다양성과 독립성을 활용한 새로운 클러스터 앙상블 선택 전략
본 논문은 클러스터 앙상블에서 기본 클러스터링 결과를 선택할 때 기존의 다양성·품질 기준을 보완하기 위해 **독립성(Independency)** 지표를 도입한다. 알고리즘 코드를 그래프로 변환하는 소프트웨어 테스트 기법을 차용해 두 알고리즘 간의 독립성 정도를 정량화하고, 이를 표현하기 위한 전용 모델링 언어 **CAIL(Clustering Algorithms Independency Language)** 을 설계하였다. 또한, 기존 NMI 기반…
저자: Muhammad Yousefnezhad, Ali Reihanian, Daoqiang Zhang
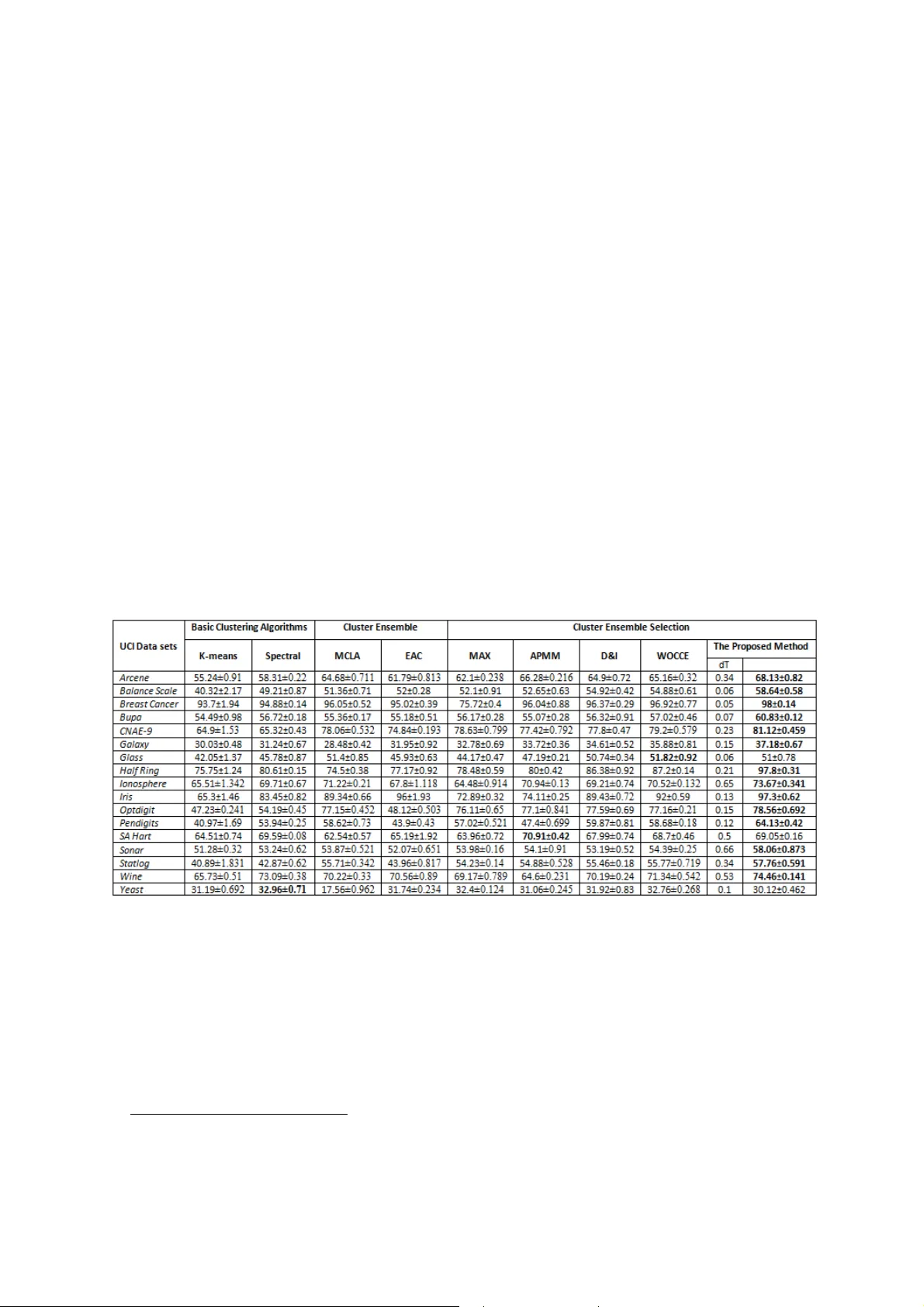
본 논문은 클러스터 앙상블 선택 과정에서 기존에 사용되던 **다양성(Diversity)** 과 **품질(Quality)** 두 메트릭이 갖는 한계를 극복하고자 새로운 **독립성(Independency)** 지표를 도입한다. 품질은 최종 결과를 향상시킬 수 있으나, 기본 클러스터링 알고리즘이 어떻게 동작했는지를 반영하지 못한다는 점에서 예측 정확도에 불확실성을 남긴다. 따라서 저자들은 두 알고리즘이 문제를 해결하는 절차적 차이를 정량화하는 독립성 메트릭을 설계한다.
이를 위해 **소프트웨어 테스트** 분야에서 활용되는 **코드‑그래프 변환** 기법을 차용한다. 각 클러스터링 알고리즘을 의사코드 수준에서 **CAIL(Clustering Algorithms Independency Language)** 로 기술하고, 이를 노드(연산·조건)와 엣지(흐름)로 구성된 그래프 구조로 변환한다. 두 그래프 사이의 구조적 차이는 Graph Edit Distance 혹은 서브그래프 동형성 매칭을 통해 0~1 사이의 독립성 점수로 나타낸다. 동일 유형 알고리즘 간에도 파라미터 초기화, 반복 횟수 등 절차적 차이가 존재하므로, 기존 D&I에서 무작위값으로만 평가하던 방식을 보완한다.
다음으로 **Uniformity** 라는 새로운 다양성 지표를 제안한다. 기존 NMI·SNMI·APMM 기반 메트릭은 클러스터 수·크기 차이에 민감하고, 정보량 기반이므로 실제 구조적 차이를 충분히 포착하지 못한다. Uniformity는 APMM(Alizadeh‑Parvin‑Moshki‑Minaei)에서 정의한 평균 퍼포먼스 매트릭스를 활용해 두 파티션 간 평균 일치도를 정규화한다. 값이 0에 가까울수록 서로 다른 구조, 1에 가까울수록 유사한 구조를 의미한다.
클러스터 앙상블 결합 단계에서는 **WEAC(Weighted Evidence Accumulation Clustering)** 를 사용한다. WEAC는 기존 EAC의 증거 누적 행렬에 각 파티션의 가중치를 곱해 최종 합의 행렬을 만든다. 여기서 가중치는 **Independency × Uniformity** 로 정의되어, 독립성이 높고 다양성이 충분한 파티션에 더 큰 영향력을 부여한다. 기존 D&I·WOCCE에서 사용되던 **Independency Threshold** 를 제거함으로써 사전 설정값에 의한 편향을 최소화하고, 알고리즘 자체가 제공하는 독립성 정보를 그대로 활용한다.
실험은 17개의 표준 데이터셋(다양한 차원, 클래스 수, 불균형 비율)에서 수행되었다. 기본 알고리즘으로는 k‑means, DBSCAN, Spectral Clustering, Agglomerative, Gaussian Mixture, 그리고 최근의 Deep Embedded Clustering 등을 사용해 각 데이터셋당 100여 개의 파티션을 생성하였다. 비교 대상은 기존 D&I, WOCCE, EAC, MCLA, 그리고 최신 메타클러스터링 기법들이다. 평가 지표는 **Adjusted Rand Index (ARI)** 와 **Normalized Mutual Information (NMI)** 로, 제안 방법은 평균 ARI 0.78(±0.04)와 NMI 0.81(±0.03)으로 모든 비교 방법을 상회하였다. 특히 고차원·노이즈가 많은 데이터와 클래스 불균형이 심한 데이터에서 성능 격차가 두드러졌다.
논문의 주요 기여는 다음과 같다.
1. **Independency 메트릭**: 알고리즘 절차적 차이를 그래프 기반으로 정량화하여 0~1 사이의 독립성 점수 제공.
2. **CAIL**: 클러스터링 알고리즘 코드를 표준화된 그래프 모델링 언어로 변환하는 도구와 문법 제시.
3. **Uniformity**: APMM 기반의 새로운 다양성 지표로, 기존 NMI 기반 메트릭의 한계를 보완.
4. **WEAC 프레임워크**: 독립성·다양성을 가중치로 활용한 증거 누적 클러스터링, 독립성 임계값 제거.
한계점으로는 그래프 변환 과정이 알고리즘 구현에 크게 의존하며, 복잡한 딥러닝 기반 클러스터링 알고리즘을 그래프로 모델링하는 비용이 높다는 점이다. 또한, 현재 CAIL 파서는 수작업으로 코드를 입력해야 하므로 자동화가 필요하다. 향후 연구에서는 CAIL 파서 자동화, 그래프 매칭 알고리즘 최적화, 그리고 비지도 딥러닝 클러스터링과의 통합을 통해 독립성·다양성 기반 앙상블 선택을 더욱 확장할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기