대규모 엔터티 정합을 위한 성능 하한 분석
본 논문은 소규모 라벨링된 검증 데이터를 이용해 매치 함수의 성능을 평가하고, 이를 기반으로 임의 크기의 데이터셋에 대한 페어와이즈 엔터티 정합(pairwise ER)의 정밀도·재현율·F1 하한을 이론적으로 도출한다. ICAR(동등성, 교환성, 결합성, 대표성) 성질을 전제로 하며, 최적의 병합 함수는 연결 컴포넌트를 찾는 것과 동등함을 보인다. 실험을 통해 제시한 하한이 실제 성능에 매우 근접함을 확인한다.
저자: Matt Barnes, Kyle Miller, Artur Dubrawski
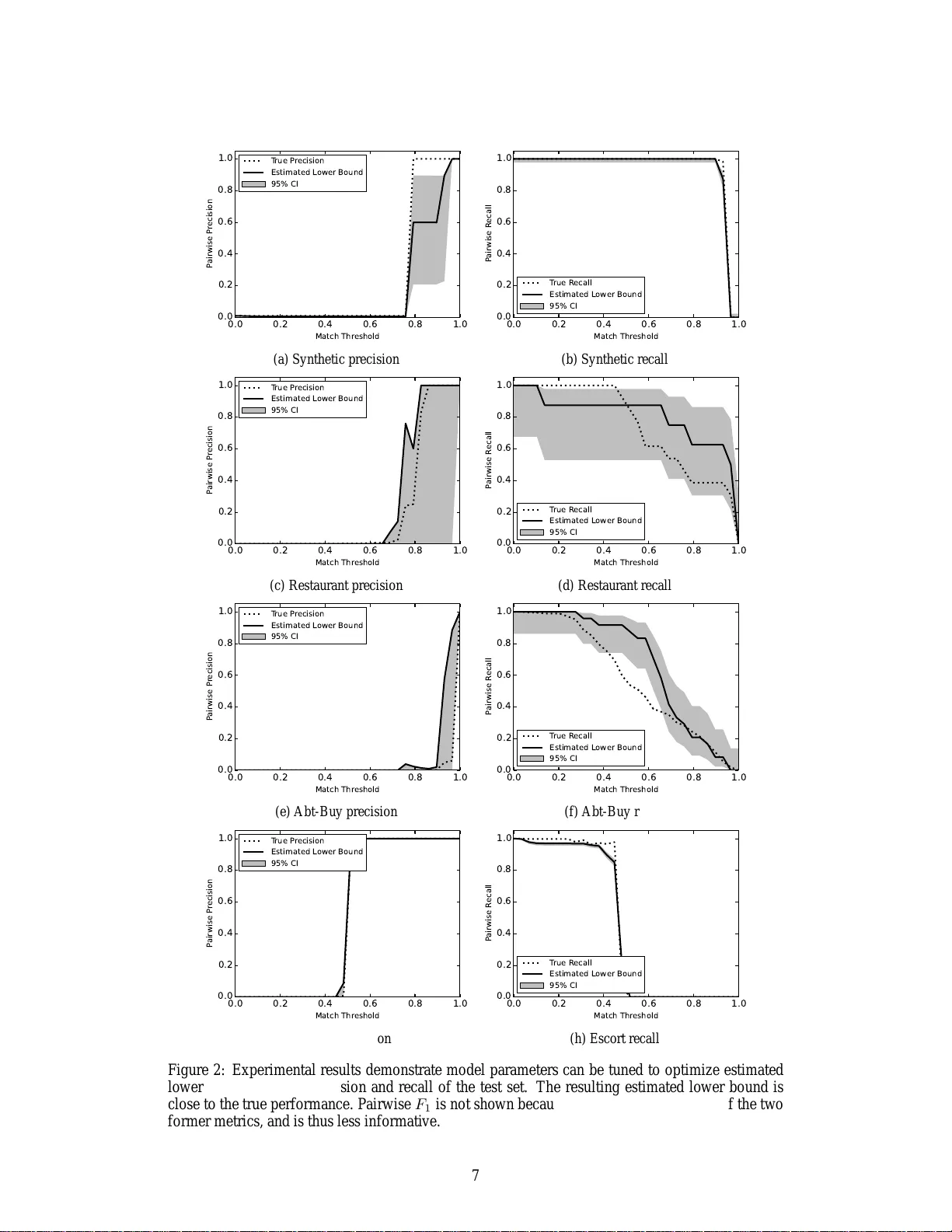
본 논문은 엔터티 정합(Entity Resolution, ER) 시스템을 대규모 데이터셋에 적용할 때, 소규모 라벨링된 검증 데이터만으로도 성능을 예측하고 최적화할 수 있는 이론적 기반을 제시한다. 전통적인 머신러닝과 달리 ER에서는 데이터 규모가 증가함에 따라 엔터티(클러스터) 수가 선형적으로 늘어나며, 작은 검증 집합에서 얻은 높은 정밀도·재현율이 큰 데이터에서 그대로 유지된다는 보장이 없다. 이러한 문제점을 해결하고자 저자들은 매치 함수 m의 성능을 검증 집합 V에서 측정하고, 이를 기반으로 임의 크기의 테스트 집합 T에 대한 페어와이즈 정밀도(Precision), 재현율(Recall), 그리고 F1 점수의 하한을 수식적으로 도출한다.
핵심 이론적 전제는 ICAR 속성이다. ICAR는 (1) Idempotence(자기 매치), (2) Commutativity(대칭성), (3) Associativity(결합성), (4) Representativity(대표성) 네 가지 성질을 의미한다. 특히 대표성은 “병합은 매치 가능성을 감소시키지 않는다”는 의미로, 매치된 레코드 쌍이 반드시 같은 클러스터에 포함된다는 Lemma 1을 가능하게 한다. 이를 바탕으로 Theorem 1에서는 정밀도 하한을 다음과 같이 표현한다.
E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기