A Language-independent and Compositional Model for Personality Trait Recognition from Short Texts
Many methods have been used to recognize author personality traits from text, typically combining linguistic feature engineering with shallow learning models, e.g. linear regression or Support Vector Machines. This work uses deep-learning-based model…
Authors: Fei Liu, Julien Perez, Scott Nowson
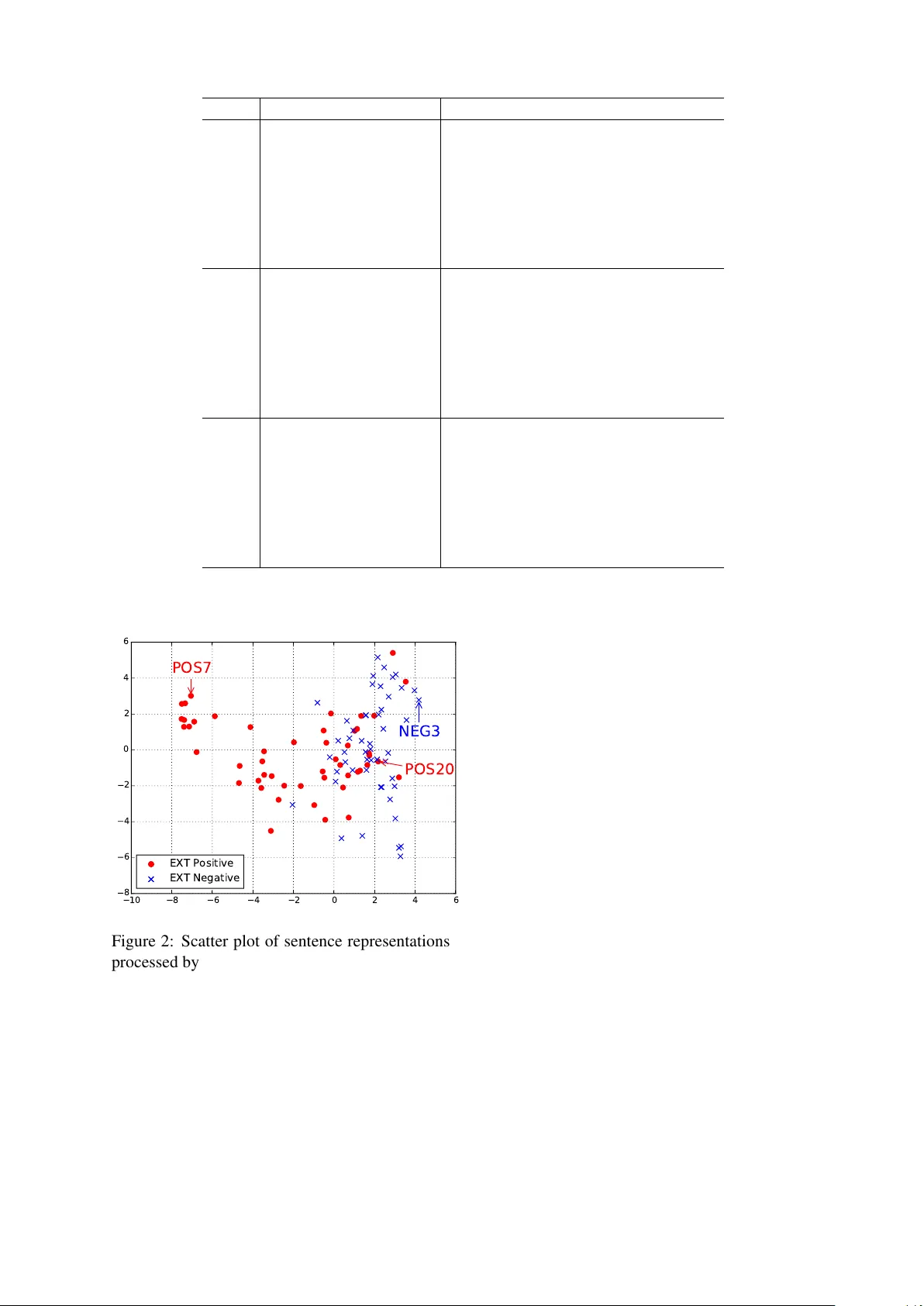
A Language-independent and Compositional Model f or P ersonality T rait Recognition fr om Short T exts F ei Liu Julien P er ez Xerox Research Center Europe firstname.lastname@xrce.xerox.com Scott Nowson Abstract Many methods have been used to recog- nise author personality traits from text, typically combining linguistic feature en- gineering with shallo w learning models, e.g. linear regression or Support V ector Machines. This w ork uses deep-learning- based models and atomic features of text – the characters – to build hierarchical, vec- torial word and sentence representations for trait inference. This method, applied to a corpus of tweets, sho ws state-of-the- art performance across fi ve traits and three languages (English, Spanish and Italian) compared with prior work in author profil- ing. The results, supported by preliminary visualisation work, are encouraging for the ability to detect complex human traits. 1 Introduction T echniques falling under the umbrella of “deep- learning” are increasingly commonplace in the space of Natural Language Processing (NLP) (Manning, 2016). Such methods hav e been ap- plied to a number of tasks from part-of-speech- tagging (Ling et al., 2015; Huang et al., 2015) to sentiment analysis (Socher et al., 2013; Kalch- brenner et al., 2014; Kim, 2014). Essentially , each of these tasks is concerned with learning represen- tations of language at different levels. The work we outline here is no dif ferent in essence, though we choose perhaps the highest le vel of represen- tation – that of the author of a gi ven text rather than the text itself. This task, modelling peo- ple from their language, is one built on the long- standing foundation that language use is known to be influenced by sociodemographic characteris- tics such as gender and personality (T annen, 1990; Pennebaker et al., 2003). The study of personality traits in particular is supported by the notion that they are considered temporally stable (Matthews et al., 2003), and thus our modelling ability is en- riched by the acquisition of more data ov er time. Computational personality recognition, and its broader applications, is becoming of increasing in- terest with workshops exploring the topic (Celli et al., 2014; Tkal ˇ ci ˇ c et al., 2014). The addition of personality traits in the P AN Author Profiling challenge at CLEF in 2015 (Rangel et al., 2015) is further e vidence. Much prior literature in this field has used some v ariation of enriched bag-of-words; e.g. the Open vocab ulary approach (Schwartz et al., 2013). This is understandable as exploring the relationship between w ord use and traits has deli v- ered significant insight into aspects of human be- haviour (Pennebaker et al., 2003). Dif ferent lev- els of representation of language have been used such as syntactic, semantic, and higher -order such as the psychologically-deri ved le xica of the Lin- guistic Inquiry and W ord Count (LIWC) tool (Pen- nebaker et al., 2015). One drawback of this bag-of-linguistic-features approach is that considerable ef fort can be spent on feature engineering. Moreov er , such linguis- tic features are mostly language-dependent, such as LIWC (Pennebaker et al., 2015), making the adoptation to multi-lingual models more time- comsuming. Another issue is an unspoken as- sumption that these features, like the traits to which they relate, are similarly stable: the same language features always indicate the same traits. Ho wev er , this is not the case. As Nowson and Gill (2014) have shown, the relationship between language and personality is not consistent across all forms of communication the relationship is more complex. In order to better e xplore this complexity in this work we propose a novel deep-learning feature- engineering-free modelisation of the problem of personality trait recognition, making the model language independent and enablling it to work in various languages without the need to create language-specific linguistic features. The task is framed as one of supervised sequence regression based on a joint atomic representation of the text: specifically on the character and word le vel. In this context, we are exploring short texts. T ypi- cally , classification of such texts tends to be partic- ularly challenging for state-of-the-art BoW based approaches due, in part, to the noisy nature of such data (Han and Baldwin, 2011). T o cope with this we propose a novel recurrent and compositional neural network architecture, capable of construct- ing representations at character , word and sen- tence lev el. W e believ e a latent representation in- ference based on a parse-free input representation of the text seen as a sequence of characters can bal- ance the bias and v ariance of such sparse dataset. The paper is structured as follows: after we con- sider previous approaches to the task of compu- tational personality recognition, including those which have a deep-learning component, we de- scribe our model. W e report on two sets of ex- periments, the first of which demonstrates the ef- fecti veness of the model in inferring personality for users, while the second reports on the short text le vel analysis. In both settings, the pro- posed model achie ves state-of-the-art performance across fi ve personality traits and three languages. 2 Related W ork Early work on computational personality recogni- tion (Argamon et al., 2005; Nowson and Oberlan- der , 2006) used SVM-based approaches and ma- nipulated lexical and grammatical feature sets. T o- day , according to the organisers (Rangel et al., 2015) “most” participants to the P AN 2015 Au- thor Profiling task still use a combination of SVM and feature engineering. Data labelled with per- sonality data is sparse (Nowson and Gill, 2014) and there has been more interest in reporting no vel feature sets. In the P AN task alone 1 there were fea- tures used from multiple levels of representation on language. Surface forms were present in word, lemma and character n-grams, while syntactic fea- tures included POS tags and dependency relations. There were some efforts of feature curation, such as analysis of punctuation and emoticon use, along 1 Due to space consideration we are unable to cite the in- dividual w orks. with the use of latent semantic analysis for topic modelling. Another popular feature set is the use of external resources such as LIWC (Pennebaker et al., 2015) which, in this conte xt, represents over 20 years of psychology-based feature engineering. When applied to tweets, howe ver , LIWC requires further cleaning of the data (Kreindler , 2016). Deep-learning based approaches to personality trait recognition are, unsurprisingly gi ven the typ- ical size of data sets, relati vely few . The model de- tailed in Kalghatgi et al. (2015) presents a neural network based approach to personality prediction of users. In this model, a Multilayer Perceptron (MLP) takes as input a collection of hand-crafted grammatical and social behavioral features from each user and assigns a label to each of the 5 per- sonality traits. Unfortunately no e valuation of this work, nor details of the dataset, were provided. The w ork of Su et al. (2016) describes a Recurrent Neural Network (RNN) based system, exploiting the turn-taking of con versation for personality trait prediction. In their work, RNNs are employed to model the temporal ev olution of dialog, taking as input LIWC-based and grammatical features. The output of the RNNs is then used for the prediction of personality trait scores of the participants of the con versations. It is worth noting that both works utilise hand-crafted features which rely hea vily on domain expertise. Also the focus is on the predic- tion of trait scores on the user level giv en all the av ailable te xt from a user . In contrast, not only can the approach presented in this paper infer the per- sonality of a user gi ven a collection of short texts, it is also flexible to predict trait scores from a sin- gle short text, arguably a more challenging task considering the limited amount of information. The model we present in Section 3.2 is inspired by Ling et al. (2015), who proposed a character- le vel word representation learning model under the assumption that character sequences are syn- tactically and semantically informative of the words the y compose. Based on a widely used RNN named long short-term memory network (LSTM) (Hochreiter and Schmidhuber , 1997), the model learns the embeddings of characters and ho w they can be used to construct words. T opped by a softmax layer at each word, the model was applied to the tasks of language modelling and part-of-speech tagging and successful in improv- ing upon traditional baselines particularly in mor - phologically rich languages. Inspired by this, Y ang et al. (2016) introduced Hierarchical At- tention Networks where the representation of a document is hierarchically built up. They con- struct the representation of a sentence by pro- cessing a sequence of its constituent words using a bi-directional gated recurrent unit (GR U) (Cho et al., 2014). The representations of sentences are in turn processed by another bi-directional GR U at the sentence le vel to form the represen- tation of the document. The work of (Ling et al., 2015) provides a way to construct words from their constituent characters (Character to W ord, C2W ) while Y ang et al. (2016) describe a hier - archical approach to b uilding representations of documents from words to sentences, and e ven- tually to documents (W ord to Sentence to Docu- ment, W2S2D ). In this work, inspired by the above works, we present a hierarchical model situated between the above two models, connecting char - acters, words and sentences, and ultimately per- sonality traits (Character to W ord to Sentence for Personality T rait, C2W2S4PT ). 3 Proposed Model T o motiv ate our methodology , we revie w a commonly-used approach to representing sen- tences and discuss some of its limitations and mo- ti vation. Then, we propose the use of a composi- tional model to tackle the identified problems. 3.1 Current Issues and Motivation One classical approach for applying deep learning models to NLP problems in volv es word lookup tables where words are typically represented by dense real-valued vectors in a lo w-dimensional space (Socher et al., 2013; Kalchbrenner et al., 2014; Kim, 2014). In order to obtain a sensi- ble set of embeddings, a common practice is to train on a lar ge corpus in an unsupervised fashion, e.g. W ord2V ec (Mikolo v et al., 2013a; Mikolov et al., 2013b) and GloV e (Pennington et al., 2014). Despite the success in capturing syntactic and se- mantic information with such word vectors, there are two practical problems with such an approach (Ling et al., 2015). First, due to the flexibility of language, previously unseen words are bound to occur regardless of how large the unsupervised training corpus is. The problem is particularly serious for text extracted from social media plat- forms such as T witter and Facebook due to the noisy nature of user-generated text – e.g. typos, ad hoc acronyms and abbre viations, phonetic sub- stitutions, and ev en meaningless strings (Han and Baldwin, 2011). A naiv e solution is to map all un- seen words to a vector UNK representing the un- kno wn word. Not only does this approach gi ve up critical information regarding the meaning of the unkno wn words, it is also difficult for the model to generalise to made up words, such as beauti- fication , despite the components beautiful and - ification ha ving been observed. Second, the num- ber of parameters for a model to learn is ov er- whelmingly large. Assume each word is repre- sented by a vector of d dimensions, the total size of the word lookup table is d × | V | where | V | is the size of the vocabulary which tends to scale to the order of hundreds and thousands. Again, this problem is e ven more pronounced in noisier do- main such as short text generated by online users. T o address the above issues, we adopt a compo- sitional character to word model described in the next section. From the personality perspectiv e, character- based features hav e been widely adopted in trait inference, such as character n-grams(Gonz ´ alez- Gallardo et al., 2015; Sulea and Dichiu, 2015), emoticons (Nowson et al., 2015; Palomino- Garibay et al., 2015), and character flooding (No wson et al., 2015; Gim ´ enez et al., 2015). Mo- ti vated by this and the issues identified abov e, we propose in the next section a language- independent compositional model that operates hi- erarchically at the character , word and sentence le vel, capable of harnessing personality-sensiti ve signals buried as deep as the character le vel. 3.2 Character to W ord to Sentence f or Personality T raits T o address the problems identified in Section 3.1, we propose to extend the compositional charac- ter to word model first introduced by Ling et al. (2015) wherein the representation of each word is constructed, via a character-le vel bi-directional RNN (Char-Bi-RNN), from its constituent charac- ters. The constructed word vectors are then fed to another layer of word-le vel Bi-RNN (W ord-Bi- RNN) and a sentence is represented by the con- catenation of the last and first hidden states of the forward and backward W ord-RNNs respectiv ely . Eventually , a feedforward neural network takes as input the representation of a sentence and returns a scalar as the prediction for a specific personal- ity trait. Thus, we name the model C2W2S4PT (Character to W ord to Sentence for Personality T raits) which is illustrated in Figure 1. Specifi- cally , suppose we have a sentence s consisting of a sequence of words { w 1 , w 2 , . . . , w i , . . . , w m } . W e define a function c ( w i , j ) which takes as in- put a word w i , together with an index j and re- turns the one-hot v ector representation of the j th character of the word w i . Then, to get the embed- ding c i,j of the character , we transform c ( w i , j ) by: c i,j = E c c ( w i , j ) where E c ∈ R d ×| C | and | C | is the size of the character vocab ulary . Next, in order to construct the representation of word w i , the sequence of character embeddings { c i, 1 , . . . , c i,n } is taken as input to the Char-Bi- RNN (assuming w i is comprised of n characters). In this work, we employ GR U as the recurrent unit in the Bi-RNNs, giv en that recent studies indicate that GR U achie ves comparable, if not better , re- sults to LSTM (Chung et al., 2014; Kumar et al., 2015; Jozefowicz et al., 2015). 2 Concretely , the forward pass of the Char-Bi-RNN is carried out using the follo wing: − → z c i,j = σ ( − → W c z c i,j + − → U c hz − → h c i,j − 1 + − → b c z ) (1) − → r c i,j = σ ( − → W c r c i,j + − → U c hr − → h c i,j − 1 + − → b c r ) (2) − → ˜ h c i,j = tanh( − → W c h c i,j + − → r c i,j − → U c hh − → h c i,j − 1 + − → b c h ) (3) − → h c i,j = − → z c i,j − → h c i,j − 1 + (1 − − → z c i,j ) − → ˜ h c i,j (4) where is the element-wise product, − → W c z , − → W c r , − → W c h , − → U c hz , − → U c hr , − → U c hh are the pa- rameters for the model to learn, and − → b c z , − → b c r , − → b c h the bias terms. The backward pass, the hidden state of which is symbolised by ← − h c i,j , is performed similarly , although with a different set of GR U weight matrices and bias terms. It should be noted that both the forward and backward Char -RNN share the same character embeddings. Ultimately , w i is represented by the concatenation of the last and first hidden states of the forward and back- ward Char-RNNs: e w i = [ − → h c i,n ; ← − h c i, 1 ] > . Once all the word representations e w i for i ∈ [1 , n ] hav e been constructed from their constituent characters, they are then processed by the W ord-Bi-RNN, similar to Char-Bi-RNN but on word lev el with 2 W e performed additional experiments which confirmed this finding. Therefore due to space considerations, we do not report results using LSTMs here. word rather than character embeddings: − → z w i = σ ( − → W w z e w i + − → U w hz − → h w i − 1 + − → b w z ) (5) − → r w i = σ ( − → W w r e w i + − → U w hr − → h w i − 1 + − → b w r ) (6) − → ˜ h w i = tanh( − → W w h e w i + − → r w i − → U w hh − → h w i − 1 + − → b w h ) (7) − → h w i = − → z w i − → h w i − 1 + (1 − − → z w i ) − → ˜ h w i (8) where − → W w z , − → W w r , − → W w h , − → U w hz , − → U w hr , − → U w hh are the parameters for the model to learn, and − → b w z , − → b w wr , − → b w h the bias terms. In a similar fashion to how a word is represented, we con- struct the sentence embedding by concatenation: e s = [ − → h w m ; ← − h w 1 ] > . Lastly , to estimate the score for a particular personality trait, we top the W ord- Bi-RNN with an MLP which takes as input the sentence embedding e s and returns the estimated score ˆ y s : h s = max(0 , W eh e s + b h ) (9) ˆ y s = W hy h s + b y (10) where ReLU is the REctified Linear Unit defined as ReLU ( x ) = max(0 , x ) , W eh , W hy the param- eters for the model to learn, b h , b y the bias terms, and h s the hidden representation of the MLP . All the components in the model are jointly trained with mean square err or being the objectiv e func- tion: L ( θ ) = 1 n n X i =1 ( y s i − ˆ y s i ) 2 (11) where y s i is the ground truth personality score of sentence s i and θ the collection of all embedding and weight matrices and bias terms for the model to learn. Note that no language-dependent compo- nent is present in the proposed model. 4 Experiments and Results W e report two sets of experiments: the first a comparison at the user lev el between our feature- engineering-free and language-independent ap- proach and current state-of-the-art models which rely on linguistic features; the second designed to e valuate the performance of the proposed model against other feature-engineering-free approaches on individual short texts. W e show that in both set- tings, i.e., against models with or without feature engineering, our proposed model achiev es better results across two languages (English and Span- ish) and is equally competiti ve in Italian. c i, 1 c i,j c i,n ← − h c i, 1 − → h c i, 1 ← − h c i,j − → h c i,j ← − h c i,n − → h c i,n ← − h c i, 1 − → h c i,n Char-Bi-RNN ← − h w i − → h w i ← − h w 1 − → h w 1 ← − h w m − → h w m ← − h w 1 − → h w m W ord-Bi-RNN e w 1 e w i e w m Rectified Linear Hidden Layer Linear Layer ˆ y h s Figure 1: Illustration of the C2W2S4PT model. Dotted boxes indicate concatenation. 4.1 Dataset and Data Prepr ocessing W e use the English, Spanish and Italian data from the P AN 2015 Author Profiling task dataset (Rangel et al., 2015), collected from T wit- ter and consisting of 14 , 166 English (EN), 9 , 879 Spanish (ES) and 3 , 687 Italian (IT) tweets (from 152 , 110 and 38 users respectively). Due to space constraints and the limited size of the data, the Dutch dataset is not included. For each user there is a set of tweets (av erage n = 100 ) and gold stan- dard personality labels. The fi ve trait labels, scores between -0.5 and 0.5, are calculated following the author’ s self-assessment responses to the short Big 5 test, BFI-10 (Rammstedt and John, 2007) which is the most widely accepted and exploited scheme for personality recognition and has the most solid grounding in language (Poria et al., 2013). In our experiments, each tweet is tokenised us- ing T wokenizer (Owoputi et al., 2013), in order to preserve hashtag-preceded topics and user men- tions. Unlike the majority of the language used in a tweet, URLs and mentions are used for their targets, and not their surface forms. Therefore each text is normalised by mapping these fea- tures to single characters (e.g., @username → @ , http://t.co/ → ˆ ). Thus we limit the risk of mod- elling, say , character usage which was not directly influenced by the personality of the author . 4.2 Evaluation Method Due to the unav ailability of the test corpus – withheld by the P AN 2015 organisers – we compare the k -fold cross-v alidation performance ( k = 5 or 10 ) on the av ailable dataset. Per- formance is measured using Root Mean Square Error (RMSE) on either the tweet lev el or user le vel depending on the granularity of the task: RM S E tweet = q P T i =1 ( y s i − ˆ y s i ) 2 n and RM S E user = q P U i =1 ( y user i − ˆ y user i ) 2 n where T and U are the total numbers of tweets and users in the corpus, y s i and ˆ y s i the true and estimated personality trait score of the i th tweet, similarly y user i and ˆ y user i are their user-le vel counterparts. Each tweet in the dataset inherits the same fiv e trait scores as assigned to the author from whom they were drawn. ˆ y user i = 1 T i P T i j =1 ˆ y s j where T i refers to the total number of tweets of user i . In Section 4.3 and Section 4.4, we present the re- sults measured at the user and tweet lev el using RM S E user and RM S E tweet respecti vely . It is important to note that, to enable direct compari- son, we use exactly the same dataset and ev alua- tion metric R M S E user as in the works of (Sulea and Dichiu, 2015; Mirkin et al., 2015; No wson et al., 2015). 4.3 Personality T rait Prediction at User Level W e test the proposed models on the dataset de- scribed in Section 4.1 and train our model to predict the personality trait scores based purely on the text without additional features supplied. T o demonstrate the effecti veness of the proposed model, we e valuate the performance on the user le vel against models incorporating linguistic and psychologically motiv ated features. This allows us to directly compare the performance of cur - rent state-of-the-art models and C2W2S4PT . For 5 -fold cross-validation, we compare to the tied- highest ranked (under ev aluation conditions in EN, ranked 7 th and 4 th in ES and IT) of the P AN 2015 submissions (Sulea and Dichiu, 2015). 3 For 10 -fold cross-validation, we similarly choose the work by ranking and metric reporting (Nowson et al., 2005) (ranked 9 th , 6 th and 8 th in EN, ES and IT). As here, these works predicted scores on text lev el, and averaged for each user . Therefore, we include subsequent work which reports results on concatenated tweets – a single document per user (Mirkin et al., 2015). F or each language, we also show the most straightforw ard baseline Average Baseline which assigns the av er - age of all the scores to each user . C2W2S4PT is trained with Adam (Kingma and Ba, 2014) and hyper -parameters: E c ∈ R 50 ×| C | , − → h c i,j and ← − h c i,j ∈ R 256 , − → h w i and ← − h w i ∈ R 256 , W eh ∈ R 512 × 256 , b h ∈ R 256 , W hy ∈ R 256 × 1 , b y ∈ R , dropout rate to the embedding output: 0 . 5 , batch size: 32 . T raining is performed until 100 epochs are reached. The RM S E user results are shown in T able 1 where EXT , ST A, A GR, CON and OPN are abbre viations for Extro version, Emotional Sta- bility (the in verse of Neuroticism), Agreeableness, Conscientiousness and Openness respecti vely . C2W2S4PT outperforms the current state of the art in EN and ES In the 5 -fold cross- v alidation group, C2W2S4PT is superior to the baselines, achie ving better performance except for CON in ES. In terms of the performance measured by 10 -fold cross-validation, the dominance of the proposed model is ev en more pronounced with C2W2S4PT outperforming the two selected base- line systems across all personality traits. Over - all, in comparison to the previous state-of-the-art models in both groups, C2W2S4PT not only out- performs them, by a significant margin in the case of 10 -fold cross-validation, but it also achie ves so without any hand-crafted features, underlining the soundness of the approach. On CON in ES, 5 -fold cross-validation W e sus- pect that the surprisingly good performance of Sulea and Dichiu (2015) may likely be attributed to overfitting. Indeed, the performance on the test set on CON in ES is e ven inferior to Nowson et al. (2015), further confirming our speculation. The superiority of C2W2S4PT is less clear in IT This can possibly be caused by the inadequate 3 Cross-validation RM S E user performance is not re- ported for the other top system ( ´ Alvarez-Carmona et al., 2015). amount of Italian data, less than 4 k tweets as com- pared to 14 k and 10 k in the English and Spanish datasets, limiting the capability of C2W2S4PT to learn a reasonable model. 4.4 Personality T rait Pr ediction at Single T weet Level Although user-le vel e valuation is the common practice, we choose tweet-lev el performance to study the models’ capabilities to infer personality at a lo wer granularity level. T o support our e valua- tion, a number of baselines were created. T o facil- itate fair comparison, the only feature used is the surface form of the text. Average Baseline assigns the av erage of all the scores to each tweet. Also, two BoW systems, namely , Random Forest and SVM Regression , hav e been implemented for comparison. For these two BoW -based baseline systems, we perform grid search to find the best hyper-parameter config- uration. For SVM Regression , the hyper - parameters include: k ernel ∈ { linear , rbf } and C ∈ { 0 . 01 , 0 . 1 , 1 . 0 , 10 . 0 } whereas for Random Forest , the number of trees is chosen from the set { 10 , 50 , 100 , 500 , 1000 } . Additionally , two simpler RNN-based mod- els, namely Bi-GRU-Char and Bi-GRU-Word , which only work on character and word level respecti vely but share the same structure of the final MLP classifier ( h s and ˆ y s ), hav e also been presented in contrast to the more sophis- ticated character to word compositional model C2W2S4PT . F or training, C2W2S4PT inherits the same hyper-parameter configuration as de- scribed in Section 4.3. For Bi-GRU-Char and Bi-GRU-Word , we set the character and word embedding size to 50 and 256 respectiv ely . Due to time constraints, we did not perform hyper- parameter fine-tuning for the RNN-based models and C2W2S4PT . The RM S E tweet of each effort, measured by 10 -fold stratified cross-validation, is sho wn in T able 2. C2W2S4PT achiev es comparable or better perf ormance with SVM Regression and Random Forest in EN and ES C2W2S4PT is state of the art in almost ev ery trait with the exception of AGR in EN and ST A in ES. This demonstrates that C2W2S4PT generates at least reasonably comparable performance with SVM Regression and Random Forest in the feature-engineering-free setting on the tweet Lang. k Model EXT ST A A GR CON OPN EN — Average Baseline 0.166 0.223 0.158 0.151 0.146 5 Sulea and Dichiu (2015) 0.136 0.183 0.141 0.131 0.119 C2W2S4PT 0.131 0.171 0.140 0.124 0.109 10 Mirkin et al. (2015) 0.171 0.223 0.173 0.144 0.146 No wson et al. (2015) 0.153 0.197 0.154 0.144 0.132 C2W2S4PT 0.130 0.167 0.137 0.122 0.109 ES — Average Baseline 0.171 0.203 0.163 0.187 0.166 5 Sulea and Dichiu (2015) 0.152 0.181 0.148 0.114 0.142 C2W2S4PT 0.148 0.177 0.143 0.157 0.136 10 Mirkin et al. (2015) 0.153 0.188 0.155 0.156 0.160 No wson et al. (2015) 0.154 0.188 0.155 0.168 0.160 C2W2S4PT 0.145 0.177 0.142 0.153 0.137 IT — Average Baseline 0.162 0.172 0.162 0.123 0.151 5 Sulea and Dichiu (2015) 0.119 0.150 0. 122 0.101 0.130 C2W2S4PT 0.124 0.144 0.130 0.095 0.131 10 Mirkin et al. (2015) 0.095 0.168 0.142 0.098 0.137 No wson et al. (2015) 0.137 0.168 0.142 0.098 0.141 C2W2S4PT 0.118 0.147 0.128 0.095 0.127 T able 1: R M S E user across fi ve traits. Bold highlights best performance. le vel and it does so without exhausti ve hyper- parameter fine-tuning. C2W2S4PT outperforms the RNN-based base- lines in EN and ES This success can be attributed to the model’ s capability of coping with arbitrary words while not forgetting information due to ex- cessi ve lengths as can arise from representing a text as a sequence of characters. Also, gi ven that C2W2S4PT does not need to maintain a large vo- cabulary embedding matrix as in Bi-GRU-Word , there are much fewer parameters for the model to learn (Ling et al., 2015), making it less prone to ov erfitting. The performance of C2W2S4PT is inferior to Bi-GRU-Word in IT Bi-GRU-Word achiev es the best performance across all personality traits with C2W2S4PT coming in as a close second and tying in 3 traits. Apart from the inadequate amount of Italian data causing the fluctuation in perfor- mance as explained in Section 4.3, further in vesti- gation is needed to analyse the strong performance of Bi-GRU-Word . 4.5 V isualisation T o further in vestigate into the learned represen- tations and features, we choose the C2W2S4PT model trained on a single personality trait and vi- sualise the sentences with the help of PCA (T ip- ping and Bishop, 1999). W e also experimented with t-SNE (V an der Maaten and Hinton, 2008) but it did not produce an interpretable plot. 100 tweets hav e been randomly selected (50 tweets each from either end of the EXT spectrum) with their representations constructed by the model. Figure 2 shows the scatter plot of the representa- tions of the sentences reduced to a 2 D space by PCA for the trait of Extraversion (EXT), selected as it is the most commonly studied and well un- derstood trait. The figure shows clusters of both positi ve and ne gati ve Extrav ersion, though the for- mer intersect the latter . For discussion we consider three examples as highlighted in Figure 2: • POS7: “@username: F eeling like you’r e not good enough is pr obably the worst thing to feel. ” • NEG3: “Being good ain’ t enough lately . ” • POS20: “o.O Lovely . ” The first two examples (POS7 and NEG3) are drawn from largely distinct areas of the distrib u- tion. In essence the semantics of the short texts are the same. Howe ver , they both sho w linguis- tic attributes commonly understood to relate to Extrav ersion (Gill and Oberlander , 2002): POS7 Lang. Model EXT ST A A GR CON OPN EN Average Baseline 0.163 0.222 0.157 0.150 0.147 SVM Regression 0.148 0.196 0.148 0.140 0.131 Random Forest 0.144 0.192 0.146 0.138 0.132 Bi-GRU-Char 0.150 0.202 0.152 0.143 0.137 Bi-GRU-Word 0.147 0.200 0.146 0.138 0.130 C2W2S4PT 0.142 0.188 0.147 0.136 0.127 ES Average Baseline 0.171 0.204 0.163 0.187 0.165 SVM Regression 0.158 0.190 0.157 0.171 0.152 Random Forest 0.159 0.195 0.157 0.177 0.158 Bi-GRU-Char 0.163 0.195 0.158 0.178 0.155 Bi-GRU-Word 0.159 0.192 0.154 0.173 0.154 C2W2S4PT 0.158 0.191 0.153 0.168 0.150 IT Average Baseline 0.164 0.171 0.164 0.125 0.153 SVM Regression 0.141 0.159 0.145 0.113 0.141 Random Forest 0.140 0.161 0.140 0.111 0.147 Bi-GRU-Char 0.149 0.163 0.153 0.117 0.146 Bi-GRU-Word 0.135 0.156 0.140 0.109 0.141 C2W2S4PT 0.139 0.156 0.143 0.109 0.141 T able 2: R M S E tweet across fi ve traits le vel. Bold highlights best performance. 10 8 6 4 2 0 2 4 6 8 6 4 2 0 2 4 6 POS7 POS20 NEG3 EXT Positive EXT Negative Figure 2: Scatter plot of sentence representations processed by PCA. is longer and, with the use of the second person pronoun, is more inclusive of others; NEG3 on the other hand is shorter and self-focused, aspects indicati ve of Introversion. The third sentence, POS20, is a statement from an Extravert which appears to map to an Introv ert space. Indeed, while short, the use of “Eastern” style, non-rotated emoticons (such as o.O ) has also been shown to relate to Introversion on social media (Schwartz et al., 2013). This is perhaps not the v enue to consider the implications of this further , although one explanation might be that the model has un- cov ered a flexibility often associated with Am- bi verts (Grant, 2013). Ho we ver , it is important to consider that the model is indeed capturing well- understood dimensions of language yet with no feature engineering. 5 Conclusion and Future W ork Overall, the results in the paper support our methodology: C2W2S4PT not only provides state-of-the-art results on the user lev el, but also performs reasonably well when adapted to the short text lev el compared to other widely used models in the feature-engineering-free setting. More importantly , one advantage of our approach is the lack of feature engineering which allo ws us to adapt the same model to other languages with no modification to the model itself. T o further examine this property of the proposed model, we plan to adopt T wiSty (V erhoev en et al., 2016), a re- cently introduced corpus consisting of 6 languages and labelled with MBTI type indicators (Myers and Myers, 2010). References [ ´ Alvarez-Carmona et al.2015] Miguel A. ´ Alvarez- Carmona, A. Pastor L ´ opez-Monroy , Manuel Montes y G ´ omez, Luis V illase ˜ nor-Pineda, and Hugo Jair Escalante. 2015. INA OE’ s participation at P AN’15: Author Profiling task—Notebook for P AN at CLEF 2015. In W orking Notes P apers of the CLEF 2015 Evaluation Labs . [Argamon et al.2005] Shlomo Argamon, Sushant Dhawle, Moshe K oppel, and James W . Pennebaker . 2005. Le xical predictors of personality type. In Pr oceedings of the 2005 Joint Annual Meeting of the Interface and the Classification Society of North America . [Celli et al.2014] Fabio Celli, Bruno Lepri, Joan-Isaac Biel, Daniel Gatica-Perez, Giuseppe Riccardi, and Fabio Pianesi. 2014. The workshop on com- putational personality recognition 2014. In Pr oc. A CMMM , pages 1245–1246, Orlando, USA. [Cho et al.2014] K yunghyun Cho, Bart V an Merri ¨ enboer , Dzmitry Bahdanau, and Y oshua Bengio. 2014. On the properties of neural machine translation: Encoder-decoder approaches. arXiv pr eprint arXiv:1409.1259 . [Chung et al.2014] Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Y oshua Bengio. 2014. Em- pirical ev aluation of gated recurrent neural net- works on sequence modeling. arXiv pr eprint arXiv:1412.3555 . [Gill and Oberlander2002] Alastair J. Gill and Jon Oberlander . 2002. T aking Care of the Linguistic Features of Extrav ersion. In Proc. CogSci , pages 363–368, Fairfax, USA. [Gim ´ enez et al.2015] Maite Gim ´ enez, Delia Iraz ´ u Hern ´ andez, and Ferran Pla. 2015. Segmenting T arget Audiences: Automatic Author Profiling Us- ing T weets—Notebook for P AN at CLEF 2015. In W orking Notes P apers of the CLEF 2015 Evaluation Labs . [Gonz ´ alez-Gallardo et al.2015] Carlos E. Gonz ´ alez- Gallardo, Azucena Montes, Gerardo Sierra, J. Antonio N ´ u ˜ nez-Ju ´ arez, Adolfo Jonathan Salinas- L ´ opez, and Juan Ek. 2015. T weets Classification Using Corpus Dependent T ags, Character and POS N-grams—Notebook for P AN at CLEF 2015. In W orking Notes P apers of the CLEF 2015 Evaluation Labs . [Grant2013] Adam M. Grant. 2013. Rethinking the ex- trav erted sales ideal: The ambi vert advantage. Psy- chological Science 24(6) , 24(6):1024–1030. [Han and Baldwin2011] Bo Han and T imothy Baldwin. 2011. Lexical normalisation of short text messages: Makn sens a #twitter . In Pr oc. A CL , pages 368–378, Portland, Oregon, USA. [Hochreiter and Schmidhuber1997] Sepp Hochreiter and J ¨ urgen Schmidhuber . 1997. Long short-term memory . Neural computation , 9(8):1735–1780. [Huang et al.2015] Zhiheng Huang, W ei Xu, and Kai Y u. 2015. Bidirectional lstm-crf models for se- quence tagging. arXiv pr eprint arXiv:1508.01991 . [Jozefowicz et al.2015] Rafal Jozefowicz, W ojciech Zaremba, and Ilya Sutskev er . 2015. An empiri- cal exploration of recurrent network architectures. In Pr oc. ICML , pages 2342–2350. JMLR W orkshop and Conference Proceedings. [Kalchbrenner et al.2014] Nal Kalchbrenner , Edward Grefenstette, and Phil Blunsom. 2014. A con vo- lutional neural network for modelling sentences. In Pr oc. ACL , Baltimore, USA. [Kalghatgi et al.2015] Mayuri Pundlik Kalghatgi, Man- jula Ramannav ar , and Nandini S. Sidnal. 2015. A neural network approach to personality prediction based on the big-fiv e model. International Jour - nal of Innovative Resear ch in Advanced Engineering (IJIRAE) , 2(8):56–63. [Kim2014] Y oon Kim. 2014. Conv olutional neural net- works for sentence classification. In Pr oc. EMNLP , Doha, Qatar . [Kingma and Ba2014] Diederik Kingma and Jimmy Ba. 2014. Adam: A method for stochastic opti- mization. arXiv pr eprint arXiv:1412.6980 . [Kreindler2016] Jon Kreindler . 2016. T wit- ter psychology analyzer api and sample code. http : / / www . receptiviti . ai / blog / twitter- psychology- analyzer- api- and- sample- code/. Accessed: 2016-09-30. [Kumar et al.2015] Ankit Kumar , Ozan Irsoy , Jonathan Su, James Bradbury , Robert English, Brian Pierce, Peter Ondruska, Ishaan Gulrajani, and Richard Socher . 2015. Ask me anything: Dynamic mem- ory netw orks for natural language processing. arXiv pr eprint arXiv:1506.07285 . [Ling et al.2015] W ang Ling, Chris Dyer, Alan W Black, Isabel T rancoso, Ramon Fermandez, Silvio Amir , Luis Marujo, and T iago Luis. 2015. Finding function in form: Compositional character models for open vocabulary word representation. In Proc. EMNLP , pages 1520–1530, Lisbon, Portugal. [Manning2016] Christopher D Manning. 2016. Com- putational linguistics and deep learning. Computa- tional Linguistics . [Matthews et al.2003] Gerald Matthews, Ian J. Deary , and Martha C. Whiteman. 2003. P ersonality T raits . Cambridge Univ ersity Press, second edition. Cam- bridge Books Online. [Mikolov et al.2013a] T omas Mikolov , Kai Chen, Greg Corrado, and Jeffrey Dean. 2013a. Efficient esti- mation of word representations in vector space. In Pr oc. ICLR , Scottsdale, USA. [Mikolov et al.2013b] T omas Mikolov , Ilya Sutskev er , Kai Chen, Gre g Corrado, and Jef f Dean. 2013b. Distributed representations of words and phrases and their compositionality . In Proc. NIPS , pages 3111–3119, Stateline, USA. [Mirkin et al.2015] Shachar Mirkin, Scott Nowson, Caroline Brun, and Julien Perez. 2015. Motiv at- ing personality-aware machine translation. In Pr oc. EMNLP , pages 1102–1108, Lisbon, Portugal. [Myers and Myers2010] Isabel Myers and Peter Myers. 2010. Gifts differing: Understanding personality type . Nicholas Brealey Publishing. [Nowson and Gill2014] Scott Nowson and Alastair J. Gill. 2014. Look! Who’ s T alking? Projection of Extraversion Across Different Social Contexts. In Pr oceedings of WCPR14, W orkshop on Compu- tational P ersonality Recognition at ACMM (22nd A CM International Confer ence on Multimedia) . [Nowson and Oberlander2006] Scott Nowson and Jon Oberlander . 2006. The Identity of Bloggers: Open- ness and gender in personal weblogs. In AAAI Spring Symposium, Computational Appr oaches to Analysing W eblogs . [Nowson et al.2005] Scott Nowson, Jon Oberlander , and Alastair J. Gill. 2005. W eblogs, genres and in- dividual differences. In Pr oc. CogSci , pages 1666– 1671. [Nowson et al.2015] Scott Nowson, Julien Perez, Car- oline Brun, Shachar Mirkin, and Claude Roux. 2015. XRCE Personal Language Analytics Engine for Multilingual Author Profiling. In W orking Notes P apers of the CLEF 2015 Evaluation Labs . [Owoputi et al.2013] Olutobi Owoputi, Brendan O’Connor , Chris Dyer , Ke vin Gimpel, Nathan Schneider , and Noah A. Smith. 2013. Improv ed part-of-speech tagging for online con versational text with word clusters. In Pr oc. N AACL , pages 380–390, Atlanta, USA. [Palomino-Garibay et al.2015] Alonso Palomino- Garibay , Adolfo T . Camacho-Gonz ´ alez, Ricardo A. Fierro-V illaneda, Iraz ´ u Hern ´ andez-Farias, Davide Buscaldi, and Ivan V . Meza-Ruiz. 2015. A Random Forest Approach for Authorship Profiling— Notebook for P AN at CLEF 2015. In W orking Notes P apers of the CLEF 2015 Evaluation Labs . [Pennebaker et al.2003] James W Pennebaker , Kate G Niederhoffer , and Matthias R Mehl. 2003. Psycho- logical aspects of natural language use: Our words, our selves. Annual Revie w of Psychology , 54:547– 577. [Pennebaker et al.2015] J. W . Pennebaker , R. L. Boyd, K. Jordan, and K. Blackburn. 2015. The devel- opment and psychometric properties of LIWC2015. This article is published by LIWC Inc, Austin, T exas 78703 USA in conjunction with the LIWC2015 soft- ware program. [Pennington et al.2014] Jef frey Pennington, Richard Socher , and Christopher Manning. 2014. Glove: Global vectors for word representation. In Pr oc. EMNLP , pages 1532–1543, Doha, Qatar . [Poria et al.2013] Soujanya Poria, Alexandar Gelbukh, Basant Agarwal, Erik Cambria, and Newton How ard, 2013. Common Sense Knowledge Based P ersonality Recognition fr om T e xt , pages 484–496. [Rammstedt and John2007] Beatrice Rammstedt and Oliv er P . John. 2007. Measuring personality in one minute or less: A 10-item short version of the big fiv e in ventory in english and german. Journal of Re- sear ch in P ersonality , 41(1):203–212. [Rangel et al.2015] Francisco Rangel, F abio Celli, Paolo Rosso, Martin Potthast, Benno Stein, and W al- ter Daelemans. 2015. Overvie w of the 3rd Au- thor Profiling T ask at P AN 2015. In W orking Notes P apers of the CLEF 2015 Evaluation Labs , CEUR W orkshop Proceedings. [Schwartz et al.2013] H Andrew Schwartz, Johannes C Eichstaedt, Mar garet L K ern, Lukasz Dziurzyn- ski, Stephanie M Ramones, Megha Agrawal, Achal Shah, Michal K osinski, David Stillwell, Martin E P Seligman, and L yle H Ungar . 2013. Personality , Gender , and Age in the Language of Social Media: The Open-V ocabulary Approach. PLOS ONE , 8(9). [Socher et al.2013] Richard Socher , Alex Perelygin, Jean Y W u, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts Potts. 2013. Recursiv e deep models for semantic composition- ality over a sentiment treebank. In Pr oc. EMNLP , Seattle, USA. [Su et al.2016] Ming-Hsiang Su, Chung-Hsien W u, and Y u-Ting Zheng. 2016. Exploiting turn-taking temporal ev olution for personality trait perception in dyadic con versations. IEEE/ACM T ransac- tions on Audio, Speech, and Language Pr ocessing , 24(4):733–744. [Sulea and Dichiu2015] Octavia-Maria Sulea and Daniel Dichiu. 2015. Automatic profiling of twitter users based on their tweets. In W orking Notes P apers of the CLEF 2015 Evaluation Labs . [T annen1990] Deborah T annen. 1990. Y ou Just Dont Understand: W omen and Men in Conver sation . Harper Collins, New Y ork. [T ipping and Bishop1999] Michael E Tipping and Christopher M Bishop. 1999. Probabilistic principal component analysis. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , 61(3):611–622. [Tkal ˇ ci ˇ c et al.2014] Marko Tkal ˇ ci ˇ c, Berardina De Car- olis, Marco de Gemmis, Ante Odi ´ c, and Andrej K o ˇ sir . 2014. Preface: Empire 2014. In Proceed- ings of the 2nd W orkshop Emotions and P ersonality in P ersonalized Services (EMPIRE 2014) . CEUR- WS.org, July . [V an der Maaten and Hinton2008] Laurens V an der Maaten and Geoffrey Hinton. 2008. V isualizing data using t-sne. J ournal of Machine Learning Resear ch , 9(2579-2605):85. [V erhoeven et al.2016] Ben V erhoe ven, W alter Daele- mans, and Barbara Plank. 2016. T wiSty: a mul- tilingual twitter stylometry corpus for gender and personality profiling. In Pr oc. LREC , pages 1632– 1637, Portoro ˇ z, Slov enia. [Y ang et al.2016] Zichao Y ang, Diyi Y ang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy . 2016. Hierarchical attention networks for document clas- sification. In Pr oc. N AACL , pages 1480–1489, San Diego, USA.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment