약한 라벨의 센서 데이터에서 강력한 예시 추출
EXTRACT는 정확한 시작·끝 위치를 모르는 약한 라벨만으로도 다변량 시계열에서 반복되는 이벤트를 자동으로 찾아낸다. 특징을 이진 매트릭스로 변환하고 블러링해 길이와 차원에 무관하게 유사성을 평가해, 실시간 수준의 속도로 96%까지 정밀·재현율을 달성한다.
저자: Davis W. Blalock, John V. Guttag
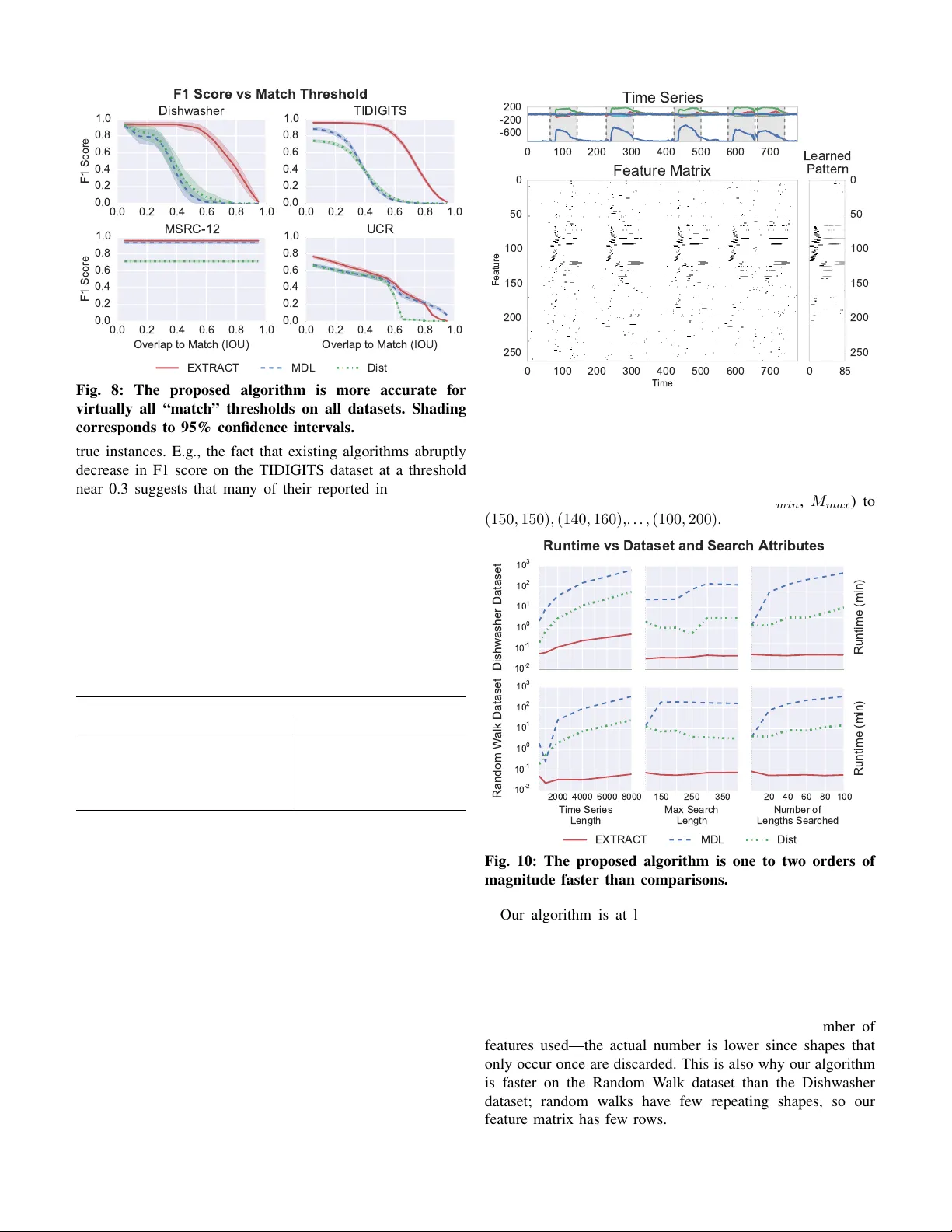
### 1. 서론 및 문제 정의
웨어러블·IoT 기기의 급증으로 가속도, 전압, 전류 등 저수준 센서 시계열 데이터가 폭발적으로 늘어나고 있다. 그러나 실제 응용에서는 이러한 원시 신호가 아니라 ‘제스처’, ‘가전 작동’, ‘음성 단어’와 같은 고수준 이벤트가 필요하다. 라벨링된 데이터가 풍부한 이미지·텍스트와 달리, 시계열 데이터는 정확한 이벤트 경계가 없는 약한 라벨만 제공되는 경우가 많다. 저자들은 이러한 상황을 “시간 구간에 이벤트가 여러 번 존재한다는 것만 알고, 정확한 시작·끝은 모르는” 문제로 정의하고, 이를 해결하기 위한 일반적인 알고리즘을 제시한다.
### 2. 기존 연구와 차별점
기존 모티프·패턴 탐색 기법은 (1) 단일 차원, (2) 동일 길이, (3) 모든 차원이 영향을 받는 등 강한 가정을 전제로 한다. 또한 대부분은 유사도 측정에 유클리드 거리 등을 사용해 전체 윈도우를 비교하므로, 길이 불일치와 시간 왜곡에 취약하다. EXTRACT는 (i) 다변량 시계열, (ii) 부분 차원만 영향을 받는 경우, (iii) 이벤트 길이와 개수가 가변적인 상황을 모두 허용한다.
### 3. 핵심 아이디어와 수학적 모델
- **특징 매트릭스 Φ**: 전체 시계열을 슬라이딩 윈도우로 스캔하면서, 무작위로 추출한 짧은 서브시퀀스(‘shape’)가 해당 위치에 존재하면 1, 없으면 0을 기록한다. 이렇게 하면 각 윈도우는 고정 길이(최대 가능한 이벤트 길이 M_max)와 무관하게 이진 벡터로 표현된다.
- **블러링**: 시간축으로 1을 확장해 인접 시점에서도 특징이 존재하는 것처럼 만든다. 이는 시간 스케일링·워핑에 강인하게 만든다.
- **목표 함수**: 각 특징 j에 대해 전체 시계열에서의 발생 확률 θ₀ⱼ와 후보 윈도우 집합 R에서의 발생 확률 θ₁ⱼ를 계산하고, 로그 비율 log(θ₁ⱼ/θ₀ⱼ)와 특징 빈도 cⱼ를 곱해 합산한다. 최적의 R*와 특징 집합 F를 MAP 추정한다(식 (1)).
- **제약**: 윈도우 간 겹침은 M_min−1 이하, 길이 범위는
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기