Variational hybridization and transformation for large inaccurate noisy-or networks
Variational inference provides approximations to the computationally intractable posterior distribution in Bayesian networks. A prominent medical application of noisy-or Bayesian network is to infer potential diseases given observed symptoms. Previou…
Authors: Yusheng Xie, Nan Du, Wei Fan
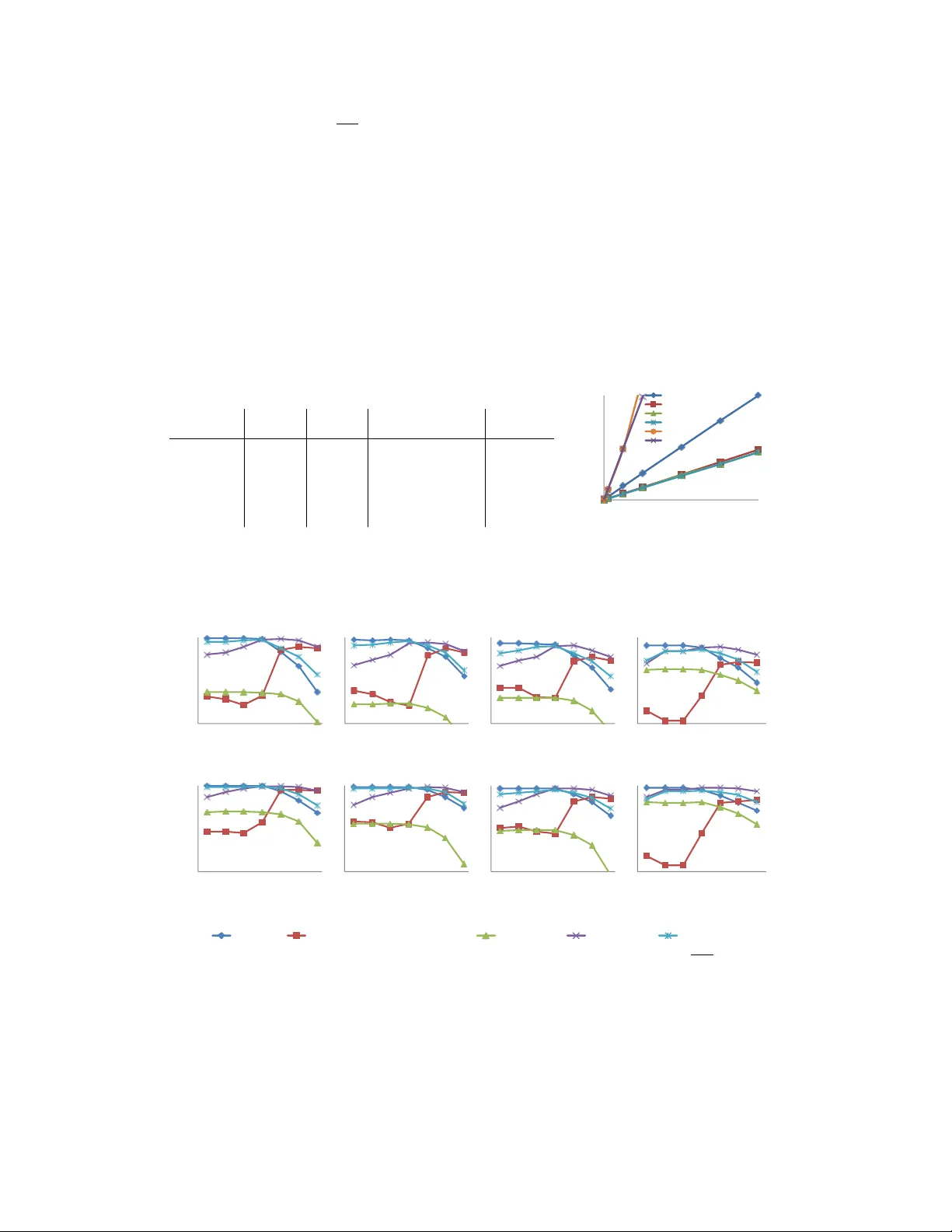
V ariational h ybridization and transf ormation f or large inaccurate noisy-or netw orks Y usheng Xie Nan Du W ei F an Jing Zhai W eicheng Zhu Baidu Research Sunnyv ale, CA 94089 {xieyusheng,dunan,fanwei03,zhaijing01,zhuweicheng}@baidu.com Abstract V ariational inference pro vides approximations to the computationally intractable posterior distribution in Bayesian networks. A prominent medical application of noisy-or Bayesian network is to infer potential diseases given observ ed symptoms. Previous studies focus on approximating a handful of complicated pathological cases using v ariational transformation. Our goal is to use v ariational transformation as part of a nov el hybridized inference for serving reliable and real time diagnosis at web scale. W e propose a hybridized inference that allows v ariational parameters to be estimated without disease posteriors or priors, making the inference faster and much of its computation recyclable. In addition, we propose a transformation ranking algorithm that is very stable to large variances in network prior probabilities, a common issue that arises in medical applications of Bayesian networks. In experiments, we perform comparativ e study on a large real life medical network and scalability study on a much larger (36,000x) synthesized netw ork. 1 Introduction Noisy-or Bayesian network (NOBN) is a popular class of statistical models in modeling observ able ev ents and their unobserved potential causes. One of the best known medical applications of NOBN is Quick Medical Reference ( QMR-DT ) (Middleton et al., 1991). QMR-DT describes expert-assessed relationships between 4,000+ observ able binary symptom v ariables (collectively denoted as S ) and 500+ binary latent disease variables (collecti vely denoted as D ) as illustrated in Figure 1 (a). W e improve v ariational inference for a large QMR-DT style NOBN in areas of scalability , stability , and accuracy to previously unattainable or untested levels. As part of a medical messaging bot, the inference goal is to perform reliable real time diagnosis at web scale. Figure 1 (b) shows the messaging bot’ s interface. The ongoing project aims to serve a substantial portion of Internet users who experience health issues (e.g., 3 to 8 million daily acti ve users 1 ) with reliable disease diagnosis that is more accurate and accessible than te xt-based web searches, web searches that emphasize retriev al similarity but lack clinical technicality (e.g., 38.5 ◦ C fever lasting 3 days and 39.5 ◦ C fever lasting 8 days . The latter could be 20x more fatal in probability). The dev eloping bot has completed 1,000+ organic, non-scripted dialogues with 100+ qualified human testers. Assessed by 50+ licensed doctors, the network plans to cov er all concei vable human diseases and health conditions 2 : approximately 40,000 (80x that of QMR-DT ) according to the 10th r evision of the International Statistical Classification of Diseases and Related Health Pr oblems (ICD-10). T o the best of our knowledge, the aforementioned scales make it the lar gest medical application of noisy-or Bayesian networks. 1 Assume an av erage person is sick 2-4 days per year and our reachable population is 600 to 800 million. 2 A sub-network focusing on maternal and infant care is completed and used in our e xperiments. (a) (b) !" #" $" %" &" &" '" (" #!" #$" #&" #'" )*+",-+./" 0"12"31-4)5+"678479-" :-",*;<=;>/" :-",?@A/" :-",BC=4;/" 5;D4;)17;=" (c) Figure 1: (a) Graphical model structure of QMR-DT . The shaded round nodes are observ ed nodes ( f + or f − ). All variables are binary . (b) Screenshot of the diagnosis bot. (c) Running time comparison of exact Quickscore (qs) and variational inference for | F + | = 4 , 6 , . . . , 16 . qs(matlab) and qs(MEX) are provided by (Murphy, 2002). qs(julia) and variational are authors’ own implementation. Recent advances in modern machine learning and artificial intelligence quickly proliferate f ar beyond the traditional Bayesian frame work. But for mission critical applications such as medical diagnosis, one prefers Bayesian network-based approach for reasoning instead of entirely data driven approach. The reasons are due to traceable outcome, easy debuggability , and provenance. Data source unrelia- bility and scarcity also pre vent some medical applications from taking full adv antage of the large body of data driv en algorithms that can be quickly accelerated by larger datasets (e.g., machine translation (Luong et al., 2015), speech recognition (Amodei et al., 2015)). For example, the Car oli disease 3 has fewer than 250 recorded cases worldwide, making it almost impossible to “gather/label more data points”. On the other hand, no disease should be too rare to deserve attention From an ethical perspectiv e, even a 1-in-1,000,000 chance (technically extr emely rar e ) translates into over 6,000 suf fering indi viduals worldwide. From an academic perspectiv e, understanding rare diseases brings irreplaceable medical knowledge. The expert-assessed probability of observing symptom f giv en only disease d is denoted as P ( f + | d + ) . W e use π ( f ) to denote { d | d ∈ D, P ( f + | d + ) > 0 } , the set of diseases that could cause f with non-zero probability . Like QMR-DT , we assume 4 P ( d + ) for each d ∈ D : the prior probability of having disease d without observing any symptoms. W e further define P ( f − ) and P ( d − ) notations as P ( f − ) = 1 − P ( f + ) and P ( d − ) = 1 − P ( d + ) , respectiv ely . In a typical diagnosis session, the user first inputs her positi ve and neg ati ve findings: F + = { f + 1 , f + 2 , . . . } ⊂ S , F − = { f − 1 , f − 2 , . . . } ⊂ S . Then the model performs inference to calculate P ( F + , F − ) , which is the crux in deriving the conditional P ( d + i | F + , F − ) for each d ∈ D . 1.1 Background on v ariational inference The exact inference for P ( F + , F − ) is intractable (Cooper, 1990) and intractability moti vates in- vestigations into approximation inference algorithms. The variational method (Jordan et al., 1999; Jaakkola and Jordan, 1999) and the mean field local approximation (Ng and Jordan, 2000) are both hybrid approximation algorithms. T o describe the v ariational approximation, let θ j i ≡ − log P ( f − j | d + i ) . (Jordan et al., 1999; Jaakkola and Jordan, 1999) show that P f + j | π ( f j ) + = e f P | π ( f j ) | i =1 θ j i ≤ e P | π ( f j ) | i =1 ξ j θ j i − f ∗ ( ξ j ) ≡ P ( f + j | π ( f j ) + , ξ j ) (1) and P ( f + j | ξ j ) = Y d i ∈ π ( f j ) P ( f + j | d + i , ξ j ) · P ( d + i ) + P ( f + j | d − i , ξ j ) · P ( d − i ) ≥ P ( f + j ) , (2) 3 Caroli disease is a type of congenital dilatation of intrahepatic bile duct. It has the code Q44.6 in ICD-10. 4 W ithout loss of generality , the leak probabilities (Jordan et al., 1999) are omitted in our discussion. 2 where ξ j is the free v ariational parameter , f ( x ) ≡ log (1 − e − x ) , and f ( x ) ’ s conv ex conjugate function takes the form f ∗ ( ξ ) = − ξ log ξ + ( ξ + 1) log( ξ + 1) , for ξ > 0 . Equation 2 transforms P ( f + j ) into its variational upper bound P ( f + j | ξ j ) using the inequality from conjugate duality . Breaking F + = { f + 1 , f + 2 , . . . } into the partition F + 1 and F + 2 allows exact inference on F + 2 and variational inference on F + 1 . (Jaakkola and Jordan, 1999) (JJ99) calculates the joint variational posterior as P J J 99 ( F + 1 , F + 2 , F − | Ξ min ) = e − P | F + 1 | j =1 f ∗ ( ξ min j ) Y d i ∈ π ( F + 1 ) e P | F + | j =1 ξ min j θ j i · P ( d + i | F + 2 , F − ) + P ( d − i | F + 2 , F − ) , (3) where Ξ = { ξ 1 , ξ 2 , . . . } . Finding arg min Ξ P ( F + | Ξ) can be relaxed to finding arg min ξ j log P ( f + j | ξ j ) for each ξ j ∈ Ξ . The ξ -con vexity permits second order optimization methods (CVX) to find each ξ j . From Equation 6, the 1st order partial deri vati ves are ∂ ∂ ξ j log P ( f + j | ξ j ) = log ξ j 1 + ξ j + X d i ∈ π ( f + j ) θ j i p i · e − ξ j θ j i + 1 , (4) where p i ≡ P ( d − i ) /P ( d + i ) is the in verse prior odds for the i th disease. The 2nd order partial deriv ativ es are deri ved mechanically . Figure 1 (c) illustrates the complexity of e xact and variational inference in real application. More discussion on existing inference algorithms are in related works section (see T able 2). 2 Inaccuracy in widely-ranged disease priors Inaccurate hidden variable prior is a recognized (Jernite et al., 2013; Mansinghka et al., 2006) but often av oided (Cheng et al., 2002; Liao and Ji, 2009; Riggelsen, 2006) issue in NOBN. Inaccuracy in disease prior is among the most likely errors in constructing a NOBN for medical applications. Real life disease priors can span se veral orders of magnitude. For example, acne (ICD-10 code: L70.0) affects 80% to 90% teenagers in the western world (Da wson and Dellav alle, 2013) while syndromes like the Car oli disease ha ve historical infection rates less than 0.00001%. It is very likely , ev en for medical experts or statistical estimators, to misjudge the prior probability by an order of magnitude relativ e to other very rare or very common diseases. So it is beneficial to obtain fast and accurate variational algorithms that are r esistant to the large v ariances in disease priors. In the following two sections, we propose inference algorithms that can greatly immunize the current variational inference ag ainst inaccuracy in disease priors. 3 V ariational-first h ybridization and joint hybridization The F + = F + 1 ∪ F + 2 partition employed in JJ99 is a realization of the classic hybrid paradigm: balancing accuracy and runtime over the entire F + by 1) applying different posterior estimators (variational, e xact, MCMC, etc.) to F + 1 , F + 2 , and 2) controlling their cardinalities. But JJ99 has tw o main drawbacks that pre vent it from fulfilling the scalability and stability requirements in building a web diagnostic bot. First, Equation 3 estimates Ξ min by using the exactly treated disease posterior P ( d + i | F + 2 , F − ) . The Ξ min estimations need be recalculated for ev ery case of F + 1 ∪ F + 2 ∪ F − since each case would produce dif ferent disease posteriors that af fect the gradients in Equation 4. Second, in order to pass confident posteriors to its variational step, JJ99 basically “primes” the potentially inaccurate disease priors with evidences from F + 2 ∪ F − . Since the hybridized complexity decreases e xponentially w .r .t. to | F + 1 | , F + 1 usually contains less evidence than F + 2 ∪ F − in practice (i.e., | F + 1 | < | F + 2 ∪ F − | ). In other words, JJ99 uses a substantial portion of the evidence in priming the unaudited priors first and then refines the posterior probabilities using the smaller leftov er portion of e vidence. W e propose the v ariational-first hybridization (VFH) that can fix both issues. Described in Algorithm 1, VFH performs inference on F + 1 first (to prime the unaudited priors) and on F + 2 and F − later (to refine the posteriors). Calculating Ξ min in VFH relies on disease priors instead of posteriors. 3 Algorithm 1: the proposed variational-first h ybridization (VFH) algorithm. Input : F + 1 , list of positiv e findings to be inferred variationally , F + 2 , list of positiv e findings to be inferred exactly , F − , list of negati ve findings to be inferred exactly , θ j i for each f j ∈ S and d i ∈ D , P ( d i ) , disease prior probability for each d i ∈ D . Output : The joint v ariational evidence of gi ven findings F + 1 , F + 2 , and F − . 1 Calculate P ( F + 1 | Ξ) as a function of Ξ from Equation 6. 2 Ξ min ← arg min Ξ P ( F + 1 | Ξ) using Newton’ s method on its deriv ativ es (shown in Equation 4). 3 f or each d i ∈ D do 4 Calculate P ( d + i | F + 1 , Ξ min ) from Equation 6 and P ( F + 1 | Ξ) . 5 P ( d i ) ← P ( d + i | F + 1 , Ξ min ) (update disease priors with posteriors). 6 P ( F + 2 , F − ) ← Quickscore ( F + 2 , F − ) . 7 r eturn P ( F + 2 , F − ) Therefore, the calculation is in variant to the findings that mak e up F + 1 ∪ F + 2 ∪ F − . Inv ariant Ξ min allows caching Ξ min values and leads to f aster inference as summarized in T able 1. Equation 5 explicitly e xpresses the joint v ariational e vidence of gi ven findings using VFH: P V F H ( F + 1 , F + 2 , F − | Ξ min ) = X F 0 ∈ 2 F + 2 ( − 1) | F 0 | | D | Y i =1 | F − ∪ F 0 | Y j =1 P ( f − j | d + i ) P ( d + i | F + 1 , Ξ min ) + P ( d − i | F + 1 , Ξ min ) , (5) where 2 F + 2 denotes the power set of F + 2 and the P ( d + i | F + 1 , Ξ min ) terms are calculated from P ( F + | Ξ) = e − P | F + | j =1 f ∗ ( ξ j ) Y d i ∈ π ( F + ) e P | F + | j =1 ξ j θ j i · P ( d + i ) + P ( d − i ) . (6) Besides VFH, we can also hybridize the exact evidence P ( F + 2 , F − ) and the variational evidence P ( F + 1 | Ξ) jointly (JH): P J H F + 1 , F + 2 , F − | Ξ min = X F 0 ∈ 2 F + 2 ( − 1) | F 0 | | D | Y i =1 | F − ∪ F 0 | Y j =1 P ( f − j | d + i ) | F + 1 | Y k =1 P ( f + k | d + k , ξ min k ) P ( d + i ) + | F + 1 | Y k =1 P ( f + k | d − k , ξ min k ) P ( d − i ) = e − P | F + 1 | k =1 f ∗ ( ξ min k ) X F 0 ∈ 2 F + 2 ( − 1) | F 0 | | D | Y i =1 | F − ∪ F 0 | Y j =1 P ( f − j | d + i ) e P | F + 1 | k =1 ξ min k θ ki P ( d + i ) + P ( d − i ) . (7) Like VFH, JH has the same adv antages ov er JJ99 when | F + 1 | < | F + 2 ∪ F − | . 3.1 Estimate ξ min j without disease prior or posterior If we solve ξ min j from arg min ξ j log P f + j | ξ j , π ( f j ) + instead of arg min ξ j log P f + j | ξ j , the resulting ξ min j has a closed form solution. T o see this, take the equality in Equation 1 and let x j ≡ P | π ( f + j ) | i =1 θ j i . The equality e f ( x j ) = e ξ j x j − f ∗ ( ξ j ) holds if and only if ξ min j = arg min ξ j ξ j x j − f ∗ ( ξ j ) . Simple algebra gives the closed form ξ min j = ( e x j − 1) − 1 . Concep- tually , arg min ξ j log P f + j | ξ j , π ( f j ) + would surely result in suboptimal ξ min j due to its lack of prior kno wledge. Howe ver , we find this approach competitiv e for a certain range of disease priors (shown in experiments). The prior/posterior-free (PPF) estimator of Ξ min is independent of disease prior or posterior and allows ξ min j to be pre-computed and cached regardless of JJ99, VFH or JH. 3.2 N -scalability of JJ99, VFH, and JH The ability to process a large number ( N ) of diagnosis with low latency is quintessential for web scalability . The v ariational step in JJ99+CVX (baseline) is O ( N ) , which would put increasing strain 4 on the server as N grows. On the other hand, the proposed VFH and JH perform the v ariational step in constant time w .r .t. N . W ith the proposed PPF estimator of Ξ min , all hybridization schemes can ex ecute v ariational transformation in constant time w .r .t. N . T able 1 summarizes the practical efficienc y of the proposed v ariational hybridization when used with either CVX or PPF estimator of Ξ min . The log log 1 term is the optimization cost using second order algorithms like Newton’ s method. Note that T able 1 only compares the cost of the variational step. W e ev aluate the overall inference cost for different inferencers in the Experiments section. T able 1: Detailed temporal comple xities for the proposed v ariational parameter estimation in terms of | D | , | F + 1 | , | F − | , , | S | , and N . All entries are Big- O complexity . Note that although JH is equi v alent to VFH in variational parameter estimation, JH will ha ve higher o verall inference complexity due to difference between Equation 5 and 7. Ξ min solver # of queries JJ99 VFH JH 1 | D | · | F + 1 | log log 1 | D | · | F + 1 | log log 1 | D | · | F + 1 | log log 1 CVX N N · | D | · | F + 1 | log log 1 | D | · | S | log log 1 | D | · | S | log log 1 1 | D | · | F + 1 | | D | · | F + 1 | | D | · | F + 1 | PPF N N · | D | · | F + 1 | | D | · | S | | D | · | S | 4 V ariational transf ormation with uncertain disease priors In addition to the inference formula (JJ99, VFH, or JH) and the Ξ min solver (CVX or PPF), there is a third component in variational inference that is critical to the posterior accurac y: the transformation ranking algorithm that partitions F + into F + 1 and F + 2 , giv en fixed | F + 1 | . (Jaakkola and Jordan, 1999) and (Ng and Jordan, 2000) use a simple greedy heuristic ordering (GDO) algorithm to rank the order of transformation based on the greedy local optimum for further minimizing the ov erall variational upper bound (which is firstly minimized by setting Ξ = Ξ min ). Minimizing the overall variational upper bound is, naturally , a commendable goal. But giv en the inaccuracy in widely-ranged disease priors, is there an ordering algorithm that can fender of f that uncertainty more effecti vely than GDO? T o simplify the discussion, we assume uniform θ j i = c for any j, i pair such that P ( f − j | d + i ) < 1 , where c ∈ (0 , + ∞ ) . Let the random variable (r .v .) P = 1 m P m k =1 U k , where U k ∼ iid Unif (0 , 2 1+ p ) for k = 1 , 2 , . . . , m . W e further assume that the inv erse disease prior odds: P d − i /P d + i = p i for any i ∈ { 1 , . . . , | D |} are drawn independently from P . The choice of m is rather inconsequential in our discussion. For a reasonable m (e.g., 5 < m < 1 , 000 ), the uniform mean distribution P introduces Gaussian-like v ariance without breaking the positi ve definite constraint on p i ’ s. W e desire to establish an ordering algorithm that minimizes the variance in posterior predictions due to P . The first step is to sho w its existence. F ormally , it is stated and proved in Proposition 1. Proposition 1. F ix p ∈ [0 , + ∞ ) , c ∈ (0 , + ∞ ) , and n ∈ { 1 , 2 , . . . , | F + |} . Then there e xists a F + 1 ⊂ F + such that | F + 1 | = n and V ar log P d i | F + 1 , P , Ξ min · P is appr oximately minimized for every d i ∈ D . Pr oof. Let the r .v . Q i denote P d i | F + 1 , P , Ξ min · P . And let γ > 1 denote the expected value of exp h c P | F + 1 | j =1 ξ min j 1 j i i , where the r .v . 1 j i models the likelihood of whether d i ∈ π ( f j ) . No w we can express Q i as Q i = γ γ P +1 −P and reduce V ar [log Q i ] to simple functions of E [ P ] and V ar [ P ] , which are known quantities of the uniform mean (Bates) distrib ution. V ar [log Q i ] = V ar log γ ( γ − 1) P + 1 = V ar [log (( γ − 1) P + 1)] ≈ V ar [( γ − 1) P + 1] ( E [( γ − 1) P + 1]) 2 , where V ar [( γ − 1) P + 1] ( E [( γ − 1) P + 1]) 2 = ( γ − 1) 2 V ar [ P ] [( γ − 1) E [ P ] + 1] 2 = 1 12 n 2 γ − 1 1+ p γ − 1 1+ p + 1 ! 2 = 1 3 n 1 1 + 1+ p γ − 1 ! 2 . (8) The “ ≈ ” in Equation 8 is the result of T aylor series expansion on log (( γ − 1) P + 1) , a common resort to approximate the moments of a ( log -)transformed random variable (van der V aart, 1998). 5 0" 40" 80" 120" 0.0" 1.0" 2.0" 3.0" 4.0" 5.0" ξ min "value ! |π(f+)|" γ" (a) 0" 50" 100" 150" 200" 1.0" 2.0" 3.0" 4.0" 5.0" 6.0" ξ min "value ! |π(f+)|" γ" (b) 0" 40" 80" 120" 0.0" 1.0" 2.0" 3.0" 4.0" ξ min "value" |π(f+)|" γ" (c) 0" 40" 80" 120" 0.0" 0.5" 1.0" 1.5" 2.0" ξ min "value ! |π(f+)|" γ" (d) Figure 2: Blue: E [ | π ( f + ) | ] ( y -axis) vs. ξ min ( x -axis) on synthesized experimental data. Red: γ ( y -axis) vs. the a verage of ξ min ’ s correspond to that γ ( x -axis). (a) p = 1 − 0 . 01 0 . 01 , c = − log (1 − 0 . 5) . (b) p = 1 − 0 . 001 0 . 001 , c = − log (1 − 0 . 6) . (c) p = 1 − 0 . 002 0 . 002 , c = − log (1 − 0 . 7) . (d) p = 1 − 0 . 005 0 . 005 , c = − log (1 − 0 . 9) . Approximately , V ar [log Q i ] ∝ γ . Observe that, for fixed n , choosing the n smallest ξ min j E [ 1 j i ] ’ s will guarantee the smallest γ . W e show the existence of F + 1 ⊂ F + by the following construction: consecutiv ely selecting the f + j ’ s associated with the n smallest ξ min j E [ 1 j i ] ’ s. Proposition 1 states the existence and the construction of F + 1 ⊂ F + for each n . Howe ver , the construction of F + 1 in volves calculating γ for each Q i and ξ min j for all f j ∈ F + , which makes the ordering algorithm slower than the actual v ariational transformation (so is GDO). Now we show how to simplify the construction algorithm of F + 1 to FDO without calculating γ ’ s or ξ min j ’ s. F or a wide range of practical parameter settings we are interested in (e.g., Figure 2 subfigures), we notice that γ is empirically ∝ P | F + 1 | j =1 ξ min j − 1 . The exact analysis of this claim may be tran- scendent but lim ξ min j →∞ E | π f + j | ξ min j = 0 , suggesting that γ ev entually approaches minimum when F + 1 is made of f + ’ s that ha ve the lar gest ξ min ’ s. Proposition 2 sho ws that E | π f + j | ∝ 1 ξ min j for any fixed p ∈ [0 , + ∞ ) , c ∈ (0 , + ∞ ) . As a result, we have P | F + 1 | j =1 E | π f + j | ∝ γ . In other words, compose F + 1 with the f + j ’ s that hav e the smallest | π f + j | yields the minimal γ . Proposition 2. F ix p ∈ [0 , + ∞ ) , c ∈ (0 , + ∞ ) . Then for any j ∈ j | π f + j 6 = ∅ , its variational parameter ξ min j decr eases monotonically on (0 , + ∞ ) as E | π f + j | incr eases. Pr oof. ξ min j can be solv ed from either arg min ξ j P f + j | ξ j , π ( f j ) + or arg min ξ j P f + j | ξ j . Since ξ min j = arg min ξ j P f + j | ξ j , π ( f j ) + can be seen as the special case when p = 0 , our argument belo w applies to both cases. For fixed p, c , we can solve for ξ min j by letting ∂ ∂ ξ j log P ( f + j | ξ j ) = 0 . W e ha ve E | π f + j | = 1 c log 1 + 1 ξ min j pe c e − ξ min j + 1 . T aking deri v ati ve of E | π f + j | w .r .t. ξ min j giv es: d E | π f + j | dξ min j = − e ξ min j + pe c 1 + ξ min j ξ min j + 1 log(1 + 1 ξ min j ) ce ξ min j ξ min j ( ξ min j + 1) < 0 , for ξ min j > 0 . (9) Since the same strategy minimizes V ar [log Q i ] for ev ery d i ∈ D , it must be the most stable globally as well. Therefore, we arri ve at an extremely simple v ariational transformation algorithm: sort f + j ∈ F + by ascending rank of π f + j and let that order be the order of v ariational transformation. W e refer to this strategy as finding-degree order (FDO). 5 Related work Exact inference on NOBN is fundamentally intractable (Cooper, 1990). Brute force inference on NOBN is O ( | F | · 2 | D | ) as it calculates P ( F ) by summing up P ( F | D 0 ) · P ( D 0 ) , where D 0 can be 6 the combination of the presence or the absence of any subsets of D . Junction tree algorithms (Pearl, 1988) can be more efficient in practice at O (2 | M | ) , where | M | is the maximal clique size of the moralized network. Quickscore (Heckerman, 1990) reduces the temporal complexity to some exponential function of a quantity substantially smaller than | D | or | M | and make the inference practical for common usage. Quickscore (Heckerman, 1990) achie ves e O | D | · 2 | F | by exploiting marginal and conditional independence 5 . T able 2: Overall temporal complexities for exact and variational inferences on NOBN in terms of | D | , | M | , | F | , and | F 0 | (note that all results are independent of | S | ). In practical applications like QMR-DT , | D | = 534 , | M | ≈ 151 , and | F | ≈ 43 (Jordan et al., 1999; Jaakkola and Jordan, 1999). Brute force Junction tree Quickscore V ariational O | F | · 2 | D | O | D | · 2 | M | e O | D | · 2 | F | e O | D | · h | F 0 | + 2 | F − F 0 | i V arious approximate inference methods are proposed in place of Quickscore when processing expen- siv e inference cases in NOBN (particularly QMR-DT ). V ariational inference for NOBN de veloped in (Jaakkola and Jordan, 1999) reduces the cost in computing P ( F ) by applying variational transforma- tion to a subset of F 0 ⊂ F . The variational e vidence is incorporated as posterior probability when performing quickscore on the remaining findings. The running time is then e O | D | · h | F 0 | + 2 | F − F 0 | i . Other general approximation methods that can be applied to NOBN include loopy belief propaga- tion (Murphy et al., 1999), mean field approximation (Ng and Jordan, 2000), and importance sampling based sampling methods (Gogate and Domingos, 2010). Some hav e also considered processing each finding in F sequentially (Bellala et al., 2013), which is arguably more similar to the style of a realistic patient-to-doctor diagnosis. 6 Experiments W e e v aluate the proposed inference algorithms on a real-world symptom-disease NOBN called F120 . F120 is a QMR-like medical NOBN constructed from multiple reliable medical knowledge sources and is amended by medical experts. Unlike QMR-DT , F120 focuses on symptoms and diseases related to maternal and infant care. Due to the anonymous submission, the authors refrain from discussing F120 ’ s details other than listing its vital statistics in T able 3. Due to the unav ailability of the proprietary QMR-DT network (Mansinghka et al., 2006), an anonymized v ersion ( aQMR ) is av ailable (Halpern and Sontag, 2013). Ho wever , aQMR anonymizes the symptom and disease node names and randomizes QMR-DT ’ s P ( f + | d + ) probabilities. W ith the medical connotation remov ed, it is difficult to confidently generate user queries (a user query is a tuple h F + , F − , d l i , where d l is the label disease: the most likely disease giv en the symptoms according to medical experts). Previous works working with aQMR do not face this issue since they do not require use-cases. F or example, (Halpern and Sontag, 2013; Jernite et al., 2013) focus on recovering the network structure and parameters; (Gogate and Domingos, 2010) focuses on the inference time and the r elative diver gence between approximate inference outcome and the exact inference outcome. W e also ev aluate the algorithm’ s scalability on the artificially generated S1 that is much larger in scale than F120 and QMR-DT . S1 has 40,000 hidden disease nodes, which is approximately the total number of diseases in ICD-10 classification. Figure 3 compares various inference algorithms against the baseline in (Jaakkola and Jordan, 1999) (JJ99+CVX). The proposed v ariational-first hybridization (VFH) is consistently faster than other methods. Despite having the same v ariational cost as VFH (shown in T able 1), Joint hybridization (JH) is the slowest due to its repeated negati ve e vidence computation of Equation 7. JJ99+PPF is significantly faster than JJ99+CVX due to the simplified Ξ min estimation. Figure 4 compares the inference accuracies on F120 . T o simulate the wide-ranged inaccuracy in the disease priors P ( d + ) ’ s, we scramble them with samples drawn from the uniform mean (Bates) 5 the soft- O bound is deriv ed from O | D | · | F − | · 2 | F + | giv en in (Heckerman, 1990). 7 distribution P at different 1 1+ p values. In total, we test four sets of queries with different kinds of false positi ve findings. Each query in the 1st set ( random20 ) contains 20% random f + ’ s that are not caused by the labeled disease. For the 2nd set ( chronic20 ), the 20% false f + ’ s are symptoms caused by some common chronic diseases (e.g., asthma, hypertension). Chronic symptoms are often mentioned inadvertently by patients during doctor’ s visit and making the diagnosis harder . The 3rd set ( chronic40 ) has the same type of f alse f + ’ s as chronic20 but the ratio is 40% of F + . For the 4th set ( confuse20 ), the 20% false f + ’ s are symptoms caused by diseases similar to the labeled disease (e.g., influenza and common cold). Such diseases share sev eral symptoms, but often the sev erity and other key symptoms are decisi ve in telling them apart. Each of the four sets has 800 queries and each query consists of on average eight f + ’ s and four f − ’ s. Shown in Figure 4, VFH+CVX+FDO performs better than the JJ99+CVX+GDO baseline across the wide range of P ( d + ) and ev en outperforms the exact Quickscore for certain P ( d + ) values. VFH+PPF+FDO suffers from its suboptimal (although fast, sho wn in Figure 3) ξ min estimations. VFH+PPF+FDO is comparable to JJ99+CVX+JJ99 at the lower range of P ( d + ) values. Lastly , JH+CVX+FDO has the closest performance portfolio to that of Quickscore and is quite competitiv e. NOBN | D | | S | |{ P ( f + | d + ) > 0 }| Density F120 665 1,276 10,552 1.24% QMR-DT 534 4,040 40,740 1.89% S1 40,000 12,000 384 million 80.0% T able 3: Comparisons of NOBNs on the netw ork size and den- sity (measured as total number of nonzero P ( f + | d + ) as a percentage of | D | · | F | ). 0" 10" 20" 30" 40" 50" 60" 0" 100" 200" 300" 400" Time%(sec)% #%of%queries% JJ99+CVX"(baseline)" JJ99+PPF" VFH+CVX" VFH+PPF" JH+CVX" JH+PPF" Figure 3: Runtime comparisons of different algorithms on the S1 network. 60# 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (a) 60# 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (b) 60# 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (c) 30# 40# 50# 60# 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (d) 60# 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (e) 60# 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (f) 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (g) 30# 40# 50# 60# 70# 80# 90# 100# 1.00E-06# 1.00E-05# 1.00E-04# 1.00E-03# 1.00E-02# 0.02# 0.04# (h) Quickscore* JJ99+CVX+GDO*(Jordan&Jakkola,*99)* VFH+PPF+FDO* VFH+CVX+FDO* JH+CVX+FDO* Figure 4: Accuracy comparisons on F120 . x -axis is the mean P ( d + ) value (i.e., 1 1+ p ); y -axis is top-1/top-3 accuracy . All configurations (except Quickscore) transforms 2 findings v ariationally . (a, e) random20 . (b, f) chronic20 . (c, g) chronic40 . (d, h) confuse20 . (a, b, c, d) measure top-1 accuracies. (e, f, g, h) measure the corresponding top-3 accuracies. 7 Conclusions and future w ork In this work, we study the important problem of approximate inference on noisy-or Bayesian networks (specifically , their medical applications). W e introduce novel algorithms for v ariational hybridization 8 and v ariational transformation. The proposed algorithms greatly immunize the current variational inference algorithms against the inaccuracies in widely-ranged hidden prior probabilities, a common issue that arises in modern medical applications of Bayesian networks. In the future, we plan to in vestigate the applicability of the proposed algorithms to more general Bayesian networks. References D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper , B. C. Catanzaro, J. Chen, M. Chrzanowski, A. Coates, G. Diamos, E. Elsen, J. Engel, L. Fan, C. Fougner , T . Han, A. Y . Hannun, B. Jun, P . LeGresley , L. Lin, S. Narang, A. Y . Ng, S. Ozair , R. Prenger , J. Raiman, S. Satheesh, D. Seetapun, S. Sengupta, Y . W ang, Z. W ang, C. W ang, B. Xiao, D. Y ogatama, J. Zhan, and Z. Zhu. Deep speech 2: End-to-end speech recognition in english and mandarin. CoRR , abs/1512.02595, 2015. URL . G. Bellala, J. Stanley , S. K. Bhavnani, and C. Scott. A rank-based approach to acti ve diagnosis. IEEE T ransactions on P attern Analysis and Machine Intelligence , 35(9):2078–2090, Sept 2013. ISSN 0162-8828. doi: 10.1109/TP AMI.2013.30. J. Cheng, R. Greiner, J. Kelly , D. Bell, and W . Liu. Learning bayesian networks from data: An information- theory based approach. Artificial Intelligence , 137(1 - 2):43 – 90, 2002. ISSN 0004-3702. doi: http: //dx.doi.org/10.1016/S0004- 3702(02)00191- 1. URL http://www.sciencedirect.com/science/ article/pii/S0004370202001911 . G. F . Cooper . The computational complexity of probabilistic inference using bayesian belief networks (research note). Artif . Intell. , 42(2-3):393–405, Mar . 1990. ISSN 0004-3702. doi: 10.1016/0004- 3702(90)90060- D. URL http://dx.doi.org/10.1016/0004- 3702(90)90060- D . A. L. Dawson and R. P . Dellav alle. Acne vulgaris. BMJ , 346, 2013. doi: 10.1136/bmj.f2634. URL http: //www.bmj.com/content/346/bmj.f2634 . V . Gog ate and P . M. Domingos. Formula-based probabilistic inference. In P . Grunwald and P . Spirtes, editors, U AI , pages 210–219. AU AI Press, 2010. Y . Halpern and D. Sontag. Unsupervised learning of noisy-or bayesian networks. In Pr oceedings of the 29th Confer ence, U AI , pages 272–281, 2013. D. Heckerman. A tractable inference algorithm for diagnosing multiple diseases. In U AI , pages 163–172, 1990. T . S. Jaakkola and M. I. Jordan. V ariational probabilistic inference and the qmr-dt network. J ournal of artificial intelligence r esearc h , pages 291–322, 1999. Y . Jernite, Y . Halpern, and D. Sontag. Discovering hidden variables in noisy-or networks using quartet tests. In Advances in Neural Information Pr ocessing Systems 26 , pages 2355–2363, 2013. M. I. Jordan, Z. Ghahramani, T . S. Jaakk ola, and L. K. Saul. An introduction to variational methods for graphical models. Machine learning , 37(2):183–233, 1999. W . Liao and Q. Ji. Learning bayesian network parameters under incomplete data with domain kno wledge. P attern Recognition , 42(11):3046 – 3056, 2009. ISSN 0031-3203. doi: http://dx.doi.org/10.1016/j.patcog.2009.04.006. URL http://www.sciencedirect.com/science/article/pii/S0031320309001472 . T . Luong, I. Sutskever , Q. V . Le, O. V inyals, and W . Zaremba. Addressing the rare word problem in neural machine translation. In A CL , 2015. URL . V . K. Mansinghka, C. K emp, T . L. Griffiths, and J. B. T enenbaum. Structured priors for structure learning. In Pr oceedings of the 22nd Conference, U AI , 2006. B. Middleton, M. Shwe, D. Heckerman, M. Henrion, E. Horvitz, H. Lehmann, and G. Cooper . Probabilistic diagnosis using a reformulation of the internist-1/qmr kno wledge base. Methods of information in medicine , 30:241–255, 1991. K. Murphy . Bayes Net T oolbox. https://github.com/bayesnet/bnt , 2002. [Online Lecture notes; accessed Jan-2016]. K. P . Murphy , Y . W eiss, and M. I. Jordan. Loopy belief propagation for approximate inference: An empirical study . In U AI , pages 467–475, 1999. A. Y . Ng and M. I. Jordan. Approximate inference a lgorithms for two-layer bayesian networks. In Advances in Neural Information Pr ocessing Systems , pages 533–539, 2000. 9 J. Pearl. Pr obabilistic Reasoning in Intelligent Systems: Networks of Plausible Infer ence . Mor gan Kaufmann Publishers Inc., San Francisco, CA, USA, 1988. ISBN 1558604790. C. Riggelsen. Learning parameters of bayesian networks from incomplete data via importance sampling. International Journal of Approximate Reasoning , 42(1 - 2):69 – 83, 2006. ISSN 0888-613X. doi: http://dx. doi.org/10.1016/j.ijar .2005.10.005. URL http://www.sciencedirect.com/science/article/ pii/S0888613X05000654 . A. W . van der V aart. Asymptotic statistics . Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge Univ ersity Press, 1998. ISBN 0-521-49603-9. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment