matrix factor ization– provably . In ACM symposium on Theory of Computing , pages 145–162. A CM, 2012. [5] B. Recht, C. Re, J. T ropp, and V . Bittorf. Factoring nonnegative matrices with linear p rogra ms. In Pr oc. NIPS 2012 , pages 1214–12 22, 2012. [6] N. Gillis and S.A. V avasis . Fast and robust r ecursive algo rithms for separ able nonn egati ve matrix factorization. IEEE T rans. P attern Ana l. Mach. Intell. , 36(4):6 98–7 14, April 201 4. [7] N. Gillis. Robustness analysis of hottopixx , a linear p rogram ming model for f actorin g nonneg- ativ e matrices. SI AM J ournal on Matrix Analysis and Application s , 34(3):1189 –1212, 20 13. 9 [8] A. Kumar, V . Sindh wani, and P . Kamb adur . Fast conical h ull algorith ms f or near-separab le non-n egati ve matrix factoriz ation. In Pr oc. ICML-12 , 20 12. [9] S. Arora, R. Ge, and A. Moitra. Learnin g to pic models–g oing b eyond SVD. In Pr oc. FOCS 2012 , pages 1–10. IEEE, 2012. [10] S. Arora, R. Ge, Y . Halpern , D. Mimno, A. Moitra, D. Sontag, Y . W u, and M. Zhu. A practical algorithm for topic modeling with provable guarantees. I n Pr oc. ICML-13 , 2013. [11] N. G illis. Su ccessi ve n onnegative projection algorithm fo r r obust non negativ e blin d so urce separation. SI AM J ournal on Imaging Sciences , 7(2):1420 –145 0, 2014 . [12] D. Donoh o and V . Stod den. When does non -negativ e matrix factorization give a co rrect de- composition into parts? In Pr oc. NIPS 2013 , v olume 16, 2003 . [13] A. Anandk umar, Y .-K. Liu, D. J. Hsu, D. P . Foster , and S. M. Kakad e. A spectral algorithm for latent Dirichlet allocation. In Pr oc. NIPS 2012 , pages 917–9 25, 2012. [14] A. A nandku mar, S. M. K akade, D. P . Foster , Y .-K. Liu, and D. Hsu. T wo SVDs suffice: Sp ec- tral decom positions for probab ilistic topic modeling and late nt Dirichlet allo cation. T ech nical report, 2012 . [15] A. Anan dkuma r , D. J. Hsu, M. Janzamin, and S. M. Kakad e. When are overcomplete topic models iden tifiable? uniq ueness of tensor Tucker decomp ositions with stru ctured spar sity . In Pr oc. NIPS 2013 , pages 1986– 1994 , 201 3. [16] D. Cai, X. He, and J. Han. Lo cally consistent concep t factorization for docu ment clustering. IEEE T rans. Knowl. Data En g. , 23(6):9 02–9 13, 201 1. [17] K. Huang, N. Sidiro poulos, and A. Swami. Non-negative matrix factorization revisited: Uniquene ss and algor ithm for sym metric d ecompo sition. IEEE T r ans. Signal Pr ocess. , 62(1) :211–2 24, 201 4. [18] K. H uang, N. D. Sidirop oulos, E. E. Papalexakis, C. Faloutsos, P . P . T alukdar, and T . M. Mitchell. Principle d neuro- function al co nnectivity discovery . In Pr oc. SIAM Confer ence on Data Mining (SDM) , 2015 . [19] X. Fu, W .-K. M a, K. Huan g, and N. D. Sidiropo ulos. Blind separ ation of quasi-station ary sources: Exp loiting co n vex geometry in cov ariance domain . IEEE T r ans. Signa l Pr ocess. , 63(9) :2306– 2320, May 201 5. [20] W .-K. Ma, T .-H. Chan, C.-Y . Chi, and Y . W ang. Con vex analysis for non-negative b lind source separation with application in imaging . I n D. P . Palomar an d Y . Eldar, editors, Con vex Opti- mization in Signal Pr ocessing and Communications , chapter 7, pages 229–265 . 2010. [21] W ei Xu, Xin Liu, an d Y ihon g Gong. D ocumen t clu stering based o n non-negative matrix f actor- ization. In Pr oceeding s of th e 2 6th ann ual intern ational ACM SIGI R conference on Researc h and development in informaion r etrieval , pages 267 –273. A CM, 2003. 10 Supplementary Material A Proof of Proposition 1 Let us d enote a feasible solution of Prob lem (3) in the manuscript a s ( ˜ C , ˜ E ) , and let C ♮ and E ♮ stand for the gr ound -truth word-to pic PMF matrix and the topic co rrelation matrix, respecti vely . Note that we can represent any f easible solution as ˜ C = C ♮ A , ˜ E = A − 1 C ♮ A − 1 where A ∈ R F × F is an in vertible matrix. Giv en rank( P ) = F and that Assumptio n 1 holds, we must ha ve rank( ˜ C ) = rank( ˜ E ) = F , for any solution pair ( ˜ C , ˜ E ) . In fact, if the anch or-word assumptio n h olds, the n there is a nonsin- gular diagonal submatrix in C ♮ , so ra nk( C ♮ ) = F , and the same h olds f or ˜ C = C ♮ A since A is in vertible. By th e assump tion r a nk( P ) = F a nd the equ ality P = C ♮ E ♮ C T ♮ = ˜ C ˜ E ˜ C T , one can see that all the factors mu st h ave full column r ank. Theref ore, | det ˜ E | > 0 for any feasible ˜ E – a trivial solution cannot arise under the model considered . Furthermo re, ˜ C satisfies ˜ C T 1 = 1 and ˜ C ≥ 0 since ˜ C is a solution to Problem (3). Because the rows o f Diag( c ) all ap pear in the rows of C und er Assum ption 1, a matrix A satisfies ˜ C (Λ , :) = C (Λ , :) A ≥ 0 if and only if A ≥ 0 . Also note that A T C T 1 = 1 ⇒ A T 1 = 1 . Th en, we ha ve that | det A | ≤ F Y f =1 k A (: , f ) k 2 ≤ F Y f =1 k A (: , f ) k 1 = F Y f =1 A (: , f ) T 1 = 1 , (8) where the first bound ing step is the Hada mard in equality , the seco nd comes f rom elem entary prop- erties of vecto r no rms, and f or non-negative v ector s the ℓ 1 norm is simply the sum of all elements. The first ineq uality b ecomes equality if and o nly if A is a column-or thogon al matrix, and the second holds with equ ality if an d only if A (: , f ) fo r f = 1 , . . . , F are un it vectors. Therefo re, fo r non - negativ e matrices the equalities in (8) hold if and only if A is a permutation matrix. As a result, an y alternative solution ˜ E has the form that ˜ E = A − 1 E ♮ A − 1 , and we simply hav e that | det ˜ E | = | det A − 1 det E ♮ det A − 1 | = | det E || det A | − 2 ≥ | det E ♮ | , where equality holds if and only if A is a permutation matrix. This means that for o ptimal solutions that satisfy P = C ⋆ E ⋆ C T ⋆ , we ha ve C ⋆ = C ♮ Π a nd E ⋆ = Π T E ♮ Π , and achieve min imal v alue | det E ⋆ | , where Π is a perm utation matrix. Q.E.D . B Proof of Le mma 1 If C is sufficiently scattered, it satisfies cone( C T ) ∗ ⊆ K . (9) Suppose that C is r ank-d eficient. The n, all the vectors that lie in the n ull space of C satisfy C x = 0 , which implies that for x ∈ N ( C ) we have C x ≥ 0 . (10) Eq. (10) and Eq. (9) together imply that N ( C ) ⊆ K . Howe ver , a null space cannot be contained in a second-ord er cone, which is a contradiction . W e now show that any feasible solutio n pair ( ˜ E , ˜ C ) has full ran k. Den ote the gr ound -truth word - topic PMF ma trix as C ♮ , and the c orrelation matrix between to pics as E ♮ . Un der Assump tion 2, the g round -truth C ♮ has fu ll column ra nk, and th us E ♮ ∈ R F × F has fu ll ran k when ra nk( P ) = F . Now , since any other feasible solution can be written as C = C ♮ A , E = A − 1 E ♮ A − 1 , where A is in vertible, we h ave that any fea sible solutio n p air ( ˜ E , ˜ C ) has f ull r ank an d det ˜ E is b ound ed away from zero. Q.E.D . 11 C Proof of Theore m 1 Denote the g round truth word-top ic PMF matrix as C ♮ , an d the correlatio n m atrix between top ics as E ♮ . What we observe is their product P = C ♮ E ♮ C T ♮ , and we want to in fer, from the observation P , what th e matr ices C ♮ and E ♮ are. T he metho d propo sed in this paper is via solving (3), repeated here minimize E , C | det E | subject to P = C E C T C T 1 = 1 , C ≥ 0 . Now , d enote o ne optimal solu tion of the above as C ⋆ and E ⋆ , and Theorem 1 claims that if C ♮ is sufficiently scattered (cf. Assump tion 2), then there exists a permutatio n matrix Π such that C ⋆ = C ♮ Π , E ⋆ = Π T E ♮ Π . Because rank ( P ) = F , and b oth C ♮ and C ⋆ have F column s, th is means C ♮ and C ⋆ span the same column space, therefo re there exists a non-singular matrix A such that C ⋆ = C ♮ A , E ⋆ = A − 1 E ♮ A − T . In terms of problem ( 3), C ♮ and E ♮ are clearly feasible, wh ich yields an o bjective value det E ♮ . Since we assume ( C ⋆ , E ⋆ ) is an optimal solution of (3), we hav e that | det E ⋆ | = | det A − 1 det E ♮ det A − T | ≤ | det E ♮ | , implying | det A | ≥ 1 . (11) On the other hand, since C ⋆ is feasible for (3), we also have th at C ♮ A ≥ 0 , A T C T ♮ 1 = A T 1 = 1 . Geometrically , the inequality constraint C ♮ A ≥ 0 m eans that co lumns of A are contained in cone ( C T ♮ ) ∗ . W e assume C ♮ is sufficiently scattered, therefor e A (: , f ) ∈ co ne ( C T ♮ ) ∗ ⊆ K , or equiv alently k A (: , f ) k 2 ≤ 1 T A (: , f ) . Then for matrix A , we have that | det A | ≤ F Y f =1 k A (: , f ) k 2 ≤ F Y f =1 1 T A (: , f ) = 1 . (12) Combining (11) and (12), we conclu de that | det A | = 1 . Furthermo re, if (12) holds as an equality , we must have k A (: , f ) k 2 = 1 T A (: , f ) , ∀ f = 1 , ..., F , which, geometrically , mean s that t he columns of A all lie on the boundary o f K . Howe ver , since C ♮ is sufficiently scattered, cone ( C T ♮ ) ∗ ∩ bd K = { λ e f : λ ≥ 0 , f = 1 , ..., F } , so A (: , f ) b eing contained in cone ( C T ♮ ) ∗ then implies that c olumns of A can on ly be selected from the columns of the identity matrix I . T oge ther with the f act tha t A shou ld be non-singular, we have that A c an only be a permutation matrix. Q.E.D . 12 D Synthetic Experiments In this section we giv e simulation results showing the word-topic PMF ma trix C an d to pic co rrela- tion matrix E can ind eed be e xactly recovered e ven in the absence of anchor w ords, using synthetic data. For a gi ven v ocabulary size V = 1 0 00 and number of top ics F increasing from 5 to 30, groun d truth matrices C ♮ and E ♮ are synthetically generated : th e entries of C ♮ are first drawn from an i.i.d. exponential distribution, an d then appro ximately 50% of the entries are ran domly set to z ero, ac- cording to an i.i.d. Berno ulli distribution; matrix E ♮ is obtained from R T R /F , where entries of the F × F matrix R are dr awn fro m an i.i.d. Gaussian distribution. I n th is way , C ♮ is su fficiently scattered with very h igh p robability , but is very un likely to satisfy th e separability / ancho r-word assumption. Using the synth etically gen erated C ♮ and E ♮ , we set the w ord co-occurr ence m atrix P = C ♮ E ♮ C T ♮ , and app ly various topic modeling algo rithms on P to try to recover C ♮ and E ♮ , including our propo sed An chorFree described in Algor ithm 2. Denotin g th e outp ut of any algo rithm as C ⋆ and E ⋆ , bef ore we comp are them with the gro und tr uth C ♮ and E ♮ , we n eed to fix the permu tation ambiguity . This task can be formulated as the following optimization problem minimize Π k C ⋆ − C ♮ Π k 2 F subject to Π is a permu tation matrix which is equ iv alent to the linear assign ment pro blem, an d ca n be solved efficiently v ia th e Hun- garian algorithm . A fter optim ally ma tching the column s of C ⋆ and C ♮ , the estimation errors k C ⋆ − C ♮ k 2 F and k E ⋆ − E ♮ k 2 F giv en by different m ethods are shown in T ab le 4 and 5, where each estimation error is av erag ed o ver 10 Monte-Carlo trials. Based on the results shown in T able 4 and 5, sev eral comments are in order: 1. Th e ancho r-w ord -based algor ithms a re n ot able to recover the grou nd-tru th C ♮ and E ♮ , since the separability / anchor-word assumption is grossly violated; 2. Anc horFree, on the other hand, recovers C ♮ and E ♮ almost perfectly in all the cases under test, which supports our claim in Theorem 1; 3. Even thou gh the iden tification criterion (3 ) is a n on-convex optimization p roblem, the pro - posed procedu re e mpirically a lways works, wh ich is o bviously en courag ing and deserves future study . T able 4: Estimation err or k C ⋆ − C ♮ k 2 F on synthetic data. F FastAnchor SP A SNP A XR A Y Anc horFree 5 0.0284 0.028 4 0 .015 9 0.0 800 5.83e- 20 10 0.19 84 0 .1984 0.3746 0.0284 4. 35e-16 15 0.63 17 0 .5356 0.7454 0.0509 8. 44e-10 20 0.26 10 0 .2261 0.1776 0.0698 1. 00e-09 25 0.21 85 0 .2235 0.1758 0.1228 6. 67e-15 30 0.29 99 0 .2769 0.2927 0.1471 2. 65e-15 T able 5: Estimation err or k E ⋆ − E ♮ k 2 F on synthetic data. F FastAnchor SP A SNP A XRA Y Anchor Free 5 2.08e 10 2 .08e10 1.00e10 8.79 1 .33e-1 6 10 7.73 e5 1.75 e7 1.75 e7 13.4 6 1.0 4e-12 15 1.90 e6 2.86 e6 3.39 e6 34.1 7 1.9 1e-06 20 1.92 e5 6.44 e5 2.37 e5 30.1 7 9.4 6e-07 25 7.97 e4 1.09 e4 2.15 e4 40.2 5 1.3 4e-11 30 1.03 e5 1.03 e4 1.12 e4 67.5 4 5.8 0e-12 13 E Complete Results of the Illustrative E xample The complete results of the illustrati ve example in th e manuscript are presented in T ables 6-10. On e observation is that FastAnchor, SP A and SNP A gi ve th e same anchor words and topics with dif ferent orders. XRA Y gives different anchor w ord s and topics, b ut th e topics mined are qualitatively w orse compare d to tho se of FastAnchor , SP A an d SNP A. The pr oposed Anch orFree alg orithm y ields five clean topics. T able 6: TDT2; F = 5 . AnchorFree anchor lewinsk y gm shuttle bulls jonesboro monica motors space jazz arkansas starr plants columbia nb a school grand fl int astronauts chicago shooting white workers nasa game boys jury michigan crew utah teacher house auto experiments finals students clinton plant rats jordan westside counsel strikes m ission malone middle intern gms nerv ous mi chael 1 1year independent strike brain series fire president union aboard championship girls in vestigation idled system karl mitchell aff air assembly wei ghtlessness pippen shootings lewinsk ys production earth basketball suspects relationship north mice win funerals sexual sh ut animals night children ken t alks fish sixth killed former autow orkers ne urological games 13year starrs walko uts sev en title johnson T able 7: TDT2; F = 5 . FastAnchor anchor predicts slipping cleansing strangled tenday allegations poll columbia gm bulls lewinsk y cnnusa shuttle motors jazz clinton gallup space plants nba lady allegations crew workers utah white clinton astronauts mi chigan finals hillary presidents nasa flint game monica rating experiments strikes chicago starr le winsky mission auto jordan house president stories plant series husband approv al fix strike malone dissipate starr repair gms michael president white rats idled championsh ip intern monica unit pro duction tonight aff air house a board walk outs lakers infidelity hurting brain north win grand slipping system union karl jury americans broken assembly le winsky sexual public nervous talk s games justice sexual cleansing shut basketball obstruction affair dioxide striking nigh t 14 T able 8: TDT2; F = 5 . XRA Y anchor strangled topping dioxide repriev e i ndicting gm lewinsk y shuttle lewinsky lewinsk y motors monica columbia grand starr plants white space jury mon ica work ers starr astronauts monica counsel michigan house nasa starr grand flint grand crew white jury strikes intern dioxide house indepen dent auto jury expe riments counsel ken plant clinton mission clinton white strike affair carbo n whitew ater inv estigation gms counsel aboard ind ependent house idled former rats lewinsk ys clinton production independent system inv estigation intern walko uts lie brain president starrs north p resident nerv ous i ntern stories union lewinsk ys earth k en president assembly r elationship shut relati onship lewinskys talks alleg ations weightlessness testimony checking shut ken unit testify former striking sexual mice starrs af fair T able 9: TDT2; F = 5 . SNP A anchor predicts slipping cleansing strangled tenday allegations oll columbia gm bu lls lewinsk y cnnusa shuttle motors jazz clinton gallup space plants nba lady allegations crew workers utah white clinton astronauts mi chigan finals hillary presidents nasa flint game monica rating experiments strikes chicago starr le winsky mission auto jordan house president stories plant series husband approv al fix strike malone dissipate starr repair gms michael president white rats idled championsh ip intern monica unit pro duction tonight aff air house a board walk outs lakers infidelity hurting brain north win grand slipping system union karl jury americans broken assembly le winsky sexual public nervous talk s games justice sexual cleansing shut basketball obstruction affair dioxide striking nigh t T able 10: TDT2 ; F = 5 . SP A anchor slipping predicts tenday cleansing strangled poll allegations bulls co lumbia gm cnnusa lewinsky jazz shuttle motors gallup clinton nba space plan ts allegations lady utah crew workers clinton white finals astronauts michigan presidents hil lary game nasa flint rating monica chicago e xperiments strikes lewinsk y starr jordan mission auto president hous e series stories plant approv al husband malone fix strike starr dissipate michael repair gms white president championship rats idled monica intern tonight unit produc tion house affair lakers aboard walkouts hurting infidelity win brain north slipping grand karl system u nion americans jury lewinsky broke n assemb ly public sexual games nervous talks sexual justice bask etball cleansing shut aff air obstruction night dioxide striking 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment