시간 제한 속 인간 의사결정: 제한 합리성 모델 검증
본 연구는 통계역학·정보이론 기반의 제한 합리성 모델을 실험적으로 검증한다. 피험자들에게 다양한 시간 제한 하에 조합 퍼즐을 풀게 하고, 선택 확률을 사전 확률·효용·역온도(자원) 세 요소로 분해하였다. 모델은 높은 적합도를 보였으며, 시간(자원) 증가에 따라 사전 선택 패턴에서 최적 선택으로 점진적으로 전이함을 확인했다.
저자: Pedro A. Ortega, Alan A. Stocker
본 논문은 인간 의사결정이 무한한 계산 자원을 가정하는 전통적 기대 효용 이론과 달리, 실제 생활에서 흔히 마주하는 시간·인지·계산 자원의 제약을 고려한 ‘제한 합리성(bounded rationality)’ 모델을 실험적으로 검증한다. 연구팀은 통계역학과 정보이론에서 차용한 자유 에너지 함수(식 1)를 기반으로, 선택 확률을 사전 확률 P(y), 효용 Uₓ(y), 역온도 β(자원) 세 요소로 분해하는 수학적 프레임워크를 제시한다. 이 프레임워크는 기대 효용을 최대화하면서 KL 발산(정보 비용)을 최소화하는 최적화 문제로 정의되며, 해는 Gibbs 분포 형태(식 2)로 나타난다. β가 0에 가까우면 사전 P(y)와 동일한 무작위 선택을, β가 무한대로 커지면 효용에만 의존하는 완전 합리적 선택을 의미한다.
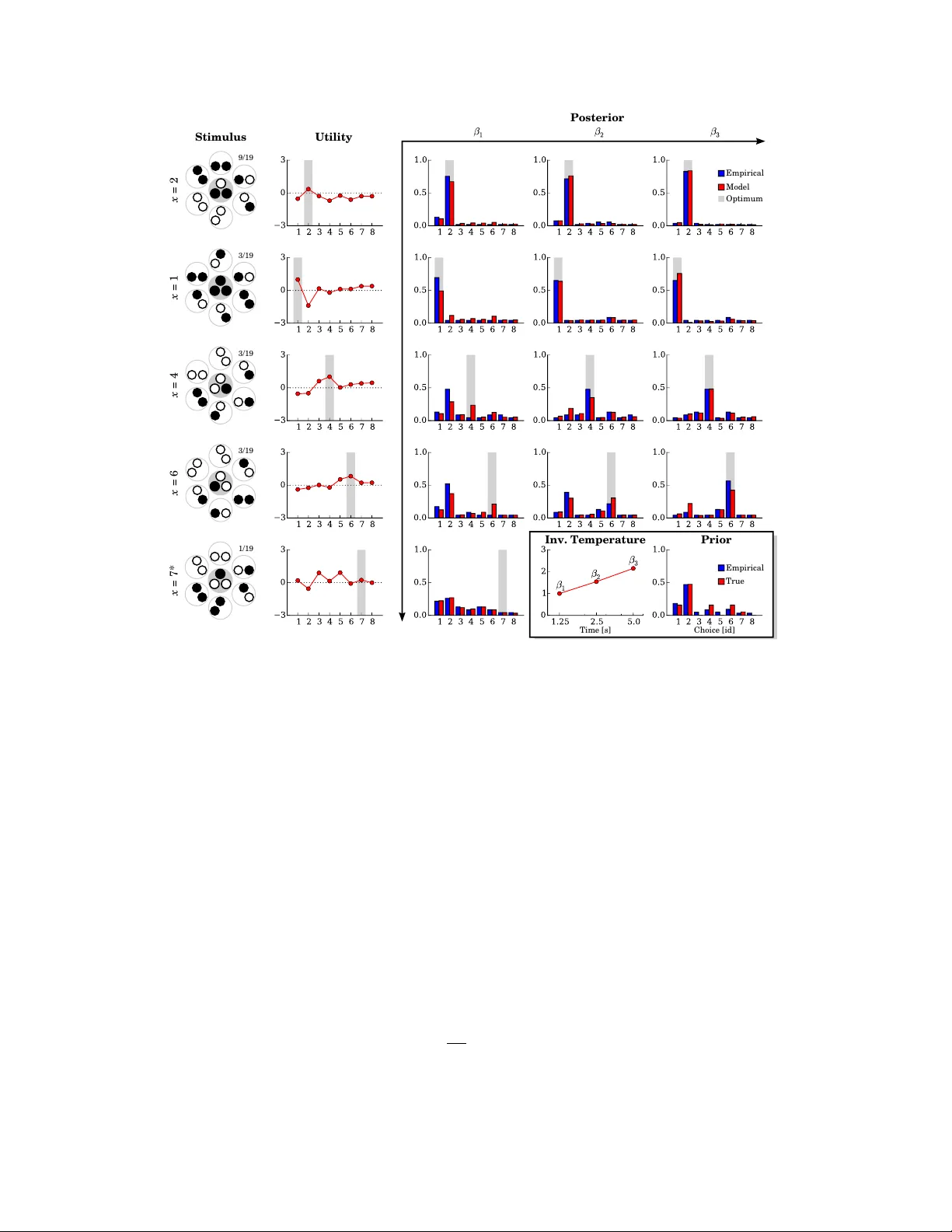
실험은 30명의 미국 거주자를 대상으로 Amazon Mechanical Turk에서 수행되었다. 피험자들은 6개의 원형 패치를 이용해 2‑리터럴 6‑절(2‑SAT) CNF 퍼즐을 해결하도록 요구받았다. 훈련 단계에서는 4개의 퍼즐을 10 초씩 제공해 충분히 학습하도록 하였고, 테스트 단계에서는 1.25 s, 2.5 s, 5 s의 세 가지 시간 제한을 무작위로 부여했다. 각 퍼즐은 8가지 가능한 색상 배합 중 하나를 선택하도록 설계되었으며, 정답은 단 하나뿐이었다. 피험자는 시간 제한을 사전에 알 수 없었으며, 시각적 신호만으로 남은 시간을 추정해야 했다.
수집된 데이터는 (자극 x, 자원 r, 선택 y) 튜플 형태이며, 연구팀은 이를 기반으로 경험적 선택 확률 P(y|x,r)를 추정했다. 이후 KL 발산 최소화(식 6)를 목표 함수로 설정하고, 경사 하강법을 통해 β(r)와 Uₓ(y)를 동시에 학습하였다. β는 r₀=1 s에서 1로 고정하고, 효용은 확실성 등가값을 빼는 정규화(식 10)를 적용해 스케일과 오프셋을 제거했다. 이 과정은 Gibbs 분포의 무한 자유도를 제한하고, 각 피험자마다 고유한 효용 맵과 β(r) 곡선을 도출한다.
분석 결과, 모든 피험자에 대해 평균 적합 오차가 0.0347 bits(±0.0024)로 매우 낮았다. 이는 모델이 실제 인간 선택을 거의 완벽히 설명한다는 의미이다. β는 시간과 로그 선형 관계를 보이며, 시간이 길어질수록 효용에 대한 민감도가 증가한다. 훈련된 퍼즐(예: x∈{1,2,4,6})에서는 효용이 정답 선택에 최대값을 갖고, 비훈련 퍼즐(x=7)에서는 효용이 평탄해져 사전 선택 편향에 크게 의존한다는 점이 관찰되었다. 또한, 사전 P(y)를 포함한 모델이 사전만을 이용한 Softmax(식 13)보다 적합도가 현저히 우수했으며, 인간이 사전 선택 경향을 유지하면서도 자원 제한에 따라 효용을 조절한다는 가설을 뒷받침한다.
논문의 주요 기여는 다음과 같다. 첫째, 제한 합리성 모델을 실제 인간 행동 데이터에 적용해 정량적 검증을 수행했다. 둘째, 사전 선택 편향(P(y))과 효용(Uₓ) 그리고 자원 파라미터(β)를 명확히 분리함으로써, 시간 제한이 증가할 때 인간이 학습된 선호에서 사전 확률로 회귀하는 메커니즘을 밝혀냈다. 셋째, 정보 용량(β)와 선택 변동성 사이의 관계를 mutual information(Iβ)로 정량화하여, ‘결정 대역폭’이라는 새로운 개념을 제시했다. 마지막으로, 이러한 모델링 접근은 행동경제학, 인지과학, 인간‑컴퓨터 상호작용 설계 등 다양한 분야에서 인간의 제한된 자원 하에서의 의사결정을 예측·보조하는 도구로 활용될 가능성을 열어준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기