제로바이어스 오토인코더와 공동 적응 특징의 장점
본 논문은 정규화된 오토인코더 학습 시 숨겨진 유닛의 바이어스가 크게 음수로 수렴하는 현상을 분석하고, 이러한 음수 바이어스가 고차원 데이터의 내재 차원을 학습하는 데 방해가 됨을 보인다. 저자는 선택 기능과 표현 기능을 분리하는 새로운 활성화 함수(Thresholded ReLU, TRec)를 제안하여, 바이어스를 없애고도 희소성을 유지하면서 선형 인코딩을 가능하게 한다. 실험 결과, 제안 모델은 CIFAR‑10의 퍼뮤테이션 불변 태스크에서 기…
저자: Kishore Konda, Rol, Memisevic
본 논문은 오토인코더 학습 과정에서 흔히 관찰되는 숨겨진 유닛 바이어스가 크게 음수로 수렴하는 현상을 체계적으로 분석한다. 저자는 이 현상이 ‘선택’과 ‘표현’이라는 두 가지 기능을 하나의 유닛이 동시에 수행하기 때문에 발생한다고 주장한다. 음수 바이어스가 있는 ReLU 혹은 sigmoid 활성화는 입력과 가중치 벡터의 내적이 일정 임계값 이하일 때 출력을 0으로 만들며, 이는 입력 공간의 구형 캡(구면 위의 작은 영역)만을 활성화한다. 이러한 선택 메커니즘은 각 유닛이 데이터의 국소 클러스터를 담당하게 만들고, 다중 유닛이 협력해 다차원 밀도 영역을 모델링하는 것을 방해한다. 특히, 활성화된 유닛 집합 S(x)에 대해 재구성 조건 r(x)=x을 만족시키는 선형 방정식 (W_S W_S^T – I)x = –W_S b 가 도출되는데, 여기서 b가 0이 아니면 정규 직교성(orthogonality)이 깨져 최적의 프레임을 형성하기 어렵다.
이 문제를 해결하기 위해 저자는 선택 기능과 선형 인코딩을 명시적으로 분리하는 새로운 활성화 함수를 제안한다. 구체적으로, h(z)=𝟙(z>θ) 로 정의된 이진 스위치를 사용해 입력이 임계값 θ를 초과할 때만 선형 출력 z를 전달한다. 이때 전체 재구성 함수는 r(x)=∑_k h(w_k^T x)·w_k^T x·w_k 로 표현된다. 학습 단계에서는 θ를 0 혹은 1로 고정하고, 바이어스 없이도 희소성을 유지한다. 테스트 단계에서는 스위치를 제거하고 일반 ReLU(바이어스 없음)로 전환해 선형 표현을 얻는다. 이러한 구조는 스파이크‑앤‑슬랩 모델과 유사하지만 확률적 해석 없이 결정론적으로 동작한다.
활성화 함수는 두 가지 변형을 제시한다. 첫 번째는 Thresholded ReLU (TRec) 로, h(z)=𝟙(z>θ)·z 형태이며, 비미분점 θ에서 미분이 0이지만 SGD에서는 무시한다. 두 번째는 Thresholded Linear (TLin) 로, h(z)=𝟙(|z|>θ)·z 로 정의되어, 큰 양·음 입력 모두를 선형적으로 전달한다. 두 함수 모두 ‘선택‑표현 분리’를 구현해 바이어스 없이도 희소성을 유지한다.
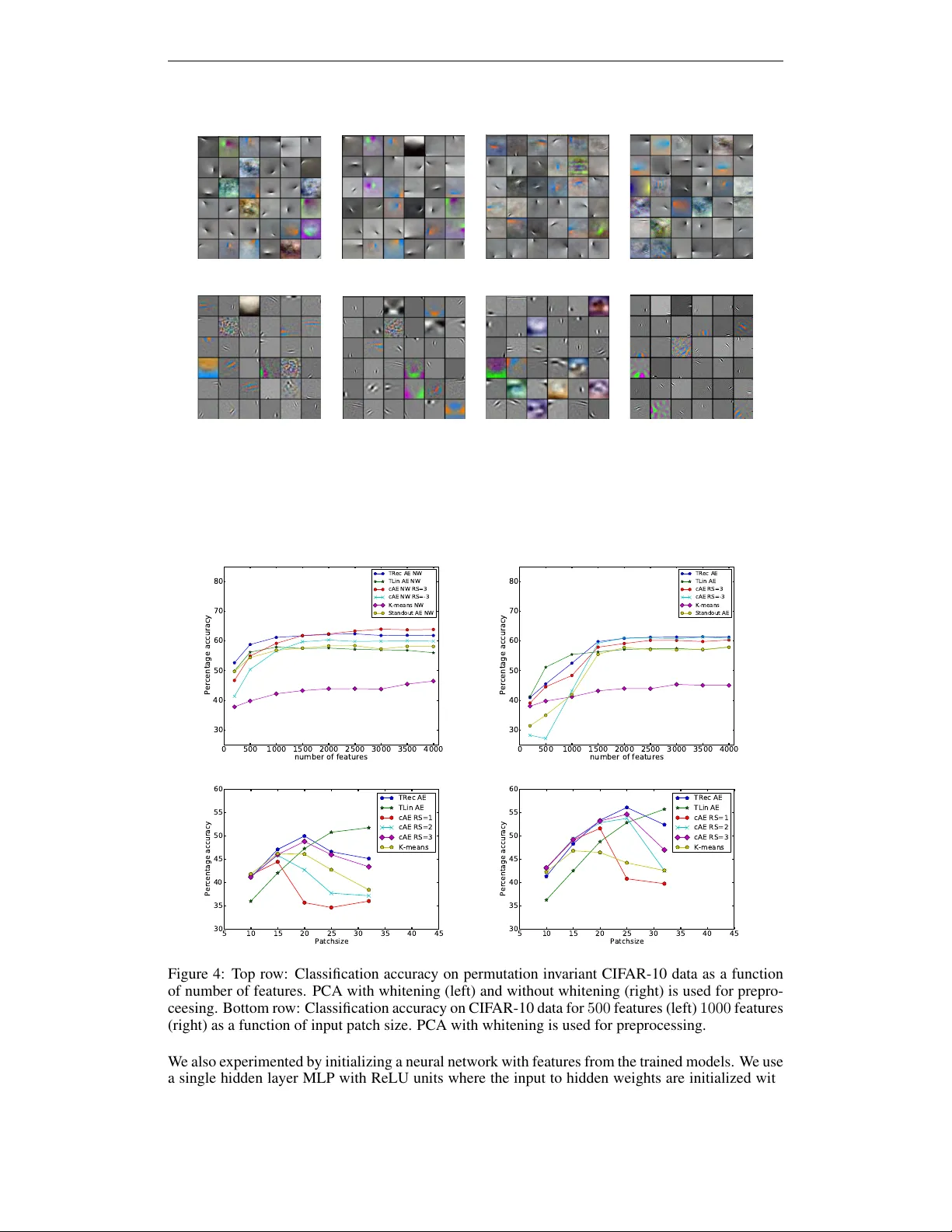
실험에서는 CIFAR‑10 데이터셋을 사용해 퍼뮤테이션 불변 인식 태스크를 수행하였다. 입력은 대비 정규화 후 PCA(99% 분산 유지) 혹은 비정규화 PCA로 차원 축소하였다. 모델은 200~4000개의 과잉 특징을 학습했으며, 모든 모델을 동일한 SGD 설정(학습률 0.0001 → 0.001, 모멘텀 0.9, 1000 epoch)으로 훈련하였다. 평가에는 로지스틱 회귀(가중치 감쇠)를 사용하였다.
결과는 다음과 같다. 제로바이어스 오토인코더(ZAE)는 동일한 조건의 계약(auto‑encoder), 디노이징(auto‑encoder), 스탠드아웃(auto‑encoder), K‑means 기반 모델보다 일관되게 높은 정확도를 기록했다. 특히, 테스트 시에 바이어스를 완전히 제거하고 ReLU만 사용했을 때 정확도가 크게 상승했으며, 이는 기존 연구(Ranzato et al., 2007; Coates et al., 2011)와 일치한다. 또한, 프레임 이론을 적용해 가중치가 데이터 공간을 완전히 스팬하면 파스발 프레임(Parseval frame) 형태가 근사적으로 형성되어, 재구성 오류 최소화와 동시에 정규 직교성을 유지한다는 이론적 근거를 제시한다.
결론적으로, 음수 바이어스는 희소성을 유도하지만 고차원 데이터의 복합 구조를 학습하는 데 구조적 제한을 만든다. 선택‑표현 분리를 통한 제로바이어스 활성화는 이러한 제한을 해소하고, 추가적인 정규화 없이도 강력한 특징 학습을 가능하게 한다. 이는 고차원, 고밀도 데이터에 대한 비지도 학습에서 새로운 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기