Learning an Astronomical Catalog of the Visible Universe through Scalable Bayesian Inference
Celeste is a procedure for inferring astronomical catalogs that attains state-of-the-art scientific results. To date, Celeste has been scaled to at most hundreds of megabytes of astronomical images: Bayesian posterior inference is notoriously demandi…
Authors: Jeffrey Regier, Kiran Pamnany, Ryan Giordano
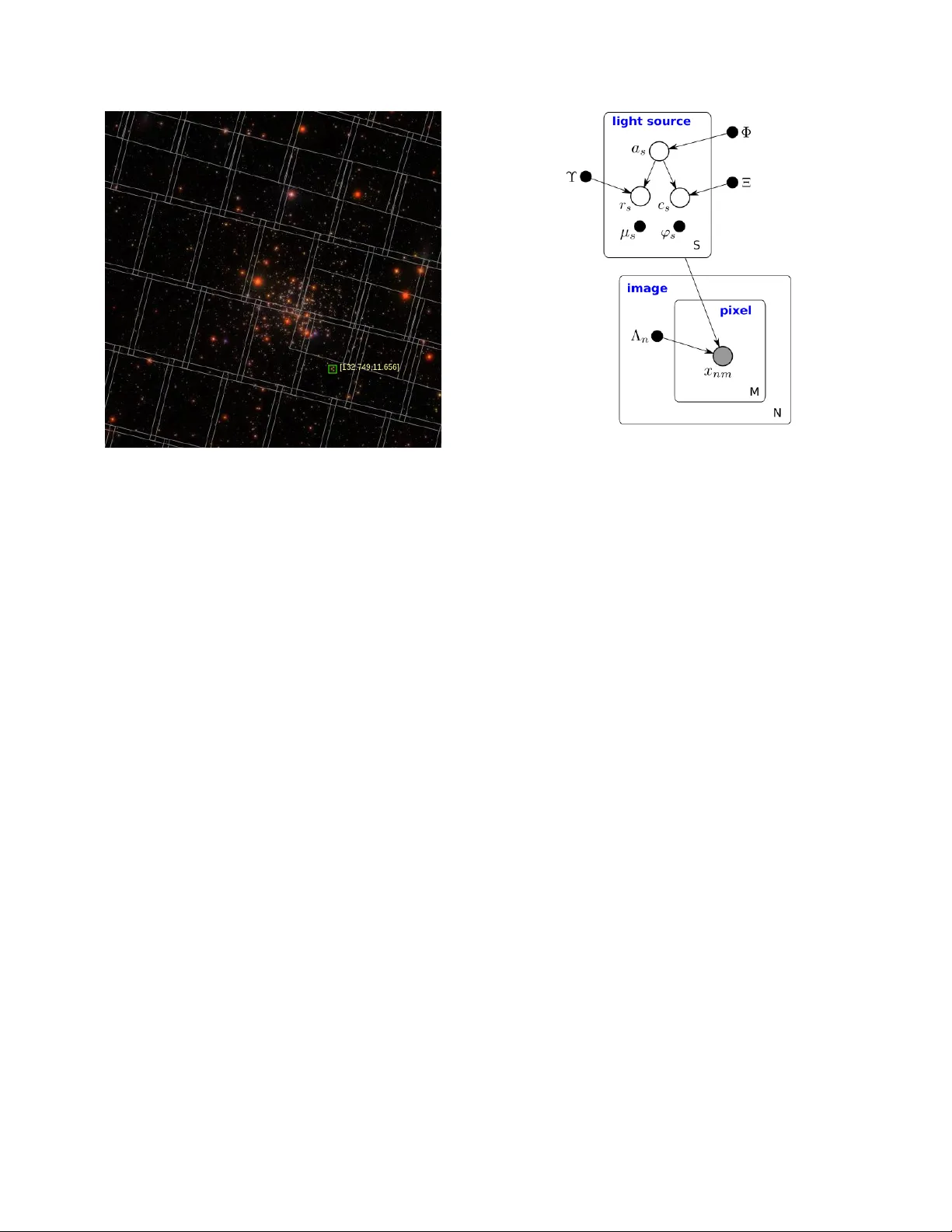
Learning an Astr onomical Catalog of the V isible Univ erse through Scalable Bayesian Infer ence Jeffre y Regier ∗ , Kiran P amnany † , Ryan Giordano ‡ , Rollin Thomas ¶ , Da vid Schlegel § , Jon McAulif fe ‡ and Prabhat ¶ ∗ Department of Electrical Engineering and Computer Science, University of California, Berkele y † P arallel Computing Lab, Intel Corporation ‡ Department of Statistics, University of California, Berkele y § Physics Division, Lawrence Berkele y National Laboratory ¶ NERSC, Lawrence Berkele y National Laboratory Abstract —Celeste is a procedure for inferring astronomical catalogs that attains state-of-the-art scientific results. T o date, Celeste has been scaled to at most hundreds of megabytes of astronomical images: Bayesian posterior infer ence is noto- riously demanding computationally . In this paper , we report on a scalable, parallel version of Celeste, suitable for lear ning catalogs from modern large-scale astronomical datasets. Our algorithmic innovations include a fast numerical optimization routine for Bayesian posterior inference and a statistically efficient scheme for decomposing astronomical optimization problems into subproblems. Our scalable implementation is written entir ely in Julia, a new high-level dynamic programming language designed for scientific and numerical computing . W e use Julia’ s high-lev el constructs for shared and distributed memory parallelism, and demonstrate effective load balancing and efficient scaling on up to 8192 Xeon cores on the NERSC Cori supercomputer . Keyw ords -Astronomy , Bay esian, V ariational Inference, Julia, Big Data Analytics, High Performance Computing I . I N T RO D U C T I O N The principal product of an astronomical imaging surve y is a catalog of celestial objects, such as stars and galaxies. These catalogs are generated by identifying light sources in surve y images and characterizing each according to physical parameters such as brightness, color, and mor- phology . Astronomical catalogs are the starting point for many scientific analyses, such as theoretical modeling of individual light sources, modeling groups of similar light sources, or modeling the spatial distribution of galaxies. Catalogs also inform the design and operation of subsequent surve ys using more advanced or specialized instrumentation (e.g., spectrographs). Astronomical catalogs are key tools for studying the life-cycles of stars and galaxies as well as the origin and ev olution of the Univ erse itself. Modern astronomical surveys produce vast amounts of complex data. The Large Synoptic Survey T elescope (LSST) is slated to capture more than 15 terabytes of ne w images on a daily basis [1]; ov erall the instrument will produce 10s– 100s of PBs over the lifetime of the project. Constructing a catalog is computationally demanding for any method because of the scale of the data. Approaches to date are largely based on computationally efficient heuristics [2], [3]. Constructing a high-quality catalog based on a rigor- ous statistical treatment of the problem is computationally challenging even for datasets of modest size. Bayesian posterior inference is effecti ve for learning as- tronomical catalogs because Bayesian models can combine prior knowledge of astrophysics with new data from surveys in a statistically efficient manner . Bayesian inference also yields accurate estimates of uncertainty . Because most light sources will be near the detection limit, uncertainty estimates are as important as the parameter estimates themselves for many analyses. For example, they enable robust population- lev el analysis ev en when every individual light source is highly ambiguous [4]. Celeste [5] is a procedure for inferring an astronomical catalog from a collection of images, based on a principled statistical model, that attains state-of-the-art results. While exact posterior inference is computationally intractable, the approximation proposed in [5] is nearly linear time in all relev ant quantities: the number of light sources, the number of pixels, and the number of parameters. Nonetheless, it is a computationally expensi ve procedure, ne ver before scaled beyond sev eral hundreds of MBs of imaging data. The procedure described in [5] is single-threaded. In this paper , we present a new , parallel version of Celeste that enables scaling the procedure to large datasets on large clusters. Our contributions include: • A fast numerical optimization routine for Bayesian posterior inference. • A statistically efficient scheme for decomposing astro- nomical optimization problems into sub-problems. • A demonstration of the viability of using the high-level Julia programming language to implement a comple x, real-world data analytics application on a contemporary HPC platform. • Dev elopment and optimization of a Julia package to enable multi-node distributed memory parallelism. 1 I I . R E L A T E D W O R K T o date, astronomical catalogs ha ve been constructed primarily by heuristics—algorithms that may be intuitiv ely reasonable, but that do not follow from a statistical model of the data. For the dataset we analyze in this work, discussed in Section IV, the state-of-the-art software pipeline is a heuristic called “Photo” [3]. Heuristics have a number of shortcomings. First, they typically cannot make effecti ve use of prior information, because it is unclear how to “weight” it in relation to new information from the survey . Y et much is kno wn about stars’ and galaxies’ colors, brightness, and shapes before new data is collected—both from previous surve ys and from astrophysical theory . Second, heuristics do not effecti vely combine knowledge from multiple image surveys, or even from multiple overlap- ping images from the same surve y . They may “co-add” the ov erlapping images, but this effecti vely discards properties unique to each image, like the atmospheric conditions at the time of exposure, or the exact alignment of the pixels. Third, heuristics do not correctly quantify uncertainty of their estimates. They may flag some estimates as particularly unreliable. But confidence intervals follo w only from a statistical model. Without modeling the arriv al of photons as a Poisson process, for example, there is little basis for reasoning about uncertainty in the underlying brightness of objects. These shortcomings are addressed by the Bayesian for- malism. Unknown quantities, such as the catalog entries for our problem, are modeled as unobserved random variables with prior distributions. Then the posterior distribution, that is, the conditional distribution of the latent v ariables gi ven the data, encapsulates kno wledge about the latent variables. Unfortunately , exact Bayesian posterior inference is com- putationally intractable for all but the simplest statistical models. In T ractor [6], rather than inferring the posterior , the mode of the posterior is learned through maximum a poste- rior (MAP) estimation. Though MAP estimation is scalable, and retains many of the adv antages of Bayesian modeling, it does not provide uncertainties, as one would obtain from posterior inference. Approximate posterior inference is an alternati ve to MAP estimation and an alternativ e to heuristics. Marko v Chain Monte Carlo (MCMC) is the most common approach to approximate posterior inference. At each iteration, MCMC draws a sample from an approximation to the posterior distribution. Unfortunately , consecuti ve samples are not in- dependent. MCMC can require tens of thousands of samples to approximate the posterior . Thus, to date MCMC has only been used to infer properties of small collections of stellar and galactic images relativ e to the sizes of modern astronomical datasets [7]. Moreo ver , e ven gi ven tens of thou- sands of MCMC samples, it is generally unknown whether enough samples have been collected to adequately represent the posterior —the number of samples needed could, for example, gro w exponentially in some dimension of the model. V ariational inference (VI) is an alternati ve to MCMC that uses numerical optimization to find a distribution that approximates the posterior without sampling [8]. In prac- tice, the resulting optimization problem is often orders of magnitude faster to solve compared to MCMC approaches. Scaling VI to large astronomical datasets is nonetheless challenging. The largest published applications of VI ha ve been to text mining, where topic models are fit to sev eral gigabytes of text [9]. The SDSS dataset is four orders of magnitude larger than that. Moreover , most models learned by v ariational inference to date hav e a form that allo ws optimization by coordinate ascent, where each update can be computed without explicitly forming gradients. The Celeste model does not have this property . Our new scalable version of Celeste instead bases its optimization on a variant of Newton’ s method, with manually computed gradients and Hessians—a considerably more in volved undertaking. Furthermore, the datasets for topic modeling, and for many machine learning tasks, are modeled as N condi- tionally independent observations giv en a modest number of global parameters. Astronomical images, on the other hand, overlap. Light sources are often imaged many times: Figure 1 shows image boundaries for SDSS data. Images hav e substantial overlap, and even non-overlapping parts of different images receive light from a single light source. The Celeste statistical model accounts for all of these unique characteristics. I I I . C E L E S T E Celeste approximates the posterior distribution using a variational inference procedure that facilitates parallel pro- cessing. The Celeste model and the variational objective function are described in earlier work about a single- threaded version of Celeste [5]. Our approach to optimizing the objective function, based on a trust-region Newton’ s method, is new , as is the approach to parallelism. A. The Celeste Model A generativ e Bayesian model is a joint probability distri- bution over observed random variables (the pixel intensities) and unobserved, or latent, random variables (the catalog entries). The Celeste model is represented graphically in Figure 2. Images: Each of N images has fixed metadata Λ n , describing its sky location and the atmospheric conditions at the time of the exposure. Each image contains M pix- els. Each pixel intensity is an observed random variable, denoted x nm , that follows a Poisson distribution with a rate parameter F nm unique to that pixel. F nm is a deterministic function of the catalog (which includes random quantities) 2 Figure 1: SDSS image boundaries. Some images overlap substantially . Some light sources appear in multiple images that do not ov erlap. Celeste uses all rele vant data to lo- cate and characterize each light source whereas heuristics typically ignore all but one image in regions with overlap. credit: SDSS DR10 Sky Navigate T ool. and the image metadata. It follows that pixel intensities are conditionally independent given the catalog. Light sources: For each of S light sources, a Bernoulli random variable a s indicates whether it is a star or a galaxy; a lognormal random variable r s denotes its brightness in a particular band of emissions (the “reference band”); and a multiv ariate normal random vector represents its colors— defined formally as the log ratio of brightnesses in adjacent bands, b ut corresponding to the colloquial definition of color . These random quantities hav e prior distrib utions with param- eters Φ , Υ , and Ξ , respecti vely . These parameters are learned from pre-e xisting astronomical catalogs. Additionally , each light source is characterized by (non-random) vectors µ s and ϕ s . The former indicates the light source’ s location and the latter , if the light source is a galaxy , represents its shape, scale, and morphology . Though non-random, these vectors are nonetheless learned within our inference procedure. It is straightforward to sample collections of “synthetic” astronomical images from the Celeste model, given the preceding description. Indeed, we do generate data in this way for testing purposes. Our primary use for the model, howe ver , is to compute the distribution of its unobserved random v ariables conditional on a particular collection of (real) astronomical images. This distribution is known as the posterior . Exact posterior inference is computationally intractable for the Celeste model, as it is for most non-trivial Bayesian models. Instead, we use variational inference to Figure 2: The Celeste graphical model. Shaded vertices represent observed random variables. Empty vertices repre- sent latent random variables. Black dots represent constants. Constants denoted by uppercase Greek characters are fixed throughout our procedure. Constants denoted by lowercase Greek letters are inferred, along with the posterior distribu- tion of the latent random variables. Edges signify permitted conditional dependencies. Plates (the boxes) represent inde- pendent replication. approximate the posterior . B. V ariational Infer ence Let x := { x nm } N ,M n =1 ,m =1 denote all pixels. Let z := { a s , r s , c s } S s =1 denote all the latent random variables. The posterior distribution on z , i.e. p ( z | x ) , combines our prior knowledge with the new information contained in the data. V ariational inference (VI) chooses a distribution q from a class of candidates to approximate the posterior p ( z | x ) by maximizing the following lo wer bound on the log probability of the data [8]: log p ( x 11 , . . . , x N M ) ≥ E q [log p ( x, z ) − log q ( z )] (1) =: L ( θ ) . (2) This lower bound holds for every q , which follows from Jensen’ s inequality . W e take the density q to factorize across light sources and across each light source’ s latent variables: q ( z ) = S Y s =1 q ( r s | a s ) q ( c s | a s ) q ( a s ) . (3) In our formulation, each factor of q is an exponential family that is conjugate to the corresponding prior distribution: q ( r s | a s ) is univ ariate lognormal, q ( c s | a s ) is multiv ariate normal, and q ( a s ) is Bernoulli. 3 W e index the class of candidate q ’ s by the real-valued vector θ . Then, maximizing ov er q is equiv alent to maxi- mizing ov er θ . It can be shown that the maximizer of L also minimizes D KL ( q ( z ) , p ( z | x )) , (4) the Kullback-Leibler diver gence to the posterior [8]. The objectiv e function L may also be maximized over the model parameters { µ s , ϕ s } S s =1 , simultaneously , to estimate them. The posterior distribution typically will not hav e the form of the candidate variational distrib utions, so the min- imum Kullback-Leibler diver gence will not be zero, and the posterior distribution will not be recovered exactly . For classes of variational distributions that factorize, such as ours, the variational distribution that minimizes Kullback- Leibler diver gence tends to underestimate the posterior’ s variance. T echniques exist to correct this bias [10]. Though q factorizes across the light sources, the light sources are still coupled in L by p ( x, z ) : pixels may receiv e photons from multiple light sources. The parameter vector θ contains 32 entries per light source, for each of hundreds of millions of light sources. T o simplify optimization, rather than maximizing L with respect to all of θ jointly , we optimize subsets of θ corre- sponding to the parameters for distinct light sources indepen- dently , while holding the parameters for other light sources fixed at estimates from previous astronomical surv eys. For light sources that do not o verlap with any other light sources, the optimal point returned by this technique is no different than had we optimized θ jointly across all light sources. For light sources that do overlap with others, we anticipate that existing estimates of neighboring light sources will be sufficiently accurate. Regardless, max θ L is a lower bound on the log probability of the data. Our alternative optimization procedure may find a looser lower bound, but with significant computational savings from decoupling optimization of the light sources. In [5], we used L-BFGS [11] to optimize L . Howe ver , some light sources require thousands of L-BFGS iterations to con verge. These light sources dominate runtime. The approach based on L-BFGS is too inefficient for large-scale optimization. For our scalable version of Celeste, we use Ne wton’ s method, with updates constrained by a trust region, to optimize L for each source. Newton’ s method consistently reaches machine tolerance within 50 iterations for our op- timization problems. Furthermore, to maximize efficiency , rather than using automatic differentiation, we manually compute the gradient and the (dense) Hessian for each light source. C. P arallel W ork Decomposition T o find the optimal parameters for a light source, Celeste must load the following: (a) all the images containing that light source, (b) an initial estimate of its parameters, and (c) initial estimates of any nearby light source that may overlap with it. Image data is at least an order of magnitude larger than the initial parameter estimates. An image is stored as a collection of five files that are roughly 60 MB in aggregate. Approximately 500 light sources appear in each image. W e aim to limit the I/O cost associated with loading images repeatedly . On a fast, modern processor , Celeste finds the optimal parameters for a light source in anywhere from one second to over two minutes, with most sources taking less than fiv e seconds. Because the work is irregular , we use dynamic scheduling to balance load. These two aims present a challenge. W e must limit I/O— multiple processes loading the same image repeatedly , once for each light source in in it, would lead to a severe I/O bottleneck. Y et we cannot distribute work at the image lev el, as that could lead to load imbalance on the order of minutes. W e considered two work decomposition strategies. The first strategy partitions the sky into equal-size contiguous regions smaller than an image. Each region corresponds to a task. If an image contains R such regions, then at most R nodes must load the same image, limiting the I/O burden. Howe ver , our experiments with this approach still showed high load imbalance. Although cosmological theory predicts a certain type of uniformity of light sources across the Uni verse, in practice we find that some re gions of the sky hav e many sources while other regions hav e few to none. For our second strategy , candidate light sources corre- spond to tasks. Giv en an existing catalog of light sources, we dynamically schedule batches of light sources to nodes for optimization. Since each image typically contains many light sources, this second strategy could potentially require the same image to be loaded many times by different processes. W e use two techniques to reduce the I/O burden: first, we load all images from disk into the memory of all the participating processes, using a global array implementation, thus con verting a slow , disk-bound operation into a much faster one-sided RMA operation on a high-performance in- terconnect fabric. Second, we use a task scheduling scheme that distributes tasks in spatially aware batches, thereby reducing the frequency of multiple processes requiring the same image data. W e implement the second strategy for our experiments. D. Implementation The current implementation proceeds in three phases: 1. Load images: All required images are loaded into a global array . Each process loads images concurrently , using only a single thread since this stage is I/O bound. 2. Load catalog: An existing catalog of candidate light sources is loaded into a second global array . Each entry includes initial estimates of the suspected light sources’ 4 parameters (recall that these initial estimates are used for rendering neighboring light sources during optimization). The candidate light sources are ordered according to their spatial position, thus nearby light sources are also close together in the global array . This ordering reduces commu- nication but is not necessary for correctness. 3. Optimize sour ces: Each entry in the catalog global array is a task. W e use the Dtree scheduler [12] to distribute batches of contiguous indices into the catalog global array , to processes. The batches are small to help balance load. A process uses multiple threads to optimize the light source in the region it is assigned. These threads share a process-lev el cache of images and catalog entries. Each thread retriev es the next index from the batch assigned to the process, fetches that entry from the catalog global array , and then checks the cache for the necessary images and neighbor catalog entries, fetching them from the global arrays as needed. E. Language considerations Celeste is implemented entirely in Julia, a high level dynamic programming language. Julia offers many desir- able features for scientists and engineers—familiar syntax, interactiv e dev elopment, a high level of abstraction, garbage collection, dynamic types, and excellent integrated open- source libraries for many areas, including linear algebra and signal processing. Julia’ s compiler is based on LL VM. It uses type inference, JIT compilation, vectorization, and inlining to achie ve excellent performance, competitive with statically-typed languages such as C/C++. This combination of features—expressi veness and ease of use, together with high performance—makes Julia a compelling choice for scientific and numerical computing. While still at an early stage with version 0 . 5 (as of October 2016), the Julia language is maturing rapidly . As such, using Julia presents advantages as well as challenges, particularly relating to parallelism. W e discuss these challenges in Sec- tion VIII. F . Multi-pr ocess scaling Julia offers distributed parallelism capabilities in its base libraries. This functionality is built around remote procedure calls (RPC), an abstraction that has limited application to HPC applications, which tend to be mostly data parallel, and have stringent latency and bandwidth needs. Julia applications can directly use MPI via a wrapper package. Howe ver , MPI does not offer high-level abstrac- tions that are easy to use and expressiv e. The PGAS model [13], on the other hand, was developed precisely to improve the producti vity of distributed parallel program- ming. Thus, we have developed a lean and fast global arrays library that implements essential parts of the Global Arrays interface [14]. W e use MPI-3 as the transport layer for our library; get and put operations on global array elements make use of one-sided RMA operations that are supported in hardware on most supercomputer fabrics [15]. W e hav e also developed a Julia wrapper package for this library , making the PGAS programming model av ailable to Julia applications such as Celeste. G. Distributed dynamic scheduling T o serve the dynamic scheduling needs of Celeste, we hav e written a Julia wrapper for Dtree [12], a distributed dynamic scheduler that has been shown to be capable of balancing load for a di verse range of irregular tasks, e ven at petascale. The ef fectiveness of this scheduler can be seen in the minimal scheduling ov erhead we observed in our experiments. Dtree organizes processes into a short tree for task dis- tribution; the tree fan-out is configurable and allows for multiple parents in order to eliminate any bottleneck arising from too many children sharing a single parent. Giv en a total number of tasks, T , parents in the tree distribute batches of number ranges, f - l , where f , l < = T in response to requests from child processes. The size of each batch, n = l − f , reduces as T is approached; this balances load. Celeste uses the size of the catalog global array , that is, the number of candidate light sources, as the total number of tasks, T , as previously described. I V . S D S S DAT A S E T The Sloan Digital Sky Survey (SDSS) [16] is the archety- pal modern astronomical imaging survey . SDSS Data Re- lease 12 (DR12) contains almost half a billion indi vidual sources. It covers 14,555 square degrees of the night sky . The images are composed of 938,046 “fields”. Each field has images of it stored in five different files, one per filter band. Each file stores one image in the FITS file format. The images are 1361 × 2048 pix els, and roughly 12 MB each. The dataset in total is 55 TB; we processed 250 GB during the tests reported in this paper . V . H A R DW A R E P L AT F O R M Our experiments are conducted on the Cori supercom- puter at the National Energy Research Scientific Computing Center (NERSC). Cori is a Cray XC40 supercomputer . W e used Cori Phase I (also known as the “Cori Data Partition”) which has 1,630 compute nodes, each containing two Intel R Xeon R E5-2698v3 processors 1 (16 cores each) running at 2.3 GHz, and 128 GB of DDR4 memory . Nodes are linked through a Cray Aries high speed “dragonfly” topology interconnect. Datasets used in these experiments were staged on Cori’ s 30 PB Lustre file system, which has an aggregate bandwidth exceeding 700 GB/s. 1 Intel, Xeon, and Intel Xeon Phi are trademarks of Intel Corporation in the U.S. and/or other countries. 5 V I . S C A L I N G R E S U LT S W e ran a variety of experiments to explore the scalability of Celeste using the parallelization strategy described in Section III-C. W e analyze Celeste’ s performance by partitioning the measured runtime for a job into a number of components: (a) garbage collection time, (b) image load time, (c) load imbalance, (d) the time taken in retrieving elements of the global arrays used, (e) dynamic scheduling ov erhead, and (f) source optimization time. This partitioning is not precise as it is averaged across nodes and certain components of runtime are not completely independent. Nonetheless, it is indicativ e. W e use a light-sources-per -second metric to detail source optimization performance in each scaling test. A. Single node, multi-threaded performance Figure 3: Multi-threaded performance. Strong-scaling Ce- leste on 154 light sources ov er up to 16 threads on a Cori Phase I node. Observe that scalability drops off beyond 4 threads; this is due to serial garbage collection. A Celeste process uses multiple threads to process multi- ple light sources in parallel. W e partition runtime as previ- ously described, and show the number of sources optimized per second at different thread counts in Figure 3. Note the drop-off in scalability be yond 4 threads; this is caused by the serial operation of Julia’ s garbage collector , requiring threads to synchronize each GC cycle. Thus, Amdahl’ s Law [17] limits multi-threaded scalability . W e discuss this challenge further in Section VIII-A. Software and workloads used in performance tests may ha ve been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary . Y ou should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more information go to http: //www .intel.com/performance. T o limit time in GC, we use 4 threads per process on our multi-node runs. A single Cori Phase I node has 32 cores; we run 8 processes per node. B. W eak scaling Figure 4 sho ws the components of runtime for our weak scaling experiment. Garbage collection takes between 15% and 25% of runtime at all scales. Image load time does not exceed 1% of runtime. Load imbalance is 6.5% of runtime at most. In absolute terms, 256 nodes exhibits the highest av erage load imbal- ance, yet the runtime attributed to load imbalance is less than 70 seconds. This is an acceptable level of imbalance: some individual tasks alone take more than double this time. The portion of runtime spent retrieving data from the global array is the most concerning. Retriev al time is negli- gible at 64 nodes and fe wer, but grows to 18% of runtime at 256 nodes. Such a growth rate indicates that transferring images between nodes is saturating the fabric bandwidth. Recall from Section III-C, that Celeste faces a trade-off between I/O burden and load balance. The use of global arrays is intended to reduce the I/O burden, but although the network is far faster than disk, there are nonetheless bandwidth limitations. Each image is roughly 120 MB in size, and the av erage task ex ecution time is less than 5 seconds. If ev ery thread in every process executes a task that requires a different image, then ev ery 5 seconds on av erage, a node will fetch 3.75 GB of image data from across the fabric. Clearly , as the node count increases, ev en a high performance fabric such as Cray’ s Aries HSN would be overwhelmed—for this worst case at 256 nodes, 192 GB of images would have to mov e across the fabric ev ery second. These results indicate that we hav e not sufficiently re- duced the I/O burden, howe ver further reduction in I/O will cause increased load imbalance. W e will pursue more advanced strategies in future work. W e note the slight increase in scheduling overhead on the 256 node run; this is due to global arrays traf fic saturating the interconnect and slowing down the task scheduler, rather than to any issue with the scheduler itself. Figure 6a shows the light-sources-per-second rate achiev ed at different scales in the weak-scaling experiments. W e observe perfect scaling up to 64 nodes followed by a degradation primarily due to slower fetches from the images global array . C. Str ong scaling Our strong scaling experiments process a region of the sky containing 332,631 light sources. Figure 5 shows the runtimes, and their breakdowns by routine, at each scale. Garbage collection time is highest (30% of total runtime) for the 16 node run, the run with the fe west nodes. That indicates that Julia’ s serial GC is detrimental not only 6 Figure 4: W eak-scaling Celeste. While the total runtime shown is precise, the components of runtime shown are averaged across nodes and thus should be treated as being representativ e rather than exact. Figure 5: Strong-scaling Celeste. Note the reduction in GC time correlates with reduction in runtime, whereas the increase in global arrays fetch time correlates with the increase in nodes. for large numbers of threads, but also for long running processes. For the 256 node strong-scaling run, garbage collection time is 11% of total runtime. This finding further underscores the need for improv ed GC; see Section VIII-A for further discussion. The next largest portion of total runtime, global arrays retriev al time, does not exceed 2% of runtime at 16 nodes. Howe ver , at 256 nodes, we find that it reaches 26% of runtime, reaffirming the need for improvements in task scheduling to reduce the I/O burden. The light-sources-per-second rates achieved at dif ferent scales in the strong-scaling experiment are shown in Fig- ure 6b. Again, we see perfect scaling up to 64 nodes, followed by a drop-of f due to serial GC and fabric bandwidth saturation. V I I . D I S C U S S I O N : S C I E N T I FI C R E S U LT S For astronomical images, ground truth is unkno wable. That in part is what makes Bayesian models of the data desirable for astronomy: if their output follo ws a plausible model of the data, then it too is plausible. Nonetheless, validation is essential: ev ery model entails assumptions about the process that generated the data. A particular region of the sky , known as Stripe 82, has been imaged ev erywhere at least 30 times. Most other regions have been imaged just once. W ith images from so many exposures, galaxies and stars that would be faint and hard to accurately characterize with just one exposure are 7 (a) W eak scaling (b) Strong scaling Figure 6: Celeste sources/second. W e observe perfect scaling up to 64 nodes, after which we are limited by interconnect bandwidth. easily resolved. “Photo” [3] is the current state-of-the-art software pipeline for constructing large astronomical catalogs. Photo is a carefully hand-tuned heuristic. Running Photo on all 30+ exposures of Stripe 82 generates a catalog that we let stand in for ground truth in our subsequent analysis. The first numeric column of T able I shows average error for Photo itself fit to just one segment of one exposure from Stripe 82. The second numeric column shows average error for Celeste fit to the same data. Celeste has lower error than on Photo by nearly 30% for locating stars and galaxies— an improv ement that is both statistically significant and of practical significance to astronomers. For all four colors, Celeste reduces the error rate by large amounts—always at least 30%. For brightness, Photo outperforms Celeste significantly . That may be due to systematic errors by Photo, reflected in both ground truth as well as Photo’ s predictions based on one exposure, but we do not hav e firm conclusions yet. W e hav e seen cases where a light source is over -saturated, that is, it is too bright for all the photons from it be counted, yet not flagged as being ov er-saturated. In these cases the ground truth does not reflect reality , but Photo run on all the data largely agrees with itself run on one exposure. Photo is more likely to misclassify stars as galaxies whereas Celeste is more likely to misclassify galaxies as stars. Photo is more accurate at determining the scales (sizes) of galaxies whereas Celeste is more accurate at determining their eccentricities and angles. W e anticipate that adjustments to the Celeste model, as discussed in Section IX, will enable Celeste to outperform Photo across board. Already , Celeste’ s results are the new state-of-the-art by a wide margin for location and color , and thus should be released. T able I: A verage error on celestial bodies from Stripe 82. Photo Celeste position 0.33 0.24 missed gals 0.06 0.03 missed stars 0.02 0.09 brightness 0.22 0.37 color u-g 1.23 0.69 color g-r 0.40 0.22 color r-i 0.26 0.17 color i-z 0.30 0.13 profile 0.28 0.29 eccentricity 0.19 0.13 scale 1.97 2.79 angle 17.60 12.91 Lower is better . Results in bold are better by more than 2 standard deviations. “Position” is error, in pixels, for the location of the celestial bodies’ centers. “Missed gals” is the proportion of galaxies labeled as stars. “Missed stars” is the proportion of stars labeled as galaxies. “Brightness” measures the reference band (r-band) magnitude. “Colors” are ratios of magnitudes in consecutive bands. “Profile” is a proportion indicating whether a galaxy is de V aucouleurs or exponential. “Eccentricity” is the ratio between the lengths of a galaxy’ s minor and major axes. “Scale” is the effectiv e radius of a galaxy in arcseconds. “ Angle” is the orientation of a galaxy in degrees. V I I I . D I S C U S S I O N : J U L I A F O R H P C A N D B I G D A TA A NA LY T I C S Dev eloping Celeste in Julia has generally been a positiv e experience: rapid prototyping, the high level of abstraction, and a rich set of libraries hav e allowed for high productivity . Julia’ s compiler has produced high performance code. Our greatest challenge arose from our use of Julia’ s threads, a feature clearly identified as experimental. A. Thr eads and garbage collection Celeste uses Julia’ s experimental multi-threading capa- bility for shared memory parallelism. While this capability 8 is reasonably stable and allo ws excellent scaling, we dis- cov ered an important limitation: Julia’ s garbage collector currently does not scale well. With 16 threads per process, the time consumed by garbage collection exceeds a third of total runtime. The GC time approaches half of total runtime for longer duration jobs. The foremost reason for excessiv e GC time is that Julia’ s garbage collector is serial. Thus, Amdahl’ s Law limits scaling. In addition, serial GC requires synchronization of all threads before a collection cycle. Celeste’ s work is irregular and threads run mostly asynchronously , which adds additional ov erhead as compared to applications with regular work such as PDE solvers. Parallel garbage collection is not a solved problem; there is activ e research in this area [18]. Howe ver , there are a number of well-understood methods to improv e scalability , such as parallelizing the marking phase and doing sweeps concurrently with running threads. There are ef forts un- derway to improve Julia’ s memory management in these and other ways. Currently , howe ver , to scale beyond 4 to 6 threads requires the programmer to carefully consider memory utilization—avoiding copies and temporaries, and extensi vely using in-place operations—which hinders the ease and expressiv eness of programming in Julia. Additionally , while Julia’ s runtime is thread-safe, much of the standard library currently is not. That too limits the ease of writing multi-threaded programs in Julia. I X . C O N C L U S I O N S A N D F U T U R E W O R K W e dev eloped a multi-threaded, distributed version of Celeste, and demonstrated good weak and strong scaling on up to 256 nodes. Using this version of Celeste, we generated a catalog for a subset of SDSS that contains better parameter estimates for location, color , galaxy eccentricity , and galaxy angle. This new catalog is the largest ev er to include uncertainty estimates that follo w from a realistic model of the data. In the process of generating the catalog, we scaled Bayesian inference to datasets larger than those reported in the literature, through a combination of mathematical and algorithmic innov ations. A widely held view is that Bayesian inference works for small datasets, when accuracy is paramount, but that heuristics are typically necessary . Our results suggest otherwise: given a realistic model, the poste- rior can be approximated within the av ailable computational budget. Celeste is a unique project that has advanced the frontier of scalable inference methods in the context of a truly large-scale, important scientific application on an advanced HPC architecture. W e have sev eral methodological innov ations planned for future work. First, we aim to find a stationary point of our objectiv e function by optimizing all light sources jointly , rather than optimizing each light source with all other light sources’ parameters fixed to their estimates from previous surve ys. That requires greater communication among nodes. Second, we plan to allow candidate light sources to “turn off ”, effecti vely estimating the true number of light sources from an oversubscribed list of candidates. Third, we will apply linear response methods [10] to improv e the uncertainty quantification of our variational inference procedure. These methods should mitigate bias stemming from our choice of a variational distribution that factorizes and provide us with uncertain estimates for quantities that we model as unknown constants rather than random variables. Fourth, we anticipate switching from deterministic to stochastic optimization. By basing updates on samples from the variational distribution, stochastic optimization can ap- proximate the posterior for arbitrary combinations of models and classes of candidate variational distributions, whereas deterministic optimization is limited to combinations that lead to an analytic objective function. That frees us to experiment with e ven more realistic models of the data, and even more expressiv e distributions for approximating the posterior . Stochastic optimization, ho wever , is likely to be orders of magnitude more computationally expensiv e than our current highly optimized form of second-order deterministic optimization. Fortunately , the upcoming integration of Cori Phase II (based on Intel Phi Knights Landing processors) will increase the system’ s computational throughput by roughly one order of magnitude. An additional order of magnitude speedup may follo w from subsampling the pixels, in addition to sampling from the variational distrib ution— an approach known as “doubly” stochastic VI [19]. Another order of magnitude speedup may follow from using a second-order stochastic method [20] rather than stochastic gradient descent. Finally , applying Celeste to multiple images surveys jointly is a promising direction. In conjunction with SDSS, we will process the Dark Energy Camera Legac y Survey (DECaLS) [21] in future work. A C K N O W L E D G M E N T S This research used resources of the National Energy Re- search Scientific Computing Center (NERSC), a DOE Office of Science User Facility supported by the Office of Science of the U.S. Department of Energy under Contract No. DE- A C02-05CH11231. The authors express their gratitude to T ina Declerck, Doug Jacobsen, David Paul and Zhengi Zhao who helped make the results presented in this paper possible. Debbie Bard and Dustin Lang provided expert advice on astronomy datasets and image processing issues. W e are grateful for the tremendous assistance rendered by various members of the Julia dev eloper community: T ony Kelman, Jameson Nash, Andreas Noack, Alan Edelman and V iral Shah addressed various functionality and performance 9 issues in Julia. Finally , we thank Andy Miller , Ryan Adams and Ste ve Ho ward, who assisted in developing the Celeste codebase. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P . Sloan Foundation, the U.S. De- partment of Energy Office of Science, and the Participating Institutions. SDSS-IV ackno wledges support and resources from the Center for High-Performance Computing at the Univ ersity of Utah. The SDSS web site is www .sdss.org. R E F E R E N C E S [1] Large Synoptic Survey T elescope Consortium, http://www . lsst.org/lsst/about, 2016, [Online; accessed October 18, 2016]. [2] E. Bertin and S. Arnouts, “SExtractor: Software for source extraction, ” Astronomy and Astr ophysics Supplement Series , vol. 117, no. 2, pp. 393–404, 1996. [3] R. H. Lupton, Z. Iv ezic, J. E. Gunn, G. Knapp, M. A. Strauss, M. Richmond, N. Ellman, H. Newb urg, X. Fan, N. Y asuda et al. , “SDSS image processing II: The photo pipelines, ” T echnical report, Princeton University , T ech. Rep., 2005. [4] M. D. Schneider, D. W . Hogg, P . J. Marshall, W . A. Dawson, J. Me yers, D. J. Bard, and D. Lang, “Hierarchical probabilistic inference of cosmic shear , ” The Astr ophysical Journal , vol. 807, no. 1, p. 87, 2015. [5] J. Regier , A. Miller , J. McAuliffe, R. Adams, M. Hoffman, D. Lang, D. Schlegel, and Prabhat, “Celeste: V ariational inference for a generative model of astronomical images, ” in Pr oceedings of the 32nd International Conference on Machine Learning , 2015. [6] D. Lang, http://thetractor.or g/about/, 2016, [Online; accessed October 21, 2016]. [7] B. J. Brewer , D. Foreman-Mackey , and D. W . Hogg, “Proba- bilistic catalogs for crowded stellar fields, ” The Astr onomical Journal , vol. 146, no. 1, p. 7, 2013. [8] D. M. Blei, A. Kucukelbir , and J. D. McAuliffe, “V aria- tional inference: A revie w for statisticians, ” arXiv preprint arXiv:1601.00670 , 2016. [9] M. D. Hoffman, D. M. Blei, C. W ang, and J. W . Paisley , “Stochastic variational inference. ” Journal of Machine Learn- ing Researc h , vol. 14, no. 1, pp. 1303–1347, 2013. [10] R. J. Giordano, T . Broderick, and M. I. Jordan, “Linear re- sponse methods for accurate cov ariance estimates from mean field v ariational bayes, ” in Advances in Neural Information Pr ocessing Systems , 2015, pp. 1441–1449. [11] S. Wright and J. Nocedal, “Numerical optimization, ” Springer Science , vol. 35, pp. 67–68, 1999. [12] K. Pamnan y , S. Misra, V . Md, X. Liu, E. Chow , and S. Aluru, “Dtree: Dynamic task scheduling at petascale, ” in International Confer ence on High P erformance Computing . Springer , 2015, pp. 122–138. [13] Tim Stitt, http://cnx.org/content/m20649/latest/, 2016, [On- line; accessed October 23, 2016]. [14] J. Nieplocha, B. Palmer , V . T ipparaju, M. Krishnan, H. T rease, and E. Apr ` a, “ Advances, applications and performance of the global arrays shared memory programming toolkit, ” Interna- tional Journal of High P erformance Computing Applications , vol. 20, no. 2, pp. 203–231, 2006. [15] T . Hoefler , J. Dinan, R. Thakur, B. Barrett, P . Balaji, W . Gropp, and K. Underwood, “Remote memory access programming in mpi-3, ” ACM T rans. P arallel Comput. , vol. 2, no. 2, pp. 9:1–9:26, Jun. 2015. [Online]. A vailable: http://doi.acm.org/10.1145/2780584 [16] C. Stoughton, R. H. Lupton, M. Bernardi, M. R. Blanton, S. Burles, F . J. Castander , A. Connolly , D. J. Eisenstein, J. A. Frieman, G. Hennessy et al. , “Sloan digital sky survey: early data release, ” The Astronomical Journal , vol. 123, no. 1, p. 485, 2002. [17] M. D. Hill and M. R. Marty , “ Amdahl’ s law in the multicore era, ” IEEE Computer , vol. 41, pp. 33–38, 2008. [18] R. Jones, A. Hosking, and E. Moss, The Garbage Collec- tion Handbook: The Art of Automatic Memory Management , 1st ed. Chapman & Hall/CRC, 2011. [19] M. Titsias and M. L ´ azaro-Gredilla, “Doubly stochastic vari- ational bayes for non-conjugate inference, ” in Pr oceedings of The 31st International Conference on Machine Learning , 2014, pp. 1971–1979. [20] J. Blanchet, C. Cartis, M. Menickelly , and K. Schein- berg, “Conv ergence rate analysis of a stochastic trust re- gion method for noncon vex optimization, ” arXiv pr eprint arXiv:1609.07428 , 2016. [21] Dark Energy Camera Legacy Survey (DECaLS), http:// legac ysurvey .org/decamls/, 2016, [Online; accessed October 20, 2016]. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment