Zero-bias autoencoders and the benefits of co-adapting features
Regularized training of an autoencoder typically results in hidden unit biases that take on large negative values. We show that negative biases are a natural result of using a hidden layer whose responsibility is to both represent the input data and …
Authors: Kishore Konda, Rol, Memisevic
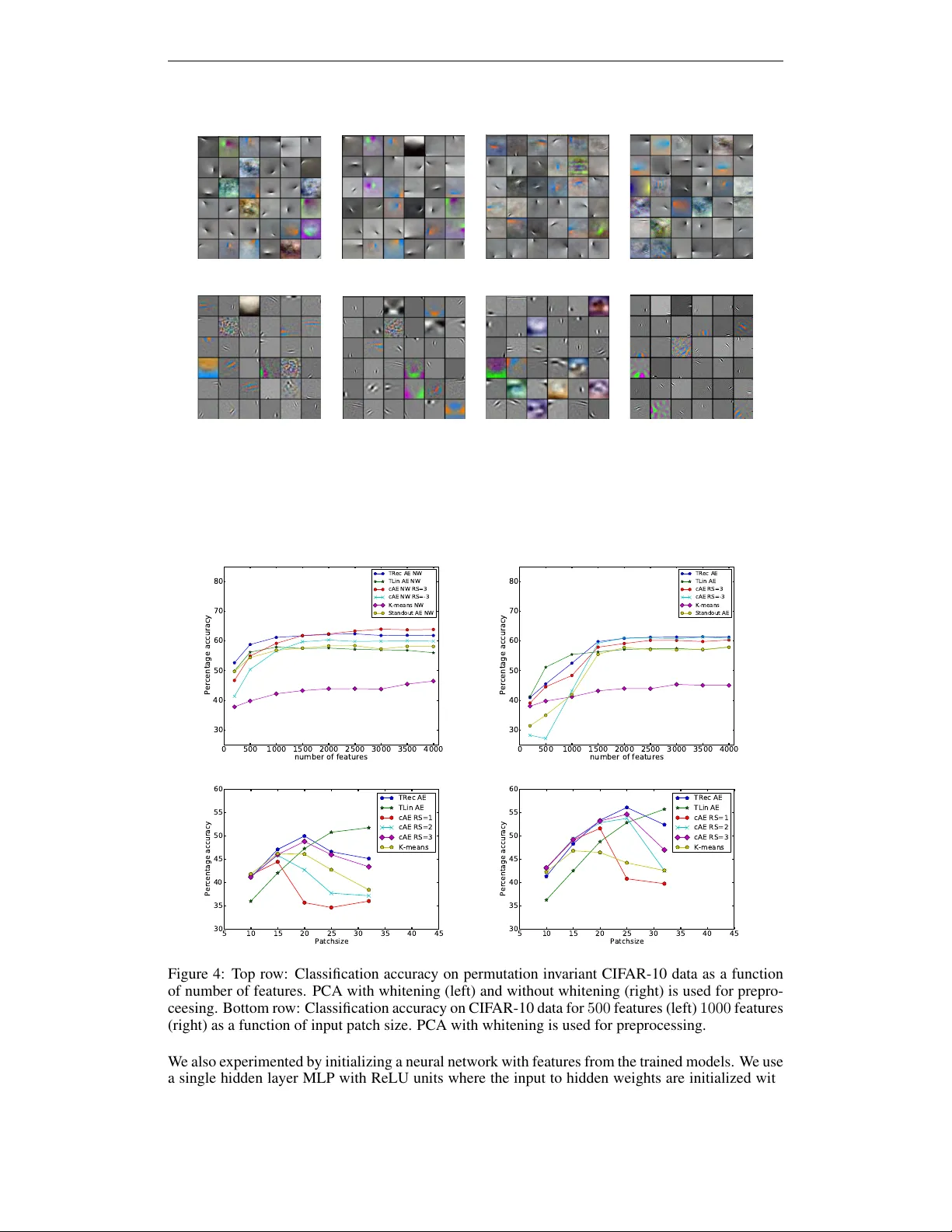
Published as a conference paper at ICLR 2015 Z E R O - B I A S AU T O E N C O D E R S A N D T H E B E N E FI T S O F C O - A D A P T I N G F E A T U R E S Kishore Konda Goethe Univ ersity Frankfurt Germany konda.kishorereddy@gmail.com Roland Memisevic Univ ersity of Montreal Canada roland.memisevic@umontreal.ca David Krueger Univ ersity of Montreal Canada david.krueger@umontreal.ca A B S T R AC T Regularized training of an autoencoder typically results in hidden unit biases that take on large ne gativ e values. W e show that neg ativ e biases are a natural result of using a hidden layer whose responsibility is to both represent the input data and act as a selection mechanism that ensures sparsity of the representation. W e then show that neg ativ e biases impede the learning of data distrib utions whose intrinsic dimensionality is high. W e also propose a new activ ation function that decouples the two roles of the hidden layer and that allows us to learn representations on data with very high intrinsic dimensionality , where standard autoencoders typi- cally f ail. Since the decoupled activ ation function acts like an implicit re gularizer , the model can be trained by minimizing the reconstruction error of training data, without requiring any additional re gularization. 1 I N T RO D U C T I O N Autoencoders are popular models used for learning features and pretraining deep networks. In their simplest form, they are based on minimizing the squared error between an observation, x , and a non-linear reconstruction defined as r ( x ) = X k h w T k x + b k w k + c (1) where w k and b k are weight vector and bias for hidden unit k , c is a vector of visible biases, and h ( · ) is a hidden unit acti vation function. Popular choices of activ ation function are the sigmoid h ( a ) = 1 + exp( − a ) − 1 , or the rectified linear (ReLU) h ( a ) = max(0 , a ) . V arious regularization schemes can be used to prevent trivial solutions when using a large number of hidden units. These include corrupting inputs during learning V incent et al. (2008), adding a “contraction” penalty which forces deriv ativ es of hidden unit acti vations to be small Rifai et al. (2011), or using sparsity penalties Coates et al. (2011). This work is motiv ated by the empirical observation that across a wide range of applications, hid- den biases, b k , tend to take on large negati ve values when training an autoencoder with one of the mentioned regularization schemes. In this work, we sho w that neg ative hidden unit biases are at odds with some desirable properties of the representations learned by the autoencoder . W e also show that negati ve biases are a simple 1 Published as a conference paper at ICLR 2015 0 500 1000 1500 2000 2500 3000 3500 4000 number of features 40 45 50 55 60 65 70 75 Percentage accuracy cAE Relu with bias cAE Relu cAE Sigmoid Figure 1: Left: Filters learned by a sigmoid contractive autoencoder Rifai et al. (2011) (contraction strength 1 . 0 ; left) and a ReLU denoising autoencoder V incent et al. (2008) (zeromask-noise 0.5; right) from CIF AR-10 patches, and resulting histograms over learned hidden unit biases. Right: Classication accuracy on permutation in variant CIF AR-10 data using cAE with multiple different inference schemes. All plots in this paper are best vie wed in color . consequence of the fact that hidden units in the autoencoder have the dual function of (1) selecting which weight vectors take part in reconstructing a giv en training point, and (2) representing the coefficients with which the selected weight vectors get combined to reconstruct the input (cf., Eq. 1). T o overcome the detrimental effects of negati ve biases, we then propose a new activ ation function that allows us to disentangle these roles. W e show that this yields features that increasingly outper- form regularized autoencoders in recognition tasks of increasingly high dimensionality . Since the regularization is “built” into the acti vation function, it allo ws us to train the autoencoder without ad- ditional regularization, like contraction or denoising, by simply minimizing reconstruction error . W e also show that using an encoding without negati ve biases at test-time in both this model and a con- tractiv e autoencoder achiev es state-of-the-art performance on the permutation-in variant CIF AR-10 dataset. 1 1 . 1 R E L A T E D W O R K Our analysis may help explain why in a network with linear hidden units, the optimal number of units tends to be relati vely small Ba & Frey (2013); Makhzani & Frey (2013). Training via thresholding, which we introduce in Section 3, is loosely related to dropout Hinton et al. (2012), in that it forces features to align with high-density regions. In contrast to dropout, our thresholding scheme is not stochastic. Hidden activ ations and reconstructions are a deterministic function of the input. Other related work is the work by Goroshin & LeCun (2013) who introduce a variety of new acti vation functions for training autoencoders and argue for shrinking non-linearities (see also Hyv ¨ arinen et al. (2004)), which set small activ ations to zero. In contrast to that work, we show that it is possible to train autoencoders without additional regularization, when using the right type of shrinkage function. Our work is also loosely related to Martens et al. (2013) who discuss limitations of RBMs with binary observations. 2 N E G A T I V E B I A S AU T O E N C O D E R S This work is moti vated by the observ ation that regularized training of most common autoencoder models tends to yield hidden unit biases which are ne gativ e. Figure 1 shows an experimental demon- stration of this ef fect using whitened 6 × 6 -CIF AR-10 color patches Krizhe vsky & Hinton (2009). Negati ve biases and sparse hidden units hav e also been sho wn to be important for obtaining good features with an RBM Lee et al. (2008); Hinton (2010). 1 An example implementation of the zero-bias autoencoder in python is a vailable at http://www.iro. umontreal.ca/ ˜ memisevr/code/zae/ . 2 Published as a conference paper at ICLR 2015 2 . 1 N E G A T I V E B I A S E S A R E R E Q U I R E D F O R L E A R N I N G A N D B A D I N T H E E N C O D I N G Negati ve biases are arguably important for training autoencoders, especially ov ercomplete ones, because they help constrain capacity and localize features. But they can ha ve sev eral undesirable consequences on the encoding as we shall discuss. Consider the effect of a negativ e bias on a hidden unit with “one-sided acti vation functions”, such as ReLU or sigmoid (i.e. activ ations which asymptote at zero for increasingly negati ve preactiv ation): On contrast-normalized data, it will act lik e a selection function, zeroing out the acti vities for points whose inner product with the weight vector w k is small. As a result, the region on the hypersphere that activ ates a hidden unit (ie. that yields a value that is significantly different from 0 ) will be a spherical cap, whose size is determined by the size of the weight vector and the bias. When activ a- tions are defined by spherical caps, the model effecti vely defines a radial basis function network on the hypersphere. (For data that is not normalized, it will still hav e the effect of limiting the number of training examples for which the acti vation function gets acti ve.) As long as the regions where weight vectors become acti ve do not ov erlap this will be equi valent to clustering. In contrast to clustering, regions may of course o verlap for the autoencoder . Ho wev er, as we show in the following on the basis of an autoencoder with ReLU hidden units and negati ve biases, e ven where acti ve regions mer ge, the model will resemble clustering, in that it will learn a point attractor to represent that region. In other words, the model will not be able to let multiple hidden units “collaborate” to define a multidimensional region of constant density . 2 . 1 . 1 M O D E S O F T H E D E N S I T Y L E A R N E D B Y A R E L U AU T O E N C O D E R W e shall focus on autoencoders with ReLU activ ation function in the follo wing. W e add an approx- imate argument about sigmoid autoencoders in Section 2.1.2 belo w . Consider points x with r ( x ) = x which can be reconstructed perfectly by the autoencoder . The set of such points may be viewed as the mode of the true data generating density , or the true “manifold” the autoencoder has to find. For an input x , define the active set (see also Razvan Pascanu (2014)) as the set of hidden units which yield a positiv e response: S ( x ) = { k : w T k x + b k > 0 } . Let W S ( x ) denote the weight matrix restricted to the activ e units. That is, W S ( x ) contains in its columns the weight vectors associated with activ e hidden units for data point x . The fixed point condition r ( x ) = x for the ReLU autoencoder can now be written W S ( x ) ( W T S ( x ) x + b ) = x , (2) or equiv alently , ( W S ( x ) W T S ( x ) − I ) x = − W S ( x ) b (3) This is a set of inhomogeneous linear equations, whose solutions are given by a specific solution plus the null-space of M = ( W S ( x ) W T S ( x ) − I ) . The null-space is gi ven by the eigenv ectors cor - responding to the unit eigen values of W S ( x ) W T S ( x ) . The number of unit eigen values is equal to the number of orthonormal weight vectors in W S ( x ) . Although minimizing the reconstruction error without bias, k x − W S ( x ) W T S ( x ) x k 2 , would enforce orthogonality of W S ( x ) for those hidden units that are active together, learning with a fixed, non-zero b will not: it amounts to minimizing the reconstruction error between x and a shifted projection, k x − W S ( x ) W T S ( x ) x + W S ( x ) b k 2 , for which the orthonormal solution is no longer optimal (it has to account for the non-zero translation W S ( x ) b ). 2 . 1 . 2 S I G M O I D AC T I V A T I O N S The case of a sigmoid acti vation function is harder to analyze because the sigmoid is nev er exactly zero, and so the notion of an active set cannot be used. But we can characterize the manifold learned by a sigmoid autoencoder (and thereby an RBM, which learns the same density model (Kamyshanska & Memise vic (2013)) approximately using the binary activ ation h k ( x ) = ( w T k x ) + 3 Published as a conference paper at ICLR 2015 b k ≥ 0 . The reconstruction function in this case would be r ( x ) = X k : ( w T k x )+ b k ≥ 0 w k which is simply the superposition of acti ve weight v ectors (and hence not a multidimensional mani- fold either). 2 . 1 . 3 Z E R O - B I A S A C T I V A T I O N S A T T E S T - T I M E This analysis suggests that ev en though negati ve biases are required to achie ve sparsity , they may hav e a detrimental ef fect in that the y make it difficult to learn a non-trivial manifold. The observation that sparsity can be detrimental is not ne w , and has already been discussed, for e xample, in Ranzato et al. (2007); Kavukcuoglu et al. (2010), where the authors giv e up on sparsity at test-time and show that this impro ves recognition performance. Similarly , Coates et al. (2011); Saxe et al. (2011) showed that very good classification performance can be achie ved using a linear classifier applied to a bag of features, using ReLU activ ation without bias. They also showed how this classification scheme is robust wrt. the choice of learning method used for obtaining features (in fact, it ev en works with random training points as features, or using K-means as the feature learning method). 2 In Figure 1 we confirm this finding, and we show that it is still true when features represent whole CIF AR-10 images (rather than a bag of features). The figure sho ws the classification performance of a standard contractiv e autoencoder with sigmoid hidden units trained on the permutation-in v ariant CIF AR-10 training dataset (ie. using the whole images not patches for training), using a linear classifier applied to the hidden activ ations. It shows that much better classification performance (in fact better than the previous state-of-the-art in the permutation in v ariant task) is achieved when replacing the sigmoid activ ations used during training with a zero-bias ReLU activ ation at test-time (see Section 4.3 for more details). 3 L E A R N I N G W I T H T H R E S H O L D - G A T E D A C T I V AT I O N S In light of the preceding analysis, hidden units should promote sparsity during learning, by becoming activ e in only a small region of the input space, b ut once a hidden unit is active it should use a linear not affine encoding. Furthermore, any sparsity-promoting process should be remov ed at test time. T o satisfy these criteria we suggest separating the selection function, which sparsifies hiddens, from the encoding , which defines the representation, and should be linear . T o this end, we define the autoencoder reconstruction as the product of the selection function and a linear representation: r ( x ) = X k h w T k x w T k x w k (4) The selection function, h ( · ) , may use a negati ve bias to achie ve sparsity , but once activ e, a hidden unit uses a linear activ ation to define the coefficients in the reconstruction. This acti v ation function is reminiscent of spike-and-slab models (for example, Courville et al. (2011)), which define probability distributions ov er hidden variables as the product of a binary spike variable and a real-v alued code. In our case, the product does not come with a probabilistic interpretation and it only serves to define a deterministic activ ation function which supports a linear encoding. The activ ation function is differentiable almost e verywhere, so one can back-propagate through it for learning. The activ ation function is also related to adaptiv e dropout (Ba & Frey (2013)), which ho wever is not dif ferentiable and thus cannot be trained with back-prop. 3 . 1 T H R E S H O L D I N G L I N E A R R E S P O N S E S In this work, we propose as a specific choice for h ( · ) the boolean selection function h w T k x = w T k x > θ (5) 2 In Coates et al. (2011) the so-called “triangle activ ation” was used instead of a ReLU as the inference method for K -means. This amounts to setting activations below the mean activ ation to zero, and it is almost identical to a zero-bias ReLU since the mean linear preactiv ation is very close to zero on a verage. 4 Published as a conference paper at ICLR 2015 w T k x θ w T k x · ( w T k x > θ ) w T k x θ w T k x · ( | w T k x | > θ ) − θ Figure 2: Activ ation functions for training autoencoders: thresholded rectified (left); thresholded linear (right). W ith this choice, the overall activ ation function is w T k x > θ ) w T k x . It is shown in Figure 2 (left). From the product rule, and the fact that the deriv ativ e of the boolean expression w T k x > θ ) is zero, it follows that the deriv ati ve of the activ ation function wrt. to the unit’ s net input, w T k x , is w T k x > θ ) · 1 + 0 · w T k x = w T k x > θ ) . Unlike for ReLU, the non-differentiability of the activ ation function at θ is also a non-continuity . As common with ReLU acti vations, we train with (minibatch) stochastic gradient descent and ignore the non-dif ferentiability during the optimization. W e will refer to this activ ation function as Truncated Rectified (TRec) in the following. W e set θ to 1 . 0 in most of our experiments (and all hiddens hav e the same threshold). While this is unlikely to be optimal, we found it to work well and often on par with, or better than, traditional regularized autoencoders like the denoising or contractiv e autoencoder . Truncation, in contrast to the negati ve- bias ReLU, can also be vie wed as a hard-thresholding operator , the inv ersion of which is fairly well-understood Boche et al. (2013). Note that the TRec activ ation function is simply a peculiar activ ation function that we use for train- ing. So training amounts to minimizing squared error without any kind of regularization. W e drop the thresholding for testing, where we use simply the rectified linear response. W e also experiment with autoencoders that use a “subspace” v ariant of the TRec acti v ation function (Rozell et al. (2008)), giv en by r ( x ) = X k h ( w T k x ) 2 w T k x w k (6) It performs a linear reconstruction when the preacti vation is either very large or very negati ve, so the active region is a subspace rather than a con vex cone. T o contrast it with the rectified v ersion, we refer to this activ ation function as thresholded linear (TLin) below , but it is also known as hard- thresholding in the literature Rozell et al. (2008). See Figure 2 (right plot) for an illustration. Both the TRec and TLin activ ation functions allow hidden units to use a linear rather than affine encoding. W e shall refer to autoencoders with these acti vation functions as zero-bias autoencoder (ZAE) in the following. 3 . 2 P A R S E V A L AU T O E N C O D E R S For overcomplete representations orthonormality can no longer hold. Howe ver , if the weight vectors span the data space, they form a frame (eg. K ov acevic & Chebira (2008)), so analysis weights ˜ w i exist, such that an e xact reconstruction can be written as r ( x ) = X k ∈ S ( x ) ˜ w T k x w k (7) 5 Published as a conference paper at ICLR 2015 The vectors ˜ w i and w i are in general not identical, but they are related through a matrix multipli- cation: w k = S ˜ w k . The matrix S is known as frame operator for the frame { w k } k giv en by the weight vectors w k , and the set { ˜ w k } k is the dual frame associated with S (K ov acevic & Chebira (2008)). The frame operator may be the identity in which case w k = ˜ w k (which is the case in an autoencoder with tied weights.) Minimizing reconstruction error will make the frames { w k } k and { ˜ w k } k approximately duals of one another , so that Eq. 7 will approximately hold. More interestingly , for an autoencoder with tied weights ( w k = ˜ w k ), minimizing reconstruction error would let the frame approximate a Parse val frame (K ovace vic & Chebira (2008)), such that Parse v al’ s identity holds P k ∈ S ( x ) w T k x 2 = k x k 2 . 4 E X P E R I M E N T S 4 . 1 C I FA R - 1 0 W e chose the CIF AR-10 dataset (Krizhe vsky & Hinton (2009)) to study the ability of various models to learn from high dimensional input data. It contains color images of size 32 × 32 pixels that are assigned to 10 different classes. The number of samples for training is 50 , 000 and for testing is 10 , 000 . W e consider the permutation inv ariant recognition task where the method is unaware of the 2D spatial structure of the input. W e ev aluated sev eral other models along with ours, namely contractiv e autoencoder, standout autoencoder (Ba & Frey (2013)) and K-means. The ev aluation is based on classification performance. The input data of size 3 × 32 × 32 is contrast normalized and dimensionally reduced us- ing PCA whitening retaining 99% variance. W e also ev aluated a second method of di- mensionality reduction using PCA without whitening (denoted NW below). By whitening we mean normalizing the variances, i.e., dividing each dimension by the square-root of the eigen values after PCA projection. The number of features for each of the model is set to 200 , 500 , 1000 , 1500 , 2000 , 2500 , 3000 , 3500 , 4000 . All models are trained with stochastic gradi- ent descent. For all the experiments in this section we chose a learning rate of 0 . 0001 for a few (e.g. 3 ) initial training epochs, and then increased it to 0 . 001 . This is to ensure that scaling issues in the initializing are dealt with at the outset, and to help avoid any blow-ups during training. Each model is trained for 1000 epochs in total with a fixed momentum of 0 . 9 . For inference, we use rectified linear units without bias for all the models. W e classify the resulting representation using logistic regression with weight decay for classification, with weight cost parameter estimated using cross-validation on a subset of the training samples of size 10000 . The threshold parameter θ is fixed to 1 . 0 for both the TRec and TLin autoencoder . For the cAE we tried the regularization strengths 1 . 0 , 2 . 0 , 3 . 0 , − 3 . 0 ; the latter being “uncontraction”. In the case of the Standout AE we set α = 1 , β = − 1 . The results are reported in the plots of Figure 4. Learned filters are shown in Figure 3. From the plots in Figure 4 it is observable that the results are in line with our discussions in the earlier sections. Note, in particular that the TRec and TLin autoencoders perform well even with very few hidden units. As the number of hidden units increases, the performance of the models which tend to “tile” the input space tends to improv e. In a second e xperiment we ev aluate the impact of different input sizes on a fix ed number of features. For this experiment the training data is given by image patches of size P cropped from the center of each training image from the CIF AR-10 dataset. This yields for each patch size P a training set of 50000 samples and a test set of 10000 samples. The different patch sizes that we ev aluated are 10 , 15 , 20 , 25 as well as the original image size of 32 . The number of features is set to 500 and 1000 . The same preprocessing (whitening/no whitening) and classification procedure as abo ve are used to report performance. The results are sho wn in Figure 4. When using preprocessed input data directly for classification, the performance increased with in- creasing patch size P , as one would expect. Figure 4 shows that for smaller patch sizes, all the models perform equally well. The performance of the TLin based model improv es monotonically as the patch size is increased. All other model’ s performances suffer when the patch size gets too large. Among these, the ZAE model using TRec activ ation suffers the least, as e xpected. 6 Published as a conference paper at ICLR 2015 (a) TLin AE (b) TRec AE (c) cAE RS=3 (d) cAE RS=-3 (e) TLin AE NW (f) TRec AE NW (g) cAE RS=3 NW (h) cAE RS=-3 NW Figure 3: Features of dif ferent models trained on CIF AR-10 data. T op: PCA with whitening as pre- processing. Bottom: PCA with no whitening as preprocessing. RS denotes regularization strength. 0 500 1000 1500 2000 2500 3000 3500 4000 number of features 30 40 50 60 70 80 Percentage accuracy TRec AE NW TLin AE NW cAE NW RS=3 cAE NW RS=-3 K-means NW Standout AE NW 0 500 1000 1500 2000 2500 3000 3500 4000 number of features 30 40 50 60 70 80 Percentage accuracy TRec AE TLin AE cAE RS=3 cAE RS=-3 K-means Standout AE 5 10 15 20 25 30 35 40 45 Patchsize 30 35 40 45 50 55 60 Percentage accuracy TRec AE TLin AE cAE RS=1 cAE RS=2 cAE RS=3 K-means 5 10 15 20 25 30 35 40 45 Patchsize 30 35 40 45 50 55 60 Percentage accuracy TRec AE TLin AE cAE RS=1 cAE RS=2 cAE RS=3 K-means Figure 4: T op ro w: Classification accurac y on permutation inv ariant CIF AR-10 data as a function of number of features. PCA with whitening (left) and without whitening (right) is used for prepro- ceesing. Bottom ro w: Classification accuracy on CIF AR-10 data for 500 features (left) 1000 features (right) as a function of input patch size. PCA with whitening is used for preprocessing. W e also experimented by initializing a neural network with features from the trained models. W e use a single hidden layer MLP with ReLU units where the input to hidden weights are initialized with features from the trained models and the hidden to output weights from the logistic regression mod- els (following Krizhevsky & Hinton (2009)). A hyperparameter search yielding 0 . 7 as the optimal threshold, along with supervised fine tuning helps increase the best performance in the case of the 7 Published as a conference paper at ICLR 2015 TRec AE to 63 . 8 . The same was not observed in the case of the cAE where the performance went slightly do wn. Thus using the TRec AE followed by supervised fine-tuning with dropout regular - ization yields 64 . 1% accurac y and the cAE with regularization strength of 3 . 0 yields 63 . 9% . T o the best of our knowledge both results beat the current state-of-the-art performance on the permutation in variant CIF AR-10 recognition task (cf., for example, Le et al. (2013)), with the TRec slightly out- performing the cAE. In both cases PCA without whitening w as used as preprocessing. In contrast to Krizhevsk y & Hinton (2009) we do not train on any extra data, so none of these models is provided with any kno wledge of the task beyond the preprocessed training set. 4 . 2 V I D E O DAT A An dataset with very high intrinsic dimensionality are videos that show transforming random dots, as used in Memisevic & Hinton (2010) and subsequent work: each data example is a vectorized video, whose first frame is a random image and whose subsequent frames show transformations of the first frame. Each video is represented by concatenating the vectorized frames into a lar ge vector . This data has an intrinsic dimensionality which is at least as high as the dimensionality of the first frame. So it is very high if the first frame is a random image. It is widely assumed that only bi-linear models, such as Memisevic & Hinton (2010) and related models, should be able to learn useful representations of this data. The interpretation of this data in terms of high intrinsic dimensionality suggests that a simple autoencoder may be able to learn reasonable features, as long as it uses a linear acti vation function so hidden units can span larger regions. W e found that this is indeed the case by training the ZAE on rotating random dots as proposed in Memisevic & Hinton (2010). The ZAE model with 100 hiddens is trained on vectorized 10 -frame random dot videos with 13 × 13 being the size of each frame. Figure 5 depicts filters learned and shows that the model learns to represent the structure in this data by dev eloping phase-shifted rotational Fourier components as discussed in the context of bi-linear models. W e were not able to learn features that were distinguishable from noise with the cAE, which is in line with existing results (eg. Memisevic & Hinton (2010)). Model A verage precision TRec AE 50.4 TLin AE 49.8 covAE Memise vic (2011) 43.3 GRBM T aylor et al. (2010) 46.6 K-means 41.0 contractiv e AE 45.2 Figure 5: T op: Subset of filters learned from rotating random dot movies (frame 2 on the left, frame 4 on the right). Bottom: A verage precision on Hollyw ood2. 8 Published as a conference paper at ICLR 2015 W e then chose activity recognition to perform a quantitati ve ev aluation of this observation. The intrinsic dimensionality of real world movies is probably lower than that of random dot movies, but higher than that of still images. W e used the recognition pipeline proposed in Le et al. (2011); K onda et al. (2014) and ev aluated it on the Hollywood2 dataset Marszałek et al. (2009). The dataset consists of 823 training videos and 884 test videos with 12 classes of human actions. The models were trained on PCA-whitened input patches of size 10 × 16 × 16 cropped randomly from training videos. The number of training patches is 500 , 000 . The number of features is set to 600 for all models. In the recognition pipeline, sub blocks of the same size as the patch size are cropped from 14 × 20 × 20 super-blocks, using a stride of 4 . Each super block results in 8 sub blocks. The concatenation of sub block filter responses is dimensionally reduced by performing PCA to get a super block descriptor , on which a second layer of K-means learns a vocab ulary of spatio-temporal words, that get classified with an SVM (for details, see Le et al. (2011); K onda et al. (2014)). In our experiments we plug the features learned with the different models into this pipeline. The performances of the models are reported in Figure 5 (right). They show that the TRec and TLin autoencoders clearly outperform the more localized models. Surprisingly , they also outperform more sophisticated gating models, such as Memise vic & Hinton (2010). 4 . 3 R E C T I FI E D L I N E A R I N F E R E N C E In previous sections we discussed the importance of (unbiased) rectified linear inference. Here we experimentally show that using rectified linear inference yields the best performance among different inference schemes. W e use a cAE model with a fixed number of hiddens trained on CIF AR-10 images, and ev aluate the performance of 1. Rectified linear inference with bias (the natural preactiv ation for the unit): [ W T X + b ] + 2. Rectified linear inference without bias: [ W T X ] + 3. natural inference: sigmoid( W T X + b ) The performances are sho wn in Figure 1 (right), confirming and extending the results presented in Coates et al. (2011); Saxe et al. (2011). 5 D I S C U S S I O N Quantizing the input space with tiles proportional in quantity to the data density is arguably the best way to represent data giv en enough training data and enough tiles, because it allows us to approx- imate any function reasonably well using only a subsequent linear layer . Ho wever , for data with high intrinsic dimensionality and a limited number of hidden units, we have no other choice than to summarize re gions using responses that are inv ariant to some changes in the input. Inv ariance, from this perspectiv e, is a necessary evil and not a goal in itself. But it is increasingly important for increasingly high dimensional inputs. W e sho wed that linear not affine hidden responses allow us to get in v ariance, because the density defined by a linear autoencoder is a superposition of (possibly very lar ge) regions or subspaces. After a selection is made as to which hidden units are active for a given data example, linear coef- ficients are used in the reconstruction. This is very similar to the way in which gating and square pooling models (eg., Olshausen et al. (2007); Memisevic & Hinton (2007; 2010); Ranzato et al. (2010); Le et al. (2011); Courville et al. (2011)) define their reconstruction: The response of a hid- den unit in these models is defined by multiplying the filter response or squaring it, followed by a non-linearity . T o reconstruct the input, the output of the hidden unit is then multiplied by the filter response itself, making the model bi-linear . As a result, reconstructions are defined as the sum of feature vectors, weighted by linear coefficients of the active hiddens. This may suggest interpreting the fact that these models work well on videos and other high-dimensional data as a result of using linear , zero-bias hidden units, too. 9 Published as a conference paper at ICLR 2015 A C K N O W L E D G M E N T S This work was supported by an NSERC Discov ery grant, a Google faculty research aw ard, and the German Federal Ministry of Education and Research (BMBF) in the project 01GQ0841 (BFNT Frankfurt). R E F E R E N C E S Ba, Jimmy and Frey , Brendan. Adaptiv e dropout for training deep neural networks. In Advances in Neural Information Pr ocessing Systems , pp. 3084–3092, 2013. Boche, Holger, Guillemard, Mijail, Kutyniok, Gitta, and Philipp, Friedrich. Signal recov ery from thresholded frame measurements. In SPIE 8858, W avelets and Sparsity XV , August 2013. Coates, Adam, Lee, Honglak, and Ng, A. Y . An analysis of single-layer networks in unsupervised feature learning. In Artificial Intelligence and Statistics , 2011. Courville, Aaron C, Bergstra, James, and Bengio, Y oshua. A spike and slab restricted boltzmann machine. In International Confer ence on Artificial Intelligence and Statistics , pp. 233–241, 2011. Goroshin, Rotislav and LeCun, Y ann. Saturating auto-encoders. In International Conference on Learning Repr esentations (ICLR2013) , April 2013. Hinton, Geoffre y . A Practical Guide to Training Restricted Boltzmann Machines. T echnical report, University of T oronto, 2010. Hinton, Geof frey E., Srivasta va, Nitish, Krizhe vsky , Alex, Sutsk ever , Ilya, and Salakhutdino v , Ruslan. Improv- ing neural networks by pre venting co-adaptation of feature detectors. CoRR , abs/1207.0580, 2012. Hyv ¨ arinen, Aapo, Karhunen, Juha, and Oja, Erkki. Independent component analysis , volume 46. John W iley & Sons, 2004. Kamyshanska, Hanna and Memisevic, Roland. On autoencoder scoring. In Pr oceedings of the 30th Interna- tional Confer ence on Machine Learning (ICML 2013) , 2013. Kavukcuoglu, Koray , Ranzato, Marc’Aurelio, and LeCun, Y ann. Fast inference in sparse coding algorithms with applications to object recognition. arXiv pr eprint arXiv:1010.3467 , 2010. K onda, Kishore Reddy , Memise vic, Roland, and Michalski, V incent. The role of spatio-temporal synchron y in the encoding of motion. In International Confer ence on Learning Representations (ICLR2014) , 2014. K ovace vic, J. and Chebira, A. An Intr oduction to F rames . Foundations and trends in signal processing. No w Publishers, 2008. Krizhevsk y , Ale x and Hinton, Geof frey . Learning multiple layers of features from tiny images. Master’ s thesis, Department of Computer Science, University of T oronto , 2009. Le, Quoc, Sarlos, T amas, and Smola, Alex. Fastfood - approximating kernel e xpansions in loglinear time. In 30th International Confer ence on Machine Learning (ICML) , 2013. Le, Q.V ., Zou, W .Y ., Y eung, S.Y ., and Ng, A.Y . Learning hierarchical in variant spatio-temporal features for action recognition with independent subspace analysis. In CVPR , 2011. Lee, Honglak, Ekanadham, Chaitanya, and Ng, Andre w . Sparse deep belief net model for visual area v2. In Advances in Neural Information Pr ocessing Systems 20 , 2008. Makhzani, Alireza and Frey , Brendan. k-sparse autoencoders. CoRR , abs/1312.5663, 2013. Marszałek, Marcin, Lapte v , Iv an, and Schmid, Cordelia. Actions in context. In IEEE Confer ence on Computer V ision & P attern Recognition , 2009. Martens, James, Chattopadhyay , Arkadev , Pitassi, T oniann, and Zemel, Richard. On the representational effi- ciency of restricted boltzmann machines. In Neural Information Pr ocessing Systems (NIPS) 2013 , 2013. Memisevic, Roland. Gradient-based learning of higher-order image features. In ICCV , 2011. Memisevic, Roland and Hinton, Geof frey . Unsupervised learning of image transformations. In CVPR , 2007. 10 Published as a conference paper at ICLR 2015 Memisevic, Roland and Hinton, Geoffre y E. Learning to represent spatial transformations with factored higher- order boltzmann machines. Neural Computation , 22(6):1473–1492, June 2010. ISSN 0899-7667. Olshausen, Bruno, Cadieu, Charles, Culpepper, Jack, and W arland, David. Bilinear models of natural images. In SPIE Pr oceedings: Human V ision Electronic Ima ging XII , San Jose, 2007. Ranzato, M, Huang, Fu Jie, Boureau, Y -L, and LeCun, Y ann. Unsupervised learning of in variant feature hierarchies with applications to object recognition. In Computer V ision and P attern Recognition, 2007. CVPR’07. IEEE Confer ence on , pp. 1–8. IEEE, 2007. Ranzato, Marc’Aurelio, Krizhevsk y , Alex, and Hinton, Geoffre y E. Factored 3-W ay Restricted Boltzmann Machines For Modeling Natural Images. In Artificial Intelligence and Statistics , 2010. Razvan Pascanu, Guido Montufar, Y oshua Bengio. On the number of inference regions of deep feed forw ard networks with piece-wise linear acti vations. CoRR , arXi v:1312.6098, 2014. Rifai, Salah, V incent, P ascal, Muller , Xavier , Glorot, Xavier , and Bengio, Y oshua. Contracti ve Auto-Encoders: Explicit In variance During Feature Extraction. In ICML , 2011. Rozell, Christopher J, Johnson, Don H, Baraniuk, Richard G, and Olshausen, Bruno A. Sparse coding via thresholding and local competition in neural circuits. Neural computation , 20(10):2526–2563, 2008. Saxe, Andrew , K oh, Pang W ei, Chen, Zhenghao, Bhand, Maneesh, Suresh, Bipin, and Ng, Andrew . On random weights and unsupervised feature learning. In Pr oceedings of the 28th International Confer ence on Machine Learning , 2011. T aylor , Graham W ., Fergus, Rob, LeCun, Y ann, and Bregler , Christoph. Con volutional learning of spatio- temporal features. In Pr oceedings of the 11th Eur opean confer ence on Computer vision: P art VI , ECCV’10, 2010. V incent, P ascal, Larochelle, Hugo, Bengio, Y oshua, and Manzagol, Pierre-Antoine. Extracting and composing robust features with denoising autoencoders. In Pr oceedings of the 25th international confer ence on Machine learning , 2008. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment