RL$^2$: Fast Reinforcement Learning via Slow Reinforcement Learning
Deep reinforcement learning (deep RL) has been successful in learning sophisticated behaviors automatically; however, the learning process requires a huge number of trials. In contrast, animals can learn new tasks in just a few trials, benefiting fro…
Authors: Yan Duan, John Schulman, Xi Chen
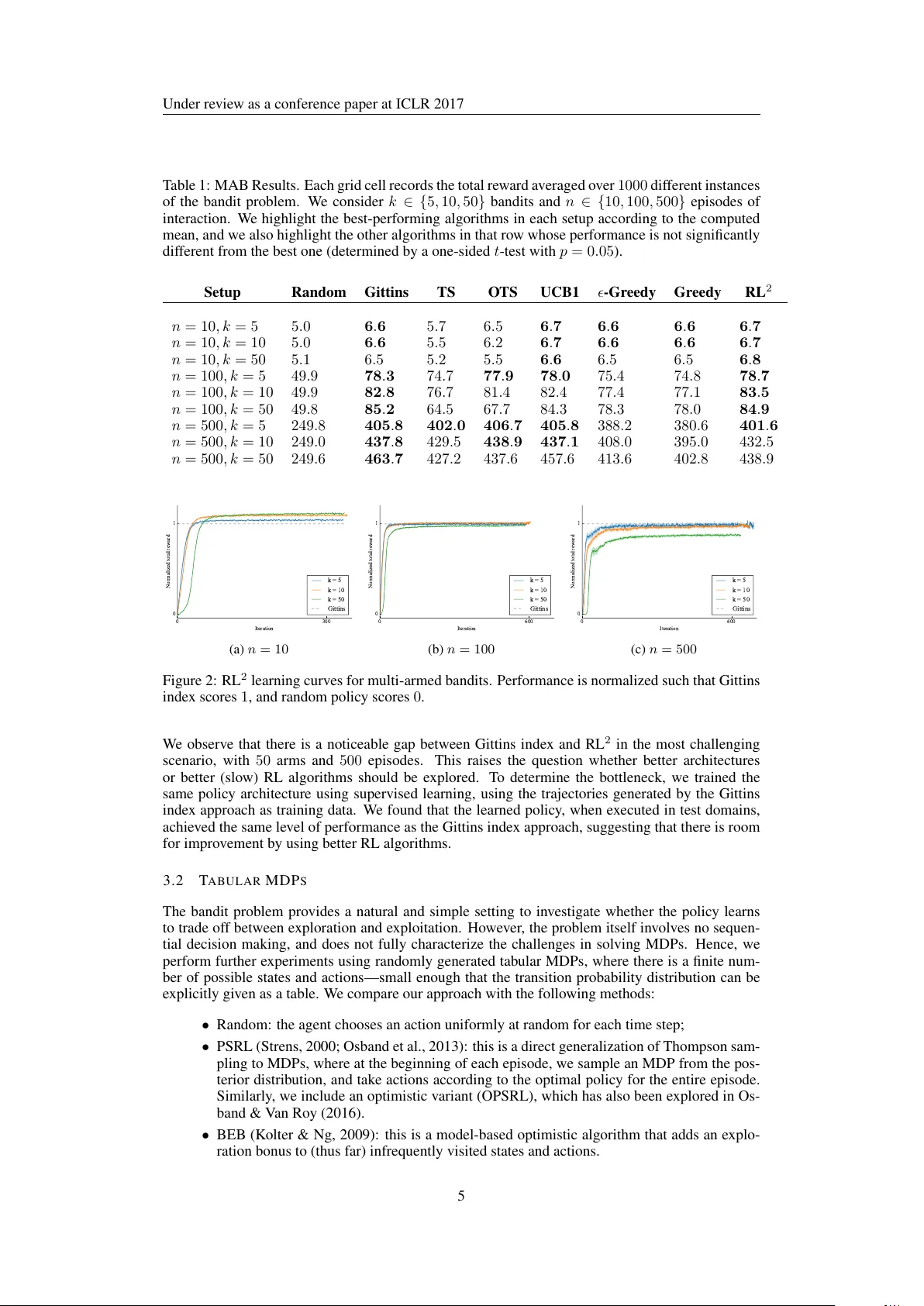
Under revie w as a conference paper at ICLR 2017 R L 2 : F A S T R E I N F O R C E M E N T L E A R N I N G V I A S L O W R E I N F O R C E M E N T L E A R N I N G Y an Duan † ‡ , John Schulman † ‡ , Xi Chen † ‡ , Peter L. Bartlett † , Ilya Sutskev er ‡ , Pieter Abbeel † ‡ † UC Berkeley , Department of Electrical Engineering and Computer Science ‡ OpenAI { rocky,joschu,peter } @openai.com, peter@berkeley.edu, { ilyasu,pieter } @openai.com A B S T R AC T Deep reinforcement learning (deep RL) has been successful in learning sophis- ticated behaviors automatically; howe ver , the learning process requires a huge number of trials. In contrast, animals can learn ne w tasks in just a fe w trials, bene- fiting from their prior knowledge about the world. This paper seeks to bridge this gap. Rather than designing a “fast” reinforcement learning algorithm, we propose to represent it as a recurrent neural network (RNN) and learn it from data. In our proposed method, RL 2 , the algorithm is encoded in the weights of the RNN, which are learned slo wly through a general-purpose (“slo w”) RL algorithm. The RNN receiv es all information a typical RL algorithm would recei ve, including ob- servations, actions, rewards, and termination flags; and it retains its state across episodes in a gi ven Marko v Decision Process (MDP). The acti vations of the RNN store the state of the “fast” RL algorithm on the current (pre viously unseen) MDP . W e ev aluate RL 2 experimentally on both small-scale and large-scale problems. On the small-scale side, we train it to solv e randomly generated multi-armed ban- dit problems and finite MDPs. After RL 2 is trained, its performance on ne w MDPs is close to human-designed algorithms with optimality guarantees. On the lar ge- scale side, we test RL 2 on a vision-based na vigation task and sho w that it scales up to high-dimensional problems. 1 I N T R O D U C T I O N In recent years, deep reinforcement learning has achiev ed many impressive results, including playing Atari games from raw pixels (Guo et al., 2014; Mnih et al., 2015; Schulman et al., 2015), and acquiring adv anced manipulation and locomotion skills (Le vine et al., 2016; Lillicrap et al., 2015; W atter et al., 2015; Heess et al., 2015; Schulman et al., 2015; 2016). Ho wev er, many of the successes come at the expense of high sample complexity . For example, the state-of-the-art Atari results require tens of thousands of episodes of experience (Mnih et al., 2015) per game. T o master a game, one would need to spend nearly 40 days playing it with no rest. In contrast, humans and animals are capable of learning a new task in a very small number of trials. Continuing the previous e xample, the human player in Mnih et al. (2015) only needed 2 hours of experience before mastering a game. W e argue that the reason for this sharp contrast is largely due to the lack of a good prior , which results in these deep RL agents needing to rebuild their kno wledge about the world from scratch. Although Bayesian reinforcement learning pro vides a solid frame work for incorporating prior knowledge into the learning process (Strens, 2000; Gha vamzadeh et al., 2015; K olter & Ng, 2009), exact computation of the Bayesian update is intractable in all but the simplest cases. Thus, practi- cal reinforcement learning algorithms often incorporate a mixture of Bayesian and domain-specific ideas to bring down sample complexity and computational b urden. Notable examples include guided policy search with unknown dynamics (Levine & Abbeel, 2014) and PILCO (Deisenroth & Ras- mussen, 2011). These methods can learn a task using a few minutes to a few hours of real experience, compared to days or ev en weeks required by pre vious methods (Schulman et al., 2015; 2016; Lilli- crap et al., 2015). Howe ver , these methods tend to make assumptions about the en vironment (e.g., instrumentation for access to the state at learning time), or become computationally intractable in high-dimensional settings (W ahlstr ¨ om et al., 2015). 1 Under revie w as a conference paper at ICLR 2017 Rather than hand-designing domain-specific reinforcement learning algorithms, we take a dif ferent approach in this paper: we vie w the learning process of the agent itself as an objecti ve, which can be optimized using standard reinforcement learning algorithms. The objectiv e is a veraged across all possible MDPs according to a specific distribution, which reflects the prior that we would like to distill into the agent. W e structure the agent as a recurrent neural network, which receiv es past rew ards, actions, and termination flags as inputs in addition to the normally recei ved observ ations. Furthermore, its internal state is preserv ed across episodes, so that it has the capacity to perform learning in its o wn hidden acti vations. The learned agent thus also acts as the learning algorithm, and can adapt to the task at hand when deployed. W e ev aluate this approach on two sets of classical problems, multi-armed bandits and tab ular MDPs. These problems hav e been extensi vely studied, and there exist algorithms that achieve asymptoti- cally optimal performance. W e demonstrate that our method, named RL 2 , can achiev e performance comparable with these theoretically justified algorithms. Next, we e valuate RL 2 on a vision-based navigation task implemented using the V iZDoom en vironment (Kempka et al., 2016), sho wing that RL 2 can also scale to high-dimensional problems. 2 M E T H O D 2 . 1 P R E L I M I NA R I E S W e define a discrete-time finite-horizon discounted Marko v decision process (MDP) by a tuple M = ( S , A , P , r , ρ 0 , γ , T ) , in which S is a state set, A an action set, P : S × A × S → R + a transition probability distribution, r : S × A → [ − R max , R max ] a bounded rew ard function, ρ 0 : S → R + an initial state distrib ution, γ ∈ [0 , 1] a discount factor , and T the horizon. In polic y search methods, we typically optimize a stochastic policy π θ : S × A → R + parametrized by θ . The objectiv e is to maximize its e xpected discounted return, η ( π θ ) = E τ [ P T t =0 γ t r ( s t , a t )] , where τ = ( s 0 , a 0 , . . . ) denotes the whole trajectory , s 0 ∼ ρ 0 ( s 0 ) , a t ∼ π θ ( a t | s t ) , and s t +1 ∼ P ( s t +1 | s t , a t ) . 2 . 2 F O R M U L A T I O N W e no w describe our formulation, which casts learning an RL algorithm as a reinforcement learning problem, and hence the name RL 2 . W e assume kno wledge of a set of MDPs, denoted by M , and a distribution over them: ρ M : M → R + . W e only need to sample from this distribution. W e use n to denote the total number of episodes allo wed to spend with a specific MDP . W e define a trial to be such a series of episodes of interaction with a fixed MDP . Episode 1 Episode 2 s 0 s 1 s 2 h 0 h 1 a 0 r 0 ,d 0 h 2 h 3 s 3 a 1 r 1 ,d 1 a 2 r 2 ,d 2 s 0 s 1 s 2 h 4 h 5 a 0 r 0 ,d 0 h 6 a 1 r 1 ,d 1 Agent MDP 1 Episode 1 s 0 s 1 … h 0 h 1 a 0 r 0 ,d 0 … a 1 Agent MDP 2 … … … Trial 1 Trial 2 Figure 1: Procedure of agent-en vironment interaction This process of interaction between an agent and the en vironment is illustrated in Figure 1. Here, each trial happens to consist of two episodes, hence n = 2 . For each trial, a separate MDP is drawn from ρ M , and for each episode, a fresh s 0 is drawn from the initial state distribution specific to the corresponding MDP . Upon recei ving an action a t produced by the agent, the en vironment computes re ward r t , steps forward, and computes the ne xt state s t +1 . If the episode has terminated, it sets termination flag d t to 1 , which otherwise defaults to 0 . T ogether, the next state s t +1 , action 2 Under revie w as a conference paper at ICLR 2017 a t , rew ard r t , and termination flag d t , are concatenated to form the input to the policy 1 , which, conditioned on the hidden state h t +1 , generates the next hidden state h t +2 and action a t +1 . At the end of an episode, the hidden state of the policy is preserved to the next episode, but not preserved between trials. The objecti ve under this formulation is to maximize the expected total discounted re ward accumu- lated during a single trial rather than a single episode. Maximizing this objectiv e is equiv alent to minimizing the cumulati ve pseudo-regret (Bubeck & Cesa-Bianchi, 2012). Since the underlying MDP changes across trials, as long as dif ferent strategies are required for dif ferent MDPs, the agent must act differently according to its belief over which MDP it is currently in. Hence, the agent is forced to integrate all the information it has recei ved, including past actions, rewards, and termi- nation flags, and adapt its strate gy continually . Hence, we have set up an end-to-end optimization process, where the agent is encouraged to learn a “fast” reinforcement learning algorithm. For clarity of exposition, we hav e defined the “inner” problem (of which the agent sees n each trials) to be an MDP rather than a POMDP . Ho wever , the method can also be applied in the partially- observed setting without any conceptual changes. In the partially observed setting, the agent is faced with a sequence of POMDPs, and it recei ves an observ ation o t instead of state s t at time t . The visual navigation e xperiment in Section 3.3, is actually an instance of the this POMDP setting. 2 . 3 P O L I C Y R E PR E S E N TA T I O N W e represent the polic y as a general recurrent neural netw ork. Each timestep, it receiv es the tuple ( s, a, r , d ) as input, which is embedded using a function φ ( s, a, r, d ) and provided as input to an RNN. T o alleviate the dif ficulty of training RNNs due to v anishing and exploding gradients (Bengio et al., 1994), we use Gated Recurrent Units (GR Us) (Cho et al., 2014) which ha ve been demonstrated to ha ve good empirical performance (Chung et al., 2014; J ´ ozefowicz et al., 2015). The output of the GR U is fed to a fully connected layer followed by a softmax function, which forms the distrib ution ov er actions. W e have also experimented with alternativ e architectures which explicitly reset part of the hidden state each episode of the sampled MDP , but we did not find any improv ement over the simple archi- tecture described abov e. 2 . 4 P O L I C Y O P TI M I Z A T I O N After formulating the task as a reinforcement learning problem, we can readily use standard of f-the- shelf RL algorithms to optimize the polic y . W e use a first-order implementation of T rust Region Policy Optimization (TRPO) (Schulman et al., 2015), because of its excellent empirical perfor- mance, and because it does not require excessi ve hyperparameter tuning. For more details, we refer the reader to the original paper . T o reduce v ariance in the stochastic gradient estimation, we use a baseline which is also represented as an RNN using GRUs as building blocks. W e optionally apply Generalized Advantage Estimation (GAE) (Schulman et al., 2016) to further reduce the v ariance. 3 E V A L UA T I O N W e designed experiments to answer the follo wing questions: • Can RL 2 learn algorithms that achie ve good performance on MDP classes with special structure, relativ e to existing algorithms tailored to this structure that hav e been proposed in the literature? • Can RL 2 scale to high-dimensional tasks? For the first question, we e valuate RL 2 on tw o sets of tasks, multi-armed bandits (MAB) and tab ular MDPs. These problems ha ve been studied e xtensively in the reinforcement learning literature, and this body of work includes algorithms with guarantees of asymptotic optimality . W e demonstrate that our approach achiev es comparable performance to these theoretically justified algorithms. 1 T o make sure that the inputs have a consistent dimension, we use placeholder v alues for the initial input to the policy . 3 Under revie w as a conference paper at ICLR 2017 For the second question, we e valuate RL 2 on a vision-based na vigation task. Our experiments sho w that the learned polic y makes ef fectiv e use of the learned visual information and also short-term information acquired from previous episodes. 3 . 1 M U L T I - A R M E D BA N D I T S Multi-armed bandit problems are a subset of MDPs where the agent’ s en vironment is stateless. Specifically , there are k arms (actions), and at e very time step, the agent pulls one of the arms, say i , and receives a reward dra wn from an unknown distrib ution: our experiments take each arm to be a Bernoulli distribution with parameter p i . The goal is to maximize the total re ward obtained ov er a fixed number of time steps. The key challenge is balancing exploration and e xploitation— “exploring” each arm enough times to estimate its distrib ution ( p i ), b ut ev entually switching ov er to “exploitation” of the best arm. Despite the simplicity of multi-arm bandit problems, their study has led to a rich theory and a collection of algorithms with optimality guarantees. Using RL 2 , we can train an RNN policy to solve bandit problems by training it on a gi ven distribution ρ M . If the learning is successful, the resulting policy should be able to perform competiti vely with the theoretically optimal algorithms. W e randomly generated bandit problems by sampling each parameter p i from the uniform distribution on [0 , 1] . After training the RNN policy with RL 2 , we compared it against the follo wing strategies: • Random: this is a baseline strate gy , where the agent pulls a random arm each time. • Gittins index (Gittins, 1979): this method giv es the Bayes optimal solution in the dis- counted infinite-horizon case, by computing an index separately for each arm, and taking the arm with the lar gest index. While this work shows it is sufficient to independently com- pute an index for each arm (hence av oiding combinatorial e xplosion with the number of arms), it doesn’ t show how to tractably compute these indi vidual indices e xactly . W e fol- low the practical approximations described in Gittins et al. (2011), Chakravorty & Mahajan (2013), and Whittle (1982), and choose the best-performing approximation for each setup. • UCB1 (Auer, 2002): this method estimates an upper-confidence bound, and pulls the arm with the largest value of ucb i ( t ) = ˆ µ i ( t − 1) + c q 2 log t T i ( t − 1) , where ˆ µ i ( t − 1) is the estimated mean parameter for the i th arm, T i ( t − 1) is the number of times the i th arm has been pulled, and c is a tunable hyperparameter (Audibert & Munos, 2011). W e initialize the statistics with exactly one success and one failure, which corresponds to a Beta(1 , 1) prior . • Thompson sampling (TS) (Thompson, 1933): this is a simple method which, at each time step, samples a list of arm means from the posterior distribution, and choose the best arm according to this sample. It has been demonstrated to compare fav orably to UCB1 empir- ically (Chapelle & Li, 2011). W e also experiment with an optimistic variant (OTS) (May et al., 2012), which samples N times from the posterior , and takes the one with the highest probability . • -Greedy: in this strategy , the agent chooses the arm with the best empirical mean with probability 1 − , and chooses a random arm with probability . W e use the same initial- ization as UCB1. • Greedy: this is a special case of -Greedy with = 0 . The Bayesian methods, Gittins index and Thompson sampling, take advantage of the distribution ρ M ; and we pro vide these methods with the true distribution. For each method with hyperparame- ters, we maximize the score with a separate grid search for each of the e xperimental settings. The hyperparameters used for TRPO are sho wn in the appendix. The results are summarized in T able 1. Learning curv es for various settings are shown in Figure 2. W e observe that our approach achieves performance that is almost as good as the the reference meth- ods, which were (human) designed specifically to perform well on multi-armed bandit problems. It is worth noting that the published algorithms are mostly designed to minimize asymptotic regret (rather than finite horizon re gret), hence there tends to be a little bit of room to outperform them in the finite horizon settings. 4 Under re vie w as a conference paper at ICLR 2017 T able 1: MAB Results. Each grid cell records the total re w ard a v eraged o v er 1000 dif ferent instances of the bandit problem. W e consider k ∈ { 5 , 10 , 50 } bandits and n ∈ { 10 , 100 , 500 } episodes of interaction. W e highlight the best-performing algorithms in each setup according to the computed mean, and we also highlight the other algorithms in that ro w whose performance is not significantly dif ferent from the best one (determined by a one-sided t -test with p = 0 . 05 ). Setup Random Gittins TS O TS UCB1 -Gr eedy Gr eedy RL 2 n = 10 , k = 5 5 . 0 6 . 6 5 . 7 6 . 5 6 . 7 6 . 6 6 . 6 6 . 7 n = 10 , k = 10 5 . 0 6 . 6 5 . 5 6 . 2 6 . 7 6 . 6 6 . 6 6 . 7 n = 10 , k = 50 5 . 1 6 . 5 5 . 2 5 . 5 6 . 6 6 . 5 6 . 5 6 . 8 n = 100 , k = 5 49 . 9 78 . 3 74 . 7 77 . 9 78 . 0 75 . 4 74 . 8 78 . 7 n = 100 , k = 10 49 . 9 82 . 8 76 . 7 81 . 4 82 . 4 77 . 4 77 . 1 83 . 5 n = 100 , k = 50 49 . 8 85 . 2 64 . 5 67 . 7 84 . 3 78 . 3 78 . 0 84 . 9 n = 500 , k = 5 249 . 8 405 . 8 402 . 0 406 . 7 405 . 8 388 . 2 380 . 6 401 . 6 n = 500 , k = 10 249 . 0 437 . 8 429 . 5 438 . 9 437 . 1 408 . 0 395 . 0 432 . 5 n = 500 , k = 50 249 . 6 463 . 7 427 . 2 437 . 6 457 . 6 413 . 6 402 . 8 438 . 9 0 300 Iteration 0 1 Normalized total reward k = 5 k = 10 k = 50 Gittins (a) n = 10 0 600 Iteration 0 1 Normalized total reward k = 5 k = 10 k = 50 Gittins (b) n = 1 00 0 600 Iteration 0 1 Normalized total reward k = 5 k = 10 k = 50 Gittins (c) n = 500 Figure 2: RL 2 learning curv es for multi-armed bandits. Performance is normalized such that Gittins inde x scores 1 , and random polic y scores 0 . W e observ e that there is a noticeable g ap between Gittins inde x and RL 2 in the most challenging scenario, with 50 arms and 500 episodes. This raises the question whether better architectures or better (slo w) RL algorithms should be e xplored. T o determine the bottleneck, we trained the same polic y architecture using supervised learning, using the trajectories generated by the Gittins inde x approach as training data. W e found that the learned polic y , when e x ecuted in test domains, achie v ed the same le v el of performance as the Gittins inde x approach, suggesting that there is room for impro v ement by using better RL algorithms. 3 . 2 T A B U L A R M D P S The bandit problem pro vides a natural and simple setting to in v estig ate whether the polic y learns to trade of f between e xploration and e xploitation. Ho we v er , the problem itself in v olv es no sequen- tial decision making, and does not fully characterize the challenges in solving MDPs. Hence, we perform further e xperiments using randomly generated tab ular MDPs, where there is a finite num- ber of possible states and acti o ns —small enough that the transition probability distrib ution can be e xplicitly gi v en as a table. W e compare our approach with the follo wing methods: • Random: the agent chooses an action uniformly at random for each time step; • PSRL (Strens, 2000; Osband et al., 2013): this is a direct generalization of Thompson sam- pling to MDPs, where at the be ginning of each episode, we sample an MDP from the pos- terior distrib ution, and tak e actions according to the optimal polic y for the entire episode. Similarly , we include an optimistic v ariant (OPSRL), which has also been e xplored in Os- band & V an Ro y (2016). • BEB (K olter & Ng, 2009): this is a model-based optimistic algorithm that adds an e xplo- ration bonus to (thus f ar) infrequently visited states and actions. 5 Under re vie w as a conference paper at ICLR 2017 • UCRL2 (Jaksch et al., 2010): this algorithm computes, at each iter ation, the optimal pol- ic y ag ainst an optimistic MDP under the current belief, using an e xtended v alue iteration procedure. • -Greedy: this algorithm tak es a ctions optimal ag ainst the MAP estimate according to the current posterior , which is updated once per episode. • Greedy: a special case of -Greedy with = 0 . T able 2: Random MDP Results Setup Random PSRL OPSRL UCRL2 BEB -Gr eedy Gr eedy RL 2 n = 10 100 . 1 138 . 1 144 . 1 146 . 6 150 . 2 132 . 8 134 . 8 156 . 2 n = 25 250 . 2 408 . 8 425 . 2 424 . 1 427 . 8 377 . 3 368 . 8 445 . 7 n = 50 499 . 7 904 . 4 930 . 7 918 . 9 917 . 8 823 . 3 769 . 3 936 . 1 n = 75 749 . 9 1417 . 1 1449 . 2 1427 . 6 1422 . 6 1293 . 9 1172 . 9 1428 . 8 n = 100 999 . 4 1939 . 5 1973 . 9 1942 . 1 1935 . 1 1778 . 2 1578 . 5 1913 . 7 The distrib ution o v er MDPs is constructed with |S | = 10 , |A| = 5 . The re w ards follo w a Gaus- sian distrib ution with unit v ariance, and the mean parameters are sampled independently from Normal(1 , 1) . The transitions are sampled from a flat Dirichlet distrib ution. This construction matches the commonly used prior in Bayesian RL methods. W e set the horizon for each episode to be T = 10 , and an episode al w ays starts on the first state. 0 1000 5000 Iteration 0 1 Normalized total reward n = 10 n = 25 n = 50 n = 75 n = 100 OPSRL Figure 3: RL 2 learning curv es for tab ular MDPs. Performance is normalized such that OPSRL scores 1 , and random polic y scores 0 . The results are summarized in T able 2, and the learning curv es are sho wn in Figure 3. W e follo w the same e v aluation procedure as in the bandit case. W e e xperiment with n ∈ { 10 , 25 , 50 , 75 , 100 } . F or fe wer episodes, our approach surprisingly outperforms e xisting methods by a lar ge mar gin. The adv antage is re v ersed as n increases, suggesting that the reinforcement learning problem in the outer loop becomes more challenging to solv e. W e think that the adv antage for small n comes from the need for more aggressi v e e xploitation: since there are 140 de grees of freedom to estimate in order to characterize the MDP , and by the 10 th episode, we will not ha v e enough samples to form a good es timate of the entire dynamics. By directly optimizing the RNN in this setting, our approach should be able to cope with this shortage of samples, and decides to e xploit sooner compared to the reference algorithms. 3 . 3 V I S U A L N A V I G A T I O N The pre vious tw o tasks both only in v olv e v ery lo w-dimensional state spaces. T o e v aluate the fea- sibility of scaling up RL 2 , we further e xperiment with a challengi ng vision-based task, where the 6 Under re vie w as a conference paper at ICLR 2017 agent is ask ed to na vig ate a randomly generated maze to find a randomly placed tar get 2 . The agent recei v es a +1 re w ard when it reaches the tar get, − 0 . 001 when it hits the w all, and − 0 . 04 per tim e step to encourage it to reach tar gets f aster . It can interact with the maze for multiple episodes, dur - ing which the maze structure and tar get position are held fix ed. The optimal strate gy is to e xplore the maze ef ficiently during the first episode, and after locating the tar get, act optimally ag ainst the current maze and tar get based on the collected information. An illustration of the task is gi v en in Figure 4. (a) Sample observ ation (b) Layout of the 5 × 5 maze in (a) (c) Layout of a 9 × 9 maze Figure 4: V isual na vig ati on. The tar get block is sho wn in red, and occupies an entire grid in the maze layout. V isual na vig ation alone is a challenging task for reinforcement learning. The agent only recei v es v ery sparse re w a rds during training, and does not ha v e the primiti v es for ef ficient e xploration at the be ginning of training. It also needs to mak e ef ficient use of memory to decide ho w it should e xplore the space, without for getting about where it has already e xplored. Pre viously , Oh et al. (2016) ha v e studied similar vision-based na vig ation tasks in Minecraft. Ho we v er , the y use higher -le v el actions for ef ficient na vig ation. Similar high-le v el actions in our task w ould each require around 5 lo w-le v el actions combined in the right w ay . In contrast, our RL 2 agent needs to learn these higher -le v el actions from scratch. W e use a simple training setup, where we use small mazes of size 5 × 5 , with 2 episodes of interac- tion, each with horizon up to 250 . Here the size of the maze is measured by the number of grid cells along each w all in a discrete representation of the maze. During each trial, we sample 1 out of 1000 randomly generated configurations of map layout and tar get positions. During testing, we e v aluate on 1000 separately generated configurations. In addition, we also study its e xtrapolation beha vior along tw o ax es , by (1) testing on lar ge mazes of size 9 × 9 (see Figure 4c) and (2) running the agent for up to 5 episodes in both small and lar ge maz es. F or the lar ge maze, we also increase the horizon per episode by 4x due to the increased size of the maze. T able 3: Results for visual na vig ation. These metrics are computed using t he best run among all runs sho wn in Figure 5. In 3c, we measure the proportion of mazes where the trajectory length in the second episode does not e xceed the trajectory length in the first episode. (a) A v erage length of successful trajectories Episode Small Lar ge 1 52 . 4 ± 1 . 3 180 . 1 ± 6 . 0 2 39 . 1 ± 0 . 9 151 . 8 ± 5 . 9 3 42 . 6 ± 1 . 0 169 . 3 ± 6 . 3 4 43 . 5 ± 1 . 1 162 . 3 ± 6 . 4 5 43 . 9 ± 1 . 1 169 . 3 ± 6 . 5 (b) %Success Episode Small Lar ge 1 99 . 3% 97 . 1% 2 99 . 6% 96 . 7% 3 99 . 7% 95 . 8% 4 99 . 4% 95 . 6% 5 99 . 6% 96 . 1% (c) %Impro v ed Small Lar ge 91 . 7% 71 . 4% 2 V ideos for the task are a v ailable at https://goo.gl/rDDBpb . 7 Under re vie w as a conference paper at ICLR 2017 0 500 1000 1500 2000 2500 3000 3500 Iteration 16 14 12 10 8 6 4 2 0 Total reward Figure 5: RL 2 learning curv es for visual na vig ation. Each curv e sho ws a dif ferent random initial- ization of the RNN weights. Performance v aries greatly across dif ferent initializations. The results are summarized in T able 3, and the learning curv es are sho wn in Figure 5. W e observ e that there is a significant reduction in trajectory lengths between the first tw o episodes in both the smaller and lar ger mazes, suggesting that the agent has learned ho w to use information from past episodes. It also achie v es reasonable e xtrapolation beha vior in fur ther episodes by maintaining its performance, although there is a small drop in the rate of success in the lar ger mazes. W e also observ e that on lar ger mazes, the ratio of impro v ed trajectories is lo wer , lik ely because the agent has not learned ho w to act optimally in the lar ger mazes. Still, e v en on the small mazes, the agent does not learn to perfectly reuse prior information. An illustration of the agent’ s beha vior is sho wn in Figure 6. The intended beha vior , which occurs most frequently , as sho wn in 6a and 6b, is that the agent should remember the tar get’ s location, and utilize it to act optimally in the second episode. Ho we v er , occasionally the agent for gets about where the tar get w as, and continues to e xplore in the second episode, as sho wn in 6c and 6d. W e belie v e that better reinforcement learning techniques used as the outer -loop algorithm will impro v e these results in the future. (a) Good beha vior , 1st episode (b) Good beha vior , 2nd episode (c) Bad beha vior , 1st episode (d) Bad beha vior , 2nd episode Figure 6: V isualization of the agent’ s beha vior . In each scenario, the agent starts at the center of the blue block, and the goal is to reach an ywhere in the red block. 4 R E L A T E D W O R K The concept of using prior e xperience to speed up reinforcement learning algorithms has been e x- plored in the past in v arious forms. Earlier studies ha v e in v estig ated automatic tuning of h yper - parameters, such as learning rate and temperature (Ishii et al., 2002; Schweighofer & Do ya, 2003), as a form of meta-learning. W ilson et al . (2007) use hierarchical Bayesian methods to maintain a posterior o v er possible model s of dynamics, and apply optimistic Thompson sampling according to the posterior . Man y w orks in hierarchical reinforcement learning propose to e xtract reusable skills from pre vious tasks to speed up e xploration in ne w tasks (Singh, 1992; Perkins et al., 1999). W e refer the reader to T aylor & Stone (2009) for a more thorough surv e y on the multi-task and transfer learning aspects. 8 Under revie w as a conference paper at ICLR 2017 More recently , Fu et al. (2015) propose a model-based approach on top of iLQG with unknown dynamics (Levine & Abbeel, 2014), which uses samples collected from previous tasks to build a neural network prior for the dynamics, and can perform one-shot learning on ne w , but related tasks thanks to reduced sample comple xity . There has been a gro wing interest in using deep neural networks for multi-task learning and transfer learning (Parisotto et al., 2015; Rusu et al., 2015; 2016a; Devin et al., 2016; Rusu et al., 2016b). In the broader context of machine learning, there has been a lot of interest in one-shot learning for object classification (V ilalta & Drissi, 2002; Fei-Fei et al., 2006; Larochelle et al., 2008; Lake et al., 2011; K och, 2015). Our work draws inspiration from a particular line of work (Y ounger et al., 2001; Santoro et al., 2016; V inyals et al., 2016), which formulates meta-learning as an optimization problem, and can thus be optimized end-to-end via gradient descent. While these work applies to the supervised learning setting, our w ork applies in the more general reinforcement learning setting. Although the reinforcement learning setting is more challenging, the resulting beha vior is far richer: our agent must not only learn to exploit e xisting information, but also learn to explore, a problem that is usually not a factor in supervised learning. Another line of work (Hochreiter et al., 2001; Y ounger et al., 2001; Andrychowicz et al., 2016; Li & Malik, 2016) studies meta-learning over the optimization process. There, the meta-learner makes explicit updates to a parametrized model. In comparison, we do not use a directly parametrized policy; instead, the recurrent neural network agent acts as the meta-learner and the resulting policy simultaneously . Our formulation essentially constructs a partially observable MDP (POMDP) which is solv ed in the outer loop, where the underlying MDP is unobserved by the agent. This reduction of an unkno wn MDP to a POMDP can be traced back to dual control theory (Feldbaum, 1960), where “dual” refers to the fact that one is controlling both the state and the state estimate. Feldbaum pointed out that the solution can in principle be computed with dynamic programming, b ut doing so is usually im- practical. POMDPs with such structure have also been studied under the name “mix ed observ ability MDPs” (Ong et al., 2010). Howe ver , the method proposed there suf fers from the usual challenges of solving POMDPs in high dimensions. 5 D I S C U S S I O N This paper suggests a different approach for designing better reinforcement learning algorithms: instead of acting as the designers ourselves, learn the algorithm end-to-end using standard rein- forcement learning techniques. That is, the “fast” RL algorithm is a computation whose state is stored in the RNN activ ations, and the RNN’ s weights are learned by a general-purpose “slow” re- inforcement learning algorithm. Our method, RL 2 , has demonstrated competence comparable with theoretically optimal algorithms in small-scale settings. W e ha ve further shown its potential to scale to high-dimensional tasks. In the experiments, we ha ve identified opportunities to improv e upon RL 2 : the outer -loop reinforce- ment learning algorithm was sho wn to be an immediate bottleneck, and we belie ve that for settings with extremely long horizons, better architecture may also be required for the policy . Although we hav e used generic methods and architectures for the outer-loop algorithm and the policy , doing this also ignores the underlying episodic structure. W e e xpect algorithms and polic y architectures that exploit the problem structure to significantly boost the performance. A C K N OW L E D G M E N T S W e would like to thank our colleagues at Berkele y and OpenAI for insightful discussions. This research was funded in part by ONR through a PECASE award. Y an Duan w as also supported by a Berkeley AI Research lab Fello wship and a Hua wei Fellowship. Xi Chen was also supported by a Berkeley AI Research lab Fello wship. W e gratefully ackno wledge the support of the NSF through grant IIS-1619362 and of the ARC through a Laureate Fellowship (FL110100281) and through the ARC Centre of Excellence for Mathematical and Statistical Frontiers. R E F E R E N C E S Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthe w W Hoffman, David Pfau, T om Schaul, and Nando de Freitas. Learning to learn by gradient descent by gradient descent. arXiv pr eprint 9 Under revie w as a conference paper at ICLR 2017 arXiv:1606.04474 , 2016. Jean-Yves Audibert and R ´ emi Munos. Introduction to bandits: Algorithms and theory . ICML T utorial on bandits , 2011. Peter Auer . Using confidence bounds for exploitation-e xploration trade-of fs. Journal of Machine Learning Resear ch , 3(Nov):397–422, 2002. Y oshua Bengio, Patrice Simard, and Paolo Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE transactions on neur al networks , 5(2):157–166, 1994. S ´ ebastien Bubeck and Nicolo Cesa-Bianchi. Regret analysis of stochastic and nonstochastic multi- armed bandit problems. arXiv preprint , 2012. Jhelum Chakravorty and Aditya Mahajan. Multi-armed bandits, gittins inde x, and its calculation. Methods and Applications of Statistics in Clinical T rials: Planning, Analysis, and Infer ential Methods , 2:416–435, 2013. Olivier Chapelle and Lihong Li. An empirical ev aluation of thompson sampling. In Advances in neural information pr ocessing systems , pp. 2249–2257, 2011. Kyungh yun Cho, Bart V an Merri ¨ enboer , Dzmitry Bahdanau, and Y oshua Bengio. On the properties of neural machine translation: Encoder-decoder approaches. arXiv pr eprint arXiv:1409.1259 , 2014. Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Y oshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv pr eprint arXiv:1412.3555 , 2014. Marc Deisenroth and Carl E Rasmussen. Pilco: A model-based and data-efficient approach to polic y search. In Pr oceedings of the 28th International Confer ence on mac hine learning (ICML-11) , pp. 465–472, 2011. Coline Devin, Abhishek Gupta, T revor Darrell, Pieter Abbeel, and Serge y Levine. Learning modular neural netw ork policies for multi-task and multi-robot transfer . arXiv pr eprint arXiv:1609.07088 , 2016. Li Fei-Fei, Rob Fergus, and Pietro Perona. One-shot learning of object categories. IEEE transactions on pattern analysis and machine intelligence , 28(4):594–611, 2006. AA Feldbaum. Dual control theory . i. A vtomatika i T elemekhanika , 21(9):1240–1249, 1960. Justin Fu, Ser gey Le vine, and Pieter Abbeel. One-shot learning of manipulation skills with online dynamics adaptation and neural network priors. arXiv pr eprint arXiv:1509.06841 , 2015. Mohammad Ghav amzadeh, Shie Mannor , Joelle Pineau, A viv T amar , et al. Bayesian r einforcement learning: a survey . W orld Scientific, 2015. John Gittins, K evin Glazebrook, and Richard W eber . Multi-armed bandit allocation indices . John W iley & Sons, 2011. John C Gittins. Bandit processes and dynamic allocation indices. Journal of the Royal Statistical Society . Series B (Methodological) , pp. 148–177, 1979. Xiaoxiao Guo, Satinder Singh, Honglak Lee, Richard L Lewis, and Xiaoshi W ang. Deep learning for real-time atari game play using of fline monte-carlo tree search planning. In Advances in neural information pr ocessing systems , pp. 3338–3346, 2014. Nicolas Heess, Gregory W ayne, Da vid Silv er, T im Lillicrap, T om Erez, and Y uv al T assa. Learning continuous control policies by stochastic v alue gradients. In Advances in Neural Information Pr ocessing Systems , pp. 2944–2952, 2015. Sepp Hochreiter , A Ste ven Y ounger , and Peter R Conwell. Learning to learn using gradient descent. In International Confer ence on Artificial Neural Networks , pp. 87–94. Springer , 2001. 10 Under revie w as a conference paper at ICLR 2017 Shin Ishii, W ako Y oshida, and Junichiro Y oshimoto. Control of exploitation–e xploration meta- parameter in reinforcement learning. Neural networks , 15(4):665–687, 2002. Thomas Jaksch, Ronald Ortner, and Peter Auer . Near-optimal regret bounds for reinforcement learning. Journal of Machine Learning Resear ch , 11(Apr):1563–1600, 2010. Rafal J ´ ozefowicz, W ojciech Zaremba, and Ilya Sutskev er . An empirical exploration of recur- rent network architectures. In Pr oceedings of the 32nd International Confer ence on Machine Learning, ICML 2015, Lille, F rance, 6-11 J uly 2015 , pp. 2342–2350, 2015. URL http: //jmlr.org/proceedings/papers/v37/jozefowicz15.html . Michał Kempka, Marek W ydmuch, Grzegorz Runc, Jakub T oczek, and W ojciech Ja ´ sko wski. V iz- doom: A doom-based ai research platform for visual reinforcement learning. arXiv preprint arXiv:1605.02097 , 2016. Gregory K och. Siamese neur al networks for one-shot image r ecognition . PhD thesis, Uni versity of T oronto, 2015. J Zico Kolter and Andrew Y Ng. Near-bayesian exploration in polynomial time. In Pr oceedings of the 26th Annual International Confer ence on Machine Learning , pp. 513–520. A CM, 2009. Brenden M Lake, Ruslan Salakhutdino v , Jason Gross, and Joshua B T enenbaum. One shot learning of simple visual concepts. In Pr oceedings of the 33rd Annual Confer ence of the Co gnitive Science Society , volume 172, pp. 2, 2011. Hugo Larochelle, Dumitru Erhan, and Y oshua Bengio. Zero-data learning of ne w tasks. In AAAI , volume 1, pp. 3, 2008. Serge y Le vine and Pieter Abbeel. Learning neural network policies with guided policy search under unknown dynamics. In Advances in Neural Information Pr ocessing Systems , pp. 1071–1079, 2014. Serge y Levine, Chelsea Finn, T rev or Darrell, and Pieter Abbeel. End-to-end training of deep visuo- motor policies. Journal of Machine Learning Resear ch , 17(39):1–40, 2016. Ke Li and Jitendra Malik. Learning to optimize. arXiv pr eprint arXiv:1606.01885 , 2016. T imothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, T om Erez, Y uv al T assa, David Silver , and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv pr eprint arXiv:1509.02971 , 2015. Benedict C May , Nathan K orda, Anthony Lee, and Da vid S Leslie. Optimistic bayesian sampling in contextual-bandit problems. Journal of Mac hine Learning Resear ch , 13(Jun):2069–2106, 2012. V olodymyr Mnih, K oray Ka vukcuoglu, Da vid Silver , Andrei A Rusu, Joel V eness, Marc G Belle- mare, Ale x Gra ves, Martin Riedmiller , Andreas K Fidjeland, Georg Ostrovski, et al. Human-lev el control through deep reinforcement learning. Nature , 518(7540):529–533, 2015. Junhyuk Oh, V alliappa Chockalingam, Satinder Singh, and Honglak Lee. Control of memory , acti ve perception, and action in minecraft. arXiv preprint , 2016. Sylvie CW Ong, Shao W ei Png, David Hsu, and W ee Sun Lee. Planning under uncertainty for robotic tasks with mixed observability . The International J ournal of Robotics Resear ch , 29(8): 1053–1068, 2010. Ian Osband and Benjamin V an Roy . Why is posterior sampling better than optimism for reinforce- ment learning. arXiv preprint , 2016. Ian Osband, Dan Russo, and Benjamin V an Roy . (more) ef ficient reinforcement learning via poste- rior sampling. In Advances in Neural Information Pr ocessing Systems , pp. 3003–3011, 2013. Emilio Parisotto, Jimmy Lei Ba, and Ruslan Salakhutdinov . Actor-mimic: Deep multitask and transfer reinforcement learning. arXiv preprint , 2015. 11 Under revie w as a conference paper at ICLR 2017 Theodore J Perkins, Doina Precup, et al. Using options for kno wledge transfer in reinforcement learning. University of Massachusetts, Amherst, MA, USA, T ech. Rep , 1999. Andrei A Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirk- patrick, Razv an Pascanu, V olodymyr Mnih, K oray Kavukcuoglu, and Raia Hadsell. Policy distil- lation. arXiv preprint , 2015. Andrei A Rusu, Neil C Rabino witz, Guillaume Desjardins, Hubert Soyer , James Kirkpatrick, K oray Kavukcuoglu, Razvan P ascanu, and Raia Hadsell. Progressiv e neural networks. arXiv preprint arXiv:1606.04671 , 2016a. Andrei A Rusu, Matej V ecerik, Thomas Roth ¨ orl, Nicolas Heess, Razv an P ascanu, and Raia Hadsell. Sim-to-real robot learning from pixels with progressi ve nets. arXiv pr eprint arXiv:1610.04286 , 2016b. Adam Santoro, Sergey Bartunov , Matthew Botvinick, Daan Wierstra, and T imothy Lillicrap. One- shot learning with memory-augmented neural networks. arXiv pr eprint arXiv:1605.06065 , 2016. John Schulman, Ser gey Le vine, Philipp Moritz, Michael I Jordan, and Pieter Abbeel. Trust region policy optimization. CoRR, abs/1502.05477 , 2015. John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized adv antage estimation. In International Con- fer ence on Learning Representations (ICLR2016) , 2016. Nicolas Schweighofer and Kenji Do ya. Meta-learning in reinforcement learning. Neural Networks , 16(1):5–9, 2003. Satinder Pal Singh. Transfer of learning by composing solutions of elemental sequential tasks. Machine Learning , 8(3-4):323–339, 1992. Malcolm Strens. A bayesian framework for reinforcement learning. In ICML , pp. 943–950, 2000. Matthew E T aylor and Peter Stone. T ransfer learning for reinforcement learning domains: A surve y . Journal of Mac hine Learning Resear ch , 10(Jul):1633–1685, 2009. W illiam R Thompson. On the likelihood that one unkno wn probability e xceeds another in view of the evidence of tw o samples. Biometrika , 25(3/4):285–294, 1933. Ricardo V ilalta and Y oussef Drissi. A perspectiv e view and surve y of meta-learning. Artificial Intelligence Revie w , 18(2):77–95, 2002. Oriol V inyals, Charles Blundell, T imothy Lillicrap, K oray Kavukcuoglu, and Daan W ierstra. Match- ing networks for one shot learning. arXiv pr eprint arXiv:1606.04080 , 2016. Niklas W ahlstr ¨ om, Thomas B Sch ¨ on, and Marc Peter Deisenroth. From pixels to torques: Policy learning with deep dynamical models. arXiv preprint , 2015. Manuel W atter , Jost Springenberg, Joschka Boedecker , and Martin Riedmiller . Embed to control: A locally linear latent dynamics model for control from raw images. In Advances in Neur al Information Pr ocessing Systems , pp. 2746–2754, 2015. Peter Whittle. Optimization over time . John Wile y & Sons, Inc., 1982. Aaron W ilson, Alan Fern, Soumya Ray , and Prasad T adepalli. Multi-task reinforcement learning: a hierarchical bayesian approach. In Pr oceedings of the 24th international conference on Machine learning , pp. 1015–1022. A CM, 2007. A Stev en Y ounger, Sepp Hochreiter , and Peter R Conwell. Meta-learning with backpropagation. In Neural Networks, 2001. Pr oceedings. IJCNN’01. International Joint Confer ence on , volume 3. IEEE, 2001. 12 Under revie w as a conference paper at ICLR 2017 A P P E N D I X A D E TA I L E D E X P E R I M E N T S E T U P Common to all experiments: as mentioned in Section 2.2, we use placeholder v alues when neces- sary . For e xample, at t = 0 there is no previous action, rew ard, or termination flag. Since all of our experiments use discrete actions, we use the embedding of the action 0 as a placeholder for actions, and 0 for both the rewards and termination flags. T o form the input to the GR U, we use the v alues for the rewards and termination flags as-is, and embed the states and actions as described separately below for each experiments. These values are then concatenated together to form the joint embedding. For the neural netw ork architecture, W e use rectified linear units throughout the e xperiments as the hidden acti vation, and we apply weight normalization without data-dependent initialization (Sali- mans & Kingma, 2016) to all weight matrices. The hidden-to-hidden weight matrix uses an orthog- onal initialization (Saxe et al., 2013), and all other weight matrices use Xavier initialization (Glorot & Bengio, 2010). W e initialize all bias v ectors to 0 . Unless otherwise mentioned, the policy and the baseline uses separate neural netw orks with the same architecture until the final layer , where the number of outputs differ . All experiments are implemented using T ensorFlow (Abadi et al., 2016) and rllab (Duan et al., 2016). W e use the implementations of classic algorithms pro vided by the T abulaRL package (Os- band, 2016). A . 1 M U LT I - A R M E D BA N D I T S The parameters for TRPO are sho wn in T able 1. Since the en vironment is stateless, we use a constant embedding 0 as a placeholder in place of the states, and a one-hot embedding for the actions. T able 1: Hyperparameters for TRPO: multi-armed bandits Discount 0 . 99 GAE λ 0 . 3 Policy Iters Up to 1000 #GR U Units 256 Mean KL 0 . 01 Batch size 250000 A . 2 T A B U L A R M D P S The parameters for TRPO are sho wn in T able 2. W e use a one-hot embedding for the states and actions separately , which are then concatenated together . T able 2: Hyperparameters for TRPO: tabular MDPs Discount 0 . 99 GAE λ 0 . 3 Policy Iters Up to 10000 #GR U Units 256 Mean KL 0 . 01 Batch size 250000 A . 3 V I S U A L N A V I G A T I O N The parameters for TRPO are sho wn in T able 3. For this task, we use a neural network to form the joint embedding. W e rescale the images to have width 40 and height 30 with RGB channels preserved, and we recenter the RGB v alues to lie within range [ − 1 , 1] . Then, this preprocessed 13 Under revie w as a conference paper at ICLR 2017 image is passed through 2 con volution layers, each with 16 filters of size 5 × 5 and stride 2 . The action is first embedded into a 256 -dimensional vector where the embedding is learned, and then concatenated with the flattened output of the final con volution layer . The joint vector is then fed to a fully connected layer with 256 hidden units. Unlike pre vious e xperiments, we let the policy and the baseline share the same neural network. W e found this to improve the stability of training baselines and also the end performance of the policy , possibly due to regularization effects and better learned features imposed by weight sharing. Similar weight-sharing techniques hav e also been explored in (Mnih et al., 2016). T able 3: Hyperparameters for TRPO: visual navigation Discount 0 . 99 GAE λ 0 . 99 Policy Iters Up to 5000 #GR U Units 256 Mean KL 0 . 01 Batch size 50000 R E F E R E N C E S Martın Abadi, Ashish Agarwal, Paul Barham, Eugene Bre vdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jef frey Dean, Matthieu De vin, et al. T ensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv pr eprint arXiv:1603.04467 , 2016. Y an Duan, Xi Chen, Rein Houthooft, John Schulman, and Pieter Abbeel. Benchmarking deep reinforcement learning for continuous control. arXiv preprint , 2016. Xavier Glorot and Y oshua Bengio. Understanding the dif ficulty of training deep feedforward neural networks. In Aistats , volume 9, pp. 249–256, 2010. V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Ale x Grav es, T imothy P Lillicrap, T im Harley , David Silver , and K oray Ka vukcuoglu. Asynchronous methods for deep reinforcement learning. arXiv preprint , 2016. Ian Osband. T abulaRL. https://github.com/iosband/TabulaRL , 2016. T im Salimans and Diederik P Kingma. W eight normalization: A simple reparameterization to ac- celerate training of deep neural networks. arXiv pr eprint arXiv:1602.07868 , 2016. Andrew M Sax e, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynam- ics of learning in deep linear neural networks. arXiv pr eprint arXiv:1312.6120 , 2013. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment