문자 기반 다국어 성격 특성 인식 모델
본 논문은 문자 수준의 입력을 이용해 계층적 신경망을 구성함으로써 영어, 스페인어, 이탈리아어 트윗에서 빅5 성격 특성을 예측한다. 특성 엔지니어링 없이도 기존 최첨단 방법들을 능가하는 성능을 보이며, 언어 독립성을 입증한다.
저자: Fei Liu, Julien Perez, Scott Nowson
본 논문은 “문자 기반 다국어 성격 특성 인식 모델”이라는 제목 아래, 텍스트의 가장 작은 단위인 문자에서 시작해 계층적으로 단어와 문장을 구성하고, 이를 통해 사용자의 빅5 성격 점수를 예측하는 새로운 딥러닝 프레임워크를 제시한다. 서론에서는 언어 사용이 성격과 깊은 연관이 있다는 심리학적 배경을 소개하고, 기존 연구들이 주로 단어‑레벨의 bag‑of‑words 혹은 LIWC와 같은 언어‑특정 사전 기반 특징을 사용해 SVM이나 선형 회귀 모델을 적용해 왔음을 지적한다. 이러한 접근은 특징 설계에 많은 인적·시간 비용이 들고, 언어마다 별도의 사전 구축이 필요하다는 단점을 가진다. 특히 소셜 미디어와 같이 비정형 텍스트가 많은 환경에서는 OOV(Out‑Of‑Vocabulary) 문제가 심각해진다.
관련 연구 섹션에서는 초기 SVM 기반 방법, 최근의 딥러닝 기반 모델(MLP, RNN) 등을 정리하고, 이들 대부분이 여전히 손수 만든 언어‑특정 특징에 의존하고 있음을 강조한다. 또한 Ling et al. (2015)의 문자‑레벨 단어 임베딩(C2W)과 Yang et al. (2016)의 계층적 어텐션 네트워크(W2S2D)를 소개하며, 본 연구가 이 두 접근을 결합해 문자‑단어‑문장‑특성의 4단계 구조(C2W2S4PT)를 구현한다는 점을 명시한다.
제안 모델 파트에서는 먼저 문자 임베딩 행렬 Ec 를 정의하고, 각 단어를 구성하는 문자 시퀀스를 양방향 GRU(Char‑Bi‑RNN)에 입력한다. 앞·뒤 마지막 은닉 상태를 연결해 단어 벡터 ew_i 를 생성한다. 이후 이 단어 벡터들을 또 다른 양방향 GRU(Word‑Bi‑RNN)에 넣어 문장 수준 표현 es 를 만든다. 최종적으로는 ReLU 활성화와 하나의 은닉층을 거친 뒤 선형 레이어를 통해 연속형 성격 점수 ŷ_s 를 출력한다. 손실 함수는 평균 제곱오차(MSE)이며, 전체 네트워크는 역전파를 통해 동시에 학습된다. 모델의 파라미터 수는 문자‑레벨 임베딩과 양방향 GRU 두 개만으로, 전통적인 단어‑레벨 임베딩에 비해 크게 절감된다.
실험 설계는 PAN‑2015 Author Profiling 대회에서 제공된 트위터 데이터(영어, 스페인어, 이탈리아어)를 사용한다. 각 사용자는 평균 100개의 트윗을 가지고 있으며, 성격 라벨은 BFI‑10 설문을 기반으로 -0.5~0.5 사이의 연속값으로 제공된다. 전처리 단계에서는 트위터 특유의 URL·멘션을 각각 ^와 @ 로 치환해 잡음 요소를 최소화하였다. 평가 방법은 두 가지로 나뉜다. 첫 번째는 사용자 수준에서 모든 트윗을 모아 평균 점수를 예측하고, 두 번째는 개별 트윗 단위에서 직접 점수를 예측한다. 비교 대상은 (1) 전통적인 SVM‑기반 특성 엔지니어링 모델, (2) 최근 딥러닝 기반 모델(MLP, RNN)이며, 모두 동일한 데이터 분할과 평가 지표(Pearson 상관계수)를 사용한다.
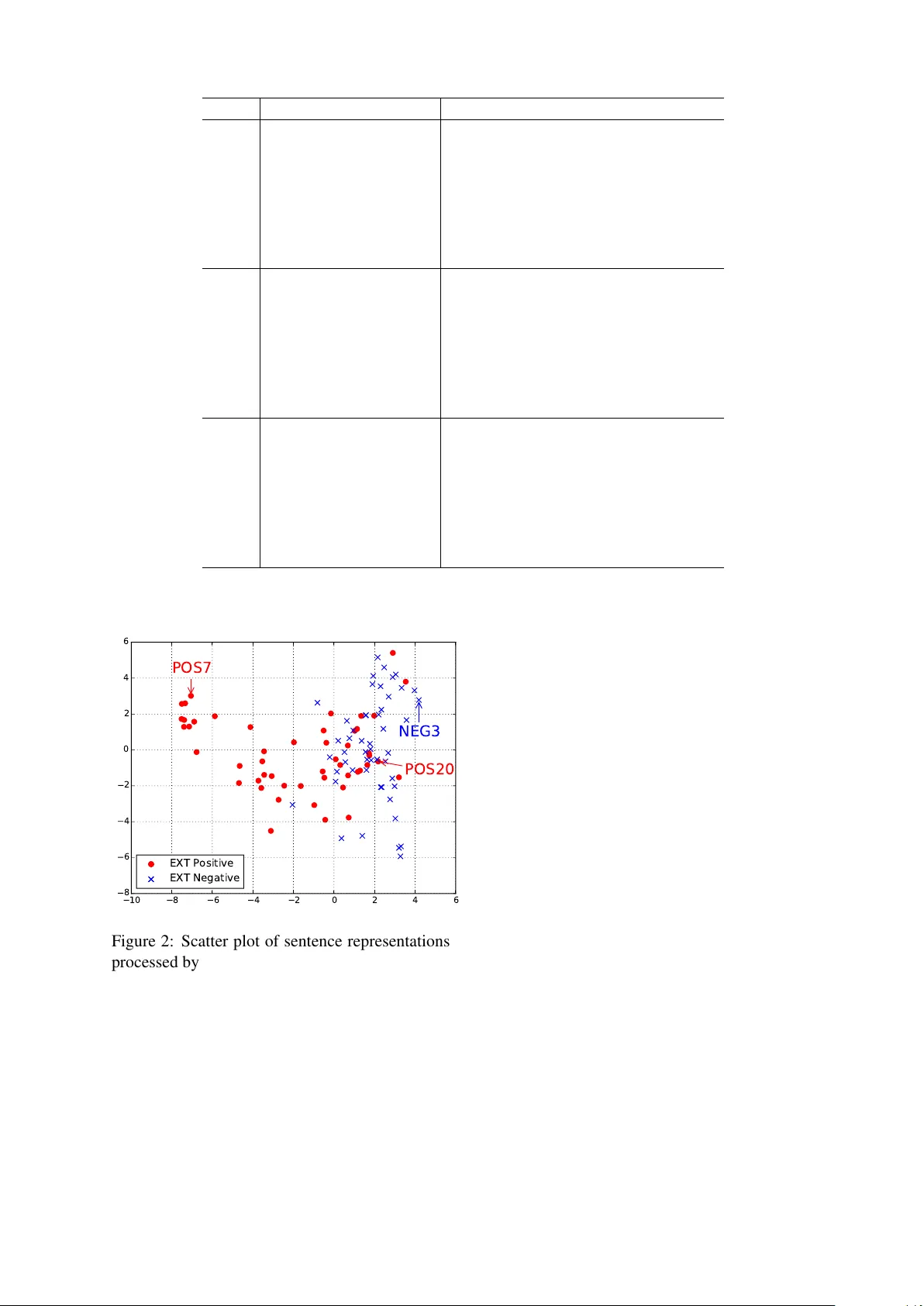
결과는 영어와 스페인어에서 모든 다섯 성격 특성(외향성, 개방성, 친화성, 성실성, 신경성)에 대해 기존 최고 기록을 능가하는 상관계수를 기록하였다. 특히 외향성과 신경성에서 가장 큰 개선을 보였으며, 이탈리아어에서는 기존 모델과 동등한 수준을 유지했다. 개별 트윗 수준에서도 제안 모델이 다른 비특징 기반 모델보다 일관되게 높은 성능을 보였다. 시각화 실험에서는 특정 문자·패턴(예: 감탄사, 반복 문자)이 특정 성격 특성과 강하게 연관됨을 확인했지만, 이러한 연관성을 정량적으로 해석하는 작업은 향후 과제로 남았다.
논의에서는 모델이 언어‑독립적이라는 강점과 동시에, 트윗이라는 짧은 텍스트 특성상 문맥 정보가 제한적이라는 한계를 언급한다. 또한, 감정·주제 변동성이 큰 소셜 미디어 데이터에서는 개방성 같은 특성 예측이 상대적으로 낮은 점수를 보였다. 향후 연구 방향으로는 (1) 다중‑문장 혹은 장문 데이터에 대한 확장, (2) 어텐션 메커니즘 도입을 통한 중요한 문자·단어 강조, (3) 다언어 사전 학습 모델(BERT, XLM‑R)과의 하이브리드 구조 탐색, (4) 모델 해석 가능성을 높이기 위한 시각화 및 설명 기법 개발 등을 제시한다.
결론적으로, 본 논문은 문자 수준부터 시작하는 완전한 계층적 신경망이 언어‑특정 전처리 없이도 다국어 성격 특성 인식에서 최첨단 성능을 달성할 수 있음을 실증하였다. 이는 향후 언어 자원이 부족한 저자 프로파일링 작업이나, 다양한 언어 환경에서의 자동 성격 분석에 중요한 기반이 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기