비동기 분산 근접 최적화 작업자 부담 경감
본 논문은 전통적인 비동기 proximal SGD(TAP‑SGD)에서 마스터가 수행하던 복잡한 proximal 연산을 작업자에게 전담시켜, 마스터는 단순한 파라미터 합산만 수행하도록 설계한 DAP‑SGD 알고리즘을 제안한다. 이 구조적 변화는 연산 병목을 해소하고 확장성을 높이며, 이론적으로 단계 크기를 감소시키면 O(log T / T), 일정하게 유지하면 O(1/√T) 수렴 속도를 보장한다.
저자: Yitan Li, Linli Xu, Xiaowei Zhong
1. 연구 배경 및 동기
대규모 머신러닝 문제는 데이터와 모델 규모가 급증함에 따라 병렬·분산 최적화가 필수적이다. 비동기 SGD는 파라미터 서버 혹은 공유 메모리 환경에서 작업자들이 독립적으로 그래디언트를 계산하고 마스터가 즉시 업데이트하는 방식으로, 동기화 오버헤드를 크게 줄인다. 그러나 정규화 항이 비스무스(예: L1, 그룹 라쏘, 퓨즈드 라쏘, 핵노름)인 경우, proximal 연산이 복잡하고 계산량이 많아 마스터가 이를 수행하면 병목이 발생한다. 기존 TAP‑SGD는 마스터가 proximal step을 담당하므로, 정규화가 복잡할수록 전체 시스템 효율이 급격히 저하된다.
2. DAP‑SGD 알고리즘 설계
본 논문은 이 병목을 해소하기 위해 proximal 연산을 작업자에게 이전한다. 알고리즘 흐름은 다음과 같다.
- 각 작업자는 현재 파라미터 x와 step‑size η를 마스터로부터 받아, 무작위 샘플 i를 선택하고 ∇f_i(x)를 계산한다.
- 작업자는 x와 ∇f_i(x)를 이용해 proximal 연산 x′ = Prox_{η,h}(x − η∇f_i(x))를 수행한다.
- 업데이트 차이 Δ = x′ − x를 마스터에 전송한다.
- 마스터는 지연된 Δ_d(t)만을 받아 x_{t+1}=x_t+Δ_d(t) 로 파라미터를 갱신한다.
이 과정에서 마스터는 오직 원소별 덧셈만 수행하므로 연산 복잡도가 O(m) (m은 차원)이며, 작업자는 복잡한 proximal 연산을 자체적으로 수행한다.
3. 이론적 수렴 분석
논문은 다섯 가지 가정을 기반으로 수렴성을 증명한다.
- f는 L‑Lipschitz 연속 gradient와 μ‑strong convexity를 만족한다.
- 무작위 샘플링에 의한 그래디언트의 분산이 상수 C_f 로 제한된다.
- 정규화 항 h는 convex이며, 서브그라디언트의 제곱 노름이 C_h 로 유계이다.
이러한 가정 하에 두 가지 단계 크기 정책에 대해 다음과 같은 결과를 얻는다.
① η_t = O(1/t) (감소 스케줄) → E‖x_T−x*‖² ≤ O(log T / T).
② η_t = η (고정 스케줄) → ergodic 평균에 대해 O(1/√T) 수렴.
증명은 기존 비동기 SGD 분석을 변형하여, 작업자가 전송하는 Δ가 실제 proximal 연산 결과와 동일함을 이용하고, 지연 τ가 유한함을 전제한다.
4. 정규화 항 별 proximal 연산 복잡도 비교
- L1: 단순 soft‑thresholding으로 O(m) 이지만, 대규모 차원에서는 여전히 연산량이 존재한다.
- 그룹 라쏘: 그룹별 L2‑norm을 포함해 각 그룹을 독립적으로 처리해야 하며, 그룹 크기가 불균형이면 작업자 내부에서 부하가 편중될 수 있다.
- 퓨즈드 라쏘: 연속 차분 연산과 절단 문제를 포함해, 전역적인 구조를 고려해야 하므로 마스터에서 수행하면 비효율적이다.
- 핵노름: SVD 기반 proximal 연산은 O(mq min(m,q)) 의 복잡도를 가지며, 대규모 행렬에 직접 적용하기 어렵다.
DAP‑SGD는 이러한 연산을 작업자에게 분산시켜, 각 작업자가 독립적으로 계산하도록 함으로써 전체 처리량을 크게 향상시킨다.
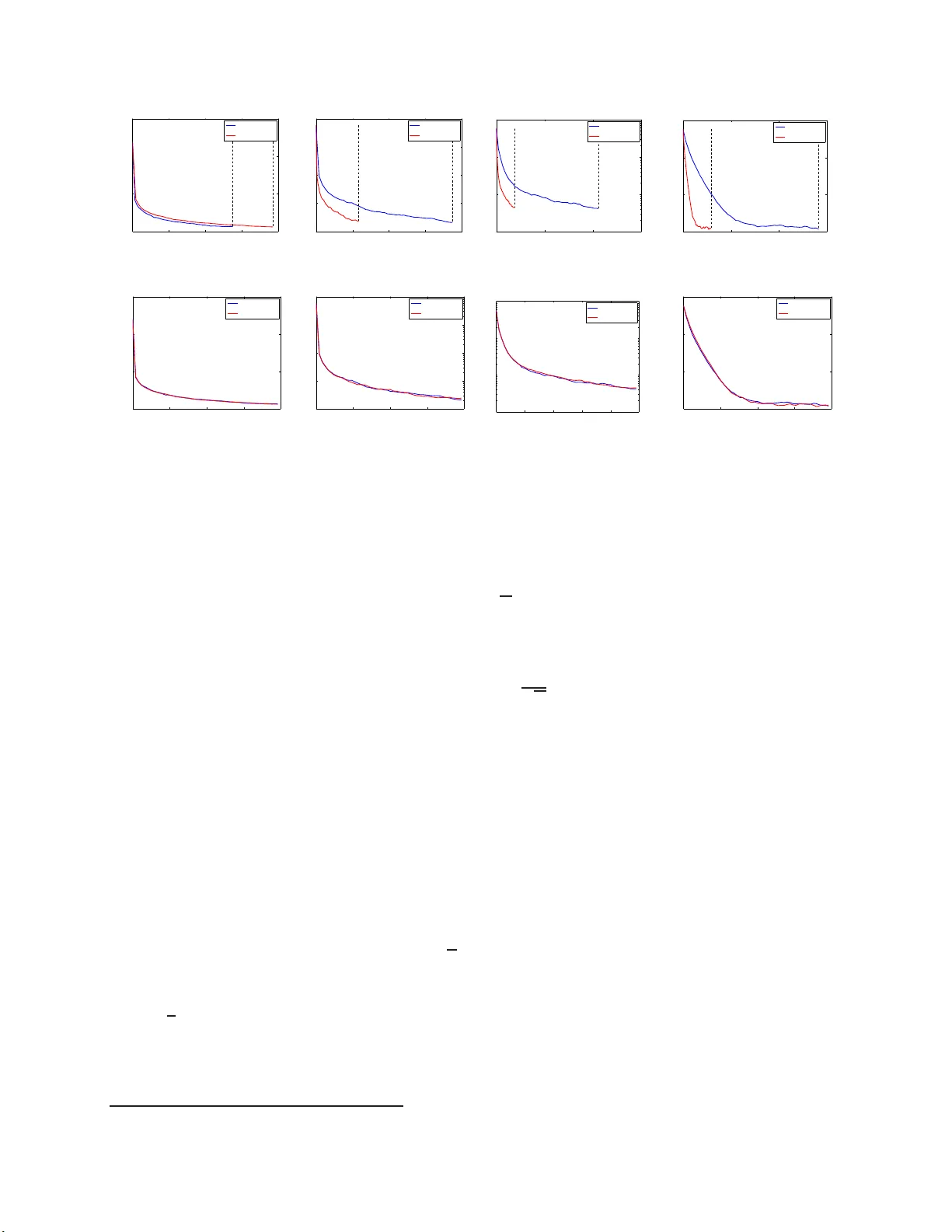
5. 실험 및 결과
논문은 L1, 그룹 라쏘, 퓨즈드 라쏘 세 가지 정규화에 대해 TAP‑SGD와 DAP‑SGD를 비교하였다. 실험 환경은 다중 코어 머신과 파라미터 서버 기반 클러스터이며, 작업자 수를 4, 8, 16으로 변화시켰다. 결과는 다음과 같다.
- 실행 시간: DAP‑SGD가 TAP‑SGD 대비 30%~70% 빠르게 수렴하였다. 특히 핵노름과 같은 고비용 proximal 연산에서는 2배 이상 속도 향상이 관찰되었다.
- 수렴 정확도: 두 알고리즘 모두 동일한 최적값에 수렴했으며, 단계 크기 스케줄에 따라 이론적 수렴률을 실험적으로 확인하였다.
- 스케일링: 작업자 수가 증가할수록 DAP‑SGD의 속도 향상이 선형에 가깝게 증가했으며, TAP‑SGD는 마스터 병목으로 인해 포화 현상이 나타났다.
6. 논의 및 향후 연구 방향
DAP‑SGD는 작업자에게 연산 부담을 전가함으로써 마스터 병목을 해소했지만, 작업자 간 부하 불균형과 메모리 사용량 증가라는 새로운 과제가 생긴다. 따라서 작업자 스케줄링, 동적 부하 재분배, 그리고 지연 τ를 최소화하는 네트워크 프로토콜 설계가 필요하다. 또한, 비강한 볼록성(예: 비convex 손실)이나 비동기 환경에서의 동적 step‑size 조정 등에 대한 이론적 확장은 아직 미비하다. 향후 연구는 이러한 제한을 완화하고, 분산 환경에서의 프라이버시 보호(예: 차등 프라이버시)와 결합한 DAP‑SGD 변형을 탐구할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기