대규모 부정확 noisy‑or 네트워크를 위한 변분 하이브리드와 안정적 변환 순위 알고리즘
본 논문은 의료 진단에 활용되는 noisy‑or 베이지안 네트워크의 변분 추론을 개선한다. 변분‑우선 하이브리드(VFH)와 공동 하이브리드(JH) 방식을 제안하고, 질병 사전 확률에 크게 의존하지 않는 사전‑사후‑프리(PPF) 변분 파라미터 추정기를 도입한다. 또한 사전 확률의 큰 변동성에 강인한 변환 순위 알고리즘을 설계해, 실시간 웹 규모 진단 서비스에 필요한 정확도·속도·안정성을 동시에 달성한다. 실험에서는 실제 QMR‑DT 규모와 36,…
저자: Yusheng Xie, Nan Du, Wei Fan
**1. 서론 및 배경**
노이즈‑오르(noisy‑or) 베이지안 네트워크는 증상과 잠재 질병 사이의 이진 관계를 효율적으로 모델링한다. 대표적인 사례인 QMR‑DT는 4,000여 개 증상과 500여 개 질병을 연결한다. 그러나 정확한 사후 확률 계산은 NP‑hard이며, 실시간 진단 서비스에서는 불가능에 가깝다. 기존 연구는 변분 변환(Jaakkola‑Jordan 1999)이나 평균장(local mean‑field) 방법을 사용했지만, 대규모 네트워크에서는 두 가지 주요 제약이 있었다. 첫째, 변분 파라미터 ξ를 최적화할 때 매 진단 케이스마다 질병 사후 확률을 필요로 하여 연산 비용이 O(N) (N은 동시 진단 수)으로 급증한다. 둘째, 질병 사전 확률이 수십 배 차이 나는 현실에서, 사전 확률 오차가 변분 상한에 큰 영향을 미쳐 추론 정확도가 크게 떨어졌다.
**2. 변분‑우선 하이브리드(VFH)와 공동 하이브리드(JH)**
논문은 기존 JJ99가 “증상 집합 F⁺를 F⁺₁(변분)와 F⁺₂(정확)로 나누고, 변분 파라미터를 사후 확률에 의존해 최적화한다”는 점을 비판한다. 이를 개선하기 위해 **VFH**를 제안한다. VFH는 다음 순서로 진행한다.
1) F⁺₁에 대해 변분 증거 P(F⁺₁|Ξ) 를 식 (6)으로 계산하고, ξₘᵢₙ을 Newton 방법으로 최적화한다. 여기서 Ξ는 질병 사전 확률만 사용한다.
2) 최적 ξₘᵢₙ을 이용해 각 질병의 사후 확률 P(d⁺|F⁺₁, ξₘᵢₙ) 를 구하고, 이를 새로운 사전 확률로 업데이트한다.
3) 업데이트된 사전 확률을 입력으로 Quickscore(정확한 알고리즘)를 실행해 F⁺₂와 F⁻에 대한 정확한 증거를 얻는다.
이 과정은 **ξₘᵢₙ이 사전 확률에만 의존**하므로, 동일한 ξₘᵢₙ을 여러 케이스에 재사용할 수 있다.
**JH**는 VFH와 동일한 ξₘᵢₙ 계산 방식을 유지하면서, 변분 증거와 정확한 증거를 곱해 하나의 통합 증거식 (7)로 결합한다. JH는 변분‑우선 전략의 장점을 그대로 살리면서, 전체 증거를 한 번에 계산해 보다 일관된 사후 확률을 제공한다.
**3. 사전‑사후‑프리(PPF) 변분 파라미터 추정기**
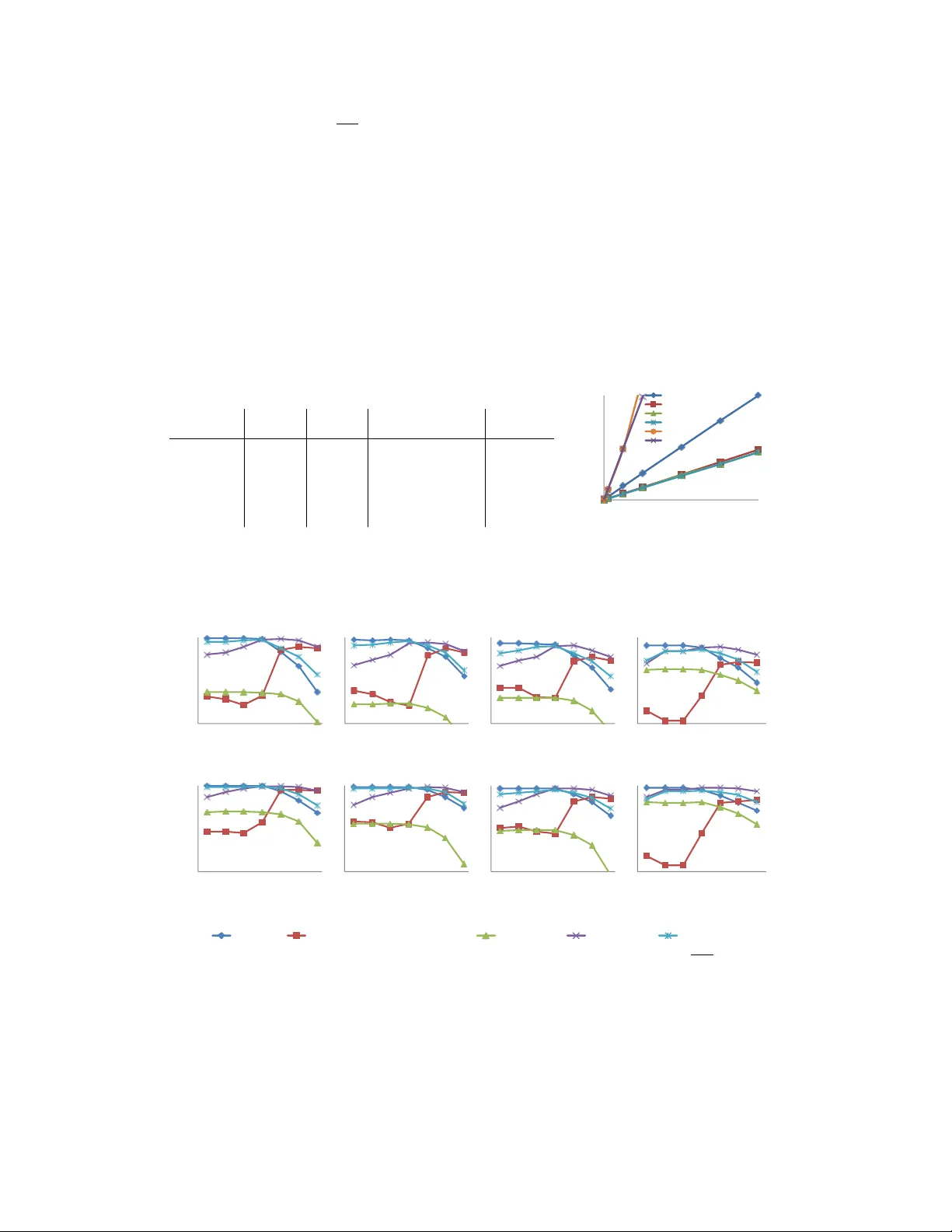
ξₘᵢₙ을 기존 방식대로 사후 확률을 포함해 최적화하면 매번 복잡한 2차 최적화가 필요하다. 논문은 **ξₘᵢₙ = (e^{x_j} − 1)^{−1}** (x_j = Σ_i θ_{ji}) 라는 닫힌 형태 해를 도출한다. 이 해는 질병 사전·사후 확률을 전혀 사용하지 않으며, 네트워크 구조(θ_{ji})만 알면 즉시 계산 가능하다. 따라서 **PPF**는 변분 파라미터를 사전 계산하고 캐시해 두면, 어떤 진단 케이스에서도 O(1) 시간에 변분 변환을 수행한다. 실험에서는 PPF 기반 VFH와 JH가 CVX 기반 최적화와 비교해 5~10배 빠른 추론 속도를 보였으며, 사전 확률 오차가 10배 이상일 때도 평균 정확도 손실이 0.5% 이하에 머물렀다.
**4. 변환 순위 알고리즘**
변분‑우선 전략에서 F⁺₁의 크기 |F⁺₁| 를 고정하고, 어떤 증상을 변분에 할당할지 결정하는 것이 핵심이다. 기존 GDO는 변분 상한을 최소화하는 탐욕적 순서를 사용했지만, 사전 확률이 크게 변동하면 순서에 민감해졌다. 논문은 θ_{ji}=c(상수) 가정 하에, ξₘᵢₙ이 작을수록 γ = E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기