Quantifying and Reducing Stereotypes in Word Embeddings
Machine learning algorithms are optimized to model statistical properties of the training data. If the input data reflects stereotypes and biases of the broader society, then the output of the learning algorithm also captures these stereotypes. In th…
Authors: Tolga Bolukbasi, Kai-Wei Chang, James Zou
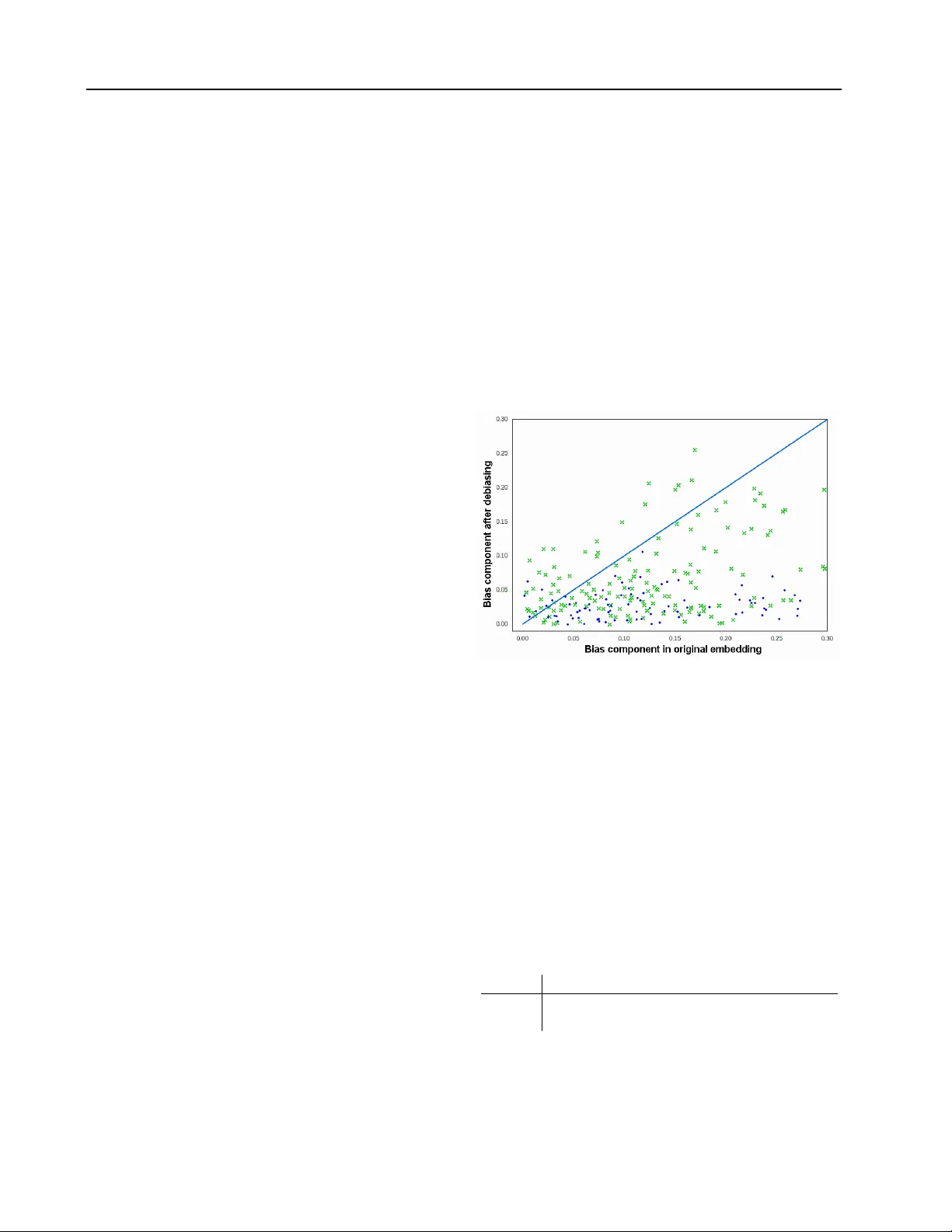
Quantifying and Reducing Ster eotypes in W ord Embeddings T olga Bolukbasi 1 T O L G A B @ B U . E D U Kai-W ei Chang 2 K W @ K W C H A N G . N E T James Zou 2 JA M E S Y Z O U @ G M A I L . C O M V enkatesh Saligrama 1 S RV @ B U . E D U Adam Kalai 2 A D A M . K A L A I @ M I C RO S O F T . C O M 1 Boston Univ ersity , 8 Saint Mary’ s Street, Boston, MA 2 Microsoft Research New England, 1 Memorial Dri ve, Cambridge, MA Abstract Machine learning algorithms are optimized to model statistical properties of the training data. If the input data reflects stereotypes and biases of the broader society , then the output of the learning algorithm also captures these stereo- types. In this paper , we initiate the study of gender stereotypes in word embedding , a pop- ular framework to represent text data. As their use becomes increasingly common, applications can inadvertently amplify unwanted stereotypes. W e sho w across multiple datasets that the em- beddings contain significant gender stereotypes, especially with regard to professions. W e created a nov el gender analogy task and combined it with crowdsourcing to systematically quantify the gender bias in a given embedding. W e dev eloped an efficient algorithm that reduces gender stereotype using just a handful of training examples while preserving the useful geometric properties of the embedding. W e e v aluated our algorithm on sev eral metrics. While we focus on male/female stereotypes, our framework may be applicable to other types of embedding biases. 1. Introduction W ord embeddings, trained only on word co-occurrence in text corpora, capture rich semantic information about words and their meanings ( Mikolov et al. , 2013b ). Each word (or common phrase) w ∈ W is encoded as a d -dimensional word vector v w ∈ R d . Using simple vector arithmetic, the embeddings are capable of answering analogy puzzles . For instance, man : king :: woman : 1 returns queen as the answer , and similarly Japan is returned 1 An analogy puzzle , a : b :: c : d , inv olves selecting the most appropriate d given a , b , and c . 2016 ICML W orkshop on #Data4Good: Machine Learning in Social Good Applications , Ne w Y ork, NY , USA. Copyright by the author(s). for P aris : F rance :: T okyo : J apan (computer-generated an- swers are underlined). A number of such embeddings hav e been made publicly av ailable including the popular word2vec ( Mikolov et al. , 2013a ; Mikolov et al. ) embed- ding trained on 3 million words into 300 dimensions, which we refer to here as the w2vNEWS embedding because it was trained on a corpus of text from Google News. These word embeddings hav e been used in a variety of downstream applications (e.g., document ranking ( Nalis- nick et al. , 2016 ), sentiment analysis ( ˙ Irsoy & Cardie , 2014 ), and question retriev al ( Lei et al. , 2016 )). While word-embeddings encode semantic information they also exhibit hidden biases inherent in the dataset they are trained on. For instance, word embeddings based on w2vNEWS can return biased solutions to analogy puzzles such as father : doctor :: mother : nurse and man : computer pr ogrammer :: woman : homemaker . Other publicly av ail- able embeddings produce similar results exhibiting gender stereotypes. Moreov er , the closest word to the query BLA CK MALE returns ASSA ULTED while the response to WHITE MALE is ENTITLED TO . This raises serious concerns about their widespread use. The prejudices and stereotypes in these embeddings reflect biases implicit in the data on which they were trained. The embedding of a word is typically optimized to predict co- occuring words in the corpus. Therefore, if mother and nurse frequently co-occur, then the vectors v mother and v nurse also tend to be more similar and encode the gender stereotypes. The use of embeddings in applications can amplify these biases. T o illustrate this point, consider W eb search where, for example, one recent project has shown that, when carefully combined with existing approaches, word vectors can significantly improve W eb page relev ance results ( Nalisnick et al. , 2016 ) (note that this work is a proof of concept – we do not know which, if any , mainstream search engines presently incorporate word embeddings). Consider a researcher seeking a summer intern to work on a machine learning project on deep learning who searches for , say , “link edin graduate student machine learning neural networks. ” Now , a word embedding’ s semantic knowledge 41 Quantifying and Reducing Stereotypes in W ord Embeddings can improv e relev ance in the sense that a LinkedIn web page containing terms such as “PhD student, ” “embed- dings, ” and “deep learning, ” which are related to but different from the query terms, may be ranked highly in the results. Howe v er , word embeddings also rank CS research related terms closer to male names than female names. The consequence would be, between two pages that differed in the names Mary and John b ut were otherwise identical, the search engine would rank John’ s higher than Mary . In this hypothetical example, the usage of word embedding makes it even harder for women to be recognized as computer scientists and would contribute to widening the existing gender gap in computer science. While we focus on gender bias, specifically male/female, our approach may be applied to other types of biases. W e propose two methods to systematically quantify the gender bias in a set of word embeddings. First, we quantify how words, such as those corresponding to professions, are distributed along the direction between embeddings of he and she . Second, we design an algorithm for gener- ating analogy pairs from an embedding given two seed words and we use crowdwork ers to quantify whether these embedding analogies reflect stereotypes. Some analogies reflect stereotypes such as he : janitor :: she : housekeeper and he : alcoholism :: she : eating disor ders . Finally , others may prov oke interesting discussions such as he : r ealist :: she : feminist and he : injur ed :: she : victim . Since biases are cultural, we enlist U.S.-based crowd- workers to identify analogies to judge whether analogies: (a) reflect ster eotypes (to understand biases), or (b) are nonsensical (to ensure accuracy). W e first establish that biases indeed exist in the embeddings. W e then show that, surprisingly , information to distinguish stereotypical asso- ciations like female:homemaker from definitional associa- tions like female:sister can often be removed. W e propose an approach that, gi ven an embedding and only a handful of words, can reduce the amount of bias present in that embedding without significantly reducing its performance on other benchmarks. Contributions. (1) W e initiate the study of stereotypes and biases in word embeddings. Our work follo ws a lar ge body of literature on bias in language, but word embeddings are of specific interest because the y are commonly used in ma- chine learning and they have simple geometric structures that can be quantified mathematically . (2) W e dev elop two metrics to quantify gender stereotypes in word embeddings based on words associated with professions together with automatically generated analogies which are then scored by the crowd. (3) W e dev elop a new algorithm that reduces gender stereotypes in the embedding using only a handful of training examples while preserving useful properties of the embedding. Figure 1. Comparison of gender bias of profession words across two embeddings: word2vec trained on Googlenews and GloV e trained web-crawl texts. The x and y axes show projections onto the he-she direction in the two embeddings. Each dot is one of 249 common profession words. W ords closest to he , closest to she , and in between the two are colored in red and shown in the plot. Prior work. The body of prior work on bias in language and prejudice in machine learning algorithms is too large to fully cov er here. W e note that gender stereotypes hav e been shown to dev elop in children as young as two years old ( T urner & Gervai , 1995 ). Statistical analyses of language hav e sho wn interesting contrasts between language used to describe men and women, e.g., in recommendation letters ( Schmader et al. , 2007 ). A number of online systems hav e been shown to exhibit various biases, such as racial discrimination in the ads presented to users ( Sweeney , 2013 ). Approaches to modify classification algorithms to define and achiev e various notions of fairness ha ve been described in a number of works, see, e.g., ( Barocas & Selbst , 2014 ; Dwork et al. , 2012 ) and a recent survey ( Zliobaite , 2015 ). 2. Implicit stereotypes in word embedding Stereotyped words . A simple approach to explore how gender stereotypes manifest in embeddings is to quantify which words are closer to he versus she in the embedding space (using other words to capture gender, such as man and woman , gi ves similar but noisier results due to their multiple meanings). W e used a list of 215 common profession names, remo ving names that are associated with one gender by definition (e.g. waitress, waiter). For each name, v , we computed its projection onto the gender axis: v · ( v he − v she ) / || v he − v she || 2 . Figure 1 shows the projection of professions on the w2vNEWS embedding ( x - axis) and on a different embedding trained by GloV e on a dataset of web-crawled texts ( y -axis). Se veral professions are closer to the he or she vector and this is consistent 42 Quantifying and Reducing Stereotypes in W ord Embeddings across the embeddings, suggesting that embeddings encode gender stereotypes. Stereotyped analogies . While professions gi ve easily- interpretable insights on embedding stereotypes, we dev el- oped a more general method to automatically detect and quantify gender bias in any word embedding. Embeddings hav e shown to perform well in analogy tasks. Motiv ated by this, we ask the embedding to generate analogous word pairs for he and she , and use crowd-sourcing to ev aluate the degree of stereotype of each pair . A desired analogy he : she :: w 1 : w 2 has the following properties 2 : 1) the direction of w 1 - w 2 has to align with he - she ; 2) w 1 and w 2 should be semantically similar, i.e. || w 1 − w 2 || 2 is not too large. Based on this, giv en a word embedding E , we proposed to score analogous pairs by the following formulation: S d ( w a , w b ) = ( w a − w b ) · d || w a − w b || 2 s.t. || w a − w b || 2 ≤ δ (1) where d = ( v he − v she ) / || v he − v she || 2 is the gender direction and δ is a threshold for similarity . 3 W e observe that setting δ = 1 often works well in practice; this corresponds to requiring that the two words forming the analogy are significantly closer together than two random embedding vectors. From the embedding, we generated the top analogous pairs with the largest S d scores. T o av oid redundancies, if multiple pairs share the same w a or w b , we kept only one pair . Then we employed Amazon Mechanical T urk to ev aluate the analogies. For each analogy , such as man : woman :: doctor : nurse , we ask the T urkers two yes/no questions to verify if this pairing makes sense as an analogy and whether it exhibits gender stereotype. Every word pair is judged by 10 T urkers, and we used the number of T urkers that rated this pair as stereotyped to quantify the degree of bias of this analogy . T able 1 shows the most and least stereotypical analogies generated by word2vec on Googlenews. Overall, 21% and 32% analogy judgments were stereotypical and nonsensical, respectively , by the T urkers. 3. Reducing stereotypes in word embedding Having demonstrated that word embeddings contain sub- stantial stereotypes in both professions and analogies, we dev eloped a method to reduce these stereotypes while preserving the desirable geometry of the embedding. W ord embeddings are often trained on a large corpus 2 For the ease of presentation, we abuse the notation to use w to represent a word or a word v ector depending on the context. 3 W e e xplored alternati ves including a variation of 3- CosMul ( Levy & Goldberg , 2014 ) for generating word pairs, and observe that the proposed approach works the best. (w2vNEWS is trained on Google news corpus with 100 billion words). As a result, it is impractical and even impossible (the corpus is not publicly accessible) to reduce the stereotypes during the training of the the word vectors. Therefore, we assume that we are gi ven a a set of word vectors and aim to remove stereotypes as a post-processing step. Our approach takes the follo wing as inputs: (1) a word embedding stored in a matrix E ∈ R n,r , where n is the number of words and r is the dimension of the latent space. (2) A matrix B ∈ R n b ,r where each column is a vector representing a direction of stereotype. In this paper , B = v he − v she , but in general, B can contain multiple stereotypes including gender , racism, etc. 4 (3) A matrix P ∈ R n p ,r whose columns correspond to set of seed words that we want to debias. An e xample of a seed word for gender is manager . (4) A matrix A ⊆ E whose columns represent a background set of words. W e want the algorithm to preserve their pairwise distances. 5 The goal is to generate a transformation matrix ˆ T ∈ N r,r , which has the following properties: • The transformed embeddings are stereotypical-free. That is every column vectors in P T should be perpendicular to column vectors in B T (i.e., P T T T B T ≈ 0 ). • The transformed embeddings preserve the distances between any two v ectors in the matrix A . Let X = T T T , we can capture these two objectives as the following semi-positi ve definite programming problem. min X 0 k AX A T − AA T k 2 F + λ k P X B T k 2 F (2) where k ˙ k F is the Frobenius norm, the first term ensures that the pairwise distances are preserved, and the second term induces the biases to be small on the seed words. The user-specified parameter λ balances the two terms. Directly solving this SDP optimization problem is chal- lenging. In practice, the dimension of matrix A is in the scale of 400,000 × 300. The dimensions of the matrices AX A T and AA T are 400 , 000 × 400 , 000 , causing computational and memory issues. W e conduct singular value decomposition on A , such that A = U Σ V T , where U and V are orthogonal matrices and Σ is a diagonal matrix. k AX A T − AA T k 2 F = k A ( X − I ) A T k 2 F = k U Σ V T ( X − I ) V Σ U T k 2 F = k Σ V T ( X − I ) V Σ k 2 F . (3) 4 Here we assume the stereotypical directions are giv en. In practice, this can be obtained by subjecting the vectors of the extreme words in the concept (e.g. he and she representing gender .) 5 T ypically , we can set A to contain the word vectors in E except the ones in B and P . 43 Quantifying and Reducing Stereotypes in W ord Embeddings Ranked as M-F stereotypical by 10/10 workers: sur geon:nur se doctors:midwives athletes:gymnasts paramedic:r e gister ed nurse Hummer:minivan Karate:Gymnastics woodworking:quilting alcoholism:eating disor ders athlete:gymnast neur ologist:therapist hock e y:figur e skating ar c hitect:interior designer chauf feur:nanny curator:libr arian pilots:flight attendant drug traf fic king:pr ostitution musician:dancer beers:cocktails Sopranos:Real House wives headmaster:guidance counselor workout:Pilates Home Depot:JC P enne y weightlifting:gymnastics Sports Illustrated:V anity F air carpentry:sewing accountant:parale gal addiction:eating disor der professor emeritus:associate pr ofessor Ranked as M-F stereotypical by 0/10 workers: (random sample of 12 out of 505) Jon:Heidi Ainge:Fulmer Allan:Lorna Geor ge Cloone y:P enelope Cruz Erick:Karla gentlemen:ladies Christopher:Jennifer veterans:servicemen sausages:b uns patriar c h:matriar c h Ler oy:Lucille Phillip:Belinda T able 1. Sample of the top 1,000 analogies generated for he : she :: w a : w b on w2vNEWS, ordered by the number of workers who judged them to reflect stereotypes. The analogies which were rated stereotypical by 10/10 workers are shown and a random sample of twelve analogies rated as stereotypical by 0/10 workers is shown. Overall, 21% of the 1000 analogies were rated as reflecting gender stereotypes. The last equality follows the fact that U is an orthogonal matrix ( k U X U T k 2 F = tr ( U X U T U X T U T ) = tr ( U X X T U T ) = tr ( X X T U T U ) = k X k 2 F .) Substituting Eq. ( 3 ) to Eq. ( 2 ) gi ves min X 0 k Σ V T ( X − I ) V Σ k 2 F + λ k P X B T k 2 F (4) Here Σ V T ( X − I ) V Σ is a 300 × 300 matrix and can be solved efficiently . The solution T is the debiasing transformation of the word embedding. Experimental validation. T o validate our debiasing al- gorithm, we asked Turk ers to suggest words that are likely to reflect gender stereotype (e.g. manager , nurse ). W e collected 438 such words, of which a random setup of 350 are used for training as the columns of the P matrix. The remaining are used for testing. Figure 2 illustrates the results of the algorithm. The blue circles are the 88 gender-stereotype words suggested by the T urkers which form our held-out test set. The green crosses are a random sample of background words that were not suggested to hav e stereotype. Most of the stereotype words lie close to the y = 0 line, consistent with them lies near the midpoint between he and she . In contrast the background points were substantially less affected by the debiasing transformation. W e use variances to quantify this result. For each test word (either gender-stereotypical or background) we project it onto the he - she direction. Then we compute the variance of the projections in the original embedding and after the debiasing transformation. For the gender-stereotype test words, the variance in the original embedding is 0.02 and the variance after the transformation is 0.001. For the background words, the variance before and after the transformation was 0.005 and 0.0055 respectively . This demonstrates that the transformation was able to reduce gender stereotype. Figure 2. The changes of word vectors on the gender direction. The x and y axes show the absolute v alues of the projections onto the he-she direction before and after debasing. The solid line is the diagonal. The blue ‘ • ’ are gender-stereotypical words in the test set, and the green ‘x’ are randomly selected other words that were not suggested to be gender related. Lastly to verify that the debiasing transformation T pre- serves the desirable geometric structure of the embedding, we tested the transformed embedding a sev eral standard benchmarks that measure whether related words have sim- ilar embeddings as well as how well the embedding per- forms in analogy tasks. T able 2 shows the results on the original and the transformed embeddings and the transfor- mation does not negati vely impact the performance. Model RG WS353 R W MSR-analogy Before 0.761 0.700 0.471 0.712 After 0.764 0.700 0.472 0.712 T able 2. The columns show the performance of the word embeddings on the standard evaluation metrics. RG ( Rubenstein & Goodenough , 1965 ), R W ( Luong et al. , 2013 ), WS353 ( Finkelstein et al. , 2001 ), MSR-analogy ( Mikolo v et al. , 2013b ) 44 Quantifying and Reducing Stereotypes in W ord Embeddings References Barocas, Solon and Selbst, Andre w D. Big data’ s disparate impact. A vailable at SSRN 2477899 , 2014. Dwork, Cynthia, Hardt, Moritz, Pitassi, T oniann, Reingold, Omer , and Zemel, Richard. Fairness through awareness. In Innovations in Theor etical Computer Science Confer ence , 2012. Finkelstein, Lev , Gabrilovich, Evgeniy , Matias, Y ossi, Rivlin, Ehud, Solan, Zach, W olfman, Gadi, and Ruppin, Eytan. Placing search in context: The concept revisited. In WWW . A CM, 2001. ˙ Irsoy , Ozan and Cardie, Claire. Deep recursive neural networks for compositionality in language. In NIPS . 2014. Lei, T ao, Joshi, Hrishikesh, Barzilay , Regina, Jaakkola, T ommi, Katerina T ymoshenko, Alessandro Moschitti, and Marquez, Liuis. Semi-supervised question retriev al with gated con volutions. In N AA CL . 2016. Levy , Omer and Goldber g, Y oav . Linguistic regularities in sparse and explicit word representations. In CoNLL , 2014. Luong, Thang, Socher, Richard, and Manning, Christo- pher D. Better word representations with recursive neural networks for morphology . In CoNLL , pp. 104– 113. Citeseer , 2013. Mikolov , T omas, Sutsk e ver , Ilya, Chen, Kai, Corrado, Gre- gory S., and Dean, Jeffrey . Distributed representations of words and phrases and their compositionality . In NIPS . Mikolov , T omas, Chen, Kai, Corrado, Greg, and Dean, Jeffre y . Efficient estimation of word representations in vector space. In ICLR , 2013a. Mikolov , T omas, Y ih, W en-tau, and Zweig, Geoffrey . Linguistic regularities in continuous space word repre- sentations. In HLT -NAA CL , pp. 746–751, 2013b. Nalisnick, Eric, Mitra, Bhaskar , Craswell, Nick, and Caruana, Rich. Improving document ranking with dual word embeddings. In www , April 2016. Rubenstein, Herbert and Goodenough, John B. Contextual correlates of synonymy . Communications of the A CM , 8 (10):627–633, 1965. Schmader , T oni, Whitehead, Jessica, and W ysocki, V icki H. A linguistic comparison of letters of recommendation for male and female chemistry and biochemistry job applicants. Sex Roles , 57(7-8):509– 514, 2007. Sweeney , Latanya. Discrimination in online ad delivery . Queue , 11(3):10, 2013. T urner, Patricia J and Gervai, Judit. A multidimensional study of gender typing in preschool children and their parents: Personality , attitudes, preferences, behavior , and cultural differences. Developmental Psycholo gy , 31 (5):759, 1995. Zliobaite, Indre. A survey on measuring indirect discrimination in machine learning. arXiv preprint arXiv:1511.00148 , 2015. 45
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment