단어 임베딩 속 성별 고정관념 정량화와 완화
이 논문은 워드 임베딩이 학습 데이터에 내재된 성별 고정관념을 어떻게 반영하는지를 정량적으로 측정하고, 소수의 라벨링된 단어만을 이용해 이러한 편향을 최소화하는 사후 처리 알고리즘을 제안한다. 직업 단어들의 성별 축 투영 분석, 군중 작업을 통한 아날로지 평가, 그리고 반편향 변환 행렬을 구하는 반정규화 SDP 접근법을 통해 편향 감소와 기존 성능 유지가 동시에 가능함을 실험적으로 입증한다.
저자: Tolga Bolukbasi, Kai-Wei Chang, James Zou
본 논문은 현대 자연어 처리에서 광범위하게 사용되는 워드 임베딩이 사회적 편향, 특히 성별 고정관념을 어떻게 내재하고 있는지를 체계적으로 조사하고, 이를 정량화 및 완화하는 새로운 방법론을 제시한다. 연구는 크게 세 부분으로 구성된다.
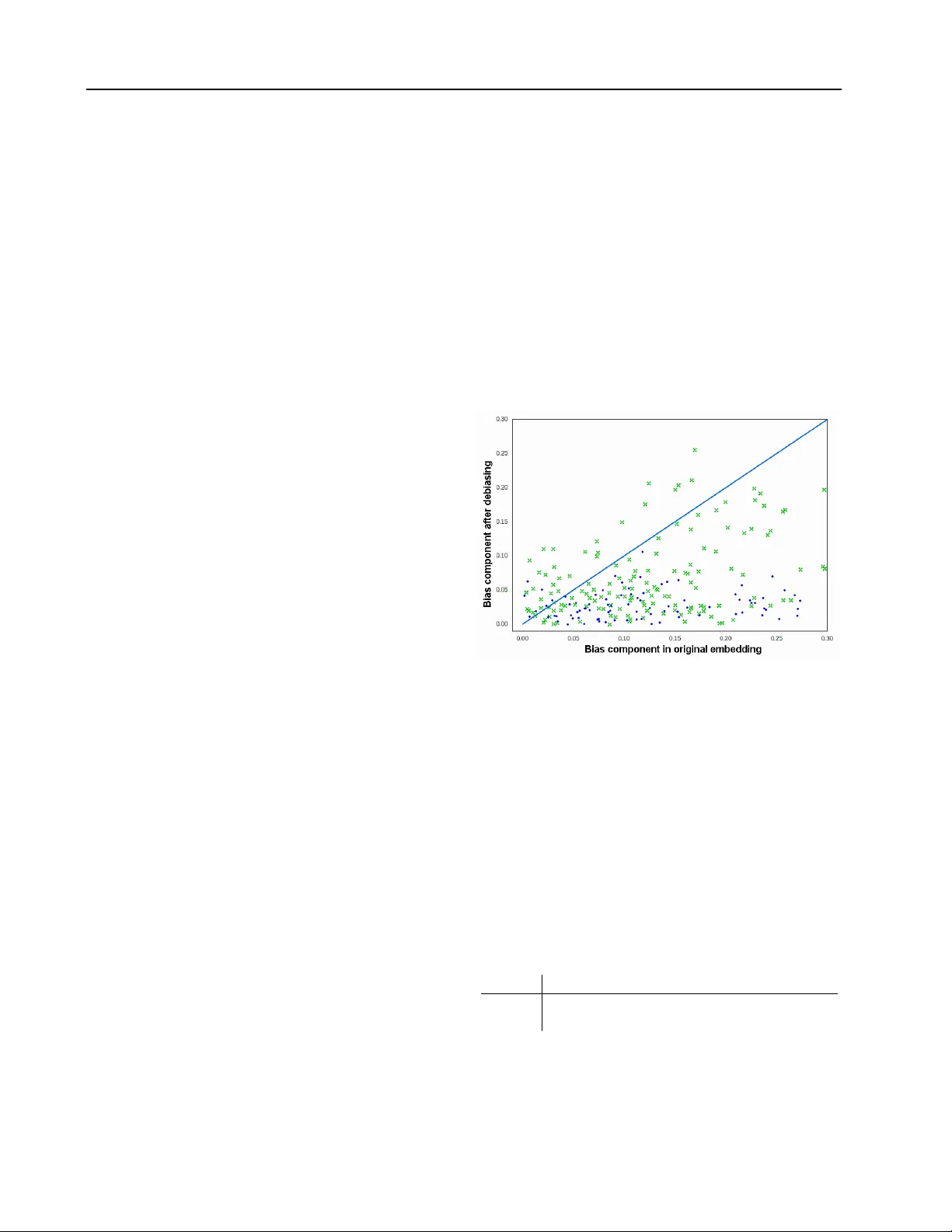
첫 번째 부분에서는 임베딩 내 성별 편향을 탐지하기 위한 두 가지 정량적 지표를 설계한다. 하나는 직업 단어들의 ‘성별 축(he‑she 방향)’ 투영값을 측정하는 방법이다. 215개의 직업 리스트(예: surgeon, nurse, engineer 등)를 선정하고, 각 단어 벡터 v에 대해 v·(v_he−v_she)/‖v_he−v_she‖를 계산한다. 이 값이 양수이면 남성 쪽, 음수이면 여성 쪽으로 치우친 것으로 해석한다. 실험 결과, Google News 기반 word2vec(w2vNEWS)와 웹 크롤링 텍스트 기반 GloVe 두 임베딩 모두에서 동일한 직업들이 비슷한 방향성을 보였으며, 이는 데이터에 존재하는 사회적 고정관념이 임베딩 공간에 그대로 반영된다는 강력한 증거가 된다.
두 번째 지표는 자동 생성된 아날로지 쌍을 활용한다. 임베딩 E에서 성별 방향 d=(v_he−v_she)/‖v_he−v_she‖를 정의하고, (w_a−w_b)·d/‖w_a−w_b‖²가 최대가 되도록 하는 단어쌍을 찾는다. 여기서 ‖w_a−w_b‖²≤δ(δ≈1)라는 제약을 두어 의미적으로 유사한 쌍만을 선택한다. 이렇게 추출한 상위 1,000개 아날로지를 Amazon Mechanical Turk에 제출하고, 두 가지 질문을 통해 (1) 해당 쌍이 의미 있는 아날로지인가, (2) 성별 고정관념을 포함하는가를 10인 평가한다. 결과는 전체 아날로지 중 21%가 고정관념을, 32%가 비논리적이라고 판단되었으며, 이는 편향이 직업 단어에 국한되지 않고 광범위한 어휘에 퍼져 있음을 보여준다.
세 번째 부분에서는 이러한 편향을 최소화하기 위한 사후 처리 알고리즘을 제안한다. 임베딩 자체를 재학습하기 어려운 현실을 고려해, 이미 학습된 임베딩에 선형 변환 행렬 T∈ℝ^{r×r}를 적용한다. 입력으로는 (1) 전체 임베딩 행렬 E, (2) 편향 방향 행렬 B(본 논문에서는 B=v_he−v_she), (3) 편향을 제거하고자 하는 seed 단어 집합 P(예: manager, nurse 등), (4) 거리 보존을 위한 배경 단어 집합 A를 사용한다. 목표는 P·T가 B·T와 직교하도록 하면서, A 내 모든 단어 쌍의 유클리드 거리가 변하지 않게 하는 것이다. 이를 Frobenius norm 기반의 두 목적 함수를 가중합한 반정규화 SDP 형태로 정의하고, A의 SVD(A=UΣVᵀ)를 수행해 차원을 축소한다. 최종 최적화 문제는 300×300 크기의 ΣVᵀ(X−I)VΣ을 최소화하는 형태가 되어, 대규모 행렬 연산의 메모리·시간 부담을 크게 낮춘다.
실험에서는 크라우드소싱을 통해 438개의 성별 편향 후보 단어를 수집하고, 350개를 학습용 P, 나머지를 테스트용으로 사용했다. 변환 전후 각 테스트 단어를 성별 축에 투영했을 때, 편향 단어들의 투영 분산이 0.02에서 0.001로 크게 감소했으며, 배경 단어는 변동이 거의 없었다(전후 0.005→0.0055). 이는 변환이 목표한 대로 편향을 억제하면서도 일반적인 의미 구조는 보존한다는 것을 의미한다. 또한, 변환 전후의 표준 벤치마크(RG, RW, WS353, MSR‑analogy) 점수를 비교했을 때, 성능 저하가 없으며 일부 지표는 미세하게 향상되었다.
논문의 주요 기여는 다음과 같다. (1) 워드 임베딩에 내재된 성별 고정관념을 정량화하는 두 가지 새로운 메트릭을 제시하였다. (2) 자동 생성된 아날로지를 인간 평가와 결합해 편향 정도를 직관적으로 측정하였다. (3) 소수의 라벨링된 단어만으로도 임베딩을 효과적으로 ‘디바이어스’할 수 있는 사후 처리 알고리즘을 설계하고, 기존 성능을 유지함을 실험적으로 입증하였다. 이 방법은 B에 성별 외의 다른 편향(인종, 연령 등)을 포함하도록 확장 가능하며, 실제 서비스에 적용하기 위한 실용적인 솔루션으로 활용될 수 있다. 다만, 편향 방향 B의 정의가 결과에 큰 영향을 미치므로, 복합적인 사회적 편향을 완전히 제거하기 위해서는 다축 정의와 추가적인 인간 피드백이 필요하다는 한계점도 존재한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기