Performance Bounds for Pairwise Entity Resolution
One significant challenge to scaling entity resolution algorithms to massive datasets is understanding how performance changes after moving beyond the realm of small, manually labeled reference datasets. Unlike traditional machine learning tasks, whe…
Authors: Matt Barnes, Kyle Miller, Artur Dubrawski
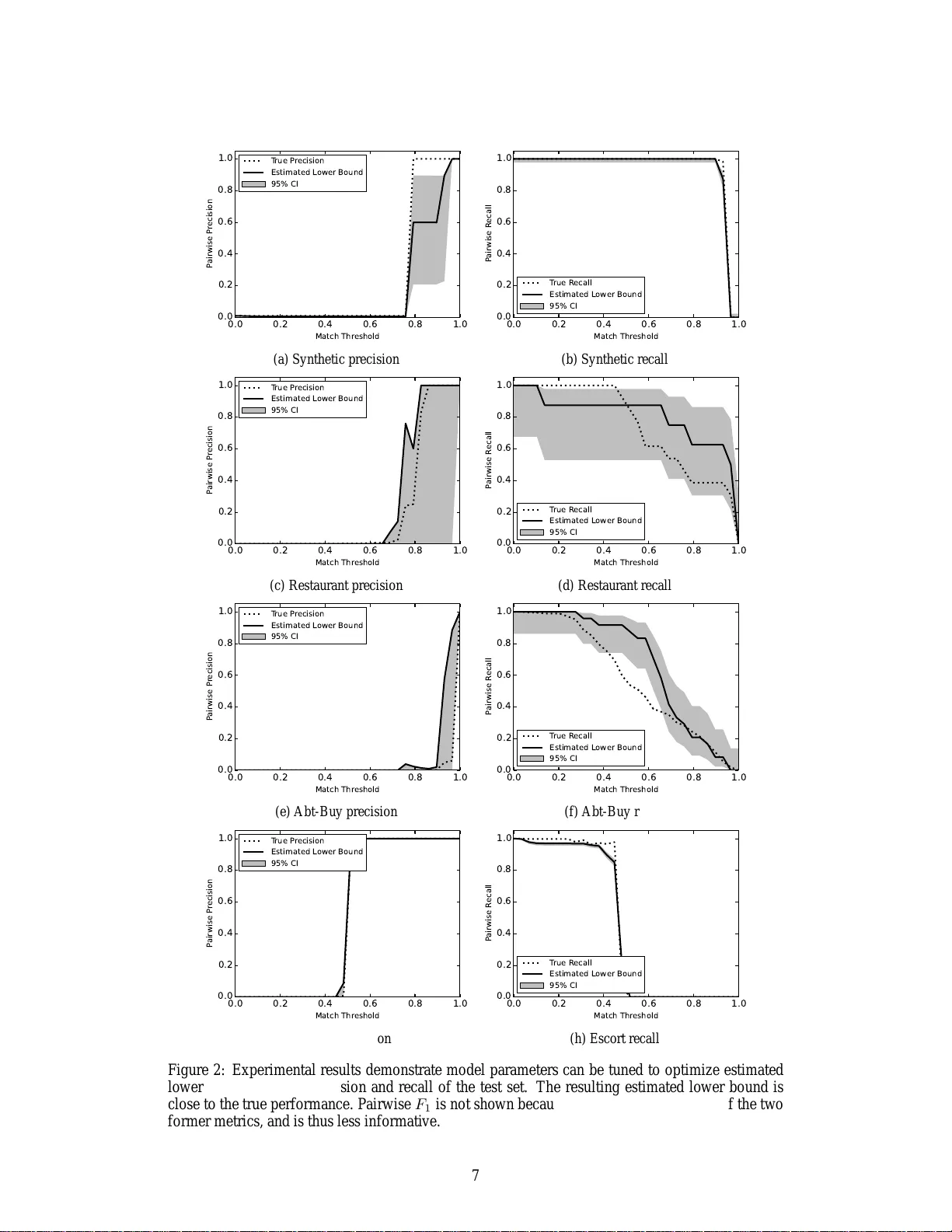
P erf ormance Bounds f or Pairwise Entity Resolution Matt Barnes School of Computer Science Carnegie Mellon Uni versity Pittsb urgh, P A 1521 3 mbarnes1@cs. cmu.edu K y le Miller School of Computer Science Carnegie Mellon Uni versity Pittsb urgh, P A 1521 3 mille856@and rew.cmu.edu Artur Dubrawski School of Computer Science Carnegie Mellon Uni versity Pittsb urgh, P A 1521 3 awd@cs.cmu.e du Abstract One significant challeng e to s caling entity resolutio n algorithms to massi ve datasets is under standing ho w performan ce changes after moving b eyond th e realm of small, manually labeled ref erence datasets. Unlike traditional machin e learning tasks, wh en an entity resolu tion algo rithm perfor ms well on small hold- out datasets, there is n o guarantee this perform ance holds on larger hold-o ut datasets. W e prove simple boundin g pr operties between the perfo rmance of a match fu nction on a small validation set and th e perfo rmance of a pair wise entity resolution algorithm on arbitrar ily sized datasets. Thus, our appr oach enables op- timization of pairwise entity resolution algorithms for large datasets, using a small set of labeled data. 1 Intr oduction Entity resolutio n (ER) is the task of iden tifying record s belonging to the s ame entity (e.g. individual, produ ct) across one or multiple datasets. Iron ically , it has multiple names: dedu plication and recor d linkage, amon g other s [ 1]. For examp le, ER is used to d isambiguate sho pping produ cts [2], merge datasets of users from d isparate sourc es, o r even p rofile p otential terro rist threats. With the u se o f blocking techniques, entity resolution can be scaled to many millions of records [3]. The can onical example in T able 1 illustrates the usefuln ess of p airwise ER for these application domains. Initially , the match fun ction may only p redict r 1 ≈ r 2 using the co mmon ph one nu mber, where ≈ denotes a match. A partial nam e may not be a strong enough comm onality to pred ict either of th ese individually m atch r 3 . However , the merge of these recor ds h r 1 , r 2 i , wh ere h i deno tes a merge, provides the full name ‘John Doe’ and enables corre ctly merging all three records. T o design an e ffecti ve entity resolution system, o ne would optim ize over the ER merge and match function s. One might be tem pted to ev aluate and optimize an ER system o n a small dataset with known labels, a nd then extend th is to real- world applicatio ns. W e stress th at per forman ce on small datasets doe s n ot necessarily imp ly similar perfor mance on large datasets. Unlike mo re tradition al machine learnin g tasks, in ER applications the numb er of entities of ten scales linearly with th e size of the dataset [1]. This is no t true in o ther c lustering pro blems, where th e num ber of clu sters is typically constant or sublinear with the dataset size – a significantly easier prob lem. Further, the ‘no negativ e evidence’ assum ption [1 , 4] can cause a ‘snowball effect, ’ wh erein several false po siti ves trigger many more clusters to merge, leadin g to a detrimental degradation in perfor mance. 1 T ab le 1: Cano nical Entity Resolution Example Record Name1 Name2 Phone r 1 John D. 377-8 328 r 2 J. Doe 377-8 328 r 3 John Doe 1 0 0 3 0 0 5 0 0 7 0 0 9 0 0 Da t a b a se S i z e 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P r e c i si o n P r e c i si o n De g r a d a ti o n O r i g i n a l O p t i m i z e d L o w e r Bo u n d Bo u n d 9 5 % C I O p t i m i z e d , tr u e Figure 1: A simple expe riment demonstra tes the po tential d egradation o f pairwise prec ision as the size of the dataset in creases. Here the ‘Origin al’ algo rithm (dash ed line) was tun ed fo r op timal perfor mance on a training set o f 100 records. ‘Optimized Lo wer Boun d’ (solid line) shows o ur results after instead o ptimizing m odel p arameters over the larger dataset’ s e stimated lower boun d. ‘T rue’ (dotted line) shows the actual perf ormance corresponding to this lo wer bound. Consider the simple example in Figure 1, using synthetic data describe d in Sectio n 5.1. First, we learned a match function using a small trainin g dataset of 100 records. On a test dataset of compara- ble size, it achieved near perf ect pairwise pr ecision and recall. Howe ver , as we adde d new entities to the test dataset, pairwise precision significantly degrad ed – an e xtreme e xample of the entire dataset snowballing into a single entity . M ore importan tly , near perfect perfo rmance on the larger datasets was possible (do tted line), just with different match function parame ters. Using our appr oach to in- stead optimize over the larger dataset’ s estimated lower bo und dramatically improves perfo rmance on the large set (solid line). Although performance on a small lab eled d ataset d oes not directly equate to perf ormanc e on an actual larger d ataset, some usefu l info rmation does exist which we will leverage into an estimated lower bou nd for ER perfor mance on arbitrarily sized problems. Th en, optimization of the estimated lower bound allows tuning of pairwise ER systems for large datasets. In this paper, our contributions are: 1. Th eoretical Perform ance Bo unds: W e prove simple, estimated , lo wer bou nds on p airwise recall, precision, and F 1 perfor mance metrics for ar bitrarily sized datasets, unde r reason - able assumptions and giv en a small number of labeled record pairs. 2. Em pirical T ightness: W e ev aluate the boun ds o n one synth etic and three real world datasets to demonstrate the theoretical bound s are tight to the true perf ormances. 3. Op timal Merge Function: Given any match function, we p rove a lower -bound optimal merge fu nction and ‘wr apper’ for the match fun ction. Th is conservati ve strategy is equiv a- lent to finding all connected compo nents, a key insight of the simple bounds. The remainder of the p aper is o rganized as follows. W e begin section 2 with a quick overview of related work in the field o f entity resolutio n. In sections 3 and 4, we derive the e stimated lower bound s and optimal merge function , respecti vely . Lastly , in section 5 we demonstra te the empirical tightness of the bound on real world datasets. 2 2 Related W ork Entity resolution en compasses a broad s et of a pproach es, including many adapted fro m the ma- chine learning, o ptimization, and grap h theory dom ains. Strategies app ropriate for ER inclu des hierarchica l clusterin g [5], in teger linear pro gramming [6], laten t Dirichlet allo cation [7], pairwise match/merge [4], Mar kov logic [8] and hybr id human-mach ine systems [9]. Pairwise entity r esolu- tion ap proach es are appealing b ecause th ey u se an intuitive and easy to implem ent iterative match and merge process between pairs o f reco rds. Furth er , un der c ertain assum ptions, pairwise algorithms will perfor m the optim al number of record comparisons [4]. Perhaps the most gen eral f ramework for p airwise entity r esolution was pr esented by Benjelloun et al. [4]. They o utlined a th eoretically disciplined approa ch, where in certain prop erties of the match and merge fun ction guaran tee a d eterministic output in the o ptimal num ber of reco rd com parisons. W e explore the use of some of these prop erties in the deriv a tion of our b ound s. Collecti vely , these proper ties are ref erred to by their acronym ICAR: 1. Id empoten ce: ∀ r, r ≈ r and h r , r i = r . 2. Com mutativity: ∀ r 1 , r 2 , r 1 ≈ r 2 iff r 2 ≈ r 1 , and if r 1 ≈ r 2 , then h r 1 , r 2 i = h r 2 , r 1 i . 3. Associativity: ∀ r 1 , r 2 , r 3 such that h r 1 , h r 2 , r 3 ii an d hh r 1 , r 2 i , r 3 i exist, h r 1 , h r 2 , r 3 ii = hh r 1 , r 2 i , r 3 i . 4. Repr esentativity: If r 3 = h r 1 , r 2 i then for any r 4 such that r 1 ≈ r 4 , we also have r 3 ≈ r 4 . The first th ree properties are straigh tforward and r easonable to assume f or m ost E R systems. Th e crux of determinism falls on the final proper ty , repr esentativity . W e, too, will take advantage o f this con venien t p roper ty , leaving the interesting pro blem of how relaxing this assumption af fects the perfor mance bo unds f or future work. Intuitively , represen tati vity means merging any two reco rds can only mon otonically increase their chanc e of m atching with othe r reco rds. T his is also referr ed to as the ‘no negativ e evidence’ clause. 3 Lower Bounds of P erf ormance Although ma ny metrics exist to evaluate entity resolution perf ormance when a groun d truth dataset is av ailable, this is rarely the case. Not sur prisingly , human-gen erated clusterings rarely numb er beyond a tho usand r ecords [2] – a relatively easy ER problem. Even find ing p ublicly a vailable datasets with groun d truth so that we cou ld objecti vely e valuate our results was a trying task. In the simplest setting, we ass ume we ha ve access to some pairs with known binary match/mismatch label y , such that x iid ∼ p ( x | y ) . For large datasets, finding all record s b elongin g to one entity is a worst- case com binatorial pro blem, but finding just two match ing record s is re lati vely easy using a hy brid human- machine s ystem [9] or with strong features (e.g. phon e number , prod uct ID) W ith both match and mismatch pairs at our dispo sal, we created a training and validation set of labeled pairs. The remaining records form the test dataset. No te the training and validation s ets will likely h av e significantly different class b alance, cluster sizes, and overall num ber of sam ples than the test set. Tho ugh an en tity resolution alg orithm may perform well o n the validation set with few samples and small cluster sizes, this may no t indicate strong perfor mance on the full data set with millions of re cords and many more clusters. In p ractice, a developer n eeds to k now perf ormanc e guaran tees of the test set beca use this is the deployed system. Here, we derive precise relationships between the perform ance of the match function on the valida- tion record pairs and estimated lower bounds on ER pairwise precision, reca ll, and F 1 on the test set. Our notation for the following proofs, which the reader may find con ven ient to refer back to, is: h r i , r j i Record forme d by mergin g reco rds r i and r j . V Set of validation record pairs with kno wn labels, V = { ( r 1 , r ′ 1 ) , . . . , ( r m , r ′ m ) } . V S Set of record pairs in the validation set with p ositiv e label, V S = { ( r i , r ′ i ) : y i = 1 , ∀ ( r i , r ′ i ) ∈ V } . 3 V M Set of record pairs in the validation set that a re predicted to directly match, V M = { ( r i , r ′ i ) : r i ≈ r ′ i , ∀ ( r i , r ′ i ) ∈ V } . T Set of test records { r 1 , . . . , r n } . T M Set of record pairs in the test set that are predicted to directly match, T M = { ( r i , r j ) : r i ≈ r j , i < j , ∀ r i , r j ∈ T } . R Set of record pairs in the entity resolution clustering of the test set. S Set of record pairs in the true clustering of the test set (unk nown). P rec ( R, S ) Precision of predicted and true positi ve pairs, P r ec ( R, S ) = | R ∩ S | / | R | . Recal l ( R , S ) Recall of predicted and true positi ve pairs, Recal l ( R, S ) = | R ∩ S | / | S | . C V Class balance of pairs in the validation set, C V = | V S | / | V | . C T Estimated class balance of pairs in the test set, C T = | S | / | P air s ( T ) | . Lemma 1. F o r entity resolution systems satisfying the r epr esentativity p r op erty , every recor d pair that dir ectly matches will end up in the s ame entity . T M ∈ R . (1) Additional pairs in R can occ ur f rom chains of m atches (i.e. r 1 ≈ r 2 , r 2 ≈ r 3 , thu s ( r 1 , r 3 ) ∈ R ) and from merging (see T a ble 1). Howe ver , we are unable to make stron g claims about the additio nal matches since composite records do not occur in the validation set. Pr oo f. Supp ose o n the co ntrary there exists a p air of reco rds ( r 1 , r 2 ) , su ch that ( r 1 , r 2 ) ∈ T M but ( r 1 , r 2 ) 6∈ R . In othe r words, r 1 ≈ r 2 and they are resolved to sep arate entities I 1 = h r 1 , .... i and I 2 = h r 2 , .... i . Since these clusters wer e no t merged in th e ER process, h r 1 , .... i 6≈ h r 2 , .... i , which contradicts the representativity pro perty . Theorem 1. The pairwise pr ecision of an entity r esolu tion r esult ca n be lower bound ed by: E [ P r ec ( R , S )] ≥ | T M | | R | C T (1 − C V ) E [ P r ec ( V M , V S )] C V (1 − C T ) + ( C T − C V ) E [ P r ec ( V M , V S )] . (2) The b ound is composed of two parts. | T M | / | R | is the fraction of record pairs in the test set entity resolution th at d irectly ma tch, which we can make strong er claims about. P rec ( V M , V S ) is the precision of these direct matches, adjusted for the change in class balance. Pr oo f. From Lemma 1 and app lying the definitions of pairwise precision for R and T M : E [ P r ec ( R , S )] = E | R ∩ S | | R | , ≥ E | T M ∩ S | | R | , = | T M | | R | E [ P r ec ( T M , S )] , ≥ | T M | | R | C T (1 − C V ) E [ P r ec ( V M , V S )] C V (1 − C T ) + ( C T − C V ) E [ P r ec ( V M , V S )] , where the last step fo llows f rom equating the match fun ction validation set performan ce to the expected match function test set performan ce using change in match/mismatch class balance. Most of the values are straightfo rward to coun t from the resolu tion. | R | is the numbe r of pairs in the clustering o utput. | T M | is th e number of reco rds that directly match, wh ich by Lemma 1 can be efficiently com puted as P ( r 1 ,r 2 ) ∈ R r 1 ≈ r 2 . 4 The class b alance of the validation set C V is k nown, b u t we m ust estimate C T . W e refe r the read er to state-of-the-ar t results fo r class prior estimation [10, 11]. Theorem 2. The pairwise r e call of an entity r esolution r esult ca n be lower bounded by: E [ Re cal l ( R, S )] ≥ E [ R ecal l ( V M , V S )] . (3) In other words, the r ecall on the validation set alre ady for ms a lower bound fo r the pairwise recall on the test resolution. Pr oo f. From the defin itions of pairwise recall for T M and R an d then applying Lemma 1: E [ Re cal l ( R, S )] = E | R ∩ S | | S | , ≥ E | T M ∩ S | | S | , = E [ Recal l ( T M , S )] , = E [ Recal l ( V M , V S )] , where the last step does not require c lass rebalancing because recall is not a function of class balan ce (unlike precision, it only depends on the positi ve pairs). A lower b ound on p airwise F 1 (the h armonic m ean o f pairwise prec ision and recall) can b e computed with the two fo rmer lower bound s. W e will focu s m ore on measuring both pairwise precision and recall as they are more informative than the aggregated F 1 metric. 4 Optimal Merge Function Giv en any match fu nction m satisfying the id empoten ce and commutativity p roper ties, we will pr ove a merge func tion and ‘wrapper ’ match functio n that optimize the estimated lower bounds. Since the idempoten ce property is trivially satisfied for any match functio n by checkin g for identica l reco rds and the commu tati vity p roper ty is satisfied by check ing both directions r 1 ≈ r 2 and r 2 ≈ r 1 , this essentially hold s for all p airwise match fun ctions. These match and merge f unctions form a conservati ve strategy , but provide the lower bound op timal performa nce given only labeled pairs. W e con sider the original set of records R = { r 1 , . . . , r n } and use notation o for a record form ed by merging at least tw o other records. Theorem 3. F or any match function, the pairwis e pr ecision, r ecall, and F 1 estimated lower bounds ar e optimal for the mer ge function: h o 1 , o 2 i = [ r i ∈ o 1 ,o 2 r i (4) The corr esponding ‘wrapper’ matc h function between o 1 and o 2 is: o 1 ≈ o 2 = max r i ∈ o 1 ,r j ∈ o 2 m ( r i , r j ) . (5) Pr oo f. W e will show both direction s, that the optimal merge f unction and m atch ‘wrapp er’ must make at least these ma tches to satisfy the ICAR pr operties, a nd that any additio nal matc hes will decrease the estima ted perfo rmance lower boun d. By the definitio n of the set union op erator, th e merge function is ass ociative. The rest of the proof will focus on the representativity property . Dir e ction 1 : W e ar e constrained b y match a nd merge function s that satisfy th e ICAR prope rties. In the first directio n, we will show these are the minimu m matches required to satisfy repre sentativity . Assume on the con trary: th ere exist two com posite records o 1 and o 2 , such that o 1 6≈ o 2 but o ne pair of the ir constituent recor ds match , i.e. r i ≈ r j , for som e r i ∈ o 1 , r j ∈ o 2 . By definition , this contradicts the representativity pro perty . Dir e ction 2 : In the second direction, we will show any additional matches will increase | R | an d thu s decrease the estimated pair wise p recision lower b ound. Assume ther e exist two recor ds o 1 and o 2 , such th at o 1 ≈ o 2 but none of th eir co nstituent reco rds match, i.e. r i 6≈ r j , ∀ r i ∈ o 1 , r j ∈ o 2 . The additional match o 1 ≈ o 2 may increase | R | , thus decre asing P rec ( R, S ) . 5 The simplicity of this approach is d eriv ed f rom o nly claiming p erform ance k nowledge of direct record m atches fr om the v alidation set perfo rmance. Interestingly , this ER system is equivalent to finding a ll co nnected compon ents, where each edg e A ij = r i ≈ r j in the adjacency matrix A . W e stress that thoug h this may o ptimize the estimated lower bound performa nces, it does no t necessarily guaran tee better performa nce. Howe ver , if g round truth is n ot av ailable for a dataset of comparab le size to the deployed system, then this is no w a theoretically well motiv ated approach. A significant benefit of Theorem 3 is the provid ed match function need not satisfy the very restrictiv e representativity property . Further, since the idempoten ce and co mmutativity p roperties ar e trivial to s atisfy , m can be essentially any match function. For exam ple, one cou ld use more comp lex machine learning b ased match functio ns (e.g . kernelized SVM, r andom f orests) an d featu rizations which may no t have intuitiv e merge opera tions (e.g. word2 vec [12], Brown clustering [13]). Using less restricti ve match functions undoubtedly e nables better P rec ( V M , V S ) and Recal l ( V M , V S ) , further improving the lo wer bounds. 5 Experiments W e conducted experiments on multiple da tasets with known gr ound truth to empirically demon strate the tightne ss of the estimated lo wer boun ds. Specifically , we are interested in optimizing ER model parameters over the estimated lower bounds and over the groun d truth m etrics to sho w they achie ve similar results. 5.1 Datasets W e used one synthetic and three real world datasets with kn own gro und truth for our experim ents, as described in T able 2. For all these datasets, the goal of entity resolution is to find record s describin g the same entity ( e.g. restaurant, produ ct, or person) . For the synthetic dataset, we gen erated each record’ s features using a fe ature vector un ique to its respecti ve entity , plus random Gaussian noise. Unlike general mach ine learning tasks, p ublicly av ailable entity resolutio n datasets with kn own groun d tru th are e xtremely limited, and do not number b eyond se veral thousand reco rds. The restau- rant dataset is one o f the e arliest ER tasks discussed in literature [14], and still used today [9, 1 5]. Unfortu nately , the dataset is also relativ ely small – nu mbering only 8 64 reco rds and fiv e feature s (name, phone num ber, street address, city , cuisine) . W e threw away the phone n umber featur e be- cause it made the problem too simple. The Abt- Buy dataset is mor e recen t, larger at 217 3 recor ds, and used extensively in curr ent resear ch [ 9, 1 6]. It consists of pr oduct inf ormation from two retailers, including product name, description, and price. Both the Restaurant and Abt-Bu y datasets are a class o f entity resolutio n known as clean-clean, wherein two ‘clean’ datasets with completely resolved entities are merged together [3]. This p roblem is easier than the more gen eral pr oblem of resolving entities with an unknown n umber o f reco rds. T o fo rmulate these datasets in a more general context, we merged them toge ther into a single ‘dirty’ dataset and ignored the advantageous ‘clean -clean’ knowledge in our experimen ts. Lastly , we ev aluated a subset of a personal ads dataset scraped from escort advertising websites ov er the past fe w years [1 7]. W e used natur al-languag e-pro cessing algorithms to extract 20 features, such as n ame, ag e, location, and hair color of the per son being advertised. For ground truth , we used a subset of the data containing phone number match es as a prox y label. Although ph one num bers will not allow us to discover the full groun d truth, it is rea sonable to assum e a ds with the same phone T ab le 2: Datasets u sed in the experiments Dataset # dim # records # matches Synthetic 10 1000 4500 Restaurant 1 4 864 112 Abt-Buy 2 3 2173 1118 Escort (subset) 20 10000 10596 1 http://www .cs.utexas.edu/users/ml/riddle/data/restauran t.tar .gz 2 http://dbs.uni-leipzig.de/file/Abt-Buy .zip 6 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a i r w i se P r e c i si o n T r u e P r e c i si o n E st i ma te d L o w e r Bo u n d 9 5 % C I (a) Synthetic precision 0 . 0 0 .2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a irw i se R e c a l l T ru e R e c a l l E st i m a t e d L o w e r Bo u n d 9 5 % C I (b) Synthetic recall 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a i r w i se P r e c i si o n T r u e P r e c i si o n E st i ma te d L o w e r Bo u n d 9 5 % C I (c) Restaurant precision 0 . 0 0 .2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a i rw i se R e c a ll T ru e R e c a l l E st i m a t e d L o w e r Bo u n d 9 5 % C I (d) Restaurant recall 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a i r w i se P r e c i si o n T r u e P r e c i si o n E st i ma te d L o w e r Bo u n d 9 5 % C I (e) Abt-Buy precision 0 . 0 0 .2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a i rw i se R e c a l l T ru e R e c a l l E st i m a t e d L o w e r Bo u n d 9 5 % C I (f) Abt-Buy recall 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a i rw i se P r e c i si o n T r u e P r e c i si o n E st i ma te d L o w e r Bo u n d 9 5 % C I (g) Escort precision 0 . 0 0 .2 0 . 4 0 . 6 0 . 8 1 . 0 M a t c h T h r e sh o l d 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P a i r w i se R e c a l l T ru e R e c a l l E st i m a t e d L o w e r Bo u n d 9 5 % C I (h) Escort recall Figure 2: Experimen tal results dem onstrate m odel parameter s can be tun ed to optimize estimated lower b ound pairw ise precision and recall of the test set. Th e resultin g estimated lower bo und is close to the true perfor mance. Pairwise F 1 is not shown because it is the h armonic mean of the two former metrics, and is thus less inform ativ e. 7 number belong to the same en tity (i.e. person or group ) beca use those num bers are the mean s of contact for potential customers. 5.2 Entity Resolution W e used the R-Swoosh algor ithm for our ER systems [4]. For the merge fu nction, we simply used the set unio n of the respectiv e features. For example, in T able 1, h r 1 , r 2 i would be [ { J., John } , { D., Doe } , { 377-8 328 } ] . For th e match fun ction, we trained a bin ary log istic regression classifier using known matches an d mismatches in the trainin g dataset. Like all pairwise entity resolution algorithm s, it operates on pairwise f eatures, which we co mputed from two records’ features using eithe r a b inary matc h (e.g. state, hair color), nu merical difference (e.g. ages, weig hts), or Lev enshtein string edit distance (e.g. name) of each feature p air . If a re cord ha d m ultiple of a p articular fe ature fro m a m erge operatio n, we used the closest feature match. Another b enefit of using a probab ilistic ma tch fu nction is th e cho ice of p arameters is reduced to a single value: the cut- off thresh old. The choice o f cut- off th reshold is a classic tr ade-off between precision and recall – an ideal setting to examine the results of our bounds. 5.3 Results T o examine the efficacy o f the estimated lo wer bound in tuning an entity resolution system, we ev a luated the true and lower bo und perfo rmances across tightly spaced in tervals of m atch cut-off thresholds, as shown in Figures 2. Th e tightness of the bou nds demonstrate two important qualities. First, they enab le the optim ization of mod el par ameters (e.g . cut-off thresh old) using the estimated lower bound . Tho ugh this may no t necessarily r esult in the true (un known) optima l param eters, it will result in the b est estimated lower b ound . Second , it enables en forcing a level of acceptable quality prior to the use of any entity resolution results. One may be surprised to see the estima ted lower bound exceed the tru e perfor mance. This is, indeed, po ssible because of uncertain ty in estimations of P re c ( V M , V S ) , R ecal l ( V M , V S ) and C T . The 95% co nfidence in tervals are obtained via th e p ropag ation of validation set W ilson scores f or precision and recall [18]. Un certainty in creases as the gap betwe en validation set an d test set sizes widen, a p henomen on observable in Figu re 1. For very sm all datasets such as Restaurant, we were restricted to using minimal validation samp les due to the small number o f labels. Howe ver, for larger experiments such as Abt-Buy and Escor t, we could af ford hundreds or thou sands of validation samples, significan tly reducing uncertain ty . T his is also th eoretically motiv ated by the shift in class balance in Theor em 1. The fou r experiments demo nstrate different ER behavior . Th e synthetic exper iment has a narrow range o f mode l parameter s with pe rfect prec ision and r ecall, wh ere p erform ance de grade s dramati- cally o utside th is r ange. The Restaurant experiment has a mor e gradu al tradeoff between pr ecision and r ecall, thoug h there is a significant u ncertainty in the lower bou nd estimate due to the limited number o f validation samp les. Precision in Abt-Buy quick ly degrades, thou gh rec all is much more gradua l. O ur b ound s correctly captu re the nee d to improve the un derlying ER system s f or the Abt- Buy an d Escort datasets. W ith out this lower boun d, the p oor p erforman ce on larger datasets wou ld not be evident fro m smaller tests. 6 Conclusions Performan ce optimization of scala ble en tity reso lution systems is c hallenging be cause u nlike other machine learning tasks, there is not a clear und erstanding of how behavior will chan ge o n larger datasets. In this paper, we developed a simple – yet effective – method fo r optimizin g lower bound perfor mance using a small set of labeled p airs. Further, we showed the optimal lower bound strategy for any match function is the co nnected com- ponen ts pro blem f rom graph th eory – a relatively conservative clustering approach compared to many ER systems. W e u nderstand that this does not necessarily guarantee better per forman ce, but it doe s provide a better lower-bound guarantee. For instance, in our o riginal example in T able 1, r 3 8 would have matched neither r 1 nor r 2 . Ho wever , wh en lab eled datasets o f co mparable size to the deployed system are not a vailable, t his is now a theoretically well moti vated appro ach. Our bound s sp ecifically addressed performa nce o f pairwise entity r esolution alg orithms satisfying the ICAR pro perties [4]. Pairwise algorithm s are intuiti ve, easy to implem ent, and perfo rm an optimal n umber of pairwise reco rd compa risons. Howe ver , they ar e a lso o nly a subset of entity resolution appr oaches [ 1, 5, 6, 7, 8, 9]. Furth er , we o nly considered pairwise precision, recall, and F 1 due to their popu larity , intuitive interpretation and mathem atical convenience, though other existing metrics ha ve been sho wn to produce conflicting rankings [2]. Estimating th e lower b ounds relies on accur ate estimation s of se veral other quantities, including recall and precision on the validation set and class p rev alence estimation in the test set. Especially as datasets scale to muc h larger sizes, our bou nds rely on these estimates. As evident in The orem 1 and in our experim ents, uncertain ty in creases as the g ap between validation and testing set sizes widened. Refer ences [1] Li se Getoor and Ashwin Machanav ajjhala. Entity resolution: theory , practice & open challenges. Pr o- ceedings of the VLDB Endowment , 5(12):2018–2 019, 2012. [2] David Menestrina, Stev en Euijong Whang, and Hector Garcia-Molina. Evaluating entity resolution re- sults. Proce edings of the VLDB Endowment , 3(1-2):208–21 9, 2010. [3] Georgios Papa dakis. Blocking T echniqu es for efficien t Entity Resolution o ver lar ge, highly heter og eneous Information Spaces . PhD thesis, Leibniz Univ ersit ¨ at Hannov er , 2013. [4] Omar Benjelloun, Hector Garcia-Molina, David Mene strina, Qi Su, Stev en Euijong Whang, and Jennifer W idom. Swoosh: a generic approa ch to en tity resolution. The VLDB J ournal – The Internationa l J ournal on V ery Lar ge Data Bases , 18(1):25 5–276, 2009. [5] Mikhail Bilenko, S Basil, and Mehran Sahami. Adaptiv e product normalization: Using online learning for reco rd linkage in comparison sh opping. In 5th IE EE In ternational Confer ence on D ata Mining . IEE E, 2005. [6] Nir Ailon, Moses Charikar , and Alantha Newman. Aggregating inconsistent information: ranking and clustering. Jou rnal of the A CM (J ACM) , 55(5):23, 2008. [7] Indrajit Bhattacharya and Lise Getoor . Coll ectiv e entity resolution in relational data. A CM T ransaction s on Knowledg e Discovery fr om Data (TKDD) , 1(1):5, 2007. [8] Parag Singla and Pedro Domingos. Entity resolution with markov l ogic. In Sixth IEEE International Confer ence on Data Mining , pages 572–582. IEEE, 2006. [9] Jiannan W ang, T im Kraska, Michael J Franklin, an d Jianhua Feng . Crowder: Cro wdsourcing entity resolution. Pr oceedings of the VLDB Endowment , 5(11):1483–1 494, 2012. [10] Marthinus Christof fel Du Plessis and Masashi Sugiy ama. Semi- supervised learning of class balance und er class-prior change by distribution matching . Neural Networks , 50:110–119, 2014. [11] Marco Saerens, Patrice Latinne, and Christine Decaestecker . Adjusting the outputs of a classifier t o new a priori probabilities: a simple procedure. Neural computation , 14(1):21–4 1, 2002. [12] T omas Mikolov , Kai Chen, Gre g Corrado, and Jef frey Dean. Efficient Estimation of W ord Representations in V ector S pace. In Pr oceedings of the International Confer ence on Learning Repr esentations (ICRL) , 2013. [13] Peter F Bro wn, Peter V Desouza, Robert L Mercer , V incent J Della Pi etra, and Jenifer C Lai. C lass-based n-gram models of natural language. Computational Linguistics , 18(4):467–479, 1992. [14] Sheila T ejada, Craig A Kno block, and Steven Minton. Learning object identification rules for info rmation integration. Information Systems , 26(8):607–6 33, 2001. [15] Hanna K ¨ op cke and Erhard Rahm. Training selection f or t uning entity matching. In QDB/ MUD , pages 3–12, 2008. [16] Hanna K ¨ op cke and Erhard Rahm. F rame works for entit y matching: A comparison. Data & Knowledge Engineering , 69(2):197–2 10, 2010. [17] Larry Greenemeier . Human Traf fi ckers Caugh t on Hidden Internet. Scientific American , 2015. [18] Edwin B W ilson. Probable i nference, t he law of succession, and statistical inference. J ournal of the American Statistical Association , 22(158):209 –212, 1927. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment