A PAC RL Algorithm for Episodic POMDPs
Many interesting real world domains involve reinforcement learning (RL) in partially observable environments. Efficient learning in such domains is important, but existing sample complexity bounds for partially observable RL are at least exponential …
Authors: Zhaohan Daniel Guo, Shayan Doroudi, Emma Brunskill
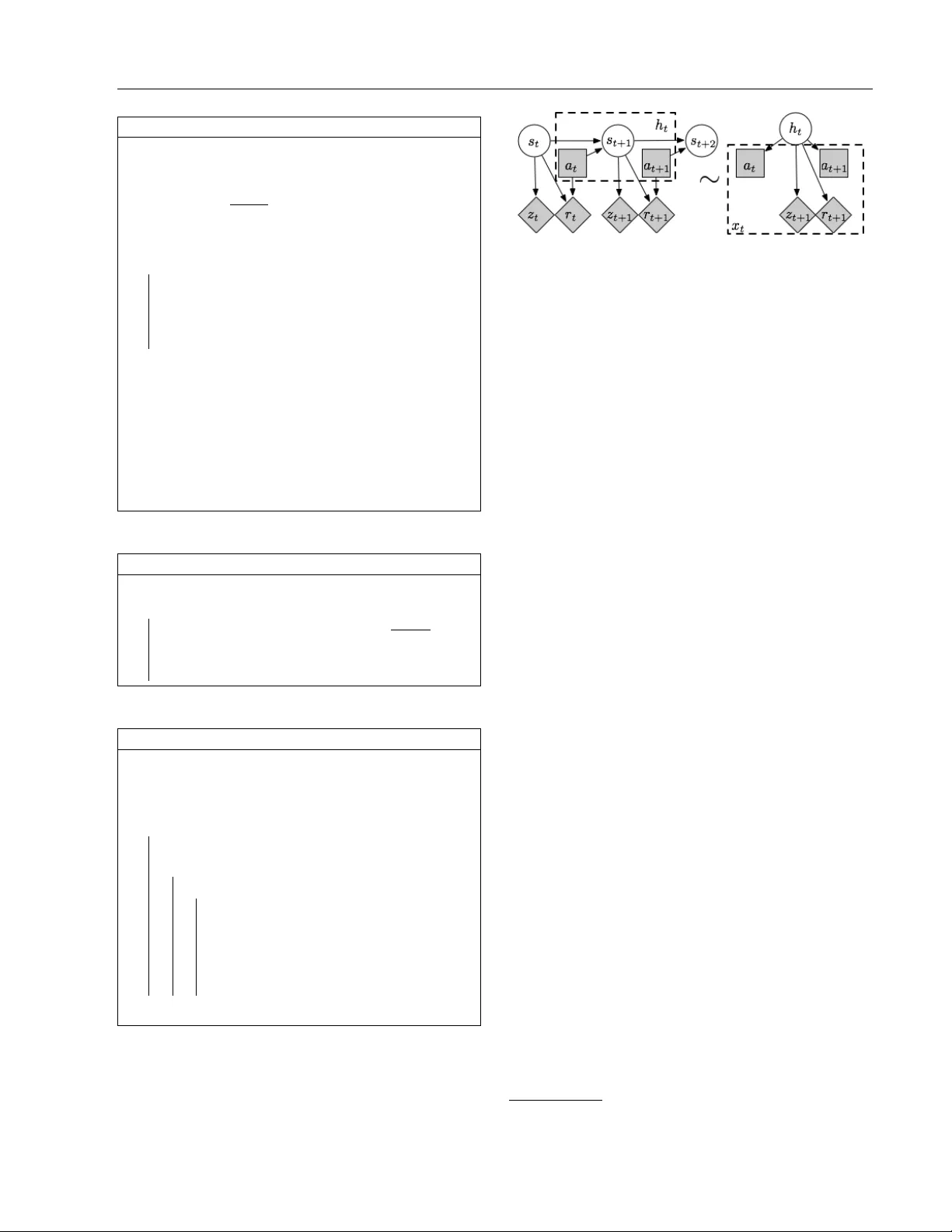
A P A C RL Algorithm for Episo dic POMDPs Zhaohan Daniel Guo Sha yan Doroudi Emma Brunskill Carnegie Mellon Univ ersity 5000 F orb es Av e Pittsburgh P A 15213, USA Carnegie Mellon Univ ersity 5000 F orb es Av e Pittsburgh P A 15213, USA Carnegie Mellon Univ ersity 5000 F orb es Av e Pittsburgh P A 15213, USA Abstract Man y in teresting real w orld domains in v olve reinforcemen t learning (RL) in partially ob- serv able en vironments. Efficien t learning in suc h domains is imp ortan t, but existing sample complexit y bounds for partially ob- serv able RL are at least exp onen tial in the episo de length. W e give, to our knowledge, the first partially observ able RL algorithm with a p olynomial b ound on the num ber of episo des on whic h the algorithm may not ac hieve near-optimal p erformance. Our al- gorithm is suitable for an important class of episo dic POMDPs. Our approach builds on recen t adv ances in metho d of momen ts for laten t v ariable mo del estimation. 1 INTR ODUCTION A key challenge in artificial intelligence is ho w to ef- fectiv ely learn to make a sequence of go o d decisions in sto c hastic, unknown en vironmen ts. Reinforcemen t learning (RL) is a subfield sp ecifically fo cused on how agen ts can learn to mak e go o d decisions giv en feedbac k in the form of a reward signal. In many important ap- plications such as rob otics, education, and healthcare, the agen t cannot directly observ e the state of the en vi- ronmen t responsible for generating the rew ard signal, and instead only receives incomplete or noisy observ a- tions. One imp ortan t measure of an RL algorithm is its sam- ple efficiency: ho w m uch data/experience is needed to compute a go o d p olicy and act w ell. One w ay to measure sample complexit y is given by the Probably Appro ximately Correct framework; an RL algorithm App earing in Pro ceedings of the 19 th In ternational Con- ference on Artificial Intelligence and Statistics (AIST A TS) 2016, Cadiz, Spain. JMLR: W&CP volume 51. Copyrigh t 2016 by the authors. is said to b e P AC if with high probability , it selects a near-optimal action on all but a num b er of steps (the sample complexity) which is a p olynomial func- tion of the problem parameters. There has b een sub- stan tial progress on P AC RL for the fully observ able setting (Brafman and T ennenholtz, 2003; Strehl and Littman, 2005; Kak ade, 2003; Strehl et al., 2012; Lat- timore and Hutter, 2012), but to our knowledge there exists no published work on P A C RL algorithms for partially observ able settings. This lack of w ork on P AC partially observ able RL is p erhaps b ecause of the additional c hallenge in tro duced b y the partial observ abilit y of the en vironment. In fully observ able settings, the world is often assumed to b eha ve as a Marko v decision pro cess (MDP). An elegan t approac h for pro ving that a RL algorithm for MDPs is P AC is to compute finite sample error bounds on the MDP parameters. How ever, b ecause the states of a partially observ able MDP (POMDP) are hidden, the naiv e approach of directly treating the POMDP as a history-based MDP yields a state space that gro ws exp onen tially with the horizon, rather than p olyno- mial in all POMDP parameters (Even-Dar et al., 2005). On the other hand, there has b een substantial recen t in terest and progress on method of momen ts and spec- tral approaches for modeling partially observ able sys- tems (Anandkumar et al., 2012, 2014; Hsu et al., 2008; Littman et al., 2001; Bo ots et al., 2011). The ma jorit y of this work has focused on inference and prediction, with little w ork tackling the con trol setting. Metho d of momen ts approaches to laten t v ariable estimation are of particular interest b ecause for a num ber of models they obtain global optima and provide finite sample guaran tees on the accuracy of the learned mo del pa- rameters. Inspired b y the this w ork, we prop ose a POMDP RL algorithm that is, to our kno wledge, the first P AC POMDP RL algorithm for episo dic domains (with no restriction on the p olicy class). Our algorithm is appli- cable to a restricted but imp ortan t class of POMDP A P AC RL Algorithm for Episo dic POMDPs settings, which include but are not limited to infor- mation gathering POMDP RL domains suc h as pref- erence elicitation (Boutilier, 2002), dialogue manage- men t slot-filling domains (Ko et al., 2010), and medical diagnosis b efore decision making (Amato and Brun- skill, 2012). Our w ork builds on metho d of momen ts inference techniques, but requires sev eral non-trivial extensions to tac kle the control setting. In particular, there is a subtle issue of latent state alignmen t: if the mo dels for eac h action are learned as independent hid- den Marko v mo dels (HMMs), then it is unclear ho w to solve the corresp ondence issue across latent states, whic h is essen tial for p erforming planning and select- ing actions. Our primary contribution is to provide a theoretical analysis of our prop osed algorithm, and pro ve that it is p ossible to obtain near-optimal p erfor- mance on all but a num b er of episo des that scales as a p olynomial function of the POMDP parameters. Sim- ilar to most fully observ able P AC RL algorithms, di- rectly instan tiating our bounds would yield an imprac- tical num ber of samples for a real application. Never- theless, we believe understanding the sample complex- it y may help to guide the amoun t of data required for a task, and also similar to P AC MDP RL work, ma y motiv ate new practical algorithms that build on these ideas. 2 BA CK GROUND AND RELA TED W ORK The inspiration for pursuing P A C b ounds for POMDPs came ab out from the success of P AC b ounds for MDPs (Brafman and T ennenholtz, 2003; Strehl and Littman, 2005; Kak ade, 2003; Strehl et al., 2012; Lattimore and Hutter, 2012). While algorithms ha ve b een dev elop ed for POMDPs with finite sam- ple b ounds (P eshkin and Mukherjee, 2001; Even-Dar et al., 2005), unfortunately these b ounds are not P AC as they ha ve an exp onential dep endence on the horizon length. Alternativ ely , Ba yesian methods (Ross et al., 2011; Doshi-V elez, 2012) are v ery p opular for solving POMDPs. F or MDPs, there exist Bay esian meth- o ds that ha ve P AC b ounds (Kolter and Ng, 2009; As- m uth et al., 2009); how ev er there hav e b een no P AC b ounds for Bay esian metho ds for POMDPs. That said, Ba yesian metho ds are optimal in the Bay esian sense of making the b est decision giv en the p osterior o ver all p ossible future observ ations, which do es not translate to a frequen tist finite sample b ound. W e build on metho d of momen ts (MoM) work for esti- mating HMMs (Anandkumar et al., 2012) in order to pro vide a finite sample bound for POMDPs. MoM is able to obtain a global optim um, and has finite sample b ounds on the accuracy of their estimates, unlike the p opular Exp ectation-Maximization (EM) that is only guaran teed to find a lo cal optima, and offers no finite sample guaran tees. MLE approaches for estimating HMMs (Ab e and W armuth, 1992) also unfortunately do not pro vide accuracy guaran tees on the estimated HMM parameters. As POMDP planning methods t yp- ically require us to hav e estimates of the underlying POMDP parameters, it w ould b e difficult to use such MLE metho ds for computing a POMDP p olicy and pro viding a finite sample guarantee 1 . Aside from the MoM metho d in Anandkumar et al. (2012), another p opular spectral metho d in volv es us- ing Predictive State Represen tations (PSRs) (Littman et al., 2001; Bo ots et al., 2011), to directly tac kle the con trol setting; ho wev er it only has asymptotic conv er- gence guarantees and no finite sample analysis. There is also another metho d of moments approac h to trans- fer across a set of bandits tasks, but the laten t v ariable estimation problem is substantially simplified b ecause the state of the system is unchanged by the selected actions (Azar et al., 2013). F ortunately , due to the p olynomial finite sample b ounds from MoM, we can ac hieve a P AC (p olyno- mial) sample complexit y b ound for POMDPs. 3 PR OBLEM SETTING W e consider a partially observ able Marko v decision pro cess (POMDP) whic h is describ ed as the tuple ( S, A, R, T , Z, b, H ) where we ha ve a set of discrete states S , discrete actions A , discrete observ ations Z , discrete rewards R , initial b elief b (more details be- lo w), and episo de length H . The transition mo del is represen ted by a set of | A | matrices T a ( i, j ) : | S | × | S | where the ( i, j )-th entry is the probability of transi- tioning from s i to s j under action a . With a slight abuse of notation, w e use Z to denote b oth the finite set of observ ations and the observ ation mo del captured b y the set of | A | observ ation matrices, Z a where the ( i, j )-th en try represen ts the probability of observing z i giv en the agent to ok action a and transitioned to state s j . W e similarly do a sligh t abuse of notation 1 Ab e and W armuth (1992)’s MLE approach guaran- tees that the estimated probability ov er H -length obser- v ation sequences has a bounded KL-divergence from the true probabilit y of the sequence under the true parameters, whic h is expressed as a function of the n umber of underly- ing data samples used to estimate the HMM parameters. W e think it ma y b e possible to use such estimates in the con trol setting when modeling hidden state control systems as PSRs, and emplo ying a forw ard search approac h to plan- ning; how ever, there remain a n umber of subtle issues to address to ensure suc h an approach is viable and we leav e this as an interesting direction for future work. Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill and let R denote b oth the finite set of rewards, and the rew ard matrices R a where the ( i, j )-th en try in a matrix denotes the probability of obtaining reward r i when taking action a in state s j . Note that in our setting we also treat the reward as an additional ob- serv ation 2 . The ob jective in POMDP planning is to compute a p olicy π that ac hieves a large exp ected sum of future rew ards, where π is a mapping from histories of prior sequences of actions, observ ations, and rewards, to ac- tions. In many cases we capture prior histories using a sufficient statistic called the b elief b where b ( s ) rep- resen ts the probability of b eing in a particular state s giv en the prior history of actions, observ ations and re- w ards. One p opular metho d for POMDP planning in- v olves represen ting the v alue function by a finite set of α -vectors, where α ( s ) represents the expected sum of future rewards of follo wing the p olicy asso ciated with the α -v ector from initial state s . POMDP planning then pro ceeds by taking the first action associated with the policy of the α -vector which yields the maxim um exp ected v alue for the curren t belief state, whic h can b e computed for a particular α -vector using the dot pro duct h b, α i . In the reinforcement learning setting, the transition, observ ation, and/or reward mo del parameters are ini- tially unknown. The goal is to learn a policy that ac hieves large sum of rew ards in the en vironment with- out adv ance knowledge of how the world w orks. W e make the following assumptions ab out the domain and problem setting: 1. W e consider episo dic, finite horizon partially ob- serv able RL (PORL) settings 2. It is p ossible to achiev e a non-ze ro probabilit y of b eing in an y state in tw o steps from the initial b elief. 3. F or each action a , the transition matrix T a is full rank, and the observ ation matrix Z a and rew ard matrix R a are full column rank. The first assumption on the setting is satisfied b y many real w orld situations inv olving an agen t repeatedly do- ing a task: for example, an agent may sequentially in- teract with man y different customers each for a finite 2 In planning problems the reward is typically a real- v alued scalar, but in PORL we m ust learn the reward mo del. This requires assuming some mapping b et ween states and rewards. F or simplicity w e assume multinomial distribution o ver a discrete set of rew ards. Note that w e can alwa ys discretized a real-v alued reward in to a finite set of v alues with b ounded error on the resulting v alue func- tion estimates, and our c hoice makes very little restrictions on the underlying setting. amoun t of time. The key restrictions on the setting are captured in assumptions 2 and 3. Assumption 2 is similar to a mixing assumption and is necessary in order for MoM to estimate dynamics for all states. Assumption 3 is necessary for MoM to uniquely deter- mine the transition, observ ation, and reward dynam- ics. The second assumption may sound quite strong, as in some POMDP settings states are only reachable b y a complex sequence of carefully chosen actions, suc h as in rob otic navigation or video games. How ev er, as- sumption 2 is commonly satisfied in man y important POMDP settings that primarily in volv e information gathering. F or example, in preference elicitation or user mo deling, POMDPs are commonly used to iden- tify the, t ypically static, hidden inten t or preference or state of the user, b efore taking some action based on the resulting information (Boutilier, 2002). Exam- ples of this include dialog systems (Ko et al., 2010), medical diagnosis and decision supp ort (Amato and Brunskill, 2012), and even human-robot collab oration preference modeling (Nik olaidis et al., 2015). In suc h settings, the b elief commonly starts out non-zero ov er all possible user states, and slowly gets narrow ed do wn o ver time. The third assumption is also significant, but is still satisfied by an important class of prob- lems that ov erlap with the settings captured by as- sumption 2. Information gathering POMDPs where the state is hidden but static automatically satisfy the full rank assumption on the transition mo del, since it is an identit y matrix. Assumption 3 on the observ a- tion and reward matrices imply that the cardinality of the set of observ ations (and rew ards) is at least as large as the size of the state space. A similar assump- tion has b een made in man y laten t v ariable estimation settings (e.g. (Anandkumar et al., 2012, 2014; Song et al., 2010)) including in the control setting (Bo ots et al., 2011). Indeed, when the observ ations consist of videos, images or audio signals, this assumption is t ypically satisfied (Bo ots et al., 2011), and such sig- nals are very common in dialog systems and the user in tent and modeling situations cov ered by assumption 2. Satisfying that the reward matrix has full rank is t ypically trivial as the rew ard signal is often obtained b y discretizing a real-v alued rew ard. Therefore, while w e readily ac knowledge that our setting does not co v er all generic POMDP reinforcement learning settings, w e b eliev e it do es cov er an imp ortant class of prob- lems that are relev an t to real applications. 4 ALGORITHM Our goal is to create an algorithm that can achiev e near optimal p erformance from the initial b elief on eac h episo de. Prior w ork has shown that the error in the POMDP v alue function is b ounded when us- A P AC RL Algorithm for Episo dic POMDPs Algorithm 1: EEPORL input : S, A, Z, R, H , N , c, π rest 1 Let π explor e b e the p olicy where a 1 , a 2 are uniformly random, and p ( a t +2 | a t ) = 1 1+ c | A | ( I + c 1 | A |×| A | ) ; 2 X ← ∅ ; // Phase 1: 3 for episo de i ← 1 to N do 4 F ollo w π explor e for 4 steps ; 5 Let x t = ( a t , r t , z t , a t +1 ) ; 6 X ← X ∪ { ( x 1 , x 2 , x 3 ) } ; 7 Execute π rest for the rest of the steps ; // Phase 2: 8 Get b T , b O , b w for the induced H M M from X through our extended MoM metho d ; 9 Using the lab eling from Algorithm 2 with b O , compute estimated POMDP parameters.; 10 Call Algorithm 3 with estimated POMDP parameters to estimate a near optimal p olicy b π ; 11 Execute b π for the rest of the episo des ; Algorithm 2: Lab elActions input : b O 1 foreach c olumn i of b O do 2 Find a ro w j suc h that b O ( i, j ) ≥ 2 3 | R || Z | ; 3 Let the observ ation asso ciated with row j b e ( a, r 0 , z 0 , a 0 ), lab el column i with ( a, a 0 ) ; Algorithm 3: FindPolicy input : b b ( s ( a 0 ,a 1 ) ), b p ( z | a, s ( a,a 0 ) ), b p ( r | s ( a,a 0 ) , a 0 ), b p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) 1 ∀ a − , a ∈ A, Γ a − ,a 1 = { b β a 1 ( s ( a − ,a ) ) } ; 2 for t ← 2 to H do 3 ∀ a, a 0 ∈ A, Γ a,a 0 t = ∅ ; 4 for a, a 0 ∈ A do 5 for f t ( r , z ) ∈ ( | R | × | Z | → Γ a,a 0 t − 1 ) do // all mappings from an observation pair to a previous β -vector 6 ∀ a − ∈ A, Γ a − ,a t = Γ a − ,a t ∪ { β a,f t t ( s ( a − ,a ) ) } ; 7 Return arg max a 0 ,a 1 ,β H ( s ( a 0 ,a 1 ) )) ∈ Γ a 0 ,a 1 H ( b b · β H ) ; ing mo del parameter estimates that themselves ha ve b ounded error (Ross et al., 2009; F ard et al., 2008); ho wev er, this w ork tak es a sensitivity analysis persp ec- tiv e, and do es not address how such mo del estimation Figure 1: POMDP (left) analogous to induced HMM (righ t). Gra y no des show fully observed v ariables, whereas white no des show latent states. errors themselv es could b e computed or b ounded. 3 In contrast, man y P AC RL algorithms for MDPs ha ve shown that exploration is critical in order to get enough data to estimate the mo del parameters. How- ev er in MDPs, algorithms can directly observ e how man y times every action has b een tried in every state, and can use this information to steer exploration to- w ards less explored areas. In partially observ able set- tings it is more c hallenging, as the state itself is hidden, and so it is not possible to directly observ e the num- b er of times an action has b een tried in a laten t state. F ortunately , recent adv ances in metho d of momen ts (MoM) estimation pro cedures for latent v ariable es- timation (see e.g. (Anandkumar et al., 2012, 2014)) ha ve demonstrated that in certain uncon trolled set- tings, including many types of hidden Marko v mo dels (HMMs), it is still p ossible to achiev e accuracy esti- mates of the underlying latent v ariable mo del param- eters as a function of the amount of data samples used to p erform the estimation. F or some intuition ab out this, consider starting in a b elief state b which has non-zero probabilit y ov er all p ossible states. If one can repeatedly tak e the same action a from same b e- lief b , giv en a sufficient num b er of samples, we will ha ve actually taken action a in each state many times (ev en if we don’t know the sp ecific instances on which action a w as taken in a state s ). The control setting is more subtle than the uncon- trolled setting which has b een the fo cus of the ma- jorit y of recent MoM sp ectral learning researc h, be- cause we wish to estimate not just the transition and observ ation models of a HMM, but to estimate the POMDP mo del parameters. Our ultimate in terest is in b eing able to select go od actions. A naive approach is to indep enden tly learn the transition, observ ation, and rew ard parameters for eac h separate action, b y re- stricting the POMDP to only execute a single action, thereb y turning the POMDP into an HMM. How ever, this simple aproac h fails b ecause the returned parame- ters can corresp ond to a different labeling of the hidden 3 F ard et al. (2008) assume that labels of the hidden states are provided, whic h remo ves the need for laten t v ari- able esimtation. Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill states. F or example, the first column of the transition matrix for action a 1 ma y actually corresp ond to the state s 2 , while the first column of the transition ma- trix for action a 2 ma y truly corresp ond to s 5 . W e require that the lab eling must b e consistent for all ac- tions since w e wish to compute what happ ens when differen t actions are executed consecutively . An un- satisfactory wa y to matc h up the lab els for different actions is by requiring that the initial b elief state hav e probabilities that are unique and well separated p er state. Then we can use the estimated initial b elief from each action to match up the lab els. How ev er, this is a very strong assumption on the starting b elief state whic h is unlikely to b e realized. T o address this challenge of mismatched lab els, we transform our POMDP in to an induced HMM (see Figure 1) b y fixing the p olicy to π explor e (for a few steps, during a certain n umber of episo des), and create an alternate hidden state represen tation that directly solv es the problem of alignmen t of hidden states across actions. Sp ecifically , we mak e the hidden state at time t of the induced HMM, denoted b y h t , equal to the tu- ple of the action at time step t , the next state, and the subsequen t action, h t = ( a t , s t +1 , a t +1 ). W e denote the observ ations of the induced HMM by x , and the observ ation asso ciated with a hidden state h t is the tuple x t = ( a t , r t , z t , a t +1 ). Figure 1 sho ws how the graphical model of our original POMDP is related to the graphical mo del of the induced HMM. In making this transformation, our resulting HMM still satisfies the Marko v assumption: the next state is only a func- tion of the prior state, and the observ ation is only a function of the current state. But, this transformation also has the desired prop ert y that it is now possible to directly align the identit y of states across selected ac- tions. This is because HMM parameters no w depend on both state and action, so there is a built-in corre- lation b et ween differen t actions. W e will discuss this more in the theoretical analysis. W e are no w ready to describ e our algorithm for episo dic finite horizon reinforcement learning in POMDPs, EEPORL (Explore then Exploit Partially Observ able RL, which is sho wn in Algorithm 1). Our algorithm is mo del-based and pro ceeds in tw o phases. In the first phase, it performs exploration to collect samples of trying different actions in different (latent) states. After the first phase completes, we extend a MoM approac h (Anandkumar et al., 2012) to compute estimates of the induced HMM parameters. W e use these estimates to obtain a near-optimal p olicy . 4.1 Phase 1 The first phase consists of the first N episo des. Let π explor e b e a fixed op en-loop p olicy for the first four actions of an episo de. In π explor e actions a 1 , a 2 are selected uniformly at random, and p ( a t +2 | a t ) = 1 1+ c | A | ( I + c 1 | A |×| A | ) where c can b e an y p ositiv e real n umber. F or our pro of, we pic k c = O (1 / | A | ). Note that π explor e only depends on previous actions and not on any observ ations. The definition of p ( a t +2 | a t ) for what will w ork for the pro of only requires it to b e full-rank and having some minimum probabilit y o ver all actions. W e c hose a p erturbed identit y matrix for simplicit y . Since π explor e is a fixed policy , the POMDP pro cess reduces to a HMM for these first four steps. During these steps we store the observed exp erience as ( x 1 , x 2 , x 3 ), where x t = ( a t , r t , z t , a t +1 ) is an obser- v ation of our previously defined induced HMM. The algorithm then follows p olicy π rest for the remaining steps of the episo de. All of these episo des will b e con- sidered as p oten tially non-optimal, and so the choice of π rest do es not impact the theoretical analysis. Ho w- ev er, empirically π rest could b e constructed to encour- age near optimal behavior giv en the observ ed data col- lected up to the curren t episo de. 4.2 P arameter Estimation After Phase 1 completes, w e hav e N samples of the tuple ( x 1 , x 2 , x 3 ). W e then apply our extension to the MoM algorithm for HMM parameter estimation b y Anandkumar et al. (2012). Our e xtension com- putes estimates and b ounds on the transition mo del b T which is not computed in the original metho d. T o summarize, this pro cedure yields an estimated transi- tion matrix b T , observ ation matrix b O , and b elief v ector b w for the induced HMM. The b elief b w is ov er the sec- ond hidden state, h 2 . As mentioned b efore as one ma jor c hallenge, lab el- ing of the states h of the induced HMM is arbi- trary; ho wev er it is consisten t b et ween b T , b O , b w since this is a single HMM inference problem. Recall that a hidden state in our induced HMM is defined as h t = ( a t , s t +1 , a t +1 ). Since the actions are fully ob- serv able, it is p ossible to lab el each state h = ( a, s 0 , a 0 ) (i.e. the columns of b O , the rows and columns of b T , and the rows of b w ) with tw o actions ( a, a 0 ) that are asso ci- ated with that state. This is p ossible b ecause the true observ ation matrix en tries for the actions of a hidden state must b e non-zero, and the true v alue of all other en tries (for other actions) m ust be zero; therefore, as long as w e hav e sufficien tly accurate estimates of the observ ation matrix, we can use the observ ation matrix parameters to augmen t the states h with their asso ci- ated action pair. This procedure is p erformed b y Algo- rithm 2. This lab eling provides a connection betw een the HMM state h and the original POMDP state. F or a particular pair of actions a, a 0 , there are exactly | S | HMM states that correspond to them. Thus looking at A P AC RL Algorithm for Episo dic POMDPs the columns of b O from left-to-right, and only picking out the columns that are lab eled with a, a 0 results in a sp ecific ordering of the states ( a, · , a 0 ), whic h is a p er- m utation of the POMDP states, whic h we denote as { s ( a,a 0 ) , 1 , s ( a,a 0 ) , 2 , . . . , s ( a,a 0 ) , | S | } . W e will also use the notation s ( a,a 0 ) to implicitly refer to a vector of states in the order of the p erm utation. The algorithm proceeds to estimate the original POMDP parameters in order to p erform planning and compute a policy . Note that the estimated parameters use the computed s ( a,a 0 ) p erm utations of the state. Let b O a,a 0 b e the submatrix where the ro ws and columns corresp ond to the actions ( a, a 0 ) and b T a,a 0 ,a 00 b e the submatrix where the rows corresp ond to the actions ( a 0 , a 00 ) and columns corresp ond to the actions ( a, a 0 ). Then the estimated POMDP parameters can b e com- puted as follo ws: b b ( s ( a 0 ,a 1 ) ) = nor maliz e (( b T − 1 b T − 1 b w )( a 0 , · , a 1 )) b p ( z | a, s ( a,a 0 ) ) = nor maliz e ( X r b O a,a 0 ) b p ( r | s ( a,a 0 ) , a 0 ) = nor maliz e ( X z b O a,a 0 ) b p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) = nor maliz e ( b T a,a 0 ,a 00 ) Note that w e require an additional normal iz e () pro ce- dure since the MoM approach w e leverage is not guar- an teed to return well formed probabilit y distributions. The normalization pro cedure just divides b y the sum to make them into v alid probability distributions (if there are negative v alues we can either set them to zero or ev en just use the absolute v alue). Algorithm 3 then uses these estimated POMDP pa- rameters to compute a p olicy . The algorithm con- structs β -vectors (see Definition 1) that represent the exp ected sum of rewards of following a particular p olicy starting with action a 0 giv en an input p er- m uted state s ( a,a 0 ) . Aside from this slight mo difica- tion, β -v ectors are analogous to α -vectors in standard POMDP planning. The β -v ectors form an approxi- mate v alue function for the underlying POMDP and can b e used in a similar wa y to standard α -vectors. 4.3 Phase 2 In phase 2, after estimating the POMDP parameters and β -vectors, we use the estimated POMDP v alue function to extract a p olicy for acting, and we will shortly pro ve sufficient conditions for this p olicy to b e near-optimal for all remaining episo des. The p olicy follow ed dep ends on the computed v alue function. If computationally tractable, one can com- pute β -vectors incremen tally for all p ossible H -step p olicies. In this case, con trol proceeds by finding the b est β -vector for the estimated initial b elief b b ( s ( a 0 ,a 1 ) ) (largest dot pro duct of the β -vector with the initial b elief ) and then following the associated p olicy b π . b π is then follow ed for the entire episo de with no additional b elief up dating required as the p olicy itself enco des the conditional branc hing. Ho wev er, in practical circumstances, it will not be p os- sible to enumerate all p ossible H -step p olicies. In this case, one can use p oin t-based approaches or other metho ds that use α -v ectors to enumerate only a sub- set of possible p olicies. In this case there will b e an additional error planning in the final error b ound due to finite set of policies considered. In our analysis we omit planning for simplicity and assume that we enu- merate all H -step p olicies. Definition 1. A β -ve ctor taking as input s ( a,a 0 ) with r o ot action a 0 and t -step c onditional p olicies f t ( r , z ) for e ach observation p air ( r , z ) is define d as β a 0 1 ( s ( a,a 0 ) ) = X r p ( r | s ( a,a 0 ) , a ) · r β a 0 ,f t t +1 ( s ( a,a 0 ) ) = X r,z,s ( a 0 ,f t ( r,z )) ( r + γ β f t ( r,z ) t ( s ( a 0 ,f t ( r,z )) )) · p ( r | s ( a,a 0 ) , a ) p ( z | s ( a 0 ,f t ( r,z )) , a ) p ( s ( a 0 ,f t ( r,z )) | s ( a,a 0 ) , a ) wher e f t ( r , z ) c an also denote the r o ot action of the p olicy f t ( r , z ) use d in terms like s ( a,f t ( r,z )) . 5 THEOR Y 5.1 P AC Theorem Setup W e now state our primary result. F or full details, please refer to our tec h rep ort 4 . Before doing so, we define some additional notation. Let V π ( b ) = P H i =1 r t starting from b elief b b e the total undiscoun ted re- w ard following policy π for an episo de. Let σ 1 ,a ( T a ) = max a σ 1 ( T a ) and similarly for σ 1 ,a ( R a ) and σ 1 ,a ( Z a ). Let σ a ( T a ) = min a σ | S | ( T a ) and similarly for σ a ( R a ) and σ a ( Z a ). Assume σ a ( T a ), σ a ( R a ), and σ a ( Z a ) are all at most 1 (otherwise each term can b e replaced by 1 in the final sample complexit y b ound b elo w). 5.2 P AC Theorem Theorem 1. F or POMDPs that satisfy the state d as- sumptions define d in the pr oblem setting, exe cuting EEPORL wil l achieve an exp e cte d episo dic r ewar d of V ( b 0 ) ≥ V ∗ ( b 0 ) − on al l but a numb er of episo des that is b ounde d by O H 4 V 2 max | A | 12 | R | 4 | Z | 4 | S | 12 1 + q log( 3 δ ) 2 log 3 δ C d,d,d δ 3 2 σ a ( T a ) 6 σ a ( R a ) 8 σ a ( Z a ) 8 2 4 http://www.cs.cmu.edu/ ~ zguo/#publications Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill with pr ob ability at le ast 1 − δ , wher e C d,d,d ( δ ) = min( C 1 , 2 , 3 ( δ ) , C 1 , 3 , 2 ( δ )) C 1 , 2 , 3 ( δ ) = min min i 6 = j || M 3 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 2 ) 2 || P 1 , 2 , 3 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 3 ) 1 C 1 , 3 , 2 ( δ ) = min min i 6 = j || M 2 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 3 ) 2 || P 1 , 3 , 2 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 2 ) 1 The quantities C 1 , 2 , 3 , C 1 , 3 , 2 directly arise from using the previously referenced MoM metho d for HMM pa- rameter estimation (Anandkumar et al., 2012) and in- v olve singular v alues of the moments of the induced HMM and the induced HMM parameters (see (Anand- kumar et al., 2012) for details). W e now briefly ov erview the proof. Detailed pro ofs are a v ailable in the supplemental material. W e first sho w that b y executing EEPORL we obtain param- eter estimates of the induced HMM, and bounds on these estimates, as a function of the num b er of data p oin ts (Lemma 2). W e then pro ve that we can use the induced HMM to obtain estimated parameters of the underlying POMDP (Lemma 4). Then we sho w that w e can compute policies that are equiv alen t (in struc- ture and v alue) to those from the original POMDP (Lemma 5). W e then b ound the error in the resulting v alue function estimates of the resulting p olicies due to the use of approximate (instead of exact) mo del parameters (Lemma 6). This allows us to compute a b ound on the num b er of required samples (episo des) necessary to ac hieve near-optimal p olicies, with high probabilit y , for use in phase 2. W e commence the proof b y b ounding the error in es- timates of the induced HMM parameters. In order to do that, we introduce Lemma 1, which pro ves that samples taken in phase 1 b elong to an induced HMM where the transition and observ ation matrices are full rank. This is a requiremen t for b eing able to apply the MoM HMM parameter estimation procedure of Anandkumar et al. (2012). Lemma 1. The induc e d HMM has the observation and tr ansition matric es define d as O ( x i t , h j t ) = δ ( a i t , a j t ) δ ( a i t +1 , a j t +1 ) p ( z i t +1 | a j t , s j t +1 ) p ( r i t +1 | s j t +1 , a j t +1 ) T ( h i t +1 , h j t ) = δ ( a i t +1 , a j t +1 ) p ( s i t +2 | s j t +1 , a j t +1 ) p ( a i t +2 | a j t ) wher e i is the index over the r ows and j is the in- dex over the c olumns, and x i t = ( a i t , z i t +1 , r i t +1 , a i t +1 ) , h i t +1 = ( a i t +1 , s i t +2 , a i t +2 ) , h j t = ( a j t , s j t +1 , a j t +1 ) . T and O ar e b oth ful l r ank and w = p ( h 2 ) has p osi- tive pr ob ability everywher e. F urthermor e the fol lowing terms ar e b ounde d: k T k 2 ≤ p | S | , k T − 1 k 2 ≤ 2(1+ c | A | ) σ a ( T a ) , σ min ( O ) ≥ σ a ( R a ) σ a ( Z a ) , and k O k 2 = σ 1 ( O ) ≤ | S | . Next, w e use Lemma 2, which is an extension of the metho d of moments metho d by Anandkumar et al. (2012) that provides a b ound on the accuracies of the estimated induced HMM parameters in terms of N , the num b er of samples collected. Our extension in- v olves computing b T (the original method only had b O and d O T ) and b ounding its accuracy . Lemma 2. Given an HMM such that p ( h 2 ) has p osi- tive pr ob ability everywher e, the tr ansition matrix is ful l r ank, and the observation matrix is ful l c olumn r ank, then by gathering N samples of ( x 1 , x 2 , x 3 ) , the esti- mates b T , b O , b w c an b e c ompute d such that || b T − T || 2 ≤ 18 | A || S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 1 || b O − O || 2 ≤ | A || S | 0 . 5 1 || b O − O || max ≤ 1 || b w − w || 2 ≤ 14 | A | 2 | S | 2 . 5 ( σ a ( R a ) σ a ( Z a )) − 4 1 wher e || · || 2 is the sp e ctr al norm for matric es, and the euclide an norm for ve ctors, and w is the mar ginal pr ob ability of h 2 , with pr ob ability 1 − δ , as long as N ≥ O | A | 2 | Z || R | (1 + p log(1 /δ )) 2 ( C d,d,d ( δ )) 2 · 2 1 log 1 δ ! Next w e pro ceed b y showing ho w to b ound the error in the estimates of the POMDP parameters. The fol- lo wing Lemma 3 is a prerequisite for computing the submatrices of b O and b T needed for the estimates of the POMDP parameters. Lemma 3. Given b O with max-norm err or O ≤ 1 3 | Z || R | , then the c olumns which c orr esp ond to HMM states of the form h = ( a, s 0 , a 0 ) c an b e lab ele d with their c orr esp onding a, a 0 using Algorithm 2. With the correct lab els, the submatrices of b O and b T allo w us to compute estimates of the original POMDP parameters in terms of these permutations s ( a,a 0 ) . Lemma 4 bounds the error in these resulting estimates. Lemma 4. Given b T , b O , b w with max-norm err ors T , O , w r esp e ctively, then the fol lowing b ounds hold on the estimate d POMDP mo del p ar ameters with pr ob- A P AC RL Algorithm for Episo dic POMDPs ability at le ast 1 − δ | b p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) − p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) | ≤ 4 | S | T 2 a | b p ( z | a, s ( a,a 0 ) ) − p ( z | a, s ( a,a 0 ) ) | ≤ 4 | Z || R | O | b p ( r | s ( a,a 0 ) , a 0 ) − p ( r | s ( a,a 0 ) , a 0 ) | ≤ 4 | Z || R | O | b b ( s ( a 0 ,a 1 ) ) − b ( s ( a 0 ,a 1 ) ) | ≤ 4 | A | 4 | S | ( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T ) wher e a = Θ(1 / | A | ) W e pro ceed b y b ounding the error in computing the estimated β -vectors. Lemma 5 states that β -vectors are equiv alen t under p erm utation to α -vectors. Lemma 5. Given the p ermutation of the states s ( a,a 0 ) ,j = s φ (( a,a 0 ) ,j ) , β -ve ctors and α -ve ctors over the same p olicy π t ar e e quivalent i.e. β π t t ( s ( a,a 0 ) ,j ) = α π t t ( s φ (( a,a 0 ) ,j ) ) The following lemma b ounds the error in the resulting α -vectors obtained b y p erforming POMDP planning, and follows from prior work (F ard et al., 2008; Ross et al., 2009). Lemma 6. Supp ose we have appr oximate POMDP p ar ameters with err ors | b p ( s 0 | s, a ) − p ( s 0 | s, a ) | ≤ T , | b p ( z | a, s 0 ) − p ( z | a, s 0 ) | ≤ Z , and | b p ( r | s, a ) − p ( r | s, a 0 ) | ≤ R . Then for any t -step c onditional p olicy π t | α π t t ( s ) − b α π t t ( s ) | ≤ t 2 R max ( | R | R + | S | T + | Z | Z ) . W e next prov e that our EEPORL algorithm computes a p olicy that is optimal for the input parameters 5 : Lemma 7. Algorithm 3 finds the p olicy b π which maximizes V b π ( b b ( s 1 )) for a POMDP with p ar ameters b b ( s 1 ) , b p ( z | a, s 0 ) , b p ( r | s, a ) , and b p ( s 0 | s, a ) . W e no w hav e all the key pieces to prov e our result. Pr o of. (Pro of sketc h of Theorem 1). Lemma 4 shows that the error in the estimates of the POMDP pa- rameters can b e b ounded in terms of the error in the induced HMM parameters, whic h is itself bounded in terms of the num ber of samples (Lemma 1). Lemma 5 and Lemma 6 together bound in the error in comput- ing the estimated v alue function (as represented b y β -vectors) using estimated POMDP parameters. W e then need to b ound the error from executing b π that Algorithm 3 returns compared to the optimal pol- icy π ∗ . W e kno w from Lemma 7 that Algorithm 3 5 Again, we could easily modify this to accoun t for ap- pro ximate planning error, but leav e this out for simplicity , as w e do not exp ect this to mak e a significan t impact on the resulting sample complexity , except in terms of minor c hanges to the p olynomial terms. correctly identifies the b est p olicy for the estimated POMDP . Then let the initial b eliefs b, b b hav e error k b − b b k ∞ ≤ b , and the b ound o ver α -vectors of an y p olicy π , k α π − b α π k ∞ ≤ α b e given. Then b V b π ( b b ) = b b · b α b π ≥ b b · b α π ∗ ≥ b b · α π ∗ − | b b · α π ∗ − b b · b α π ∗ | ≥ b b · α π ∗ − α ≥ b · α π ∗ − | b · α π ∗ − b b · α π ∗ | − α ≥ b · α π ∗ − b V max − α = V ∗ ( b ) − b V max − α where the first inequality is because b π is the optimal p olicy for b b and b α , the second inequality is b y the trian- gle inequalit y , the third inequalit y is b ecause k b b k 1 = 1, the fourth inequality is by the triangle inequality , the fifth inequalit y is since α is at most V max . Next V b π ( b ) = b · α b π ≥ b b · α b π − | b b · α b π − b · α b π | ≥ b b · α b π − b V max ≥ b b · b α b π − | b b · b α b π − b b · α b π | − b V max ≥ b b · b α b π − α − b V max where the first inequality is by triangle inequality , the second inequality is b ecause α is at most V max , the third inequality is triangle inequality , and the fourth inequalit y is due to k b b k 1 = 1. Putting those tw o to- gether results in V b π ( b ) ≥ V ∗ ( b ) − 2 b V max − 2 α Letting = 2 b V max + 2 α , and setting the num b er of episo des N to the v alue sp ecified in the theorem will ensure that the resulting errors b and α are small enough to obtain an -optimal p olicy as desired. 6 CONCLUSION W e hav e pro vided a P A C RL algorithm for an impor- tan t class of episodic POMDPs, whic h includes many information gathering domains. T o our kno wledge this is the first RL algorithm for partially observ able set- tings that has a sample complexit y that is a p olyno- mial function of the POMDP parameters. There are man y areas for future work. W e are inter- ested in reducing the set of curren tly required assump- tions, thereby creating P AC PORL algorithms that are suitable to more generic settings. Suc h a direc- tion ma y also require exploring alternatives to method of moments approaches for p erforming latent v ariable estimation. W e also hope that our theoretical results will lead to further insights on practical algorithms for partially observ able RL. Ac knowledgemen ts This w ork was supp orted b y NSF CAREER gran t 1350984. Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill References Naoki Ab e and Manfred K W armuth. On the compu- tational complexity of approximating distributions by probabilistic automata. Machine L e arning , 9(2-3):205– 260, 1992. Christopher Amato and Emma Brunskill. Diagnose and de- cide: An optimal bay esian approach. In In Pr oc e e dings of the Workshop on Bayesian Optimization and De cision Making at the Twenty-Sixth Annual Conferenc e on Neu- r al Information Pro c essing Systems (NIPS-12) , 2012. Animashree Anandkumar, Daniel Hsu, and Sham M Kak ade. A metho d of moments for mixture mo dels and hidden mark ov models. arXiv pr eprint arXiv:1203.0683 , 2012. Animashree Anandkumar, Rong Ge, Daniel Hsu, Sham M Kak ade, and Matus T elgarsky . T ensor decomp ositions for learning latent v ariable mo dels. The Journal of Ma- chine L e arning R ese ar ch , 15(1):2773–2832, 2014. John Asmuth, Lihong Li, Michael L Littman, Ali Nouri, and David Wingate. A bay esian sampling approach to exploration in reinforcement learning. In Pr o c e e dings of the Twenty-Fifth Confer enc e on Unc ertainty in Artificial Intel ligenc e , pages 19–26. AUAI Press, 2009. Mohammad Azar, Alessandro Lazaric, and Emma Brun- skill. Sequential transfer in multi-armed bandit with finite set of mo dels. In C.J.C. Burges, L. Bottou, M. W elling, Z. Ghahramani, and K.Q. W einberger, ed- itors, A dvanc es in Neur al Information Pr o c essing Sys- tems 26 , pages 2220–2228. Curran Associates, Inc., 2013. Byron Bo ots, Sa jid M Siddiqi, and Geoffrey J Gordon. Closing the learning-planning lo op with predictive state represen tations. The International Journal of Rob otics R ese ar ch , 30(7):954–966, 2011. Craig Boutilier. A p omdp formulation of preference elici- tation problems. In AAAI/IAAI , pages 239–246, 2002. Ronen I Brafman and Moshe T ennenholtz. R-max-a gen- eral p olynomial time algorithm for near-optimal rein- forcemen t learning. The Journal of Machine Le arning R ese ar ch , 3:213–231, 2003. Finale Doshi-V elez. Bayesian nonp ar ametric appr o aches for r einfor c ement le arning in p artial ly observable do- mains . PhD thesis, Massac husetts Institute of T echnol- ogy , 2012. Ey al Even-Dar, Sham M Kak ade, and Yishay Mansour. Reinforcemen t learning in p omdps without resets. In IJCAI , pages 690–695, 2005. Mahdi Milani F ard, Jo elle Pineau, and Peng Sun. A v ari- ance analysis for pomdp p olicy ev aluation. In AAAI , pages 1056–1061, 2008. Daniel Hsu, Sham M Kak ade, and T ong Zhang. A sp ec- tral algorithm for learning hidden marko v models. arXiv pr eprint arXiv:0811.4413 , 2008. Sham M. Kak ade. On the Sample Complexity of R einfor c e- ment L e arning. . PhD thesis, Univ ersity College London, 2003. Li Ling Ko, Da vid Hsu, W ee Sun Lee, and Sylvie CW Ong. Structured parameter elicitation. In AAAI , 2010. J Zico Kolter and Andrew Y Ng. Near-ba yesian exploration in polynomial time. In Pr o c e e dings of the 26th A nnual International Conferenc e on Machine L e arning , pages 513–520. ACM, 2009. T or Lattimore and Marcus Hutter. P ac b ounds for dis- coun ted mdps. In A lgorithmic le arning the ory , pages 320–334. Springer, 2012. Mic hael L Littman, Richard S Sutton, and Satinder P Singh. Predictiv e represen tations of state. In NIPS , v olume 14, pages 1555–1561, 2001. Stefanos Nik olaidis, Ramy a Ramakrishnan, Keren Gu, and Julie Shah. Efficient mo del learning from joint-action demonstrations for human-robot collab orativ e tasks. In HRI , pages 189–196, 2015. Leonid Peshkin and Say an Mukherjee. Bounds on sam- ple size for policy ev aluation in marko v en vironments. In Computational L e arning The ory , pages 616–629. Springer, 2001. Kaare Brandt Petersen et al. The matrix co okbo ok. 2015. Stephane Ross, Masoumeh Izadi, Mark Mercer, and David Buc keridge. Sensitivit y analysis of pomdp v alue func- tions. In Machine L e arning and Applic ations, 2009. ICMLA’09. International Confer enc e on , pages 317–323. IEEE, 2009. St ´ ephane Ross, Jo elle Pineau, Brahim Chaib-draa, and Pierre Kreitmann. A bay esian approac h for learning and planning in partially observ able marko v decision pro- cesses. The Journal of Machine L e arning Rese ar ch , 12: 1729–1770, 2011. L. Song, B. Bo ots, S. M. Siddiqi, G. J. Gordon, and A. J. Smola. Hilb ert space embeddings of hidden Mark ov mo dels. In Pr o c. 27th Intl. Conf. on Machine L e arning (ICML) , 2010. Gilb ert W Stewart, Ji-guang Sun, and Harcourt Brace Jo- v ano vich. Matrix p erturb ation the ory , volume 175. Aca- demic press New Y ork, 1990. Alexander L Strehl and Michael L Littman. A theoretical analysis of mo del-based interv al estimation. In Pr o c e e d- ings of the 22nd international c onfer enc e on Machine le arning , pages 856–863. ACM, 2005. Alexander L Strehl, Lihong Li, and Michael L Littman. Incremen tal mo del-based learners with formal learning- time guarantees. arXiv pr eprint arXiv:1206.6870 , 2012. Tsac hy W eissman, Erik Orden tlich, Gadiel Seroussi, Sergio V erdu, and Marcelo J W einberger. Inequalities for the l1 deviation of the empirical distribution. Hew lett-Packard L abs, T e ch. Rep , 2003. A P AC RL Algorithm for Episo dic POMDPs A App endix Ov erview This app endix is organized as follows. Section B, con tains a few generic help er lemmas. Section C contains pseudo-co de of the algorithm. Section D contains some small lemmas to b e used later. Section E states the main lemmas, which are also stated in the main pap er. Finally , section F contains the main theorem and pro of of the pap er. B Help er Lemmas B.1 Matrix Norms Lemma T ak en from the matrix norms section in the matrix co okb ook Petersen et al. (2015). 1. Induced norms (e.g. || · || 2 ) are sub-m ultiplicative: || AB || 2 ≤ || A || 2 || B || 2 2. || A || 2 ≤ || A || F 3. || A || max ≤ || A || 2 where || A || max = max ij | A ij | 4. || A || max ≤ || A || F 5. || A || F ≤ √ d || A || 2 where A has rank d 6. || A || F ≤ √ mn || A || max where A is m × n 7. || A || 2 ≤ √ mn || A || max 8. || AB || max ≤ √ mn 2 k || A || max || B || max deriv ed from || · || 2 where B is n × k B.2 P erturb ed In v erse Lemma T ak en from MoM pap er Anandkumar et al. (2012), whic h was taken from Theorem 2.5, p. 118 in Stewart et al. (1990). If 1. A, E ∈ R k × k , A is in vertible 2. || A − 1 E || 2 < 1 ( || A − 1 || 2 || E || 2 < 1 is sufficien t) 3. b A = A + E Then 1. b A is in vertible 2. || b A − 1 − A − 1 || 2 ≤ || E || 2 || A − 1 || 2 2 1 − || A − 1 E || 2 ≤ || E || 2 || A − 1 || 2 2 1 − || A − 1 || 2 || E || 2 (1) B.3 Submatrix Eigen v alue Extreme Lemma Let M b e a n × n symmetric matrix, which can b e viewed as a blo c k matrix M = A B C D (2) where A is k × k and B , C, D hav e appropriate dimensions. Then λ n ( M ) ≤ λ k ( A ) ≤ λ 1 ( A ) ≤ λ 1 ( M ) i.e. the min and max eigen v alues of A are b ounded in-b etw een the min and max eigenv alues of M . Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill Pr o of. The Rayleigh quotient with M is R ( M , x ) = x T M x x T x (3) suc h that min x R ( M , x ) is equal to the smallest eigen v alue λ n ( M ) and max x R ( M , x ) is equal to the largest eigen v alue λ 1 ( M ). Let x T = y T z T where y is column v ector of size k . Note that A is symmetric as well. Then R ( M , x ) = y T z T A B C D y z [ y T z T ] y z (4) = y T Ay + z T C y + y T B z + z T D z y T y + z T z (5) = ⇒ R ( M , [ y T 0]) = y T Ay y T y (6) = R ( A, y ) (7) This means that min x R ( M , x ) ≤ min y R ( M , [ y T 0]) = min y R ( A, y ) ≤ max y R ( A, y ) = max y R ( M , [ y T 0]) ≤ max x R ( M , x ). Thus λ n ( M ) ≤ λ k ( A ) ≤ λ 1 ( A ) ≤ λ 1 ( M ). B.4 Normalization Lemma Giv en a nonnegativ e, nonzero v ector x ∈ R n and an estimated v ector ˜ x ∈ R n suc h that k x − ˜ x k ∞ ≤ ≤ k x k 1 2 n , let the normalization function b e b x = nor maliz e ( ˜ x ) where b x i = | ˜ x i | k ˜ x k 1 . Then k nor maliz e ( x ) − nor maliz e ( ˜ x ) k ∞ ≤ 2( x i n + k x k 1 ) k x k 2 1 (8) Pr o of. Let abs ( ˜ x ) i = | ˜ x i | . Then | abs ( ˜ x ) i − x i | = || ˜ x i | − x i | ≤ | ˜ x i − x i | since x i ≥ 0. This implies that k abs ( ˜ x ) − x k ∞ ≤ k x − ˜ x k ∞ ≤ . Next note that | ( P i x i ) − P i ( abs ( ˜ x ) i ) | ≤ P i | x i − abs ( ˜ x ) i | which means |k x k 1 − k abs ( ˜ x ) k 1 | ≤ k x − abs ( ˜ x ) k 1 ≤ n . Note that k abs ( ˜ x ) k 1 = k ˜ x k 1 . Then | nor maliz e ( x ) i − nor maliz e ( ˜ x ) i | = x i k x k 1 − | ˜ x i | k ˜ x k 1 (9) ≤ | x i k ˜ x k 1 − | ˜ x i |k x k 1 | k x k 1 k ˜ x k 1 (10) ≤ | x i k ˜ x k 1 − x i k x k 1 | + | x i k x k 1 − | ˜ x i |k x k 1 | k x k 1 ( k x k 1 − n ) (11) ≤ x i n + k x k 1 1 2 k x k 2 1 (12) ≤ 2( x i n + k x k 1 ) k x k 2 1 (13) where the n umerator of the third inequality follows from k x − abs ( ˜ x ) k 1 ≤ n that w as derived ab o ve. A P AC RL Algorithm for Episo dic POMDPs C Algorithm Algorithm 1: EEPORL input : S, A, Z, R, H , N , c, π rest 1 Let π explor e b e the p olicy where a 1 , a 2 are uniformly random, and p ( a t +2 | a t ) = 1 1+ c | A | ( I + c 1 | A |×| A | ) ; 2 X ← ∅ ; // Phase 1: // Collect samples for an induced HMM 3 for episo de i ← 1 to N do 4 F ollo w π explor e for 4 steps ; 5 Let x t = ( a t , r t , z t , a t +1 ) ; // collect observation sample tuple 6 X ← X ∪ { ( x 1 , x 2 , x 3 ) } ; 7 Execute π rest for the rest of the steps ; // Phase 2: // Compute estimated POMDP parameters 8 Get b T , b O , b w for the induced H M M from X through an adapted MoM metho d ; 9 Call Algorithm 2 with b O to lab el the columns with their corresp onding actions ; 10 Let s ( a,a 0 ) ,i b e a p erm utation of states by following the ordering of the columns of b O corresponding to h = ( a, · , a 0 ) ; 11 Let b O a,a 0 b e the submatrix where the rows and columns corresp ond to the actions ( a, a 0 ) ; 12 Let b T a,a 0 ,a 00 b e the submatrix where the rows corresp ond to the actions ( a 0 , a 00 ) and columns corresp ond to the actions ( a, a 0 ) ; 13 Compute the following estimates of the POMDP parameters: b b ( s ( a 0 ,a 1 ) ) = nor maliz e (( b T − 1 b T − 1 b w )( a 0 , · , a 1 )) b p ( z | a, s ( a,a 0 ) ) = nor maliz e ( X r b O a,a 0 ) b p ( r | s ( a,a 0 ) , a 0 ) = nor maliz e ( X z b O a,a 0 ) b p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) = nor maliz e ( b T a,a 0 ,a 00 ) Call Algorithm 3 with the ab o v e quantities to estimate a p olicy b π ; 14 Execute b π for the rest of the episo des ; Algorithm 2: Lab elActions input : b O 1 foreach c olumn i of b O do 2 Find a ro w j suc h that b O ( i, j ) ≥ 2 3 | R || Z | ; 3 Let the observ ation asso ciated with row j b e ( a, r 0 , z 0 , a 0 ), then lab el column i with ( a, a 0 ) ; D Small Lemmas D.1 Spectral Norm Lemma Lemma. F or any a ∈ A || T a || 2 ≤ p | S | (14) || Z a || 2 ≤ p | S | (15) || R a || 2 ≤ p | S | (16) Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill Algorithm 3: FindPolicy input : b b ( s ( a 0 ,a 1 ) ) b p ( z | a, s ( a,a 0 ) ) b p ( r | s ( a,a 0 ) , a 0 ) b p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) // First, incrementally compute β -vectors for all t -step policies // Γ a − ,a t contains all β -vectors for t -step policies that take as input the permtuation s ( a − ,a ) 1 ∀ a − , a ∈ A, Γ a − ,a 1 = { b β a 1 ( s ( a − ,a ) ) } ; 2 for t ← 2 to H do 3 ∀ a, a 0 ∈ A, Γ a,a 0 t = ∅ ; 4 for a, a 0 ∈ A do 5 for f t ( r , z ) ∈ ( | R | × | Z | → Γ a,a 0 t − 1 ) do // all mappings from an observation pair to a previous β -vector 6 ∀ a − ∈ A, Γ a − ,a t = Γ a − ,a t ∪ { β a,f t t ( s ( a − ,a ) ) } ; 7 Return arg max a 0 ,a 1 ,β H ( s ( a 0 ,a 1 ) )) ∈ Γ a 0 ,a 1 H P s ( a 0 ,a 1 ) b b ( s ( a 0 ,a 1 ) ) · β H ( s ( a 0 ,a 1 ) ) ; Pr o of. Using || A || 2 ≤ || A || F = || v ec ( A ) || 2 ≤ p || v ec ( A ) || 1 where v ec ( A ) is the vector of the en tries of the matrix A , and the last inequalit y holds b ecause all entries of A are at most 1 || T a || 2 ≤ p | S | (17) || Z a || 2 ≤ p | S | (18) || R a || 2 ≤ p | S | (19) D.2 Exploration P olicy Lemma Lemma. L et Π b e the | A | × | A | matrix that π explor e is b ase d on wher e p ( a t +2 | a t ) = Π( a t +2 , a t ) (20) = 1 1 + c | A | ( I + c 1 | A |×| A | ) (21) and c > 0 is an op en p ar ameter, and 1 | A |×| A | is a | A | × | A | matrix of al l ones. Then it fol lows that || Π || 2 ≤ 1 (22) || Π − 1 || 2 ≤ 2(1 + c | A | ) (23) a = min a 00 ,a Π( a 00 , a ) = c 1 + c | A | (24) Pr o of. Π is a p erturbed identit y matrix Π = 1 1 + c | A | ( I + c 1 | A |×| A | ) (25) where c > 0 is a real num ber w e can choose, and 1 | A |×| A | is a | A | × | A | matrix of all ones. This yields Π such that eac h column is a probability distribution, where the off diagonal en tries are all equal, and the diagonal entries A P AC RL Algorithm for Episo dic POMDPs are equal and greater than the off diagonal entries. Then a = min a 00 ,a Π( a 00 , a ) = c 1 + c | A | (26) Since 1 | A |×| A | has only a rank of 1, it can ha ve at most one nonzero eigen v alue. Note 1 | A |×| A | 1 | A | = | A | 1 | A | where 1 | A | is a column v ector of ones. Then 1 | A |×| A | has only one nonzero eigenv alue of | A | . Thus || 1 | A |×| A | || 2 = | A | . Then k Π k 2 = 1 1 + c | A | ( I + c 1 | A |×| A | ) 2 (27) ≤ 1 1 + c | A | ( k I k 2 + c k 1 | A |×| A | k 2 ) (28) ≤ 1 1 + c | A | (1 + c | A | ) (29) ≤ 1 (30) Next, b y the Sherman-Morrison formula ( I + c 1 | A |×| A | ) − 1 = ( I + c 1 | A | 1 T | A | ) − 1 (31) = I − I ( c 1 | A | ) 1 T | A | I 1 + 1 T | A | I ( c 1 | A | ) (32) = I − c 1 | A |×| A | 1 + c | A | (33) then k Π − 1 k 2 = 1 1 + c | A | ( I + c 1 | A |×| A | ) − 1 2 (34) = (1 + c | A | ) I + c 1 | A |×| A | − 1 2 (35) = (1 + c | A | ) I − c 1 | A |×| A | 1 + c | A | 2 (36) ≤ (1 + c | A | ) k I k 2 + c 1 + c | A | 1 | A |×| A | 2 (37) = (1 + c | A | ) 1 + c | A | 1 + c | A | (38) ≤ (1 + c | A | ) (1 + 1) (39) = 2(1 + c | A | ) (40) E Main Lemmas E.1 Lemma 1 and Proof Lemma 1. The induc e d HMM has the observation and tr ansition matric es define d as O ( x i t , h j t ) = δ ( a i t , a j t ) δ ( a i t +1 , a j t +1 ) p ( z i t +1 | a j t , s j t +1 ) p ( r i t +1 | s j t +1 , a j t +1 ) T ( h i t +1 , h j t ) = δ ( a i t +1 , a j t +1 ) p ( s i t +2 | s j t +1 , a j t +1 ) p ( a i t +2 | a j t ) Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill wher e i is the index over the r ows and j is the index over the c olumns, and x i t = ( a i t , z i t +1 , r i t +1 , a i t +1 ) , h i t +1 = ( a i t +1 , s i t +2 , a i t +2 ) , h j t = ( a j t , s j t +1 , a j t +1 ) . T and O ar e b oth ful l r ank and w = p ( h 2 ) has p ositive pr ob ability everywher e. F urthermor e k T k 2 ≤ p | S | (41) k T − 1 k 2 ≤ 2(1+ c | A | ) σ a ( T a ) (42) σ min ( O ) ≥ σ a ( R a ) σ a ( Z a ) (43) k O k 2 = σ 1 ( O ) ≤ | S | (44) Pr o of: First we will show that the Mark o v property holds for the newly defined hidden state. Then we will show that the middle b elief has p ositiv e probabilit y ev erywhere. Then we will show that the observ ation and transition matrices of this induced HMM are as stated and hav e full column rank and hav e b ounded s ingular v alues. E.1.1 HMM The HMM state is defined as h t = ( a t , s t +1 , a t +1 ), i.e. a state along with the previous and current actions. The new HMM observ ation will be x t = ( a t , z t +1 , r t +1 , a t +1 ). Note that the action is defined to only depend on the action 2 steps ago i.e. p ( a t +2 | a t ) and is indep enden t of everything else. First, the Marko v prop ert y will b e shown to hold p ( h t +1 | . . . , h t ) = p (( a 0 t +1 , s 0 t +2 , a 0 t +2 ) | . . . , ( a t , s t +1 , a t +1 )) (45) = p ( a 0 t +2 | a t ) p ( a 0 t +1 | a t +1 ) p ( s 0 t +2 | s t +1 , a t +1 ) (46) = p ( h t +1 | h t ) (47) Note that p ( a 0 t +1 | a t +1 ) is just a delta function. Next, the HMM observ ation will b e sho wn to only directly depend on the curren t HMM state p ( x t | h t , . . . ) = p ( a 0 t , z t +1 , r t +1 , a 0 t +1 | a t , s t +1 , a t +1 , . . . ) (48) = p ( a 0 t | a t ) p ( a 0 t +1 | a t +1 ) p ( z t +1 | a t , s t +1 ) p ( r t +1 | s t +1 , a t +1 ) (49) = p ( x t | h t ) (50) where p ( a 0 t | a t ) and p ( a 0 t +1 | a t +1 ) are essen tially delta functions. Thus this formulation gives rise to an HMM. E.1.2 Middle Belief By the assumptions on the initial b elief of the POMDP , after any a 2 , all states are reachable for s 3 . This means p ( a 2 , s 3 ) has p ositiv e probability for all v alues. F urthermore, a 3 only dep ends on a 1 . Since a 1 is uniformly random, b y the choice of Π, a 3 is also uniformly random. Th us p ( a 2 , s 3 , a 3 ) = p ( h 2 ) has positive probability for all v alues. E.1.3 Observ ation Matrix Next, the HMM observ ation matrix will b e derived O ( x i t , h j t ) = p ( a i t , z i t +1 , r i t +1 , a i t +1 | a j t , s j t +1 , a j t +1 ) (51) = δ ( a i t , a j t ) δ ( a i t +1 , a j t +1 ) p ( z i t +1 | a j t , s j t +1 ) p ( r i t +1 | s j t +1 , a j t +1 ) (52) where i is the index ov er the rows and j is the index ov er the columns, and x i t = ( a i t , z i t +1 , r i t +1 , a i t +1 ) , h j t = ( a j t , s j t +1 , a j t +1 ). Also note that the t here doesn’t really matter (since the matrix is the same for all t ), and is only used in a relativ e wa y to distinguish b et ween current and next time steps. The next claim is that O is full column rank. T o see this, first p erm ute the columns and rows of O so that they are group ed by ( a i t , a i t +1 ) for the rows and ( a j t , a j t +1 ) for the columns. Then the only nonzero blocks are when ( a i t , a i t +1 ) = ( a j t , a j t +1 ) i.e. O b ecomes a blo c k diagonal matrix with rectangular blo cks. Next, fix A P AC RL Algorithm for Episo dic POMDPs ( a t , a t +1 ) = ( a i t , a i t +1 ) = ( a j t , a j t +1 ). Then the blo ck corresp onding to ( a t , a t +1 ) is made up of the en tries p ( z i t +1 | a t , s j t +1 ) p ( r i t +1 | s j t +1 , a t +1 ). Call this blo c k O a t ,a t +1 . Consider lo oking only at the ro ws where we fix r i t +1 = r , then the columns are just a scaled v ersion of the columns of Z a t . Since Z a t has full column rank, this implies that this blo c k also has linearly indep enden t columns. Since all of the diagonal blo c ks of O hav e full column rank, this implies O itself has full column rank. Finally , consider the singular v alues of O . Recall O can be view ed as a blo c k diagonal matrix with rectangular blo c ks O a t ,a t +1 . Then ( O T O ) is a block diagonal matrix with square blo cks of (( O a t ,a t +1 ) T O a t ,a t +1 ) on the diagonal. The eigen v alues of ( O T O ) are therefore just the eigenv alues of (( O a t ,a t +1 ) T O a t ,a t +1 ) i.e. the singular v alues of O are just the singular v alues of O a t ,a t +1 . Note that O a t ,a t +1 (( z , r ) , s ) = p ( z | a t , s ) p ( r | s, a t +1 ) and can b e though t of as the kroneck er pro duct ( R a t +1 ⊗ Z a t )(( r , z ) , ( s 1 , s 2 )) = p ( z | a t , s 1 ) p ( r | s 2 , a t +1 ) but with all the columns remov ed except for the columns in which s 1 = s 2 = s . In other words the kronec ker product can b e though t of as the following blo ck matrix R a t +1 ⊗ Z a t = [ O a t ,a t +1 B ] (53) where B is a matrix con taining the columns of the kroneck er pro duct not present in O a t ,a t +1 . Then ( R a t +1 ⊗ Z a t ) T ( R a t +1 ⊗ Z a t ) = (( O a t ,a t +1 ) T O a t ,a t +1 ) . . . . . . . . . (54) Then by the submatrix eigenv alue extreme lemma, it follows that σ min ( R a t +1 ⊗ Z a t ) ≤ σ min ( O a t ,a t +1 ) ≤ σ 1 ( O a t ,a t +1 ) ≤ σ 1 ( R a t +1 ⊗ Z a t ). Then σ min ( O ) = σ min ( O a t ,a t +1 ) (55) ≥ (min a,a 0 σ min ( R a ) σ min ( Z a 0 )) (56) ≥ σ a ( R a ) σ a ( Z a ) (57) σ 1 ( O ) = σ 1 ( O a t ,a t +1 ) (58) ≤ (max a,a 0 σ 1 ( R a ) σ 1 ( Z a 0 )) (59) ≤ | S | (60) where the last inequalit y follows from Lemma D.1. E.1.4 T ransition Matrix Next, the HMM transition matrix will b e derived T ( h i t +1 , h j t ) = p ( a i t +1 , s i t +2 , a i t +2 | a j t , s j t +1 , a j t +1 ) (61) = δ ( a i t +1 , a j t +1 ) p ( s i t +2 , a i t +2 | a j t , s j t +1 , a j t +1 ) (62) = δ ( a i t +1 , a j t +1 ) p ( s i t +2 | s j t +1 , a j t +1 ) p ( a i t +2 | a j t ) (63) where i is the index o ver the rows and j is the index ov er the columns, and h i t +1 = ( a i t +1 , s i t +2 , a i t +2 ) , h j t = ( a j t , s j t +1 , a j t +1 ). T o see that T is full rank, first p erm ute the rows to be group ed by a i t +1 , and p ermute the columns to b e group ed b y a j t +1 . Then T b ecomes a blo ck diagonal matrix, with each diagonal block composed of p ( s i t +2 | s j t +1 , a t +1 ) p ( a i t +2 | a j t ), where a t +1 = a i t +1 = a j t +1 . This diagonal blo c k is actually the kronec ker pro d- uct of T a t +1 and Π. Since T a t +1 and Π are both full rank, their kronc k er product is also full rank. Since all the diagonal blo c ks are full rank, that means T is full rank. Finally , consider the singular v alues of T . Since T is a block diagonal matrix, the singular v alues are exactly the singular v alues of all the diagonal blo c ks. Eac h blo c k is kronec k er pro duct T a ⊗ Π, th us the singular v alues of eac h blo ck is made up of the pro duct of singular v alues of T a and Π. Therefore σ 1 ( T ) = max a σ 1 ( T a ) σ 1 (Π) and Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill σ min ( T ) = min a σ min ( T a ) σ min (Π). Thus k T k 2 = max a k T a k 2 k Π k 2 (64) ≤ p | S | (65) k T − 1 k 2 = 1 σ min ( T ) (66) = 1 min a σ min ( T a ) σ min (Π) (67) = k Π − 1 k 2 σ a ( T a ) (68) ≤ 2(1 + c | A | ) σ a ( T a ) (69) E.2 Lemma 2 and Proof Lemma 2. Given an HMM such that the mar ginal pr ob ability of h 2 has p ositive pr ob ability everywher e, the tr ansition matrix is ful l r ank, and the observation matrix is ful l c olumn r ank, then by gathering N samples of ( x 1 , x 2 , x 3 ) , the estimates b T , b O , b w c an b e c ompute d such that || b T − T || 2 ≤ 18 | A || S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 1 (70) || b O − O || 2 ≤ | A || S | 0 . 5 1 (71) || b O − O || max ≤ 1 (72) || b w − w || 2 ≤ 14 | A | 2 | S | 2 . 5 ( σ a ( R a ) σ a ( Z a )) − 4 1 (73) wher e || · || 2 is the sp e ctr al norm for matrix ar guments, and the Euclide an norm for ve ctor ar guments, and w is the mar ginal pr ob ability of h 2 , with pr ob ability 1 − δ , as long as O | A | 2 | Z || R | (1 + p log(1 /δ )) 2 ( C d,d,d ( δ )) 2 · 2 1 log 1 δ ! ≤ N (74) Pr o of: The pro of will first use prior metho d of momen ts w ork to deriv e bounds on the estimation error on O and O T of the induced HMM. Then using those estimates, we will show how to compute an estimate of T and b ound its error. Then, we will show how to estimate w and its error. Finally we will give a sufficient low er b ound on N in order to ac hieve an estimation error of 1 on the estimated matrices. E.2.1 Method of Moments Theorem 3.1 from Anandkumar et al. (2012) states that given 3 , if the follo wing is satisfied (i.e. there are at least this man y samples of ( x 1 , x 2 , x 3 )) 1 + p log(1 /δ ) √ N ≤ C · C 1 , 2 , 3 ( δ ) · 3 (75) ⇐ ⇒ 1 + p log(1 /δ ) C · C 1 , 2 , 3 ( δ ) · 3 ≤ √ N (76) ⇐ ⇒ (1 + p log(1 /δ )) 2 C 2 ( C 1 , 2 , 3 ( δ )) 2 · 2 3 ≤ N (77) and also giv en 2 , if the follo wing is also satisfied (1 + p log(1 /δ )) 2 C 2 ( C 3 , 1 , 2 ( δ )) 2 · 2 2 ≤ N (78) A P AC RL Algorithm for Episo dic POMDPs where C 1 , 2 , 3 ( δ ) = min min i 6 = j || M 3 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 2 ) 2 || P 1 , 2 , 3 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 3 ) 1 (79) C 1 , 3 , 2 ( δ ) = min min i 6 = j || M 2 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 3 ) 2 || P 1 , 3 , 2 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 2 ) 1 (80) C d,d,d ( δ ) = min( C 1 , 2 , 3( δ ) , C 1 , 3 , 2 ( δ )) (81) then || col ( ˜ O ) − col ( O ) || 2 ≤ 2 (82) || col ( ˜ O T ) − col ( O T ) || 2 ≤ 3 (83) with probabilit y 1 − δ . In other words, the estimated parameters are close in the Euclidean norm. Note that the columns of ˜ O and ˜ O T may b e permuted from O and O T , how ever ˜ O and ˜ O T are p erm uted in the same unknown w ay to match. No knowledge of the permutation is necessary . Then b y matrix norms k ˜ O − O k 2 ≤ k ˜ O − O k F (84) ≤ | A | p | S | 2 (85) k ˜ O − O k max ≤ max i || col i ( ˜ O ) − col i ( O ) || ∞ (86) ≤ max i || col i ( ˜ O ) − col i ( O ) || 2 (87) ≤ 2 (88) k ˜ O T − O T k 2 ≤ | A | p | S | 3 (89) using the fact that from the Euclidean distances of the columns we can conclude that the F rob enius norm is p P ncols 2 2 = 2 p | A | 2 | S | . E.2.2 Constructing T ransition Matrix Estimate The pseudoin verse of O can b e used to compute the HMM transition matrix T since O is full column rank O + O T = ( O T O ) − 1 O T O T (90) = T (91) Then follo wing the same pro cedure, the HMM transition matrix estimate can b e computed b T = b O + d O T (92) = ( b O T b O ) − 1 b O T d O T (93) Next, to compute the error || b T − T || 2 = || ( b O T b O ) − 1 b O T d O T − ( O T O ) − 1 O T O T || 2 (94) first some in termediate quantities will b e computed. T o begin, because we will be computing in v erses, w e need to bound the accuracy 2 in order to use the perturb ed in v erse lemma; therefore w e first assume the following condition Condition 1. 2 ≤ 1 6 | A || S | 1 . 5 ( σ a ( R a ) σ a ( Z a )) − 4 (95) Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill Then || b O T b O − O T O || 2 (96) ≤ || b O T b O − b O T O || 2 + || b O T O − O T O || 2 (97) ≤ || b O T || 2 || b O − O || 2 + || O || 2 || b O T − O T || 2 (98) ≤ ( || b O T || 2 + || O || 2 ) | A | p | S | 2 (99) ≤ (2 || O || 2 + | A | p | S | 2 ) | A | p | S | 2 (100) ≤ (2 | S | + 1) | A | p | S | 2 (101) ≤ (3 | S | ) | A | p | S | 2 (102) ≤ 3 | A || S | 1 . 5 2 (103) where we substitute in our previous b ounds on the estimation error, matrix norms from lemma 1, and also use the rev erse triangle inequality on ( || b O T || 2 − || O || 2 + || O || 2 ). Then by the p erturbed inv erse lemma || ( b O T b O ) − 1 − ( O T O ) − 1 || 2 ≤ 3 | A || S | 1 . 5 2 || ( O T O ) − 1 || 2 2 1 − 3 | A || S | 1 . 5 2 || ( O T O ) − 1 || 2 (104) ≤ 3 | A || S | 1 . 5 2 || ( O T O ) − 1 || 2 2 1 2 (105) ≤ 6 | A || S | 1 . 5 || ( O T O ) − 1 || 2 2 2 (106) ≤ 6 | A || S | 1 . 5 ( σ a ( R a ) σ a ( Z a )) − 4 2 (107) where the second inequality follows from substituting in the b ound on σ min ( O ) from lemma 1 combined with the ab o v e condition. Now the error in estimating the HMM transition matrix will b e computed || b T − T || 2 (108) = || ( b O T b O ) − 1 b O T d O T − ( O T O ) − 1 O T ( O T ) || 2 (109) ≤ || ( b O T b O ) − 1 b O T d O T − ( O T O ) − 1 b O T d O T || 2 + || ( O T O ) − 1 b O T d O T − ( O T O ) − 1 O T ( O T ) || 2 (110) ≤ || ( b O T b O ) − 1 − ( O T O ) − 1 || 2 || b O T d O T || 2 + || b O T d O T − O T ( O T ) || 2 || ( O T O ) − 1 || 2 (111) ≤ || ( b O T b O ) − 1 − ( O T O ) − 1 || 2 || b O T || 2 || d O T || 2 (112) + || b O T − O T || 2 || d O T || 2 || ( O T O ) − 1 || 2 (113) + || O || 2 || d O T − O T || 2 || ( O T O ) − 1 || 2 (114) ≤ 6 | A || S | 1 . 5 || ( O T O ) − 1 || 2 2 2 | S | 2 . 5 + | A || S | 0 . 5 2 | S | 1 . 5 || ( O T O ) − 1 || 2 + | S || A || S | 0 . 5 3 || ( O T O ) − 1 || 2 (115) where we substitute in v alues from lemma 1 and the estimation errors calculated ab o ve. The next simplification is b y letting 2 = 3 = 1 , then || b T − T || 2 (116) ≤ 6 | A || S | 1 . 5 || ( O T O ) − 1 || 2 2 1 | S | 2 . 5 + | A || S | 0 . 5 1 | S | 1 . 5 || ( O T O ) − 1 || 2 + | S || A || S | 0 . 5 1 || ( O T O ) − 1 || 2 (117) ≤ 6 | A || S | 4 || ( O T O ) − 1 || 2 2 1 + | A || S | 2 || ( O T O ) − 1 || 2 1 + | A || S | 1 . 5 || ( O T O ) − 1 || 2 1 (118) ≤ 6( | A || S | 4 + | A || S | 2 + | A || S | 1 . 5 ) || ( O T O ) − 1 || 2 2 1 (119) ≤ 18 | A || S | 4 || ( O T O ) − 1 || 2 2 1 (120) ≤ 18 | A || S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 1 (121) E.2.3 Estimating w Let X 2 b e random v ariable for x 2 i.e. the HMM observ ation of the second step. Let p b e the distribution of x 2 . Let b p b e the empirical distribution made from the coun ts of the samples from x 2 obtained from the exploring A P AC RL Algorithm for Episo dic POMDPs episo des. Then from W eissman et al. (2003) we can b ound the deviation δ p = P ( || b p − p || 1 ≥ 1 ) ≤ (2 | A | 2 | R || Z | − 2) e − N 2 2 (122) ⇐ = N ≥ O log 1 δ p | A | 2 | R || Z | 2 1 (123) and get a sufficien t condition on how many samples we need. w = p ( h 2 ) can b e computed by p = O w (124) = ⇒ w = ( O ) + p (125) = (( O ) T ( O )) − 1 ( O ) T p (126) and th us estimated using b O and b p . Next, the error of the estimate will be b ounded. Let || b p − p || 2 = 1 . Note that || ( b O T b O ) − 1 − ( O T O ) − 1 || 2 has b een computed in the previous section. || b w − w || 2 (127) = || ( b O T b O ) − 1 b O T b p − ( O T O ) − 1 O T p || 2 (128) ≤ || ( b O T b O ) − 1 b O T b p − ( O T O ) − 1 b O T b p || 2 + || ( O T O ) − 1 b O T b p − ( O T O ) − 1 O T p || 2 (129) ≤ || b O T || 2 || b p || 2 || ( b O T b O ) − 1 − ( O T O ) − 1 || 2 + || ( O T O ) − 1 || 2 || b O T b p − O T p || 2 (130) ≤ || b O T || 2 || ( b O T b O ) − 1 − ( O T O ) − 1 || 2 + || ( O T O ) − 1 || 2 ( || b O T b p − O T b p || 2 + || O T b p − O T p || 2 ) (131) ≤ ( || O || 2 + || b O T − O T || 2 ) || ( b O T b O ) − 1 − ( O T O ) − 1 || 2 + || ( O T O ) − 1 || 2 ( || b O T − O T || 2 + || O || 2 1 ) (132) ≤ ( | S | + | A || S | 0 . 5 1 )(6 | A || S | 1 . 5 || ( O T O ) − 1 || 2 2 1 ) + || ( O T O ) − 1 || 2 ( | A || S | 0 . 5 1 + | S | 1 ) (133) ≤ 14 | A | 2 | S | 2 . 5 || ( O T O ) − 1 || 2 2 1 (134) ≤ 14 | A | 2 | S | 2 . 5 ( σ a ( R a ) σ a ( Z a )) − 4 1 (135) where the first inequalit y is from using triangle inequality; the third inequality uses the fact that || b p || 1 ≤ 1 and also another triangle inequality; the fifth inequalit y substitutes in v alues computed from previous sections; the sixth inequality comes from assuming that || ( O T O ) − 1 || 2 ≤ || ( O T O ) − 1 || 2 2 , which is implied by assuming that σ a ( R a ) − 1 ≥ 1 and σ a ( Z a ) − 1 ≥ 1. T o b e precise we should instead use the quantities max( σ a ( R a ) − 1 , 1) and max( σ a ( z a ) − 1 , 1). In the final sample complexit y bound, we will implicitly use the v ersions with the max op erator wherever the quantities σ a ( R a ) − 1 and σ a ( Z a ) − 1 . E.2.4 Com bining the Conditions Recall eqn 78 (1 + p log(1 /δ )) 2 C 2 ( C 3 , 1 , 2 ( δ )) 2 · 2 2 ≤ N (136) whic h needs to b e satisfied in order to get estimation error b ounds on 2 (and resp ectiv ely 3 ). Combining these requiremen ts with the one from estimating w (eqn 123), and letting 2 = 3 = 1 , we get a single requirement of O | A | 2 | R || Z | (1 + p log(3 /δ )) 2 C 2 ( C d,d,d ( δ / 3)) 2 · 2 1 log 3 δ ! ≤ N (137) where w e give each of the three requirements an error probability of δ / 3. E.3 Lemma 3 and Proof Lemma 3. Given b O with max-norm err or O ≤ 1 3 | Z || R | , then the c olumns which c orr esp ond to HMM states of the form h = ( a, s 0 , a 0 ) c an b e lab ele d with their c orr esp onding a, a 0 using Algorithm 2. Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill Pr o of: Recall O ( i, j ) = p ( x t = i | h t = j ) = δ ( a i t , a j t ) δ ( a i t +1 , a j t +1 ) p ( z i t +1 | a j t , s j t +1 ) p ( r i t +1 | s j t +1 , a j t +1 ). Consider a column of O . The column corresp onds to some HMM state j = ( a j t , s j t +1 , a j t +1 ), but the ( a j t , s j t +1 , a j t +1 ) are unknown and only the index j is known. Ho wev er the rows, which corresp ond to HMM observ ation i = ( a i t , z i t +1 , r i t +1 , a i t +1 ), are known since the observ ations are fully observed. The only entries in this column that can b e nonzero are the ro ws where the actions match i.e. ( a t , a t +1 ) = ( a i t , a i t +1 ) = ( a j t , a j t +1 ). There are | Z || R | n um b er of these en tries. The nonzero entries form a probabilit y distribution and must sum to one. Therefore, the largest nonzero v alue in this column must b e at least 1 | Z || R | . Since by assumption O ≤ 1 3 | R || Z | , the largest nonzero v alue in b O m ust b e at least 2 3 | Z || R | . Thus there exist at least one entry in this column of b O that is at least 2 3 | Z || R | and where the actions matc h, so it is p ossible to encounter this during Algorithm 2. Also, Algorithm 2 cannot pick en tries from b O that are zero in O , since those entries w ould b e at most only 1 3 | Z || R | . Thus Algorithm 2 will alwa ys pick an entry with matc hing actions, and correctly lab el the HMM state corresp onding to each column with the matching actions. E.4 Lemma 4 and Proof Lemma 4. Given b T , b O , b w with max-norm err ors T , O , w r esp e ctively, then the fol lowing b ounds hold on the estimate d POMDP mo del p ar ameters with pr ob ability at le ast 1 − δ : | b p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) − p ( s ( a 0 ,a 00 ) | s ( a,a 0 ) , a 0 ) | ≤ 4 | S | T 2 a (138) | b p ( z | a, s ( a,a 0 ) ) − p ( z | a, s ( a,a 0 ) ) | ≤ 4 | Z || R | O (139) | b p ( r | s ( a,a 0 ) , a 0 ) − p ( r | s ( a,a 0 ) , a 0 ) | ≤ 4 | Z || R | O (140) | b b ( s ( a 0 ,a 1 ) ) − b ( s ( a 0 ,a 1 ) ) | (141) ≤ 4 | A | 4 | S | ( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T ) (142) wher e a = Θ(1 / | A | ) Pr o of: First we will show the errors for the estimated observ ation, rew ard, and transition parameters. Then we will sho w the errors for the estimated initial b elief. E.4.1 Observ ation, Rew ard, and T ransition By the normalization lemma for P r b O H M M ,a,a 0 (( z , r ) , s ( a, a 0 )) o ver z | b p ( z | a, s ( a, a 0 )) − p ( z | a, s ( a, a 0 )) | (143) = k nor maliz e X r O H M M ,a,a 0 (( z , r ) , s ( a, a 0 )) ! − nor maliz e X r b O H M M ,a,a 0 (( z , r ) , s ( a, a 0 )) ! k ∞ (144) ≤ 2( | Z | + 1) | R | O 1 (145) = 4 | Z || R | O (146) By the normalization lemma for P z b O H M M ,a,a 0 (( z , r ) , s ( a, a 0 )) o ver r | b p ( r | a, s ( a, a 0 )) − p ( r | a, s ( a, a 0 )) | (147) = k nor maliz e X z O H M M ,a,a 0 (( z , r ) , s ( a, a 0 )) ! − nor maliz e X z b O H M M ,a,a 0 (( z , r ) , s ( a, a 0 )) ! k ∞ (148) ≤ 2( | R | + 1) | Z | O 1 (149) = 4 | Z || R | O (150) A P AC RL Algorithm for Episo dic POMDPs F or the transition estimates, first note X s ( a 0 ,a 00 ) T H M M ,a,a 0 ,a 00 ( s ( a 0 , a 00 ) | s ( a, a 0 )) = X s ( a 0 ,a 00 ) p ( s ( a 0 , a 00 ) | s ( a 0 , a ) , a 0 ) p ( a 00 | a ) (151) = p ( a 00 | a ) (152) = a (153) Then b y the Normalization Lemma | p ( s ( a 0 , a 00 ) | s ( a 0 , a ) , a 0 ) − b p ( s ( a 0 , a 00 ) | s ( a 0 , a ) , a 0 ) | (154) = k nor maliz e ( T H M M ,a,a 0 ,a 00 ( s ( a 0 , a 00 ) i | s ( a, a 0 ) j )) − nor maliz e ( b T H M M ,a,a 0 ,a 00 ( s ( a 0 , a 00 ) i | s ( a, a 0 ) j )) k ∞ (155) ≤ 2( | S | + a ) T 2 a (156) ≤ 4 | S | T 2 a (157) E.4.2 Initial distribution First, consider || T − 1 − b T − 1 || 2 . In order to apply the perturb ed in verse lemma, w e start b e assuming the follo wing condition holds Condition 2. T ≤ 1 2 || T − 1 || 2 (158) Then it follo ws by the p erturb ed inv erse lemma that || b T − 1 − T − 1 || 2 ≤ T || T − 1 || 2 2 1 − || T − 1 || 2 T (159) ≤ 2 T || T − 1 || 2 2 (160) (161) Then (note || · || 2 is Euclidean when the inside is a v ector, and the op erator norm when the inside is a matrix) || T − 1 T − 1 w − b T − 1 b T − 1 b w || 2 (162) ≤ || T − 1 T − 1 w − T − 1 T − 1 b w || 2 + || T − 1 T − 1 b w − b T − 1 b T − 1 b w || 2 (163) ≤ || T − 1 T − 1 || 2 || w − b w || 2 + || T − 1 T − 1 − b T − 1 b T − 1 || 2 || b w || 2 (164) ≤ || T − 1 || 2 2 w + || T − 1 T − 1 − b T − 1 b T − 1 || 2 · 1 (165) then that inner term can b e simplified || T − 1 T − 1 − b T − 1 b T − 1 || 2 (166) ≤ || T − 1 T − 1 − T − 1 b T − 1 || 2 + || T − 1 b T − 1 − b T − 1 b T − 1 || 2 (167) ≤ || T − 1 || 2 || T − 1 − b T − 1 || 2 + || T − 1 − b T − 1 || 2 || b T − 1 || 2 (168) = ( || T − 1 || 2 + || b T − 1 || 2 ) || T − 1 − b T − 1 || 2 (169) ≤ (2 || T − 1 || 2 + || T − 1 − b T − 1 || 2 ) || T − 1 − b T − 1 || 2 (170) ≤ (2 || T − 1 || 2 + 2 T || T − 1 || 2 2 )2 T || T − 1 || 2 2 (171) ≤ (2 || T − 1 || 2 + || T − 1 || 2 )2 T || T − 1 || 2 2 (172) ≤ 6 || T − 1 || 2 T || T − 1 || 2 2 (173) ≤ 6 || T − 1 || 3 2 T (174) Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill Th us plugging that back that inner term results in || T − 1 T − 1 w − b T − 1 b T − 1 b w || 2 ≤ || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T (175) = ⇒ || T − 1 T − 1 w − b T − 1 b T − 1 b w || ∞ ≤ || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T (176) = ⇒ | p ( a 0 , s ( a 0 , a 1 ) , a 1 ) − b p ( a 0 , s ( a 0 , a 1 ) , a 1 ) | ≤ || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T (177) so now the final step is to extract out only the en tries corresp onding to ( a 0 , a 1 ) and normalize (the normalization will b e ov er s ( a 0 , a 1 )). Assuming that the following condition holds Condition 3. ( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T ) ≤ 1 2 | A | 2 | S | (178) then b y the Normalization Lemma | b p ( s ( a 0 , a 1 )) − p ( s ( a 0 , a 1 )) | = b p ( a 0 , s ( a 0 , a 1 ) , a 1 ) b p ( a 0 , a 1 ) − p ( a 0 , s ( a 0 , a 1 ) , a 1 ) p ( a 0 , a 1 ) (179) ≤ 2 | A | 4 ( | S | + 1 | A | 2 )( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T ) (180) ≤ 4 | A | 4 | S | ( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T ) (181) noting that P s ( a 0 ,a 1 ) p ( a 0 , s ( a 0 , a 1 ) , a 1 ) = p ( a 0 , a 1 ) = p ( a 0 ) p ( a 1 ) = 1 | A | 2 (since the first tw o actions are uniformly random). E.5 Lemma 5 and Proof Lemma 5. Given the p ermutation of the states s ( a,a 0 ) ,j = s φ (( a,a 0 ) ,j ) , β -ve ctors and α -ve ctors over the same p olicy π t ar e e quivalent i.e. β π t t ( s ( a,a 0 ) ,j ) = α π t t ( s φ (( a,a 0 ) ,j ) ) (182) Pr o of: Note that we are using the notation a − as just another v ariable for actions, just lik e the notation a . First the base case β a 1 ( s ( a − , a ) j ) = X r p ( r | s ( a − , a ) j , a ) · r (183) = X r p ( r | s φ ( a − ,a,j ) , a ) · r (184) = α a 1 ( s φ ( a − ,a,j ) ) (185) Next is the induction step. The induction hypothesis is that this equiv alence holds for all β -v ectors with t -step p olicies i.e. β π t t ( s ( a − , a ) i ) = α π t t ( s φ ( a − ,a,j ) ) where a is the ro ot action of π t . Also note that f t ( r , z ) is the rest of conditional p olicy π t after executing a and seeing ( r , z ). Then β a,f t t +1 ( s ( a − , a ) j ) (186) = X r,z,s ( a,f t ( r,z )) k p ( r | s ( a − , a ) j , a ) p ( s ( a, f t ( r , z )) k | s ( a − , a ) j , a ) p ( z | s ( a, f t ( r , z )) k , a )( r + γ β f t ( r,z ) ( s ( a, f t ( r , z )) k )) (187) = X r,z,s ( a,f t ( r,z )) k p ( r | s φ ( a − ,a,j ) , a ) p ( s φ ( a,f t ( r,z ) ,k ) | s φ ( a − ,a,j ) , a ) p ( z | s φ ( a,f t ( r,z ) ,k ) , a )( r + γ α f t ( r,z ) ( s φ ( a,f t ( r,z ) ,k ) )) (188) A P AC RL Algorithm for Episo dic POMDPs where w e use the induction hypothesis. In order to simplify further, consider the partial term g ( r , z ) = X s ( a,f t ( r,z )) k p ( r | s φ ( a − ,a,j ) , a ) p ( s φ ( a,f t ( r,z ) ,k ) | s φ ( a − ,a,j ) , a ) p ( z | s φ ( a,f t ( r,z ) ,k ) , a )( r + γ α f t ( r,z ) ( s φ ( a,f t ( r,z ) ,k ) )) (189) Since this is a sum, the order of summation does not matter. In particular, the summation can b e done in the order of the original state s i where i = φ ( a, f t ( r , z ) , k ). g ( r , z ) = X s i p ( r | s φ ( a − ,a,j ) , a ) p ( s i | s φ ( a − ,a,j ) , a ) p ( z | s i , a )( r + γ α f t ( r,z ) ( s i )) (190) Then β a,f t t +1 ( s ( a − , a ) j ) = X r,z g ( r , z ) (191) = X r,z,s i p ( r | s φ ( a − ,a,j ) , a ) p ( s i | s φ ( a − ,a,j ) , a ) p ( z | s i , a )( r + γ α f t ( r,z ) ( s i )) (192) = α a,f t t +1 ( s φ ( a − ,a,j ) ) (193) E.6 Lemma 6 and Proof Lemma 6. Supp ose we have appr oximate POMDP p ar ameters with err ors | b p ( s 0 | s, a ) − p ( s 0 | s, a ) | ≤ T (194) | b p ( z | a, s 0 ) − p ( z | a, s 0 ) | ≤ Z (195) | b p ( r | s, a ) − p ( r | s, a 0 ) | ≤ R (196) then for any t -step c onditional p olicy π t | α π t t ( s ) − b α π t t ( s ) | ≤ t 2 R max ( | R | R + | S | T + | Z | Z ) . (197) Pr o of: First the base case for 1-step p olicies | α a 1 ( s ) − b α a 1 ( s ) | = X r p ( r | s, a ) · r − X r b p ( r | s, a ) · r (198) ≤ X r | ( p ( r | s, a ) − b p ( r | s, a )) · r | (199) ≤ || p ( r | s, a ) − b p ( r | s, a ) || ∞ X r | r | (200) ≤ | R | R max R (201) ≤ R max ( | R | R + | S | T + | Z | Z ) (202) Next the induction step, where V max ( t ) is the upp er b ound on the v alue for t steps, and where the induction Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill h yp othesis is that | α f t ( r,z )( s 0 ) − b α f t ( r,z )( s 0 ) | ≤ t 2 R max ( | R | R + | S | T + | Z | Z ) (also γ = 1) | α a,f t t +1 ( s ) − b α a,f t t +1 ( s ) | (203) = X r,z,s 0 p ( r | s, a ) p ( s 0 | s, a ) p ( z | s 0 , a )( r + γ α f t ( r,z ) ( s 0 )) − X r,z,s 0 b p ( r | s, a ) b p ( s 0 | s, a ) b p ( z | s 0 , a )( r + γ b α f t ( r,z ) ( s 0 )) (204) ≤ X r,z,s 0 | p ( r | s, a ) − b p ( r | s, a ) | p ( s 0 | s, a ) p ( z | s 0 , a )( r + γ α f t ( r,z ) ( s 0 )) (205) + X r,z,s 0 b p ( r | s, a ) | p ( s 0 | s, a ) − b p ( s 0 | s, a ) | p ( z | s 0 , a )( r + γ α f t ( r,z ) ( s 0 )) (206) + X r,z,s 0 b p ( r | s, a ) b p ( s 0 | s, a ) | p ( z | s 0 , a ) − b p ( z | s 0 , a ) | ( r + γ α f t ( r,z ) ( s 0 )) (207) + X r,z,s 0 b p ( r | s, a ) b p ( s 0 | s, a ) b p ( z | s 0 , a ) | ( r + γ α f t ( r,z ) ( s 0 )) − ( r + γ b α f t ( r,z ) ( s 0 )) | (208) ≤ V max ( t + 1) X r | p ( r | s, a ) − b p ( r | s, a ) | X s 0 p ( s 0 | s, a ) X z p ( z | s 0 , a ) (209) + V max ( t + 1) X s 0 | p ( s 0 | s, a ) − b p ( s 0 | s, a ) | X z p ( z | s 0 , a ) X r b p ( r | s, a ) (210) + V max ( t + 1) X r b p ( r | s, a ) X s 0 b p ( s 0 | s, a ) X z | p ( z | s 0 , a ) − b p ( z | s 0 , a ) | (211) + γ X r b p ( r | s, a ) X s 0 b p ( s 0 | s, a ) X z b p ( z | s 0 , a ) | α f t ( r,z ) ( s 0 )) − b α f t ( r,z ) ( s 0 ) | (212) ≤ V max ( t + 1)( | R | R + | S | T + | Z | Z ) + γ ( t 2 R max ( | R | R + | S | T + | Z | Z )) (213) ≤ ( t + 1) R max ( | R | R + | S | T + | Z | Z ) + t 2 R max ( | R | R + | S | T + | Z | Z ) (214) ≤ ( t 2 + t + 1) R max ( | R | R + | S | T + | Z | Z ) (215) ≤ ( t + 1) 2 R max ( | R | R + | S | T + | Z | Z ) (216) E.7 Lemma 7 and Proof Lemma 7. Algorithm 3 finds the p olicy b π which maximizes V b π ( b b ( s 1 )) for a POMDP with p ar ameters b b ( s 1 ) , b p ( z | a, s 0 ) , b p ( r | s, a ) , and b p ( s 0 | s, a ) . Pr o of: The outer lo op builds up the set Γ a − ,a t of beta vectors that take as input s ( a − , a ) with a as the ro ot action. This is true in the base case for Γ a − ,a 1 . F or the induction step, fix ( a − , a . Then f t ( r , z ) is taken from all p ossible mappings from an observ ation pair to β t − 1 ( s ( a, a 0 )) ∈ Γ a,a 0 t − 1 and all possible next actions a 0 . Thu s all p ossible β t ( s ( a − , a )) are computed. The final step is an argmax. Since b p ( s 1 ( a 0 , a 1 )) is just a permutation of b p ( s 1 ), using it will not change the dot pro duct b p ( s 1 ( a 0 , a 1 )) · β H ( s ( a 0 , a 1 )). Th us the argmax is correctly finding the p olicy asso ciated with b V ∗ ( b p ( s 1 )). F Main Theorem Theorem 1. F or POMDPs that satisfy the state d assumptions define d in the pr oblem setting, exe cuting EEPORL wil l achieve an exp e cte d episo dic r ewar d of V ( b 0 ) ≥ V ∗ ( b 0 ) − on al l but a numb er of episo des that is b ounde d by O H 4 V 2 max | A | 12 | R | 4 | Z | 4 | S | 12 1 + q log 3 δ 2 C d,d,d δ 3 2 σ a ( T a ) 6 σ a ( R a ) 8 σ a ( Z a ) 8 2 log 3 δ A P AC RL Algorithm for Episo dic POMDPs with pr ob ability at le ast 1 − δ , wher e C d,d,d ( δ ) = min( C 1 , 2 , 3 ( δ ) , C 1 , 3 , 2 ( δ )) wher e C 1 , 2 , 3 ( δ ) = min min i 6 = j || M 3 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 2 ) 2 || P 1 , 2 , 3 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 3 ) 1 C 1 , 3 , 2 ( δ ) = min min i 6 = j || M 2 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 3 ) 2 || P 1 , 3 , 2 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 2 ) 1 Pr o of: Let the initial b eliefs b, b b and error k b − b b k ∞ ≤ b , and the bound o ver α -v ectors of an y policy π , k α π − b α π k ∞ ≤ α b e given. Let b π be the p olicy returned b y Algorithm 3 i.e the optimal p olicy for b b and b α . Let π ∗ b e the optimal p olicy for b and α . Then b V b π ( b b ) = b b · b α b π (217) ≥ b b · b α π ∗ (218) ≥ b b · α π ∗ − | b b · α π ∗ − b b · b α π ∗ | (219) ≥ b b · α π ∗ − α (220) ≥ b · α π ∗ − | b · α π ∗ − b b · α π ∗ | − α (221) ≥ b · α π ∗ − b V max − α (222) = V ∗ ( b ) − b V max − α (223) where the first inequality is b ecause b π is the optimal p olicy for b b ; the second inequality comes from triangle inequalit y; the third inequality uses Holder’s inequality and the fact that || b b || ∞ ≤ 1; the fourth inequality uses triangle inequalit y again. Next V b π ( b ) = b · α b π (224) ≥ b b · α b π − | b b · α b π − b · α b π | (225) ≥ b b · α b π − b V max (226) ≥ b b · b α b π − | b b · b α b π − b b · α b π | − b V max (227) ≥ b b · b α b π − α − b V max (228) Putting those t wo together results in V b π ( b ) ≥ V ∗ ( b ) − 2 b V max − 2 α (229) Plugging in b and α from lemma 4 and lemma 6 gets us V b π ( b ) ≥ V ∗ ( b ) − 2(4 | A | 4 | S | ( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T )) V max − 2( H 2 R max ( | R | R + | S | T + | Z | Z )) (230) W e kno w || T − 1 || 2 = 2(1 + c | A | )( σ a ( T a )) − 1 and a = c 1+ c | A | from Lemma 1 and the exploration policy lemma. Note that c = O (1 / | A | ) and so a = O (1 / | A | ). Now let’s carefully substitute in quan tities from Lemma 2 and Lemma 4 ( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T ) (231) ≤ || T − 1 || 2 2 (14 | A | 2 | S | 2 . 5 ( σ a ( R a ) σ a ( Z a )) − 4 1 ) (232) + 6 || T − 1 || 3 2 (18 | A || S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 1 ) (233) ≤ 122 || T − 1 || 3 2 | A | 2 | S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 1 (234) ≤ 122(8(1 + c | A | ) 3 ( σ a ( T a ) − 3 ) | A | 2 | S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 1 (235) ≤ O | A | 2 | S | 4 σ a ( T a ) − 3 ( σ a ( R a ) σ a ( Z a )) − 4 1 (236) Zhaohan Daniel Guo, Shay an Doroudi, Emma Brunskill ( | R | R + | S | T + | Z | Z ) (237) ≤ ( | R | (4 | Z || R | O ) + | S | 4 | S | T 2 a + | Z | (4 | Z || R | O )) (238) ≤ | R | (4 | Z || R | 1 ) + | S | 18 · 4 2 a | S || A || S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 1 + | Z | 4 | Z || R | 1 (239) ≤ (18 · 4 + 8) 1 2 a | A || S | 6 | R | 2 | Z | 2 ( σ a ( R a ) σ a ( Z a )) − 4 1 (240) = O | A | 3 | S | 6 | R | 2 | Z | 2 ( σ a ( R a ) σ a ( Z a )) − 4 1 (241) no w putting that back into the b ound V b π ( b ) ≥ V ∗ ( b ) (242) − O V max | A | 6 | S | 5 σ a ( T a ) − 3 ( σ a ( R a ) σ a ( Z a )) − 4 1 (243) − O H 2 R max | A | 4 | S | 6 | R | 2 | Z | 2 ( σ a ( R a ) σ a ( Z a )) − 4 1 (244) − O H 2 V max | A | 5 | R | 2 | Z | 2 | S | 6 ( σ a ( T a )) − 3 ( σ a ( R a ) σ a ( Z a )) − 4 1 (245) no w if w e let that error be equal to i.e. V b π ( b ) ≥ V ∗ ( b ) − , then w e can substitute for 1 in to eqn 74 from Lemma 2 to get the follo wing requirement on N O H 4 V 2 max | A | 12 | R | 4 | Z | 4 | S | 12 ( σ a ( T a )) − 6 ( σ a ( R a ) σ a ( Z a )) − 8 (1 + p log(3 /δ )) 2 ( C d,d,d ( δ / 3)) 2 · 2 log 3 δ ! ≤ N (246) where C d,d,d ( δ ) = min( C 1 , 2 , 3( δ ) , C 1 , 3 , 2 ( δ )) (247) C 1 , 2 , 3 ( δ ) = min min i 6 = j || M 3 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 2 ) 2 || P 1 , 2 , 3 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 3 ) 1 (248) C 1 , 3 , 2 ( δ ) = min min i 6 = j || M 2 ( ~ e i − ~ e j ) || 2 · σ k ( P 1 , 3 ) 2 || P 1 , 3 , 2 || 2 · k 5 · κ ( M 1 ) 4 · δ log( k /δ ) , σ k ( P 1 , 2 ) 1 (249) are the quan tities from MoM from Anandkumar et al. (2012). And that is the final sample complexity b ound (eqn 246). Note that we assume σ a ( R a ) − 1 ≥ 1, σ a ( Z a ) − 1 ≥ 1 and σ a ( T a ) − 1 ≥ 1 or else w e can just replace those quantities by 1 in the b ound. One final thing to do is to give sufficient conditions on N so that the conditions made on all of the 1 , 2 , . . . in the lemmas hold. W e then note that the final sample complexit y b ound is a sufficient condition on N (w e only consider ≤ 1 to b e interesting and don’t consider > 1). F rom Lemma 3, the condition is that O ≤ 1 3 | R || Z | . This translates into 1 ≤ 1 3 | R || Z | (250) ⇐ = O | A | 2 | Z | 2 | R | 2 (1 + p log(3 /δ )) 2 ( C d,d,d ( δ / 3)) 2 log 3 δ ! ≤ N (251) where the first inequalit y is due to 1 = O from Lemma 2; the second inequalit y is from substituting the first inequalit y into eqn 74 from Lemma 2. The se cond inequalit y condition is already satisfied by the final bound (eqn 246). Next up is the condition (eqn 95) made during the pro of of Lemma 2 where 1 ≤ 1 6 | A || S | 1 . 5 ( σ a ( R a ) σ a ( Z a )) − 4 (252) ⇐ = O | A | 4 | S | 3 | Z || R | ( σ a ( R a ) σ a ( Z a )) − 8 (1 + p log(3 /δ )) 2 ( C d,d,d ( δ / 3)) 2 log 3 δ ! ≤ N (253) A P AC RL Algorithm for Episo dic POMDPs where the second inequalit y is obtrained from substituting the first inequality in to eqn 74. The second inquality is also already satisfied b y the final b ound. Then the condition made during the pro of of Lemma 4 (eqn 158) is T ≤ 1 2 || T − 1 || 2 (254) ⇐ = 1 ≤ 1 36 | A || S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 ( 2(1+ c | A | ) σ a ( T a ) ) (255) ⇐ = 1 ≤ O 1 | A || S | 4 ( σ a ( R a ) σ a ( Z a )) − 4 ( σ a ( T a )) − 1 (256) ⇐ = O | A | 4 | S | 8 | Z || R | ( σ a ( R a ) σ a ( Z a )) − 8 ( σ a ( T a )) − 2 (1 + p log(3 /δ )) 2 ( C d,d,d ( δ / 3)) 2 log 3 δ ! ≤ N (257) where the second inequality comes from substituting the v alue for || T − 1 || 2 from Lemma 1, and then using the relationship betw een 1 and T from Lemma 2. The fourth inequality is from eqn 74 and is also satisfied by the final b ound. Finally the second condition from the pro of of Lemma 4 (eqn 178) is ( || T − 1 || 2 2 w + 6 || T − 1 || 3 2 T ) ≤ 1 2 | A | 2 | S | (258) ⇐ = 1 ≤ O 1 | A | 4 | S | 5 σ a ( T a ) − 3 ( σ a ( R a ) σ a ( Z a )) − 4 (259) ⇐ = O | A | 10 | S | 10 | Z || R | σ a ( T a ) − 6 ( σ a ( R a ) σ a ( Z a )) − 8 (1 + p log(3 /δ )) 2 ( C d,d,d ( δ / 3)) 2 log 3 δ ! ≤ N (260) where the second inequality comes from using eqn 236. The third inequality is from eqn 74 and is also satisfied b y the final b ound. Thus, the given final sample complexity b ound is sufficient.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment