Make Workers Work Harder: Decoupled Asynchronous Proximal Stochastic Gradient Descent
Asynchronous parallel optimization algorithms for solving large-scale machine learning problems have drawn significant attention from academia to industry recently. This paper proposes a novel algorithm, decoupled asynchronous proximal stochastic gra…
Authors: Yitan Li, Linli Xu, Xiaowei Zhong
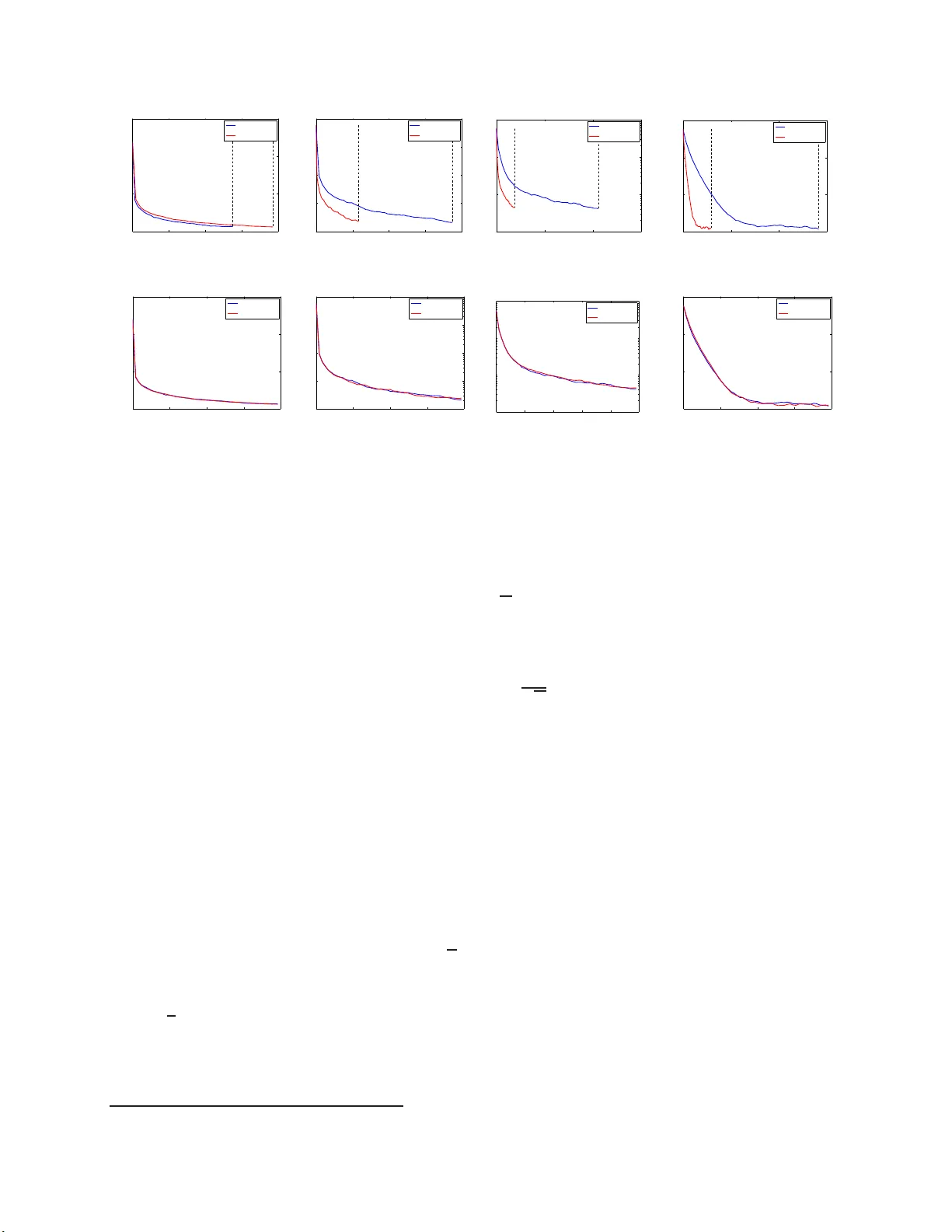
Mak e W ork ers W ork Har de r: Decoupled Async hronous Pro ximal Sto c hastic Gradien t Descen t Yitan Li, Linli Xu, Xiao we i Zhong, Qing Ling Univ ersit y of Scienc e and T ec hnology of China etali@mail.ustc.edu .cn, linlixu@ustc.edu .cn, {xwzhong,qingling}@mail.ustc.edu.c n Ma y 2 4, 2016 Abstract Asynchronous parallel optimization algorithms for solving large-scale mac h in e learning p roblems ha ve draw n significan t attention from academia t o industry recentl y . This pap er prop oses a n o vel algorithm, decoupled asynchronous pro ximal sto chastic gradien t d escen t (DAP-SGD), to minimize an ob jectiv e func- tion that is the composite of th e av erage of multiple empirical losses and a regularization term. Un like the traditional asynchronous pro x imal sto chas tic gradien t descent (T AP-SGD) in which the master car- ries muc h of the computation load, the prop osed algorithm off-loads the ma jority of computation tasks from th e master to w orkers, and leav es the master to conduct simple addition op erations. This strategy yields an eas y -to-parallelize algorithm, whose p erformance is justified by theoretical conver gence analyses. T o b e sp ecific, DAP-SGD achiev es an O (log T /T ) rate when the step-size is diminishing and an ergodic O (1 / √ T ) rate when the step-size is constan t, where T is the num b er of total iterations. 1 In tro duction A ma jority of classical mac hine learning tasks can b e form ulated as solving a general r e g ularized optimizatio n problem: min x ∈ R m P ( x ) = f ( x ) + h ( x ) , where f ( x ) , 1 n n X i =1 f i ( x ) . (1) Given n samples, f i ( x ) r epresents the empirical loss of the i th sample with regard to the decision v ariable x , and h ( x ) co rresp onds to a (usua lly non-smoo th) r egulariza tion term. Our goal is to find the optimal solution, defined as x ∗ , which minimizes the summation of the av erag ed empirica l loss and the regula r ization term ov er the whole dataset. With the enormous growth of data s ize n and mo del complexity , asynchronous parallel algorithms [1, 2 , 3, 4, 5, 6] hav e b eco me an imp or tant to ol and rece ived significant success e s for solving large scale ma chine learning problems in the form of (1). Async hrono us para llel algorithms distribute computation on multi- core systems (shared memor y architecture) or multi-machine sy stem (parameter server a rchitecture), whose computation p ow er generally scales up with the increasing num b er of cores or machines. As a consequence, effectiv e design and implementation of asynchronous para llel alg orithms is critical for la rge scale machine learning. Numerous effo r ts have been dev oted to this topic. Among them, asynchronous sto chastic gradient descent is pro po sed in [1, 2], and its per formance is guara nt ee d by theoretical con vergence analyses . An asynchronous proximal gradient descent algorithm is desig ned on the para meter server architecture in [3] with a distributed optimization so ft ware pr ovided. Convergence r ate of asynchronous sto chastic gr a dient descent with a non- conv ex ob jectiv e is analyzed in [4]. Apart from work on asynchronous gra dient descent and its proximal 1 v ariant, muc h atten tion has also b een attracted to asy nchronous alternating direction metho d of m ultipli- ers (ADMM) [5], a synchronous sto chastic co ordinate ascent [7, 8, 9, 10, 11, 12] and as ynchronous d ua l sto chastic co ordina te ascent [13]. The tra ditional asy nchronous proximal sto chastic gradient method (T AP-SGD) that solves (1) works as follows. The workers (multiple cores or machines) access samples, co mpute the gra dients of their corres p o nd- ing empirical losses , and send to the ma ster. The master fuses the g radients and runs a proximal step on the regular ization term (more details are given in Section 2). How ever, the p erformance o f this paradigm is restricted when the proximal op era tor is not an element-wise op eratio n. F or this ca se, running pr oximal steps can be time-consuming, and the c o mputation in the master bec o mes the b o ttleneck of the whole system. W e note that this is co mmon for many p opular re g ularization ter ms, as s hown in Section 2. T o av oid this difficult y , one has to design a customized para llel computation for every s ingle reg ularization term, which makes the framework inflexible. F o r the sake of sp eeding up computation and simplifying algorithm desig n, we exp ect to design an alter native algo rithm that is easier to parallelize. In light of this issue, this pa p er develops a deco upled asynchronous pr oximal sto chastic gradient descent (D AP-SGD), which off-lo ads the ma jority of computation tasks (esp ecially the proximal steps) from the master to work er s, a nd leaves the master to co nduct simple addition op era tions. This algorithmic framework is suitable for man y master/worker architectures including the single machine multi-core system (shared memory architect ur e) wher e the master is the parameter updating thread and the w or kers corresp o nd to other threads pro cess ing samples, and the multi-mac hine sys tem (parameter server architecture) where the master is the central mac hine for storing and up da ting para meters and the workers represent those mac hines for storing and pro cessing samples. The main contributions o f this pap e r are highlighted a s follows: • The prop osed DAP-SGD a lgorithm off-loa ds the co mputation b ottleneck from the master to workers. T o b e more sp ecific, DAP-SGD allows work er s to ev aluate the proximal o p e rators (work harder) and the master only needs to do element-wise addition ope r ations, which is easy to parallelize. • Co nv ergence analysis is provided for D AP-SGD. DAP-SGD ac hieves an O (log T /T ) rate when the step- size is diminishing and an ergo dic O (1 / √ T ) rate when the step-size is constant, where T is the num b er of total iterations. 2 T raditional Async hronous Pro ximal Sto c hasti c Gradien t Descen t (T AP-SGD) W e start from the synchronous proximal sto chastic gra dient descen t (P-SGD) algor ithm that solves (1). P- SGD only requires the gra dient o f one sample in a single iteration. Hence in large scale optimization problems, it is a prefer red surro gate for pr oximal gra dient descent [14, 15], which requires co mputing gra dient s of all samples in a single iteration. The recurs ion o f P-SGD is x t +1 = Pro x η t ,h ( x t − η t ▽ f i t ( x t )) , (2) where Pro x η, h ( x ) = arg min y k y − x k 2 2 / (2 η ) + h ( y ) denotes a pr oximal ope r ator, while η t is the step-size and i t is the index of the s e le c ted sa mple in the t th iteration. The traditional asynchronous proximal stochastic g radient d es cent (T AP -SGD) a lgorithm is an asyn- chronous v aria nt of P-SGD, as summarized in Algorithm 1 . The master is the main updating processo r, while the workers provide the gradients of the s amples. Every worker r eceives the parameter (namely , de- cision v ariables) x from the master , computes the gr adient of one random sample ▽ f i ( x ) and sends it to the master. Obviously , when o ne worker is computing and sending its g radient, the master may update the parameter using the g radients s ent by the other w orkers in t he previous time p erio d. As a conseq uence, the g radients received at the master ar e o ften delayed, ca using th e main diff er ence b etw een P-SGD and T AP-SGD. In the master, the delayed gradient received at the t th iteration is denoted by ▽ f i t ( x d ( t ) ) where i t indexes the s elected sample, x d ( t ) refers to that the pa rameter is the one from the d ( t ) th iteration, and d ( t ) ∈ [ t − τ , t ] where τ stands for the maximum delay of the system. Therefore, we can write the recurs ion 2 of T AP-SGD as x t +1 = Prox η t ,h ( x t − η t ▽ f i t ( x d ( t ) )) . (3) Algorithm 1: Asynchronous Proximal Stochastic Gradient Descent (AP-SGD) Input : Initialization x 0 , t = 0 , dataset with n samples in which the lo ss function of the i th sample is denoted by f i ( x ) , regulariza tion term h ( x ) , maximum nu mber o f iterations T , num b er of work ers S , step-size in the t th iteration η t , maxim um delay τ Output : x T Pro cedure of eac h work er s ∈ [1 , ..., S ] 1 rep eat 2 Uniformly sample i from [1 , ..., n ] ; 3 Obtain the parameter x from the master (sha red memory or parameter server); 4 Ev aluate the gradient of the i th sample ov er parameter x , denoted by ▽ f i ( x ) ; 5 Send ▽ f i ( x ) to the master; 6 until pr o c e dur e of master ends Pro cedure of master 1 for t = 0 t o T − 1 do 2 Get a gradient ▽ f i t ( x d ( t ) ) (the delay t − d ( t ) is bounded b y τ ); 3 Update the parameter with the proximal o p erator x t +1 = Prox η t ,h ( x t − η t ▽ f i t ( x d ( t ) )) ; 4 t = t + 1 ; Observe that the up dating pr o cedure of the master is the computationa l bottleneck of the T AP-SGD algorithm. When the proximal step is time-consuming to calculate, the workers must wait for a lo ng time to receive up dated parameters, which significantly degra des the per formance of the system. T o a void this difficult y , one has to design a customized para llel computation for every s ingle reg ularization term, which makes the framework inflexible. In a m ulti-machine system with multiple masters, suc h para llelize d proximal op erators will also cause complicated netw ork communications betw een masters. Coupled Pro ximal Op erators In practice, many widely used (usually non-smo oth) r egulariza tion terms a re as so ciated with co upled proximal op erators , which lead to high computational co mplexity , including gro up la sso regulariza tion [16], fused la sso regulariza tion [17], nuclear no rm regular ization [18, 1 9], etc. The proximal op erator of group l asso regul arization h ( x ) = λ P g i =1 k x k i :( k i +1 − 1) k 2 : Prox η, h ( x ) = a r gmin y 1 2 η k y − x k 2 2 + λ g X i =1 k y k i :( k i +1 − 1) k 2 . (4) Here g is the num b er o f groups and k 1 = 1 < ... k i < k i +1 ... < k g +1 = m + 1 . The clo sed-form solution of the proximal op er a tor a bove is [ Prox η, h ( x )] k i :( k i +1 − 1) = x k i :( k i +1 − 1) 1 − λ k x k i :( k i +1 − 1) k 2 + . (5) F or the gro up lasso regula rization, the proximal o p er ator (4) is separated into g groups. When partitions of groups are unbalanced, it will be har d to sp eed up the computa tio n with para llelization. The proximal op erator of si mplified fus ed lass o regul arization h ( x ) = λ P m − 1 i =1 k x i − x i +1 k 1 : Prox η, h ( x ) = arg min y 1 2 η k y − x k 2 2 + λ m − 1 X i =1 k y i − y i +1 k 1 = y − R T z ∗ , (6) 3 where R = 1 − 1 0 ... 0 0 1 − 1 ... 0 ... 0 ... 0 1 − 1 ∈ R ( m − 1) × m , z ∗ = arg min k z k ∞ ≤ ηλ 1 2 k R T z k 2 2 − < R T z , y > . F or the simplified fused lasso regulariza tio n, the proximal op er ator (6) has a closed form s o lution. Ho wev er, solving z ∗ in volves a subproblem that is time-cons uming . The proximal op erator of nuclear norm regularization h ( X ) = λ k X k ∗ : Prox η, h ( X ) = a rgmin Y 1 2 η k Y − X k 2 F + λ k Y k ∗ = U ˆ ΣV T , (7) where X = UΣV T calculated from singular v a lue decompo sition, σ i is the i th singular v alue of X , ˆ σ i = max( σ i − η λ, 0 ) is the i th element of ˆ σ ) , and ˆ Σ = Diag ( ˆ σ ) . F o r the nuclear norm regula rization, the pr oximal op erator (7) inv olves singular v alue decomp osition, which is c halleng ing esp ecially for la r ge scale problems. As discussed ab ov e, ev aluating the proximal operato r can b e a co mputational b ottleneck and limits the p erforma nce of T AP - SGD. This motiv ates us to desig n a novel asy nchronous para llel algor ithm, which decouples and distributes the calculation of the pr oximal op era tor to the work er s. 3 Decoupled Asy nc hronous Pro ximal Sto c hastic Gradien t Descen t (D AP-SGD) The key idea of the decoupled as y nchronous proximal sto chastic gra dient descent (D AP-SGD) a lgorithm is to off-lo ad the computationa l b ottleneck from the master to the work er s. The ma ster no longer takes ca r e of the proximal op erators ; instea d, it o nly needs to conduct elemen t-wis e addition o p er ations. On the other hand, the work ers must work harder: they ev aluate the pr oximal op era tors independently , without caring ab out the parallel mechanism. The pro cedure o f D AP-SGD is summarized in Algorithm 2. Each w or ker ev aluates the proximal ope r ator and sends up date information (namely , innov ation) ∆ = x ′ − x to the master. In the ma ster, the delay ed upda te information ∆ d ( t ) = x ′ d ( t ) − x d ( t ) is used to mo dify the para meter x . Obviously , parameter up dating in the master is no longer the co mputational b ottleneck of the s ystem, since it only inv olves element-wise addition op erations. The recursio n o f D AP-SGD is x ′ d ( t ) = Pro x η, h ( x d ( t ) − η d ( t ) ▽ f i d ( t ) ( x d ( t ) )) , x t +1 = x t + x ′ d ( t ) − x d ( t ) . (8) Comparing the recursio ns of T AP-SGD (3) and D AP-SGD (8), w e can obser ve that the DAP-SGD r ecur- sion (8) splits the proximal op er ator and para meter up dating step 1 . This is the why we call the propos ed algorithm “ decoupled ”. The benefit of deco upling is that the computational bo ttleneck (for example, the un ba lanced partitioned gro ups in (4), the s ubproblem in (6), and the singular v alue decomp osition in (7)) no longer lies in the master. The work er s c o nduct these op era tions, which improv es the p erfor mance of the system. Below, w e further analyze the co nv ergence prop erties of DA P-SGD theoretically . 4 Con v ergence Analysis This section g ives theor e ms that establish the conv ergence prop erties o f D AP-SGD. The detailed pr o ofs ar e presented in the app endix. W e s ta rt from some basic assumptions. The first tw o assumptions ar e ab out the pr op erties of the av er aged empirical cos t f ( x ) . 1 Note that both T AP-SGD and DAP-SGD can support m ini-batch updating. 4 Algorithm 2: Decoupled Asynchronous Proximal Stochastic Gradient Descent (D AP-SGD) Input : Initialization x 0 , t = 0 , dataset with n samples in which loss function of the i th sample is denoted by f i ( x ) , regulariza tion term h ( x ) , maximum nu mber o f iterations T , num b er of work ers S , step-size in the t th iteration η t , maxim um delay τ Output : x T Pro cedure of eac h work er s ∈ [1 , ..., S ] 1 rep eat 2 Uniformly sample i from [1 , ..., n ] ; 3 Obtain parameter x and step-size η fro m master (shared memory or pa rameter server); 4 Ev aluate the gradient of the i th sample ov er parameter x , denoted by ▽ f i ( x ) ; 5 Ev aluate the proximal op er ator x ′ = Pro x η, h ( x − η ▽ f i ( x )) ; 6 Send up da te information ∆ = x ′ − x to the master; 7 until pr o c e dur e of master end Pro cedure of master 1 for t = 0 t o T − 1 do 2 Get ∆ d ( t ) = x ′ d ( t ) − x d ( t ) from one work er (the delay t − d ( t ) is bo unded by τ ); 3 Update parameter with x t +1 = x t + ∆ d ( t ) ; 4 t = t + 1 ; Assumption 1 Lipschitz c ontinuous gr adient of ▽ f ( x ) : The fun ction f ( x ) is d iffer entiable and its gr adient ▽ f ( x ) is L ipschitz c ontinuous with c onstant L . Namely, the fol lowing two e quivalent ine qualities hold: f ( x ) ≤ f ( y ) + h ▽ f ( y ) , x − y i + L 2 k x − y k 2 2 , ∀ x , y , (9) and 1 L k ▽ f ( x ) − ▽ f ( y ) k 2 ≤ h ▽ f ( x ) − ▽ f ( y ) , x − y i ≤ L k x − y k 2 , ∀ x , y . (10) Assumption 2 Str ong c onvexity of f ( x ) : T he funct ion f ( x ) is str ongly c onvex with c onstant µ . Namel y, the fol lo wing ine quali t y holds: f ( x ) ≥ f ( y ) + h ▽ f ( y ) , x − y i + µ 2 k x − y k 2 2 , ∀ x , y . (11) The next assumption b ounds the v a riance of sa mpling a ra ndom gradient ▽ f i ( x ) to r eplace the t r ue gradient ▽ f ( x ) . Assumption 3 Bounde d vari anc e of gr adient evaluation : The varianc e of a sele cte d gr adient is b ounde d by a c onstant C f : E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f , ∀ x . (12) The last tw o assumptions are ab out the pro p er ties of the regular ization term h ( x ) . Assumption 4 Convexity of h ( x ) : The fun ction h ( x ) is c onvex. Namely, t he fol low ing ine quality holds: h ( x ) ≥ h ( y ) + h ∂ h ( y ) , x − y i , ∀ x , y , (13) where ∂ h ( x ) stands for any subgr a dient of h ( x ) . Assumption 5 Bounde d sub gr adient of h ( x ) : The squar e d sub gr adient of h ( x ) is b ounde d by a c onstant C h k ∂ h ( x ) k 2 2 ≤ C h . (14) 5 An immediate result from Assumption 5 is that, ▽ f ( x ∗ ) is also bounded where x ∗ is the optimal solution to (1), as given in the following corolla ry . Corollary 1 Bounde d gr adient of f ( x ) at the optimum : L et x ∗ = a rgmin x f ( x ) + h ( x ) b e the optimal solution to (1) , then we have k ▽ f ( x ∗ ) k 2 2 = k ∂ h ( x ∗ ) k 2 2 ≤ C h . (15) Assumptions 1, 2, 3 a nd 4 are common in the con vergence analysis of sto chastic g r adient des cent algo- rithms [1, 3, 4, 20, 21]. Assumption 5 is du e to the (usually non-s mo oth) regularizatio n ter m h ( x ) , a nd is rea sonable for many non-smo o th regular ization terms such as L 1 regulariza tion, group la sso, fused lasso and nuclear nor m, etc. Next we provide the constan t upp er bounds of s ubgradients for these non-smo oth regulariza tion ter ms. In the following part, ∂ d eno tes the set of sub der iv atives, and with a slig ht abuse o f notation, also denotes any element (namely , subgradient) i n the set. Upp er b ound of subgradien t for L 1 regularization k x k 1 : k ∂ k x k 1 k 2 ≤ m . (16) Upp er b ound of subgradien t for group lass o regularization P g i =1 k x k i :( k i +1 − 1) k 2 : ∂ g X i =1 k x k i :( k i +1 − 1) k 2 ≤ g , where ∂ k x k i :( k i +1 − 1) k 2 = ( 1 k x k i :( k i +1 − 1) k x k i :( k i +1 − 1) if x k i :( k i +1 − 1) 6 = 0 , { g |k g k 2 ≤ 1 } if x k i :( k i +1 − 1) = 0 . (17) Upp er b ound of subgradient for simpl ified fused lasso regularization P m − 1 i =1 k x i − x i +1 k 1 = k Rx k 1 : k ∂ k Rx k 2 k 2 = k R T S GN ( Rx ) k 2 ≤ X i k R : ,i k 2 k S GN ( Rx ) k 2 ≤ ( m − 1 ) X i k R : ,i k 2 ≤ √ 2 m ( m − 1) , (18) where S GN [17] is a function whose output is w ithin [ − 1 , 1] . Upp er b ound of subgradien t of nuclear norm regularization k X k ∗ , X ∈ R m × q , d = min ( m, q ) : k ∂ k X k ∗ k F ≤ k UV T k F + k W k F ≤ k U k F k V T k F + k W k F ≤ rank( X ) 2 + d ≤ d 2 + d , (19) where ∂ k X k ∗ = { UV T + W | W ∈ R m × q , U T W = 0 , WV = 0 , k W k 2 ≤ 1 , X = UΣV T } . Under the assumptions g iven ab ov e, we prov e that D AP-SGD ac hieves an O (log T / T ) rate when the step-size is diminishing (Theorem 1) and an ergo dic O (1 / √ T ) rate when the step-size is co nstant (Theorem 2), where T is the num b er of total iterations. The pr o ofs of the theorems ar e g iven in the a ppe ndix. Theorem 1 Supp ose that the c ost function of (1) satisfies the fol lo wing c onditions: f ( x ) is str ongly c onvex with c onstant µ and h ( x ) is c onvex; f ( x ) is differ entiable and ▽ f ( x ) is Lipsc hitz c ontinuous with c onstant L ; E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f ; k ∂ h ( x ) k 2 2 ≤ C h . D efi ne the optimal solution of (1) as x ∗ . At time t , set t he step-size of the DAP-SGD r e cursion (8) as η t = O (1 /t ) . Then the iter ate gener ate d by (8) at time T , denote d by x T , satisfies E k x T − x ∗ k 2 2 ≤ O log T T . (20) Theorem 2 Supp ose that the c ost function of (1) satisfies the fol lo wing c onditions: f ( x ) is str ongly c onvex with c onstant µ and h ( x ) is c onvex; f ( x ) is differ entiable and ▽ f ( x ) is Lipsc hitz c ontinuous with c onstant L ; E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f ; k ∂ h ( x ) k 2 2 ≤ C h . Define the optimal solution of (1) as x ∗ . At time t , fix the 6 0 10 20 30 40 10 −2 10 0 10 2 10 4 seconds TAP−SGD DAP−SGD (a) L 1 0 20 40 60 80 10 −1 10 0 10 1 10 2 10 3 seconds TAP−SGD DAP−SGD (b) group lasso 0 500 1000 1500 10 0 10 1 10 2 10 3 seconds TAP−SGD DAP−SGD (c) fused lasso 0 200 400 600 10 −2 10 0 10 2 10 4 seconds TAP−SGD DAP−SGD (d) n uclear norm 0 0.5 1 1.5 2 x 10 5 10 −2 10 0 10 2 10 4 iter TAP−SGD DAP−SGD (e) L 1 0 0.5 1 1.5 2 x 10 5 10 −1 10 0 10 1 10 2 10 3 iter TAP−SGD DAP−SGD (f ) group lasso 0 2000 4000 6000 8000 10000 10 0 10 1 10 2 10 3 iter TAP−SGD DAP−SGD (g) fused lasso 0 0.5 1 1.5 2 x 10 4 10 −2 10 0 10 2 10 4 iter TAP−SGD DAP−SGD (h) n uclear norm Figure 1: Compariso n of T AP-SGD and DA P-SGD in terms of time and num b e r of itera tions. The Y-axis shows the log distance b etw een the solution g enerated by an algorithm and the optimal s olution, denoted by log k x − x ∗ k 2 2 . Results o f L 1 , gr oup lasso, simplified fused lasso a nd n uclea r norm r e gularized ob jectiv es are shown in columns from left to r ig ht, re sp ectively . T op and b o ttom rows corresp ond to the results r egarding time and nu mber o f iterations, resp ectively . step-size of the DAP-SGD r e cursion (8) η t as η = O (1 / √ T ) , wher e T is the maximum numb er of iter ations. Define the iter ate gener ate d by (8) at time t as x t . Then the running aver age iter ate gener ate d by (8) at time T , denote d by ¯ x T = P T t =0 x t / ( T + 1) , satisfies E k ¯ x T − x ∗ k 2 2 ≤ O 1 √ T . (21) 5 Exp erime n ts W e compar e the pr o p osed DAP-SGD algor ithm with T AP -SGD in a c onsistent wa y without assuming the data is sparse. The implementation is based on the single machine multi-core system (shar ed memory architecture). Both algorithms are implement ed in C++ a nd run on a mul ti-co re server. Singular v alue decomp osition (SVD) is calculated by eig en3 2 . The para meters are lo ck ed while they are being upda ted. The lock o p er ation will slow down the computation; howev er it guara nt ee s that the implementation conforms to the algor ithm and its corre s po nding con vergence a nalysis. Without loss of genera lit y , we choose the least squa re loss with a non-smo o th regularizatio n term as the optimization ob jectiv e: min x ∈ R m P ( x ) = f ( x ) + h ( x ) = 1 n n X i =1 k x T s i − y i k 2 2 + λ k x k 2 2 + h ( x ) . (22) In the case of n uclea r norm re g ularization, the loss function f ( x ) b ecomes the multi-target least squa re loss f ( X ) = 1 n P n i =1 k X T s i − y i k 2 2 + λ k X k 2 F corresp o ndingly . In the implementation T AP-SGD, the proximal ope rator of the L 1 regularize d ob jectiv e c a n b e para llelized easily , while the pr oximal op e r ators of group lasso , simplified fused lasso and nuclear no r m a re not parallelized due to their coupled and non-element-wise op e r ations. O n the other hand, the pro cedure of the master in the prop o sed D AP-SGD only inv olves simple element-wise op e rations. 2 eigen.tuxfamily . org 7 0 1 2 3 4 5 6 7 8 9 0 2 4 6 8 number of workers speed up TAP−SGD DAP−SGD (a) L 1 0 1 2 3 4 5 6 7 8 9 0 2 4 6 8 number of workers speed up TAP−SGD DAP−SGD (b) group lasso 0 1 2 3 4 5 6 7 8 9 0 2 4 6 8 number of workers speed up TAP−SGD DAP−SGD (c) fused lasso 0 1 2 3 4 5 6 7 8 9 0 2 4 6 8 number of workers speed up TAP−SGD DAP−SGD (d) n uclear norm Figure 2: Sp eedup of T AP-SGD and D AP-SGD with 4 differen t no n-smo oth regulariza tion terms. Exp erimental Setup . W e conduct t wo ex pe r iment s to ev aluate the algo rithms with 4 different non- smo oth reg ularization terms ( L 1 , group lasso, simplified fused lasso, nuclear norm) regarding the running time and num b er o f iterations, a s well a s the sp eedup. Data is generated rando mly . In the first exp eriment, for the 4 differen t ob jectiv es, the nu mber o f samples n is set to 1 × 10 3 , 1 × 1 0 3 , 1 × 1 0 3 , and 4 × 10 3 , while the length of the para meter is s et to 5 × 10 3 , 5 × 10 3 , 5 × 10 3 and 2 × 10 3 (in the form of a 50 × 40 ma tr ix for nuclear norm reg ularization), r esp ectively . The num b er of iteratio ns T is set to 2 × 1 0 5 , 2 × 10 5 , 1 × 1 0 4 and 2 × 10 4 , a nd the step-size η t is set to 1 2 × 10 5 +200 t , 1 2 × 10 5 +200 t , 1 2 × 10 5 +200 t and 1 2 × 10 4 + t , r e s pe c tiv ely , whic h is decreasing with iterations. The h yp er-par ameter λ is set to 20 0 , 200 , 200 , 0 . 1 corre s po ndingly . In the second exp eriment of ev aluating the sp eedup, the settings ar e identical to the firs t ex per iment except that the num ber of iterations for simplified fused no rm and nuclear norm regular ized o b jectiv es is set to 10 4 and 2 × 10 4 , and the num b er of para meters for L 1 and g roup las so re g ularized o b jectiv es is set to 5 × 1 0 4 . The total time cost of a system consists of tw o parts: ev a luation of up dating information in the workers and upda ting in the master. If w e ca n sp eed up b oth with k times, then w e can achiev e a k -sp eed up in the ideal case. In our exp er iment , the num ber of up dating threads runn ing in parallel and maximum delay τ in the master is fixed to the num b er of workers. Results are summar ized in Fig ur es 1 a nd 2. Figure 1 shows the co mparison b etw een T AP -SGD and D AP-SGD r egarding the running time and num b er o f iter a tions. As shown in the top row of Figure 1, the prop osed DAP - GSD a lg orithm is slightly slow er than T AP-SGD with the L 1 regularize d ob jectiv e. The reaso n is that the proximal oper ator of L 1 norm is element-wise and ca n b e parallelized. The decoupled up date of D AP-SGD (8) involv es more o p e r ations in workers than the update o f T AP-SGD (3), whose work er s only need to ev aluate the gradients. Nevertheless, D AP-SGD is m uch faster than T AP-SGD with group lasso, simplified fused lasso and nuclear norm regula rized ob jectiv es bec ause the pr oximal op era tors of these norms are not element-wise and ha rd to parallelize. As a c o nsequence, ev aluation of the proximal op er ator in the master of T AP-SGD becomes the computationa l bo ttlenec k of the whole system and the p er fo r mance degrades significantly . In contrast, D AP-SGD a llows each worker to ev aluate the proximal o p e r ator, which justifies our cor e idea of decoupling the computation. Meanwhile, a ccording to the b o ttom row of Figur e 1, T AP-SGD a nd DAP-SGD p erform similarly r egarding the n umber of iterations. The exp erimental r esults shown in Figure 1 v alidate that the decoupled oper ation in D AP-SGD makes the a lgorithm mo re flexible and easier to parallelize without affecting the prec ision of the algor ithm. Figure 2 co mpa res T AP-SGD and D AP-SGD in terms of the sp eedup with different regular ization terms. Obviously , DAP - SGD c a n a chiev e significa nt speedup with the num be r o f workers increasing except fo r the L 1 regularize d ob jective due to the sa me reason discuss e d a b ov e. With g roup lasso , simplified fused lasso and nuclear norm regularized ob jectiv es, T AP-SGD essentially fails to sp eedup when the num ber of workers increases, which indicates the computationa l b ottleneck a t the master for ev aluating the coupled proximal op erator. Meanwhile, the decoupling op eration of DAP-SGD is effective to off-load the computation to the work ers and improv es the parallelism in asynchronous proximal stochastic gradient descent. 6 Conclusion This pa per prop oses a nov el decoupled asynchronous proximal sto chastic gr adient descent (D AP-SGD) alg o- rithm for optimizing a comp osite ob jective function. By o ff-loading computation from the master to workers, 8 the prop os ed DAP-SGD algor ithm b ecomes ea sy to parallelize. DAP-SGD is suitable fo r many mas ter-worker architectures, including sing le machine m ulti-co r e sys tems and multi-mach ine systems. W e further provide theoretical conv ergence analyses for D AP-SGD, with bo th diminishing and fixed step-sizes. 9 References [1] F. Niu, B. Rech t, C. Re, S. J. W right, Hogwild: A lo ck-free appr o ach to para llelizing stochastic gradient descent, in: Pro ceedings of Adv ance s in Neural Information Proc e ssing Systems 24 , December 12-14 , 2011, Granada , Spain, 2011, pp. 693–7 01. [2] A. Agarw a l, J. C. Duchi, Distributed dela yed sto chastic optimization, in: Pro ceedings of Adv ances in Neural Information Pro cessing Systems 2 4, Decem b er 1 2-14 , 2011, Granada, Spain, 20 11, pp. 8 73–8 81. [3] M. Li, D. G. Andersen, A. J. Smo la, K. Y u, Co mm unica tion efficient distributed machine learning with the par ameter server, in: Pro c eedings o f Adv a nces in Neura l Informa tion Pro ces s ing Systems 27, Decem b er 8-13 2014, Montreal, Q ueb e c , Canada, 2014, pp. 19–2 7. [4] X. Lia n, Y. Huang, Y. Li, J. Liu, Asynchronous par allel sto chastic gradient for nonco nv ex optimiza- tion, in: Pro ceedings o f Adv a nces in Neura l Information Pro ce ssing Systems 28, December 7-12 , 2015 , Montreal, Q ueb ec, Ca na da, 2015, pp. 2737– 2745 . [5] R. Z hang, J. T. K wok, Async hro no us distributed ADMM for consensus optimization, in: Pro c e e dings of the 31th International Conference on Machine Learning, ICML 2 014, Beijing, C hina , 21 - 26 June 201 4, 2014, pp. 170 1–17 09. [6] H. R. F eyzmahda vian, A. A ytekin, M. Jo hansson, A delay ed proximal gradient metho d with linear conv ergence rate, in: IEEE International W orks hop on Ma chine L e arning for Signal Pro cessing, MLSP 2014, Reims, F rance, September 21 -24, 2014, pp. 1–6. [7] J. L iu, S. J. W righ t, C. Ré, V. Bittorf, S. Sridhar , An a synchronous pa rallel sto chastic co o rdinate descent algorithm, Jour na l o f Mach ine Lea rning Research 16 (201 5) 2 85–3 22. [8] J. Liu, S. J. W righ t, Asynchronous sto chastic co ordinate desce nt: Parallelism and co nv ergence prop erties, SIAM Journal on Optimization 25 (1 ) (2015) 351– 376. [9] O. F ercoq, P . Rich tár ik, A cceler ated, parallel, a nd proximal co ordinate descen t, SIAM Jo urnal on Opti- mization 25 (4) (201 5) 1997–2 0 23. [10] J. Mareče k, P . Rich tá r ik, M. T akáč, Distributed blo ck co ordinate descent for minimizing partially s epa- rable functions, in: Numer ic a l Analysis and Optimization, Springer , 2 015, pp. 261 – 288. [11] M. Hong, A distributed, async hro nous and incremental algo rithm for noncon vex optimization: An admm based approach, a r Xiv preprint arXiv:1 412.60 58. [12] Y. Zhou, Y. Y u, W. Dai, Y. Liang, E. Xing , On co nv ergence of mo del par allel proximal gr adient algor ithm for stale synchronous pa r allel system, in: In ternationa l Conference o n Artificial Int ellig ence and Statistics (AIST A TS), 20 1 6. [13] C. Hsieh, H. Y u, I. S. Dhillon, Passco de: P a rallel a s ynchronous stochastic dual co-or dinate descent , in: Pro ceedings of the 32nd International C o nference on Mac hin e Learning, ICML 2015 , Lille, F rance, 6-11 July 2015, 2015 , pp. 2370– 2379 . [14] A. Beck, M. T eboulle, A fast itera tive shrink age-thresho lding algo rithm for linear inverse problems, SIAM journal on imaging sciences 2 (1) (2009) 183–2 02. [15] N. Parikh, S. P . Boyd, Proximal a lgorithms., F oundations a nd T rends in optimization 1 (3) (20 14) 127–2 39. [16] J. F riedman, T. Hastie, R. Tibshira ni, A no te on the gro up lasso a nd a s parse gr oup lasso , ar Xiv preprint arXiv:100 1.073 6 . [17] J. Liu, L. Y uan, J. Y e, An efficient alg orithm for a class of fused lasso problems, in: Pro ceedings of the 16th A CM SIGKDD International Co nference on K nowledge Discov ery a nd Data Mining , W a shington, DC, USA, July 25 - 28, 2 010, 2010 , pp. 3 23–3 32. 10 [18] S. Ji, J. Y e, An accelerated gradient metho d fo r trace norm minimization, in: Pro ceedings of the 26th Ann ual International C o nference on Machine Lea r ning, ICML 200 9, Montreal, Q ueb ec, Canada, June 14-18 , 200 9, 2009, pp. 457–4 64. [19] J. Cai, E. J. Candès , Z. Shen, A singular v alue thresholding alg orithm for matrix c ompletion, SIAM Journal on Optimization 20 (4) (20 1 0) 1956–1 982. [20] Y. Nesterov, Int r o ductory lectures on conv ex optimization: A basic cours e, V ol. 8 7 , Springer Science & Business Media, 2013 . [21] A. Nemirovski, A. Juditsky , G. Lan, A. Shapiro , Robust sto chastic a pproximation appro ach to s to chastic progra mming, SIAM J ournal on Optimization 19 (4) (200 9) 1574–16 09. 11 App endix for Ma k e W ork ers W ork Harder: Decoupled Async hronous Pro ximal Sto c hastic Gradient Descen t Theorem 1 Supp ose that the c ost function of (1) satisfies the fol lo wing c onditions: f ( x ) is str ongly c onvex with c onstant µ and h ( x ) is c onvex; f ( x ) is differ entiable and ▽ f ( x ) is Lipsc hitz c ontinuous with c onstant L ; E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f ; k ∂ h ( x ) k 2 2 ≤ C h . D efi ne the optimal solution of (1) as x ∗ . At time t , set t he step-size of the DAP-SGD r e cursion (8) as η t = O (1 /t ) . Then the iter ate gener ate d by (8) at time T , denote d by x T , satisfies E k x T − x ∗ k 2 2 ≤ O log T T . (23) Pro of of Theorem 1: F rom the DAP-SGD upda te x t +1 = x t + x ′ d ( t ) − x d ( t ) , we have E k x t +1 − x ∗ k 2 2 = E k x t − x ∗ + x ′ d ( t ) − x d ( t ) k 2 = E k x t − x ∗ k 2 2 + E k x ′ d ( t ) − x d ( t ) k 2 + 2 E D x ′ d ( t ) − x d ( t ) , x t − x ∗ E = E k x t − x ∗ k 2 2 + E k x ′ d ( t ) − x d ( t ) k 2 + 2 E D x ′ d ( t ) − x d ( t ) , x d ( t ) − x ∗ E | {z } Q 1 +2 E D x ′ d ( t ) − x d ( t ) , x t − x d ( t ) E . (24) Below we bound the v alue of Q 1 from ab ov e. Recalling the up date of x ′ d ( t ) in (8) of the pap er, which is x ′ d ( t ) = Pro x η, h ( x d ( t ) − η d ( t ) ▽ f i d ( t ) ( x d ( t ) )) = argmin y 1 2 η d ( t ) k y − ( x d ( t ) − η d ( t ) ▽ f i d ( t ) ( x d ( t ) )) k 2 2 + h ( y ) , (25) we hav e 1 η d ( t ) ( x d ( t ) − x ′ d ( t ) ) − ▽ f i d ( t ) ( x d ( t ) ) ∈ ∂ h ( x ′ d ( t ) ) . (26) Because f ( x ) is conv ex (right now we do not need to use its stro ng conv exity) and h ( x ) is a lso c o nv ex, we hav e the following lo wer b ound for the o ptimal v alue P ( x ∗ ) , f ( x ∗ ) + h ( x ∗ ) ≥ f ( x d ( t ) ) + ▽ f ( x d ( t ) ) , x ∗ − x d ( t ) + h ( x ′ d ( t ) ) + D ∂ h ( x ′ d ( t ) ) , x ∗ − x ′ d ( t ) E . (27) With a sligh t abuse of nota tion, here and therea fter ∂ h ( x ′ d ( t ) ) stands for any subg radient. Hence we substitute the one given in (26) into (27) and obtain P ( x ∗ ) ≥ f ( x d ( t ) ) + ▽ f ( x d ( t ) ) , x ∗ − x d ( t ) + h ( x ′ d ( t ) ) + 1 η d ( t ) ( x d ( t ) − x ′ d ( t ) ) − ▽ f i d ( t ) ( x d ( t ) ) , x ∗ − x ′ d ( t ) . (28) On the other hand, ▽ f ( x ) b eing Lipschit z contin uous with co nstant L implies f ( x ′ d ( t ) ) ≤ f ( x d ( t ) ) + D ▽ f ( x d ( t ) ) , x ′ d ( t ) − x d ( t ) E + L 2 k x ′ d ( t ) − x d ( t ) k 2 2 . (29) Substituting (29) into (28) P ( x ∗ ) ≥ f ( x ′ d ( t ) ) − D ▽ f ( x d ( t ) ) , x ′ d ( t ) − x d ( t ) E − L 2 k x ′ d ( t ) − x d ( t ) k 2 2 + ▽ f ( x d ( t ) ) , x ∗ − x d ( t ) + h ( x ′ d ( t ) ) + 1 η d ( t ) ( x d ( t ) − x ′ d ( t ) ) − ▽ f i d ( t ) ( x d ( t ) ) , x ∗ − x ′ d ( t ) . (30) 12 Noticing that by definition P ( x ′ d ( t ) ) , f ( x ′ d ( t ) ) + h ( x ′ d ( t ) ) and reorg anizing the ter ms of (3 0 ), we obta in − [ P ( x ′ d ( t ) ) − P ( x ∗ )] ≥ D ▽ f ( x d ( t ) ) − ▽ f i d ( t ) ( x d ( t ) ) , x ∗ − x ′ d ( t ) E + 1 η d ( t ) D x d ( t ) − x ′ d ( t ) , x ∗ − x d ( t ) E + 1 η d ( t ) k x d ( t ) − x ′ d ( t ) k 2 − L 2 k x d ( t ) − x ′ d ( t ) k 2 . (31) Assuming that η t ≤ 1 / L fo r an y t (this as sumption holds according to the step-s ize rule given later), (31) yields − [ P ( x ′ d ( t ) ) − P ( x ∗ )] ≥ D ▽ f ( x d ( t ) ) − ▽ f i d ( t ) ( x d ( t ) ) , x ∗ − x ′ d ( t ) E + 1 η d ( t ) D x d ( t ) − x ′ d ( t ) , x ∗ − x d ( t ) E + 1 2 η d ( t ) k x d ( t ) − x ′ d ( t ) k 2 . (32) T aking ex p ecta tion on bo th sides of (32) and re o rganizing ter ms, we have − E [ P ( x ′ d ( t ) ) − P ( x ∗ )] + E D ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) , x ∗ − x ′ d ( t ) E | {z } Q 2 ≥ 1 η d ( t ) E D x d ( t ) − x ′ d ( t ) , x ∗ − x d ( t ) E + 1 2 η d ( t ) E k x d ( t ) − x ′ d ( t ) k 2 . (33) Define ˆ x ′ d ( t ) , Pro x η, h ( x d ( t ) − η d ( t ) ▽ f ( x d ( t ) )) as a n a pproximation of x ′ d ( t ) , Pro x η, h ( x d ( t ) − η d ( t ) ▽ f i d ( t ) ( x d ( t ) )) . Because the r andom v aria ble i d ( t ) is indep endent with x ∗ and ˆ x ′ d ( t ) , while E ▽ f i d ( t ) ( x d ( t ) ) = ▽ f ( x d ( t ) ) , it holds E h ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) , x ∗ − ˆ x ′ d ( t ) i = 0 . Hence, Q 2 can be upper b ounded by Q 2 = E D ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) , x ∗ − x ′ d ( t ) E = E D ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) , x ∗ − ˆ x ′ d ( t ) E + E D ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) , ˆ x ′ d ( t ) − x ′ d ( t ) E = E D ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) , ˆ x ′ d ( t ) − x ′ d ( t ) E ≤ E k ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) k 2 k ˆ x ′ d ( t ) − x ′ d ( t ) k 2 , (34) where the la s t inequality comes from the Cauch y-Sch warz inequality . F ur ther, the non-expansive prop er t y of proximal op era tors [8 ] implies k ˆ x ′ d ( t ) − x ′ d ( t ) k 2 = k Prox η, h ( x d ( t ) − η d ( t ) ▽ f ( x d ( t ) )) − Prox η, h ( x d ( t ) − η d ( t ) ▽ f i d ( t ) ( x d ( t ) )) k 2 ≤ η d ( t ) k ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) k 2 . (35) Combining (34) and (3 5) yields an upp er b ound of Q 2 as Q 2 ≤ η d ( t ) E k ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) k 2 2 ≤ η d ( t ) C f , (36) where the last inequality is due to the assumption of b ounded v aria nce E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f . Substituting (36) into (33), we hav e − E [ P ( x ′ d ( t ) ) − P ( x ∗ )] + η d ( t ) C f ≥ 1 η d ( t ) E D x d ( t ) − x ′ d ( t ) , x ∗ − x d ( t ) E + 1 2 η d ( t ) E k x d ( t ) − x ′ d ( t ) k 2 . (37) Now we end up with an uppe r b ound of Q 1 as Q 1 , E k x ′ d ( t ) − x d ( t ) k 2 + 2 E D x ′ d ( t ) − x d ( t ) , x d ( t ) − x ∗ E ≤ − 2 η d ( t ) E [ P ( x ′ d ( t ) ) − P ( x ∗ )] + 2 η 2 d ( t ) C f . (38) 13 Therefore Q 1 ≤ − 2 η d ( t ) E [ P ( x t ) − P ( x ∗ )] − 2 η d ( t ) E [ P ( x ′ d ( t ) ) − P ( x t )] + 2 η 2 d ( t ) C f . ≤ − µη d ( t ) E k x t − x ∗ k 2 2 − 2 η d ( t ) E [ P ( x ′ d ( t ) ) − P ( x t )] + 2 η 2 d ( t ) C f . (39) The second line comes from the inequality P ( x t ) − P ( x ∗ ) ≥ µ 2 k x t − x ∗ k 2 2 , (40) which is due to the facts tha t x ∗ is the optimal solution of P ( x ) = f ( x ) + h ( x ) , f ( x ) is strongly co nv ex with constant µ , and h ( x ) is co nv ex. Substituting (39) into (24), we hav e E k x t +1 − x ∗ k 2 2 ≤ (1 − µη d ( t ) ) E k x t − x ∗ k 2 2 + 2 η d ( t ) E [ P ( x d ( t ) ) − P ( x ′ d ( t ) )] | {z } Q 3 + 2 η d ( t ) t − d ( t ) X p =1 E [ P ( x t − p +1 ) − P ( x t − p )] | {z } Q 4 +2 η 2 d ( t ) C f + 2 E D x ′ d ( t ) − x d ( t ) , x t − x d ( t ) E | {z } Q 5 . (41) W e pro ceed to bo und the terms Q 3 , Q 4 , and Q 5 . Because f ( x ) and h ( x ) a re conv ex as well as the norm of ∂ h ( x ) is b ounded, we hav e the following basic inequality P ( x ) − P ( y ) = f ( x ) − f ( y ) + h ( x ) − h ( y ) ≤ h ▽ f ( x ) , x − y i + h ∂ h ( x ) , x − y i ≤k ▽ f ( x ) k 2 k x − y k 2 + k ∂ h ( x ) k 2 k x − y k 2 ≤k ▽ f ( x ) k 2 k x − y k 2 + p C h k x − y k 2 =( k ▽ f ( x ) k 2 + p C h ) k x − y k 2 . (42) In (42), the second line comes from the conv exity of f ( x ) and h ( x ) , while the third line comes from the Cauch y-Sch warz inequality . Repla c ing x b y x d ( t ) and y b y x ′ d ( t ) in (42), we hav e Q 3 = E h P ( x d ( t ) ) − P ( x ′ d ( t ) ) i ≤ E h ( k ▽ f ( x d ( t ) ) k 2 + p C h ) k x d ( t ) − x ′ d ( t ) k 2 i . (43) Applying the express ion of x d ( t ) − x ′ d ( t ) in (26) into (43) yields Q 3 ≤ η d ( t ) E h ( k ▽ f ( x d ( t ) ) k 2 + p C h ) k ▽ f i d ( t ) ( x d ( t ) ) + ∂ h ( x ′ d ( t ) ) k 2 i ≤ 1 2 η d ( t ) E k ▽ f ( x d ( t ) ) k 2 2 + 1 2 η d ( t ) C h + η d ( t ) E k ▽ f i d ( t ) ( x d ( t ) ) + ∂ h ( x ′ d ( t ) ) k 2 2 . (44) Due to the inequalities 1 2 k ▽ f ( x d ( t ) ) k 2 2 ≤ k ▽ f ( x d ( t ) ) − ▽ f ( x ∗ ) k 2 2 + k ▽ f ( x ∗ ) k 2 2 , (45) and k ▽ f i d ( t ) ( x d ( t ) ) + ∂ h ( x ′ d ( t ) ) k 2 2 ≤ 2 k ▽ f i d ( t ) ( x d ( t ) ) k 2 2 + 2 k ∂ h ( x ′ d ( t ) ) k 2 2 ≤ 4 k ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) k 2 2 + 4 k ▽ f ( x d ( t ) ) k 2 2 + 2 k ∂ h ( x ′ d ( t ) ) k 2 2 ≤ 4 k ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) k 2 2 + 8 k ▽ f ( x d ( t ) ) − ▽ f ( x ∗ ) k 2 2 + 8 k ▽ f ( x ∗ ) k 2 2 + 2 k ∂ h ( x ′ d ( t ) ) k 2 2 , (46) 14 (44) turns to Q 3 ≤ 9 η d ( t ) E k ▽ f ( x d ( t ) ) − ▽ f ( x ∗ ) k 2 2 + 9 η d ( t ) E k ▽ f ( x ∗ ) k 2 2 + 4 η d ( t ) E k ▽ f i d ( t ) ( x d ( t ) ) − ▽ f ( x d ( t ) ) k 2 2 + 2 η d ( t ) E k ∂ h ( x ′ d ( t ) ) k 2 2 + 1 2 η d ( t ) C h . (47) Considering L ipschit z contin uity of ▽ f ( x ) , k ▽ f ( x ∗ ) k 2 2 ≤ C h from C o rollar y 1, E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f , as well as k ∂ h ( x ) k 2 2 ≤ C h , (47) further turns to Q 3 ≤ 9 η d ( t ) L 2 E k x d ( t ) − x ∗ k 2 2 + 4 η d ( t ) C f + 23 2 η d ( t ) C h . (48) Similar to the deriv ation of (48), we have Q 4 = E [ P ( x t − p +1 ) − P ( x t − p )] ≤ E h ( k ▽ f ( x t − p +1 ) k 2 + p C h ) k x t − p +1 − x t − p k 2 i ≤ η d ( t − p ) E h ( k ▽ f ( x t − p +1 ) k 2 + p C h ) k ▽ f i d ( t − p ) ( x d ( t − p ) ) + ∂ h ( x ′ d ( t − p ) ) k 2 i ≤ 1 2 η d ( t − p ) E k ▽ f ( x t − p +1 ) k 2 2 + 1 2 η d ( t − p ) C h + η d ( t − p ) E k ▽ f i d ( t − p ) ( x d ( t − p ) ) + ∂ h ( x ′ d ( t − p ) ) k 2 2 . (49) Using the inequalities (see (45) and (46)) 1 2 k ▽ f ( x t − p +1 ) k 2 2 ≤ k ▽ f ( x t − p +1 ) − ▽ f ( x ∗ ) k 2 2 + k ▽ f ( x ∗ ) k 2 2 , (50) and k ▽ f i d ( t − p ) ( x d ( t − p ) ) + ∂ h ( x ′ d ( t − p ) ) k 2 2 ≤ 4 k ▽ f i d ( t − p ) ( x d ( t − p ) ) − ▽ f ( x d ( t − p ) ) k 2 2 + 8 k ▽ f ( x d ( t − p ) ) − ▽ f ( x ∗ ) k 2 2 + 8 k ▽ f ( x ∗ ) k 2 2 + 2 k ∂ h ( x ′ d ( t − p ) ) k 2 2 , (51) (49) yields Q 4 ≤ η d ( t − p ) E k ▽ f ( x t − p +1 ) − ▽ f ( x ∗ ) k 2 2 + 9 η d ( t − p ) E k ▽ f ( x ∗ ) k 2 + 8 η d ( t − p ) E k ▽ f ( x t − p ) − ▽ f ( x ∗ ) k 2 2 + 4 η d ( t − p ) E k ▽ f i d ( t − p ) ( x d ( t − p ) ) − ▽ f ( x d ( t − p ) ) k 2 2 + 2 η d ( t − p ) E k ∂ h ( x ′ d ( t − p ) ) k 2 2 + 1 2 η d ( t − p ) C h ≤ η d ( t − p ) L 2 E k x t − p +1 − x ∗ k 2 2 + 8 η d ( t − p ) L 2 E k x d ( t − p ) − x ∗ k 2 2 + 4 η d ( t − p ) C f + 23 2 η d ( t − p ) C h . (52) Again, the la st line of (52) utilizes Lipschitz contin uit y of ▽ f ( x ) , k ▽ f ( x ∗ ) k 2 2 ≤ C h from Coro llary 1, E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f , as well a s k ∂ h ( x ) k 2 2 ≤ C h . F or the ter m Q 5 , we use the Cauch y-Sch warz inequality follow ed by the substitution of (26) a nd get Q 5 = E D x ′ d ( t ) − x d ( t ) , x t − x d ( t ) E ≤ E k x ′ d ( t ) − x d ( t ) k 2 k x t − x d ( t ) k 2 ≤ η d ( t ) E k ▽ f i d ( t ) ( x d ( t ) ) + ∂ h ( x ′ d ( t ) ) k 2 k x t − x d ( t ) k 2 . (53) F urther rela xing (53) by the triangle inequalit y yields Q 5 ≤ η d ( t ) t − d ( t ) X p =1 E k ▽ f i d ( t ) ( x d ( t ) ) + ∂ h ( x ′ d ( t ) ) k 2 k x t − p +1 − x t − p k 2 . (54) Since the maximum delay is τ , we hav e Q 5 ≤ η d ( t ) τ X p =1 E k ▽ f i d ( t ) ( x d ( t ) ) + ∂ h ( x ′ d ( t ) ) k 2 k x t − p +1 − x t − p k 2 . (55) 15 Noticing the relations x t − p +1 − x t − p = x ′ d ( t − p ) − x d ( t − p ) from the D AP-SGD r ecursion and x ′ d ( t − p ) − x d ( t − p ) = η d ( t ) ( ▽ f ( x d ( t − p ) ) + ∂ h ( x ′ d ( t − p ) )) from (26), (56) leads to Q 5 ≤ η d ( t ) τ X p =1 η d ( t − p ) E k ▽ f i d ( t ) ( x d ( t ) ) + ∂ h ( x ′ d ( t ) ) k 2 k ▽ f ( x d ( t − p ) ) + ∂ h ( x ′ d ( t − p ) ) k 2 . (56) F ollowing the similar routines as those in (48) a nd (52), even tually we reach Q 5 ≤ 4 η d ( t ) L 2 τ X p =1 η d ( t − p ) E k x d ( t ) − x ∗ k 2 2 + 4 η d ( t ) L 2 τ X p =1 η d ( t − p ) E k x d ( t − p ) − x ∗ k 2 2 + 4 η d ( t ) τ X p =1 η d ( t − p ) C f + 10 η d ( t ) τ X p =1 η d ( t − p ) C h (57) Substituting (48), (52) and (57) into (41), w e have E k x t +1 − x ∗ k 2 2 ≤ 1 − µη d ( t ) E k x t − x ∗ k 2 2 + 8 η d ( t ) L 2 τ X p =1 η d ( t − p ) + 18 η 2 d ( t ) L 2 ! E k x d ( t ) − x ∗ k 2 2 + 2 η d ( t ) L 2 τ X p =1 η d ( t − p ) E k x t − p +1 − x ∗ k 2 2 + 24 η d ( t ) L 2 τ X p =1 η d ( t − p ) E k x d ( t − p ) − x ∗ k 2 2 + 16 η d ( t ) τ X p =1 η d ( t − p ) + 8 η 2 d ( t ) ! C f + 43 η d ( t ) τ X p =1 η d ( t − p ) + 23 η 2 d ( t ) ! C h . (58) Define the step-size rule η t = 1 µ ( t + 1) + u = O 1 t , (59) where u is a p ositive constant satisfying: • u > (2 τ − 1 ) µ such that η t ≤ η d ( t ) ; • u is large enough such that min( µ/ (4 C 1 τ ) , 1 / L ) ≥ η t , where C 1 is a constant w e give b elow. Define tw o constant s C 1 = 2 L 2 µ + u µ + u − 2 µτ + 48 τ L 2 + 8 τ L 2 µ + u µ + u − 2 µτ µ + u µ + u − µτ + 18 L 2 , and C 2 = [(16 τ + 8) C f + (43 τ + 23) C h ] ( µ + u ) 2 ( µ + u − 2 µτ ) 2 . Though not straightforw a rd, we c a n show that under the s tep- size rule given by (59), (58) yields E k x t +1 − x ∗ k 2 2 ≤ (1 − µη t ) E k x t − x ∗ k 2 2 + C 1 2 τ X p =0 η 2 t − p E k x t − p − x ∗ k 2 2 + C 2 η 2 t . (60) F or the ea se of presentation, we define a t = E k x t − x ∗ k 2 2 and will analyze its r ate. Rewrite (60) to a t +1 ≤ (1 − µη t ) a t + C 1 2 τ X p =0 η 2 t − p a t − p + C 2 η 2 t . (61) 16 Applying telescopic cancellatio n to (61) from t = 0 to t = T − 1 yields a T ≤ a 0 − T − 1 X t =0 µη t a t + C 1 T − 1 X t =0 2 τ X p =0 η 2 t − p a t − p + C 2 T − 1 X t =0 η 2 t ≤ a 0 − T − 1 X t =0 ( µη t − 2 C 1 η 2 t τ ) a t + C 2 O (1) . (62) As we can verify , µ/ (4 C 1 τ ) ≥ η t , meaning that T − 1 X t =0 ( µη t − 2 C 1 η 2 t τ ) a t ≥ 1 2 T − 1 X t =0 µη t a t . (63) Combining (62) and (6 3), we have 1 2 T − 1 X t =0 µη t a t ≤ a 0 − a T + C 2 O (1) , (64) which , alo ng with the step-size rule (59), implies that T − 1 X t =0 1 µ ( t + 1 ) + u a t ≤ 2 µ ( a 0 + C 2 O (1)) (65) F urther define C 3 = u / ( u − µτ ) such tha t µ ( t + 1) + u ( µ ( t − p + 1) + u ) 2 ≤ C 3 µ ( t − p + 1) + u . Substituting the step-size rule (59) into (61), w e hav e a t +1 ≤ 1 − µ µ ( t + 1) + u a t + C 1 2 τ X p =0 1 ( µ ( t − p + 1) + u ) 2 a t − p + 1 ( µ ( t + 1) + u ) 2 C 2 , (66) and consequently ( µ ( t + 1) + u ) a t +1 ≤ ( µt + u ) a t + C 1 2 τ X p =0 µ ( t + 1) + u ( µ ( t − p + 1) + u ) 2 a t − p + 1 µ ( t + 1) + u C 2 ≤ ( µt + u ) a t + C 1 C 3 2 τ X p =0 1 µ ( t − p + 1) + u a t − p + 1 µ ( t + 1 ) + u C 2 . (67) Applying telescopic cancellatio n a g ain to (67) from t = 0 to t = T − 1 , we have ( µT + u ) a T ≤ ua 0 + C 1 C 3 T − 1 X t =0 2 τ X p =0 1 µ ( t − p + 1) + u a t − p + T − 1 X t =0 1 µ ( t + 1) + u C 2 ≤ ua 0 + 2 C 1 C 3 τ T − 1 X t =0 1 µ ( t + 1) + u a t + T − 1 X t =0 1 µ ( t + 1) + u C 2 . (68) Substituting (65) in to (68) yields ( µT + u ) a T ≤ ua 0 + 4 µ C 1 C 3 τ ( a 0 + C 2 O (1)) + C 2 O (log T ) , (69) 17 and consequently a T ≤ ua 0 + 4 µ C 1 C 3 τ ( a 0 + C 2 O (1)) + C 2 O (log T ) µT + u = O log T T , (70) which completes the pro o f. Theorem 2 Supp ose that the c ost function of (1) satisfies the fol lo wing c onditions: f ( x ) is str ongly c onvex with c onstant µ and h ( x ) is c onvex; f ( x ) is differ entiable and ▽ f ( x ) is Lipsc hitz c ontinuous with c onstant L ; E k ▽ f i ( x ) − ▽ f ( x ) k 2 2 ≤ C f ; k ∂ h ( x ) k 2 2 ≤ C h . Define the optimal solution of (1) as x ∗ . At time t , fix the step-size of the DAP-SGD r e cursion (8) η t as η = O (1 / √ T ) , wher e T is the maximum numb er of iter ations. Define the iter ate gener ate d by (8) at t ime t as x t . Then the running aver age iter ate gener ate d by (8) at time T , denote d by ¯ x T = 1 T + 1 T X t =0 x t , satisfies E k ¯ x T − x ∗ k 2 2 ≤ O 1 √ T . (71) Pro of of Theorem 2: W e sta r t from (58) in the pro of of Theo rem 1. Define the step-s ize rule η t = η = 1 v √ T , (72) where v is a p ositive constant such that min( µ/ (4 C 4 τ ) , 1 / L ) ≥ η . Defining cons ta nt s C 4 = (2 + 56 τ ) L 2 , and C 5 = (16 τ + 8 ) C f + (43 τ + 23) C h , follow ed b y manipulating (5 8), we hav e (similar to the inequality (61)) the following result a t +1 ≤ (1 − µη ) a t + C 4 η 2 2 τ X p =0 a t − p + C 5 η 2 (73) Applying telescopic cancellatio n to (73) from t = 0 to t = T yields a T +1 ≤ a 0 − T X t =0 µη a t + C 4 η 2 T X t =0 2 τ X p =0 a t − p + C 5 ( T + 1) η 2 ≤ a 0 − T X t =0 ( µη − 2 C 4 η 2 τ ) a t + C 5 ( T + 1 ) η 2 . (74) Since µ/ (4 C 4 τ ) ≥ η such that T X t =0 ( µη − 2 C 4 τ η 2 ) a t ≥ µη 2 T X t =0 a t , (75) (74) implies µη 2 T X t =0 a t ≤ a 0 − a T +1 + C 5 ( T + 1 ) η 2 , (76) 18 and consequently µη T + 1 T X t =0 a t ≤ 2 a 0 + 2 C 5 ( T + 1) η 2 T + 1 . (77) A cco rding to Jensen’s inequality , we hav e µη T + 1 T X t =0 a t = µη T + 1 T X t =0 E k x t − x ∗ k 2 2 ≥ µη E 1 T + 1 T X t =0 x t − x ∗ 2 2 = µη E k ¯ x T − x ∗ k 2 2 . (78) Substituting (78) and the step-size rule (72 ) in to (77), w e have E k ¯ x T − x ∗ k 2 2 ≤ 2 a 0 v √ T + 2 C 5 ( T + 1) 1 v √ T µ ( T + 1 ) = O ( 1 √ T ) , (79) which completes the pro o f. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment