Generalization and Exploration via Randomized Value Functions
We propose randomized least-squares value iteration (RLSVI) -- a new reinforcement learning algorithm designed to explore and generalize efficiently via linearly parameterized value functions. We explain why versions of least-squares value iteration …
Authors: Ian Osb, Benjamin Van Roy, Zheng Wen
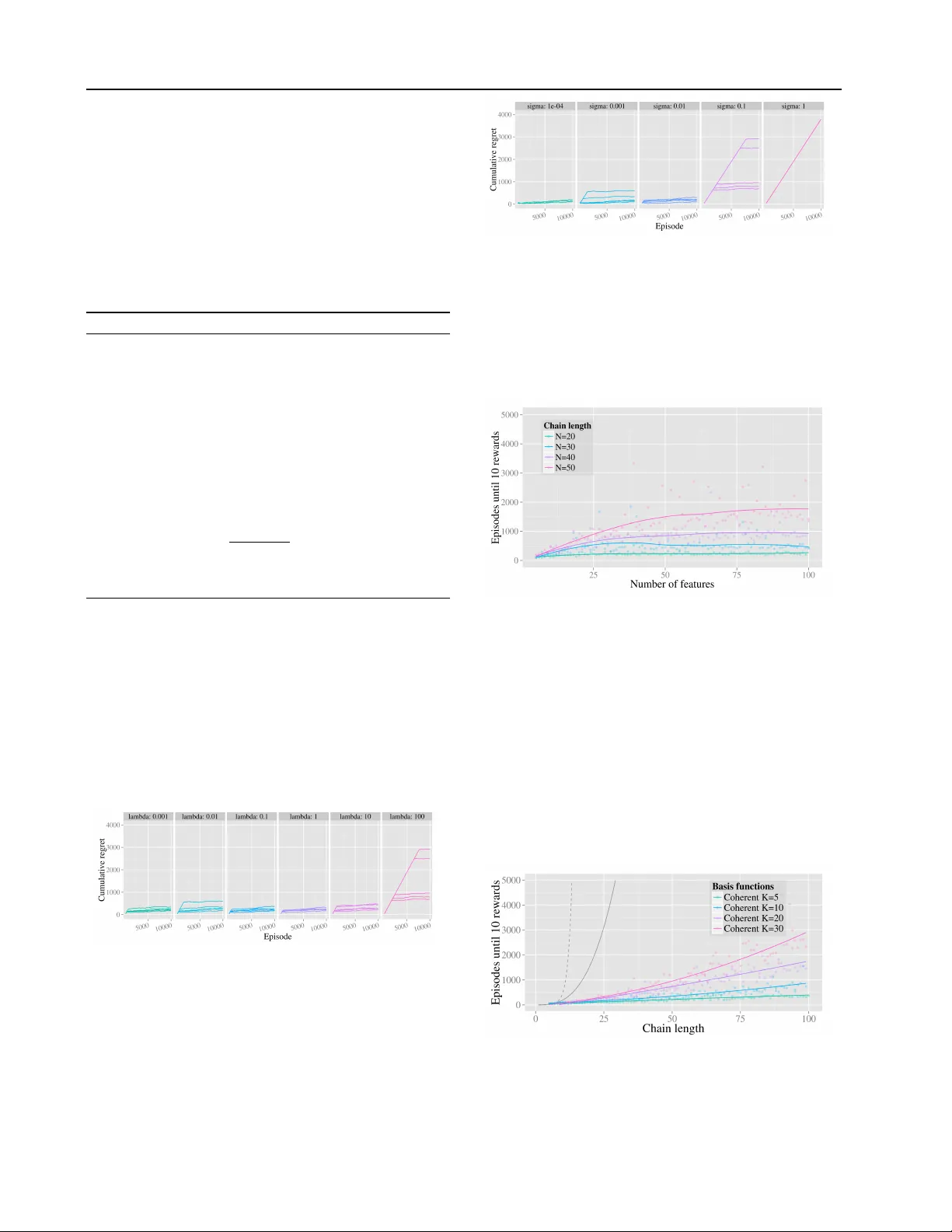
Generalization and Exploration via Randomized V alue Functions Ian Osband I O S BA N D @ S TA N F O R D . E D U Benjamin V an Roy B V R @ S TAN F O R D . E D U Zheng W en Z H E N G W E N 2 0 7 @ G M A I L . C O M Stanford Univ ersity Abstract W e propose randomized least-squares value iter- ation (RLSVI) – a new reinforcement learning al- gorithm designed to explore and generalize ef- ficiently via linearly parameterized value func- tions. W e explain why versions of least-squares value iteration that use Boltzmann or -greedy exploration can be highly inefficient, and we present computational results that demonstrate dramatic efficienc y gains enjoyed by RLSVI. Further , we establish an upper bound on the e x- pected regret of RLSVI that demonstrates near- optimality in a tabula r asa learning context. More broadly , our results suggest that random- ized v alue functions of fer a promising approach to tackling a critical challenge in reinforcement learning: synthesizing efficient e xploration and effecti ve generalization. 1. Introduction The design of reinforcement learning (RL) algorithms that explore intractably large state-action spaces efficiently re- mains an important challenge. In this paper, we propose randomized least-squares value iteration (RLSVI), which generalizes using a linearly parameterized value function. Prior RL algorithms that generalize in this way require, in the worst case, learning times exponential in the number of model parameters and/or the planning horizon. RLSVI aims to ov ercome these inefficiencies. RLSVI operates in a manner similar to least-squares value iteration (LSVI) and also shares much of the spirit of other closely related approaches such as TD, LSTD, and SARSA (see, e.g., ( Sutton & Barto , 1998 ; Szepesv ´ ari , 2010 )). What fundamentally distinguishes RLSVI is that the algorithm explores through randomly sampling statistically plausible value functions, whereas the aforementioned alternativ es are typically applied in conjunction with action-dithering schemes such as Boltzmann or -greedy exploration, which lead to highly inef ficient learning. The concept of explor - ing by sampling statistically plausible value functions is broader than any specific algorithm, and beyond our pro- posal and study of RLSVI. W e view an important role of this paper is to establish this broad concept as a promising approach to tackling a critical challenge in RL: synthesiz- ing efficient e xploration and effectiv e generalization. W e will present computational results comparing RLSVI to LSVI with action-dithering schemes. In our case stud- ies, these algorithms generalize using identical linearly pa- rameterized value functions but are distinguished by how they explore. The results demonstrate that RLSVI enjoys dramatic ef ficiency gains. Further , we establish a bound on the expected regret for an episodic tabula rasa learn- ing context. Our bound is ˜ O ( √ H 3 S AT ) , where S and A denote the cardinalities of the state and action spaces, T denotes time elapsed, and H denotes the episode duration. This matches the worst case lower bound for this problem up to logarithmic factors ( Jaksch et al. , 2010 ). It is interest- ing to contrast this against known ˜ O ( √ H 3 S 2 AT ) bounds for other prov ably efficient tab ula r asa RL algorithms (e.g., UCRL2 ( Jaksch et al. , 2010 )) adapted to this context. T o our knowledge, our results establish RLSVI as the first RL algorithm that is pro vably ef ficient in a tabula r asa context and also demonstrates efficienc y when generalizing via lin- early parameterized value functions. There is a sizable literature on RL algorithms that are pro v- ably efficient in tabula rasa contexts ( Brafman & T ennen- holtz , 2002 ; Kakade , 2003 ; Kearns & K oller , 1999 ; Latti- more et al. , 2013 ; Ortner & Ryabko , 2012 ; Osband et al. , 2013 ; Strehl et al. , 2006 ). The literature on RL algorithms that generalize and explore in a prov ably efficient manner is sparser . There is work on model-based RL algorithms ( Abbasi-Y adkori & Szepesv ´ ari , 2011 ; Osband & V an Roy , 2014a ; b ), which apply to specific model classes and are computationally intractable. V alue function generalization approaches have the potential to ov ercome those computa- tional challenges and of fer practical means for synthesizing efficient exploration and effecti ve generalization. A rele- vant line of work establishes that efficient RL with value function generalization reduces to ef ficient KWIK online Generalization and Exploration via Randomized V alue Functions regression ( Li & Littman , 2010 ; Li et al. , 2008 ). How- ev er, it is not kno wn whether the KWIK online regres- sion problem can be solv ed ef ficiently . In terms of con- crete algorithms, there is optimistic constraint propaga- tion (OCP) ( W en & V an Roy , 2013 ), a prov ably efficient RL algorithm for exploration and value function gener- alization in deterministic systems, and C-P ACE ( Pazis & Parr , 2013 ), a prov ably ef ficient RL algorithm that gen- eralizes using interpolativ e representations. These con- tributions represent important dev elopments, but OCP is not suitable for stochastic systems and is highly sensitiv e to model mis-specification, and generalizing effecti vely in high-dimensional state spaces calls for methods that e xtrap- olate. RLSVI advances this research agenda, le veraging randomized v alue functions to explore efficiently with lin- early parameterized value functions. The only other work we know of in volving exploration through random sam- pling of value functions is ( Dearden et al. , 1998 ). That work proposed an algorithm for tabula rasa learning; the algorithm does not generalize ov er the state-action space. 2. Episodic reinf orcement lear ning A finite-horizon MDP M = ( S , A , H , P, R, π ) , where S is a finite state space, A is a finite action space, H is the number of periods, P encodes transition probabilities, R encodes rew ard distributions, and π is a state distribution. In each episode, the initial state s 0 is sampled from π , and, in pe- riod h = 0 , 1 , · · · , H − 1 , if the state is s h and an action a h is selected then a ne xt state s h +1 is sampled from P h ( ·| s h , a h ) and a rew ard r h is sampled from R h ( ·| s h , a h , s h +1 ) . The episode terminates when state s H is reached and a terminal rew ard is sampled from R H ( ·| s H ) . T o represent the history of actions and observations over multiple episodes, we will often index v ariables by both episode and period. For example, s lh , a lh and r lh respec- tiv ely denote the state, action, and reward observed during period h in episode l . A policy µ = ( µ 0 , µ 1 , · · · , µ H − 1 ) is a sequence of func- tions, each mapping S to A . For each policy µ , we define a value function for h = 0 , .., H : V µ h ( s ):= E M h P H τ = h r τ s h = s,a τ = µ τ ( s τ ) for τ = h,..,H − 1 i The optimal value function is defined by V ∗ h ( s ) = sup µ V µ h ( s ) . A policy µ ∗ is said to be optimal if V µ ∗ = V ∗ . It is also useful to define a state-action optimal v alue function for h = 0 , .., H − 1 : Q ∗ h ( s, a ) := E M r h + V ∗ h +1 ( s h +1 ) s h = s, a h = a A policy µ ∗ is optimal ⇐ ⇒ µ ∗ h ( s ) ∈ argmax α ∈A Q ∗ h ( s,α ) , ∀ s,h . A reinforcement learning algorithm generates each action a lh based on observations made up to period h of episode l . Over each episode, the algorithm realizes reward P H h =0 r lh . One way to quantify the performance of a reinforcement learning algorithm is in terms of the expected cumulative re gret over L episodes, or time T = LH , defined by Regret( T , M ) = P T /H − 1 l =0 E M h V ∗ 0 ( s l 0 ) − P H h =0 r lh i . Consider a scenario in which the agent models that, for each h , Q ∗ h ∈ span [Φ h ] for some Φ h ∈ R S A× K . W ith some abuse of notation, we use S and A to denote the car- dinalities of the state and action spaces. W e refer this ma- trix Φ h as a generalization matrix and use Φ h ( s, a ) to de- note the row of matrix Φ h associated with state-action pair ( s, a ) . F or k = 1 , 2 , · · · , K , we write the k th column of Φ h as φ hk and refer to φ hk as a basis function. W e refer to contexts where the agent’ s belief is correct as coher ent learning , and refer the alternativ e as agnostic learning . 3. The problem with dithering f or exploration LSVI can be applied at each episode to estimate the op- timal v alue function Q ∗ from data gathered over previous episodes. T o form an RL algorithm based on LSVI, we must specify ho w the agent selects actions. The most com- mon scheme is to selectiv ely tak e actions at random, we call this approach dithering. Appendix A presents RL algo- rithms resulting from combining LSVI with the most com- mon schemes of -greedy or Boltzmann exploration. The literature on efficient RL sho ws that these dithering schemes can lead to regret that grows exponentially in H and/or S ( Kearns & Singh , 2002 ; Brafman & T en- nenholtz , 2002 ; Kakade , 2003 ). Prov ably efficient explo- ration schemes in RL require that exploration is directed to- wards potentially informati ve state-action pairs and consis- tent ov er multiple timesteps. This literature provides sev- eral more intelligent e xploration schemes that are pro vably efficient, b ut most only apply to tabula rasa RL, where lit- tle prior information is a vailable and learning is considered efficient ev en if the time required scales with the cardinal- ity of the state-action space. In a sense, RLSVI represents a synthesis of ideas from efficient tabula rasa reinforcement learning and value function generalization methods. T o motiv ate some of the benefits of RLSVI, in Figure 1 we provide a simple e xample that highlights the failings of dithering methods. In this setting LSVI with Boltzmann or -greedy e xploration requires e xponentially many episodes to learn an optimal polic y , ev en in a coherent learning con- text and e ven with a small number of basis functions. This en vironment is made up of a long chain of states S = { 1 , .., N } . Each step the agent can transition left or right. Actions left are deterministic, but actions right only succeed with probability 1 − 1 / N , otherwise they go left. All states ha ve zero re ward except for the far right N which Generalization and Exploration via Randomized V alue Functions giv es a reward of 1 . Each episode is of length H = N − 1 and the agent will begin each episode at state 1 . The opti- mal policy is to go right at every step to receive an e xpected rew ard of p ∗ = (1 − 1 N ) N − 1 each episode, all other policies giv e no reward. Example 1 establishes that, for any choice of basis function, LSVI with any -greedy or Boltzmann exploration will lead to regret that grows exponentially in S . A similar result holds for policy gradient algorithms. Figure 1. An MDP where dithering schemes are highly inefficient. Example 1. Let l ∗ be the first episode during which state N is visited. It is easy to see that θ lh = 0 for all h and all l < l ∗ . Furthermor e, with either -greedy or Boltzmann exploration, actions are sampled uniformly at random over episodes l < l ∗ . Thus, in any episode l < l ∗ , the r ed node will be r eached with pr obability p ∗ 2 − ( S − 1) = p ∗ 2 − H . It follows that E [ l ∗ ] ≥ 2 S − 1 − 1 and lim inf T →∞ Regret( T , M ) ≥ 2 S − 1 − 1 . 4. Randomized value functions W e now consider an alternati ve approach to exploration that in volves randomly sampling value functions rather than actions. As a specific scheme of this kind, we propose randomized least-squares value iteration (RLSVI), which we present as Algorithm 1 . 1 T o obtain an RL algorithm, we simply select greedy actions in each episode, as speci- fied in Algorithm 2 . The manner in which RLSVI explores is inspired by Thompson sampling ( Thompson , 1933 ), which has been shown to explore efficiently across a very general class of online optimization problems ( Russo & V an Roy , 2013 ; 2014 ). In Thompson sampling, the agent samples from a posterior distrib ution ov er models, and selects the action that optimizes the sampled model. RLSVI similarly sam- ples from a distribution over plausible value functions and selects actions that optimize resulting samples. This distri- bution can be thought of as an approximation to a poste- rior distribution o ver v alue functions. RLSVI bears a close connection to PSRL ( Osband et al. , 2013 ), which maintains and samples from a posterior distrib ution over MDPs and is a direct application of Thompson sampling to RL. PSRL satisfies regret bounds that scale with the dimensionality , rather than the cardinality , of the underlying MDP ( Osband & V an Ro y , 2014b ; a ). Howe ver , PSRL does not accommo- date value function generalization without MDP planning, a feature that we expect to be of great practical importance. 1 Note that when l = 0 , both A and b are empty , hence, we set ˜ θ l 0 = ˜ θ l 1 = · · · = ˜ θ l,H − 1 = 0 . Algorithm 1 Randomized Least-Squares V alue Iteration Input: Data Φ 0 ( s i 0 ,a i 0 ) ,r i 0 ,.., Φ H − 1 ( s iH − 1 ,a iH − 1 ) ,r iH : i < L , Parameters λ > 0 , σ > 0 Output: ˜ θ l 0 ,.., ˜ θ l,H − 1 1: for h = H − 1 ,.., 1 , 0 do 2: Generate regression problem A ∈ R l × K , b ∈ R l : A ← Φ h ( s 0 h ,a 0 h ) . . . Φ h ( s l − 1 ,h ,a l − 1 ,h ) b i ← ( r ih + max α Φ h +1 ˜ θ l,h +1 ( s i,h +1 ,α ) if h < H − 1 r ih + r i,h +1 if h = H − 1 3: Bayesian linear regression for the v alue function θ lh ← 1 σ 2 1 σ 2 A > A + λI − 1 A > b Σ lh ← 1 σ 2 A > A + λI − 1 4: Sample ˜ θ lh ∼ N ( θ lh , Σ lh ) from Gaussian posterior 5: end for Algorithm 2 RLSVI with greedy action Input: Features Φ 0 ,.., Φ H − 1 ; σ > 0 , λ > 0 1: for l = 0 , 1 ,.. do 2: Compute ˜ θ l 0 ,.., ˜ θ l,H − 1 using Algorithm 1 3: Observe s l 0 4: for h = 0 ,..,H − 1 do 5: Sample a lh ∈ arg max α ∈A Φ h ˜ θ lh ( s lh ,α ) 6: Observe r lh and s l,h +1 7: end for 8: Observe r lH 9: end for 5. Pro vably efficient tab ular learning RLSVI is an algorithm designed for efficient exploration in large MDPs with linear value function generalization. So far , there are no algorithms with analytical regret bounds in this setting. In fact, most common methods are provably inefficient , as demonstrated in Example 1 , regardless of the choice of basis function. In this section we will establish an expected regret bound for RLSVI in a tab ular setting without generalization where the basis functions Φ h = I . The bound is on an expectation with respect to a prob- ability space (Ω , F , P ) . W e define the MDP M = ( S , A , H , P , R , π ) and all other random variables we will consider with respect to this probability space. W e assume that S , A , H , and π , are deterministic and that R and P are drawn from a prior distribution. W e will assume that Generalization and Exploration via Randomized V alue Functions rew ards R ( s, a, h ) are dra wn from independent Dirichlet α R ( s, a, h ) ∈ R 2 + with v alues on {− 1 , 0 } and transitions Dirichlet α P ( s, a, h ) ∈ R S + . Analytical techniques exist to extend similar results to general bounded distrib utions; see, for example ( Agra wal & Goyal , 2012 ). Theorem 1. If Algorithm 1 is executed with Φ h = I for h = 0 ,..,H − 1 , λ ≥ max ( s,a,h ) 1 T α R ( s,a,h )+ 1 T α P ( s,a,h ) and σ ≥ √ H 2 +1 , then: E [Regret( T , M )] ≤ ˜ O √ H 3 S AT (1) Surprisingly , these scalings better state of the art opti- mistic algorithms specifically designed for efficient analy- sis which would admit ˜ O ( √ H 3 S 2 AT ) regret ( Jaksch et al. , 2010 ). This is an important result since it demonstrates that RLSVI can be prov ably-efficient, in contrast to popular dithering approaches such as -greedy which are prov ably inefficient . 5.1. Preliminaries Central to our analysis is the notion of stochastic optimism, which induces a partial ordering among random variables. Definition 1. F or any X and Y r eal-valued random vari- ables we say that X is stoc hastically optimistic for Y if and only if for any u : R → R conve x and incr easing E [ u ( X )] ≥ E [ u ( Y )] . W e will use the notation X < so Y to expr ess this r elation. It is worth noting that stochastic optimism is closely con- nected with second-order stochastic dominance: X < so Y if and only if − Y second-order stochastically dominates − X ( Hadar & Russell , 1969 ). W e repoduce the following result which establishes such a relation inv olving Gaussian and Dirichlet random variables in Appendix G . Lemma 1. F or all V ∈ [0 , 1] N and α ∈ [0 , ∞ ) N with α T 1 ≥ 2 , if X ∼ N ( α > V /α > 1 , 1 /α > 1 ) and Y = P T V for P ∼ Diric hlet( α ) then X < so Y . 5.2. Proof sk etch Let ˜ Q l h = Φ h ˜ θ lh and ˜ µ l denote the value function and policy generated by RLSVI for episode l and let ˜ V l h ( s ) = max a ˜ Q l h ( s, a ) . W e can decompose the per-episode regret V ∗ 0 ( s l 0 ) − V ˜ µ l 0 ( s l 0 ) = ˜ V l 0 ( s l 0 ) − V ˜ µ l 0 ( s l 0 ) | {z } ∆ conc l + V ∗ 0 ( s l 0 ) − ˜ V l 0 ( s l 0 ) | {z } ∆ opt l . W e will bound this regret by first sho wing that RLSVI gen- erates optimistic estimates of V ∗ , so that ∆ opt l has non- positiv e expectation for any history H l av ailable prior to episode l . The remaining term ∆ conc l vanishes as estimates generated by RLSVI concentrate around V ∗ . Lemma 2. Conditional on any data H , the Q-values gen- erated by RLSVI ar e stochastically optimistic for the true Q-values ˜ Q l h ( s, a ) < so Q ∗ h ( s, a ) for all s, a, h . Pr oof. Fix any data H l av ailable and use backwards in- duction on h = H − 1 , .., 1 . F or an y ( s, a, h ) we write n ( s, a, h ) for the amount of visits to that datapoint in H l . W e will write ˆ R ( s, a, h ) , ˆ P ( s, a, h ) for the empirical mean rew ard and mean transitions based upon the data H l . W e can now write the posterior mean re wards and transitions: R ( s, a, h ) |H l = − 1 × α R 1 ( s, a, h ) + n ( s, a, h ) ˆ R ( s, a, h ) 1 T α R ( s, a, h ) + n ( s, a, h ) P ( s, a, h ) |H l = α P ( s, a, h ) + n ( s, a, h ) ˆ P ( s, a, h ) 1 T α P ( s, a, h ) + n ( s, a, h ) Now , using Φ h = I for all ( s, a, h ) we can write the RLSVI updates in similar form. Note that, Σ lh is diagonal with each diagonal entry equal to σ 2 / ( n ( s, a, h ) + λσ 2 ) . In the case of h = H − 1 θ l H − 1 ( s, a ) = n ( s, a, H − 1) ˆ R ( s, a, H − 1) n ( s, a, H − 1) + λσ 2 Using the relation that ˆ R ≥ R Lemma 1 means that N ( θ l H − 1 ( s, a ) , 1 n ( s, a, h ) + 1 T α R ( s, a, h ) ) < so R H − 1 |H l . Therefore, choosing λ > max s,a,h 1 T α R ( s, a, h ) and σ > 1 , we must satisfy the lemma for all s, a and h = H − 1 . For the inducti ve step we assume that the result holds for all s, a and j > h , we now want to prove the result for all ( s, a ) at timestep h . Once again, we can express θ l h ( s, a ) in closed form. θ l h ( s, a ) = n ( s, a, h ) ˆ R ( s, a, h ) + ˆ P ( s, a, h ) T ˜ V l h +1 n ( s, a, h ) + λσ 2 T o simplify notation we omit the arguments ( s, a, h ) where they should be obvious from context. The posterior mean estimate for the next step v alue V ∗ h , conditional on H l : E [ Q ∗ h ( s, a ) |H l ] = R + P T V ∗ h +1 ≤ n ( ˆ R + ˆ P T V ∗ h +1 ) n + λσ 2 . As long as λ > 1 T α R + 1 T ( α P ) and σ 2 > H 2 . By our induction process ˜ V l h +1 < so V ∗ h +1 so that E [ Q ∗ h ( s, a ) |H l ] ≤ E " n ( ˆ R + ˆ P T ˜ V l h +1 ) n + λσ 2 | H l # . W e can conclude by Lemma 1 and noting that the noise from rewards is dominated by N (0 , 1) and the noise from transitions is dominated by N (0 , H 2 ) . This requires that σ 2 ≥ H 2 + 1 . Generalization and Exploration via Randomized V alue Functions Lemma 2 means RLSVI generates stochastically optimistic Q-values for any history H l . All that remains is to prov e the remaining estimates E [∆ conc l |H l ] concentrate around the true values with data. Intuitiv ely this should be clear , since the size of the Gaussian perturbations decreases as more data is gathered. In the remainder of this section we will sketch this result. The concentration error ∆ conc l = ˜ V l 0 ( s l 0 ) − V ˜ µ l 0 ( s l 0 ) . W e decompose the value estimate ˜ V l 0 explicitly: ˜ V l 0 ( s l 0 ) = n ( ˆ R + ˆ P T ˜ V l h +1 ) n + λσ 2 + w σ = R + P T ˜ V l h +1 + b R + b P + w σ 0 where w σ is the Gaussian noise from RLSVI and b R = b R ( s l 0 , a l 0 0) , b P = b P ( s l 0 , a l 0 0) are optimistic bias terms for RLSVI. These terms emerge since RLSVI shrinks es- timates towards zero rather than the Dirichlet prior for re- wards and transitions. Next we note that, conditional on H l we can rewrite P T ˜ V l h +1 = ˜ V l h +1 ( s 0 ) + d h where s 0 ∼ P ∗ ( s, a, h ) and d h is some martingale difference. This allo ws us to decom- pose the error in our policy to the estimation error of the states and actions we actually visit. W e also note that, con- ditional on the data H l the true MDP is independent of the sampling process of RLSVI. This means that: E [ V ˜ µ l 0 ( s l 0 ) |H l ] = R + P T V ˜ µ l h +1 . Once again, we can replace this transition term with a sin- gle sample s 0 ∼ P ∗ ( s, a, h ) and a martingale difference. Combining these observ ations allows us to reduce the con- centration error E [ ˜ V l 0 ( s l 0 ) − V ˜ µ l 0 ( s l 0 ) |H l ] = H − 1 X h =0 b R ( s lh , a lh , h ) + b P ( s lh , a lh , h ) + w σ h . W e can e ven write e xplicit expressions for b R , b P and w σ . b R ( s, a, h ) = n ˆ R n + λσ 2 − n ˆ R − α R 1 n + 1 T α R b P ( s, a, h ) = n ˆ P T ˜ V l h +1 n + λσ 2 − ( n ˆ P + α P ) T ˜ V l h +1 n + 1 T α P w σ h ∼ N 0 , σ 2 n + λσ 2 The final details for this proof are technical but the ar- gument is simple. W e let λ = 1 T α R + 1 T α P and σ = √ H 2 +1 . Up to ˜ O notation b R ' α R 1 n + 1 T α P , b P ' H 1 T α P n + 1 T α P and w σ h ' H √ n + H 2 1 T α R + 1 T α P . Summing using a pi- geonhole principle for P s,a,h n ( s,a,h )= T gives us an upper bound on the regret. W e write K ( s,a,h ):= α R 1 ( s,a,h )+ H 1 T α P ( s,a,h ) to bound the ef fects of the prior mistmatch in RLSVI arising from the bias terms b R , b P . The constraint α T 1 ≥ 2 can only be violated twice for each s, a, h . Therefore up to O ( · ) notation: E h P T /H − 1 l =0 E [∆ conc l |H l ] i ≤ 2 S AH + P s,a,h K ( s,a,h )log ( T + K ( s,a,h ))+ H p S AH T log( T ) This completes the proof of Theorem 1 . 6. Experiments Our analysis in Section 5 shows that RLSVI with tabular basis functions acts as an ef fectiv e Gaussian approximation to PSRL. This demonstrates a clear distinction between exploration via randomized value functions and dithering strategies such as Example 1 . Ho wev er , the motiv ating for RLSVI is not for tabular en vironments, where se veral prov- ably efficient RL algorithms already exist, but instead for large systems that require generalization. W e believ e that, under some conditions, it may be possi- ble to establish polynomial regret bounds for RLSVI with value function generalization. T o stimulate thinking on this topic we present a conjecture of result what may be pos- sible in Appendix B . For no w , we will present a series of experiments designed to test the applicability and scalabil- ity of RLSVI for exploration with generalization. Our experiments are divided into three sections. First, we present a series of didactic chain environments similar to Figure 1 . W e sho w that RLSVI can effecti vely synthesize exploration with generalization with both coherent and ag- nostic v alue functions that are intractable under any dither - ing scheme. Next, we apply our Algorithm to learning to play T etris. W e demonstrate that RLSVI leads to faster learning, improved stability and a superior learned policy in a large-scale video game. Finally , we consider a busi- ness application with a simple model for a recommendation system. W e show that an RL algorithm can improve upon ev en the optimal myopic bandit strategy . RLSVI learns this optimal strategy when dithering strate gies do not. 6.1. T esting for efficient exploration W e now consider a series of en vironments modelled on Example 1 , where dithering strategies for exploration are prov ably inefficient. Importantly , and unlike the tabular setting of Section 5 , our algorithm will only interact with the MDP but through a set of basis function Φ which gener- alize across states. W e examine the empirical performance of RLSVI and find that it does efficiently balance e xplo- ration and generalization in this didactic example. 6 . 1 . 1 . C O H E R E N T L E A R N I N G In our first experiments, we generate a random set of K ba- sis functions. This basis is coherent b ut the individual basis functions are not otherwise informati ve. W e form a ran- Generalization and Exploration via Randomized V alue Functions dom linear subspace V hK spanned by ( 1 , Q ∗ h , ˜ w 1 , .., ˜ w k − 2 ) . Here w i and ˜ w i are IID Gaussian ∼ N (0 , I ) ∈ R S A . W e then form Φ h by projecting ( 1 , w 1 , .., w k − 1 ) onto V hK and renormalize each component to have equal 2-norm 2 . Figure 2 presents the empirical regret for RLSVI with K = 10 , N = 50 , σ = 0 . 1 , λ = 1 and an -greedy agent ov er 5 seeds 3 . (a) First 2000 episodes (b) First 10 6 episodes Figure 2. Efficient exploration on a 50-chain Figure 1 shows that RLSVI consistently learns the opti- mal polic y in roughly 500 episodes. Any dithering strate gy would take at least 10 15 episodes for this result. The state of the art upper bounds for the efficient optimistic algo- rithm UCRL given by appendix C.5 in ( Dann & Brunskill , 2015 ) for H = 15 , S = 6 , A = 2 , = 1 , δ = 1 only kick in af- ter more than 10 10 suboptimal episodes. RLSVI is able to effecti vely exploit the generalization and prior structure from the basis functions to learn much faster . W e now examine how learning scales as we change the chain length N and number of basis functions K . W e ob- serve that RLSVI essentially maintains the optimal policy once it discov ers the rew arding state. W e use the number of episodes until 10 re wards as a proxy for learning time. W e report the average of fi ve random seeds. Figure 3 examines the time to learn as we vary the chain length N with fix ed K =10 basis functions. W e include the dithering lo wer bound 2 N − 1 as a dashed line and a lower bound scaling 1 10 H 2 S A for tab ular learning algorithms as a solid line ( Dann & Brunskill , 2015 ). F or N =100 , 2 N − 1 > 10 28 and H 2 S A> 10 6 . RLSVI demonstrates scalable gen- eralization and exploration to outperform these bounds. Figure 3. RLSVI learning time against chain length. Figure 4 examines the time to learn as we vary the basis functions K in a fixed N =50 length chain. Learning time 2 For more details on this e xperiment see Appendix C . 3 In this setting any choice of or Boltzmann η is equiv alent. scales gracefully with K . Further , the mar ginal effect of K decrease as dim( V hK )= K approaches dim( R S A )=100 . W e include a local polynomial regression in blue to high- light this trend. Importantly , ev en for large K the perfor- mance is f ar superior to the dithering and tabular bounds 4 . Figure 4. RLSVI learning time against number of basis features. Figure 5 examines these same scalings on a logarithmic scale. W e find the data for these experiments is consis- tent with polynomial learning as hypothesized in Appendix B . These results are remarkably robust over sev eral orders of magnitude in both σ and λ . W e present more detailed analysis of these sensitivies in Appendix C . Figure 5. Empirical support for polynomial learning in RLSVI. 6 . 1 . 2 . A G N O S T I C L E A R N I N G Unlike the e xample abov e, practical RL problems will typ- ically be agnostic. The true v alue function Q ∗ h will not lie within V hK . T o e xamine RLSVI in this setting we generate basis functions by adding Gaussian noise to the true value function φ hk ∼ N ( Q ∗ h , ρI ) . The parameter ρ determines the scale of this noise. For ρ = 0 this problem is coherent but for ρ > 0 this will typically not be the case. W e fix N = 20 , K = 20 , σ = 0 . 1 and λ = 1 . For i =0 ,.., 1000 we run RLSVI for 10,000 episodes with ρ = i/ 1000 and a random seed. Figure 6 presents the num- ber of episodes until 10 rew ards for each value of ρ . For large v alues of ρ , and an extremely misspecified basis, RLSVI is not effecti ve. Howe ver , there is some region 0 < ρ < ρ ∗ where learning remains remarkably stable 5 . This simple example gives us some hope that RLSVI can be 4 For chain N =50 , the bounds 2 N − 1 > 10 14 and H 2 S A> 10 5 . 5 Note Q ∗ h ( s,a ) ∈{ 0 , 1 } so ρ =0 . 5 represents significant noise. Generalization and Exploration via Randomized V alue Functions useful in the agnostic setting. In our remaining experiments we will demonstrate that RLSVI can acheiv e state of the art results in more practical problems with agnostic features. Figure 6. RLSVI is somewhat rob ust model mispecification. 6.2. T etris W e now turn our attention to learning to play the iconic video game T etris. In this game, random blocks fall se- quentially on a 2D grid with 20 rows and 10 columns. At each step the agent can move and rotate the object sub- ject to the constraints of the grid. The game starts with an empty grid and ends when a square in the top row be- comes full. Howe ver , when a ro w becomes full it is re- mov ed and all bricks above it mo ve do wnward. The objec- tiv e is to maximize the score attained (total number of ro ws remov ed) before the end of the game. T etris has been something of a benchmark problem for RL and approximate dynamic programming, with sev eral pa- pers on this topic ( Gabillon et al. , 2013 ). Our focus is not so much to learn a high-scoring T etris player , but instead to demonstrate the RLSVI offers benefits ov er other forms of e xploration with LSVI. T etris is challenging for RL with a huge state space with more than 2 200 states. In order to tackle this problem efficiently we use 22 benchmark fea- tures. These featurs gi ve the height of each column, the ab- solute difference in height of each column, the maximum height of a column, the number of “holes” and a constant. It is well kno wn that you can find far superior linear basis functions, but we use these to mirror their approach. In order to apply RLSVI to T etris, which does not have fixed episode length, we made a few natural modifica- tions to the algorithm. First, we approximate a time- homogeneous value function. W e also only the keep most recent N =10 5 transitions to cap the linear gro wth in mem- ory and computational requirements, similar to ( Mnih , 2015 ). Details are provided in Appendix D . In Figure 7 we present learning curv es for RLSVI λ =1 ,σ =1 and LSVI with a tuned -greedy exploration schedule 6 av eraged over 5 seeds. The results are significant in se veral ways. First, both RLSVI and LSVI make significant improv e- ments ov er the previous approach of LSPI with the same 6 W e found that we could not acheiv e good performance for any fixed . W e used an annealing exploration schedule that was tuned to giv e good performance. See Appendix D basis functions ( Bertsekas & Iof fe , 1996 ). Both algorithms reach higher final performance ( ' 3500 and 4500 respec- tiv ely) than the best lev el for LSPI ( 3183 ). They also reach this performance after many fewer games and, un- like LSPI do not “collapse” after finding their peak perfor- mance. W e believe that these improv ements are mostly due to the memory replay buf fer , which stores a bank of recent past transitions, rather than LSPI which is purely online. Second, both RLSVI and LSVI learn from scratch where LSPI required a scoring initial policy to be gin learning. W e believ e this is due to improved exploration schemes, LSPI is completely greedy so struggles to learn without an ini- tial policy . LSVI with a tuned schedule is much better . Howe ver , we do see a significant impro vement through e x- ploration via RLSVI even when compared to the tuned scheme. More details are a vailable in Appendix D . Figure 7. Learning to play T etris with linear Bertsekas features. 6.3. A recommendation engine W e will no w sho w that efficient exploration and general- ization can be helpful in a simple model of customer in- teraction. Consider an agent which recommends J ≤ N products from Z = { 1 , 2 , . . . , N } sequentially to a cus- tomer . The conditional probability that the customer likes a product depends on the product, some items are better than others. Howe ver it also depends on what the user has observed, what she liked and what she disliked. W e repre- sent the products the customer has seen by ˜ Z ⊆ Z . For each product n ∈ ˜ Z we will indicate x n ∈ {− 1 , +1 } for her preferences { dislike, like } respectiv ely . If the customer has not observed the product n / ∈ ˜ Z we will write x n = 0 . W e model the probability that the customer will like a new product a / ∈ ˜ Z by a logistic transformation linear in x : P ( a | x ) = 1 / (1 + exp ( − [ β a + P n γ an x n ])) . (2) Importantly , this model reflects that the customers’ pref- erences may ev olve as their experiences change. For ex- ample, a customer may be much more likely to watch the second season of the TV show “Breaking Bad” if the y ha ve watched the first season and liked it. The agent in this setting is the recommendation system, Generalization and Exploration via Randomized V alue Functions whose goal is to maximize the cumulativ e amount of items liked through time for each customer . The agent does not kno w p ( a | x ) initially , b ut can learn to estimate the parameters β , γ through interactions across different cus- tomers. Each customer is modeled as an episode with hori- zon length H = J with a “cold start” and no previous ob- served products ˜ Z = ∅ . For our simulations we set β a = 0 ∀ a and sample a random problem instance by sampling γ an ∼ N (0 , c 2 ) independently for each a and n . Figure 8. RLSVI performs better than Boltzmann exploration. Figure 9. RLSVI can outperform the optimal myopic policy . Although this setting is simple, the number of possible states |S | = |{− 1 , 0 , +1 }| H = 3 J is exponential in J . T o learn in time less than |S | it is crucial that we can ex- ploit generalization between states as per equation ( 2 ). For this problem we constuct the follo wing simple basis func- tions: ∀ 1 ≤ n, m, a ≤ N , let φ m ( x, a ) = 1 { a = m } and φ mn ( x, a ) = x n 1 { a = m } . In each period h form Φ h = (( φ n ) n , ( φ m ) m ) . The dimension of our function class K = N 2 + N is exponentially smaller than the num- ber of states. Ho wev er , barring a freak ev ent, this simple basis will lead to an agnostic learning problem. Figure 8 and 9 show the performance of RLSVI compared to sev eral benchmark methods. In Figure 8 we plot the cumulativ e regret of RLSVI when compared against LSVI with Boltzmann exploration and identical basis features. W e see that RLSVI explores much more ef ficiently than Boltzmann exploration o ver a wide range of temperatures. In Figure 9 we show that, using this efficient exploration method, the reinforcement learning policy is able to out- perform not only benchmark bandit algorithms but e ven the optimal myopic polic y 7 . Bernoulli Thompson sampling does not learn much e ven after 1200 episodes, since the algorithm does not take context into account. The linear contextual bandit outperforms RLSVI at first. This is not surprising, since learning a myopic policy is simpler than a multi-period policy . Howe ver as more data is gathered RLSVI ev entually learns a richer policy which outperforms the myopic policy . Appendix E provides pseudocode for this computational study . W e set N = 10 , H = J = 5 , c = 2 and L = 1200 . Note that such problems have |S | = 4521 states; this al- lows us to solv e each MDP exactly so that we can compute regret. Each result is av eraged ov er 100 problem instances and for each problem instance, we repeat simulations 10 times. The cumulativ e regret for both RLSVI (with λ = 0 . 2 and σ 2 = 10 − 3 ) and LSVI with Boltzmann exploration (with λ = 0 . 2 and a variety of “temperature” settings η ) are plotted in Figure 8 . RLSVI clearly outperforms LSVI with Boltzmann exploration. Our simulations use an e xtremely simplified model. Nev er- theless, the y highlight the potential value of RL ov er multi- armed bandit approaches in recommendation systems and other customer interactions. An RL algorithm may out- perform even ev en an optimal myopic system, particularly where large amounts of data are av ailable. In some settings, efficient generalization and e xploration can be crucial. 7. Closing remarks W e ha ve established a regret bound that af firms ef ficiency of RLSVI in a tabula rasa learning context. Howe ver the real promise of RLSVI lies in its potential as an efficient method for exploration in large-scale en vironments with generalization. RLSVI is simple, practical and explores efficiently in sev eral en vironments where state of the art approaches are ineffecti ve. W e believe that this approach to exploration via random- ized v alue functions represents an important concept be- yond our specific implementation of RLSVI. RLSVI is designed for generalization with linear value functions, but many of the great successes in RL hav e come with highly nonlinear “deep” neural networks from Backgam- mon ( T esauro , 1995 ) to Atari 8 ( Mnih , 2015 ). The insights and approach gained from RLSVI may still be useful in this nonlinear setting. For example, we might adapt RLSVI to instead take approximate posterior samples from a nonlin- ear value function via a nonparametric bootstrap ( Osband & V an Roy , 2015 ). 7 The optimal myopic policy knows the true model defined in Equation 2 , but does not plan o ver multiple timesteps. 8 Interestingly , recent work has been able to reproduce similar performance using linear value functions ( Liang et al. , 2015 ). Generalization and Exploration via Randomized V alue Functions References Abbasi-Y adkori, Y asin and Szepesv ´ ari, Csaba. Re gret bounds for the adaptiv e control of linear quadratic sys- tems. Journal of Mac hine Learning Resear ch - Pr oceed- ings T rack , 19:1–26, 2011. Agrawal, Shipra and Goyal, Navin. Further optimal re- gret bounds for Thompson sampling. arXiv preprint arXiv:1209.3353 , 2012. Bertsekas, Dimitri P and Ioffe, Serge y . T emporal differences-based policy iteration and applications in neuro-dynamic programming. Lab. for Info. and De- cision Systems Report LIDS-P-2349, MIT , Cambridge, MA , 1996. Brafman, Ronen I. and T ennenholtz, Moshe. R-max - a general polynomial time algorithm for near-optimal re- inforcement learning. Journal of Machine Learning Re- sear ch , 3:213–231, 2002. Dann, Christoph and Brunskill, Emma. Sample complex- ity of episodic fixed-horizon reinforcement learning. In Advances in Neural Information Pr ocessing Systems , pp. 2800–2808, 2015. Dearden, Richard, Friedman, Nir, and Russell, Stuart J. Bayesian Q-learning. In AAAI/IAAI , pp. 761–768, 1998. Gabillon, V ictor, Gha vamzadeh, Mohammad, and Scher- rer , Bruno. Approximate dynamic programming finally performs well in the game of tetris. In Advances in Neural Information Pr ocessing Systems , pp. 1754–1762, 2013. Hadar , Josef and Russell, W illiam R. Rules for ordering uncertain prospects. The American Economic Revie w , pp. 25–34, 1969. Jaksch, Thomas, Ortner , Ronald, and Auer , Peter . Near- optimal regret bounds for reinforcement learning. J our- nal of Machine Learning Resear ch , 11:1563–1600, 2010. Kakade, Sham. On the Sample Complexity of Reinforce- ment Learning . PhD thesis, University College London, 2003. Kearns, Michael J. and K oller , Daphne. Efficient reinforce- ment learning in f actored MDPs. In IJCAI , pp. 740–747, 1999. Kearns, Michael J. and Singh, Satinder P . Near -optimal reinforcement learning in polynomial time. Machine Learning , 49(2-3):209–232, 2002. Lagoudakis, Michail, Parr , Ronald, and Littman, Michael L. Least-squares methods in reinforcement learning for control. In Second Hellenic Conference on Artificial Intelligence (SETN-02) , 2002. Lattimore, T or, Hutter, Marcus, and Sunehag, Peter . The sample-complexity of general reinforcement learning. In ICML , 2013. Levy , Haim. Stochastic dominance and expected utility: surve y and analysis. Management Science , 38(4):555– 593, 1992. Li, Lihong and Littman, Michael. Reducing reinforcement learning to KWIK online regression. Annals of Mathe- matics and Artificial Intelligence , 2010. Li, Lihong, Littman, Michael L., and W alsh, Thomas J. Knows what it knows: a framew ork for self-aware learn- ing. In ICML , pp. 568–575, 2008. Liang, Y itao, Machado, Marlos C., T alvitie, Erik, and Bowling, Michael H. State of the art control of atari games using shallow reinforcement learning. CoRR , abs/1512.01563, 2015. URL abs/1512.01563 . Mnih, V olodymyr et al. Human-le vel control through deep reinforcement learning. Natur e , 518(7540):529–533, 2015. Ortner , Ronald and Ryabko, Daniil. Online regret bounds for undiscounted continuous reinforcement learning. In NIPS , 2012. Osband, Ian and V an Roy , Benjamin. Model-based rein- forcement learning and the eluder dimension. In Ad- vances in Neural Information Pr ocessing Systems , pp. 1466–1474, 2014a. Osband, Ian and V an Roy , Benjamin. Near-optimal rein- forcement learning in factored MDPs. In Advances in Neural Information Pr ocessing Systems , pp. 604–612, 2014b. Osband, Ian and V an Roy , Benjamin. Bootstrapped thomp- son sampling and deep exploration. arXiv pr eprint arXiv:1507.00300 , 2015. Osband, Ian, Russo, Daniel, and V an Roy , Benjamin. (More) efficient reinforcement learning via posterior sampling. In NIPS , pp. 3003–3011. Curran Associates, Inc., 2013. Pazis, Jason and Parr , Ronald. P A C optimal exploration in continuous space Markov decision processes. In AAAI . Citeseer , 2013. Generalization and Exploration via Randomized V alue Functions Russo, Dan and V an Roy , Benjamin. Eluder dimension and the sample complexity of optimistic exploration. In NIPS , pp. 2256–2264. Curran Associates, Inc., 2013. Russo, Daniel and V an Roy , Benjamin. Learning to opti- mize via posterior sampling. Mathematics of Operations Resear ch , 39(4):1221–1243, 2014. Strehl, Alexander L., Li, Lihong, Wie wiora, Eric, Lang- ford, John, and Littman, Michael L. P A C model-free reinforcement learning. In ICML , pp. 881–888, 2006. Sutton, Richard and Barto, Andrew . Reinfor cement Learn- ing: An Intr oduction . MIT Press, March 1998. Szepesv ´ ari, Csaba. Algorithms for Reinforcement Learn- ing . Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers, 2010. T esauro, Gerald. T emporal difference learning and td- gammon. Communications of the ACM , 38(3):58–68, 1995. Thompson, W .R. On the likelihood that one unknown prob- ability exceeds another in view of the evidence of two samples. Biometrika , 25(3/4):285–294, 1933. W en, Zheng and V an Roy , Benjamin. Efficient exploration and v alue function generalization in deterministic sys- tems. In NIPS , pp. 3021–3029, 2013. Generalization and Exploration via Randomized V alue Functions APPENDICES A. LSVI with Boltzmann exploration/ -greedy exploration The LSVI algorithm iterates backwards over time periods in the planning horizon, in each iteration fitting a value function to the sum of immediate rew ards and value esti- mates of the next period. Each value function is fitted via least-squares: note that vectors θ lh satisfy θ lh ∈ arg min ζ ∈ R K k Aζ − b k 2 + λ k ζ k 2 . (3) Notice that in Algorithm 3 , when l = 0 , matrix A and vec- tor b are empty . In this case, we simply set θ l 0 = θ l 1 = · · · = θ l,H − 1 = 0 . Algorithm 3 Least-Squares V alue Iteration Input: Data Φ( s i 0 ,a i 0 ) ,r i 0 ,.., Φ( s iH − 1 ,a iH − 1 ) ,r iH : i < L . Parameter λ > 0 Output: θ l 0 ,...,θ l,H − 1 1: θ lH ← 0 , Φ H ← 0 2: for h = H − 1 ,..., 1 , 0 do 3: Generate regression problem A ∈ R l × K , b ∈ R l : A ← Φ h ( s 0 h ,a 0 h ) . . . Φ h ( s l − 1 ,h ,a l − 1 ,h ) b i ← ( r ih + max α Φ h +1 ˜ θ l,h +1 ( s i,h +1 ,α ) if h < H − 1 r ih + r i,h +1 if h = H − 1 4: Linear regression for v alue function θ lh ← ( A > A + λI ) − 1 A > b 5: end for RL algorithms produced by synthesizing Boltzmann e xplo- ration or -greedy exploration with LSVI are presented as Algorithms 4 and 5 . In these algorithms the “temperature” parameters η in Boltzmann exploration and in -greedy exploration control the degree to which random perturba- tions distort greedy actions. Algorithm 4 LSVI with Boltzmann exploration Input: Features Φ 0 ,.., Φ H − 1 ; η > 0 , λ > 0 1: for l = 0 , 1 , ··· do 2: Compute θ l 0 ,...,θ l,H − 1 based on Algorithm 3 3: Observe x l 0 4: for h = 0 , 1 ,...,H − 1 do 5: Sample a lh ∼ E [(Φ h θ lh )( x lh ,a ) /η ] 6: Observe r lh and x l,h +1 7: end for 8: end for Algorithm 5 LSVI with -greedy exploration Input: Features Φ 0 ,.., Φ H − 1 ; > 0 , λ > 0 1: for l = 0 , 1 ,... do 2: Compute θ l 0 ,...,θ l,H − 1 using Algorithm 3 3: Observe x l 0 4: for h = 0 , 1 , ··· ,H − 1 do 5: Sample ξ ∼ Bernoulli ( ) 6: if ξ = 1 then 7: Sample a lh ∼ unif ( A ) 8: else 9: Sample a lh ∈ arg max α ∈A (Φ h θ lh )( x lh ,α ) 10: end if 11: Observe r lh and x l,h +1 12: end for 13: end for B. Efficient exploration with generalization Our computational results suggest that, when coupled with generalization, RLSVI enjoys le vels of ef ficiency far be- yond what can be achie ved by Boltzmann or -greedy ex- ploration. W e leav e as an open problem establishing effi- ciency guarantees in such contexts. T o stimulate thinking on this topic, we put forth a conjecture. Conjecture 1. F or all M = ( S , A , H , P , R, π ) , Φ 0 , . . . , Φ H − 1 , σ , and λ , if r ewar d distributions R have support [ − σ, σ ] , ther e is a unique ( θ 0 , . . . , θ H − 1 ) ∈ R K × H satisfying Q ∗ h = Φ h θ h for h = 0 , . . . , H − 1 , and P H − 1 h =0 k θ h k 2 ≤ K H λ , then ther e exists a polynomial p oly such that Regret( T , M ) ≤ √ T p oly K, H , max h,x,a k Φ h ( x, a ) k , σ, 1 /λ . As one would hope for from an RL algorithm that gener- alizes, this bound does not depend on the number of states or actions. Instead, there is a dependence on the number of basis functions. In Appendix C we present empirical results that are consistent with this conjecture. Generalization and Exploration via Randomized V alue Functions C. Chain experiments C.1. Generating a random coherent basis W e present full details for Algorithm 6 , which generates the random coherent basis functions Φ h ∈ R S A × K for h = 1 , .., H . In this algorithm we use some standard notation for indexing vector elements. For any A ∈ R m × n we will write A [ i, j ] for the element in the i th row and j th column. W e will use the placeholder · to repesent the entire axis so that, for example, A [ · , 1] ∈ R n is the first column of A . Algorithm 6 Generating a random coherent basis Input: S, A, H , K ∈ N , Q ∗ h ∈ R S A for h = 1 , .., H Output: Φ h ∈ R S A × K for h = 1 , .., H 1: Sample Ψ ∼ N (0 , I ) ∈ R H S A × K 2: Set Ψ[ · , 1] ← 1 3: Stack Q ∗ ← ( Q ∗ 1 , .., Q ∗ h ) ∈ R H S A 4: Set Ψ[ · , 2] ← Q ∗ 5: Form projection P ← Ψ(Ψ T Ψ) − 1 Ψ T 6: Sample W ∼ N (0 , I ) ∈ R H S A × K 7: Set W [ · , 1] ← 1 8: Project W P ← P W ∈ R H S A × K 9: Scale W P [ · , k ] ← W P [ · ,k ] k W P [ · ,k ] k 2 H S A for k = 1 , .., K 10: Reshape Φ ← reshap e( W P ) ∈ R H × S A × K 11: Return Φ[ h, · , · ] ∈ R S A × K for h = 1 , .., H The reason we rescale the value function in step (9) of Al- gorithm 6 is so that the resulting random basis functions are on a similar scale to Q ∗ . This is a completely arbitrary choice as an y scaling in Φ can be exactly replicated by sim- ilar rescalings in λ and σ . C.2. Robustness to λ, σ In Figures 10 and 11 we present the cumulativ e re gret for N = 50 , K = 10 ov er the first 10000 episodes for sev eral orders of magnitude for σ and λ . For most combinations of parameters the learning remains remarkably stable. Figure 10. Fixed σ = 0 . 1 , varying λ . W e find that large values of σ lead to slowers learning, since the Bayesian posterior concentrates only very slowly with new data. Howe ver , in stochastic domains we found that choosing a σ which is too small might cause the RLSVI posterior to concentrate too quickly and so fail to suffi- ciently e xplore. This is a similar insight to previous anal- yses of Thompson sampling ( Agraw al & Goyal , 2012 ) and matches the flav our of Theorem 1 . Figure 11. Fixed λ = 100 , varying σ . C.3. Scaling with number of bases K In Figure 4 we demonstrated that RLSVI seems to scale gracefully with the number of basis features on a chain of length N = 50 . In Figure 13 we reproduce these reults for chains of several different lengths. T o highlight the over - all trend we present a local polynomial regression for each chain length. Figure 12. Graceful scaling with number of basis functions. Roughly speaking, for low numbers of features K the num- ber of episodes required until learning appears to increase linearly with the number of basis features. Howe ver , the marginal increase from a new basis features seems to de- crease and almost plateau once the number of features reaches the maximum dimension for the problem K ≥ S A . C.4. Appr oximate polynomial learning Our simulation results empirically demonstrate learning which appears to be polynomial in both N and K . Inspired by the results in Figure 5 , we present the learning times for different N and K together with a quadratic regression fit separately for each K . Figure 13. Graceful scaling with number of basis functions. This is only one small set of experiments, but these re- sults are not inconsistent with Conjecture 1 . This quadratic model seems to fit data pretty well. Generalization and Exploration via Randomized V alue Functions D. T etris experiments D.1. Algorithm specification In Algorithm 7 we present a natural adaptation to RLSVI without known episode length, but still a regular episodic structure. This is the algorithm we use for our experiments in T etris. The LSVI algorithms are formed in the same way . Algorithm 7 Stationary RLSVI Input: Data Φ( s 1 ,a 1 ) ,r 1 ,.., Φ( s T ,a T ) . Previous estimate ˜ θ − l ≡ ˜ θ l − 1 . Parameters λ > 0 , σ > 0 , γ ∈ [0 , 1] Output: ˜ θ l 1: Generate regression problem A ∈ R T × K , b ∈ R T : A ← Φ h ( s 1 ,a 1 ) . . . Φ h ( s T ,a T ) b i ← ( r i + γ max α Φ ˜ θ − l ( s i +1 ,α ) if s i not terminal r i if s i is terminal 2: Bayesian linear regression for the value function θ l ← 1 σ 2 1 σ 2 A > A + λI − 1 A > b Σ l ← 1 σ 2 A > A + λI − 1 3: Sample ˜ θ l ∼ N ( θ l , Σ l ) from Gaussian posterior Algorithm 8 RLSVI with greedy action Input: Features Φ ; λ > 0 , σ > 0 , γ ∈ [0 , 1] 1: θ − 0 ← 0 ; t ← 0 2: for Episode l = 0 , 1 ,.. do 3: Compute ˜ θ l using Algorithm 7 4: Observe s t 5: while TR UE do 6: Update t ← t + 1 7: Sample a t ∈ arg max α ∈A Φ ˜ θ ( s t ,α ) 8: Observe r t and s t +1 9: if s t +1 is terminal then 10: BREAK 11: end if 12: end while 13: end for This algorithm simply approximates a time-homogenous value function using Bayesian linear regression. W e found that a discount rate of γ = 0 . 99 was helpful for stability in both RLSVI and LSVI. In order to av oid growing computational and memory cost as LSVI collects more data we used a very simple strategy to only store the most recent N transitions. For our ex- periments we set N = 10 5 . Computation for RLSVI and LSVI remained negligible compared to the cost of running the T etris simulator for our implementations. T o see how small this memory requirement is note that, apart from the number of holes, ev ery feature and re ward is a positiv e integer between 0 and 20 inclusiv e. The number of holes is a positive integer between 0 and 199. W e could store the information 10 5 transitions for ev ery possible ac- tion using less than 10mb of memory . D.2. Effecti ve impro vements W e present the results for RLSVI with fixed σ = 1 and λ = 1 . This corresponds to a Bayesian linear regression with a known noise variance in Algorithm 7 . W e actually found slightly better performance using a Bayesian linear regression with an in verse gamma prior ov er an unknown variance. This is the conjugate prior for Gaussian regres- sion with known variance. Since the improvements were minor and it slightly complicates the algorithm we omit these results. Howe ver , we believe that using a wider prior ov er the variance will be more robust in application, rather than picking a specific σ and λ . D.3. Mini-tetris In Figure 7 we show that RLSVI outperforms LSVI even with a highly tuned annealing scheme for . Ho wev er , these results are much more extreme on a didactic version of mini-tetris. W e make a tetris board with only 4 rows and only S, Z pieces. This problem is much more difficult and highlights the need for efficient exploration in a more ex- treme way . In Figure 14 we present the results for this mini-tetris en- vironment. As expected, this example highlights the ben- efits of RLSVI over LSVI with dithering. RLSVI greatly outperforms LSVI ev en with a tuned schedule. RLSVI learns faster and reaches a higher con vergent polic y . Figure 14. Reduced 4-row tetris with only S and Z pieces. Generalization and Exploration via Randomized V alue Functions E. Recommendation system experiments E.1. Experiment Setup For the recommendation system e xperiments, the e xperi- ment setup is specified in Algorithm 9 . W e set N = 10 , J = H = 5 , c = 2 and L = 1200 . Algorithm 9 Recommendation System Experiments: Ex- periment Setup Input: N ∈ Z ++ , J = H ∈ Z ++ , c > 0 , L ∈ Z ++ Output: ˆ ∆(0) , . . . , ˆ ∆( L − 1) for i = 1 , . . . , 100 do Sample a problem instance γ an ∼ N (0 , c 2 ) Run the Bernoulli bandit algorithm 100 times Run the linear contextual bandit algorithm 100 times for for each η ∈ { 10 − 4 , 10 − 3 , 10 − 2 , 10 − 1 , 1 , 10 } do Run LSVI-Boltzmann with λ = 0 . 2 and η 10 times end for Run RLSVI with λ = 0 . 2 and σ 2 = 10 − 3 10 times end for Compute the av erage regret for each algorithm The myopic policy is defined as follo ws: for all episode l = 0 , 1 , · · · and for all step h = 0 , · · · , H − 1 , choose a lh ∈ arg max a P ( a | x lh ) , where a lh and x lh are respecti vely the action and the state at step h of episode l . E.2. Bernoulli bandit algorithm The Bernoulli bandit algorithm is described in Algorithm 10 , which is a Thompson sampling algorithm with uniform prior . Obviously , this algorithm aims to learn the myopic policy . Algorithm 10 Bernoulli bandit algorithm Input: N ∈ N , J ∈ N , L ∈ N Initialization: Set α n = β n = 1 , ∀ n = 1 , 2 , . . . , N for l = 0 , . . . , L − 1 do Randomly sample ˆ p ln ∼ b eta ( α n , β n ) , ∀ n = 1 , . . . , N Sort ˆ p ln ’ s in the descending order, and recommend the first J products in order to the customer for n = 1 , . . . , N do if product n is recommended in episode l then if customer likes product then α n ← α n + 1 else β n ← β n + 1 end if end if end for end for E.3. Linear contextual bandit algorithm In this subsection, we describe the linear contextual bandit algorithm. The linear contextual bandit algorithm is simi- lar to RLSVI, but without backwar d value propa gation , a key feature of RLSVI. It is straightforward to see that the linear contextual bandit algorithm aims to learn the my- opic policy . This algorithm is specified in Algorithm 11 and 12 . Notice that this algorithm can be implemented in- crementally , hence, it is computationally efficient. In this computational study , we use the same basis functions as RLSVI, and the same algorithm parameters (i.e. λ = 0 . 2 and σ 2 = 10 − 3 ). Algorithm 11 Randomized exploration in linear contextual bandits Input: Data Φ( s i 0 ,a i 0 ) ,r i 0 ,.., Φ( s iH − 1 ,a iH − 1 ) ,r iH : i < L . Parameters λ > 0 , σ > 0 Output: ˆ θ l 0 ,..., ˆ θ l,H − 1 1: ˆ θ lH ← 0 , Φ H ← 0 2: for h = H − 1 ,..., 1 , 0 do 3: Generate regression matrix and v ector A ← Φ h ( s 0 h ,a 0 h ) . . . Φ h ( s l − 1 ,h ,a l − 1 ,h ) b ← r 0 ,h . . . r l − 1 ,h 4: Estimate value function θ lh ← 1 σ 2 1 σ 2 A > A + λσ 2 I − 1 A > b Σ lh ← 1 σ 2 A > A + λI − 1 5: Sample ˆ θ lh ∼ N ( θ lh , Σ lh ) 6: end for Algorithm 12 Linear contextual bandit algorithm Input: Features Φ 0 ,.., Φ H , σ > 0 ,λ > 0 1: for l = 0 , 1 , ··· do 2: Compute ˆ θ l 0 ,..., ˆ θ l,H − 1 using Algorithm 11 3: Observe x l 0 4: for h = 0 , ··· ,H − 1 do 5: Sample a lh ∼ unif argmax α ∈A Φ h ˆ θ lh ( x lh ,α ) 6: Observe r lh and x l,h +1 7: end for 8: end for Generalization and Exploration via Randomized V alue Functions F . Extensions W e no w briefly discuss a couple possible e xtensions of the version of RLSVI proposed in Algorithm 1 and 8 . One is an incremental version which is computationally more efficient. The other addresses continual learning in an infinite horizon discounted Mark ov decision process. In the same sense that RLSVI shares much with LSVI but is distinguished by its new approach to exploration, these e xtensions share much with least-squares Q-learning ( Lagoudakis et al. , 2002 ). F .1. Incremental learning Note that Algorithm 1 is a batch learning algorithm, in the sense that, in each episode l , though Σ lh ’ s can be computed incrementally , it needs all past observ ations to compute ¯ θ lh ’ s. Thus, its per -episode compute time gro ws with l , which is undesirable if the algorithm is applied ov er many episodes. One way to fix this problem is to deriv e an incremental RLSVI that updates ¯ θ lh ’ s and Σ lh ’ s using summary statistics of past data and new observ ations made over the most recent episode. One approach is to do this by computing Σ − 1 l +1 ,h ← (1 − ν l )Σ − 1 lh + 1 σ 2 Φ h ( x lh , a lh ) > Φ h ( x lh , a lh ) y l +1 ,h ← (1 − ν l ) y lh + 1 σ 2 r lh + max α ∈A Φ h +1 ˜ θ l,h +1 ( x l,h +1 , α ) Φ h ( x lh , a lh ) > , (4) and setting ¯ θ l +1 ,h = Σ − 1 l +1 ,h y l +1 ,h . Note that we sample ˜ θ lh ∼ N ( ¯ θ lh , Σ lh ) , and initialize y 0 h = 0 , Σ − 1 0 h = λI , ∀ h . The step size ν l controls the influence of past observ ations on Σ lh and ¯ θ lh . Once ˜ θ lh ’ s are computed, the actions are chosen based on Algorithm 8 . Another approach would be simply to approximate the solution for θ lh numerically via random sampling and stochastic gradient descent similar to other works with non-linear architectures ( Mnih , 2015 ). The per-episode compute time of these incremental algorithms are episode-independent, which allows for deployment at large scale. On the other hand, we expect the batch v ersion of RLSVI to be more data ef ficient and thus incur lower re gret. F .2. Continual learning Finally , we propose a v ersion of RLSVI for RL in infinite-horizon time-in variant discounted MDPs. A discounted MDP is identified by a sextuple M = ( S , A , γ , P , R, π ) , where γ ∈ (0 , 1) is the discount factor . S , A , P , R, π are defined similarly with the finite horizon case. Specifically , in each time t = 0 , 1 , . . . , if the state is x t and an action a t is selected then a subsequent state x t +1 is sampled from P ( ·| x t , a t ) and a rew ard r t is sampled from R ( ·| x t , a t , x t +1 ) . W e also use V ∗ to denote the optimal state value function, and Q ∗ to denote the optimal action-contingent value function. Note that V ∗ and Q ∗ do not depend on t in this case. Algorithm 13 Continual RLSVI Input: ˜ θ t ∈ R K , w t ∈ R K , Φ ∈ R |S ||A|× K , σ > 0 , λ > 0 , γ ∈ (0 , 1) , { ( x τ , a τ , r τ ) : τ ≤ t } , x t +1 Output: ˜ θ t +1 ∈ R K , w t +1 ∈ R K 1: Generate regression matrix and vector A ← Φ( x 0 , a 0 ) . . . Φ( x t , a t ) b ← r 0 + γ max α ∈A Φ ˜ θ t ( x 1 , α ) . . . r t + γ max α ∈A Φ ˜ θ t ( x t +1 , α ) 2: Estimate value function θ t +1 ← 1 σ 2 1 σ 2 A > A + λI − 1 A > b Σ t +1 ← 1 σ 2 A > A + λI − 1 3: Sample w t +1 ∼ N ( p 1 − γ 2 w t , γ 2 Σ t +1 ) 4: Set ˜ θ t +1 = θ t +1 + w t +1 Similarly with the episodic case, an RL algorithm generates each action a t based on observations made up to time t , Generalization and Exploration via Randomized V alue Functions including all states, actions, and rew ards observed in previous time steps, as well as the state space S , action space A , discount factor γ , and possible prior information. W e consider a scenario in which the agent has prior knowledge that Q ∗ lies within a linear space spanned by a generalization matrix Φ ∈ R |S ||A|× K . A version of RLSVI for continual learning is presented in Algorithm 13 . Note that ˜ θ t and w t are values computed by the algorithm in the previous time period. W e initialize ˜ θ 0 = 0 and w 0 = 0 . Similarly to Algorithm 1 , Algorithm 13 randomly perturbs value estimates in directions of significant uncertainty to incentivize exploration. Note that the random perturbation vectors w t +1 ∼ N ( p 1 − γ 2 w t , γ 2 Σ t +1 ) are sampled to ensure autocorrelation and that marginal cov ariance matrices of consecuti ve perturbations dif fer only slightly . In each period t , once ˜ θ t is computed, a greedy action is selected. A voiding frequent abrupt changes in the perturbation vector is important as this allo ws the agent to ex ecute on multi-period plans to reach poorly understood state-action pairs. G. Gaussian vs Dirichlet optimism The goal of this subsection is to prov e Lemma 1 , reproduced below: For all v ∈ [0 , 1] N and α ∈ [1 , ∞ ) N with α T 1 ≥ 2 , if x ∼ N ( α > v /α > 1 , 1 /α > 1 ) and y = p T v for p ∼ Dirichlet( α ) then x < so y . W e begin with a lemma recapping some basic equi valences of stochastic optimism. Lemma 3 (Optimism equiv alence) . The following ar e equivalent to X < so Y : 1. F or any random variable Z independent of X and Y , E [max( X , Z )] ≥ E [max( Y , Z )] 2. F or any α ∈ R , R ∞ α { P ( X ≥ s ) − P ( Y ≥ s ) } ds ≥ 0 . 3. X = D Y + A + W for A ≥ 0 and E [ W | Y + A ] = 0 for all values y + a . 4. F or any u : R → R con vex and incr easing E [ u ( X )] ≥ E [ u ( Y )] These properties are well known from the theory of second order stochastic dominance ( Levy , 1992 ; Hadar & Russell , 1969 ) but can be re-deri ved using only elementary integration by parts. X < so Y if and only if − Y is second order stochastic dominant for − X . G.1. Beta vs. Dirichlet In order to prove Lemma 1 we will first pro ve an intermediate result that shows a particular Beta distribution ˜ y is optimistic for y . Before we can prove this result we first state a more basic result that we will use on Gamma distrib utions. Lemma 4. F or independent random variables γ 1 ∼ Gamma ( k 1 , θ ) and γ 2 ∼ Gamma ( k 2 , θ ) , E [ γ 1 | γ 1 + γ 2 ] = k 1 k 1 + k 2 ( γ 1 + γ 2 ) and E [ γ 2 | γ 1 + γ 2 ] = k 2 k 1 + k 2 ( γ 1 + γ 2 ) . W e can now present our optimistic lemma for Beta v ersus Dirichlet. Lemma 5. Let y = p > v for some random variable p ∼ Dirichlet ( α ) and constants v ∈ < d and α ∈ N d . W ithout loss of generality , assume v 1 ≤ v 2 ≤ · · · ≤ v d . Let ˜ α = P d i =1 α i ( v i − v 1 ) / ( v d − v 1 ) and ˜ β = P d i =1 α i ( v d − v i ) / ( v d − v 1 ) . Then, ther e exists a r andom variable ˜ p ∼ Beta ( ˜ α, ˜ β ) suc h that, for ˜ y = ˜ pv d + (1 − ˜ p ) v 1 , E [ ˜ y | y ] = E [ y ] . Pr oof. Let γ i = Gamma ( α, 1) , with γ 1 , . . . , γ d independent, and let γ = P d i =1 γ i , so that p ≡ D γ /γ . Let α 0 i = α i ( v i − v 1 ) / ( v d − v 1 ) and α 1 i = α i ( v d − v i ) / ( v d − v 1 ) so that α = α 0 + α 1 . Define independent random variables γ 0 ∼ Gamma ( α 0 i , 1) and γ 1 ∼ Gamma ( α 1 i , 1) so that γ ≡ D γ 0 + γ 1 . Generalization and Exploration via Randomized V alue Functions T ake γ 0 and γ 1 to be independent, and couple these variables with γ so that γ = γ 0 + γ 1 . Note that ˜ β = P d i =1 α 0 i and ˜ α = P d i =1 α 1 i . Let γ 0 = P d i =1 γ 0 i and γ 1 = P d i =1 γ 1 i , so that 1 − ˜ p ≡ D γ 0 /γ and ˜ p ≡ D γ 1 /γ . Couple these variables so that 1 − ˜ p = γ 0 /γ and ˜ p = γ 1 /γ . W e then have E [ ˜ y | y ] = E [(1 − ˜ p ) v 1 + ˜ pv d | y ] = E v 1 γ 0 γ + v d γ 1 γ y = E E v 1 γ 0 + v d γ 1 γ γ , y y = E v 1 E [ γ 0 | γ ] + v d E [ γ 1 | γ ] γ y = E " v 1 P d i =1 E [ γ 0 i | γ i ] + v d P d i =1 E [ γ 1 i | γ i ] γ y # (a) = E " v 1 P d i =1 γ i α 0 i /α i + v d P d i =1 γ i α 1 i /α i γ y # = E " v 1 P d i =1 γ i ( v i − v 1 ) + v d P d i =1 γ i ( v d − v i ) γ ( v d − v 1 ) y # = E " P d i =1 γ i v i γ y # = E " d X i =1 p i v i y # = y , where (a) follows from Lemma 4 . G.2. Gaussian vs Beta In the pre vious section we showed that a matched Beta distribution ˜ y would be optimistic for the Dirichlet y . W e will now show that the Normal random v ariable x is optimistic for ˜ y and so complete the proof of Lemma 1 , x < so ˜ y < so y . Unfortunately , unlike the case of Beta vs Dirichlet it is quite dif ficult to sho w this optimism relationship between Gaussian x and Beta ˜ y directly . Instead we make an appeal to the stronger dominance relationship of single-crossing CDFs. Definition 2 (Single crossing dominance) . Let X and Y be real-valued random variables with CDFs F X and F Y r espectively . W e say that X single-cr ossing domi- nates Y if E [ X ] ≥ E [ Y ] and ther e a crossing point a ∈ R such that: F X ( s ) ≥ F Y ( s ) ⇐ ⇒ s ≤ a. (5) Note that single crossing dominance implies stochastic optimism. The remainder of this section is dev oted to proving that the following lemma: Lemma 6. Let ˜ y ∼ B eta ( α, β ) for any α > 0 , β > 0 and x ∼ N µ = α α + β , σ 2 = 1 α + β . Then, x single cr ossing dominates ˜ y . T rivially , these two distributions will always hav e equal means so it is enough to show that their CDFs can cross at most once on (0 , 1) . G.3. Double crossing PDFs By repeated application of the mean value theorem, if we want to prov e that the CDFs cross at most once on (0 , 1) then it is sufficient to prove that the PDFs cross at most twice on the same interval. Our strategy will be to show via mechanical calculus that for the kno wn densities of x and ˜ y the PDFs cross at most twice on (0 , 1) . W e lament that the proof as it stands is so laborious, but our attempts at a more elegant solution has so far been unsucessful. The remainder of this appendix is dev oted to proving this “double-crossing” property via manipulation of the PDFs for different v alues of α, β . W e write f N for the density of the Normal x and f B for the density of the Beta ˜ y respectively . W e know that at the boundary f N (0 − ) > f B (0 − ) and f N (1+) > f B (1+) where the ± represents the left and right limits respectively . Since the densities are postiv e over the interv al, we can consider the log PDFs instead. l B ( x ) = ( α − 1) log ( x ) + ( β − 1) log(1 − x ) + K B Generalization and Exploration via Randomized V alue Functions l N ( x ) = − 1 2 ( α + β ) x − α α + β 2 + K N Since log( x ) is injectiv e and increasing, if we could show that l N ( x ) − l B ( x ) = 0 has at most tw o solutions on the interv al we would be done. Instead we will attempt to prove an even stronger condition, that l 0 N ( x ) − l 0 B ( x ) = 0 has at most one solution in the interval. This is not necessary for what we actually want to show , but it is sufficient and easier to deal with since we can ignore the annoying constants. l 0 B ( x ) = α − 1 x − β − 1 1 − x l 0 N ( x ) = α − ( α + β ) x Finally we will consider an e ven stronger condition, if l 00 N ( x ) − l 00 B ( x ) = 0 has no solution then l 0 B ( x ) − l 0 N ( x ) must be monotone ov er the region and so it can ha ve at most one root. l 00 B ( x ) = − α − 1 x 2 − β − 1 (1 − x ) 2 l 00 N ( x ) = − ( α + β ) So now let us define: h ( x ) := l 00 N ( x ) − l 00 B ( x ) = α − 1 x 2 + β − 1 (1 − x ) 2 − ( α + β ) (6) Our goal now is to sho w that h ( x ) = 0 does not ha ve any solutions for x ∈ [0 , 1] . Once again, we will look at the deri vati ves and analyse them for different v alues of α , β > 0 . h 0 ( x ) = − 2 α − 1 x 3 − β − 1 (1 − x ) 3 h 00 ( x ) = 6 α − 1 x 4 + β − 1 (1 − x ) 4 G . 3 . 1 . S P E C I A L C A S E α > 1 , β ≤ 1 In this region we want to show that actually g ( x ) = l 0 N ( x ) − l 0 B ( x ) has no solutions. W e follow a very similar line of argument and write A = α − 1 > 0 and B = β − 1 ≤ 0 as before. g ( x ) = α − ( α + β ) x + β − 1 1 − x − α − 1 x g 0 ( x ) = h ( x ) = A x 2 + B (1 − x ) 2 − ( α + β ) g 00 ( x ) = h 0 ( x ) = − 2 A x 3 − B (1 − x ) 3 Now since B ≤ 0 we note that g 00 ( x ) ≤ 0 and so g ( x ) is a concav e function. If we can show that the maximum of g lies below 0 then we know that there can be no roots. W e now attempt to solv e g 0 ( x ) = 0 : g 0 ( x ) = A x 2 + B (1 − x ) 2 = 0 = ⇒ − A/B = x 1 − x 2 = ⇒ x = K 1 + K ∈ (0 , 1) Generalization and Exploration via Randomized V alue Functions Where here we write K = p − A/B > 0 . W e’ re ignoring the case of B = 0 as this is e ven easier to show separately . W e now e valuate the function g at its minimum x K = K 1+ K and write C = − B ≥ 0 . g ( x K ) = ( A + 1) − ( A + B + 2) K 1 + K + B (1 + K ) − A 1 + K K = − AK 2 − AK − A + B K 3 + B K 2 + B K − K 2 + K = − AK 2 − AK − A − C K 3 − C K 2 − C K − K 2 + K = − A ( A/C ) − A ( A/C ) 1 / 2 − A − C ( A/C ) 3 / 2 − C ( A/C ) − C ( A/C ) 1 / 2 − A/C + ( A/C ) 1 / 2 = − A 2 C − 1 − A 3 / 2 C − 1 / 2 − A − A 3 / 2 C − 1 / 2 − A − A 1 / 2 C 1 / 2 − AC − 1 + A 1 / 2 C 1 / 2 = − A 2 C − 1 − 2 A 3 / 2 C − 1 / 2 − 2 A − AC − 1 ≤ 0 Therefore we are done with this sub proof. The case of α ≤ 1 , β > 1 can be dealt with similarly . G . 3 . 2 . C O N V E X F U N C T I O N α > 1 , β > 1 , ( α − 1)( β − 1) ≥ 1 9 In the case of α, β > 1 we know that h ( x ) is a con vex function on (0 , 1) . So now if we solve h 0 ( x ∗ ) = 0 and h ( x ∗ ) > 0 then we hav e prov ed our statement. W e will write A = α − 1 , B = β − 1 for con venience. W e now attempt to solv e h 0 ( x ) = 0 h 0 ( x ) = A x 3 − B (1 − x ) 3 = 0 = ⇒ A/B = x 1 − x 3 = ⇒ x = K 1 + K ∈ (0 , 1) Where for conv enience we ha ve written K = ( A/B ) 1 / 3 > 0 . W e no w e valuate the function h at its minimum x K = K 1+ K . h ( x K ) = A ( K + 1) 2 K 2 + B ( K + 1) 2 − ( A + B + 2) = A (2 /K + 1 /K 2 ) + B ( K 2 + 2 K ) − 2 = 3( A 2 / 3 B 1 / 3 + A 1 / 3 B 2 / 3 ) − 2 So as long as h ( x K ) > 0 we have sho wn that the CDFs are single crossing. W e note a simpler characterization of A, B that guarantees this condition: A, B ≥ 1 / 3 = ⇒ AB ≥ 1 / 9 = ⇒ ( A 2 / 3 B 1 / 3 + A 1 / 3 B 2 / 3 ) ≥ 2 / 3 And so we hav e shown that somehow for α, β large enough away from 1 we are OK. Certianly we have prov ed the result for α, β ≥ 4 / 3 . G . 3 . 3 . F I N A L R E G I O N { α > 1 , β > 1 , ( α − 1)( β − 1) ≤ 1 9 } W e no w produce a final argument that ev en in this remaining region the two PDFs are at most double crossing. The argument is really no different than before, the only difficulty is that it is not enough to only look at the deri vati ves of the log likelihoods, we need to use some bound on the normalizing constants to get our bounds. By symmetry in the problem, it will suffice to consider only the case α > β , the other result follo ws similarly . In this region of interest, we know that β ∈ (1 , 4 3 ) and so we will make use of an upper bound to the normalizing constant of the Beta distribution, the Beta function. B ( α, β ) = Z 1 x =0 x α − 1 (1 − x ) β − 1 dx ≤ Z 1 x =0 x α − 1 dx = 1 α (7) Generalization and Exploration via Randomized V alue Functions Our thinking is that, because in B the value of β − 1 is relatively small, this approximation will not be too bad. Therefore, we can explicitly bound the log likelihood of the Beta distrib ution: l B ( x ) ≥ ˜ l B ( x ) := ( α − 1) log ( x ) + ( β − 1) log(1 − x ) + log( α ) W e will no w make use of a calculus ar gument as in the previous sections of the proof. W e want to find two points x 1 < x 2 for which h ( x i ) = l 00 N ( x ) − l 00 B ( x ) > 0 . Since α, β > 1 we know that h is conv ex and so for all x / ∈ [ x 1 , x 2 ] then h > 0 . If we can also show that the g ap of the Beta over the maximum of the normal log lik elihood Gap : l B ( x i ) − l N ( x i ) ≥ f ( x i ) := ˜ l B ( x i ) − max x l N ( x ) > 0 (8) is positi ve then it must mean there are no crossings o ver the re gion [ x 1 , x 2 ] , since ˜ l B is conca ve and therefore totally abo ve the maximum of l N ov er the whole region [ x 1 , x 2 ] . Now consider the regions x ∈ [0 , x 1 ) , we know by consideration of the tails that if there is more than one root in this segment then there must be at least three crossings. If there are three crossings, then the second deriv ativ e of their difference h must hav e at least one root on this region. Ho wev er we know that h is con vex, so if we can show that h ( x i ) > 0 this cannot be possible. W e use a similar argument for x ∈ ( x 2 , 1] . W e will no w complete this proof by lengthy amounts of calculus. Let’ s remind ourselves of the definition: h ( x ) := l 00 N ( x ) − l 00 B ( x ) = α − 1 x 2 + β − 1 (1 − x ) 2 − ( α + β ) For ease of notation we will write A = α − 1 , B = β − 1 . W e note that: h ( x ) ≥ h 1 ( x ) = A x 2 − ( A + B + 2) , h ( x ) ≥ h 2 ( x ) = B (1 − x ) 2 − ( A + B + 2) and we solve for h 1 ( x 1 ) = 0 , h 2 ( x 2 ) = 0 . This means that x 1 = r A A + B + 2 , x 2 = 1 − r B A + B + 2 and clearly h ( x 1 ) > 0 , h ( x 2 ) > 0 . Now , if we can show that, for all possible values of A, B in this region f ( x i ) = l B ( x i ) − max x l N ( x ) > 0 , our proof will be complete. W e will now write f ( x i ) = f i ( A, B ) to make the dependence on A, B more clear . f 1 ( A, B ) = log (1 + A ) + A log r A A + B + 2 ! + B log 1 − r A A + B + 2 ! + 1 2 log(2 π ) − 1 2 log( A + B + 2) f 2 ( A, B ) = log (1 + A ) + A log 1 − r B A + B + 2 ! + B log r B A + B + 2 ! + 1 2 log(2 π ) − 1 2 log( A + B + 2) Generalization and Exploration via Randomized V alue Functions W e will now sho w that ∂ f i ∂ B ≤ 0 for all of the v alues in our region A > B > 0 . ∂ f 1 ∂ B = − A 2( A + B + 2) + log 1 − r A A + B + 2 ! + B √ A 2( A + B + 2) 3 / 2 1 − q A A + B +2 − 1 2( A + B + 2) = 1 2( A + B + 2) B √ A √ A + B + 2 1 − q A A + B +2 − A − 1 + log 1 − r A A + B + 2 ! = 1 2( A + B + 2) B √ A √ A + B + 2 − √ A − A − 1 ! + log 1 − r A A + B + 2 ! ≤ 1 2( A + B + 2) √ B / 3 √ A + B + 2 − √ A − A − 1 ! − r A A + B + 2 ≤ 1 2( A + B + 2) 1 3 r B B + 2 − A − 1 ! − r A A + B + 2 ≤ − A 2( A + B + 2) − r A A + B + 2 ≤ 0 and similarly , ∂ f 2 ∂ B = − A q B A + B +2 2 B + 1 2( A + B + 2) + log r B A + B + 2 ! + B A + 2 2 B ( A + B + 2) − 1 2( A + B + 2) = 1 2( A + B + 2) A + 2 − A − 1 − A r A + B + 2 B ! + log r B A + B + 2 ! = 1 2( A + B + 2) 1 − A r A + B + 2 B ! + 1 2 log B A + B + 2 Now we can look at each term to observe that ∂ 2 f 2 ∂ A∂ B < 0 . Therefore this expression ∂ f 2 ∂ B is maximized ov er A for A = 0 . W e now e xamine this expression: ∂ f 2 ∂ B A =0 = 1 2( B + 2) + 1 2 log B B + 2 ≤ 1 2 1 B + 2 + B B + 2 − 1 ≤ 0 Therefore, the expressions f i are minimized at at the largest possible B = 1 9 A for any giv en A ov er our re gion. W e will now write g i ( A ) := f i ( A, 1 9 A ) for this e valutation at the extremal boundary . If we can show that g i ( A ) ≥ 0 for all A ≥ 1 3 and i = 1 , 2 we will be done. W e will perform a similar argument to sho w that g i is monotone increasing, g 0 i ( A ) ≥ 0 for all A ≥ 1 3 . g 1 ( A ) = log(1 + A ) + A log s A A + 1 9 A + 2 ! + 1 9 A log 1 − s A A + 1 9 A + 2 ! + 1 2 log(2 π ) − 1 2 log( A + 1 9 A + 2) = log(1 + A ) + A 2 log( A ) − 1 2 (1 + A ) log ( A + 1 9 A + 2) + 1 9 A log 1 − s A A + 1 9 A + 2 ! + 1 2 log(2 π ) Generalization and Exploration via Randomized V alue Functions Note that the function p ( A ) = A + 1 9 A is increasing in A for A ≥ 1 3 . W e can conservati vely bound g from below noting 1 9 A ≤ 1 in our region. g 1 ( A ) ≥ = log(1 + A ) + A 2 log( A ) − 1 2 (1 + A ) log ( A + 3) + 1 9 A log 1 − r A A + 2 ! + 1 2 log(2 π ) ≥ log(1 + A ) + A 2 log( A ) − 1 2 (1 + A ) log ( A + 3) − 1 9 A √ A + 1 2 log(2 π ) =: ˜ g 1 ( A ) Now we can use calculus to say that: ˜ g 0 1 ( A ) = 1 A + 1 + 1 A + 3 + log( A ) 2 + 1 18 A 3 / 2 − 1 2 log( A + 3) ≥ 1 A + 1 + 1 A + 3 + 1 18 A 3 / 2 + 1 2 log( A A + 3 ) This expression is monotone decreasing in A and with a limit ≥ 0 and so we can say that ˜ g 1 ( A ) is monotone increasing. Therefore g 1 ( A ) ≥ ˜ g 1 ( A ) ≥ ˜ g 1 (1 / 3) for all A . W e can explicitly ev aluate this numerically and ˜ g 1 (1 / 3) > 0 . 01 so we are done. The final piece of this proof is to do a similar argument for g 2 ( A ) g 2 ( A ) = log(1 + A ) + A log 1 − s 1 9 A A + 1 9 A + 2 ! + 1 9 A log s 1 9 A A + 1 9 A + 2 ! + 1 2 log(2 π ) − 1 2 log( A + 1 9 A + 2) = log(1 + A ) + A log 1 − r 1 9 A 2 + 18 A + 1 ! + 1 2 1 9 A log 1 9 A − 1 2 1 9 A + 1 log A + 1 9 A + 2 + 1 2 log(2 π ) ≥ log(1 + A ) + A − 1 √ 9 A 2 + 1 2 1 9 A log 1 9 A − 1 2 1 3 + 1 log A + 1 3 + 2 + 1 2 log(2 π ) ≥ log(1 + A ) − 1 3 − 1 2 e − 2 3 log( A + 7 3 ) + 1 2 log(2 π ) =: ˜ g 2 ( A ) Now , once again we can see that ˜ g 2 is monotone increasing: ˜ g 0 2 ( A ) = 1 1 + A − 2 / 3 A + 7 / 3 = A + 5 ( A + 1)(3 A + 7) ≥ 0 W e complete the argument by noting g 2 ( A ) ≥ ˜ g 2 ( A ) ≥ ˜ g 2 (1 / 3) > 0 . 01 , which concludes our proof of the PDF double crossing in this region. G.4. Recap Using the results of the previous sections we complete the proof of Lemma 6 for Gaussian vs Beta dominance for all possible α, β > 0 such that α + β ≥ 1 . Piecing together Lemma 5 with Lemma 6 completes our proof of Lemma 1 . W e imagine that there is a much more elegant and general proof method a vailable for future work.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment