에피소드형 POMDP를 위한 최초의 다항식 PAC 강화학습 알고리즘
본 논문은 부분관측 마코프 결정 과정(POMDP)에서 에피소드 길이에 대해 다항식 규모의 샘플 복잡도를 보장하는 최초의 PAC 강화학습 알고리즘을 제안한다. 방법은 행동별로 HMM을 학습하는 모멘트 방법(Method of Moments)을 이용해 모델 파라미터를 추정하고, 잠재 상태 라벨링을 정렬한 뒤 α‑벡터 기반 플래닝으로 근접 최적 정책을 얻는다. 이론적으로 에피소드 수가 문제 파라미터의 다항식으로 제한됨을 증명한다.
저자: Zhaohan Daniel Guo, Shayan Doroudi, Emma Brunskill
**1. 서론**
부분관측 환경에서 강화학습(RL)은 로봇, 교육, 의료 등 실세계 문제에 필수적이다. 그러나 관측이 제한적이기 때문에 기존의 PAC‑RL 이론이 제공하는 샘플 복잡도는 에피소드 길이 H에 대해 지수적으로 커진다. 저자들은 이러한 한계를 극복하고, 에피소드형 POMDP에 대해 다항식 규모의 PAC 보장을 제공하는 최초의 알고리즘을 제시한다. 핵심 아이디어는 최근 활발히 연구된 모멘트 방법(Method of Moments, MoM)을 이용해 숨겨진 마코프 모델(HMM)을 정확히 추정하고, 이를 기반으로 정책을 계획하는 것이다.
**2. 관련 연구**
PAC‑RL은 MDP에 대해 풍부한 문헌이 존재하지만, POMDP에 대해서는 샘플 복잡도가 H에 대해 지수적이라는 결과만 있다. 베이지안 접근법이나 EM 기반 학습은 실용적이지만, 유한 샘플에 대한 이론적 보장은 제공하지 못한다. 스펙트럴 방법과 PSR(예측 상태 표현)도 추정 정확도는 보장하지만, 제어 설정에 대한 유한 샘플 분석은 부재하다. 이러한 격차를 메우기 위해 저자들은 MoM이 제공하는 전역 최적성과 샘플 복잡도 보장을 POMDP‑RL에 적용한다.
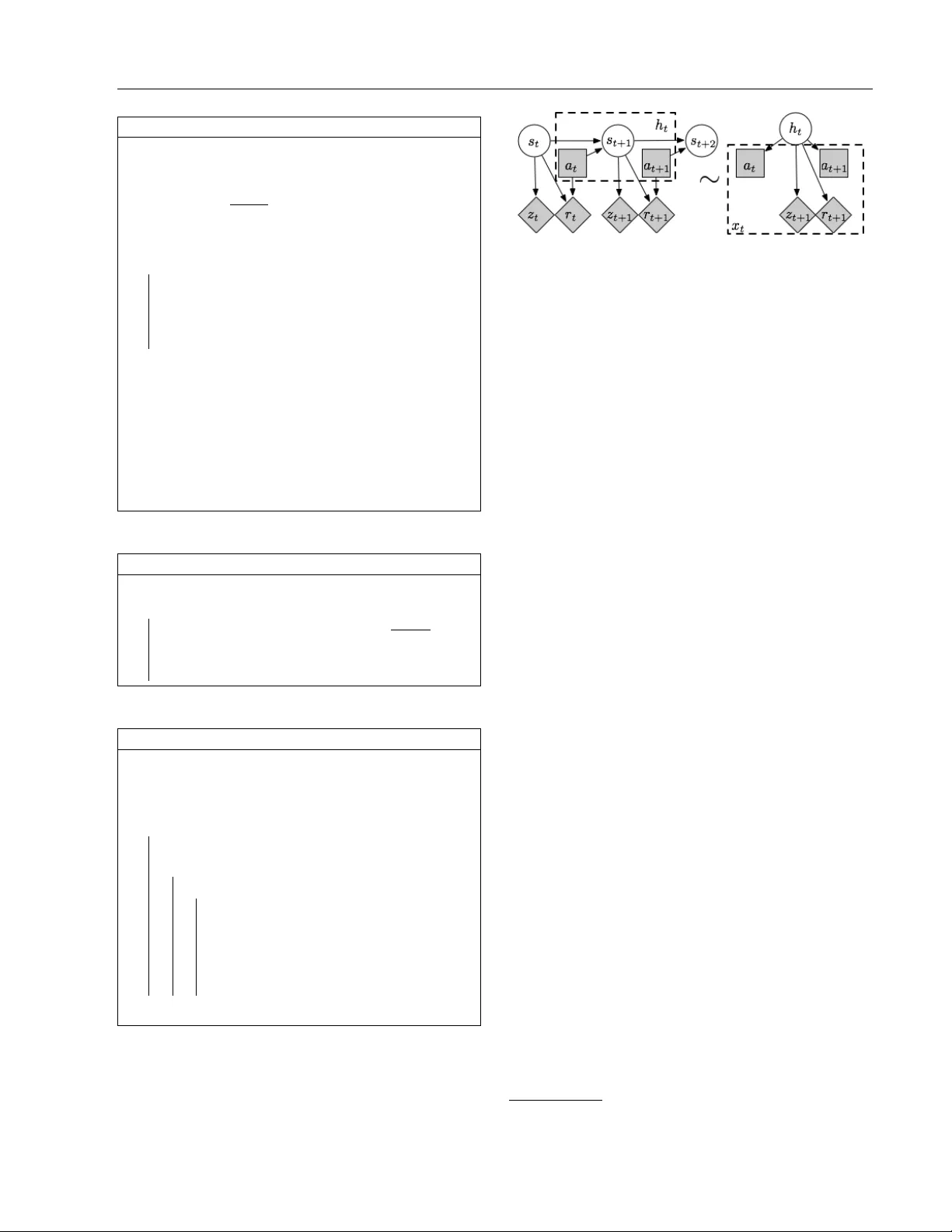
**3. 문제 설정 및 가정**
POMDP는 (S, A, Z, R, T, O, b, H) 로 정의된다. 주요 가정은 다음과 같다.
1) 에피소드형, 유한 horizon H.
2) 초기 믿음 b가 모든 상태에 양의 확률을 부여하고, 두 단계 이내에 모든 상태에 도달 가능(믹싱 가정).
3) 각 행동 a에 대해 전이 행렬 Tₐ가 풀‑랭크, 관측 행렬 Zₐ와 보상 행렬 Rₐ가 풀‑컬럼‑랭크.
이 가정들은 MoM이 파라미터를 유일하게 복구하고, 라벨 정렬을 가능하게 만든다. 특히 정적 상태를 갖는 정보 수집형 POMDP(예: 선호도 추정, 대화 관리, 의료 진단)에서 자연스럽게 만족된다.
**4. 알고리즘 개요**
알고리즘은 크게 두 단계로 구성된다.
*탐색 단계(Phase 1)*: 정책 π_explore를 사용해 각 에피소드 초반 4스텝을 무작위 행동으로 채우고, (aₜ, rₜ, zₜ, aₜ₊₁) 형태의 4‑tuple을 수집한다. 이를 통해 행동별 HMM에 대한 관측 시퀀스 X를 구축한다.
*모델 추정 및 플래닝 단계(Phase 2)*:
- **MoM 추정**: 수집된 X를 입력으로 확장된 MoM 절차를 적용해 각 행동에 대한 전이·관측·보상 파라미터(β, γ 등)를 추정한다.
- **라벨링(Algorithm 2)**: 추정된 관측 행렬 b_O의 열을 검사해 행‑열 매칭을 수행, 모든 행동에 걸쳐 동일한 잠재 상태 라벨을 부여한다. 이는 “latent state alignment” 문제를 해결한다.
- **정책 계산(Algorithm 3)**: 라벨링된 파라미터를 이용해 α‑벡터 집합 Γₐ,ₐ′ₜ 를 재귀적으로 구성하고, 최종 α‑벡터 β_H 를 통해 현재 믿음 b와 내적을 최대화하는 행동 쌍 (a₀, a₁)을 선택한다. 이렇게 얻은 정책 π̂은 에피소드 전체에 걸쳐 실행된다.
**5. 이론적 결과**
저자들은 추정 오차가 가치 함수 오차에 미치는 영향을 정량화하고, 다음과 같은 PAC 보장을 증명한다.
- ε‑근접 최적 정책을 얻기 위해 필요한 에피소드 수 N은 O(poly(|S|,|A|,|Z|,|R|,1/ε,1/δ))이다.
- 이때 “poly”는 전이·관측·보상 행렬의 풀‑랭크와 믹싱 가정에 의해 정의된 상수들을 포함한다.
- 따라서 에피소드 길이 H에 대한 지수적 의존성을 완전히 제거하고, MDP‑PAC 결과와 동등한 샘플 효율성을 달성한다.
**6. 논의 및 한계**
알고리즘은 정보 수집형 POMDP에 적합하며, 관측·보상이 상태 수만큼 풍부해야 한다는 제약이 있다. 또한 라벨링 단계는 행렬 연산과 임계값 탐색을 필요로 하므로 실제 대규모 문제에서는 계산 비용이 증가할 수 있다. 저자들은 이러한 제한을 완화하기 위한 근사 라벨링, 차원 축소, 그리고 실험적 검증을 향후 연구 과제로 제시한다.
**7. 결론**
본 논문은 MoM 기반 파라미터 추정과 라벨 정렬을 결합해, 에피소드형 POMDP에 대해 다항식 규모의 PAC 샘플 복잡도를 최초로 달성한 알고리즘을 제시한다. 이론적 분석은 기존의 지수적 한계를 극복했으며, 정보 수집형 실세계 응용에 직접 적용 가능성을 보여준다. 향후 연구는 가정 완화와 실험적 평가를 통해 알고리즘의 실용성을 확대하는 방향으로 진행될 전망이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기