Human Decision-Making under Limited Time
Subjective expected utility theory assumes that decision-makers possess unlimited computational resources to reason about their choices; however, virtually all decisions in everyday life are made under resource constraints - i.e. decision-makers are …
Authors: Pedro A. Ortega, Alan A. Stocker
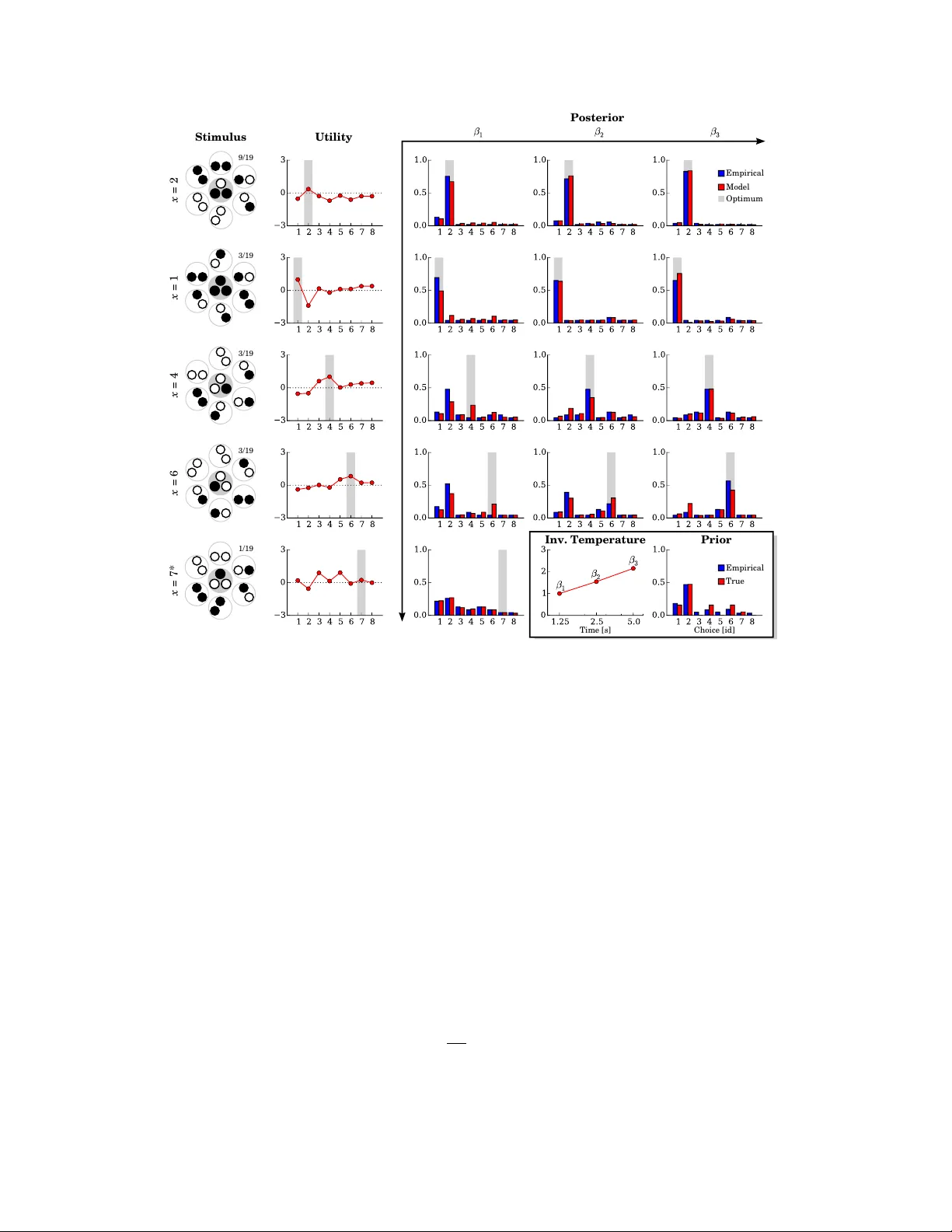
Human Decision-Making under Limited T ime Pedr o A. Ortega Department of Psychology Univ ersity of Pennsylv ania Philadelphia, P A 19104 ope@seas.upenn.edu Alan A. Stocker Department of Psychology Univ ersity of Pennsylv ania Philadelphia, P A 19014 astocker@sas.upenn.edu Abstract Subjectiv e expected utility theory assumes that decision-mak ers possess unlimited computational resources to reason about their choices; ho wev er , virtually all deci- sions in e veryday life are made under resource constraints—i.e. decision-makers are bounded in their rationality . Here we experimentally tested the predictions made by a formalization of bounded rationality based on ideas from statistical mechanics and information-theory . W e systematically tested human subjects in their ability to solve combinatorial puzzles under different time limitations. W e found that our bounded-rational model accounts well for the data. The decompo- sition of the fitted model parameter into the subjects’ expected utility function and resource parameter provide interesting insight into the subjects’ information ca- pacity limits. Our results confirm that humans gradually fall back on their learned prior choice patterns when confronted with increasing resource limitations. 1 Introduction Human decision-making is not perfectly rational. Most of our choices are constrained by man y fac- tors such as perceptual ambiguity , time, lack of knowledge, or computational effort [6]. Classical theories of rational choice do not apply in such cases because they ignore information-processing resources, assuming that decision-makers always pick the optimal choice [10]. Howe ver , it is well known that human choice patterns de viate qualitati vely from the perfectly rational ideal with in- creasing resource limitations. It has been suggested that such limitations in decision-making can be formalized using ideas from statistical mechanics [9] and information theory [16]. These frame works propose that decision- makers act as if their choice probabilities were an optimal compromise between maximizing the expected utility and minimizing the KL-di ver gence from a set of prior choice probabilities, where the trade-off is determined by the amount of av ailable resources. This optimization scheme reduces the decision-making problem to the infer ence of the optimal choice from a stimulus, where the like- lihood function results from a combination of the decision-maker’ s subjective preferences and the resource limitations. The aim of this paper is to systematically validate the model of bounded-rational decision-making on human choice data. W e conducted an experiment in which subjects had to solve a sequence of combinatorial puzzles under time pressure. By manipulating the allotted time for solving each puzzle, we were able to record choice data under dif ferent resource conditions. W e then fit the bounded-rational choice model to the dataset, obtaining a decomposition of the choice probabilities in terms of a resource parameter and a set of stimulus-dependent utility functions. Our results show that the model captures very well the gradual shifts due to increasing time constraints that are present in the subjects’ empirical choice patterns. 29th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain. 2 A Probabilistic Model of Bounded-Rational Choices W e model a bounded-rational decision maker as an expected utility maximizer that is subject to information constraints. Formally , let X and Y be two finite sets, the former corresponding to a set of stimuli and the latter to a set of choices ; and let P ( y ) be a prior distrib ution ov er optimal choices y ∈ Y that the decision-maker may ha ve learned from e xperience. When presented with a stimulus x ∈ X , a bounded-rational decision-maker transforms the prior choice probabilities P ( y ) into posterior choice probabilities P ( y | x ) and then generates a choice according to P ( y | x ) . This transformation is modeled as the optimization of a regularized expected utility kno wn as the fr ee ener gy functional : F Q ( y | x ) := X y Q ( y | x ) U x ( y ) | {z } Expected Utility − 1 β X y Q ( y | x ) log Q ( y | x ) P ( y ) | {z } Regularization , (1) where the posterior is defined as the maximizer P ( y | x ) := arg max Q ( y | x ) F [ Q ( y | x )] . Crucially , the optimization is determined by two factors. The first is the decision-maker’ s subjective utility function U x : Y → R encoding the desirability of a choice y given a stimulus x . The second is the in verse temperatur e β , which determines the resources of deliberation available for the decision- task 1 , but which are neither known to, nor controllable by the decision-maker . The resulting posterior has an analytical expression gi ven by the Gibbs distribution P ( y | x ) = 1 Z β ( x ) P ( y ) exp β U x ( y ) , (2) where Z β ( x ) is a normalizing constant [9]. The expression (2) highlights a connection to infer- ence: bounded-rational decisions can also be computed via Bayes’ rule in which the likelihood is determined by β and U x as follows: P ( y | x ) = P ( y ) P ( x | y ) P y 0 P ( y 0 ) P ( x | y 0 ) , hence P ( x | y ) ∝ exp β U x ( y ) . (3) The objectiv e function (1) can be motiv ated as a trade-off between maximizing expected utility and minimizing information cost [9, 16]. Near -zero values of β , which correspond to hea vily-regularized decisions, yield posterior choice probabilities that are similar to the prior . Conv ersely , with growing values of β , the posterior choice probabilities approach the perfectly-rational limit. Connection to regret. Bounded-rational decision-making is related to r egr et theory [2, 4, 8]. T o see this, define the certainty-equivalent as the maximum attainable value for (1): U ∗ x := max Q ( y | x ) n F Q ( y | x ) o = 1 β log Z β ( x ) . (4) The certainty-equi valent quantifies the net worth of the stimulus x prior to making a choice. The de- cision process treats (4) as a reference utility used in the assessment of the alternati ves. Specifically , the modulation of an y choice is obtained by measuring up the utility against the certainty-equi valent: log P ( y | x ) P ( y ) | {z } Change of y = − β h U ∗ x − U x ( y ) | {z } Regret of y i . (5) Accordingly , the difference in log-probability is proportional to the negati ve regret [3]. The decision- maker’ s utility function specifies a direction of change relative to the certainty-equiv alent, whereas the strength of the modulation is determined by the in verse temperature. 1 For simplicity , here we consider only strictly positive v alues for the inv erse temperature β , but its domain can be extended to ne gativ e v alues to model other effects, e.g. risk-sensiti ve estimation [9]. 2 3 Experimental Methods W e conducted a choice experiment where subjects had to solve puzzles under time pressure. Each puzzle consisted of Boolean formula in conjuncti ve normal form (CNF) that was disguised as an arrangement of circular patterns (see Fig. 1). The task was to find a truth assignment that satisfied the formula. Subjects could pick an assignment by setting the colors of a central pattern highlighted in gray . Formally , the puzzles and the assignments corresponded to the stimuli x ∈ X and the choices y ∈ Y respectiv ely , and the duration of the puzzle was the resource parameter that we controlled (see equation 1). b) c) d) a) ? ? ? Figure 1: Example puzzle . a) Each puzzle is a set of six circularly arranged patches containing patterns of black ( • ) and white circles ( ◦ ). In each trial, the positions of the patches were randomly assigned to one of the six possible locations. Subjects had to choose the three center colors such that there was at least one (color and position) match for each patch. For instance, the choice in (b) only matches four out of six patches (in red), while (c) solves the puzzle. The puzzle is a visualization of the Boolean formula in (d). W e restricted our puzzles to a set of five CNF formulas having 6 clauses, 2 literals per clause, and 3 variables. Subjects were trained only on the first four puzzles, whereas the last one was used as a control puzzle during the test phase. All the chosen puzzles had a single solution out of the 2 3 = 8 possible assignments. W e chose CNF formulas because they provide a general 2 and flexible platform for testing decision- making beha vior . Crucially , unlik e in an estimation task, finding the relation between a stimulus and a choice is non-trivial and requires solving a computational problem. 3.1 Data Collection T wo symmetric versions of the experiment were conducted on Amazon Mechanical T urk. For each, we collected choice data from 15 anonymized participants living in the United States, totaling 30 subjects. Subjects were paid 10 dollars for completing the experiment. The typical runtime of the experiment ranged between 50 and 130 minutes. For each subject, we recorded a sequence of 90 training and 285 test trials. The puzzles were dis- played throughout the whole trial, during which the subjects could modify their choice at will. The training trials allowed subjects to familiarize themselves with the task and the stimuli, whereas the test trials measured their adapted choice beha vior as a function of the stimulus and the task duration. T raining trials were presented in blocks of 18 for a long, fixed duration; the test trials, which were of variable duration, were presented in blocks of 19 (18 regular + 1 control trial). T o a void the col- lection of poor quality data, subjects had to repeat a block if they failed more than 6 trials within the same block, thereby setting a performance threshold that was well abov e chance lev el. P articipants could initiate a block whenever they felt ready to proceed. W ithin a block, the inter-trial durations were drawn uniformly between 0.5 and 1.5s. Each trial consisted of one puzzle that had to be solved within a limited time. T raining trials lasted 10s each, while test trials had durations of 1.25, 2.5, and 5s. Apart from a visual cue sho wn 1s before the end of each trial, there was no explicit feedback communicating the trial length. Therefore, subjects did not know the duration of indi vidual test trials beforehand and thus could not use this information in their solution str ate gy . A trial was considered successful only if all the clauses of the puzzle were satisfied. 2 More precisely , the 2-SA T and SA T problems are NL- and NP-complete respectiv ely . This means that ev ery other decision problem within the same complexity class can be reduced (i.e. rephrased) as a SA T problem. 3 4 Analysis The recorded data D consists of a set of tuples ( x, r , y ) , where x ∈ X is a stimulus, r ∈ R is a resource parameter (i.e. duration), and y ∈ Y a choice. In order to analyze the data, we made the following assumptions: 1. T ransient r e gime : During the training trials, the subjects con ver ged to a set of subjective preferences ov er the choices which depended only on the stimuli. 2. P ermanent r e gime : During the test trials, subjects did not significantly change the prefer- ences that they learned during the training trials. Specifically , choices in the same stimulus- duration group were i.i.d. throughout the test phase. 3. Ne gligible noise : W e assumed that the operation of the input de vice and the cue signaling the imminent end of the trial did not have a significant impact on the distribution over choices. Our analysis only focused only the test trials. Let P ( x, r, y ) denote the empirical probabilities 3 of the tuples ( x, r, y ) estimated from the data. From these, we deri ved the probability distribution P ( x, r ) ov er the stimulus-resource context, the prior P ( y ) ov er choices, and the posterior P ( y | x, r ) over choices giv en the context through marginalization and conditioning. 4.1 Inferring Prefer ences By fitting the model, we decomposed the choice probabilities into: (a) an inv erse temperature func- tion β : R → R ; and (b) a set of subjecti ve utility functions U x : Y → R , one for each stimulus x . W e assumed that the sets X , R , and Y were finite, and we used vector representations for β and the U x . T o perform the decomposition, we minimized the average K ullback-Leibler di ver gence J = X x,r P ( x, r ) X y P ( y | x, r ) log P ( y | x, r ) Q ( y | x, r ) , (6) w .r .t. the in verse temperatures β ( r ) and the utilities U x ( y ) through the probabilities Q ( y | x, r ) of the choice y gi ven the conte xt ( x, r ) as deriv ed from the Gibbs distrib ution Q ( y | x, r ) = 1 Z β P ( y ) exp n β ( r ) U x ( y ) o , (7) where Z β is the normalizing constant. W e used the objective function (6) because it is the Bregman div ergence ov er the simplex of choice probabilities [1]. Thus, by minimizing the objective func- tion (6) we were seeking a decomposition such that the Shannon information contents of P ( y | x, r ) and Q ( y | x, r ) were matched against each other in expectation. W e minimized (6) using gradient descent. For this, we first re wrote (6) as J = X x,β ,y P ( x, r, y ) log P ( y | x, r ) P ( y ) − β ( r ) U x ( y ) + log Z β to expose the coordinates of the exponential manifold and then calculated the gradient. The partial deriv ativ es of J w .r .t. β ( r ) and U x ( y ) are equal to ∂ J ∂ β ( r ) = X x,y P ( x, r ) X y h Q ( y | x, r ) − P ( y | x, r ) i U x ( y ) (8) and ∂ J ∂ U x ( y ) = X x,y P ( x, r ) h Q ( y | x, r ) − P ( y | x, r ) i β ( r ) (9) respectiv ely . The Gibbs distribution (7) admits an infinite number of decompositions, and therefore we had to fix the scaling factor and the offset to obtain a unique solution. The scale was set by clamping the value of β ( r 0 ) = β 0 for an arbitrarily chosen resource parameter r 0 ∈ R ; we used 3 More precisely , P ( x, r, y ) ∝ N ( x, r, y ) + 1 , where N ( x, r, y ) is the count of ocurrences of ( x, r, y ) . 4 β ( r 0 ) = 1 for r 0 = 1 s. The offset was fixed by normalizing the utilities. A simple way to achieve this is by subtracting the certainty-equiv alent from the utilities, i.e. for all ( x, y ) , U x ( y ) ← U x ( y ) − 1 β ( r 0 ) log X y P ( y ) exp n β ( r 0 ) U x ( y ) o . (10) Utilities normalized in this w ay are proportional to the ne gati ve re gret (see Section 2) and thus have an intuitiv e interpretation as modulators of change of the choice distribution. The resulting decomposition algorithm repeats the follo wing two steps until con vergence: first it updates the in verse temperature and utility functions using gradient descent, i.e. β ( r ) ← − β ( r ) − η t ∂ J ∂ β ( r ) and U x ( y ) ← − U x ( y ) − η t ∂ J ∂ U x ( y ) (11) for all ( r , x, y ) ∈ R × X × Y ; and seconds it projects the parameters back onto a standard subman- ifold by setting r = r 0 and normalizing the utilities in each iteration using (10). For the learning rate η t > 0 , we choose a simple schedule that satisfied the Robbins-Monro conditions P t η t = ∞ and P t η 2 t < ∞ . 4.2 Expected Utility and Decision Band width The inferred model is useful for in vestigating the decision-maker’ s performance under dif ferent settings of the resource parameter—in particular , to determine the asymptotic performance limits. T wo quantities are of special interest: the expected utility averaged over the stimuli and the mutual information between the stimulus and the choice, both as functions of the inv erse temperature β . Giv en β , we define these quantities as E U β := X x,y P ( x ) Q β ( y | x ) U x ( y ) and I β := X x,y P ( x ) Q β ( y | x ) log Q β ( y | x ) Q β ( y ) (12) respectiv ely . Both definitions are based on the joint distrib ution P ( x ) Q β ( y | x ) in which Q β ( y | x ) ∝ P ( y ) exp { β U x ( x ) } is the Gibbs distribution deriv ed from the prior P ( y ) and the utility functions U x ( y ) . The marginal ov er choices is given by Q β ( y ) = P x P ( x ) Q β ( y | x ) . The mutual informa- tion I β is a measure of the decision bandwidth, because it quantifies the average amount of informa- tion that the subject has to extract from the stimulus in order to produce the choice. 5 Results 5.1 Decomposition into prior , utility , and in verse temperature For each one of the 30 subjects, we first calculated the empirical choice probabilities and then esti- mated their decomposition into an in verse temperature β and utility functions U x using the procedure detailed in the pre vious section. The mean error of the fit was v ery low ( 0 . 0347 ± 0 . 0024 bits), im- plying that the choice probabilities are well explained by the model. As an example, Fig. 2 sho ws the decomposition for subject 1 (error 0 . 0469 bits, 83% percentile rank) along with a comparison between the empirical posterior and the model posterior calculated from the inferred components using equation (7). As durations become longer and β increases, the model captures the gradual shift from the prior tow ards the optimal choice distribution. As seen in Fig. 3, the resulting decomposition is stable and shows little v ariability across subjects. The stimuli of version B of the experiment differed from version A only in that they were color- in verted, leading to mirror-symmetric decompositions of the prior and the utility functions. The results suggest the following trends: • Prior: Compared to the true distrib ution over solutions, subjects tended to concentrate their choices slightly more on the most frequent optimal solution (i.e. either y = 2 or y = 7 for version A or B respectively) and on the all-black or all-white solution (either y = 1 or y = 8 ). 5 x = 2 Empirical Model Optimum Empirical True Time [s] Choice [id] Stimulus Utility Posterior x = 1 x = 4 x = 6 x = 7* Prior Inv. Temper ature 9/19 3/19 3/19 3/19 1/19 Figure 2: Decomposition of subject 1’ s posterior choice pr obabilities . Each row corresponds to a different puzzle. The left column shows each puzzle’ s stimulus and optimal choice. The posterior distributions P ( y | x, β ) were decomposed into a prior P ( y ) ; a set of time-dependent in verse tem- peratures β r ; and a set of stimulus-dependent utility functions U x ov er choices, normalized relati ve to the certainty-equiv alent (10). The plots compare the subject’ s empirical frequencies against the model fit (in the posterior plots) or against the true optimal choice probabilities (in the prior plot). The stimuli are sho wn on the left (more specifically , one out of the 6! arrangement of patches) along with their probability . Note that the untrained stimulus x = 7 is the color -in verse of x = 2 . • In verse temperatur e: The in verse temperature increases monotonically with longer dura- tions, and the dependency is approximately linear in log-time (Fig. 2 and 3). • Utility functions: In the case of the stimuli that subjects were trained in (namely , x ∈ { 1 , 2 , 4 , 6 } ), the maximum subjective utility coincides with the solution of the puzzle. No- tice that some choices are enhanced while others are suppressed according to their sub- jectiv e utility function. Especially the choice for the most frequent stimulus ( x = 2 ) is suppressed when it is suboptimal. In the case of the untrained stimulus ( x = 7 ), the utility function is comparativ ely flat and variable across subjects. Finally , as a comparison, we also computed the decomposition assuming a Softmax function (or Boltzmann distribution ): Q ( y | x, r ) = 1 Z β exp n β ( r ) U x ( y ) o . (13) The mean error of the resulting fit was significantly worse (error 0 . 0498 ± 0 . 0032 bits) than the one based on (7), implying that the inclusion of the prior choice probabilities P ( y ) improves the explanation of the choice data. 6 x = 2 Time [s] Choice [id] Version A Utility x = 1 x = 4 x = 6 x = 7* Prior Inverse Temper ature Choice [id] Version B Optimum Figure 3: Summary of inferred pr eferences acr oss all subjects . The two rows depict the results for the tw o versions of the e xperiment, each one averaged over 15 subjects. The stimuli of both versions are the same but with their colors inv erted, resulting in a mirror symmetry along the vertical axis. The figure sho ws the inferred utility functions (normalized to the certainty-equiv alent); the in verse temperatures; and the prior ov er choices. Optimal choices are highlighted in gray . Error bars denote one standard deviation. 0.652 1.792 100.00 % Correc t Mutual Information Expec ted Utility Subjec t 1 Averag e 0.688 1.783 95.68 Figure 4: Extrapolation of the performance measur es . The panels show the expected utility E U β , the mutual information I β , and the expected percentage of correct choices as a function of the in- verse temperature β . The top and bottom rows correspond to subject 1 and the a veraged subjects respectiv ely . Each plot shows the performance measure obtained from the empirical choice proba- bilities (blue markers) and the choice probabilities deriv ed from the model (red curve) together with the maximum attainable value (dotted red). 5.2 Extrapolation of performance measures W e calculated the e xpected utility and the mutual information as a function of the in verse tempera- ture using (12). The resulting curves for subject 1 and the average subject are shown in Fig. 4 together with the predicted percentage of correct choices. All the curves are monotonically increasing and upper bounded. The e xpected utility and the percentage of correct choices are conca ve in the in verse temperature, indicating mar ginally diminishing returns with longer durations. Similarly , the mutual information approaches asymptotically the upper bound set by the stimulus entropy H ( X ) ≈ 1 . 792 bits (excluding the untrained stimulus). 7 6 Discussion and Conclusion It has long been recognized that the model of perfect rationality does not adequately capture human decision-making because it neglects the numerous resource limitations that prev ent the selection of the optimal choice [13]. In this work, we considered a model of bounded-rational decision-making inspired by ideas from statistical mechanics and information-theory . A distinctiv e feature of this model is the interplay between the decision-maker’ s preferences, a prior distribution over choices, and a resource parameter . T o test the model, we conducted an experiment in which participants had to solv e puzzles under time pressure. The e xperimental results are very well predicted by the model, which allows us to dra w the following conclusions: 1. Prior : When the decision-making resources decrease, people’ s choices fall back on a prior distribution. This conclusion is supported by two observations. First, the bounded-rational model explains the gradual shift of the subjects’ choice probabilities tow ards the prior as the duration of the trial is reduced (e.g. Fig.2). Second, the model fit obtained by the Soft- max rule (13), which differs from the bounded rational model (7) only by the lack of a prior distribution, has a significantly larger error . Thus, our results conflict with the pre- dictions made by models that lack a prior choice distrib ution—most notably with expected utility theory [11, 17] and the choice models based on the Softmax function (typical in re- inforcement learning, but also in e.g. the logit rule of quantal response equilibria [5] or in maximum entr opy in verse reinfor cement learning [18]). 2. Utility and In verse T emperatur e : Posterior choice probabilities can be meaningfully pa- rameterized in terms of utilities (which capture the decision-maker’ s preferences) and in- verse temperatures (which encode resource constraints). This is evidenced by the quality of the fit and the cogent operational role of the parameters. Utilities are stimulus-contingent enhancers/inhibitors that act upon the prior choice probabilities, consistent with the role of utility as a measure of relativ e desirability in re gr et theory [3] and also related to the cognitiv e functions attributed to the dorsal anterior cingulate cortex [12]. On the other hand, the in verse temperature captures a determinant f actor of choice behavior that is inde- pendent of the preferences—mathematically embodied in the low-rank assumption of the log-likelihood function that we used for the decomposition in the analysis. This assump- tion does not comply with the necessary conditions for rational meta-reasoning, wherein decision-makers can utilize the kno wledge about their o wn resources in their strategy [7]. 3. Pr efer ence Learning : Utilities are learned from experience. As is seen in the utility func- tions of Fig. 3, subjects did not learn the optimal choice of the untrained stimulus (i.e. x = 7 ) in spite of being just a simple color -in version of the most frequent stimulus (i.e. x = 2 ). Our experiment did not address the mechanisms that underlie the acquisition of preferences. Howe ver , given that the information necessary to establish a link between the stimulus and the optimal choice is belo w two bits (that is, far below the 3 2 · 2 2 · 6 = 72 bits necessary to represent an arbitrary member of the considered class of puzzles), it is likely that the training phase had subjects synthesize perceptual features that allowed them to efficiently identify the optimal solution. Other a venues are e xplored in [14, 15] and references therein. 4. Diminishing r eturns : The decision-maker’ s performance is marginally diminishing in the amount of resources. This is seen in the concavity of the expected utility curve (Fig. 4; similarly in the percentage of correct choices) combined with the sub-linear growth of the in verse temperature as a function of the duration (Fig. 3). For most subjects, the model predicts a perfectly-rational choice behavior in the limit of unbounded trial duration. In summary , in this work we ha ve shown empirically that the model of bounded rationality pro vides an adequate explanatory frame work for resource-constrained decision-making in humans. Using a challenging cognitive task in which we could control the time av ailable to arri ve at a choice, we have shown that human decision-making can be explained in terms of a trade-of f between the gains of maximizing subjectiv e utilities and the losses due to the deviation from a prior choice distribution. Acknowledgements This work was supported by the Of fice of Nav al Research (Grant N000141110744) and the Univer - sity of Pennsylvania. 8 References [1] A. Banerjee, S. Merugu, I. S. Dhillon, and J. Ghosh. Clustering with Bre gman Diver gences. J ournal of Machine Learning Resear ch , 6:1705–1749, 2005. [2] D.E. Bell. Regret in decision making under uncertainty. Operations Resear ch , 33:961–981, 1982. [3] H. Bleichrodt and P . P . W akker . Regret theory: A bold alternati ve to the alternati ves. The Economic Journal , 125(583):493–532, 2015. [4] P .C. Fishburn. The F oundations of Expected Utility . D. Reidel Publishing, Dordrecht, 1982. [5] J.W . Friedman and C. Mezzetti. Random belief equilibrium in normal form games. Games and Economic Behavior , 51(2):296–323, 2005. [6] G. Gigerenzer and R. Selten. Bounded rationality: the adaptive toolbox . MIT Press, Cambridge, MA, 2001. [7] F . Lieder, D. Plunkett, J. B. Hamrick, S. J. Russell, N. Hay , and T . Griffiths. Algorithm selection by ratio- nal metareasoning as a model of human strategy selection. Advances in Neural Information Pr ocessing Systems , pages 2870–2878, 2014. [8] G. Loomes and R. Sugden. Regret theory: An alternati ve approach to rational choice under uncertainty. Economic Journal , 92:805–824, 1982. [9] P . A. Ortega and D. A. Braun. Thermodynamics as a theory of decision-making with information- processing costs. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Science , 469(2153), 2013. [10] A. Rubinstein. Modeling bounded rationality . MIT Press, 1998. [11] L.J. Sav age. The F oundations of Statistics . John Wile y and Sons, New Y ork, 1954. [12] A. Shenha v , M. M. Botvinick, and J. D. Cohen. The e xpected value of control: an integrati ve theory of anterior cingulate cortex function. Neuron , 79:217–240., 2013. [13] H. Simon. Models of Bounded Rationality . MIT Press, Cambridge, MA, 1984. [14] N. Sriv astav a and P . R. Schrater . Rational inference of relative preferences. Advances in neural informa- tion processing systems , 2012. [15] N. Sriv astav a, E. V ul, and P . R. Schrater . Magnitude-sensitiv e preference formation. Advances in neural information processing systems , 2014. [16] N. Tishby and D. Polani. Information Theory of Decisions and Actions. In Hussain T aylor V assilis, editor , P erception-r eason-action cycle: Models, algorithms and systems . Springer, Berlin, 2011. [17] J. V on Neumann and O. Morgenstern. Theory of Games and Economic Behavior . Princeton University Press, Princeton, 1944. [18] B. D. Ziebart, A. L. Maas, J. A. Bagnell, and A. K. Dey . Maximum Entropy In verse Reinforcement Learning. In AAAI , pages 1433–1438, 2008. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment