다중과제 평균 추정의 새로운 패러다임
본 논문은 여러 독립 데이터셋의 평균을 동시에 추정하기 위한 다중과제 평균(Multi‑Task Averaging, MTA) 방법을 제안한다. MTA는 각 과제의 최대우도 평균을 가중합한 형태의 볼록 조합으로, 정규화된 손실과 그래프 라플라시안 기반의 과제 유사도 정규화를 결합한다. 저자는 최소 위험 추정량과 최소극대(minimax) 추정량을 이론적으로 도출하고, 닫힌 형태의 해 Y* = (I+γ Σ L)⁻¹ Ȳ를 제시한다. 실험 결과는 MTA가…
저자: Sergey Feldman, Bela A. Frigyik, Maya R. Gupta
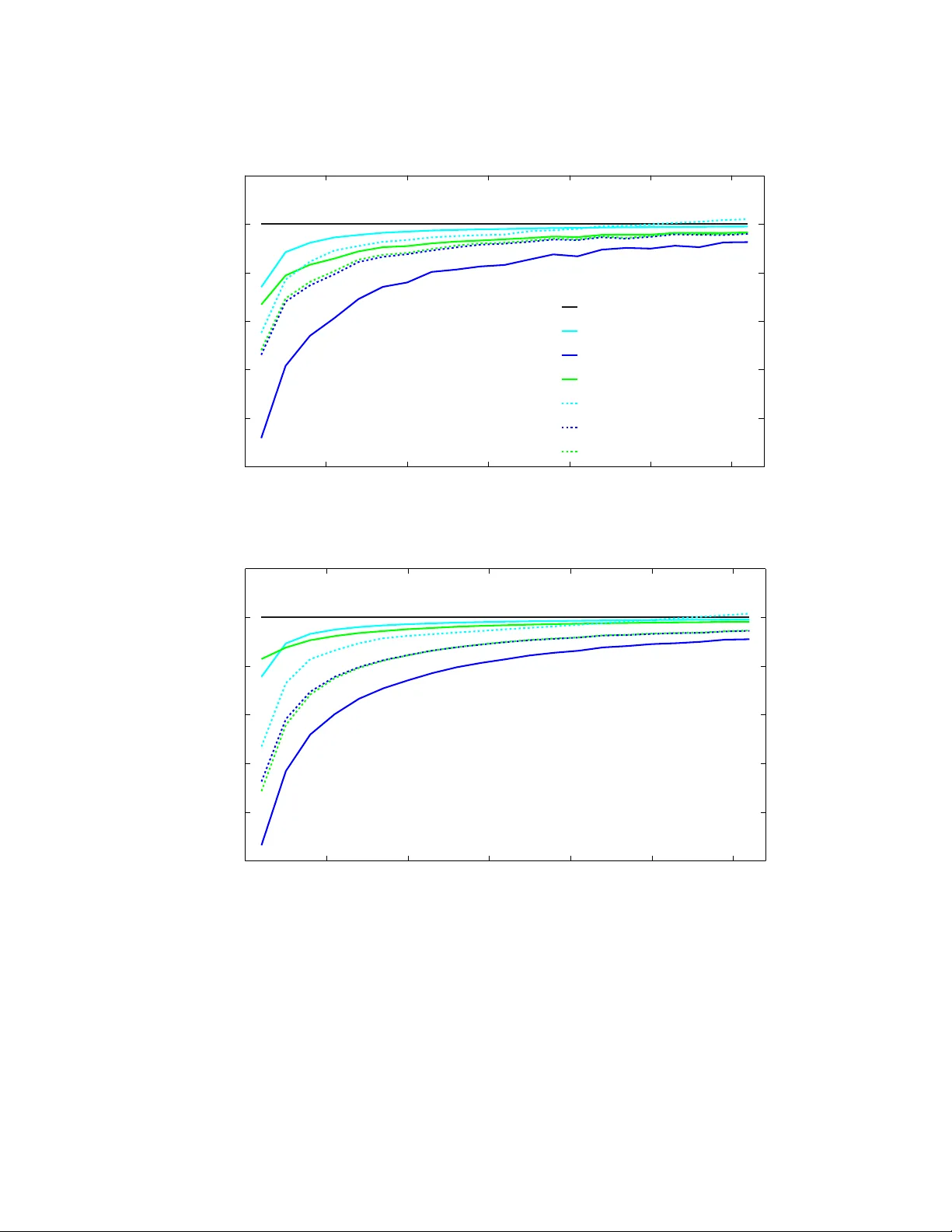
본 논문은 “다중과제 평균(Multi‑Task Averaging, MTA)”이라는 새로운 방법론을 제시하여, 여러 독립적인 데이터셋의 평균을 동시에 추정하는 문제를 다중과제 학습 관점에서 해결한다. 서론에서는 Stein의 역설을 언급하며, 독립적인 정규분포들의 평균을 각각 추정하는 전통적인 최대우도(MLE) 방식이 위험(risk) 측면에서 비효율적일 수 있음을 강조한다. 이러한 배경에서 MTA는 각 과제의 샘플 평균을 단순히 사용하지 않고, 과제 간 유사도 정보를 활용해 전체 위험을 최소화한다는 목표를 갖는다.
2절에서는 MTA의 수식적 정의를 제시한다. T개의 과제 각각에 대해 Nₜ개의 i.i.d. 표본 Y_{ti} 가 주어지고, 각 과제의 분산 σₜ² 를 이용해 정규화된 제곱오차를 구성한다. 과제 간 유사도 행렬 A (대각 원소는 0)와 라플라시안 L = D − A 를 도입해 정규화된 라플라시안 정규화 항 γ∑_{r,s}A_{rs}(ĤY_r−ĤY_s)² 을 추가한다. γ는 정규화 강도를 조절하는 하이퍼파라미터이며, σₜ²에 따라 각 과제의 손실이 스케일링된다.
3절에서는 관련 연구를 검토한다. James‑Stein 추정은 동일한 분산을 가정하고 평균을 0으로 수축시키는 방식으로, MTA와는 달리 수축 대상이 고정돼 있다. 다중과제 학습 분야에서는 회귀·분류·특징 선택에 초점을 맞춘 방법들이 많으며, 평균 추정에 직접 적용하기엔 부적합한 경우가 많다. 특히 그래프 라플라시안 기반의 매니폴드 정규화와의 유사성을 강조하면서, MTA는 각 과제에 대한 상수 함수(평균)만을 학습한다는 점에서 차별화된다.
4절에서는 이론적 분석을 전개한다. 대칭 A 와 비음수 원소를 가정하면 목적함수는 볼록하고 미분 가능함을 증명한다. 최적 해는
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기