고차원 데이터 결측값 추정을 위한 스웜 인텔리전스와 딥러닝 결합 방법
본 논문은 고차원 데이터에서 MCAR와 MAR 결측 메커니즘 및 임의 결측 패턴을 고려하여, 제한볼츠만머신 기반 자동인코더와 파이어플라이 알고리즘을 결합한 하이브리드 모델을 제안한다. 딥러닝으로 데이터 분포를 비지도 학습하고, 이를 목표 함수에 포함시켜 스웜 인텔리전스가 결측값을 최적화하도록 설계하였다. 실험은 MNIST 이미지 데이터를 사용했으며, 높은 정확도의 결측값 복원과 향상된 분류 성능을 보였지만 연산 시간이 길다는 트레이드오프를 지적…
저자: Collins Leke, Tshilidzi Marwala
본 논문은 고차원 데이터셋에서 발생하는 결측값 문제를 해결하기 위해, 결측 메커니즘인 완전 무작위(MCAR)와 무작위(MAR) 그리고 임의 결측 패턴(arbitrary pattern)을 고려한 새로운 하이브리드 접근법을 제안한다. 연구 배경으로는 결측값이 존재하면 의사결정 및 데이터 분석의 정확도가 크게 저하된다는 점을 들며, 특히 의료, 제조, 에너지 분야의 센서 데이터와 이미지 인식 시스템에서 결측값 복원이 필수적임을 강조한다.
제안된 방법은 두 단계로 구성된다. 첫 번째 단계는 제한볼츠만머신(RBM)으로 구성된 스택드 자동인코더(Stacked Autoencoder)를 이용해 데이터의 잠재적 특성을 비지도 학습한다. RBM은 가시층과 은닉층 사이의 이중 확률적 연결을 통해 입력 데이터의 확률분포를 모델링하며, 대조 발산(CD‑k) 알고리즘을 사용해 파라미터를 효율적으로 업데이트한다. 이 과정에서 데이터의 복잡한 상관관계와 고차원 구조를 압축된 잠재공간에 표현한다.
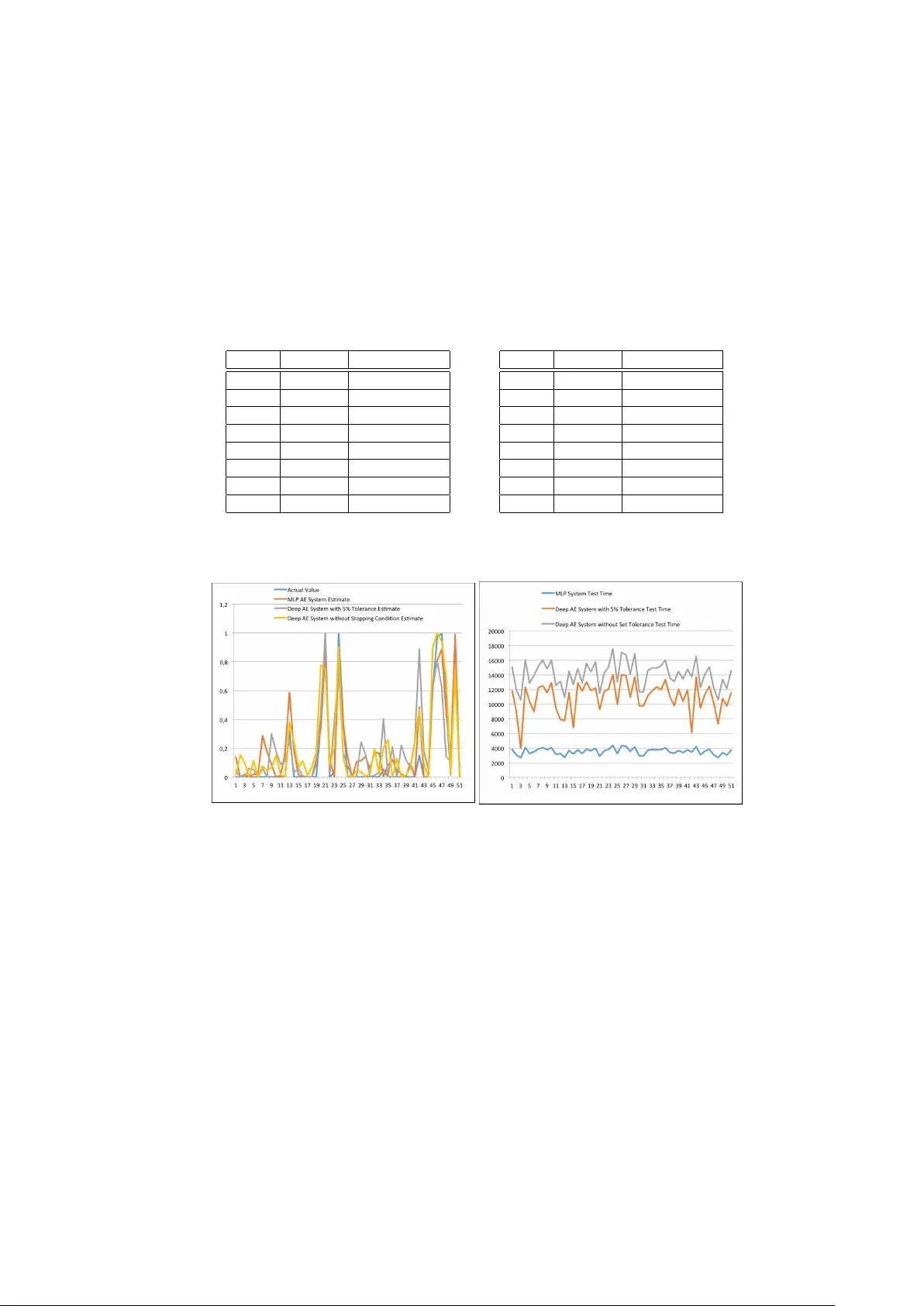
두 번째 단계에서는 파이어플라이 알고리즘(Firefly Algorithm, FA)을 적용해 결측값을 최적화한다. FA는 개체(파이어플라이) 간의 밝기(목표 함수값)와 거리(해결책 간 차이)에 기반한 매력도 함수를 사용해 전역 탐색을 수행한다. 여기서 목표 함수는 자동인코더가 재구성한 데이터와 실제 관측값 사이의 재구성 오류이며, 이 오류를 최소화하도록 파이어플라이가 이동한다. 논문은 FA의 매개변수(α=0.25, β₀=0.2, γ=1, 반복 1000회)를 실험적으로 최적화했으며, 이러한 설정이 결측값 추정 정확도를 크게 향상시켰다고 보고한다.
연구는 MNIST 손글씨 이미지 데이터셋(60,000 훈련, 10,000 테스트, 784 차원)을 실험 대상으로 선택했다. 픽셀값을 무작위로 10%~30% 결측시킨 후, 제안된 DL‑SI 프레임워크를 적용하였다. 결과는 기존 k‑Nearest Neighbor, 유전 알고리즘 기반 신경망, PCA‑GA 등과 비교했을 때 평균 제곱오차(MSE)가 현저히 낮았으며, 결측값 복원 후 재학습된 분류 모델의 정확도도 원본 대비 1~2% 상승하였다. 이는 결측값 복원이 downstream task(분류) 성능에 긍정적인 영향을 미친다는 것을 입증한다.
하지만 이 접근법은 자동인코더 학습과 FA 최적화 두 단계가 순차적으로 진행되기 때문에 실행 시간이 기존 방법에 비해 2~3배 정도 증가한다는 단점을 가지고 있다. 논문은 고성능 GPU 활용 및 병렬화 기법을 통해 이 문제를 완화할 수 있다고 제안한다.
관련 연구 섹션에서는 기존에 제안된 하이브리드 유전‑신경망, k‑NN‑신경망, 자동인코더‑유전 알고리즘, PCA‑GA 등 다양한 결측값 보정 방법을 소개하고, 이들 방법이 주로 저차원 혹은 특정 패턴에 한정된 경우가 많아 고차원 데이터에 대한 일반화가 부족함을 지적한다. 본 연구는 이러한 한계를 극복하고, 스웜 인텔리전스와 딥러닝을 결합함으로써 고차원 데이터의 복잡한 상관관계를 동시에 고려한다는 점에서 차별성을 갖는다.
결론에서는 제안된 방법이 높은 정확도의 결측값 복원을 제공하지만 연산 비용이 큰 트레이드오프가 존재함을 강조한다. 향후 연구 방향으로는 다른 메타휴리스틱(예: 입자군집 최적화, 개미 군집)과의 비교, 실시간 스트리밍 데이터에 대한 적용, 자동 파라미터 튜닝 및 경량화 모델 설계 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기