희소 오토인코더 기반 반지도 학습 전화 분류 성능 향상
본 논문은 TIMIT 데이터베이스의 프레임 기반 전화(phoneme) 분류에 희소 오토인코더와 반지도 학습을 결합한 단일층 신경망을 적용한다. 라벨이 있는 데이터와 없는 데이터를 동시에 미니배치 SGD로 학습함으로써, 동일한 양의 라벨 데이터만을 사용한 전통적인 지도 학습보다 높은 정확도를 달성한다. 특히 라벨 비율이 낮을수록 큰 이득을 보이며, 기존 그래프 기반 반지도 학습 방법들과도 경쟁력 있는 성능을 보여준다.
저자: Akash Kumar Dhaka, Giampiero Salvi
본 논문은 자동 음성 인식(ASR) 분야에서 라벨이 충분히 확보되지 않은 저자원 언어에 대한 해결책으로, 희소 오토인코더(sparse autoencoder)를 이용한 반지도 학습(semi‑supervised learning) 접근법을 제안한다. 전통적인 딥 뉴럴 네트워크는 대규모 라벨 데이터에 의존해 높은 정확도를 달성했지만, 라벨링 비용이 높은 음성 데이터에서는 실용적이지 않다. 기존의 비지도 사전학습‑지도 미세조정 파이프라인은 초기 가중치를 찾는 데는 도움이 되지만, 최종 모델이 라벨 정보에 충분히 최적화되지 못한다는 한계가 있다.
이에 저자들은 라벨이 있는 데이터와 없는 데이터를 동시에 활용하는 학습 방식을 설계하였다. 핵심은 오토인코더의 재구성 손실(E_R)과 분류 손실(E_C)을 선형 결합한 전체 손실 E = E_R + αE_C 를 미니배치 확률적 경사 하강법으로 최적화하는 것이다. α는 라벨 비율에 따라 검증 세트에서 최적화되는 하이퍼파라미터이며, 라벨이 적을수록 재구성 손실에 더 큰 비중을 둔다.
모델 구조는 단일 은닉층을 갖는 희소 오토인코더이다. 입력 x는 39 차원 MFCC에 전후 5프레임을 연결해 429 차원 벡터로 만든 뒤, 스피커별 평균·분산 정규화를 적용한다. 인코더는 tanh 활성화와 함께 가중치 W_E, b_E 로 은닉 표현 z = tanh(W_E x + b_E)를 만든다. 이 z는 두 갈래로 흐른다. 하나는 디코더 W_D, b_D 를 통해 재구성 x̂ = tanh(W_D z + b_D)를 수행해 E_R = ∥x − x̂∥²를 계산한다. 다른 하나는 분류기 W_C, b_C 로 소프트맥스 출력을 h = softmax(W_C z + b_C) 를 만든 뒤, 교차 엔트로피 E_C = −∑ y log h 로 라벨이 있는 샘플에 대해 손실을 구한다. 라벨이 없는 샘플은 디코더 경로만 활성화되어 E_R만 역전파된다.
학습 과정에서는 Adagrad와 선형 감소 학습률 스케줄을 사용했으며, 은닉 차원을 입력 차원보다 크게 설정해(최적 10 000 노드) 희소성을 촉진한다. 희소성은 L1 정규화 혹은 활성화 제한을 통해 구현되었다. 또한 입력에 무작위 마스크(corruption)를 적용해 잡음에 강인한 특징을 학습한다.
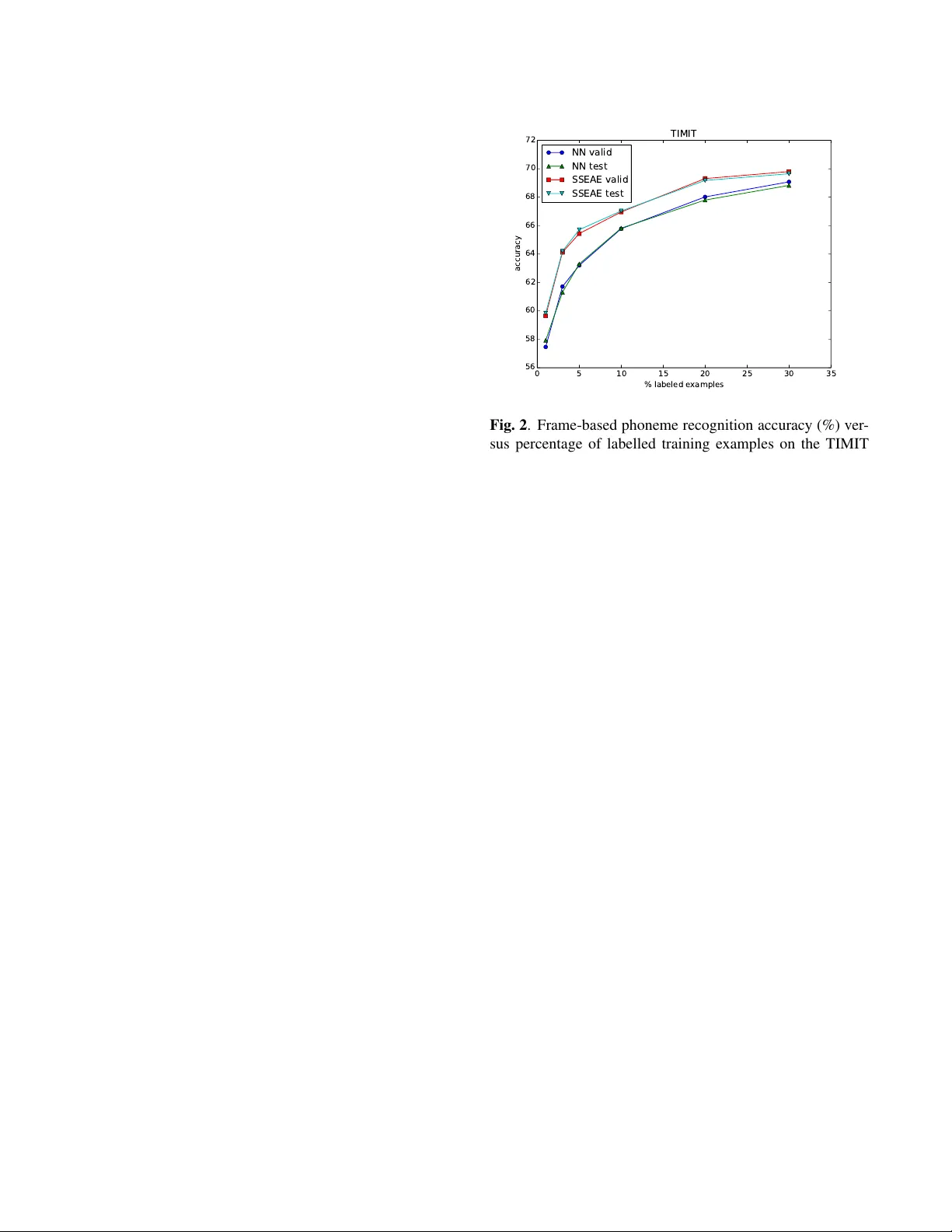
실험은 TIMIT 코어 테스트 셋(192문장)과 개발 셋(184문장)을 사용했으며, 총 1 068 818 프레임을 학습 데이터로 활용했다. 라벨 비율을 1 %, 3 %, 5 %, 10 %, 20 %, 30 %로 변동시켜 각각에 대해 α와 은닉 노드 수를 검증 세트에서 최적화했다. 결과는 다음과 같다. 라벨 비율이 1 %일 때, 제안 방법(SSSAE)은 검증 정확도 59.65 %/테스트 59.84 %를 기록했으며, 동일 라벨 양을 사용한 순수 지도 학습(NN)은 각각 57.46 %/57.93 %에 불과했다. 라벨 비율이 10 %일 때는 SSSAE가 66.96 %/67.03 %를 달성해 NN의 65.78 %/65.82 %보다 약 1.2 %p 향상되었다. 라벨 비율이 30 %일 때는 차이가 0.7 %p 수준으로 감소했다.
또한, Liu et al.이 제시한 네 가지 그래프 기반 반지도 학습 방법(LP, MP, MAD, pMP)과 비교했을 때, SSSAE는 대부분의 방법보다 우수했으며, 특히 pMP(테스트 71.06 %)만이 약간 앞섰다. 그래프 기반 방법은 데이터 간 유사도 그래프를 구축하고 라플라시안 행렬을 이용해 라벨 전파를 수행하지만, O(N³) 복잡도로 대규모 데이터에 비효율적이다. 반면 SSSAE는 미니배치 SGD를 사용해 선형 시간 복잡도를 유지한다.
논문의 결론은 다음과 같다. (1) 희소 오토인코더와 반지도 학습을 결합한 단일층 모델은 라벨이 제한된 상황에서 기존 지도 학습보다 일관되게 높은 성능을 보인다. (2) 라벨 비율이 낮을수록 이득이 크며, 실제 음성 인식 시스템에서 라벨이 부족한 경우 실용적이다. (3) 현재는 프레임 기반 전화 분류에 국한되었으며, 대규모 어휘 인식, 필터뱅크 특징, 다층 스택형 구조 등으로 확장할 여지가 있다. 향후 연구에서는 이러한 확장을 통해 실제 ASR 파이프라인에 적용하고, 그래프 기반 방법과의 하이브리드 모델을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기