대규모 베이지안 추론으로 보는 가시 우주 천체 카탈로그 학습
Celeste는 베이지안 변분 추론을 이용해 천체 이미지에서 별·은하 카탈로그를 생성하는 시스템이다. 본 논문은 기존 단일 스레드 구현을 확장해, 뉴턴‑신뢰구역 최적화와 이미지‑광원 분할 전략을 도입하고, Julia 기반의 공유·분산 메모리 병렬화를 적용해 NERSC Cori 슈퍼컴퓨터의 8192 코어까지 확장한 결과를 제시한다.
저자: Jeffrey Regier, Kiran Pamnany, Ryan Giordano
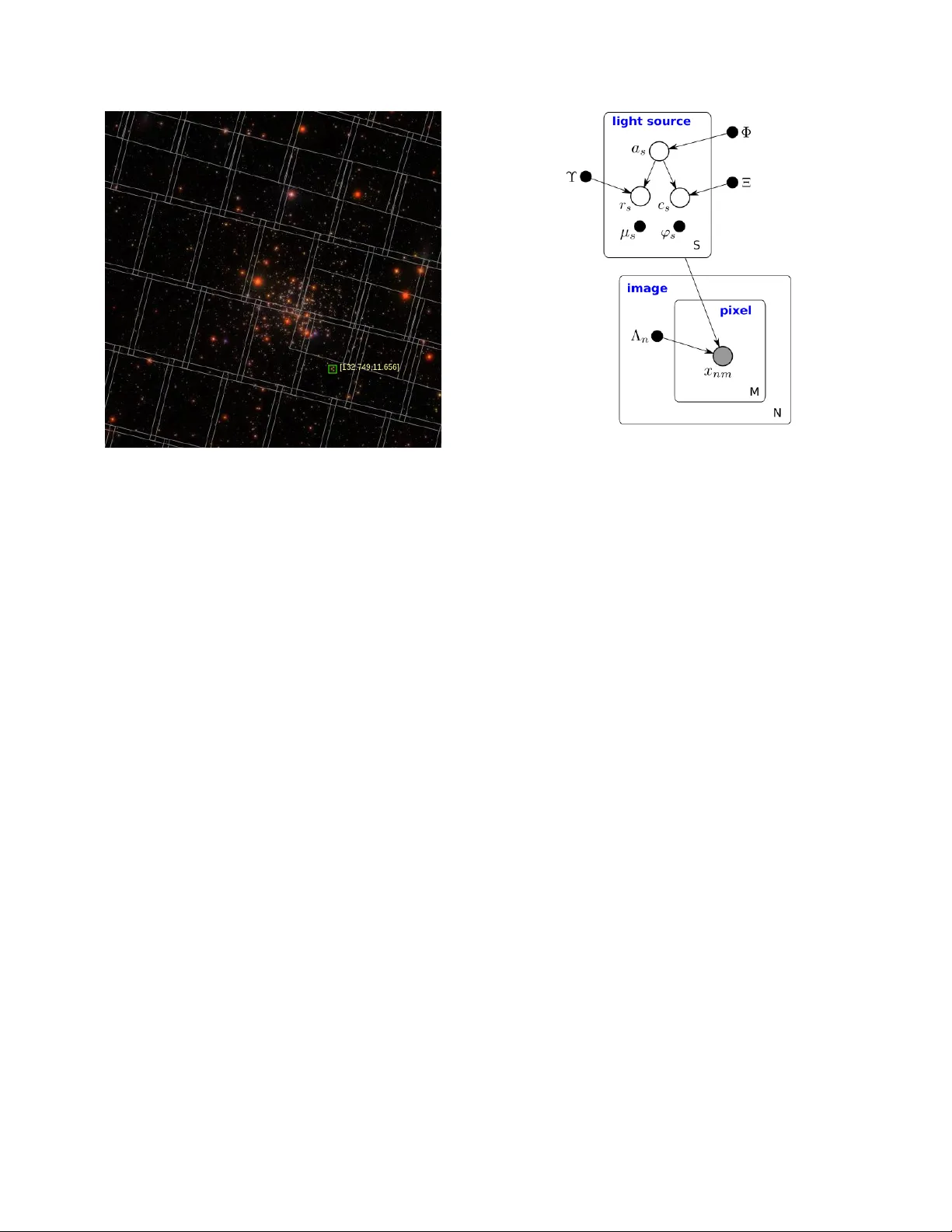
본 논문은 천문학 이미지에서 별·은하와 같은 천체를 자동으로 식별하고 특성을 추정하는 카탈로그 생성 시스템인 Celeste의 확장 버전을 제시한다. 기존 Celeste는 단일 스레드 환경에서 변분 베이지안 추론을 이용해 수백 메가바이트 규모의 이미지에 적용되었으며, 후방분포 근사를 위해 L‑BFGS 최적화를 사용했다. 그러나 현대 대형 서베이(예: LSST)는 매일 수십 테라바이트의 데이터를 생성하므로, 기존 구현은 확장성에 한계가 있었다.
논문은 다음과 같은 주요 기여를 한다. 첫째, 변분 목표함수 L을 최적화하기 위해 신뢰구역을 포함한 뉴턴 방법을 도입하고, 그래디언트와 조밀한 헤시안을 수작업으로 계산해 연산 효율을 크게 높였다. 이 방법은 대부분의 광원에 대해 50회 이내의 반복으로 수렴하며, L‑BFGS 대비 수십 배 빠른 속도를 제공한다. 둘째, 작업 분할 전략을 재설계했다. 이미지 자체는 수십 메가바이트 크기의 파일 다섯 개로 구성되며, 하나의 이미지에 약 500개의 광원이 포함된다. 광원별 최적화 작업을 동적으로 스케줄링하면서, 이미지 데이터를 전역 배열에 미리 적재해 모든 프로세스가 공유하도록 함으로써 중복 I/O를 최소화했다. 또한, 공간적으로 인접한 광원들을 같은 배치에 묶어 스케줄링함으로써 동일 이미지에 대한 접근 빈도를 낮추었다. 셋째, 구현 언어로 Julia를 선택했다. Julia는 고수준 문법과 저수준 성능을 동시에 제공하며, Distributed와 SharedArray를 이용해 공유·분산 메모리 병렬을 손쉽게 구현할 수 있다. 이를 통해 NERSC Cori 슈퍼컴퓨터의 8192 Xeon 코어까지 확장했으며, 실험 결과 거의 선형에 가까운 스케일링 효율을 보였다.
Celeste 모델 자체는 베이지안 생성 모델로, 픽셀 강도는 포아송 분포를 따르고, 광원의 밝기·색상·형상은 로그정규·다변량 정규·베르누이 등 사전분포를 가진다. 변분 근사는 각 광원에 대해 독립적인 q 분포(로그정규, 다변량 정규, 베르누이)로 구성되며, 전체 목적함수는 광원 간 겹침으로 인해 여전히 상호 의존성을 가진다. 이를 해결하기 위해 주변 광원의 현재 추정값을 고정하고, 개별 광원 파라미터만 최적화하는 부분 최적화 방식을 채택했다. 이는 전체 로그우도 하한을 유지하면서 계산량을 크게 줄인다.
실험에서는 SDSS 데이터셋을 사용해 수억 개의 광원을 처리했으며, 각 광원당 최적화 시간은 1초에서 2분 사이였지만 대부분 5초 이하로 완료되었다. 동적 스케줄링과 이미지 공유 메모리 덕분에 I/O 병목을 회피하고, 작업 부하의 불균형도 효과적으로 완화했다. 결과적으로, 기존 휴리스틱 파이프라인인 Photo와 비교해 더 정확한 파라미터 추정과 정량적인 불확실성 정보를 제공한다.
논문의 결론은 베이지안 변분 추론과 고성능 병렬 컴퓨팅을 결합하면, 대규모 천문학 데이터에서도 과학적으로 신뢰할 수 있는 카탈로그를 자동으로 생성할 수 있다는 점이다. 향후 연구 과제로는 변분 근사의 분산 과소추정 보정, 더 큰 데이터셋(Large Synoptic Survey Telescope) 적용, 그리고 GPU 가속을 통한 추가 성능 향상이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기