메타강화학습으로 구현한 빠른 학습기: RL²
RL²는 빠른 강화학습 알고리즘을 직접 설계하지 않고, RNN의 가중치를 “느린” RL(예: TRPO)로 학습시켜 메타‑강화학습 에이전트를 만든다. 에이전트는 관찰·행동·보상·종료 플래그를 입력받아 내부 상태를 유지하고, 동일 MDP 내 여러 에피소드에 걸쳐 스스로 학습한다. 실험은 (1) 다중 팔 밴드와 (2) 표형 MDP, (3) 비주얼 네비게이션 과제로 구성했으며, 작은 규모에서는 기존 최적 알고리즘에 근접하고, 큰 규모에서도 고차원 입력…
저자: Yan Duan, John Schulman, Xi Chen
본 논문은 인간이나 동물이 새로운 과업을 몇 번의 시도만에 습득하는 능력과, 현재 딥 강화학습이 수천·수만 번의 시뮬레이션을 필요로 하는 현실 사이의 격차를 메타‑강화학습(meta‑RL)이라는 새로운 프레임워크로 메우고자 한다. 저자들은 “빠른” 강화학습 알고리즘을 직접 설계하는 대신, 그 알고리즘 자체를 순환 신경망(RNN)의 파라미터에 내재화하고, 이 파라미터를 “느린” 강화학습 알고리즘을 통해 학습한다는 아이디어를 제시한다. 이를 RL²(RL-squared)라 명명한다.
**문제 정의와 메타‑학습 설정**
- MDP들의 집합 M과 그 위의 사전 분포 ρ_M을 가정한다. 학습 단계에서는 ρ_M 로부터 MDP를 샘플링하고, 각 MDP에 대해 n개의 에피소드를 연속적으로 수행한다. 이 연속된 에피소드를 하나의 “트라이얼”이라 부른다.
- 에이전트는 매 타임스텝에 (관찰 s_t, 행동 a_t, 보상 r_t, 종료 플래그 d_t)를 입력받아 임베딩 φ(s_t, a_t, r_t, d_t)를 만든 뒤, GRU 기반 RNN에 전달한다. RNN 은닉 상태 h_t는 트라이얼 전체에 걸쳐 유지되며, 이는 “빠른” 학습 알고리즘의 내부 메모리 역할을 한다.
- 트라이얼이 끝나면 은닉 상태는 초기화된다. 따라서 메타‑정책은 각 트라이얼마다 새로운 MDP에 대해 처음부터 학습을 시작한다.
- 목표는 한 트라이얼 동안 누적된 할인 보상의 기대값을 최대화하는 것으로, 이는 트라이얼 수준에서의 누적 pseudo‑regret 최소화와 동등하다.
**학습 방법**
- 메타‑정책 μ_ϕ (RNN)의 파라미터 ϕ를 최적화하기 위해 Trust Region Policy Optimization(TRPO)와 Generalized Advantage Estimation(GAE)를 사용한다. 이는 고차원 파라미터 공간에서도 안정적인 업데이트를 가능하게 한다.
- 베이스라인 역시 RNN 형태로 구현해 샘플링 변동성을 감소시킨다.
- 학습 과정은 완전한 모델‑프리 방식이며, 사전 분포 ρ_M 에서 MDP를 무작위로 샘플링해 다수의 트라이얼을 수행한다.
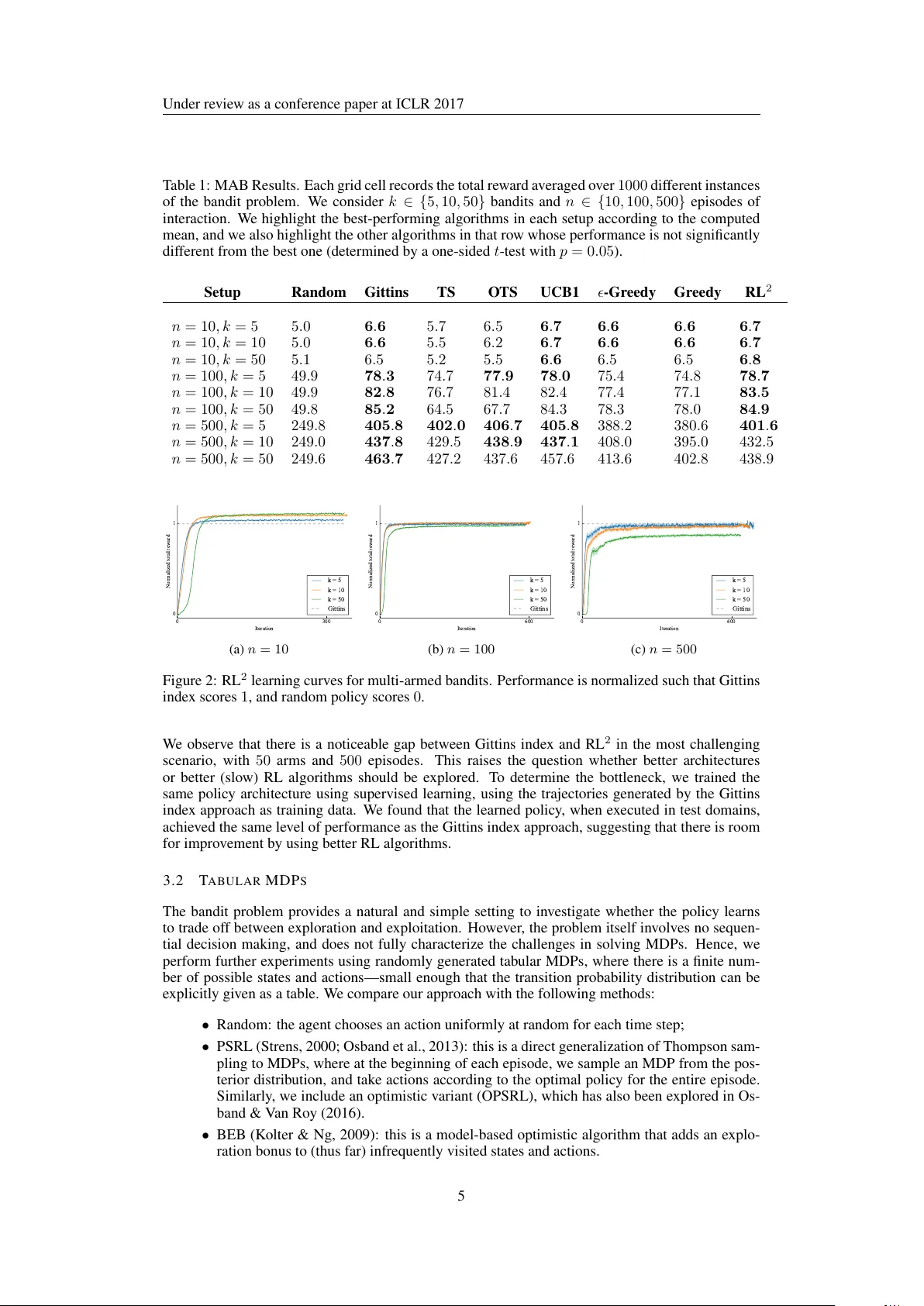
**실험 1: 다중 팔 밴드**
- k∈{5,10,50}개의 팔을 가진 베르누이 밴드 문제를 uniform
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기