Semi-supervised Learning with Sparse Autoencoders in Phone Classification
We propose the application of a semi-supervised learning method to improve the performance of acoustic modelling for automatic speech recognition based on deep neural net- works. As opposed to unsupervised initialisation followed by supervised fine t…
Authors: Akash Kumar Dhaka, Giampiero Salvi
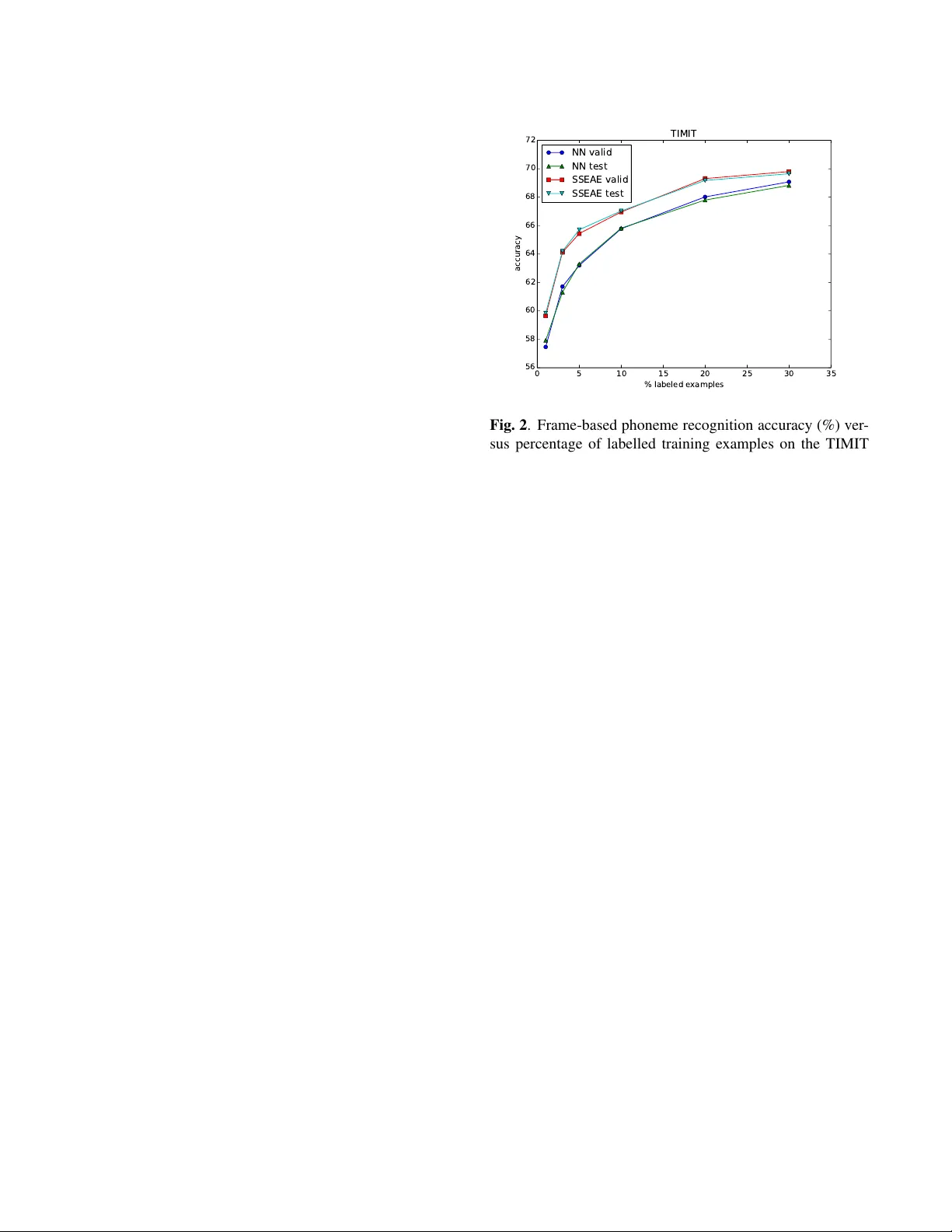
SEMI-SUPER VISED LEARNING WITH SP ARSE A UT OENCODERS IN PHONE CLASSIFICA TION Akash K umar Dhaka and Giampier o Salvi KTH Royal Institute of T echnology , School of Computer Science and Communication, Dept. for Speech, Music and Hearing, Stockholm, Sweden { akashd, giampi } @kth.se ABSTRA CT W e propose the application of a semi-supervised learning method to improv e the performance of acoustic modelling for automatic speech recognition based on deep neural net- works. As opposed to unsupervised initialisation follo wed by supervised fine tuning, our method takes advantage of both unlabelled and labelled data simultaneously through mini- batch stochastic gradient descent. W e tested the method with varying proportions of labelled vs unlabelled observations in frame-based phoneme classification on the TIMIT database. Our e xperiments sho w that the method outperforms standard supervised training for an equal amount of labelled data and provides competiti ve error rates compared to state-of-the-art graph-based semi-supervised learning techniques. Index T erms — automatic speech recognition, deep learn- ing, semi-supervised learning, autoencoders, sparsity 1. INTR ODUCTION Deep Learning has rev olutionised research in Automatic Speech Recognition (ASR) as well as man y other fields of application of machine learning (see [1, 2] for extensi ve re- views). Despite, the recent significant improvements made in word error rates (WERs), most of the experiments hav e been reported on lar ge fully-labelled data sets. The initial paradigm, where unsupervised initialisation of the network weights was followed by supervised fine-tuning of the pa- rameters [3, 4], was abandoned in fav our of fully supervised methods with more efficient models (e.g. [5]). Howe ver , for under-resources languages, where large amounts of la- belled data are not av ailable, non fully supervised learning techniques are still relev ant. Unsupervised learning has the limit of finding an initial set of weights, and consequently data representations, that are not specifically optimised for the problem at hand. As an example, we would find the same representations for speech or speak er recognition which ha ve orthogonal objectiv es. An alternati ve learning paradigm, that has recently been applied in the field of computer vision as well as ASR, is semi-supervised learning where labelled and unlabelled observations are used jointly [6, 7, 8, 9]. Semi-supervised learning using neural network has also been explored in [10], by means of a self-training scheme. The self-training scheme is, ho we ver , based on heuristics and prone to reinforcing poor predictions. The work done by [7, 8] is one of the first attempts on us- ing these semi-supervised learning in ASR. The authors pro- pose a number of algorithms emplo ying graph based learning (GBL-SSL), and obtain better WERs over a baseline neural network. In [9] the authors extend the initial results from frame based phoneme classification to large vocabulary ASR. Graph based learning is, howe ver , computationally intensi ve, and the addition of a new point in data requires the reev alua- tion of the graph laplacian. In [11], Ranzato and Szummer propose a semi-supervised learning method based on linearly combining the supervised cost function of a deep classifier with the unsupervised cost function of a deep autoencoder and minimising the combi- nation of costs through mini-batch stochastic gradient de- scent via standard backpropagation. The authors apply their method to finding representations of text documents for in- formation retriev al and classification. W e propose to use a similar approach to frame-based phoneme recognition in ASR. Although our objective func- tion is the same as the one proposed in [11], our set up is different in a number of w ays. Firstly , instead of the compact and lower dimensional encoding used in [11], we employ sparse encoding. Secondly , instead of stacking a number of encoders, decoders and classifiers in a deep architecture as in [11], we use a single layer model. This is motiv ated by work in [6], where the authors analyse the effect of se veral model parameters in unsupervised learning of neural networks on computer vision benchmark data sets such as CIF AR-10 and NORB. They conclude that state-of-the-art results can be achiev ed with single layer networks regardless of the learning method, if an optimal model setup is chosen. W e perform phoneme recognition on the TIMIT data set and compare the performance of our model with the results obtained with standard supervised learning and with the com- x W E tanh W D tanh E R + W C softmax E C E y x z ˆ x α encoder decoder classifier Fig. 1 . Flow chart for the cost calculation in a single layer of the network. Three components are considered: encoder, decoder , and classifier . The loss is weighted sum of cross- entropy E C and reconstruction loss E R . If se veral layers are stacked together, only the encoder/decoder pairs are retained after training. putationally more expensi ve GBL methods. The paper is organised as follo ws: Section 2 describes the method. Section 3 reports details on the experimental set-up. Section 4 reports the results and, finally , Section 5 concludes the paper . 2. METHOD The architecture of a single layer of our model is depicted in Figure 1. If we remove the bottom path, this is equiv alent to an autoencoder with a set of encoding weights, a logistic layer , a subsequent set of decoding weights and a ne w non- linearity . In our model, the representation z obtained by the encoder is also used by a classifier in parallel with the regular decoder . The aim of combining unsupervised and supervised cost functions is to use both the unlabelled and labelled data in an ef ficient way in order to obtain good representations of the input as well as good prediction and discriminative abilities from our network. Although the figure depicts a single layer , in [11] it was shown that a stack of such elements can be trained layer -by- layer in a greedy way . In our experiments, only single layer models were considered. The model is trained optimising the combined cost of the reconstruction error E R and the classification errors E C giv en respectiv ely by the autoencoder and the classification network. The combination is linear and defined as: E = E R + αE C (1) where α is a h yper-parameter controlling the proportion of the two costs in the objectiv e function. α is optimised on a validation set that is independent from the training set. Its optimal v alue depends in general to the proportion of labelled versus unlabelled examples in the training set, as will also be shown in Section 4. In the supervised setting, the cost function is the cross- entropy logloss gi ven by: E C = − N C X i =1 y i log h i (2) h j = exp(( W C ) j .z + b C j ) P i exp(( W C ) i .z + b C i ) , (3) where h denotes softmax output of the classifier, W C and b C are the set of weights and biases for the classification network and N C is the number of output classes. The variable z de- notes the output of the encoder network and is defined as: z = tanh( W E x + b E ) , (4) Where W E and b E are the weights and biases of the encoder network, and x is the input to the entire model. In the unsupervised path through the model, the cost func- tion is the second de gree norm of difference between origi- nal input and reconstructed input, where the input and output hav e the same dimensions. It has been found, that adding noise to the original input by a process called ’corruption’ in which some dimensions of the input vector are randomly picked and set to zero, helps the network to learn even a better representation as described in [12]. In this case, the encoded vector z defined above is fed to the decoder layer to produce the final output in the form. ˆ x = tanh( W D z + b D ) , (5) where W D and b D are the weights and biases of the decoder network. Gi ven the above definitions, the unsupervised re- construction error E R is defined as: E R = p X i =1 || x i − ˆ x i || 2 , (6) where x i is the input for a single datapoint, and ˆ x i is the re- constructed output for a single datapoint. This cost function is the same as that of a regular auto-encoder . In practice, we compute the cost E R av eraged ov er a batch of p points, which is why the optimisation is called as mini-batch Stochas- tic Gradient Descent (SGD). When the input datapoint is not accompanied by a label, the classifier part of the layer is not updated, and the loss func- tion simply reduces to E R . This model can be iteratively ap- plied to sev eral layers. Howe ver , in our experiments, we use just a single layer for feature representation. It is important to note that the update of encoder weights W E is dependent both on the decoder weights W D and on the classifier weights W C , and the delta propagated in the backpropagation algo- rithm will be a linear combination of the deltas calculated in both parts. W e used Adapti ve Learning Rate scheme with lin- ear decay , in which the learning rate decays linearly after a certain number of epochs. The size of the hidden representation z is larger than the input size in our experiments. Consequently , we promote sparsity in our feature representation. In autoencoders, encod- ing and decoding weights are often tied, which means that the decoder weight matrix is the transpose of the encoder weight matrix: W D = W 0 E . This reduces the amount of free parame- ters available, but also the expressiv e power of the model. In our experiments, instead, we optimise W D and W E indepen- dently . This makes our model more expressi ve at the cost of more computational overhead and possible delayed con ver- gence. Another aspect that increases the computational cost of our model is the use of sparse autoencoders as opposed to autoencoders with bottleneck architecture which have fewer nodes in hidden layer and, consequently , reduced memory and computational complexity . Ho wever , the computational cost is linear in the number of training samples, and thus it is more efficient than graph based semi-supervised learning algorithms which hav e cubic complexity O ( N 3 ) . 3. EXPERIMENTS 3.1. Experimental Setup W e performed our experiments on the standard TIMIT data set [13] for frame-based phoneme classification. W e used the standard core test set of 192 sentences, and a de velop- ment/validation set of 184 sentences. F or training, we had 3512 sentences. Similarly as a part of standard procedure of experiments on TIMIT , glottal stop segments are excluded. The data is created with the help of standard recipes given in [14, 15]. The input to our network was created by first ex- tracting a 39-dimensional feature v ectors for each frame. The feature vector is made of 12 MFCC coefficients computed at a rate of 10 ms with an overlapping window of 20 ms, 1 en- ergy coefficient, deltas and delta-deltas. For each time step, the features obtained 5 frames to the left to 5 frames to the right are concatenated together to form a final vector has a dimension of 11 × 39 = 429 coef ficients as in [16]. Speaker- dependent mean and v ariance normalisation was also applied. The total number of frames in the training set is 1068816. The v alidation set has 56005 frames in total, and the test set has 57919 frames. These counts are in line with the e xper- iments of [7, 17]. For training, we used the standard phone set of 48 phones, collapsed into 39 phones for ev aluation as in [18]. This means, the output layer will hav e 48 nodes, but at the time of ev aluation, the 48 phonemes will be reduced to 39 phonemes. This procedure has also been used in [7]. Al- though it is more common to use senones as the target labels for the classification network as in [16], the output of our clas- sification network was based on phonemes in order to be able to compare with other studies on semi-supervised learning for speech. T o simulate the effect of missing labels during training, the training set was di vided into a labelled portion and an un- 0 5 10 15 20 25 30 35 % labeled examples 56 58 60 62 64 66 68 70 72 accuracy TIMIT NN valid NN test SSEAE valid SSEAE test Fig. 2 . Frame-based phoneme recognition accuracy (%) ver- sus percentage of labelled training examples on the TIMIT database. NN: neural network trained with supervised back- propagation. SSSAE: our method. Both v alidation and test accuracy rates are shown. See T able 1 for the corresponding numerical values. labelled portion of data set. The percentage of labelled frames in the training set was v aried from 1% to 30% with interme- diate steps: 3%, 5%, 10%, 20%. For each of these conditions, we optimised the hyper-parameter α on the validation set. All the accuracy results are reported for the optimal v alue of α . Finally the number of nodes in the encoder network was also optimised on the v alidation set resulting in an optimal value of 10000 nodes. As a baseline, we compare the results obtained with our method with those obtained with a similar neural network trained with supervised backpropagation, on the same amount of labelled e xamples. W e also compare our results with those obtained in the literature on semi-supervised learning. 3.2. Practical Setup W e used Kaldi [14] and PDNN [15] for feature extraction, Theano [19] for symbolic algebra and GPU computing. The experiments were run on a T itan X card installed on a Ub untu 14.04 based machine. 4. RESUL TS T able 1 and Figure 2 show the frame-le vel classification ac- curacy rates for a neural network trained in a supervised way (NN) and the proposed single layer semi-supervised sparse auto-encoder (SSSAE) for varying percentage of labelled data. Both validation set accuracy and test set accuracy are reported. The hyper-parameters of the neural network such as learning rate tuned using the v alidation set are also shown Results on TIMIT Labelled Observations Neural Network SSSAE % # valid. acc. (%) test acc. (%) valid acc. (%) test acc. (%) α 1 10688 57.46 57.93 59.65 59.84 100 3 32065 61.71 61.31 64.12 64.20 150 5 53441 63.20 63.30 65.44 65.71 150 10 106881 65.78 65.82 66.96 67.03 400 20 213763 68.02 67.80 69.31 69.18 600 30 320644 69.08 68.83 69.80 69.65 900 T able 1 . Results on frame-based phoneme classification on the validation and test sets on the TIMIT material. Our method (SSSAE) is compared to a neural network trained with supervised backpropagation with the same amount of labelled data. The total number of training frames is 1068818. The value of α is optimised on the validation set as the proportion of labelled examples is v aried. Comparison with other methods 10% labelled 30% labelled Method Reference T est accuracy (%) NN this work 65.94 69.24 LP [7] 65.47 69.24 MP [7] 65.48 69.24 MAD [7] 66.53 70.25 pMP [7] 67.22 71.06 SSSAE this work 67.03 69.65 T able 2 . Accuracy rates (%) for frame-based phoneme clas- sification on TIMIT for the baseline (NN), the four dif ferent algorithms in GBL-SSL [7] and our model, SSSAE in the table. The neural network contains 2000 units in the hidden layer as in [7, 17] and performs similarly to the one reported there. T able 1 and Figure 2 show that the method always per- forms better than the supervised baseline by as much as 2.9% absolute improvement. As expected this advantage decreases when the proportion of labelled training examples is increased. The validation and test errors are always very close, indicating that the parameters optimised on the val- idation set generalise well to the test set. As expected, the optimal v alue for α is strongly dependent on the proportion of labelled material. The higher the proportion the more weight the algorithm gi ves to the classification error , compared to the unsupervised reconstruction error . In T able 2, we compare the performance of our system to the results obtained with graph based semi-supervised learn- ing methods published in [7] on 10% and 30% labelled data. W e observe that our system performs better than all the tech- niques mentioned except the Prior Regularised Measure Prop- agation (pMP) algorithm. 5. CONCLUSIONS W e reported results on frame based phoneme classification on the TIMIT database using semi-supervised learning based on sparse autoencoders. W e observe that our method outper- forms a neural network trained with supervised backpropaga- tion on the same amount of labelled training data in all ex- perimental conditions. Our results also outperform many of the semi-supervised learning methods proposed in the litera- ture for a similar task, with the exception of Prior -Regularised Measure Propagation (pMP) method. As expected, the ad- vantage of using our method decreases when the proportion of labelled training observ ations is increased. Howe ver , we can argue that in realistic situations we will always find an abundance of unlabelled data as compared to data that was carefully annotated. As a consequence, it becomes more im- portant for us to in vestigate our model when the percentage of labelled data is low . In spite of the promising results, in order to draw general conclusions on ASR, we would need to test our method on a word recognition task, and, in particular , on large-vocab ulary ASR. Howe ver , the improvements we see in frame-le vel phoneme classification are an incenti ve to continue work in this direction. Possible improvements may be obtained by using alternative features (e.g. filterbank features) instead of the MFCCs that were used here to allo w for comparison with previous results in the literature. W e may also test how the results vary if we add depth to the model, by stacking sev eral blocks of autoencoders/classifiers. 6. A CKNO WLEDGMENTS The GeForce GTX TIT AN X used for this research were do- nated by the NVIDIA Corporation. 7. REFERENCES [1] Y ann LeCun, Y oshua Bengio, and Geoffre y Hinton, “Deep learning, ” Natur e , v ol. 521, no. 7553, pp. 436– 444, 2015. [2] J ¨ urgen Schmidhuber , “Deep learning in neural net- works: An ov erview , ” Neural Networks , vol. 61, pp. 85–117, 2015. [3] Dumitru Erhan, Y oshua Bengio, Aaron Courville, Pierre-Antoine Mansagol, and Pascal V incent, “Why does unsupervised pre-training help deep learning?, ” Journal of Machine Learning Resear ch , vol. 11, pp. 625–660, 2010. [4] Ilya Sutske ver , James Martens, George Dahl, and Ge- offre y Hinton, “On the importance of initialization and momentum in deep learning, ” in Pr oc. of ICML , 2013. [5] M.D. Zeiler, M. Ranzato, R. Monga, M. Mao, K. Y ang, Q.V . Le, P . Nguyen, A. Senior, V . V anhoucke, J. Dean, and G.E. Hinton, “On rectified linear units for speech processing, ” in Pr oc. ICASSP , 2013. [6] A. Coates, H. Lee, and A.Y . Ng, “ An analysis of single- layer networks in unsupervised feature learning, ” in Pr oceedings of the F ourteenth International Confer ence on Artificial Intelligence and Statistics , Geof frey Gor- don, David Dunson, and Miroslav Dud ´ ık, Eds. 2011, vol. 15 of JMLR W orkshop and Confer ence Pr oceed- ings , pp. 215–223, JMLR W&CP . [7] Y uzong Liu and Katrin Kirchhof f, “Graph-based semi- supervised learning for phone and segment classifica- tion., ” in INTERSPEECH , 2013, pp. 1840–1843. [8] Y uzong Liu and Katrin Kirchhof f, “Graph-based semi- supervised acoustic modeling in DNN-based speech recognition, ” in Proceedings of the IEEE Spoken Lan- guage T echnology W orkshop (SLT) , 2014, pp. 177–182. [9] Y . Liu and K. Kirchhoff, “Graph-based semisu- pervised learning for acoustic modeling in automatic speech recognition, ” IEEE/A CM T ransactions on Au- dio, Speech, and Language Pr ocessing , vol. 24, no. 11, pp. 1946–1956, Nov 2016. [10] Karel V esel ´ y, Mirko Hannemann, and Luk ´ a ˇ s Burget, “Semi-supervised training of deep neural networks., ” in Pr oceedings of IEEE Confer ence on Automatic Speech Recognition and Understanding (ASR U) , 2013, pp. 267– 272. [11] Marc’Aurelio Ranzato and Martin Szummer , “Semi- supervised learning of compact document representa- tions with deep networks., ” in ICML , W illiam W . Co- hen, Andrew McCallum, and Sam T . Roweis, Eds. 2008, vol. 307 of ACM International Confer ence Pr oceeding Series , pp. 792–799, A CM. [12] Y . Bengio, P . Lamblin, D. Popovici, and H. Larochelle, “Greedy layer-wise training of deep networks, ” in Ad- vances in Neural Information Pr ocessing Systems 19 , B. Sch ¨ olkopf, J. Platt, and T . Hoffman, Eds., pp. 153– 160. MIT Press, Cambridge, MA, 2007. [13] William M. Fisher, George R. Doddington, and Kath- leen M. Goudie-Marshall, “The darpa speech recogni- tion research database: Specifications and status, ” in Pr oceedings of DARP A W orkshop on Speech Recogni- tion , 1986, pp. 93–99. [14] Daniel Pov ey , Arnab Ghoshal, Gilles Boulianne, and Burget, “The kaldi speech recognition toolkit, ” in IEEE 2011 W orkshop on Automatic Speec h Recognition and Understanding . Dec. 2011, IEEE Signal Processing So- ciety , IEEE Catalog No.: CFP11SR W -USB. [15] Y . Miao, “Kaldi+PDNN: Building DNN-based ASR Systems with Kaldi and PDNN, ” ArXiv e-prints , Jan. 2014. [16] Abdel rahman Mohamed, T ara N. Sainath, Geor ge E. Dahl, Bhuvana Ramabhadran, Geoffrey E. Hinton, and Michael A. Picheny , “Deep belief networks using dis- criminativ e features for phone recognition., ” in ICASSP . 2011, pp. 5060–5063, IEEE. [17] John Labiak and Karen Liv escu, “Nearest neighbors with learned distances for phonetic frame classifica- tion, ” in Interspeech , 2011. [18] K. F . Lee and H. W . Hon, “Speaker-independent phone recognition using hidden mark ov models, ” IEEE T rans- actions on Acoustics, Speech, and Signal Pr ocessing , vol. 37, no. 11, pp. 1641–1648, No v 1989. [19] Pascal Lamblin, Razv an Pascanu, James Ber gstra, Ian J. Goodfellow , Arnaud Bergeron, Nicolas Bouchard, and Y oshua Bengio, “Theano: new features and speed im- prov ements, ” 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment