제리 프리드만과 데이터 과학 혁명의 대화
이 인터뷰는 제리 프리드만의 어린 시절부터 물리학 박사 과정, SLAC에서의 컴퓨팅 연구, 그리고 통계·머신러닝 분야에서 CART, MARS, 부스팅, RuleFit 등 혁신적인 알고리즘을 개발한 과정을 조명한다. 그의 학문적 전환, 초기 컴퓨터 경험, 그리고 현대 데이터 과학에 미친 영향이 간결히 정리된다.
저자: N. I. Fisher
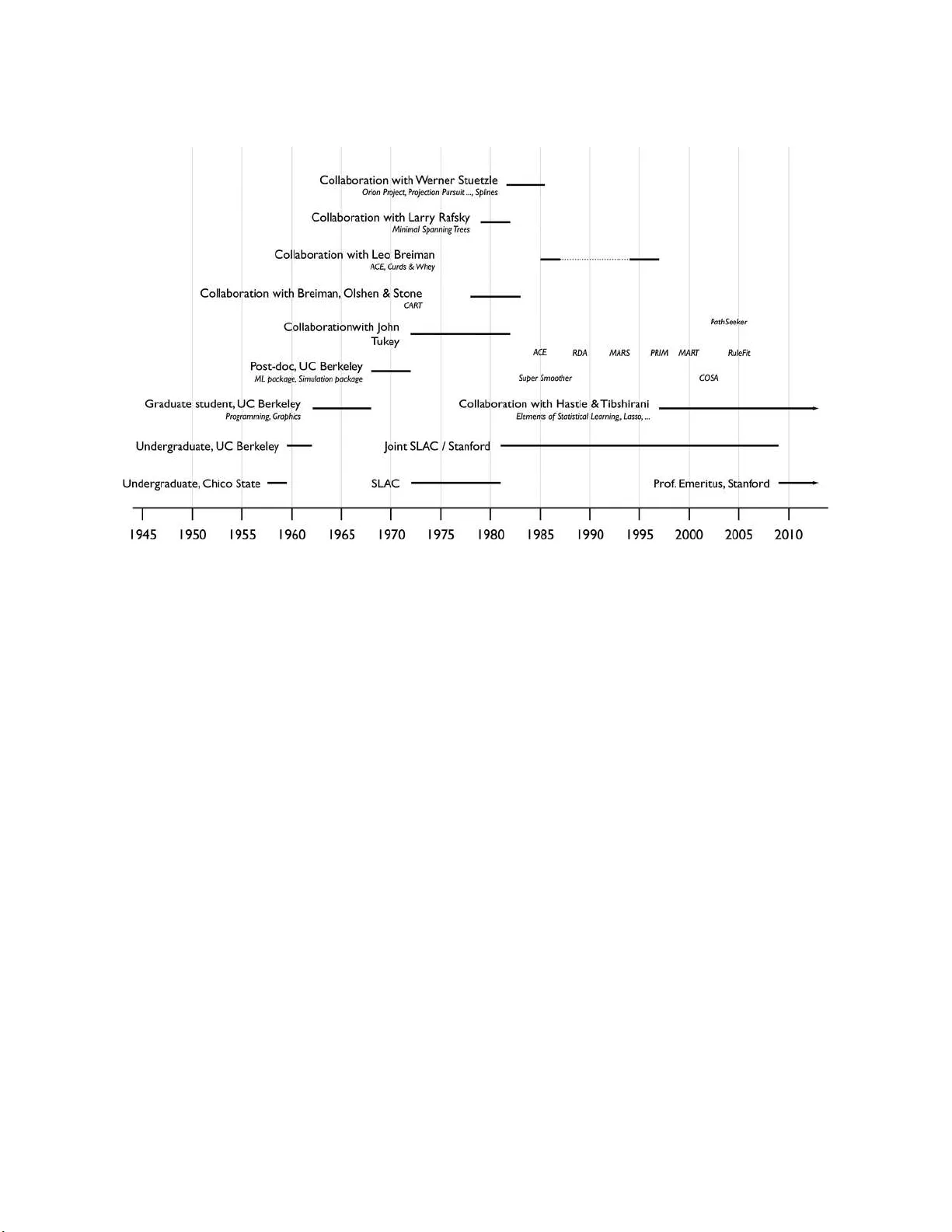
‘A Conversation with Jerry Friedman’은 2015년 통계학 저널에 실린 인터뷰 형식의 기사로, 저자 니콜라스 피셔가 2012년 8월에 캘리포니아 팔로알토에서 진행한 대화를 기록한다. 인터뷰는 프리드만의 인생 여정을 크게 네 단계로 나누어 서술한다.
첫 번째 단계는 1939년 캘리포니아 주 Yreka에서의 유년기이다. 그는 전자공학에 일찍 흥미를 보이며 라디오 수신기와 진공관 트랜시버를 직접 제작했다. 고등학교 시절 교장에게 ‘대학에 갈 수 없을 것’이라는 평가를 받았지만, 아버지의 조언에 따라 Chico State College에 진학했고, 파티 문화와 알코올이 난무하던 환경을 겪으며 학업에 대한 의지를 다졌다. 이후 화학과 공학 과목을 수강한 뒤 물리학에 매료돼 UC Berkeley로 편입했다.
두 번째 단계는 1959‑1972년 베클리에서의 학부·대학원 생활이다. 프리드만은 학부 시절 B+ / A‑ 수준의 성적을 유지했으며, 베클리 물리학과에 진학해 고에너지 입자 물리학을 전공했다. 베트남 전쟁 시기의 군 징집 위협 속에서도 학업을 지속했고, 결국 1968년 물리학 박사 학위를 받았다. 박사 과정 중에는 Lawrence Berkeley Radiation Lab에서 버블 챔버 영상을 수동으로 스캔하고, 패턴 인식을 수행하는 일을 맡았다. 이때 그는 물리 실험 데이터의 자동화 필요성을 절감하고, Fortran을 이용해 산점도와 히스토그램을 자동 생성하는 프로그램을 개발했다. 이 프로그램은 ‘Kiowa’라는 이름의 통계 패키지로 전 세계 고에너지 물리학자들에게 배포되었으며, 이후 ‘Sage’라는 범용 Monte Carlo 시뮬레이터도 만들었다.
세 번째 단계는 1972년부터 2006년까지 SLAC(Stanford Linear Accelerator Center)에서의 컴퓨팅 연구이다. 프리드만은 SLAC의 Computation Research Group을 이끌며 대규모 입자 충돌 데이터의 처리와 분석을 담당했다. 이 시기에 그는 통계적 학습 방법을 물리학 문제에 적용하면서, 데이터 마이닝과 머신러닝의 초석을 놓았다. 1981년부터는 스탠포드 통계학과와 반시간 교수직을 겸했으며, 학계와 산업계 사이의 교량 역할을 수행했다.
네 번째 단계는 1990년대 이후 통계·머신러닝 분야에서의 혁신적인 알고리즘 개발이다. 프리드만은 Leo Breiman, Charles Stone 등과 공동으로 ‘Classification and Regression Trees (CART)’를 발표했으며, 이는 변수 선택, 트리 분할, 가지치기(pruning) 등 전 과정을 체계화한 최초의 결정 트리 알고리즘이다. CART는 이후 R의 ‘rpart’, Python의 ‘sklearn.tree’ 등 다양한 패키지에 구현돼 오늘날에도 널리 사용된다. 이어서 ‘Multivariate Adaptive Regression Splines (MARS)’를 개발해 비선형 회귀와 변수 상호작용을 스플라인 형태로 자동 탐색하도록 했다. MARS는 해석 가능성과 예측 정확도 사이의 균형을 잘 맞추어, 의료·금융·환경 데이터 분석에 폭넓게 적용된다.
프리드만은 또한 부스팅(Boosting) 개념을 초기부터 탐구했으며, 약한 학습기들을 순차적으로 결합해 강력한 예측 모델을 만드는 방법을 제시했다. 이와 연계된 ‘RuleFit’은 트리 기반 규칙을 선형 회귀에 통합해 모델 해석성을 크게 향상시켰다. 이러한 방법론들은 모두 ‘통계적 컴퓨팅’이라는 관점에서, 통계 이론을 효율적인 알고리즘과 소프트웨어 구현으로 연결한 결과물이다.
인터뷰는 프리드만이 초기 컴퓨터 환경(IBM 704, IBM 650, 펀치카드)에서 겪은 어려움과, Fortran을 배우며 프로그래밍에 눈을 뜬 과정을 상세히 서술한다. 그는 하드웨어와 소프트웨어가 서로 보완적인 관계에 있음을 강조하며, 물리학자들이 ‘sissy work’라 부르던 프로그래밍 작업이 실제로는 과학적 발견에 핵심적인 역할을 했다고 회고한다.
마지막으로 인터뷰는 프리드만의 수많은 영예와 수상 경력을 정리한다. Rietz Lecture(1999), Wald Lectures(2009), 미국 국립 과학원(NAS) 회원(2010) 등 학계 최고 영예를 받았으며, ACM Data Mining Lifetime Innovation Award(2002), IEEE Data Mining Research Contribution Award(2012) 등 산업계에서도 인정받았다. 그의 저서 ‘The Elements of Statistical Learning’은 현재 데이터 과학 교육 교재의 표준이 되고 있다.
전체적으로 이 인터뷰는 프리드만이 어떻게 물리학자에서 통계·머신러닝 선구자로 변모했는지를 보여주며, 초기 컴퓨팅 경험, 탐색적 데이터 분석 도구 개발, 그리고 현대 데이터 과학의 핵심 알고리즘 창출 과정을 일목요연하게 정리한다. 그의 이야기는 오늘날 데이터 과학자가 갖추어야 할 ‘통계적 사고 + 프로그래밍 실무’의 중요성을 재조명한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기