무작위 가치 함수로 일반화와 탐색을 동시에
RLSVI는 선형 가치 함수 파라미터화를 이용해 탐색과 일반화를 효율적으로 결합한 강화학습 알고리즘이다. 기존의 ε‑greedy·볼츠만 탐색이 지수적 비효율을 보이는 반면, RLSVI는 베이즈식 선형 회귀로 얻은 무작위 가치 함수를 샘플링해 탐색한다. 저자는 탭루라 사라 설정에서 기대 레지 regret이 ˜O(√H³SAT)임을 증명해, 차원에 비례하는 최적에 근접함을 보여준다. 실험에서도 동일한 선형 함수 공간을 사용했을 때 RLSVI가 현저히…
저자: Ian Osb, Benjamin Van Roy, Zheng Wen
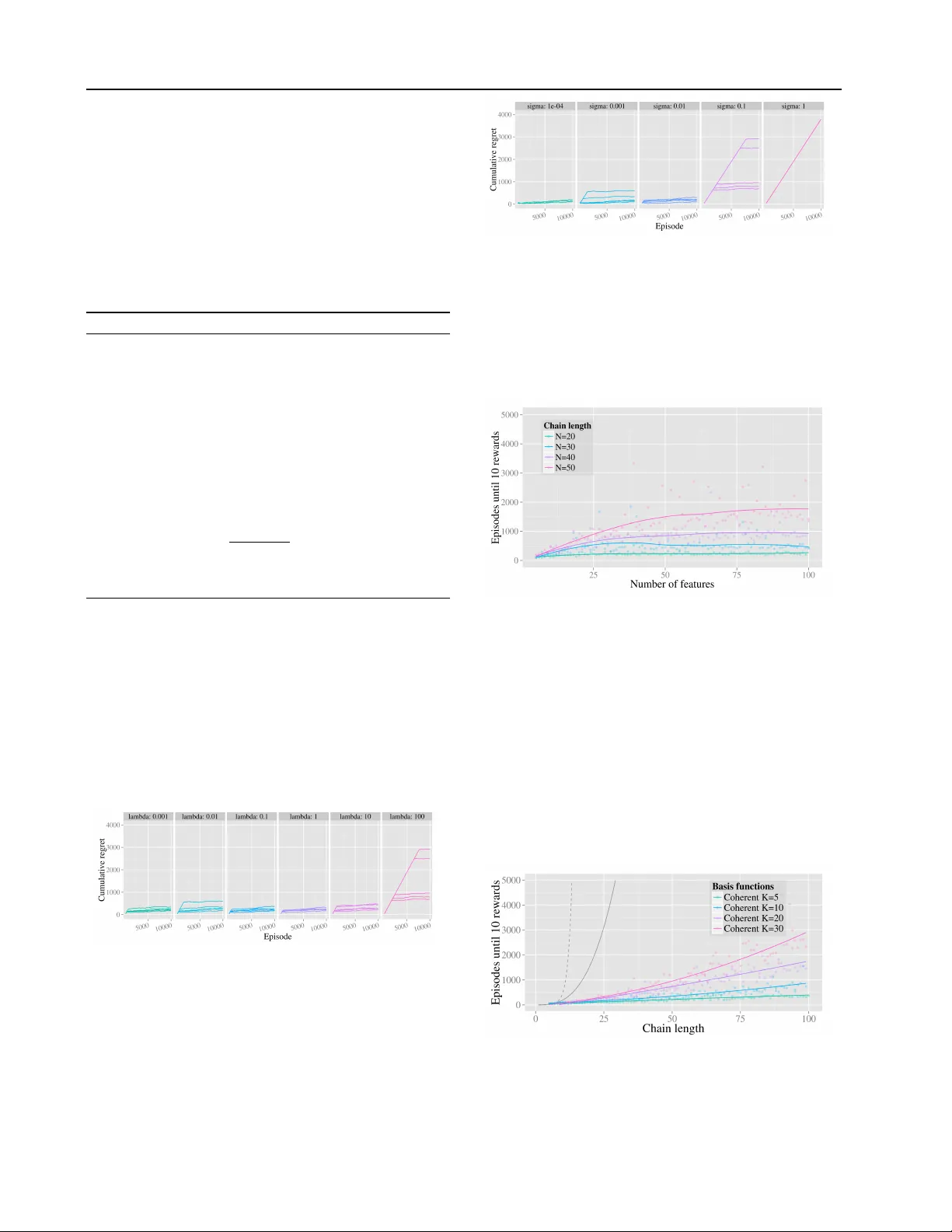
본 논문은 강화학습(RL)에서 대규모 상태‑행동 공간을 효율적으로 탐색하면서도 함수 근사를 통한 일반화를 동시에 달성하는 방법을 제시한다. 저자들은 기존의 Least‑Squares Value Iteration(LSVI) 기반 알고리즘이 ε‑greedy나 Boltzmann과 같은 액션‑다이더링 탐색 방식을 사용할 경우, 탐색 효율이 급격히 떨어져 레지 regret이 상태 수 S에 대해 지수적으로 증가할 수 있음을 지적한다. 이를 구체적으로 보여주기 위해, 상태가 1부터 N까지 순차적으로 연결된 체인 MDP를 예시로 들고, 오른쪽으로 이동하는 행동이 거의 확실하지만 작은 확률로 왼쪽으로 되돌아가는 구조를 분석한다. 이 환경에서 LSVI+ε‑greedy는 최적 정책을 찾기 위해 평균적으로 2^{S‑1} 회 이상의 에피소드가 필요함을 증명한다(Example 1).
이에 대한 대안으로 제안된 것이 Randomized Least‑Squares Value Iteration(RLSVI)이다. RLSVI는 매 에피소드마다 현재까지 수집된 데이터에 대해 베이즈 선형 회귀를 수행하고, 사후 분포 N(θ̂, Σ)에서 파라미터 θ를 샘플링한다. 샘플링된 θ를 사용해 Q‑함수 Q̂(s,a)=Φ(s,a)·θ를 구성하고, 각 단계에서 greedy 정책 argmax_a Q̂(s,a)를 선택한다. 이 과정은 Thompson sampling과 동일한 원리를 적용한 것으로, “가능성 있는 가치 함수 전체를 무작위로 선택”함으로써 탐색을 전역적으로 수행한다.
알고리즘은 두 단계로 구성된다. 첫 번째 단계(Algorithm 1)에서는 역방향으로 h=H‑1…0을 순회하며, 각 단계마다 회귀 행렬 A와 목표 벡터 b를 구성하고, 정규화 파라미터 λ와 노이즈 스케일 σ를 이용해 posterior mean θ_lh와 공분산 Σ_lh를 계산한다. 두 번째 단계(Algorithm 2)에서는 샘플링된 θ_lh를 이용해 에피소드 전체를 실행한다.
이론적 분석은 크게 두 부분으로 나뉜다. 첫째, Lemma 2를 통해 RLSVI가 생성하는 Q‑값이 실제 최적 Q‑값에 대해 stochastic optimism(확률적 낙관성)을 만족한다는 것을 보인다. 즉, 어떤 볼록·증가 함수 u에 대해 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기