A Conversation with Jerry Friedman
Jerome H. Friedman was born in Yreka, California, USA, on December 29, 1939. He received his high school education at Yreka High School, then spent two years at Chico State College before transferring to the University of California at Berkeley in 19…
Authors: N. I. Fisher
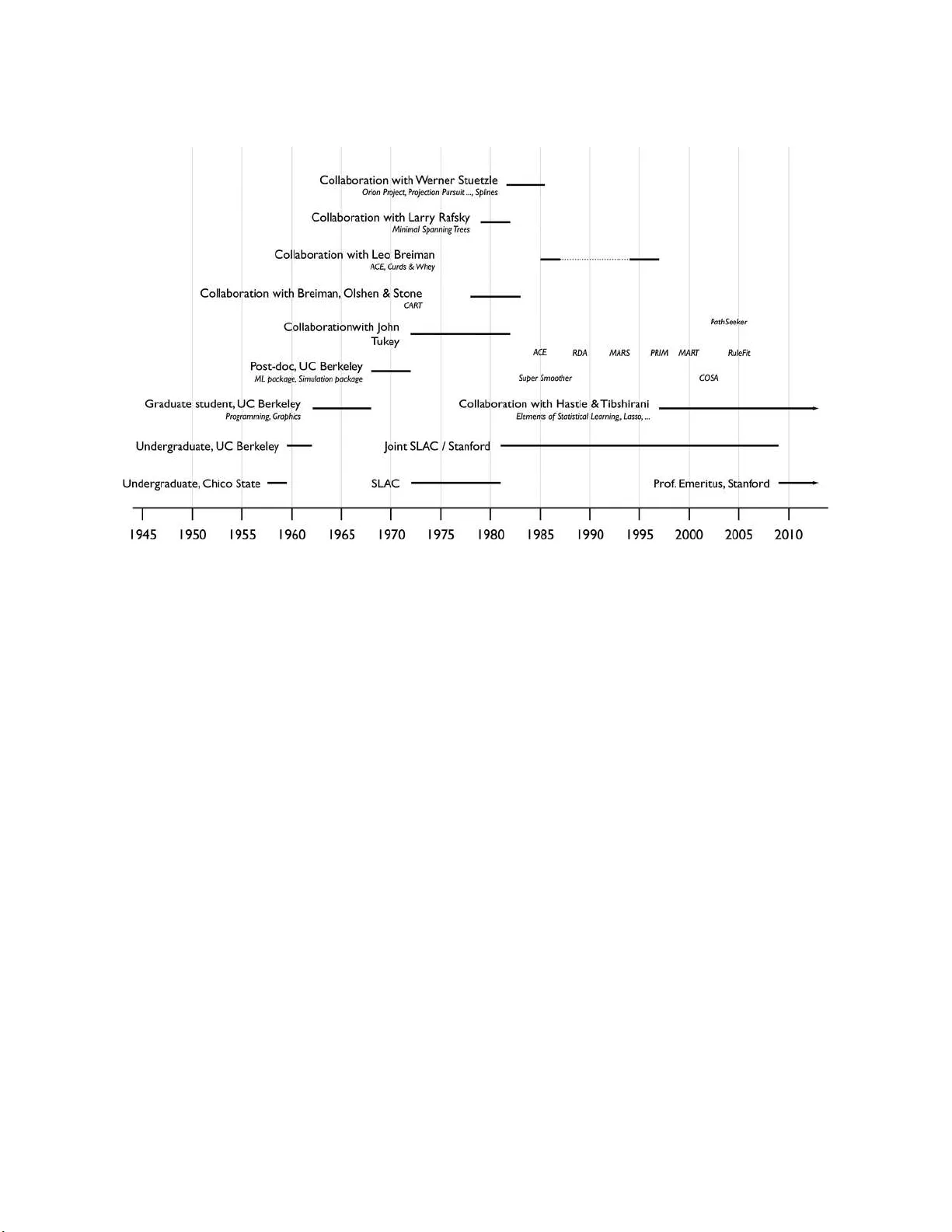
Statistic al Scienc e 2015, V ol. 30, No. 2, 268– 295 DOI: 10.1214 /14-STS509 c Institute of Mathematical Statisti cs , 2015 A Conversation with Jerry F riedman N. I. Fisher Abstr act. Jerome H. F riedman w as b orn in Y rek a, California, US A, on Decem b er 29, 1939. He receiv ed his high sc ho ol educatio n at Y rek a High Sc ho ol, then sp ent t wo y ears at Chico S tate College b efore trans f erring to the Un iv ersit y of California at Berkel ey in 1959. He completed an un- dergraduate degree in physics in 1962 and a Ph.D. in h igh-energy p ar- ticle physics in 1968 and w as a p ost-doctoral researc h ph ysicist at th e La wrence Berk eley Lab oratory du r ing 1968–19 72. In 1972, he mov ed to Stanford Linear Accelerato r Center (SLAC) as h ead of th e Compu- tation Researc h Group, retaining this p osition un til 2006. I n 1981, he w as app oin ted half ti me as Professor in the Departmen t of Statistics, Stanford Unive rsity , remaining half time with h is SLA C app oint ment. He has held visiting app ointmen ts at CSI R O in Sydney , CERN and the Departmen t of Statistics at Berk eley , and h as had a very activ e career as a commercial consu ltan t. Jerry b ecame P r ofessor Emeritus in the Departmen t of Statistics in 2007. Apart f r om some 30 pu b lications in high-energy physic s early in his career, Jerr y has p ublished o ve r 70 re- searc h articles and b o oks in s tatistics and compu ter science, including co-authoring th e p ioneering b o oks Classific ation and R e gr ession T r e es and The Elements of Statistic al L e arning . Many of h is publications ha ve h und reds if not thousan d s of citations (e.g., the CAR T b o ok h as ov er 21,000 ). Muc h of h is soft ware is incorp orated in commercial pro d ucts, including at least one p opular searc h engine. Man y of his metho ds and algorithms are essen tial inclusions in mo d ern statistica l and data min- ing pac k ages. Honors includ e the follo win g: the Rietz Lecture (1999) and the W ald Lectures (2009 ); electio n to the American Academy of Arts and Sciences (2005) and the US National Academ y of S ciences (2010 ); a F ello w of the American S tatistical Asso ciation; Pap er of the Y ear ( JASA 1980, 1985; T e chnometrics 19 98, 1992); Statistician of th e Y ear (ASA, Chicago C h apter, 1999 ); A CM Data Mining Lifetime In- no v ation Award (2002), Eman uel & C arol P arzen Aw ard for Statistical Inno v ation (20 04); No ether Senior L ecturer (American Statistic al Asso- ciation, 2010); and the IEE E Computer So ciet y Data Mining Researc h Con tribution Award (2012 ). The interview wa s recorded at his home in P alo Alto, California dur- ing 3–4 August 2012. Key wor ds and phr ases: A CE, b o osting, CAR T, mac hine learning, MARS, MAR T, pro jection pur s uit, RuleFit, statistical compu ting, sta- tistical graphics, statistical learning. Nicholas Fisher is Visiting Pr ofessor of Statistics, Scho ol of Mathematics and Statistics F07, University of Sydney, NSW 2006 , Austr alia e-mail: Nicholas.F isher@sydney.e du.au . This is an electronic repr int of the orig inal a rticle published by the Institute of Ma thematical Statistics in Statistic al Scienc e , 2015, V ol. 30, No. 2, 268–2 95 . T his reprint differs from the original in pagination and t yp ogr aphic deta il. 1 2 N. I. FISH ER Fig. 1. Early days—Y r eka. 1. EARL Y D A YS (1939–1959) NF: W elcome Jerry . Let’s b egin at the b eginning, whic h wa s n ot in this part of California. JF: That’s correct. I grew up in a tin y to wn near the Oregon b order called Y rek a: it’s “bak ery” sp elled backw ards without the “ b.” Y rek a Bak ery is a palindrome. . . and there was a Y rek a Bake ry in Y rek a. NF: What we re your p aren ts doing? JF: My mother was a housewife and m y fa- ther, along with his brother, o wned a laundr y and dry-cleaning establishment there that they and my grandparents found ed in th e 1930 s. NF: W ere yo ur grandparents b orn in America? JF: No, one s et was b orn in the Ukraine I th in k; I’m not sure where th e other set was b orn. They certainly we ren’t b orn in the US, as they all had hea vy accen ts. NF: Do y ou h a ve siblings? JF: One b rother sligh tly y ounger th an me. He’s no w retired and living in LA. He was an account ant for most of his life. NF: Ho w was school? JF: Sc ho ol w as ok a y . I wa s a dramatic under- ac h iever. I wasn’t very interested in school; I was mainly interested in electronics, so I w as into ama- teur radio, building radio electronics—transmitters, receiv ers and that kind of thing—as a kid. This was v ery u n usu al for someone in Y rek a. I w as r eally an outlier, but I though t electronics w as fascinating, to b e able to talk with p eople on th e other side of the w orld with no w ir es. No w , it’s ju st tak en for grante d. In those da ys sh ort wa ve radio was the only w a y to do it. When I w as r eally young in grammar sc ho ol— 10 to 1 3—I us ed to build crystal sets al l the time. Then I graduated to v acuum tu b es, tr an s mitters and receiv ers. It’s very differen t electronics than today . V acuum tu b es op erate at v ery high vol tage. So often while y ou’re p oking around tr y in g to see why a cir- cuit isn’t w orking, all of sudd en y ou pic k yo urself u p on the other s ide of the r o om b ecause you touc h ed a p lace at ab out 400 or 500 volt s. T o da y’s electron- ics r un at 5 vo lts. I r emem b er bugging the math teac her in mid dle school to teac h me square ro ots b ecause I needed that to understand some things in this electronics b o ok th at I w as reading. NF: Did y ou h av e an yb o d y that y ou could talk to ab out this stuff ? JF: Y es, I had a friend whose father was in am- ateur radio and knew a lot ab out electronics, so I could talk with him ab out it. My father w ent to talk to the principal b efore I graduated high sc ho ol and ask ed what h e sh ould do with me. The principal said, “W ell he’s not going to mak e it in college . Y ou migh t try Chico State and when he flunks out y ou ca n put him in th e a rmy .” So that is ho w I got to Chico State. Its claim to fame no w is that it’s where Sierra Nev ada P ale Ale b eer is brew ed. NF: What wa s yo ur view of this opinion? JF: I didn’t w ant to go to Chico Stat e, I wa nte d to go to Berke ley . S o w e struc k an agreemen t th at I w ould go to Ch ico for t wo yea rs and if I w asn’t doing to o badly , I could consider transferrin g to Berk eley . My father was r igh t ab out that. He w asn’t often righ t, bu t he wa s righ t ab ou t that. A t th at time Chico State w as one of our country’s b iggest and b est kno wn part y s chools, not big in size, bu t its rep- utation as a p art y sc ho ol wa s w ell deserv ed . There w ere big parties every n igh t. I used to lo ok forw ard to summer v acatio ns when I could get relief f rom all those parties. E v ery night we drank an enormous amoun t. There were no d rugs around at that time, but there wa s lots of alcohol. When I left for Berke - ley t wo y ears later I was ready to do something m ore A CONVERSA TION WITH JERR Y FRI ED MAN 3 serious, wh ic h m igh t not h a ve happ ened if I had gone directly to Berk eley . NF: Did y ou actually go to Chico State w an ting to learn something sp ecific? JF: I wa sn’t su re what I w an ted to b e, either a c h emist or an en gineer. I think I w ant ed to b e a c h emist and I to ok the elemen tary c hemistry course. I remem b er that we w ere learning how to test for acidit y u sing litm us pap er, wh ic h is a real ordeal, and I n oticed that the engineering stud en ts w ere taking the same lectures as us and they were in the same lab, bu t their lab w as not as in tense as ours and they we re using some sort of meter. Y ou pu t the meter in the solution and it displa ye d the pH. I said, “I like that,” so I switc hed to engineering and actually did engineering at Chico. But there w as a v ery , v ery goo d p hysic s p rofessor there who got me v ery interested in physics, so when I transferred to Berk eley I decided to study ph ysics. 2. UC BERKELEY 1959–1972 NF: Y ou then sp ent the n ext t wo years as an un - dergraduate at Berk eley . Ho w w ell d id y ou do? JF: I think it actually to ok me t w o and a half y ears. I w as working my wa y through sc ho ol. I had no money . I d id fairly we ll. T hose w ere the d a y s b e- fore grade inflation, so I had ab out a B+ / A − a ver- age, whic h in those d a ys w as considered go o d . No w they get v er y imp atien t if you don’t hav e straight A’s, but in those da ys A’s weren’t as easy to get. (See th e anecdote U nder gr aduate days at Berkeley in the e arly ‘sixties in Fisher ( 2015 ).) NF: Let’s mo ve on to y our transition from und er- graduate to graduate stud en t. Y ou’re at the end of y our un dergraduate program and y ou‘re now decid- ing what to do. What wa s your p assion of the day? JF: I wan ted to go in to Ph ysics. I though t it v ery in teresting and I couldn’t find anything else I f ound more in teresting. I never to ok a statistics course. NF: There was n o d oubt that y ou w an ted to do it at Berk eley? JF: Y es, I lo ve d Berk eley , still do. I lik e b eing in the Ba y Area. Ho w ev er, there was a p roblem. In those da ys there wa s the military draft. Sin ce I h ad tak en an extra s emester to go through u n der- graduate sc ho ol, I wa s ineligible f or an automatic deferment through graduate sc ho ol. And yo u had to b e in sc h o ol to a void b eing drafted into the Army . I though t graduate sc h o ol in finitely p referable to the arm y . So for a w hile I was worried that I w ould b e d rafted b ecause I was classified 1A, healthy and ready to go. I ev en w en t down to th e Oakland In- duction Cen ter and had m y pr e-induction ph ysical and so I figured: this is it, I’m going in to the army . Vietnam w asn’t big then, s o that w as not an issue I was worried ab out. Learning physic s seemed to b e more fun than the army w ould b e. One day I re- ceiv ed my new draft card—they reissued them ev ery y ear or something lik e that—and instead of sa yin g 1A, it said 2E, whic h meant s tu den t deferment. So I h ad a dilemma b ecause I thought maybe it w as a t yp ographical error. The n ext time I was in Y rek a, I was torn b et w een either keeping my mouth shut and hoping they wo uldn ’t disco ver the mistak e, or going up to the Draft Board and asking them if it w as r eal. I fin ally decided I’d b etter fin d out. Th e secretary of the Draft Board said, “Y ou are 2E,” and when I looked at her pu zzled, she said, ‘W ell, the Draft Board decided that sin ce y ou work ed y our w a y through sc ho ol, it’s ok a y th at y ou took an extra semester to get through.” NF: Virtue is more than its own rew ard. JF: I guess so. Also, they’re giv en quotas to fill. There are many kids in Y rek a who don’t go to co l- lege. In f act, in those days th ere w er e very f ew, so there w ere lots of y oung men not in college whom they could in d uct. They did n’t necessarily need me to fill their quota. NF: W as it hard to get in to graduate sc ho ol? JF: I don’t kn o w, I think it w as, but I w asn’t v ery resp onsib le. Berke ley physics w as the only graduate departmen t I applied to. Y ou shou ld apply ev ery- where, but it wa s the only one I applied to. If I hadn’t b een accepted, I wo uld ha v e gone into the arm y . NF: What wa s the v iew of your parent s ab out pursu ing gradu ate studies rather th an going b ac k and helping out in the bu siness? JF: Oh, I really knew I wasn’t going bac k to Y r ek a. Mac k Da vis, who is a coun tr y s in ger/songwriter, grew up in Lubb o ck, T exas. He wa s once asked wh at it was like to gro w up in Lubb o c k. He said, “W ell, happiness is L ubb o c k in y our rear view mirror,” and that’s the wa y I usually though t ab out Y rek a. It w as a nice place and all, bu t it w asn’t the place for m e. NF: Ho w did yo ur Ph.D. studies go? JF: They w ent w ell. As things got more d ifficult m y grade p oin t a v erage seemed to go up rather than do wn and I really enjo y ed it; I lo v ed doing it. I w ork ed harder and of course there was alw a ys the 4 N. I. FISH ER military d raft there if you flu nk ed out. The defer- men t w as go o d as long as y ou w ere in school. F ortu- nately for me, I didn’t flun k out and I really enjo yed learning physics. During the summers I’d w ork ed at radio stations, but in the winter when I was at school I work ed in the library sta c king b o oks, whic h I didn ’t really lik e that m uc h. My ro ommate ment ioned that there w ere these great j obs at the La wrence Berk eley Ra- diation Lab oratory . They did manual pattern recog- nition on bubble c h am b er images of elemen tary par- ticle reactio ns. Th ey needed p eople to s can the film and pic k out the particular p atterns that they w ere lo oking for. It was a grea t job, a bit b oring, but it paid muc h b etter than the libr ary , and so I w ent up there. That’s when I s tarted getti ng in terested in high-energy ph ysics. The leader of the group was Louis Alv arez. A t the time Alv arez hadn’t ye t re- ceiv ed his Nob el Pr ize. He receiv ed it later in 1968 when I w as a graduate studen t in his group. After I got my degree, h e an d his son were the ones w ho came up with the meteor / dinosaur extinction the- ory . One of the sm artest men I’v e ev er m et. NF: Did y ou end u p w orking with him? JF: No, I work ed with Ron Ross, one of the p ro- fessors in his group. I w orked there as a bub ble c h am b er scanner for a while. T hen wh en I had to c h o ose a thesis topic there were t wo r easons for go- ing into high-energy ph ysics. O ne was the Alv arez Group. The other o ne w as that in the courses that I took in th e fi rst t w o y ears my weak est su b ject w as quan tum mec hanics. I thought if I w en t into high energy-particle physics, I would really hav e to learn quan tum mec hanics w ell. NF: W ere y ou doing an y computing at this stage? JF: I didn’t do an y computing. . . well, ac tually I did, around 1962. Th e wa y I started computing is an inte resting story . I w as there as a scann er and one of the more adv anced physics graduate students w ould sometimes ask me to do little tasks for him b esides the scannin g. On e time he ask ed me to draw a scatt er p lot. He ga v e m e a piece of graph paper, a p en and a list of the pairs of num b ers. He said, “What you d o is for eac h pair of n umb ers, fin d the corresp ondin g p oint on the graph and you put a d ot there with the p en.” I wa s doing this for a while and of co urse I’d rep eatedly m ess up and ha v e to start o ver again. One of the other students said, “Y ou kno w, do wn on the fir st fl o or they ha ve a thing called a computer and it has a catho d e ra y tub e ho ok ed up to it, and it automatica lly make s scatter plots. Y ou can write a program to place the p oints on the cathod e ra y tub e. A camera then photographs the tub e so you can tak e a slide of this scatter plot an d print it.” I thought , Boy, is that a go o d ide a! I g ot a b o ok ab out programming compu ters and I d r ew m y scatter plots w ith ease. NF: What we re you pr ogramming in? JF: Mac hine language and F ortran. F ortran was brand new then and the only high-leve l p rogram- ming language. It was very con tro v ersial b ecause real p rogrammers did n ’t program in F ortran, they programmed in mac hine (assembly) language. There w as a s ign o v er the ent rance to the pr ogramming group office that said “Any pr ogram that can b e written in F ortran d eserv es to b e.” I guess that’s still true to da y . NF: What wa s the n atur e of the hardware? JF: The first co mpu ter that I actual ly pro- grammed w as a v acuum tub e computer (it wasn’t ev en a d iscrete transistor compu ter) called an IBM 704. It had mag netic core memory . There w as also an IBM 650 w ith rotating dru m memory . I lik ed the 650, eve n though it was muc h slo w er, b ecause for that y ou could just walk up and use it. With the 704 you had to b o ok time and wait to get yo ur job run. The whole thing at Berk eley used punch cards. I didn’t see a text editor u nt il I w ent to SLA C. The greatest in ven tion I ever saw wa s the termi- nal with th e bac kspace ke y . With pun c h cards, if y ou mak e a mistak e, y ou’ve got to thro w the card a wa y and start ov er again from th e b eginning. I n the Alv arez Group I wa s one of those who did most of the p rogramming. In those d a ys , it w as consid- ered sissy work to some exten t. Real p h ysicists b uilt hardware—dete ctors, particle b eams, etc. P rogram- ming w as sissy work. High-energy ph ysicists don’t think that w ay an y more b ecause most of them do programming. But I lik ed programming muc h b etter than building hardware. NF: What w ere yo u d oing in y our Ph.D. stud ies? JF: It w as part of a large p h ysics exp eriment in the 72-inc h hydroge n b ubble c ham b er, w hic h was the same d etector that pro duced th e film I w as scanning b efore. I studied a particular r eaction for my thesis: reactions in v olving th e k − meson. NF: Wh at sort of hard skills w as this calling on, mathematical skills, computational skills? JF: Certainly c omputational skills and under- standing th e theoretical ph ysics of the time, which did in v olv e some math. Y ou had to build a program, and that mean t fi gu r ing out the algorithms to write A CONVERSA TION WITH JERR Y FRI ED MAN 5 the program. While I w as there as a graduate stu- den t I wrote a suite of exploratory data analysis pro- grams that almost ev eryo ne in high-energy p hysic s w as usin g. NF: So y ou w er e actually writing a statistica l pac k age. JF: Y es. Physicists d id n’t do m u c h h yp othesis testing and things lik e that; it was mostly ex- ploratory , automatically m aking scatter plots, his- tograms, v arious other kind s of displa ys mostly dis- pla y ed on hardwa re of the time, whic h w as mostly this line prin ter output. Ki owa (that’s th e name of an Indian trib e) was a pac k age that I wr ote. It w as the standard statistical pac k age in high-energy physic s all ov er the world, for m an y years. I also wrote a f ast general-purp ose Mon te Carlo program called Sage . Physicists did a lot of Mont e Carlo for sim ulating particle r eactions. I wa s still getting en - quiries ab out Sage t w ent y years later, and I b eliev e that some p eople are still u sing it. NF: At some p oint during yo ur computing activ- ities y ou came across Maximum Lik eliho o d. JF: That’s probab ly wh en I first really started get- ting in terested in statistics. There w as a physicist, F rank Solmitz, in the Alv arez group wh o knew a lot ab out statistics. He’d wr itten a little tec hnical r e- p ort ab out fundamental statistics for ph ysicists and I though t that w as really in teresting. Th en another guy , Ja y Orear, who wa s also a physicist , wrote a lit- tle note on maxim um lik eliho o d mo del fitting (Orear ( 1982 )). W e w ere fitting a lot of mo dels and he kn ew ab out least squares. I though t that m axim um lik eli- ho o d was the most elegan t idea I h ad ev er seen and it sort of p erk ed my interest in statistics. Of course it was inv ented b y Fisher, but I didn’t kno w that; I though t that Jay O rear in v ente d it. NF: When did y ou gradu ate? JF: I got my degree in 1968 an d then they con- sidered me a go o d graduate student, so they w an ted to hire m e as a p ostdo c ph ysicist at Berk eley . P ost- do cs in those days could run forever and th ey did for a lot of p eople. S o I sta y ed until 1972 in the same Alv arez group doing muc h the same k in d of things, differen t exp eriments but b asically the same stuff. By then SLAC (Stanford Lin ear Accelerator Cen- ter) had come online and so I was in vo lv ed in an exp eriment that w as running at SLA C while I w as at Berk eley . NF: Had y ou started interacting with SLA C? JF: W ell, not really , I mean the data w as tak en to SLAC, bu t I nev er really wen t do wn to SLA C m uc h except to wa tc h the b eam. W atc hing the b eam means that you are taking data; it’s a b eam of elec- trons (at Berk eley it w as a b eam of p rotons) and it smashes into matter and then the reaction p ro du cts come out and they’re detected by p article detectors. There’s a huge amount of electronics con tr olling all that. S o someone has to b e in the control ro om mon- itoring the electronics to b e su r e that ev erything is ok a y and th at y ou’re still taking the data at a rea- sonable rate. NF: When had SLAC b een set u p? JF: SLA C had b een built in the sixties, it may ha v e started in th e fi f ties and it came online in the mid-sixties (1966). This was one of the first exp eri- men ts at SLA C. It w as an electron mac hine, s o w e w ere in collaboration w ith some S LA C p eople at Berk eley . Our bu bble c h am b er w as mov ed to SLAC. The d ata w as tak en ther e and b rough t to Berke - ley to b e scanned, measur ed and an alyzed. I didn ’t sp end m uc h time at SLA C du ring th at p erio d . NF: Wh y we re th e data going to Berk eley? JF: Because that is the w a y h igh-energy physics w orks ev en to da y . There is a lot of data to analyze, it is very labor-intensiv e, and so yo u s pread the work around and it gets done faster. NF: In other wo rds, d istributed computing? JF: In a sense, yes. Also, these exp erimen ts w ere v ery exp ensiv e to run, so p eople lik e to get toget her and do it in collaboration. In those da ys there were collaborations of tens of physicists, n ow there are collaborations of dozens of lab oratories. 3. THE MO VE T O SLAC (1972) NF: Wh y did you mo ve to SLA C? JF: W el l, we had a new director of th e Rese arc h Division at Berk eley who decided that p ostdo cs should n ot sta y on forev er and that three y ears w as the maxim um p ostdo c term. So he fired all p ostdo cs who had b een there f or more than th r ee y ears. That included me, so I had to go out and fi nd a job. Bac k then, job a v ailabilit y in h igh-energy physics w as cyclic. There would b e a lot of them and then there w ould n’t b e many . This was a time wh en there w eren’t man y . I d id hav e a few go o d opp ortunities, but they in volv ed mo vin g a w a y fr om the Ba y area and I didn’t wan t to d o that. So F r ank S olmitz, the physic s–statistics guy , came u p to me one day in the hallw a y and said, “Th ere’s a p osition at SLA C lead- ing a computer science researc h group and they w ere asking me wh o migh t b e a go o d computing physi- cist for that and I mentio ned y our name. Are y ou 6 N. I. FISH ER in terested in exploring it?” I though t it w asn’t r e- ally for me but I could explore it. So I w en t down and I in terview ed. First I in terview ed w ith all the directors and all the grou p leaders at SLAC, then I in terview ed with all of the professors in the Com- puter Science Departmen t on campus. Originally they w ante d to get a famous computer scien tist to run that group, but they couldn’t find one that they lik ed and who lik ed them, so they decided to get a computing p h ysicist, whic h is wh y they landed on me. After I returned from in terviewing I figur ed that w as it. It was a fun exp erience, but I didn’t think I w an ted it and they didn’t wan t me. Then I got a call a week or so later sa ying, “There’s b een m ore than a little interest in yo u. What do you w ant to do?” I said, “I think I’d b etter talk to th e p eople in the group b efore I do anything else.” I wen t and talke d to the p eople in the group . Th ey w ere really go o d p eople, so I thought, Why not ? So I w ent down to SLA C to lead th is computation researc h group. It w as set up b y Bill Miller, who initially established the co mpu tin g facilit y at SLA C. They wa nted h im to build u p the Computing Cen ter so h e would only come under certain conditions. One condition was that he b e made a pr ofessor in the Computer Sci- ence Department. Another condition w as that h e w ould b e able to ha v e his o wn computer science re- searc h group at SLAC. SLA C had a lot of physics researc h group s but h e w ould ha v e his in computer science and th at w as this group . He ev entually b e- came Prov ost of the Un iv ersit y (Stanf ord Unive r- sit y), s o that p osition was op en and that’s where I w en t. NF: Ho w were thin gs set up? JF: He had a lot of bright p eople there. A n umb er w ere in compu ter graphics, w hic h was in its infancy in those da ys. He had set up a really state-of-the-art computer graph ics facilit y , in cluding mo vie-making equipment worth millions of dollars, wh ic h w as a lot of money in those da ys. It was really state of the art. There were p eople d oing r esearc h in other areas of computer science, and a few p ure service t yp es d oing job-shop programming for th e physicist s at SLA C; o verall, ab out ten p eople in the group. NF: So you h ad the s ort of tec hnology adv ant age that the Bell Labs’ statistics group h ad rather later on with their workstat ions. JF: Y es, this was a fan tastic facilit y . Also, S L A C w as a physics lab and high-energy physics labs had more co mpu ting than an yb o dy else exce pt for w eap ons lab oratories. I had access to the computing facilities at SLAC, in cluding th eir mainframe com- puting system. V ery few statisticia ns had access to that kind of computing at th at time or ev en fifteen y ears later. NF: What did the job inv olv e? JF: The job inv olv ed mainly ru nning the group as an admin istrator and th en doing my o w n researc h . I th ink they exp ected me to do half a nd half: I did ab out one quarter admin istration, three qu ar- ters researc h. I arrive d there in early 1972, commut- ing from Berkele y for the first six months. Also, I w as ask ed to teac h an elementa ry computer liter- acy course in the Computer S cience Department. It w as a course on algorithms, data str u ctures and computer arc hitecture. I knew some of those things a little b it, but in order to teac h the course I had to learn them all in detail. It was one of the most v aluable courses I’v e ev er taught in terms of what I learn t. I still u se most of it in m y work to d a y . The resea rch that I w an ted to do was in pat- tern r ecognition. Even when I was a student and then a p ostdo c at Berke ley , I w as inte rested in data. I‘d wr itten some analysis pac k ages, I’d d one Monte Carlo, an d I’d written a p rogram to do maxim u m lik eliho o d. My inte rest in d ata w orke d ou t w ell b e- cause m ost other physici sts were more intereste d in building new equipment at that time, whereas I w as in terested in analyzing th e data and that is what got me in to computers. I lo ved computers. NF: Wh at d id you try to do with pattern recog- nition? JF: It w as called pattern rec ognition then; it’s called mac hine learnin g no w. Sort of basic pat- tern recognition, lik e nearest-neigh b or techniques. I’d read the Co ve r an d Ha rt ( 1967 ) pap er and I w as interested in clustering and in general statis- tical learning, but it w asn’t called that then . Th e closest name then wa s “pattern recognition.” NF: Finding groups in d ata? JF: Y es, fin ding g roups in d ata, using data to mak e predictions, th at kind of thin g. I didn’t hav e a clear-cut researc h agenda at th at particular time. I wa s just lea ving Berk eley where I’d mainly done physic s except for the other sort of statistical things, so I hadn ’t really dev elop ed a researc h agenda. I’m not sure I ev er had one. NF: I un derstand that the group that you we re in v olv ed with there had some extraordinary p eople. JF: Y es, it did. When I came, it was common then, and ma y still b e, that in th e (Stanford ) Computer A CONVERSA TION WITH JERR Y FRI ED MAN 7 Fig. 2. A n appr oximate time-line for some of Jerry’s major ar e as of r ese ar ch and r ese ar ch c ol lab or ation. Science Departmen t professors were paid half their salary from the Departmen t an d exp ected to go out and raise the other half externally . On e wa y they could do th at would b e to w ork in other places. In our group w e often had computer science professors w orking part time. When I came, Gene Golub wa s halftime in the group. An d w e had tw o visionaries, Harry S ahl and F orrest Bask ett. Harry w as there when I came. F orr est joined later. T his led to some remark able deve lopments. (S ee the anecdote Build- ing the first Gr aphics Workstation in Fisher ( 2015 ).) Collab o rating w ith John T uke y 1972–1980 NF: Just after you mo ved to SLAC y ou started collaborating with John T uk ey . JF: Y es, my predecessor, Bill Miller, w as clo se friends w ith John T uk ey , so h e’d invited T ukey to come out du r ing his sabbatical b ecause, as w e all kno w, J ohn w as v ery in terested in graphics and h e w as esp ecially intereste d in motion graph ics. Our fa- cilit y was one of the v ery f ew places y ou could do motion graphics. When I arrive d at SLAC ev ery one w as excited that this guy w as coming, not b ecause he w as a great statistician, but he b ecause he was w ell kno wn in computer science for ha ving inv en ted the F ast F ourier T ransform. Th ey were really ex- cited, and I’d neve r heard of him. NF: So w hen John came up y ou did n ot actually ha v e a research p ro ject in mind? JF: No . I talk ed to him an d he tol d me what h e w as doing, what h e w as inte rested in, and I found it very in teresting. W e j u st hit it off. He wo rked on the graphics, I w orke d a little bit on the graphics but not a lot. I w ould watc h what they were doing with the graphics—rotating p oin t clouds and isolat- ing subsets, s a y in g, “Ok a y , let’s just look at these,” and so on—trying to visually find patterns in data. John was mainly w orking w ith a p rogrammer in our group. NF: John nev er p rogrammed, himself ? JF: Not to my kno wledge, at least n ot co de that ev er ran on a computer. He w rote out his thoughts in a kind of pseudo-F ortran, but he nev er actually sat in front of a termin al to execute co de, as f ar as I knew. (See the s ample of T ukey’s researc h notes in Fisher ( 2015 ).) NF: What s ort of ideas w as he ha ving at that time, p oint cloud rotation and so on? JF: W ell, if you see the PRIM-9 mo vie, that’s the pro du ct and those were the ideas he had. It w as ba- sically in tegrating the id ea of rotating p oin t clouds in arbitrary orien tations. He was v ery inte rested in h uman interfaces and he devel op ed some really slic k con trols, esp ecially giv en the cr u deness of the equip- men t he had to w ork with. I was w atc h ing what he 8 N. I. FISH ER w as doing and he would iterate to an int eresting picture and so I started to think: What makes the pictur e inter e sting? and I would discus s this with him. He s aid, “It seems that the pictures we lik e the most are the ones that hav e con ten t; th ey hav e a lot of sm all in ter-p oin t d istances bu t then they ex- pand o v er the whole thing.” When I w as at Be rke- ley I had b een wo rking on optimization algorithms and I though t, wel l, what if we define d some index of clumping and then trie d to maximize it with an optimization algorithm? That w as basically the b e- ginning of p ro jection pursuit and we interacte d on that. So I was off doing the analytical algo rithm and John w as doing the graph ics. NF: What was John’s interest here? He w asn’t actually trying to tac kle a scien tific problem to do with physics? JF: W ell h e though t it would ha v e a big applica- tion in physics b ecause p h ysics has inh eren tly h igh- dimensional data with a great deal of structur e. I t w asn’t like th e sort of diffuse data that comes from the so cial sciences: data from physics ha v e a very sharp structure. In f act, I think the data set that’s illustrated in the movie is a high-energy physics data set. So his vision w as that it could b e u sed for high- energy physics, but I think he was certainly th inking ab out the bigger p icture. I think h e was th ere four months. When he came bac k later for a little while, I said, “John I think w e ough t to mak e a movie of th is,” sin ce w e had a lot of movie -making equ ip men t. My predecessor Bill Miller w as a genius at raising money . He had a graduate student who w as interested in graphics. The student was v ery smart and wa nte d the b est of ev erything, so h e got the b est of ev ery th ing. He knew ho w to h andle the movie equipmen t, so he made the film just p oin ting a camera at the screen with John there talking. So then w e had a film. . . and then no one wan ted to edit it. A new member, Sam Stepp el, had jus t joined the Group and I ask ed, “W ould y ou lik e to do th e editing?” And he said, “Oh yea h.” It turned out to b e a big job. Anyw a y , that w as the result of John T uk ey’s first trip to sta y with us at SLA C. W e sta yed in con tact throughout the 1970 s and he came bac k again for his next sabbatical sev en y ears later. NF: Ho w did yo u find int eracting with h im on the original Pro jection Pur suit pap er? JF: He w as v ery full of ideas and he was v ery stim- ulating. W e seemed to talk the same language, to think ab out things the same wa y . His approac h w as op erational: here’s the task, h ere’s the problem, ho w do w e app roac h it, ho w do w e get it d on e. He didn ’t seem to b e in terested in f undamental principles; he probably w as, but he never said so. NF: A v ery engineering app roac h . JF: V ery engineering, that w as alwa ys his ap- proac h. He alw ays d eligh ted in s ligh tly puzzling y ou b y h iding, not telling y ou the fu ndamenta l reason for whatev er he w as d oing, what la y b ehind it, w hat w ere his reasons. He w ould come to y ou and sa y , “Ok a y , here’s a pro cedure: y ou do this, then y ou do th is, then yo u d o this, th en y ou do that.” I was y oung and brash at the time so I w ould sa y , “John, ok a y , I und erstand that, but why would y ou do this and th is? Wh y is that a goo d idea?” He w ould re- p eat, “W ell, y ou d o this, then you d o this, th en y ou do this, then you do th is,” and I’d sa y , “John, but wh y?” It would go b ac k and forth lik e th at, him acting like there w as no guid ing prin ciple. I guess I w as p ersistent enough that he would finally get ex- asp erated and sa y , “Oh we ll,” and lucidly enunciate the guidin g pr in ciple; he had it all the time, h e ju st didn’t wan t to r eveal it, at least n ot righ t a wa y . His main though t w as he would ev aluate a pro cedu re b y its p erform ance, not by its motiv ations. He wa sn’t in terested in: Is this a Bayesian pr o c e dur e with a p articular prior? Is this a pr o c e dur e that’s optimal in som e sense? He did n’t come from that p ersp ec- tiv e. He would sa y , “All r igh t, you’v e got a p ro ce- dure, tell me the op erations on the data, the explicit op erations. I don’t care where it comes from, I don’t care wh at y our motiv ation is; you tell me the op era- tions that app ly to the data and I’ll tell y ou wh ether I think it’s a go o d idea or n ot.” Th at’s the wa y h e though t ab out th in gs. NF: Do y ou think h e was mentall y chec king this against a hidd en set of pr inciples or seeing how it sat with his instincts? JF: I don’t know whether he alw a ys had a guiding principle or he’d mak e one up so I’d stop asking. I wrote up the first draft of the Pro jection Pursu it pap er, h e edited it and then we discuss ed it. My fir st journal p u blication of an y sort in statistics was the Pro jection Pursu it pap er with John (F riedman and T uke y , 1974 ). T his is the only pap er I h a v e ev er submitted and had accepted immediately w ithout revision, and I though t, This is r e al ly ne at, I like this field . But it’s neve r happ en ed since. NF: Y ou d id some f ollo w-up w ork with him at SLA C. A CONVERSA TION WITH JERR Y FRI ED MAN 9 (a) (b) Fig. 3. F r ames f r om the PRIM-9 vide o. ( a ) Jerry F rie dman. ( b ) John T ukey sitting i n fr ont of the PRIM-9 har dwar e and using the blackb o ar d to give his explanation of the variables in the p article physics data. JF: Y es, he came bac k his next sabbatica l in the early 1980s. I think at that time h e wa s on his wa y to Ha wai i b ecause a cousin or someb o dy w as getting married, and Elizab eth fi nally con vinced him to tak e a v acation there on the b eac h. So h e stopp ed by Stanford and w e work ed together. He w as v ery impressed with the fact that th e home he was sta ying in on campu s had a sw imming p o ol; it w as the house of a professor who was on sabb atical. So he w ouldn’t come in the m orning; he w ould sp end his mornin gs sitt ing b y the p o ol, maybe swimming as well, writing out id eas—lots of ideas—ab out how to analyze high-dimens ional data, us u ally writing in cryptic words or p seudo-F ortran. Then he would bring them in later in the afterno on and ask our sec- retary to t yp e them up . This happ ened ev er y da y . Later, W erner (S tuetzle) and I w ould tak e a lo ok at them and sometimes discuss them with h im. He fin ally to ok off for his v acation in Ha wa ii and the notes stopp ed. A few da ys later, pac k ages of notes s tarted arriving in th e mail, ev ery da y another pac k age fr om Ha waii . He wa s thin k in g on the b eac h instead of at the swimm ing p o ol. I’v e still ha v e man y of these notes. After J ohn died, th er e w as an issue of the Annals that h ad a long article ab out him by Da vid Brillinger (Brillinger ( 2002 )), and W erner Stuetzle and I wr ote a shorter article (F riedman and Stuetzle ( 2002 )) talking ab out his graph ics w ork and our exp eriences with him in his graphics work. A t that ti me w e thought ma yb e w e should get th e n otes together, take a lo ok at them. There are pr obably a tr emendous n umb er of ideas there that are still rev olutionary by to day’s standards in terms of data analysis, but this is one of those things yo u do wh en y ou hav e time. NF: Going bac k to y our o wn p ersonal research, it seems that it w as b ecoming more statistica l. JF: It w as. I w as inte rested in pattern recognition in the general sense and among the more p opu lar metho ds of the time were nearest-neigh b or meth- o ds and k ernel metho ds. Co v er and Hart h ad sh o w n that, asymp toticall y , the nearest-neig hbor classifica- tion metho d reac hes half the Ba yes risk just with the nearest n eighb or. Of course, at that time we didn’t appreciate the difficulty of b ecoming asymptotic in high-dimensional settings. A t the time p eople were v ery excited ab out it and I though t, wel l, if we ar e going to u se this appr o ach in applic ations with bigger data sets like those in high-ener gy physics, we’l l ne e d a fast algorithm to find ne ar est neig hb ors in data sets . A t the time S LA C exp eriment s generated tens of thous ands of observ ations, not m illions like no w, but te ns of thousands. The straigh tforw ard w a y to compute near neighbors is t ypically an n 2 -squared op eration: for eac h p oin t y ou ha v e to make a pass o ver all the other p oints. So I started working on fast algo rithms for findin g near n eighb ors, without to o m uch success. Then I met Jon Ben tley , a student of Don Knuth’s. He had s ome really clev er ideas based on what he called k -d trees, and so he and I started working to- gether with another stud en t, Raphael Fink el, on try- ing to d ev elop fast algorithms f or fin ding near n eigh- b ors. So p robably one of the pap ers that I am b est kno wn for outside statistics is that pap er : fast algo- rithms for fin d ing near n eigh b ors (F riedman, Bent- ley and Fink el ( 1977 )). Then Jon wen t off to gradu- ate sc ho ol at the Univ ersit y of North Carolina. Af- ter that he we nt on to do great thin gs and b ecame 10 N. I. FISH ER v ery f amous in computer science . The whole k-d tree idea is considered a very imp ortant d ev elopmen t in computational geometry , and John in v en ted it, an unbeliev ably bright m an. Another in teresting asp ect is that that’s what got me in to decision trees, b ecause th e k-d tr ee algo- rithm for finding nearest neigh b ors in vo lv ed recur - siv ely partitioning the data sp ace into b o xes. If y ou w an ted to fi nd the nearest neigh b ors to a p oin t, y ou’d tra ve rse the tree do wn to th e b ox con taining the point, fi nd its nearest neigh b or in th e b o x and bac ktrac k up and find its nearest n eighb ors in other neigh b oring b o xes using the tree stru cture. That was the algorithm. I was thinking: ok a y , if y ou w ant to find nearest neig hbors , that’s fin e, but sup p ose the purp ose of fi nding the n earest neighb ors is to d o classification, maybe there would b e mo difications to the tree-building that w ould b e more appropriate for nearest neigh b ors in that con text. So it o ccurred to me that in the n earest-neigh b or algorithm y ou could recursiv ely find the v ariable with the largest spread and split it at the median to mak e b o xes. Wh y d on’t w e find the v ariable that has the most discriminativ e p o w er and split it at the b est discrim- inating p oin t? S o I came u p with that p aradigm to find the nearest neigh b ors. Then it occurred to me that you didn’t need th e nearest neigh b ors at all; y ou could u se the b oxe s (terminal n o des) themselv es to p erform the classification. NF: When wa s this h app enin g? JF: Probably around 1974, b efore I w en t to CERN. That was m y in itial thinkin g ab out w hat eve n- tually b ecame CAR T: it came from the recursiv e partitioning nearest neigh b or algorithm to get the tree structure. Somewhat later I joined with Leo Breiman, Ric hard Olshen and Ch uck Stone who had b een indep endentl y pursu in g v ery similar ideas. Oh, I forgot to men tion that when I first j oined the Computation Research Group in the early 1970s, Gene Golub came to me one d a y and said, “I’m going on s abbatical next yea r, wh ic h means that I won’t b e h ere and I’m worried that if y ou hav e an empty p osition for a ye ar it might not b e there when I get bac k. So I think y ou should fill it with someone and I kno w ju st the ideal guy . His name’s Ric h ard Olshen and he’s in the Statistics Depart- men t.” S o I hired Richard half time. That was in the early d a ys that I was working on trees. I was talking to Ric h ard and he ask ed, “What are y ou do- ing?” “W ell, I’m working on this recursiv e partition- ing idea.” Ric hard got v ery in terested in it an d he has made great con tributions to tree-based metho d- ology o v er the s ucceeding y ears. Visit to CERN 1975–1976 NF: After a few y ears at SLA C, yo u decided to tak e a sabbatical at CERN. Did you hav e a family at this stage? JF: Y es, I had a wife and a three-y ear-old dau ghter at that time, and w e all w en t to CERN, in Genev a. It w as n atural that when physicists to ok a yea r off they we nt to C ERN. It wasn’t an official sabbati- cal, I ju st decided I wan ted a y ear aw a y and so I ask ed for a lea ve of absence. I w as a s taff mem b er, but I wasn’t a faculty memb er . Intelle ctually , it was not sup er stim ulating. I was in the computer group whic h was called Data Handling and it w as a big group at CERN that h ad the compu ters. The pro- fessional thin g I did wa s to work on adaptiv e Mon te Carlo algorithms. What I mainly did was eat their fo o d, drin k red wine and dine at a lot of Mic helin three-star restauran ts, w hic h is what I mainly re- mem b er. CERN w as a lot of fun. SLAC w as quite an in tense place, wh ereas CERN was muc h more laid bac k at that time. NF: Did y ou visit any other groups wh ile yo u w ere at CERN? JF: Y es, I did, whic h turn ed out to b e v ery im- p ortant f or me. When I was at CERN I got a letter from John T uk ey sa y in g, “There’s this fello w I kno w in Z uric h at ETH, P eter Hub er; he is in terested in these pro jection pur suit kinds of stuff. Y ou should go and visit h im.” So I w ent to Zu ric h and found m y w a y f rom the train station to ETH. I’d neve r met P eter or any one else from ETH, so I w as standing there in a h allw ay , and a guy came u p to me and ask ed, “Can I help you?” I guess he knew I sp ok e English, ma yb e it was written all o ver me. I said, “Y es, I ’m tr y in g to fin d P eter Hub er.” He turned out to b e Andr eas Buja, who w as P eter’s student at the time. On that trip I also met another of P eter’s student s, W erner Stuetzle. W e had a strong collab- oration throughout the early 1980s wh en he came to S L A C and Stanford. I think Andr eas also vis- ited SLAC a couple of times. Both are unb eliev ably smart guys. Interface Meetings NF: Returning to your time at SLAC, y ou’d started attending Interface conferences and meeting p eople. . . A CONVERSA TION WITH JERR Y FRI ED MAN 11 JF: Y es. I met L eo Breiman and Ch uck Stone at an Inte rface meeting in 1975. Leo ga v e a talk ab out nearest neigh b or classification or something and I w as working on these fast algorithms at the time, so I raised my h and at the bac k of the ro om and said, “W e’v e b een w orking on s ome new fast algorithms for find ing n earest neigh b ors.” After the talk Leo lo ok ed me up. He w as v ery in terested and we started talking, bu t that wa s prett y muc h it. But th en he sen t me a letter wh ile I w as at CER N saying that he was organizing a meeting in Dallas in 1977; h e called it a conference on The Analysis of L ar ge an d Complex Data Sets . Leo was another visionary; he sa w int o the future of data min ing. He in vited me to giv e a talk there. I’d nev er b een to Dallas and so so on after I got bac k I wen t to that meeting, and that meeting to a large exten t c hanged my life professionally . I met Larry Rafsky there, with whom I later collaborated, and I also m et Bill Clev eland. NF: Ho w did this confer en ce c hange y our life? JF: Because I met Leo again. NF: W e’ll talk ab out Leo shortly . Y ou did some w ork with Larry Rafsky around this time. JF: Y es, w e started talking ab out some of our m utual inte rests in computational geometry (near neigh b ors). This led to the w ork in the late 1970s, early 1980s o n using Minimal Sp an n ing trees for m ultiv ariate goo dness of fit and t wo -sample test- ing, leading also to general measur es of m ultiv ariate asso ciation. Two Annals paper s came ou t of that (F riedman and Rafsky , 1979 , 1983 ). I was also r efi n- ing the recursiv e partitioning idea, extendin g it in v arious w a ys , and I w ork ed with Larr y a b it on this as well . He was a very bright guy with lots of ideas. I learned a lot from him. CART and Leo Breiman 1974–1997 NF: Let’s bring the bac kground murm urs ab out recursiv e partitio ning to th e foreground and talk ab out C AR T. Ho w did this celebrated collab oration come ab out? JF: After Larry and I w r ote the t w o pap ers usin g minimal sp anning trees, we started working on the CAR T idea. Ric hard Olsh en was at UC San Diego at this time (mid-1970s) and he made trip s ev ery once in a while back to Stanford, and he would come out a nd visit me at SLA C. Sometimes I wo uld tell him ab out the more recent w ork on tr ees. He’d done some nice theoretica l work with Lou Gordon (Louis I. Gordon), a former Stanford p rofessor who was w orking in industry at that time. I told h im ho w w e w ere extending decision trees and he said, “It soun ds a lot like what Leo Breiman and Chuc k Stone are doing down in LA.” He tr ied to explain to me what they were doing and I didn ’t q u ite get it; and ap- paren tly he was try in g to explain to them what w e doing and they didn’t quite und erstand eit her. Fi- nally , Ch uc k called me and w e had a long discussion. W e’d b een working totally ind ep end ently , b ut there w as a huge amoun t of commonalit y in what we w ere doing. So I guess it w as Leo w ho finally suggested that we hav e a meeting down in southern California. They w ere b oth consultants for a company called T ec hnology Service Corp oration that was op erat- ing on go ve rn m en t con tracts, m ostly en vironmenta l things I think. Leo was basically a full-time consul- tan t there and Ch uck w as also a consultant. I n fact, some of the tec h nical rep orts th at they wrote then are the classic articles on trees. So, Larry and I and Ch uck and Leo, we wen t do wn there (Ric hard wasn’t there) and h ad a meeting at TSC . W e talk ed ab out ho w v ery exciting it w as and that there was a lot of commonalit y in our resp ectiv e appr oac hes. There w ere some differences, and we discus s ed w h ic h ones seemed b est. Then Leo said, “Hey , I think we ought to wr ite a monograph.” W e w ould nev er get some- thing lik e this publish ed in a statistics jour nal (of the da y). So we set off to write it, and that’s ho w the monograph w as b orn (Breiman et al. ( 1984 )). NF: As I recall, there was other w ork on r ecursiv e partitioning going on ab out this time. JF: W ell, it’s one of those ideas that’s con tin ually re-in v en ted. Everyb o dy who re-in v ent s it thinks this is their “Nobel Prize” moment. T here wa s the w ork of Mo rgan and Sonquist ( 19 63 ), in the early 1960s at the Un iversit y of Mic higan S o cial Science Cen- ter; they did trees. Then there wa s Ross Quin lan ( 1986 ) who w as doing what he call ed the Iterativ e Dic hotomiser 3 (ID3) algorithm, a crud e tree pro- gram, at ab out the same time. Later he did C4.5, whic h tur ned out to b e v ery similar to CAR T, al- though there are a few differences. W e tak e prid e in the fact that CAR T came ten y ears earlier than C4.5, but it w as Quinlan and the mac hine lea rners who p opularized trees. W e did CAR T and it just sat there: statistici ans said, “What’s this for? What d o y ou do with it?” NF: And y ou’d also implemen ted the soft ware and made it a v ailable. JF: Y es, we ’d made it av ailable. Th en we got the idea of tryin g to sell it and that’s h ow our little compan y got started. 12 N. I. FISH ER NF: First, let’s talk ab out your long collab oration with Leo. This wa s the b eginning. JF: Righ t, it started with C AR T b ecause we were trying to w rite the soft ware. I had written the in itial soft w are, but Leo had a lot of go o d ideas ab out wh at should b e in it and how it sh ould b e structured, the user int erface etc., and so w e were collaborating on that. In the meantime, Leo left UCLA and b ecame a full-time consultan t. NF: He wa s a pr obabilist at one stage. JF: He was a pr obabilist, he used to sa y pr ob ob o- bilist . Then he came bac k to academia in 1980 and joined the Statistics Departmen t at Berk eley and, at the same time, Chuc k came u p to Berk eley . NF: W ould y ou sa y Leo wa s an unusual app oint- men t at Berke ley for that time? JF: Y es. He h ad solid mathematical credential s. He w as lik e T ukey in this sense: he could do this sup er empirical stu ff bu t he wa s also v ery strong in math, so they couldn’t say th at he w as doing metho dology b ecause he couldn’t do math. I h a v e no id ea w h y th ey hired him , bu t m y guess w ould b e they w an ted to start getting in to the computer age and they br ough t him in. He b ough t their firs t computer, a V A X, installed it, and d id its care and feeding for a long time, so it was an incredibly wise app ointmen t from that p ersp ectiv e, as w ell as many others. NF: Ho w did the collab oration go? JF: W e’d s tarted the collab oration with CAR T, w e’d decided to wr ite the b o ok, and w e’d parceled it up into d ifferen t parts. Th en Leo says, “If we write this program called CAR T and d ecide to sell it and we sell a thousand copies at a h undr ed d ol- lars eac h, y ou kno w ho w m uch money th at is?” So w e decided, ok a y , w e w ould form a compan y , Cal- ifornia Statistical Soft wa re, and try to sell CAR T. So w e had to ha ve a pro duct. Leo w as at Berkele y at that time, so we started a p attern that p ersisted for roughly the n ext ten ye ars. Ev ery Thursda y I w ould go up to Berk eley . I would leav e h ere around 10 am, get up there aroun d 11 and park on Hearst Av en ue. Leo w ould blo ck out the whole day; n ob o dy else w ould come to see him f or that da y . W e would go to his office and start w orking. Around no on he’d sa y , “Jerry let’s go hav e lunch,” So we’d go ov er to the same place ev ery time, a crˆ ep e place o v er on Hearst Aven ue. W e’d ha v e usually the s ame spinac h cr ˆ ep e with sour cream, and an espresso. Then w e’d go bac k to h is office and w ork, punctuated with me runn in g out to feed the p arking meter on Hearst. It w as all con v ersational; w e weren’t sitting there writing or typing in to a computer, w e were just dis- cussing the whole time. Typically , around 5.30 or when the progress seemed to b e slo w ing, Leo would sa y , “Jerry let’s go ha v e a b eer,” so w e’d go do w n to Sp ats , whic h is a p ub on S hattuc k Av en ue. After w e’d had a few b eers Leo would say , “Jerry let’s go to dinner,” so we’d go to on e of Berk eley’s b etter restauran ts and ha v e a n ice meal. Then Leo w ould go home and I’d drive b ac k d o wn to P alo Alto. That w as the routine ev ery Thursda y for a v ery long time. NF: What wa s his appr oac h to problems? JF: He w as lik e T ukey: “Don’t tell me the moti- v ation, tell me what y ou do to the data.” He was totally algorithmic. There was no obvio us s ort of fundamental principle lik e: This is a Bayesian pr o- c e dur e with a p articular prior . It w as nev er that kind of thinking, s tarting from an y kind of guiding pr in- ciple; it w as just what it made s en se to do with the data. NF: W ould yo u categorize this as the computer science wa y of tac kling data rather than the statis- tical w a y. . . ? JF: I wo uld h av e then. NF: . . . in the sense that what yo u are d oing is lo oking at a sp ecific data set and y ou d on’t kno w whether wh at y ou’ve done is going to w ork on an y other data set? JF: W el l, w e generally w eren’t working on sp e- cific data sets, w e were trying to dev elop metho d- ology f or classes of problems. I t was lik e d ev eloping CAR T: CAR T could b e used on a wide v ariet y of data sets, s o could A CE (Alternating Cond itional Exp ectation) (B reiman and F riedman ( 1985 )), so could Curds and Whey (Breiman an d F riedman , 1997 ). W e were thinking metho dologically . In other w ords: Pr oblem. I’ve got data, ther e’ s an outc ome, ther e ar e pr e dictor variables, the data is of a c e r- tain kind. Now how do we make a pr o c e dur e tha t c an hand le this pr oblem? I don’t think w e ever ac- tually analyzed a sp ecific data s et tog ether, except for examples that we u sed in pap ers to illustrate the metho dology . Analyzing a data set where the inter- est was not in ho w w ell th e met ho d did bu t in th e answ er that y ou got from the data set, w e b oth did a lot of that as we ll. NF: What motiv ated ACE? JF: The idea w as to simultaneously find optimal transforms. There we re all these heur istics and rules for transform in g data in the linear regression p rob- lem: do y ou tak e logs, or do you tak e other kinds A CONVERSA TION WITH JERR Y FRI ED MAN 13 of trans f ormations? In fact, I think Bo x–Co x was a sort of automated method f or trying to find transfor- mations from a parametric family o f fu nctions. W e w ere in v olv ed with s m o others, s o we thought ab out ho w w e could automatically fi n d goo d tr an s forma- tions without ha ving to restrict them to b e fr om a parametric class of functions, just s ee if y ou could estimate an optimal set of transf orm ations. NF: “Optimal” in what sens e? JF: Optimal in the squared error sense. . . of course under a smo othness constraint, otherwise there we re an infin ite num b er of transform ations that w ould fit the data p erfectly . So you h ad to pu t in a smo oth- ness constraint, w hic h we did e xplicitly by us in g smo others in the h eart of the algorithm. I remember one of the Th urs da ys when I w en t up to Berk eley , Leo ask ed m e, “If I ha ve t wo v ariables, ho w d o I find the function of one of them that’s maximally corre- lated with the other one?” I said, “W ell, if you do a smo oth, you tak e the conditional exp ectation of one of them giv en the other one, ok ay?” That do esn’t necessarily m aximize the co rrelation, so we started thinking: Okay, what if we did it one way and then, given that curve, smo oth that against the other one? Later we wen t bac k to Leo’s house w here he h ad an Apple 2. He programmed it in Basic, ju st the simple biv ariate algorithm. He sim ulated data from a mo d el where the op timal trans formation in b oth cases wa s the square r o ot. The Ap ple 2 was n ot a v ery fast mac h ine, so w e could w atc h it iterate in r eal time, displa ying the current transformations at eac h step. Starting from linear straigh t lines, w e sa w the trans- formations b egin to b ecome m ore and more curved with eac h iteration un til they con v erged. It w as an exciting momen t for u s. So we develo p ed that id ea and then Leo got v ery excited ab ou t the theory . He neve r to ok theory very seriously b ut he lo v ed to do it, so he lo oked at the asymptotic consistencies and things like that, and w e had a great time. In the early 1990 s I we nt on sabb atical for a y ear and we d idn’t collaborate t hen, bu t it pick ed u p again in the mid-1990s. Leo called me one da y and just said, “Jerry , I’d lik e to wo rk with y ou again,” and we didn’t ev en ha v e a specific pro ject to wo rk on. I w en t u p to Berk eley and we kic ked aroun d what we could w ork on. I said, “W ell, one prob- lem I’ve b een c h urn ing in m y head but hav en’t got- ten very far on is m ultiv ariate regression, where you ha v e m ultiple resp onses.” S o we started kic kin g that around and that led to the Cu rds and Whey p ap er, whic h w as a Discussion pap er at the Ro yal Statisti- cal So ciet y . This collab oration wasn’t q u ite in the same mo de as b efore. I wo uldn ’t go u p to Berk eley nearly as m uc h b ecause inf rastructure h ad d ev elop ed so that it was p ossible to wo rk apart pro ductive ly and so we basically did it through e-mail. Th e idea wa s mo- tiv ated b y my familiarit y with PLS (P artial Least Squares). PLS had a mo d e wh ere it had m ultiple outcome v ariables as well as multi ple predictor v ari- ables. T he one-outcome-v ariable case was just a sp e- cial case. In the work that I had done with Ildik o [F rank] to try and un derstand PLS (see b elo w), we only treated the single outcome case. I w ant ed to try to und er s tand the m u ltiple outcome pro cedu re to see if one could find a m ore statistically justifiable approac h. So Leo and I work ed on that together and that w as great fun . In this pap er we rev ersed r oles. Ge nerally , in our collaborations I concen trated on the m etho dological part and the computing. Leo w ould usually do the theory . In th is p ap er ou r r oles were reve rsed: Leo wrote the program, Leo had the data, and I w orke d out the theory . NF: Wh y Cur d s and Whey? JF: I’ll r etell the story I told in th e m emorial ar- ticle I w r ote ab out Leo. I came up w ith the name A CE. I lik ed it a lot bu t Leo hated it, absolutely hated it. This w as one of the afterno ons after we finished and w e’d gone d o w n to Splats for a b eer and w e were still discus sing this. Leo didn ’t lik e it and I like d it, so we w ere going bac k and forth. And then out of nowhere Leo said, “Ok a y J erry yo u’ve got it, it’s A CE.” It wa s most unusual for Leo to yield so easily . He usu ally stu ck to his gun s and so did I. I lo oke d at him in a p u zzled w ay , lik e, That was to o e asy , and he said, “Lo ok across th e street,” so I lo oked across the s tr eet and there w as a hard ware store with this b ig red sign, A c e . When we ga v e the in vited JASA pap er in 1987, Leo brough t a bunc h of bags fr om Ace Hardware that had a big ace on them and distributed them around to th e audience. Later on wh en we did the m u ltiple resp onse multi- v ariate regression wo rk, we h ad another argument ab out ho w to n ame that pro cedure. Leo prop osed Curds and Whey , wh ic h I really didn ’t lik e, but I felt that since he had conceded on A CE I w ould concede on that. It w as Leo’s thinking ab out the fact th at w e w ere separating a signal from the noise, the goo d stuff f r om the bad stu ff, separating the curds fr om 14 N. I. FISH ER the whey or the other wa y around, I guess, in cheese man ufacturing. That collab oration wa s a couple of ye ars, ma yb e three y ears. I think to some exten t our inte rests sep- arated at that time. T h ey tended to b e concerned with very similar pr oblems. He d id the nonnegativ e garrotte an d then got into bagging and I w as getting in to bo osting at that time w orkin g w ith Rob [Tib- shirani] and T rev or [Hastie]. Both approac hes w ere based on ens em bles of trees, b ut f rom d ifferen t p er- sp ectiv es. I knew what he w as doing, bu t w e didn ’t ha v e constant interac tion and in v olv emen t. When w e got together we alwa ys had a goo d time. NF: T alking ab out Leo has had us leaping thr ough the decades. Let’s r eturn to the p erio d w hen y ou w ere still full time at S L A C. Had y ou met an y b o dy from the Statistics Departmen t at this stage? JF: No, not at this stage. I didn’t start in teracting with the Statistics Department u n til th e late 1970s. 4. THE MO VE T O ST ANFORD UNIVERSITY JF: I was h anging out arou n d the department for seminars, but I had no official p osition. So Brad [Efron] ask ed me to teac h a course. NF: Did y ou thin k you w ere doing statistics? JF: W ell y es, I kn ew th e s tu ff with Rafsky wa s statistics, it w as hyp othesis testing. That’s wh at I taugh t in the course. It’s probably as close as I’v e come to classical statistics. The minimal spanning tree wa s not classical statistics bu t the rest of it w as. That brough t m e closer to the department . While I was at SLA C I wasn’t on the f aculty there. I w as just a staff mem b er, which mean t I could n ’t wr ite prop osals and submit them to NSF or other a gen- cies, Departmen t of Energy , or others who might sp onsor m y kind of w ork. SLA C wa s sp onsoring it an d that was wonderful, but sometimes I really could ha ve used a little more money to do things. S o I wan ted to w r ite p r op osals and for that I needed to b e some kind of pr ofessor. P aul Sw itzer w as Chair of the departmen t at that time, so I w en t to him and said, “Is there an y w a y y ou c ould mak e me something lik e a consulting p rofessor of th e Depart- men t, some official thing? This will allo w m e to w rite gran ts and rep orts on b ehalf of Stanford Unive rsity .” He said, “Ok ay , we’ll try it.” So all the pap er w ork w as gotte n together and su b mitted to the admin- istration, letters a nd ev erything. It came bac k and P aul said, “Sorry we can’t do it. W e’re not making an y more consulting professors; th ere is some p oliti- cal thing going on that has nothing to do with y our case, but they are not d oing consulting professors. Ho wev er, they did sa y that yo ur folder looked pretty strong, so why not try for a regular professor?” An d so P aul d id and it w orke d. P aul p robably did the lion’s share of the work on it b ecause he was Chair. That’s ho w I b ecame a p rofessor. NF: As w ell as having a job at SLA C? JF: I b ecame a half-time professor and half-time at SLA C instead of fu ll time. NF: So this was effectiv ely y our formal entry in to the statistics comm unity . Did yo u find y ou r self wel- comed? Here’s mainstr eam statistics fl owing along and th is guy sur fs in on a wa v e f rom a merging stream with n o statistics bac kground wh atso ev er, but with lots of skills and differen t id eas ab out ho w to approac h data. W as th is a great issue for yo u? JF: Y es in general, but certainly not at Stanford b ecause they h ir ed me. I alwa ys felt v ery welc ome in the Departmen t. But I don’t think the more gen- eral statisti cs comm un it y und ersto o d what moti- v ated me. I recall once Colin Mallo w s listenin g to one of m y talks, and he said afterw ards, “Bo y this is really fascinating, but it’s not statistics,” and I think that was the general feeling, that wh at I w as d oing w as p erhaps interesting but not statistics. Where’s the math? Wh er e are the usual trappings of r esearc h in statistics? It really wasn’t that sort of stuff, w ith the p ossible exception of the minimal spanning tree w ork. So in that sense, I don’t think there ev er was an y hostilit y of any kind , jus t that p eople were puz- zled: ho w was w hat I w as doing related to statistic s? NF: And yet what y ou were r eally doing was w hat y ou d escrib ed earlier: yo u and John T ukey thinking the same w a y , y ou’d ha v e an idea ab out h o w to at- tac k something and y ou’d see ho w it wo rke d on the data. Y our wo rk wa sn’t b eing informed by fund a- men tal principles. . . or was it? JF: I think that had more of an influence on me man y years later, and John th ou ght I’d sold out. He really thought I w as trying to think ab out fund a- men tal principles, whereas I was dev eloping things and using elegance of the algo rithm as a criterion. John had a real distaste for that. NF: Do y ou feel that y ou had dev elop ed some sort of a canonical wa y of tac kling the sorts of prob lems that y ou app roac h ed? JF: Probably , but I can’t think of it righ t n o w. I op erate in the mo del of a problem s olv er: here’s a problem, I ha ve a certain set of to ols and skills that A CONVERSA TION WITH JERR Y FRI ED MAN 15 I use, and so that directs ev erything. Probably there is a great deal of commonalit y s im p ly b ecause m y skill set is limited, but I d on’t think I consciously think that wa y . NF: Supp ose a y oun g p erson ca me to w ork with y ou and you treated that p erson the same w a y as John T u k ey used to treat y ou: y ou do this, y ou d o this. If y ou got p ushed wo uld y ou mak e up a prin- ciple or w ould y ou actually b e able to find a prin- ciple? Y ou suggested earlier that ma yb e J ohn made the principle up to shut you up. JF: A h euristic principle p er h aps, I d on’t thin k I could come up with a deep theoretical p rinciple, or ma yb e I could if I thou ght ab out it. NF: Joining the department pu t you in to con tact with mainstream s tatistics and statisticians and y ou started going to more stats conferences? Ho w was b eing in that departmen t c hanging what w as hap- p ening? JF: W ell, I started b ecoming more conscious of statistica l principles. I don’t th in k it changed the w a y I approac h ed problems a lot. I recall a statemen t of John Rice’s when he wa s ask ed whether he w as a Ba y esian or a frequentist and he said, “I’m an opp ortun ist.” And that’s how I view it: Her e’s a pr oblem. How do we solve it? I will try to attac k the problem from an y d irection I’m capable of. NF: Y ou were also coming into con tact with a re- mark able group of statisticians in the d epartmen t, who w ere doing extraordinary things. JF: I think sub consciously that really shap ed m y thinking a lot. That’s ma yb e why T uke y thought in later y ears I w as selling out. I did thin k ab out principles; I thin k they w ere in the back of m y mind, informal principles that I did n’t apply formally . NF: Did John ev er visit yo u once y ou had mov ed in to that department? JF: Y es, oh y es, at least a few times. I do r emem- b er one time we w ere driving along Campus D rive and I said, “Y ou kno w, J oh n , no w I ’m in a statis- tics d epartmen t and officially in statistics, maybe I should r eally go and learn basic statistics, theo- retical statistics, all the usu al stuff.” John lo oked at me an d wen t: ( r aspb erry sound ). Wheneve r yo u said an ything to John, present ed an idea or what- ev er, John didn’t tend to la vish praise, that wasn’t his s tyle. S o if he sat still and listened to y ou quietly , y ou knew he really liked it. If he had doub ts ab out it, he w ouldn ’t s a y anyt hing, b ut y ou’d see his head going slowly bac k and forth; and if h e really didn’t lik e it, he’d inte rru pt y ou by giving a thum b s do wn and blowing a r asp b erry . S o that’s what I got when I ask ed h im whether I sh ould learn statistics. I’m n ot sure he w as exactl y right and ov er the course of the y ears I d id learn some traditional statistics with the help of m y fr iends, colleagues and stud en ts, wh ic h I think help ed me a lot. The Orion Project NF: Y ou d ev elop ed more strong collab orativ e w ork at Stanford. What was the fi rst one? JF: Ar ound 1981, the d epartmen t had an op en ing for an assistan t professor and I think W erner [Stuet- zle] h ad just got his degree. I said, “I kno w this re- ally smart guy that I m et at ETH. I thin k I can pull it off so w e pa y him half time with m y group, do y ou w an t to hire him?” Th ey thought ab out it and, to cut a long story short, they said, “Sure.” I con vinced my b osses at SLA C that we could d o it, so we hired W erner half time at Stanford and I had W erner half time in my group at SLAC. I started m y collab oration with W erner , whic h was v ery prof- itable in tellectually and great fun o ver the y ears. NF: What sort of things were you doing? JF: W ell, we started a graphics pr o ject. W erner had w orke d with Pe ter Hub er on graphical te c h- niques, as P eter w as very inte rested in that. So we got some money from the O ffice of Na v al Resea rch and started to put together a graphics w orkstation. W e felt: it’s b een ten y ears since PRIM 9, the tec h- nology has adv anced dramatically , let’s see what w e can do no w. So w e joint ly w orked on that; we called it the Orion Pro ject and it was great fun. (See the anec- dote The Orion Pr oje ct—building a se c ond Gr aphics Workstation in Fisher ( 2015 ).) Sea rching for Pattern NF: Y our full-time w ork with SLAC h ad b een a v ery exciting p erio d of y our life. No w y ou had mo ved across to the d epartmen t of statistics, ho w long did the in teractions w ith SLA C con tinue? JF: Th ey tap ered off a little bit b ecause I w as only half time there and r u nning the group w as ab out a quarter-time exercise, so I had less time to work on SLA C types of things. But it was still v ery v aluable to b e in that group . I still had access to a lot of resources that I w ouldn’t ha v e had otherwise. NF: Ho w did this c h ange yo ur sour ces of insp ira- tion for things to wo rk on? JF: I was alw a y s in terested in what Leo called large and complex data sets (no w called “data min - ing”): data th at was collected n ot n ecessarily for the 16 N. I. FISH ER purp ose for which you are using it; it h as mixtur es of all kinds of v ariables; the exp erimen t wasn’t de- signed; it w as usu ally observ ational data. I guess it’s a kind of data that I fir st encountered in ph ysics, mo derately high-dimensional, a fair amount of data, the num b er of observ ations usually considerably larger than the num b er of measur ed v ariables. I was alw a ys interested in deve loping general-purp ose al- gorithms where one could p our the data in and hop e to get something sensible out without a lot of lab or- in tensiv e w ork on the part of the data analyst. NF: Jerry’s searc h for pattern? JF: Y es, I guess a generalized p attern search of data, usually fo cused on pr ediction problems. NF: Lo oking forward from your arriv al at SLAC, first there was Pro jection Pursuit wh er e you w ere lo oking for groups in high-d imensional data. . . ? JF: I think I w as asso ciated with four Pro jection Pursuit pap ers. One was the original T ukey pap er (F riedman and T uke y ( 1974 )), then there w as a re- gression p ap er with W erner Stuetzle (F riedman and Stuetzle ( 1981 )), then I wrote another follo w-up pa- p er (F r iedm an ( 1987 )) in the original T ukey styl e, and one with W ern er on dens ity estimation (F ried- man, Stuetzle and Sc hro eder ( 1984 )). In the mid-1970s I b egan work on trees whic h car- ried through to CAR T. Th en I we nt bac k to trees later in th e 1990s when the v arious ensemble meth- o ds we re coming out. Ens em bles of trees seemed esp ecially a pp r opriate for these kinds of learning mac h ines b ecause trees ha v e a lot of very desirable prop erties for data minin g. T rees just hav e one p rob- lem: they are not alw a ys very accurate. So the en - sem bles of trees cured the accuracy problem while main taining all of th e p revious adv antage s; they are v ery robust, they can deal with all kinds of data, missing data, and th at’s th e kin d of thing I w as in terested in: off-the-shelf learning algo rithms. Y ou could nev er do as w ell as a careful statisti cian or a careful scien tist analyzing the data v ery painstak- ingly , b ut it could giv e y ou go o d first answe rs, that w as the idea. That’s b asically what drov e me. Researc h inte rests are a rand om walk. Y ou get an idea and y ou pursue for a w hile. I t may b e similar to what y ou were w orking on b efore or it may b e in an en tirely new d irection. Y ou work on it for a while unt il y ou get stuck or find something more interest- ing. I tend to ha v e these problems that I would lik e to solv e and can’t solv e immediately . I pu t them in the bac k of m y mind and then when I’m reading or hearing talks or every once in a while someone sa y s something th at ma y ha v e nothing to do with wh at’s in the bac k of m y mind, it will tr igger something: Ah ha! Ther e’s an ide a tha t I c an try for this pr oblem . So I go bac k and work h ard for a w hile; eit her I push it a little bit fur ther or I don’t b ut it’s still there. I’v e got this resid u al set of problems that I hop e to solv e some da y; sometimes I do get them solv ed. NF: Y ou’d wo rked on CAR T with several p eople, Pro jection Pursuit with Joh n T uk ey a nd W erner Stuetzle, and A CE w ith L eo. T hen what? JF: O th er stuff w ith W erner, Sup erSmo other (F riedman, 1984 ) and a pap er on splines (F riedman, Grosse and Stuetzle ( 1983 )). Then MARS (Mul- tiv ariate Adaptiv e Regression Splines) came after A CE. It started in the late 198 0s. I wa nted a tec h- nique th at wo uld ha ve the prop erties of CAR T ex- cept that it would mak e a contin uous appr o xima- tion. On e of the Achilles’ heels of tr ees is that they mak e a d iscon tin uous, p iecewise constan t approxi- mation and that limits their accuracy . Also, I’d read de Boor’s little primer on splines (de Bo or ( 2001 )) whic h W erner sho w ed to me. I’d lea rnt m ost of w hat I knew ab out s mo othing from W erner . Smo othing w as an imp ortan t tool and I b eliev e h is thesis w ork had a lot ab out smo othing. After that I knew some- thing ab out splines, so I pieced together the idea. Y ou can think of CAR T as recursivel y making a spline approximati on but with a zero-order spline whic h is piecewise constan t, so I tried extend ing that so I could use a fi rst-order splin e whic h w as a con tin- uous app ro ximation, discon tin uous deriv ativ es but a con tinuous appr o ximation, and then y ou can gen- eralize th e approac h to higher ord ers (although in the implemen tation I didn’t). NF: As I recall, th is en d ed up b eing a v ery large pap er. JF: Y es, the MARS pap er w as 60 p ages of descrip- tion and then there was another 80 pages of d iscus- sion, so it ended up as a 140-page pap er (F riedm an ( 1991 )). Apart from MARS, I also devel op ed a tec hnique I called Regularized Discriminan t Analysis (RDA; F riedman ( 1989a )). Some of m y work w as inspired b y work that was going on in chemomet rics. There w as a tec h nique they called SIMCA, which w as basi- cally a strange kind of quadratic discriminant anal- ysis, view ed f rom a statistical p ersp ectiv e. It’s an acron ym for Soft Ind ep endent Mo delling of Class Analogies (W old and S jostrom ( 1977 )). Th at was used a fair amoun t for classificat ion problems in c h emometrics. A CONVERSA TION WITH JERR Y FRI ED MAN 17 NF: I recal l a meeting in volving some c hemome- tricians where y ou and Ildiko presented a pap er on y our views ab out PLS, wh ere y ou s ho w ed that it had some signifi can t deficiencies. Ha ve your views on this s u b ject eve r b een accepted by th e chemo- metrics p eople? JF: I d on’t thin k so, n o. I wen t to a chemomet- rics conference tw o or three y ears ago and everything w as still PLS after 20 yea rs. In the mac hin e learning literature everything is a mac hine, ev ery algorithm is called a mac hine. Before th at, ev ery algorithm was called a netw ork in Neural Nets. In c hemometrics ev- erything is called s ome kin d of PLS . Y ou remin ded me: Ildiko and I wrote a p ap er try in g to explain PLS from a statistica l p ersp ectiv e (F rank and F riedman ( 1993 )). Also, wh en b o osting came out muc h lat er, Rob and T rev or and I tried to sh o w what it w as do- ing, again fr om a statistical p ersp ectiv e. W e did PLS and it turns out it’s v ery close to ridge regression. I don’t think the PLS p eople appreciated it at all. PLS definitely has limitations. One th ing is that if th e v ariables are all uncorrelated, then it do esn ’t regularize at a ll. A t least ridge regression, whic h is v ery s im ilar, still regularizes in that kind of situa- tion. So it dep ends u p on the predictor v ariables b e- ing highly correlated to imp ose this regularization, whereas ridge regression, whic h giv es pretty muc h the same result for highly correlated v ariables, also regularizes in the absence of a h igh d egree of corre- lation. NF: And RD A? JF: RDA related to this SIMCA thing. It w as a v ery sim p le idea a b out linear discrimin an t analysis and quadratic discriminant analysis. Y ou consider an algorithm that is a mixture of th e t w o. Th en in the second part, when you do th e quadratic discrimi- nan t analysis, you regularize the co v ariance m atrices in a ridge st yle so there are t wo regularizat ion pa- rameters for the t w o co v ariance matrices, eac h b e- ing estimated separately . Eac h of the separate co- v ariance estimates is b lended w ith th e common co- v ariance, their a v erage, with degree of b lending b e- ing another parameter of the pro cedur e. I lik ed that idea. W e wrote th e pap er ab out PLS when I w as on m y sabbatical in 1992. Th e sabb atical was br ok en up into small pieces, part of whic h wa s in Australia. That’s w hen you and I started w orking on m ulti- v ariate geo c hemical data. NF: Y es, th at led us to PRIM. W ould y ou lik e to sa y a little b it ab out PRIM (Pa tien t Ru le Ind u ction Metho d)? JF: Th e idea ther e was hot-sp ot analysis. Data mining was coming in and one of the th ings that p eo- ple wa nte d to do was lo ok for needles in haysta c ks, hot-sp ots in data, f or example, in fraud detection. Y ou exp ect a fairly w eak signal, bu t what y ou h op e for is that it’s iden tified by a v ery sharp structure in at least a few of the v ariables. PRIM (F riedman and Fisher ( 1999 )) w as a recursiv e partitioning scheme but different from C AR T whic h w as very greedy and aggressiv e. That’s wh ere the “P atien t” comes in: it w as mean t to fin d a go o d sp lit b ut only split a little bit and b e patien t and then lo ok for another split, that w as the idea. NF: There was an earlier bias-v ariance pap er in the 1990 s. JF: Y es. There was kind of a cottag e indus- try in the mid-1990s; every one wa s a wa re of the bias-v ariance decomp osition of pr ediction error for squared error loss regression and it in trigued p eople to try and dev elop something analogous for clas- sification. Here th e loss is either zero or one, and the go al w as a corresp ond ing decomp osition of the misclassification risk. There w er e numerous paper s on that. Leo wr ote one (Breiman ( 1996 )) and there w ere a lot in the mac hin e learnin g li terature. I got the impr ession that y ou really couldn’t find such a decomp osition, but what y ou co uld do was lo ok at traditional bias an d v ariance, which are w ell defi ned, and see h o w those t wo kinds of estimation errors, lik e b ias and v ariance in estimating the probabil- ities, reflected themselv es in misclassification risk. So I wrote this pap er (F riedman ( 1997 )) where ba- sically I sho we d that the curse of d imensionalit y af- fects classification muc h less severely than it do es regression. In regression, thin gs get exp onen tially bad as the dimensionalit y in creases, but not nec- essarily for man y t yp es of classificatio n. So that is wh y things like nearest neigh b or and k ern el meth- o ds, whic h d on’t work terr ib ly w ell in regression in high-dimensional settings, can p erform reasonably w ell with classification: the curs e of dimen s ionalit y do esn’t h urt them as m uc h. Th is is esp ecially so w ith o ver-smoothing the densit y estimate: it can b e very sev ere and can in tro d uce h u ge error in the density estimate, but need n ot introdu ce muc h error in clas- sification. I didn ’t kn ow where to publish that pap er, or indeed whether to publish it all. Th en a friend of mine, Usama F a yya d, co nta cted me. He was one of the early p eople in data mining and may even ha v e coined the term “Da ta Mining.” He w as starting a 18 N. I. FISH ER journal of data mining. He said, “I’d lik e a pap er from you in the first iss u e,” so I said ok a y . I had this one ju st sitting there, so I sent it off to him. It turned out—and I d idn’t know this u n til muc h later—that pap er was r ead by a data mining fello w in Israel, S aharon Rosset. He felt that this s ho w ed that statistics could con tribute to data mining. So he decided he wan ted to come to Stanford and study . He wa s one of the b est students w e’ve ev er had. I learned a lot f r om S aharon and still do. So I would sa y the biggest success of that pap er was th at w e got Saharon to come to our d epartmen t. NF: When w as it that you had the insight ab out high-dimensional data, that every p oin t is an outlier in its o wn direction? JF: That came from Pro jection Pur s uit. Some time in the late 1980s, early 1990 s, outlier detection w as a big issue for p eople. I had seen it in v arious pap ers and talks. I thought that it m igh t b e a n atu- ral application of p ro jection pu rsuit. Pro jection pu r- suit lo oks for directions in the space suc h that wh en y ou p ro ject the data it h as a particular ”in teresting” structure d efined b y a criterion that y ou then try to optimize. So I though t, OK, we’l l define a criterion that lo oks for outliers . I came up with a criterion, programmed it up, tried it out and it was wo rking b eautifully . It w as findin g all kinds of outliers and the nice thing ab out it is you see the pro jection. So in that pro jection here is the d ata, here is th e p oin t, there is no ot her inference to b e done; it’s an out- lier, there it is. I was v ery excited and after trying it on data, b oth simulate d and real, I though t, Wel l, we’ve got to c alibr ate this. How many outliers do es it find w hen ther e ar e none? I generated data from a multiv ariate normal distribu tion, tried the algo- rithm and it f ound this incr ed ible outlier. I though t, Okay, that c an happ en, it’s an ac cident , so I remo v ed that p oin t and searched aga in. It found another one, another pr o jection w ith a far outlying p oin t. I t ju s t k ept doing this. I could ju st p eel the d ata. I found this was ve ry curious a nd I men tioned it to p eople and I b eliev e it wa s Iain Johnstone who came up with th e explanation that every point is an outlier in its o w n pro jection. That was the p henomenon that I w as ju st disco vering empirically . NF: Y ou’v e mentio ned the term “data mining,” whic h came from a nons tatistical comm un ity . What w ere y our in teractions with these other comm un i- ties? JF: In the early 1990s I w as b ecoming aw are of the mac h ine learning field. I was invited to giv e a talk at a NIPS (Neuro Information Pro cessing Systems) conference some time in the ve ry early 1990s. That op ened up a different world for me b ecause there w ere all these p eople who were doing things with similar motiv ations but not with statistics, not in a statistica l mo d e. T hey we re almost en tirely alg orith- mically dr iv en. I felt that w as w ond erful, so I ga v e a talk there and I w en t back to those conferences throughout the 1990s. NF: Had they b een a wa re of any of your work? JF: W ell, they m ust ha v e b een a ware of some of it b ecause they invite d me to give a talk. I don’t kn o w ho w muc h my work w as referenced in their p ap ers, probably some. I t was in teresting the progression throughout the 19 90s when I we nt to those confer- ences. At the first one I a ttended there w as lo ts of discussion of hardw are and these were mostly elec- trical engineers. In fact, there were t wo group s : the engineers wh o used neural n ets and neural-net-t yp e ideas to solv e prediction problems; and the psyc hol- ogists who u sed them to try to un derstand the b rain and h o w adaptiv e net w orks can learn things, the ba- sic learnin g theory . F or the engineering p art it is in teresting ho w it ev olv ed f rom a concentrat ion on programs and h ardwa re to looking m ore and more lik e s tatistics. And no w it’s basically statistics. They disco v ered Ba yesian metho ds. I r emem b er in early discussions with mac hine le arning p eople I tried to explain why fitting a training d ata as closely as p os- sible do esn’t necessarily giv e you the b est future p re- diction, or what they call generalizatio n error. No w they und erstand that completely , b ut in those d a ys it was a little h ard for some of them to grasp the concept. T o b e fair, their interest was in very lo w noise problems like p attern recognition. Obvi ously there exists an algorithm that can tell a c hair fr om a table ev ery time, the brain can do it, so th e Ba y es error rate is zero on that. I t’s just that you can’t come up with an algorithm to ac hieve the Ba yes er- ror rate. Those w ere the kin d of problems they were in terested in. So in that case fitting th e training data as w ell as p ossible is the right s trategy . If the Ba yes error rate is zero, there’s no n oise. NF: Th ere we re a num b er of d istinct communi- ties. . . JF: Y es. T here we re three distinct fields, maybe more, that I kn ow ab out. There was statistic s, there w as artificial in telligence and then ther e wa s d ata base managemen t. NF: Where did the computer scientists fit in? A CONVERSA TION WITH JERR Y FRI ED MAN 19 JF: Compu ter scien tists were doing data base managemen t and artificial intell igence. Mac hine learning ev olv ed, at lea st as far as I kno w, out of AI. Data mining originally emerged out of the data base managemen t area. It’s all kind of a blend no w and ev ery one is learnin g more of w hat the other p eople are doing. Th e mac h ine learners and data m iners are learning more statistics and their researc h is looking more and more like statistics. Some statisticia ns are learning more ab out metho dology an d algorithms and their work is looking a lot m ore like mac hin e learning or data mining. Students NF: W e’v e talk ed ab out one or tw o studen ts y ou w ere in vo lv ed with b efore you joined the Depart- men t, bu t once y ou joined you had some form al re- sp onsib ilities to su p ervise these students. JF: Y es, I had a num b er of stud en ts and I enjoy ed them all in d ifferen t w a ys. One of the real adv antag es of b eing in an academic department is th at yo u get to b e around stud en ts with y oung fresh ideas and that eagerness that hasn’t b een stilted b y time. NF: What collab oration d id y ou h a v e with y our student s? JF: I certai nly collab orated on their thesis work. Probably th e student that I had the biggest and longest collab oration with was Bogdan P op escu, from Romania. NF: Y our style of doing things clearly influenced a lot of p eople who w ere around y ou at that time as student s. JF: I think so, y es. Esp ecially in my early d a ys in the Departmen t my w a y of thinking ab out things w as really v ery different; it’s not so m uch an y more. W e’v e got Rob and T rev or and Art [Owen], all of whom w ere students when I first came. Art w as ac- tually my student. Rob and T rev or w ere n ot offi- cially m y students, b ut they came up to SLAC a lot. NF: They got infected by wh at they sa w. JF: T rev or was W erner’s student, so he got in- fected strongly and so did Rob, I think: the more phenomenological w a y of thinking, less the theorem– pro of–theorem–pro of–theorem–pro of approac h. Not that I dev alue that approac h . I don’t w an t to giv e that impression, it ’s just d ifferen t. I’m not go o d at it. I don’t hav e the s k ill to do it. 5. ST ANFORD—THE NEW MILLENNIUM NF: So far at Stanford, we ’v e thr eaded our wa y through the 1990s and in to the fi rst decade of the new millenn ium and durin g th is p eriod y ou ha v e commenced another v ery significan t collab oration with some of y our S tanford collea gues. JF: Th at’s righ t. There w ere s ome very impres- siv e and in teresting devel opments in the mac hine learning fi eld in the late 1990s and also in statistics. One of them w as Leo’s bagging idea, wh ic h was a v ery simp le but clev er idea. T hen there were th e b o osting id eas that came out of the mac h ine learn- ing literature that w ere introdu ced b y F reun d and Shapire ( 1996 ). I started to b ecome fascinated by this b ecause it h ad a similar fl a v or to PLS in the sense that it app eared to work reasonably w ell but it wa sn’t clear wh y . Again, a cottag e indu stry dev el- op ed as to why . The mac hine learners had their o wn approac h us in g what they called the P AC Learning Theory (P A C stands for P robably Almost Correct), whic h was a w a y of lo oking at it wh ic h wa s very sat- isfying to them. It w as a goo d w a y to lo ok at it, but I thin k we didn’t qu ite u nderstand it. If it’s analyz- ing data, it’s doing wh at statistical algorithms do, therefore, there s hould b e some sort of sound sta- tistical b asis for it. So Rob, T rev or and I started a collaboration to try to figure out f rom a statistica l p oint of view why this thing w as working so well. It wa s int eresting in the sen se that w e didn’t h a ve the answ er when w e started the collab oration. Th is w as similar to working with Leo, where w e ju st p osed the problem. Q u ite often w hen yo u form a collaboration y ou ha v e an idea of the solution and y ou pu t it together, bu t w e had no idea why this thing w as w orking so well. So w e plo dded alo ng and got v arious insigh ts along the wa y and I b elieve w e figured it o ut (F riedm an , Hastie and Tibshir an i ( 2000 )), at least to our satisfaction. . . but not to ev- ery one’s satisfactio n: Leo n ev er though t our expla- nation w as the essen tial reason. He thought our for- mal dev elopmen t was correct, but he didn ’t think that was the reason that led to b o osting’s apparent sp ectacular p erf ormance. But I w as con vinced that w e h ad explained it. I think the m ac h ine learners, the P A C learning p eople nev er though t so, I don’t think they completely un d ersto o d the wa y we w ere lo oking at it. NF: And since then y ou’ve had an extremely pro- ductiv e collab oration w ith Rob and T rev or. JF: Y es. W e did that in the late 1990s, th en later in the mid-2000s I w as asked to b e an outside referee 20 N. I. FISH ER for a Ph.D. oral exam in the Netherlands. A stud en t of Jacq Meulman’s, Anita v ander Ko oij, was pre- sen ting her thesis and she had an idea. By this time the LASS O which Rob Tibsh irani had prop osed in the mid-1990s wa s really coming on strong; it still is. L 1 -regularized metho d s and the LASSO , in par- ticular, we re really becoming p opular. T here w as a cottag e indu stry on d ev eloping fast algorithms for doing it. Engineers had work ed on this, m achine learners had work ed on this, and there w as a sp ec- tacular p ap er b y Brad E f ron and some colleagues (Efron et al. ( 2004 )). So this was very activ e at the time. Then Anita and J acqueline had this really simple idea that a p rofessional on optimization w ould dis- miss out of hand, namely , just doing it one at a time. They w ere working on a computer pr ogram that in- v olv ed optimal transformations of the v ariables, and for this they w ere us in g the back-fitti ng algorithm. Including regularization then tur ned out to b e sim- ple. Lot s of p eople had develo p ed th e idea of opti- mizing one at a time. T h is is usually dismissed in optimization theory as not p erf orming well. . . whic h is correct un less the one-at-a-time solution can b e obtained v ery con ve niently and rapidly: then it can b ecome comp etitiv e. W erner and I had explored this with our so-calle d bac k-fitting algo rithm in pro jec- tion pursu it r egression and to fit add itiv e mo d els as w ell. Anyw ay , their idea wa s that you hold all of the co efficien ts fixed b ut one and then solv e f or the op- timal solution for that one. This can b e done v ery fast. Then y ou ju st cycle th rough them. They de- v elop ed it indep enden tly , but it was n ot a n ew idea: other people had d evelo p ed it b efore, b ut it didn ’t seem to ha ve b een tak en v ery seriously . So wh en I came b ack from th e Netherlands I told Rob and T rev or ab out this and they got excited and w e started working on applying the idea to a wide v ariet y of constrained and regularized problems and con tin ue to do so to this da y . Rob and T rev or and their studen ts hav e come up with all kinds of new regularization metho d s, ho w w e can do things one at a time and mak e it go v ery fast. W e applied it to the LASSO and to the Elastic Net, whic h w as something that T rev or and a student , Hui Zou, had done in the mid-2000s (Zou and Hastie ( 2005 )). It’s a cont inuum of regularizati on metho ds b et ween ridge regression and the LASSO. Y ou dial in ho w muc h v ariable se- lection y ou w an t. In ridge there’s no v ariable selec- tion, LAS SO do es m o derate v ariable selection, so w e extended it to the Elastic Net. Jacqueline and Anita had also extended it to the Elastic Net. Then w e extended it to other GLMs, logistic regression, binomial, Poisson, Co x prop ortional hazards mo del, and pu t together a whole p ac k age call ed glmnet that seems to b e w idely used no w. It allo ws yo u to d o all these differen t regularized regressions with the v ari- ous different GLM lik eliho o d s, and that work is still going. I like writing th e programs b ecause they seem to run f aster than other p eople’s. It is probably b e- cause of m y imp ov erished y outh when I w orked on computers that were nothin g lik e the computers now and y ou really had to wr ite efficien t p rograms. That skill seems to ha v e remained with me. NF: This collab oration w ith Rob and T revo r re- sulted in a particularly imp ortan t publication. JF: Y es, our bo ok (Hastie, Tibshirani and F ried- man ( 2001 )). Th at turned ou t to b e an u nbeliev able success and I help ed with parts of it, bu t it w as mostly written by Rob and T revo r. It just h it the righ t nic he at the righ t time and I guess it is still selling v ery we ll, but you can d o wnload a p df ver- sion from the W eb f or free no w. NF: Jus t to pic k u p on the p oin t yo u made ab out y ou doing the p rogramming, I remem b er y ou told me y ears ago th at y ou h ad n ’t solv ed the problem un - til yo u’d wr itten the co de to demonstrate the tec h - nique. JF: I d on’t ha ve th e requisite skills to do all th e theory . T he only wa y I can see if it’s a go o d idea is if I program it u p and try it o ut, test it in a wide v ariet y of situations and see ho w we ll it w orks. NF: Let’s pic k up some parallel activities that y ou’d b een engaged in, starting with MAR T. JF: A t the time of my second lengthy visit to Aus- tralia in 1998 /1999, I w as fascinated with the b o ost- ing idea. MAR T w as a kind of a spin-off fr om the w ork that I’d done with Rob and T revo r on trying to understand ho w b o osting wo rks. I got a few ideas for ho w to extend b o osting. Bo osting w as originally de- v elop ed as a b inary classification problem and while I was visiting CSIRO in Sydney I wan ted to extend it to regression and to other kinds of loss fun ctions, so I d ev elop ed this notion of gradien t b o osting wh ic h ev olv ed into what I called MAR T, Multiple Add itiv e Regression T rees. I wrote that pr ogram (also called MAR T) and devel op ed those ideas. That was m y Rietz Lecture I b eliev e, which w as p ublished in the Anna ls (F riedman ( 2001a )), an unusual pap er for them to publish . A CONVERSA TION WITH JERR Y FRI ED MAN 21 I still wan ted to un derstand more ab out wh y b o osting w as w orking. One of the ideas that I had dev elop ed with the gradien t b o osting was the idea— again a sort of a patience idea—that you can thin k of b o osting as jus t ordin ary step wise or stage- wise regression. Y ou fit a mo del, sa y , a tree (most p eople use trees), yo u tak e the residuals an d then y ou fit a mo del to the residuals. Y ou tak e the residuals from the sum of those t wo trees and build another mo d el based on those resid u als. No w that’s very greedy; ev- ery time y ou’re tr y in g to explain as muc h ab ou t the current residuals as y ou can with the next mo d el. I came up with an id ea (ag ain bac k to patie nt r ule induction!) that when one finds the tree that b est fits th e residu als, only add a little bit of that tree , in other wo rds, shrink its cont ribu tion. S o you m ul- tiply that tree by a small num b er lik e 0.1 or 0.01, b efore it’s added to th e mo del. That tur ned out to really impro ve the p erformance. S o I w an ted to un - derstand wh y it w as improving the p erf ormance and try to unders tand more ab out gradient b o osting. This w as the time when Bogdan P op escu w as m y student . He sho we d that the shrin k age only affected the v ariance and n ot the bias. I th ou ght this was a v ery imp ortant clue. Then, along with other p eo- ple, we f ound that what this w as doing w as a kin d of LAS S O. If you didn’t do the shr in k age, then y ou w ere doing something like stepwise or stage- wise regression. It pro d uced solutions that would b e v ery similar to the LAS SO and if y ou follo we d that strategy in a linear regression, it pro du ced solution paths very close to the LASSO . In the b eginning we though t they might b e identic al b ecause w e ran a few examples and they p ro du ced iden tical paths. It turns out that it w ill only pro duce iden tical paths in t w o dimensions or if the LASSO paths are monotone functions of the regularization parameter. Saharon Rosset did nice work in this area, as did others. Th ere w as part of an issue in the An- nals d ev oted to b o osting [ A nnals of Statistics 32 (1), 2004]. T here were sev eral v ery hea vywe igh t theoret- ical papers , very fine pap ers, showing that connec- tion, sh o w ing that b o osting wa s consisten t provided y ou regularized in th is wa y . NF: Jerry , you’v e h ad long-term enth u siasm for acron yms. What do ISL E and RuleFit stand for? JF: IS L E stands f or Imp ortance Sample Learning Ensem bles. Again, throughout this time I was in ter- ested in why the ensem ble learning approac h w as so effectiv e and ISLE was a differen t wa y of lo oking at ensem ble method s. Th e idea w as that y ou define a class of f unctions, and pic k fun ctions from that class. The first thing that o ccurred to me was that with b o osting and bagging and other ensem ble metho d s y ou just kept adding trees. There were some p eople who thought, Okay, if you have an ensemble, how do you figur e out what is the optimal way to weight e ach tr e e? I though t that w as a very simple prob- lem: if I w ant to h a v e a function that’s linear in a set of things, I know how to find the co efficien ts, that’s called r egression. A t this time, Leo w as doing random forests and a lot of p eople were doing b o ost- ing. I suggested that once y ou get the ensem ble, yo u just do a regularized regression to get the w eigh ts of eac h of the trees or whatev er th ey ma y b e. Each ele- men t of the ensemble in mac hin e learning literature is called a b ase learner, or a w eak learner, b ecause generally no one of them b y themselv es is very go o d, but the ensemble of them is v ery goo d. That was one of the things that we und ersto o d ab out why b o ost- ing wo rked. One of the reasons why b o osting was so sur prising was that in mac hine learning litera- ture they h ad a notion of wea k learners and strong learners: a w eak learner is one th at h as low learning capacit y and a s tr ong one has high. There w as a lot of impressiv e theoreti cal work by Rob Sc h apire, who w as one of the co-in v ento rs of the original successful b o osting algo rithm. He sho w ed that with this b o ost- ing tec hniqu e y ou could tak e a wea k learner and turn it in to a strong learner, as long as the weak learner could ac hiev e an error rate of ε ab ov e 50%. This w as v ery lo ve ly w ork. But when you d eal with it from this linear re- gression p ersp ectiv e it do esn’t seem so surpr isin g. W e’v e encounte red many pr oblems wh ere just on e v ariable alone can’t d o muc h, but a n umb er of v ari- ables fitted together in a regression can do v ery w ell. F rom my stat istical p ersp ectiv e that’s what’s hap- p ening. I thought you could do th is with a lot of differen t thin gs. If y ou h a v e a class of fun ctions, y ou pic k functions from this class and th en y ou do a lin- ear fit. Th en the question is: h o w do you pic k the functions fr om th e class? If y ou j u st rand omly p ic k them, nearly all of the fu nctions will hav e no ex- planatory p o wer as w ill their ensem ble. If y ou pic k them to all b e very strong, then their outpu ts are all highly correlated and y ou are not gaining an ything from the ensemble. The ensem ble will giv e the same predictions as an y on e of one of them. So y ou ha v e a trade-off that Leo had discus s ed a lot. Y ou d on’t w an t yo ur learners in the ensem- ble to b e highly corr elated in their p redictions, b ut 22 N. I. FISH ER Fig. 4. Steve Marr on pr esenting Jer ry with his awar d for delivering the Wald L e ctur es, Joint Statistic al Me etings 2009. Photo gr aph: T ati Howel l. y ou do wan t them to ha v e some predictiv e strength. That’s a trade-off. T his was w ell kno wn b efore the p ost-fitting idea. The LASS O and other regulariza- tion metho d s are natural for the p ost-fitting b ecause they could b e applied ev en w hen the size of the en- sem ble is m uch larger that the n umb er o f observ a- tions. So y ou needed fast algorithms for the LASSO and other r egularized regressions that w ere b eing dev elop ed around that time. It was a conv ergence of things. RuleFit w as a n ensem b le metho d totally moti- v ated by this concept. The main difference w as that instead of fitting an ensem ble with b o osted trees and then doing the p ost regression, you w ould take the trees, decomp ose them in to rules, forget the trees the rules came fr om, and use th em as a batc h of “v ariables” in a linear fit. Leo made a remark once, ma yb e in the mid -2000s shortly b efore his death, that the real challe nge in mac h ine learnin g is not b etter algorithms, grin d- ing out a tiny bit more predictiv e accuracy . O ur v ery b est learnin g mac hines tend to b e blac k-b ox mo dels—neur al n et works, s upp ort vect or mac hines, ensem bles of decision trees—and they ha ve v ery lit- tle if an y inte rpr etiv e v alue. They may p r edict v er y w ell, bu t there is n o w a y y ou can tell y our client wh y or ho w it is making a prediction, why it made that p rediction rather th an another one. He thought that the real c h allenge w as in terpretabilit y and he had p ut some interpretational to ols into his rand om forest, namely , the relativ e imp ortance of th e pre- dictor v ariables and some other things. I w an ted to see if there was some wa y to do in terpretabilit y and the id ea was that if you hav e an ensemble metho d , it’s b asically a linear mo del and linear mo dels are v ery in terpretable as long as you ca n inte rpr et the constituen ts, the actual terms in the mo del. T rees y ou can in terp ret, but I th ough t that it’s easie r to in terpret rules. A tree p ro duces a rule deriv ed fr om the path from the r o ot to a term in al no de: that’s wh y it’s so int erpr etable. It can tell y ou exac tly w hat v ariables are used to make the prediction and ho w it used them, which is wh y trees are so p opular. Rule- based learnin g has also b een a real staple in m ac h ine learning throughout its history . So I though t of br eaking up the tree in to its ru les, putting the ru les together in a big p ot and then do- ing a LASS O linear regression on the rules. The hop e w as that since the r u les aren’t ve ry complicated and A CONVERSA TION WITH JERR Y FRI ED MAN 23 are easy to in terpret, yo u could make muc h m ore in- terpretable mo dels. That in an d of itself w as only partially successful. But along the w ay I dev elop ed w ays for assessing the imp ortance of the v ariables for in dividual ensemble predictions. Another thing that I did in th at w ork w as to deve lop some tec hniqu es f or detecting inter- action effects, seeing w hat v ariables w ere in teract- ing, exploring in teraction patterns of the v ariables. So that w as Ru leFit. I h a ven’t done m uc h b ey ond that in develo ping general learning mac hines lik e MARS and MAR T, etc. RuleFit is m y last one so far. NF: I dare say there will b e more to come. Y ou’ve b een in the Stanford d epartmen t of statistics now for o v er thir ty y ears. Ho w h a ve y ou foun d it as an en vironment for a s tatistical scien tist? JF: Unb eliev ably great, I can’t th in k of a place I’d r ather b e. My greatest jo y is to ha v e an office in the hall with so man y bright and famous p eople. My nearest office neighbors are Brad Efron, Pe rcy Diaconis a nd Wing W ong, a long with all the other fan tastic p eople do w n the h all. It’s su c h a stimulat- ing en vironment . Ev eryo ne is so sharp, so smart, so in v ent iv e and original. Y ou take it for gran ted af- ter a while, but when you visit other places yo u find it’s n ot lik e that everywhere. I consid er it great go o d fortune that I w as able to join th at Departmen t and I thank them for accepting me, b ecause I w as a kind of an o dd app oin tment at the time. NF: I am s u re yo u look lik e a mainstream app oin t- men t righ t no w. Do y ou feel that the Departmen t has, to some exten t, p rogressed to wards y ou? JF: Ok a y , ma yb e a little b it, y es. 6. CURRENT INTERESTS NF: What are yo ur cur rent in terests? JF: Th ere’s th e wh ole regularization idea whic h I still think is fascinating. There are some left- o ver questions that current r esearc h has n ot y et an - sw ered. I’d lik e to thin k more ab out that area. An- other area is impro ving decision trees. T rees hav e emerged as b eing v ery imp ortant largely , in m y view, b ecause of the ensemble metho ds . T rees hav e v ery nice robu stness prop erties. They can b e built quic kly , they are in v ariant to monotone transforma- tions of the pred ictors, they are immune to outliers in the predictors, they hav e eleg ant wa ys of handling missing v alues and of incorp orating b oth n umeric and categorical v ariables. Th ey are a very nice type of learning mac hine: y ou just p our the d ata in, and y ou don’t hav e to massage the data to o muc h prior to that. They ha v e several Ac hilles’ heels, one of wh ic h wa s of course accuracy , b ut I think that’s b een solv ed by the ensemble metho ds, whic h carry ov er all these adv an tages while dramatically impro ving their ac- curacy: not ju s t b y 10% or 20 %, but sometimes by factors of 3 or 4. I thin k b o osting is one of the key ideas of mac hine learning. It has really adv anced b oth theory and pr actice. Another Ac hilles’ heel of trees is categorical v ari- ables with a v ery large num b er of leve ls. Bac k when w e w ere doing CAR T, a t ypical categ orical v ariable migh t ha ve 6 lev els. No w it’s routine to hav e hun- dreds or th ou s ands of lev els. That destro ys tr ees b ecause there is no order r elation. The num b er of p ossible splits grows exp onen tially with the num- b er of lev els. Optimizing o v er all these p ossibilities can lead to sev ere o ver-fitting. In situations wh ere there’s a su bstan tial amount of noise, this can lead to spu rious splits that mask the t ruly imp ortan t ones. So that’s left o ver and it is one of those things that I mentioned I keep in th e back of my mind and ev ery so often try to think ab out again, whic h is w hat I’m doing no w with this one. Another thing I ha ve b een th in king ab out r ecen tly is th e issue that many of th e p r oblems arising w ith data that is seen no w, esp ecially commercial d ata, tend to b e binary classification problems. In m y in- dustrial consu lting I see muc h more classification than regression. This is su r prising b ecause histor- ically most statistics researc h has cen tered around regression. Classification wa s something of a bac k issue in statistics. In mac hine learning, classificati on has alw a ys b een the main f o cus. In fact, they r efer to regression as classification w ith a con tinuous class lab el. A lot of th e data is highly unbalanced, y ou may ha v e millions of ob s erv ations but one class has ve ry few. In engineering and mac h in e learning th ey tend to lab el the class as +1 and − 1. Usu ally there is a v ery small fraction of p ositiv es, like in fraud de- tection, for example, where yo u h a ve a data b ase with a huge amoun t of d ata, bu t the n umb er of in - stances of fraud is a small fracti on of the data—at least y ou hop e that’s th e case! It’s certainly true in e- commerce, where the r ate of clic king an ad on a page is around 1% and then th e con version rate (whic h 24 N. I. FISH ER means you clic k the ad and then an d go buy some- thing) is tw o orders of magnitud e lo w er than that. So the issu e is ho w to d eal with data lik e that and there are rules of th umb that sa y if y ou h a ve, sa y , a hundred p ositiv e examples in a million negativ es, y ou don’t u se all the million, y ou randomly sample them. So then th e question is: What’s the str ate gy and how many do you ne e d? An d there’s another rule of thum b that sa ys if y ou hav e 5 times as many negativ es as p ositive s, that’s all y ou r eally need. I doubt that’s true in general, but I’d like to b e more precise abou t it b ecause it’s of h uge p ractical imp or- tance: if you hav e millions of observ ations w hic h y ou can randomly sample d o w n to a thousand or a few thousand, th at totally c hanges the dyn amic of ho w y ou do y our analysis. So that’s another thing I’m thinking ab ou t. T revo r Hastie and a student, Will Fithian, r ecen tly did some nice w ork (Fithian and Hastie ( 2013 )) in this area in the cont ext of logisti c regression. Another area of current interest is loss fun ctions. A machine learning p ro cedure is sp ecified by a loss function on the outcome and a r egularizatio n func- tion on the mo d el p arameters. Defining appropr iate regularization fun ctions and their corresp onding es- timators for different pr oblems is curr en tly a hot topic for researc h in machine learnin g and statis- tics. There is an a v alanc he of pap ers on the sub ject. There seems to b e less in terest in finding appropri- ate loss fu n ctions for different p roblems. The loss function L ( y , F ) sp ecifies the loss or cost w hen the true v alue is y and the mo del predicts F . I hav e found in my consu lting work that b eing able to cus- tomize th e loss fun ction for the problem at hand can often lead to big p erform ance gains. Most applica- tions simply use the defaults of squared-error loss for regression and Bernoulli log-lik eliho o d on the lo- gistic scale for classification. I’d like to in v estigate broader classes of loss functions app ropriate f or cer- tain kinds of s p ecialized pr oblems that go b ey on d the ones usually used in glms. I fi n d I sp end a lot of m y time on m y programs. I pu t most of my programs on the W eb an d p eople can do wnload them and use them, and they report bugs b ac k and I feel obligated to try to fix them. As y ou go along in y our career and you’v e done more and more things, you ha v e to sp end more and more of y our time b ac k-caring—feeding those things—as w ell as mo ving forwa rd . I’ve had a long career no w and sp en d a non-negligible amoun t of m y time just main taining past stuff. NF: It’s lik e entrop y , isn ’t it, alw a ys increasing. The list of errata nev er s h rinks. JF: Y es. Then p eople ha v e questions, they don’t understand things, or p eople use the algorithms in w a ys that you nev er dream t they migh t b e us ed. Something else I ’ve just thou ght ab out. In t he mid-1990s I work ed a lot on trying to in corp orate regularization with n oncon v ex p enalties. I sp ent a fair amoun t of time on a tec h nique wh ic h is some- what similar to the b o osting tec hniqu e but in the linear regression cont ext. Th e LASSO imp oses mod - erate sp arsit y as opp osed to an L 0 -p enalt y (all sub - sets regression) whic h in duces the sparsest solutions. So I d id a lot of w ork spanning the gap b et w een all subsets—whic h is v ery aggressiv e v ariable se- lection and wh ich often do esn’t w ork, esp ecially in lo w -signal settings—and the LASS O , whic h is mo d- erately aggressiv e in selecting th e v ariables. T hat in v olv es noncon vex p enalties. The LASSO is the sparsest ind u cing con v ex p enalt y . Of course with con v ex p enalties, as long as you h a ve a con v ex loss function, then y ou h av e a conv ex optimiza tion w hic h is a lot nicer than noncon v ex optimization when y ou ha v e m ultiple lo cal minima and other p roblems. So I did sp end a lot of time wo rking on b o osting tec h- niques applied to linear regression w ith noncon v ex p enalties. NF: Statisticians around the world h av e b een us- ing your tec hniqu es for a long time n o w, ther e’s a compan y th at exists simp ly to sell y our soft ware an d y ou generated that indu stry . Also your ideas and metho ds w ere used by Y aho o!. JF: Y es. T hey used the commercial analog of MAR T as a big part of their sea rch engine. I don’t kno w exactly w hat they use no w, ma yb e the Mi- crosoft search engine. But for a long time, MAR T w as an inte gral part of the Y aho o! search engine. 7. LIFE OUTSIDE S T A TIS TICS NF: Let’s actually leav e Statistics briefly , b ecause y ou do hav e a life outsid e Statistics. JF: W ell, somewhat. (See the anecdote Life out- side Statistics in Fisher ( 2015 ).) NF: An d then there’s b een y our long-time in terest in gam b ling and computers. JF: Y es, that started when I w as a graduate stu- den t. (See the anecdote Statistics, c omputers and gambling in Fisher ( 2015 ).) A CONVERSA TION WITH JERR Y FRI ED MAN 25 Fig. 5. A fine me al at home, 1997 Photo gr aph: NIF. 8. BA CK TO THE FUTURE NF: Finally , let’s step bac k, or ma yb e mo ve to a greater height in this con versatio n, in the sense of taking a p ersp ectiv e on statistics at certain times. There hav e b een at least tw o o ccasions (F ried- man, 1989b , 2001b ) when y ou ha v e committed your though ts to print ab out “Where are w e no w with statistics and compu tin g?” Let’s go bac k to 1987 when there w as a symp osium on “Statisti cs in Sci- ence, Industry an d Public Policy .” Y ou we re invit ed to present a p ap er on “Mo dern S tatistics and the Computer Rev olution.” JF: It was an assignmen t I couldn’t r efuse b ecause it was fr om the p erson in c harge of statistics fun ding at NSF. I h ad an NSF gran t at the time, so I had to go bac k and giv e a talk ab out w hat I thought ab out the futu re of statistics and h o w compu ting migh t affect statistics in the fu ture. NF: In this pap er yo u talk ed ab out automatic data acquisition, some of its b enefits and also some of the issues that it raised. Early in the pap er you said that “What separates S tatistics to a large d e- gree fr om the in formation sciences is th at we seek to u nderstand the limits of th e v alidity of the in fer- ence.” Do y ou think that separation is s till the case in, sa y , m ac h ine learning areas? JF: Not as m uc h as it was, b ut I would sa y so. The huge con tribution of statistics to data analysis is inference, w hat y ou are getting out of the data, or learning from the data. Ho w muc h of it is r eally v alid. That has b een the main thru st of statistics. It has b ecome less of a thr ust o nly b ecause data sets ha v e gotten larger and so the sampling v ariation has b ecome less of a problem, bu t it’s still there in a big w a y . O riginally , I th ink there w ere p eople in n eu- ral net w orks and mac hine learning who weren’t very concerned ab out that at all, wh atev er th ey found they assumed wa s r ealit y . And to b e fair, at least in mac h ine learning, that wa s b ecause they w ere deal- ing with pattern recognition—problems wh ere the inherent noise w as not large, where the Ba yes er- ror rate in a cla ssification p roblem w as really v ery close to zero if not zero. Th e p articular classifier that attained that err or r ate was complicated and hard to get at. So I don’t thin k that inference w as as big a pr oblem in those kind s of things. Statis- ticians originally came f r om other areas where the data sets w ere small and signal to noise w as v ery lo w . In th ose settings inference is a very imp ortan t part of the learning pr o cedure. NF: But the co mpu ter scien tists and the ma- c h ine learners ha v en’t sta y ed in their little b o x , they started pla ying with other problems. JF: O h yes, Ba ye s-t yp e id eas are now spread throughout machine learnin g, compu ter science and engineering, for examp le. Inference is there, al- 26 N. I. FISH ER though it’s p erhap s not giv en quite the high priorit y that w e statisticians give it. NF: Y o u commen ted th at most of th e m etho ds b eing us ed in Statistics in 1986 were actually devel- op ed b efore 1950, but that the computer w as lib er- ating u s from th ese m athematical bin d ings suc h as closed-form solutions and unv erifi able assum ptions. I particularly lik e y our clo sing commen t that “The cost of computation is ev er decreasing b ut the pr ice w e pa y for in correct assu mptions is s till staying the same.” W ould y ou care to amend that s tatement no w? JF: No, I think it’s the same, we hav e to m ak e few er and f ew er unv erifiable assumptions these days. The sample reuse tec h n iques lik e cross-v alidation and the b o otstrap h a v e really fr eed u s up; they ha v e really h elp ed the kind of thing I do a lot. Quite often when y ou come up with a n ew complicated p ro ce- dure and someone will sa y , “Ho w do y ou do the infer - ence? How do yo u pu t error b ars in ?” or something lik e that, y ou just reply , “W ell yo u can b o otstrap it.” So that was a gian t con tribu tion to statistics. But in the area that I work in it is esp ecially v aluable. NF: Mo ving on 12 y ears, yo u had another opp or- tunit y to tak e a helicopter view at th e ISI meeting in Helsinki, where there w as a session on “Critical Issues for Statistics in the Next Two Decades.” Y ou present ed a pap er on “The Role of Statistics in the Data Revo lution?,” and I note th e question mark at the end of that statemen t! In the summary you said, “The natur e of data is rapidly c hanging. Data sets are b ecoming increasingly large and complex. Mo d- ern metho dologies for analysing these new t yp es of data are emerging from the fi elds of data base managemen t, artificial inte lligence, mac hine learn- ing, pattern recognition, and data visualization. So far, statistics as a field h as p la yed a minor role. This pap er explores some of the reasons for this and why statisticia ns should ha v e an int erest. . . ” and so on. What I’m intereste d in is: Ho w hav e things c hanged since then, w hat needs to b e done, and what’s blo ck- ing this c hange? JF: Oh , I think it’s c hanging quite a b it. P er- haps I hav e a nonrepresentati ve view b eing at Stan- ford, but I thin k that statistics is defi nitely mo v- ing forw ard in those areas. Statistical researc h in data analysis is definitely o v erlapping more with ma- c h ine learning and pattern r ecognitio n. As I p ointed out in th e 1987 pap er , a nd as I say whenever I a m ask ed ab out the futu re of statistics, you can’t an s w er that question, y ou hav e to ask: What i s the futur e of data ? Statistics and all o f the data sciences will resp ond to wh atev er data is presen t. No one could ha v e an ticipated gene expression arra ys in the late 1980s. No w statistic ians hav e adapted to that and the wh ole b ioinformatics r evolutio n as w ell, making h uge con tributions to th ose areas. NF: In particular, in the 1999 p ap er, reflecting on the relationship b et we en statistics and d ata min- ing, y ou said that “F rom the p ersp ectiv e of statis- tical data analysis, how eve r, one can ask wh ether data mining metho d ology is an in tellectual disci- pline. So far the answer is: Not ye t. . . ” Has the an- sw er c hanged or has the question b ecome irr elev ant? JF: T h at’s a go o d qu estion. I would say it’s rele- v an t and c hanging; I’m not sur e that it has totally c h anged yet. I think y ou need p eople who can come up with sev eral wa ys of lo oking at data b u t who p er- haps don’t h a v e the requ isite skills to un d erstand at a basic lev el what’s happ ening. And you need p eo- ple who are v ery skilled at taking a metho dology and a s itu ation and then deriving the prop erties of th e metho d in that situation. I think the attitude in the data minin g communit y is: “If it wo rks, great! W e’ll try things and we ’ll find out the things that work.” I think that’s a p erfectly reasonable wa y to p ro ceed. Some p eople lik e to p ro ceed from basic p rinciples: let’s firs t und erstand the basic p rinciples, and from there dev elop the r igh t things to d o, or go o d things to do. T he other is an ad ho c approac h—ju s t think hard ab out the pr oblem, try to figure it out—whic h is the wa y T uk ey did it wa y bac k when—and try to come up with something that w orks wel l. That approac h is fraugh t w ith danger, of course: not ev- ery one is as smart as T uk ey . As p eople d evelo p tec h- niques, they adve rtise and convince p eople they are really v ery go o d when they are n ot, so one has to b e careful. But generally , if there’s a metho d ology lik e PLS, Su p p ort V ector Mac hines, b o osting or more general ensemble metho d s th at s eems to rep eatedly w ork v ery wel l, there’s p robably a go o d s tatistical reason, ev en if in the b eginn in g it w as not kno wn. The understand ing, the underlying principles of wh y they w ork well, came later on. NF: Later in that pap er y ou said, “Perhaps m ore than an y other time in the p ast statistics is at a crossroads; w e can decide to accommo date or resist c h ange.” Ha ve we accommo dated, are we still r esist- ing c hange, how d o y ou situate statistics no w in the information sciences? JF: I think statistics is accommo d ating c hange, not as fast as I would lik e, faster than some other A CONVERSA TION WITH JERR Y FRI ED MAN 27 p eople would lik e, but certainly adapting to change. Ultimately it is data that’s driving statistics as w ell as the other in formation sciences. But I thin k statis- tics to d a y is m uc h more resp onsive . When new f orms of d ata come out there are statisticians who imme- diately see the opp ortunity , as w ell as engineers and other p eople. NF: Then in a sen s e I think you hav e answered y our concluding remark in this pap er, w h ic h w as: “Ov er the years this d iscussion has b een dr iv en mainly by tw o leading visionaries of our field. John T uke y in his 196 2 Ann als of Mathematical S tatistics pap er (T uk ey ( 1962 )) and Leo Breiman at the 1977 Dallas conferen ce. Ov er tw ent y y ears hav e passed since that conference. W e again ha ve the opp ortu- nit y to re-examine ou r place among the information sciences.” S o you feel th at w e are sitting rather more comfortably in there than we d id? JF: Again, b eing at a w ond erful place lik e Stan- ford, I think so, y es. I thin k we are doing it right. W e ha v en’t abandoned our tradition of formal inference, whic h is very go o d b ecause that’s something th at the other information sciences d on’t do nearly as w ell as we d o. There are isolated incidences of p eople in those other areas who do it v ery w ell, but it’s not the priorit y that it is in statistics. That b eing one of our p riorities r eally helps a lot b ecause yo u must understand the limits of inference at some p oin t. I think in the early stages w e were tryin g things out, seeing wh at w ould work and u sing our intuition and I think the in s igh ts are b eginning to come. These da ys, if you lo ok at th e work b eing done in bioinfor- matics, in computer science and in s tatistics, there’s a huge ov erlap w here there wasn’t b efore. . . in atti- tude as w ell as the actual w ork, the problems we ’re trying to solv e. NF: W ell, w e still hold true to the guiding stan- dard of und erstanding and managing v ariabilit y . JF: T h at’s right, and I think w e pa y more atten- tion to that than other fields do and I think th at’s go o d. In the past, p erhaps we ma y hav e paid to o it muc h atten tion. W ell, not to o m uch atten tion b e- cause statistics was wo rking on metho dology for a certain kin d of data—small data sets, high noise, where in ference w as ev erything, are y ou seeing a sig- nal or n ot? This is the essence of hypothesis testing. Not How big is the signal and what ar e its pr op er- ties? , ju s t Can we say wh ether ther e is one or not? With those sm all data sets and high noise often th at w as the only thing y ou could ask. Hyp othesis test- ing was a h u ge intelle ctual triumph . But no w with larger data sets and b etter signal-to-noise ratios, w e can start asking m ore detailed questions: What is the natur e of the sig nal? What variables ar e p artici- p ating in the pr e diction pr oblem? How ar e they p ar- ticip ating? How ar e they working to gether to pr o duc e the r esult? NF: Y ou h av e certainly c h anged the wa y a lot of p eople th ink ab out S tatistics and y ou b eliev e y ou are doing S tatistics and ha v e done consistently . If Colin Mallo ws we re in our presence no w, do yo u th ink he w ould b e d escribing what y ou do as S tatistics? JF: I guess y ou’d ha ve to ask him. P erhaps. I ha v e alw a ys b eliev ed that—p erhaps erroneously!— but I alw a ys b eliev ed th at I w as doing statistic s. Y ou kno w wh at they sa y: a r ose b y any other name w ould smell as sw eet. I think there is less of a need to cat- egorize thin gs. Wh o cares ab out th e name of w h at y ou’re doing as long as it’s in teresting and p oten- tially useful. The categories seem to b e all blurred no w and that’s all to the goo d. NF: Ok ay , we ll by a miracle of mo dern science w e h a v e sitting b eside us a reincarnation of J erry F riedman, except he’s only t we nt y y ears old, and he’s wo nderin g what to d o at college. What are yo u going to recommend? JF: What I alw a ys r ecommend wheneve r I’m ask ed: “What should I stud y , w hat sh ould I do?” I alwa ys sa y , “ Stud y and follo w what you are m ost passionately interested in . Don’t w orry ab out w hat skills are going to b e market able in ten y ears b ecause that will all c h ange.” If yo u go to sc ho ol to learn a skill that you don’t like b ecause you think it is going to b e esp ecially mark etable when y ou get out 5 or 6 or 8 yea rs from no w, that could c hange. Y ou’ve suffered through all of that and you end up with- out mark etable skills after all. A t least if y ou stu d y something y ou’re really enjo ying or are p assionate ab out, y ou’v e had all that fun. I f y ou’re luc k y lik e I was and it tur ns out that y our skill ev olv es int o b eing mark etable, then so muc h the b etter. F oll o w y our passion. NF: Y ou thin k statistics might easily b e one of those? JF: Oh, I ag ree with Hal V arian (Chief Economist, Go ogle), who m ade that statemen t, that s tatistics is going to b e the glamor field of the future for some time (“I keep sa y in g the sexy job in the next ten years will b e statisticians.” V arian ( 2009 )). P eo- ple think I’m j oking, but w ho w ould’v e guessed that computer engineers w ould’ve b een the sexy job of th e 199 0s? The data rev olution—using data 28 N. I. FISH ER Fig. 6. A fine cigar. Photo gr aph: Ildi ko F r ank. to answ er questions and solv e prob lems—h as really emerged. Not so long ag o when, say , y ou were at a factory or at some kind of pro duction line and yield w as going down, what did y ou do ab out it? W ell, y ou called on the sup ervisors and exp erts, y ou got in to a ro om and y ou tr ied to figure why yield might b e going down. It did n’t often o ccur to p eople to collect data. No w eve ryb o dy collects data. Almost ev ery pr o duction line and factory is heavi ly instru- men ted at ev ery p oint and data is b eing collected. In fact, I think mayb e it ma y come to the p oint w here p eople ask to o muc h of data; data can’t answer ev- ery question. COD A NF: I w as p ondering ho w to title this con v ersa- tion and I did ha v e in mind something lik e “Jerry’s searc h for pattern,” but then it o ccurred to me that a pattern is only a pattern. . . JF: . . . bu t a go o d cigar is a Smoke. I agree. NF: Someb o dy once said something along those lines. JF: Y es, it w as Kipling of course (e.g., Kip ling ( 1886 )). I started smoking cigars on and off wh en I w as y oung, in high sc ho ol and j ust ou t of high sc h o ol. I w ork ed for the F orestry Service figh ting forest fi res and sur veying tim b er access r oads. Where I liv ed most o f the countryside w as national forest and so that was a traditional job to d o. A t one of the camps the only facilities were out-houses and they smelled v ery , very bad. It w as a real ord eal to use them, es- p ecially if y ou h ad to stay longer than ten or tw ent y seconds. The only wa y that I could stand to do it was to ligh t up a r eally foul-smelling cigar, and sm ok e it while I was in ther e. That’s w h y I started smoking cigars. I smok e b etter cigars no w. NF: So do y ou feel w e should stop talking ab out patterns righ t now and adjou r n. . . ? JF: It w ouldn’t b e a bad idea. NF: W ell then, man y than k s , Jerry , for this glimpse of a fascinating scien tific o dyssey . I feel as if I’v e b een slip-streaming Slim Pick ens, riding a ro c k et do wn the y ears in whic h s tatistics and com- puting ha v e b ecome inextricably inte rtwined, except y ou’v e b een sitting on the nose-cone and p oint ing the ro c k et, which S lim Pic k ens d idn’t quite ha v e the abilit y to do. Ma y y ou ride for a long time to come. JF: W ell, thank y ou v ery m uch, Nic k, I really ap- preciated it. A CONVERSA TION WITH JERR Y FRI ED MAN 29 A CKNO WLEDGMENTS The author thanks Ru dy Beran and Bill v an Z w et for v aluable critical co mment on a draft of th is ar- ticle, th e Editor and an Asso ciate Ed itor for their helpful feedbac k, and Jerry for h is hospitalit y d u ring the interview and p atience du ring the preparation of the article. Th e w ork was supp orted in p art by V al- ueMetrics Australia. SUPPLEMENT AR Y MA TERIAL Supp lemen t to “A con v ersation with Jerry F ried- man” (DOI: 10.121 4/14-STS509SUPP ; .p d f ). T he supplementary materials asso ciate d with this arti- cle compr ise a n umb er of anecdotes, plu s an exam- ple of one w a y in wh ic h John T uke y communicate d his researc h ideas to J erry in the cour se of their col- lab oration. They are av ailable from Fisher ( 2015 ). REFERENCES Breiman, L. (1996). Arcing classifiers. T ec hnical Rep ort 460, Univ. California, Berk eley . Breiman, L. and Friedman, J. H. (1985). Estimating op- timal transformations for multiple regression and correla- tion. J. Amer. Statist. Asso c. 80 580–619 . MR080325 8 Breiman, L. and Friedman, J. H. (1997). Predicting m ulti- v ariate responses in multiple linear regression. J. R. Stat. So c. Ser. B Stat. Metho dol. 59 3–54. MR1436554 Breiman, L. , Frie dman, J. H. , Olshen, R. A. and Stone, C. J. (1984). Classific ation and R e gr ession T r e es . W adsw orth, Belmont, CA. MR0726392 Brillinger, D. R. (2002). John W. Tukey: His life and professional con tributions. Ann. Statist. 30 1535–1 575. In memory of John W. T ukey . MR1969439 Co ver, T. M. and Har t, P. E. (19 67). Nearest neigh b or pattern classification. IEEE T r ans. Inform. The ory IT-13 2–27. de Boor, C. (2001). A Pr actic al Guide to Splines , Revised ed. Applie d Mathematic al Scienc es 27 . Springer, N ew Y ork. MR1900298 Efr on, B. , Hastie, T. , Johnstone, I. and Tibshirani, R. (2004). Lea st angle reg ression. A nn. Statist. 32 407–499. MR2060166 Fisher, N. I. (2015). S upplement to “A con versa tion with Jerry F riedman.” DOI: 10.1214 /14-STS509SUPP . Fithian, W . a nd Hastie , T. (2013 ). Finite-sample equiv- alence in statistical mod els for presence-only d ata. Ann. Appl. Stat. 7 1917–1939. MR3161707 Frank, I. E. and Fried man, J. H. (1993). A statistical view of some chemometrics regression tools. T e chnometrics 35 109–148 . Freund, Y. and Shap ire, R. E. ( 1996). Exp eriments with a new b o osting algorithm. In Machine L e arning: Pr o c e e d- ings of the Thirte enth Internat ional Confer enc e 148– 156. Morgan Kaufmann, San F rancisco, CA. Friedman, J. H . (198 4). A v ariable span smoother. T ech- nical Rep ort 5, Lab oratory f or C omputational Statistics, Stanford Univ., S tanford, CA. Friedman, J. H. (1987). Exploratory pro jection pursuit. J. Amer . Statist. Asso c. 82 249–266. MR0883353 Friedman, J. H. (1989a ). Regularized discriminan t analysis. J. A mer. Statist. Asso c. 84 165–175 . MR0999675 Friedman, J. H. (1989 b). Mo dern statistics and the com- puter revolution. In Symp osium on Statistics in Sci- enc e, Industry, and Public Poli cy, Part 3 14–29. National Academies Press, W ashington, DC. Friedman, J. H. (1991). Multiv ariate adaptive regression splines. Ann. Statist. 19 1–141. MR1091842 Friedman, J. H. (1997). On bias, v ariance, 0/1-loss, and t he curse-of-dimensionalit y. Data Min. Know l. Disc ov. 1 55– 77. Friedman, J. H. (2 001a). Greedy fun ction approximation: A gradien t b o osting machine. Ann. Statist. 29 1189–12 32. MR1873328 Friedman, J. H . (2001b). The role of statistics in th e data revol ution? I nt. Stat. R ev. 69 5–10. Friedman, J. H. , Bentley, J. L. and Finkel, R. A. ( 1977). An algorithm for finding b est matches in logarithmic time. ACM T r ans. Math. Softwar e 3 209–226. Friedman, J. H. and Fisher, N. I. ( 1999). Bump hunting in high-dimensional data. Stat. Comput. 9 123–162. Friedman, J. H . , Gr osse, E. and Stuetzle, W. (19 83). Multidimensional additive spline approximatio n. SIA M J. Sci. Statist. Comput. 4 291–301. MR0697182 Friedman, J. , H astie, T. and Tibshira ni, R. (2000). Addi- tive logistic regression: A statistical view of b o osting. Ann. Statist. 28 337–407. MR1790002 Friedman, J. H. and Rafsky, L. C. (1979). Multiv ariate generalizations of the Wald–Wolfo witz and Smirnov tw o- sample tests. Ann. Statist. 7 697–717. MR0532236 Friedman, J. H. and Rafsky, L. C. (1983). Graph- theoretic measures of multiv ariate association and p rediction. Ann. Statist. 11 377–391. MR0696054 Friedman, J. H. and S tuetzle, W. (1981). Pr o jection pursuit regressio n. J. Amer. Statist. Asso c. 76 817–823. MR0650892 Friedman, J. H. an d Stuetzle, W. (200 2). Jo hn W. Tukey’s work on interacti ve graphics. Ann. Statist. 30 1629–16 39. In memory of John W . T ukey . MR1969443 Friedman, J. H. , Stuetzle, W . and Schroeder, A. (1984). Pro jection pursuit den sity estimation. J. Amer. Statist. Asso c. 79 599–60 8. MR0763579 Friedman, J. H. and Tukey, J. W. ( 1974). A p ro jec- tion pu rsuit algorithm for exploratory data analysis. I EEE T r ans. Comput. C-23 881–889. Hastie, T. , Tibshirani, R. and Friedma n, J. (2001). The Elements of Statistic al L e arning. Data Mining, Infer enc e, and Pr e diction . S pringer, New Y ork. MR1851606 Kipling, R. (1886). P art of th e second last coup let of “The Betrothed.” First pub lished in Dep artmental Ditties . Avai l- able at http:// en.wikipedia.org/wiki/The_Betrot hed_ %28Kipling _poem %29 . Mor gan, J. N. and S onquist, J. A. (1963). Problems in the analysis of survey data, and a prop osal. J. Amer. Statist. Asso c. 58 415–43 5. 30 N. I. FISH ER Orear, J. (1982). Notes on statistics for physicists, revised. Av ailable at http://ned.ipac.caltech.edu/ level5/Sept01/Orear/frames.html . Quinlan, J. R. ( 1986). Indu ction of decision trees. Ma- chine L e arning 1 81–106. Rep rinted in R e adings in Ma- chine L e arning ( J. W. Sha v lik and T. G. Dietterich , eds.). Morgan Kaufmann, San F rancisco, 1990, and also, in R e adings i n Know le dge Ac qui sition and L e arning (B. G. Buchanan and D. Wilkins, eds.). Morgan Kaufmann, San F rancisco, 1993. Tukey, J. W. (1962). The future of data analysis. Ann. Math. Statist. 33 1–67. MR0133937 V arian, H. (2009). H al V arian on how the W eb chal lenges managers. Av ailable at http:/ / www.mckinsey.com/insights/innovation / hal_varian _on_how_the_we b_challenges_managers . Wol d, S. and Sjostrom, M. (1977). S IMCA: A method for analyzing chemica l data in terms of similarit y and an alogy . In Chemometrics The ory and Applic ation ( B. R. Ko w al- ski , ed.). Americ an Chemic al So ciety Symp osium Series 52 243–282 . American Chemical So ciety , W ashington, D.C. Zou, H . and Hastie, T . (2005). Regularization and v ariable selection via the elastic net. J. R. Stat. So c. Ser. B Stat. Metho dol. 67 301–320 . MR2137327
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment