Multi-Task Averaging
We present a multi-task learning approach to jointly estimate the means of multiple independent data sets. The proposed multi-task averaging (MTA) algorithm results in a convex combination of the single-task maximum likelihood estimates. We derive th…
Authors: Sergey Feldman, Bela A. Frigyik, Maya R. Gupta
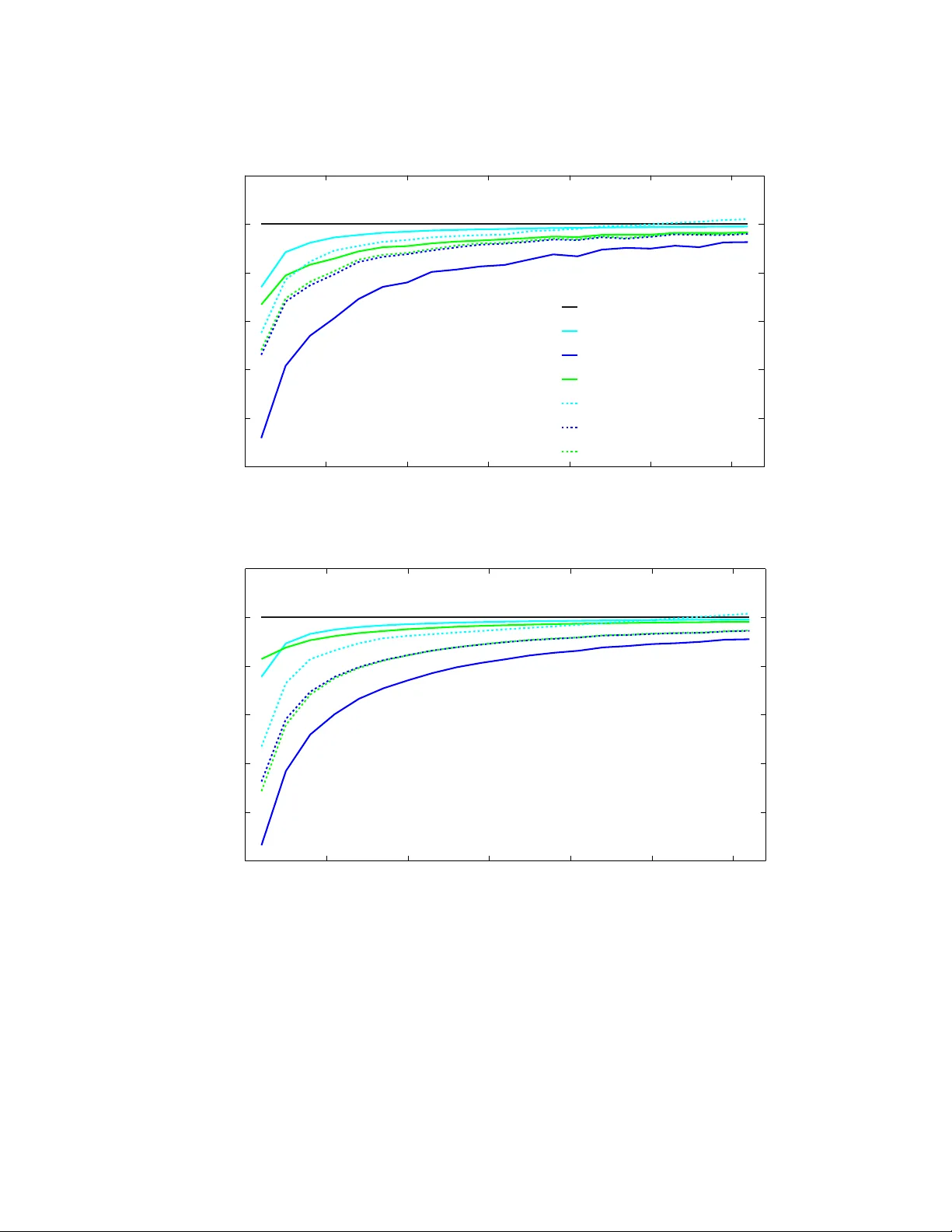
Journal of Machine Learning Research 1 (2012) 1-2 Submitted 9/12; Published - Multi-T ask Av eraging Sergey F eldman sergeyf@u.w ashington.edu Dept. of Ele ctric al Engine ering University of Washington Se attle, W A 98195, USA Ma y a R. Gupta ma y agupt a@google.com Go o gle R ese ar ch Go o gle 1225 Charleston R d Mountain View, CA 94301, USA Bela A. F rigyik frigyik@gmail.com Institute of Mathematics and Informatics University of P ´ ecs H-7624 P ´ ecs, Ifj´ us´ ag St. 6, Hungary Editor: Abstract W e present a m ulti-task learning approac h to jointly estimate the means of multiple in- dep enden t data sets. The proposed multi-task av eraging (MT A) algorithm results in a con vex com bination of the single-task maxim um likelihoo d estimates. W e derive the opti- mal minimum risk estimator and the minimax estimator, and sho w that these estimators can be efficiently estimated. Simulations and real data experiments demonstrate that MT A estimators often outp erform both single-task and James-Stein estimators. Keyw ords: m ulti-task learning, James-Stein estimators, Stein phenomenon, kernel den- sit y estimation 1. In tro duction The motiv ating h yp othesis b ehind m ulti-task learning (MTL) algorithms is that leverag- ing data from related tasks can yield sup erior performance ov er learning from each task indep enden tly . Early evidence for this hypothesis is Stein’s work on the estimation of the means of T distributions (tasks) (Stein, 1956). Stein show ed that it is b etter (in a summed squared error sense) to estimate eac h of the means of T Gaussian random v ariables using data sampled from all of them, even if the random v ariables are indep enden t and hav e differen t means. That is, it is b eneficial to consider samples from seemingly unr elate d dis- tributions in the estimation of the t th mean. This surprising result is often referred to as Stein ’s p ar adox (Efron and Morris, 1977). Mean estimation is p erhaps the most common of all estimation tasks, and often multiple means need to b e estimated. In this work we consider a multi-task regularization approac h to the problem of estimating multiple means, which we call multi-task aver aging (MT A). c 2012 F eldman et al.. Feldman et al. T able 1: Key Notation T n umber of tasks N t n umber of samples for t th task Y ti ∈ R i th random sample from t th task ¯ Y t ∈ R sample av erage for t th task: 1 N t P i Y ti ¯ Y ∈ R T v ector with t th comp onen t ¯ Y t Y ∗ t ∈ R MT A estimate of t th mean Y ∗ ∈ R T v ector with t th comp onen t Y ∗ t σ 2 t v ariance of the t th mean Σ diagonal cov ariance matrix of ¯ Y with Σ tt = σ 2 t N t A ∈ R T × T pairwise task similarity matrix L = D − A graph Laplacian of A , with diagonal D s.t. D tt = P T r =1 A tr W MT A solution matrix, W = ( I + γ T Σ L ) − 1 W e show that MT A has prov ably nice theoretical prop erties, is effective in practice, and is computationally efficient. W e define the MT A ob jective in Section 2, and review related work in Section 3. W e presen t some k ey properties of MT A in Section 4; in particular, we deriv e the optimal amoun t of regularization to b e used, and show that this optimal amoun t can b e effectiv ely estimated. Sim ulations in Section 5 v erify the adv an tage of MT A o ver standard sample means and James-Stein estimation if the true means are close compared to the v ariance. Tw o applications, (i) estimating exp ected sales and (ii) estimating final class grades, show that MT A can reduce real errors by o ver 30%, as rep orted in Sections 6.2 and 6.1. MT A can b e used anywhere multiple a verages are needed; w e demonstrate this by applying it fruitfully to the av eraging in kernel densit y estimation in Section 6.3. 2. Multi-T ask Averaging Consider the problem of estimating the means of T random v ariables that hav e finite mean and v ariance, whic h is a T -task problem from a multi-task learning persp ectiv e. Let { Y ti } N t i =1 b e N t indep enden t and identically distributed (iid) random samples for task t = 1 , . . . , T . Other k ey notation is in T able 1. Assume that the T × T matrix A describ es the relatedness or similarit y of an y pair of the T tasks, with A tt = 0 for all t without loss of generality (b ecause the diagonal self-similarity terms are canceled in the ob jective b elow). The prop osed MT A ob jective is { Y ∗ t } T t =1 = arg min { ˆ Y t } T t =1 1 T T X t =1 N t X i =1 ( Y ti − ˆ Y t ) 2 σ 2 t + γ T 2 T X r =1 T X s =1 A rs ( ˆ Y r − ˆ Y s ) 2 . (1) The first term of (1) minimizes the m ulti-task empirical loss, and the second term jointly regularizes the estimates (i.e. ties them together). The regularization parameter γ balances 2 Mul ti-T ask A veraging the empirical risk and the multi-task regularizer. Note that if γ = 0, the MT A ob jective decomp oses into T separate minimization problems, pro ducing the sample av erages ¯ Y t . The normalization of each error term in (1) by its task-sp ecific v ariance σ 2 t (whic h may b e estimated) scales the T empirical loss terms relative to the v ariance of their distribution; this ensures that high-v ariance tasks do not disprop ortionately dominate the loss term. A more general formulation of MT A is { Y ∗ t } T t =1 = arg min { ˆ Y t } T t =1 1 T T X t =1 N t X i =1 L ( Y ti , ˆ Y t ) + γ J { ˆ Y t } T t =1 , where L is some loss function and J is a regularization function. If L is chosen to b e any Bregman loss, then setting γ = 0 will pro duce the T sample a v erages (Banerjee et al., 2005). F or the analysis and exp eriments in this pap er, w e restrict our fo cus to the tractable squared-error form ulation giv en in (1). The MT A ob jectiv e and man y of the results in this pap er generalize trivially to samples that are v ectors rather than scalars, but for notational simplicit y we restrict our fo cus to scalar samples Y ti ∈ R . The task similarit y matrix A can b e sp ecified as side information (e.g. from a domain exp ert), but often this side information is not av ailable, or it may not be clear how to con vert seman tic notions of task similarity in to an appropriate choice for the task-similarit y v alues in A . In Section 4, w e derive t wo optimal c hoices of A for the T = 2 case: the A that minimizes exp ected squared error, and a minimax A . W e use the T = 2 analysis to prop ose practical estimators of A for any num b er of tasks. 3. Related W ork In this section, we review related and bac kground material: James-Stein estimation, m ulti- task learning, manifold regularization, and the graph Laplacian. 3.1 James-Stein Estimation A closely related b o dy of work to MT A is Stein estimation, an empirical Ba yes strategy for estimating multiple means sim ultaneously (James and Stein, 1961; Bo ck, 1975; Efron and Morris, 1977; Casella, 1985). James and Stein (1961) show ed that the maximum likelihoo d estimate of µ t can b e dominated b y a shrink age estimate giv en Gaussian assumptions. Sp ecifically , given a single sample dra wn from T normal distributions Y t ∼ N ( µ t , σ 2 ) for t = 1 , . . . , T , Stein sho wed that the maxim um lik eliho o d estimator ¯ Y t = Y t is inadmissible, and is dominated by the James-Stein estimator: ˆ Y J S t = 1 − ( T − 2) σ 2 ¯ Y T ¯ Y ¯ Y t , (2) where ¯ Y is a v ector with t th entry ¯ Y t . The ab ov e estimator dominates ¯ Y t when T > 2. F or T = 2, (2) rev erts to the maximum likelihoo d estimator, which turns out to b e admissible (Stein, 1956). James and Stein (James and Stein, 1961; Casella, 1985) sho wed that if σ 2 is unkno wn it can b e replaced by a standard unbiased estimate ˆ σ 2 . Note that in (2) the James-Stein estimator shrinks the maximum lik eliho o d estimates to wards zero (the terms “regularization” and “shrink age” are often used interc hangeably). 3 Feldman et al. The form of (2) and its shrink age to wards zero p oints to the implicit assumption that the µ t are drawn from a standard normal distribution centered at 0. More generally , the means are assumed to b e dra wn as µ t ∼ N ( ξ , 1). The James-Stein estimator then b ecomes ˆ Y J S t = ξ + 1 − ( T − 3) σ 2 ( Y − ξ ) T ( Y − ξ ) ( ¯ Y t − ξ ) , (3) where ξ can b e estimated (as w e do in this w ork) as the a verage of means ξ = ¯ ¯ Y = 1 T P T r =1 ¯ Y r , and this additional estimation decreases the degrees of freedom b y one 1 . There hav e b een a n umber of extensions to the original James-Stein estimator. Through- out this work, w e compare to the w ell-regarded p ositiv e-part James-Stein estimator for m ul- tiple data p oints p er task and indep enden t unequal v ariances (Bo c k, 1975; Lehmann and Casella, 1998). In particular, let Y ti ∼ N ( µ t , σ 2 t ) for t = 1 , . . . , T and i = 1 , . . . , N t , let Σ b e the co v ariance matrix of ¯ Y , the vector of task sample means, and let λ max (Σ) b e the largest eigenv alue of Σ. The James-Stein estimator given in (3) is itself is not admissible, and is dominated b y the p ositive part James -Stein estimator (Lehmann and Casella, 1998), whic h is further theoretically improv ed b y Bo ck’s James-Stein estimator (Bo ck, 1975): ˆ Y J S t = ξ + 1 − tr (Σ) λ max (Σ) − 3 ( ¯ Y − ξ ) T Σ − 1 ( ¯ Y − ξ ) + ( ¯ Y t − ξ ) , (4) where ( x ) + = max(0 , x ). The term tr (Σ) λ max is called the effe ctive dimension of the estimator. In sim ulations where we set the true co v ariance matrix to be Σ and then estimated the effective dimension b y estimating the maximum eigen v alue and trace of the sample cov ariance matrix, w e found that replacing the effectiv e dimension with the actual dimension T (when Σ is diagonal) resulted in a significan t p erformance b o ost for Bo ck’s James-Stein estimator. F or the case of a diagonal Σ, there are T separate distributions, thus the effective dimension is exactly T . In other preliminary experiments with real data, w e also found that using T rather than the effectiv e dimension performed b etter due to the high v ariance of the estimated maxim um eigen v alue in the denominator of the effectiv e dimension. Consequen tly , in the exp erimen ts in this pap er, when we compare to James-Stein estimation, we compare to (4) using T for the effective dimension. 3.2 Multi-T ask Learning for Mean Estimation MT A is an approac h to the problem of estimating T means. W e are not a ware of other w ork in the m ulti-task literature that addresses this problem explicitly; most MTL metho ds are designed for regression, classification, or feature selection, e.g. Micchelli and Pon til (2004); Bonilla et al. (2008); Argyriou et al. (2008). Estimating T means can b e considered a sp ecial case of multi-task regression 2 , where one fits a constan t function to each task. And, similarly to MT A, one of the main approaches to multi-task regression in literature is tying tasks together with an explicit m ulti-task parameter regularizer. 1. F or more details as to why T − 2 in (2) becomes T − 3 in (3) see Example 7.7 on page 278 of Lehmann and Casella (1998). 2. With a feature space of zero dimensions, only the constant offset term is learned. 4 Mul ti-T ask A veraging Ab erneth y et al. (2009), for instance, prop ose to minimize the empirical loss with the follo wing added regularizer, || β || ∗ , where the t th column of the matrix β is the vector of parameters for the t th task and || · || ∗ is the trace norm. F or mean estimation, the matrix β has only one row, and its trace norm has little meaning. Argyriou et al. (2008) propose an alternating approach with a differen t regularizer, tr ( β T D − 1 β ) , where D is a learned, shared fe atur e cov ariance matrix. Again, with no features, D is just a constan t. The regularizers in the w ork of Jacob et al. (2008) and Zhang and Y eung (2010) are similarly inappropriate when in the context of mean estimation. The most closely related work is that of Sheldon (2008) and Kato et al. (2008), where the regularizer or constraint, resp ectiv ely , is T X r =1 T X s =1 A rs k β r − β s k 2 2 , whic h is the MT A regularizer when p erforming mean estimation. 3.3 Multi-T ask Learning and the Similarit y Betw een T asks A k ey issue for MT A and many other m ulti-task learning metho ds is ho w to estimate some notion of similarity (or task relatedness) b etw een tasks and/or samples if it is not pro vided. A common approac h is to estimate the similarity matrix join tly with the task parameters (Argyriou et al., 2007; Xue et al., 2007; Bonilla et al., 2008; Jacob et al., 2008; Zhang and Y eung, 2010). F or example, Zhang and Y eung (2010) assume that there exists a cov ariance matrix for the task relatedness, and prop osed a conv ex optimization approach to estimate the task co v ariance matrix and the task parameters in a joint, alternating w ay . Applying suc h join t and alternating approaches to the MT A ob jective given in (1) leads to a degenerate solution with zero similarity . Ho wev er, the simplicity of MT A enables us to sp ecify the optimal task similarity matrix for T = 2 (see Sec. 4), which we use to obtain a n umber of closed-form estimators for the general T > 1 case. 3.4 Manifold Regularization MT A is similar in form to manifold r e gularization (Belkin et al., 2006). F or example, Belkin et al.’s Laplacian-regularized least squares ob jective for semi-supervised regression solv es arg min f ∈H P N i =1 ( y i − f ( x i )) 2 + λ || f || 2 H + γ P N + M i,j =1 A ij ( f ( x i ) − f ( x j )) 2 , where f is the regression function to be estimated, H is a reproducing kernel Hilb ert space (RKHS), N is the n umber of labeled training samples, M is the n umber of unlabeled training samples, A ij is the similarit y (or w eight in an adjacency graph) betw een feature samples x i and x j , and || f || H is the norm of the function f in the RKHS. In MT A, as opposed 5 Feldman et al. to manifold regularization, we are estimating a different function (that is, the constant function that is the mean) for each of the T tasks, rather than a single global function. One can in terpret MT A as regularizing the individual task estimates ov er the task-similarity manifold, which is defined for the T tasks b y the T × T matrix A . 3.5 Bac kground on the Graph Laplacian Matrix It will b e helpful for later sections to review the graph Laplacian matrix. F or graph G with T no des, let A ∈ R T × T b e a matrix where comp onent A rs ≥ 0 is the w eight of the edge b etw een no de r and no de s , for all r, s . The gr aph L aplacian matrix is defined as L = L ( A ) = D − A , with diagonal matrix D suc h that D tt = P s A ts . The graph Laplacian matrix is analogous to the Laplacian op erator ∆ g ( x ) = tr ( H ( g ( x ))) = ∂ 2 g ( x ) ∂ x 2 1 + ∂ 2 g ( x ) ∂ x 2 2 + . . . + ∂ 2 g ( x ) ∂ x 2 M , which quan tifies ho w lo cally smo oth a twice-differen tiable func- tion g ( x ) is. Similarly , the graph Laplacian matrix L can b e though t of as b eing a measure of the smo othness of a function defined on a graph (Chung, 2004). Given a function f defined ov er the T no des of graph G , where f i ∈ R is the function v alue at no de i , the total ener gy of a graph is (for symmetric A ) E ( f ) = 1 2 T X i =1 T X j =1 A ij ( f i − f j ) 2 = f T L ( A ) f , whic h is small when f is smooth o ver the graph (Zhu and Laffert y, 2005). If A is asymmetric then the energy can be written as E ( f ) = 1 2 T X i =1 T X j =1 A ij ( f i − f j ) 2 = f T L (( A + A T ) / 2) f . Note that the ab ov e form ulation of the energy in terms of the graph Laplacian holds for the scalar case. More generally , when eac h f i ∈ R d is a vector, one can alternatively write the energy in terms of the distance matrix: E ( f ) = 1 2 tr (∆ T A ) , where ∆ ij = ( f i − f j ) T ( f i − f j ) As discussed ab o ve, the graph Laplacian can be thought of as an operator on a function, but it is useful in and of itself (i.e. without a function). The eigenv alues of the graph Laplacian are all real and non-negativ e, and there is a w ealth of literature showing how the eigen v alues rev eal the structure of the underlying graph (Ch ung, 2004); the eigenv alues of L are particularly useful for sp ectral clustering (v. Luxburg, 2007). The graph Laplacian is a common to ol in semi-sup ervised learning literature (Zhu, 2006), and the Laplacian of a random w alk probability matrix P (i.e. all the entries are non-negative and the rows sum to 1) is also of interest. F or example, Saerens et al. (Saerens et al., 2004) show ed that the pseudo-in verse of the Laplacian of a probability transition matrix is used to compute the square ro ot of the av erage comm ute time (the av erage time taken b y a random walk er on graph G to reach no de j for the first time when starting at node i , and coming bac k to no de i ). 6 Mul ti-T ask A veraging 4. MT A Theory W e derive a closed-form solution for A and v arious prop erties. Pro ofs and deriv ations are in the app endix. 4.1 Closed-form MT A Solution F or symmetric A with non-negativ e comp onents 3 , the MT A ob jectiv e giv en in (1) is con- tin uous, differentiable, and con vex; and (1) has closed-form solution: Y ∗ = I + γ T Σ L − 1 ¯ Y (5) where ¯ Y is the vector of sample a verages with t th entry ¯ Y t = 1 N t P N t i =1 Y ti , L is the graph Laplacian of A , and Σ is the diagonal cov ariance matrix of the sample mean vector ¯ Y such that Σ tt = σ 2 t N t . The in verse I + γ T Σ L − 1 alw ays exists: Lemma 1 Assume that 0 ≤ A rs < ∞ for al l r, s , γ ≥ 0 , and 0 < σ 2 t N t < ∞ for al l t . The MT A solution matrix W = I + γ T Σ L − 1 exists. Note that the ( r , s )th en try of γ T Σ L go es to 0 as N t approac hes infinity , and since matrix in version is a con tinuous op eration, I + γ T Σ L − 1 → I in the norm. By the la w of large n umbers one can conclude that Y ∗ asymptotically approaches the true mean µ . MT A can also b e applied to vectors. Let ¯ Y ∗ ∈ R T × d b e a matrix with Y ∗ t as its t th ro w and let ¯ Y ∈ R T × d b e a matrix with ¯ Y t ∈ R d as its t th row. One can simply p erform MT A on the vectorized form of Y ∗ . 4.2 Regularized Laplacian Kernel The MT A solution matrix W = I + γ T Σ L − 1 is similar to the r e gularize d L aplacian kernel (RLK): Q = ( I + γ L ) − 1 , introduced b y Smola and Kondor (Smola and Kondor, 2003). In the RLK, the graph Laplacian matrix L is assumed to b e symmetric, but the Σ L in the MT A solution matrix is generally not symmetric. The MT A solution matrix therefore generalizes the RLK. Note that the term kernel refers to a p ositive semi-definite matrix used in, for example, supp ort v ector machines (Hastie et al., 2001). The ( r, s )th entry of any kernel matrix can b e interpreted as a similarit y b etw een the r th and s th samples. In this section, we will discuss and motiv ate the kind of similarity that is enco ded by b oth the RLK and the MT A solution matrix W . Cheb otarev and Shamis (Cheb otarev and Shamis, 2006) studied matrices of the form Q = ( I + γ L ) − 1 in the context of answ ering the question “given a graph, how should one ev aluate the proximit y b etw een its v ertices?” They pro ve a num b er of prop erties that lead them to conclude that Q ij is a go o d measure of how ac c essible j is from i when taking all p ossible paths in to accoun t (as opp osed to just the direct path that A ij enco des). In their o wn words, “ Q ij ma y b e interpreted as the fraction of the connectivity of vertices i and j in 3. Using an asymmetric A with MT A is equiv alent to using the symmetric matrix ( A T + A ) / 2. 7 Feldman et al. the total connectivit y of i with all vertices.” The following is a list of in teresting prop erties of Q from the work of Chebotarev and Shamis when A is symmetric and its en tries are “strictly p ositive” (Cheb otarev and Shamis, 2006): • Q exists and has con vex ro ws. • Q ii > Q ij . • T riangle inequalit y: Q ij + Q ik − Q j k ≤ Q ii . • The distance d α ij = α ( Q α ii + Q α j j − Q α ij − Q α j i ) is a v alid metric distance o ver vertices. • Q ij = 0 if and only if there exists no path betw een i and j . F or intuition as to why Q measures connectivit y , consider the follo wing expansion (Berman and Plemmons, 1979): ( I + γ L ) − 1 = ∞ X k =0 ( − γ L ) k . This equality holds only if the righ t-hand side is con vergen t. Thus, the RLK is a t yp e of path coun ting with − L instead of A as the adjacency matrix, where paths of all p ossible lengths are tak en into account, and longer paths are weigh ted: equally ( γ = 1), less hea vily ( γ < 1), or more heavily ( γ > 1). The MT A solution matrix I + γ T Σ L − 1 generalizes the RLK; the diagonal matrix Σ left-m ultiplies the Laplacian, and the RLK is pro duced in the special case that Σ = cI for an y scalar c . Using a differen t approach than Cheb otarev and Shamis, w e will pro ve in the next subsection that the conv exity of the ro ws of W still holds, assuming only non-negativit y of the entries of A (instead of strict p ositivity as in Cheb otarev and Shamis). (W e did not in vestigate whether the other prop erties listed abov e still hold for the MT A solution.) The RLK is one of many p ossible graph kernels. T o find the b est one for a collab orative recommendation task, F ouss et al. (F ouss et al., 2006) empirically compared seven graph k ernels. They found that the best three kernels were the RLK, the pseudo-in verse of L , and the Mark ov diffusion k ernel. Y a jima and Kuo (Y a jima and Kuo, 2006) tested v arious graph k ernels in the context of a one-class SVM for the application of recommendation tasks. They also found that the RLK w as one of the top p erformers. 4.3 Con vexit y of MT A Solution F rom insp ection of (5), it is clear that eac h of the elemen ts of the MT A solution Y ∗ is a linear combination of the single-task sample av erages in ¯ Y . In fact, each MT A estimate is a conv ex com bination of the single-task sample av erages: Theorem If γ ≥ 0 , 0 ≤ A rs < ∞ for al l r, s and 0 < σ 2 t N t < ∞ for al l t , then the MT A estimates { Y ∗ t } given in (5) ar e a c onvex c ombination of the task sample aver ages { ¯ Y t } . 4.4 Analysis of the Tw o T ask Case In this section we analyze the T = 2 task case, with N 1 and N 2 samples for tasks 1 and 2 resp ectiv ely . Supp ose { Y 1 i } are iid with finite mean µ 1 and finite v ariance σ 2 1 , and { Y 2 i } are 8 Mul ti-T ask A veraging iid with finite mean µ 2 = µ 1 + ∆ and finite v ariance σ 2 2 . Let the task-relatedness matrix b e A = [0 a ; a 0], and without loss of generalit y , w e fix γ = 1. Then the closed-form solution (5) can b e simplified: Y ∗ 1 = T + σ 2 2 N 2 a T + σ 2 1 N 1 a + σ 2 2 N 2 a ¯ Y 1 + σ 2 1 N 1 a T + σ 2 1 N 1 a + σ 2 2 N 2 a ¯ Y 2 . (6) The mean squared error of Y ∗ 1 is MSE[ Y ∗ 1 ] = σ 2 1 N 1 T 2 + 2 T σ 2 2 N 2 a + σ 2 1 σ 2 2 N 1 N 2 a 2 + σ 4 2 N 2 2 a 2 ( T + σ 2 1 N 1 a + σ 2 2 N 2 a ) 2 + ∆ 2 σ 4 1 N 2 1 a 2 ( T + σ 2 1 N 1 a + σ 2 2 N 2 a ) 2 . Next, we compare the MT A estimate to the sample av erage ¯ Y 1 , which is the maxim um lik eliho o d estimate of the mean for man y distributions. 4 The MSE of the single-task sample a verage ¯ Y 1 is σ 2 1 N 1 , and thus MSE[ Y ∗ 1 ] < MSE[ ¯ Y 1 ] if ∆ 2 < 4 a + σ 2 1 N 1 + σ 2 2 N 2 , (7) Th us the MT A estimate of the first mean has low er MSE than the sample av erage estimate if the squared mean-separation ∆ 2 is small compared to the summed v ariances of the sample means. See Figure 1 for an illustration. Note that as a approaches 0 from ab ov e, the term 4 /a in (7) approac hes infinity , whic h means that a small amoun t of regularization can b e helpful ev en when the difference b etw een the task means ∆ is large. 4.5 Optimal T ask Relatedness A for T = 2 W e analyze the optimal choice of a in the task-similarity matrix A = [0 a ; a 0]. The risk is the sum of the mean squared errors: R ( µ, Y ∗ ) = MSE[ Y ∗ 1 ] + MSE[ Y ∗ 2 ] , whic h is a conv ex, contin uous, and differen tiable function of a , and therefore the first deriv a- tiv e can b e used to specify the optimal v alue a ∗ , when all the other v ariables are fixed. Minimizing the risk MSE[ Y ∗ 1 ] + MSE[ Y ∗ 2 ] w.r.t. a one obtains the following solution: a ∗ = 2 ∆ 2 , (8) whic h is alw ays non-negativ e, as was assumed. This result is key b ecause it sp ecifies that the optimal task-similarity a ∗ ideally should measure the inv erse of the s quared task mean- difference. F urther, the optimal task-similarit y is independent of the num b er of samples N t or the sample v ariance σ 2 t , as these are accounted for in Σ. Note that a ∗ also minimizes the functions MSE[ Y ∗ 1 ] and MSE[ Y ∗ 2 ], separately . Analysis of the second deriv ative sho ws that this minimizer alwa ys holds for the cases of in terest (that is, for N 1 , N 2 ≥ 1). The effect on the risk of the c hoice of a and the optimal a ∗ 9 Feldman et al. 0 0.5 1 1.5 2 2.5 −30 −20 −10 0 10 20 30 mean of the second task % change in risk vs. single−task Single−Task MTA, N = 2 MTA, N = 10 MTA, N = 20 Figure 1: Plot shows the p ercent change in av erage risk for tw o tasks (a veraged ov er 10,000 runs of the sim ulation). F or eac h task there are N IID samples, for N = 2 , 10 , 20. The first task generates samples from a standard Gaussian. The second task generates samples from a Gaussian with σ 2 = 1 and v arying mean v alue, as mark ed on the x-axis. The symmetric task-relatedness v alue w as fixed at a = 1 (note this is generally not the optimal v alue). One sees that giv en N = 2 samples from each Gaussian, the MT A estimate is b etter if the Gaussians are closer than 2 units apart. Given N = 20 samples from each Gaussian, the MT A estimate is b etter if the Gaussians are closer than 1.5 units apart. In the extreme case that the tw o Gaussians hav e the same mean ( µ 1 = µ 2 = 0), then with this suboptimal choice of a = 1, MT A provides a 20% win for N = 2 samples, and a 5% win for N = 20 samples. is illustrated in Figure 2. The optimal t wo-task similarity giv en in (8) requires knowledge of the true means µ 1 and µ 2 . These are, in practice, unav ailable. What similarity should b e used then? A straightforw ard approac h is to use single-task estimates instead: ˆ a ∗ = 2 ( ¯ y 1 − ¯ y 2 ) 2 , And to use maxim um likelihoo d estimates ˆ σ 2 t to form the matrix ˆ Σ. This data-dep endent approac h is analogous to empirical Bay esian metho ds in whic h prior parameters are esti- mated from data (Casella, 1985). 4. The uniform distribution is p erhaps the simplest example where the sample av erage is not the maximum lik eliho o d estimate of the mean. F or more examples, see Sec. 8.18 of Romano and Siegel (1986). 10 Mul ti-T ask A veraging 0 2 4 6 8 10 0 0.2 0.4 0.6 0.8 1 task relatedness value risk MTA, N = 2 MTA, N = 10 MTA, N = 20 Figure 2: Plot sho ws the risk for t wo tasks, where the task samples were drawn IID from Gaussians N (0 , 1) and N (1 , 1). The task-relatedness v alue a was v aried as sho wn on the x-axis. The minimum exp ected squared error is mark ed by a ∗ , is indep endent of N and matches the optimal task- relatedness v alue given by (8). 4.6 Estimating A from Data for Arbitrary T Based on our analysis in the preceding sections of the optimal A for the tw o-task case, we prop ose t wo metho ds to estimate A from data for arbitrary T > 1. The first metho d is designed to minimize the approximate risk using a constant similarit y matrix. The second metho d provides a minimax estimator. With b oth metho ds one can take adv an tage of the Sherman-Morrison form ula (Sherman and Morrison, 1950) to a void taking the matrix in verse or solving a set of linear equations in (5), resulting in an O ( T ) computation time for Y ∗ . 4.6.1 Const ant MT A Recalling that E [ ¯ Y ¯ Y T ] = µµ T + Σ, the risk of estimator ˆ Y = W ¯ Y of unknown parameter v ector µ for the squared loss is the sum of the mean squared errors: R ( µ, W ¯ Y ) = E [( W ¯ Y − µ ) T ( W ¯ Y − µ )] = tr ( W Σ W T ) + µ T ( I − W ) T ( I − W ) µ. (9) One approach to generalizing the results of Section 4.4 to arbitrary T is to try to find a symmetric, non-negative matrix A suc h that the (conv ex, differen tiable) risk R ( µ, W ¯ Y ) is 11 Feldman et al. minimized for W = I + γ T Σ L − 1 (recall L is the graph Laplacian of A ). The problem with this approach is t wo-fold: (i) the solution is not analytically tractable for T > 2 and (ii) an arbitrary A has T ( T − 1) degrees of freedom, which is considerably more than the num b er of means w e are trying to estimate in the first place. T o a void these problems, w e generalize the tw o-task results by constraining A to b e a scaled constan t matrix A = a 11 T , and find the optimal a ∗ that minimizes the risk in (9). In addition, w.l.o.g. we set γ to 1, and for analytic tractabilit y w e assume that all the tasks ha ve the same v ariance, estimating Σ as tr (Σ) T I . Then it remains to solve: a ∗ = arg min a R µ, I + 1 T tr (Σ) T L ( a 11 T ) − 1 ¯ Y ! , whic h has the solution a ∗ = 2 1 T ( T − 1) P T r =1 P T s =1 ( µ r − µ s ) 2 , whic h reduces to the optimal t wo task MT A solution (8) when T = 2. In practice, one of course do es not hav e { µ r } as these are precisely the v alues one is trying to estimate. So, to estimate a ∗ w e use the sample means { ¯ y r } : ˆ a ∗ = 2 1 T ( T − 1) P T r =1 P T s =1 ( ¯ y r − ¯ y s ) 2 . Using this optimal estimated c onstant similarity and an estimated co v ariance matrix ˆ Σ pro duces what we refer to as the c onstant MT A estimate Y ∗ = I + γ T ˆ Σ L (ˆ a ∗ 11 T ) − 1 ¯ Y . (10) Note that w e made the assumption that the entries of Σ w ere the same in order to b e able to compute the constant similarit y a ∗ , but w e do not need nor suggest that assumption when using a ∗ in (10). T o compute this estimate one needs the diagonal matrix Σ, which in practice also m ust b e estimated. 4.6.2 Minimax MT A Bo c k’s James-Stein estimator is minimax , that is, it minimizes the w orst-case loss, and not necessarily the exp ected risk (Lehmann and Casella, 1998). This leads to a more conserv ative use of regularization. In this section, we derive a minimax version of MT A for arbitrary T that prescrib es less regularization than constant MT A. F ormally , an estimator Y M of µ is called minimax if it minimizes the maxim um risk: inf ˆ Y sup µ R ( µ, ˆ Y ) = sup µ R ( µ, Y M ) . Let r ( π , ˆ Y ) b e the a verage risk of estimator ˆ Y w.r.t. a prior π ( µ ) suc h that r ( π , ˆ Y ) = R R ( µ, ˆ Y ) π ( µ ) dµ . The Ba yes estimator Y π is the estimator that minimizes the a verage risk, 12 Mul ti-T ask A veraging and the Bay es risk r ( π , Y π ) is the a verage risk of the Bay es estimator. A prior distribution π is called least fa vorable if r ( π , Y π ) > r ( π 0 , Y π 0 ) for all priors π 0 . First, we will sp ecify minimax MT A for the T = 2 case. T o find a minimax estimator Y M it is sufficien t to show that (i) Y M is a Ba yes estimator w.r.t. the least fav orable prior (LFP) and (ii) it has constant risk (Lehmann and Casella, 1998). T o find a LFP , we first need to specify a constrain t set for µ t : w e use an in terv al: µ t ∈ [ b l , b u ] , for all t , where b l ∈ R and b u ∈ R . With this constraint set the minimax estimator is (see app endix for details): Y M = I + 2 γ T ( b u − b l ) 2 Σ L ( 11 T ) − 1 ¯ Y , whic h reduces to (8) when T = 2. This minimax analysis is only v alid for the case when T = 2, but w e found that the follo wing extension of minimax MT A to larger T w ork ed w ell in simulations and applications for any T ≥ 2. T o estimate b u and b l from data we assume the unkno wn T means are drawn from a uniform distribution and use maxim um lik eliho o d estimates of the low er and upp er endpoints for the supp ort: ˆ b l = min t ¯ y t and ˆ b u = max t ¯ y t . Th us, in practice, minimax MT A is Y M = I + 2 γ T ( ˆ b u − ˆ b l ) 2 ˆ Σ L ( 11 T ) ! − 1 ¯ Y , 4.6.3 Comput a tional Efficiency of Const ant and Minimax MT A Both the constant MT A and minimax MT A weigh t matrices can b e written as ( I + c Σ L ( 11 T )) − 1 = ( I + c Σ( T I − 11 T )) − 1 = ( I + cT Σ − c Σ 11 T ) − 1 = ( Z − x 1 T ) − 1 , where c is different for constant MT A and minimax MT A, Z = I + cT Σ, x = c Σ 1 . The ma- trix Z is diagonal (since Σ is diagonal), and thus the Sherman-Morrison form ula (Sherman and Morrison, 1950) can be used to find the inv erse: ( Z − x 1 T ) − 1 = Z − 1 + Z − 1 x 1 T Z − 1 1 + 1 T Z − 1 x . Since Z is diagonal, Z − 1 can b e computed in O ( T ) time, and so can Z − 1 x . Thus, the entire computation W ¯ Y can b e done in O ( T ) time for constan t MT A and minimax MT A. 4.7 Generalit y of Matrices of MT A F orm Figure 3 is a visual summary of the sets of estimators of type ˆ Y = W ¯ Y , where W is a T × T matrix. The pink region represen ts estimators of the form ˆ Y = W ¯ Y , with right-stochastic W . MT A estimators are all within the green region, and man y w ell-known estimators 13 Feldman et al. (suc h as the James-Stein Estimator and its v arian ts) fall within the purple region. In this section we will pro ve that the purple region is a strict subset of the the green region with a prop osition. In other words, w e will show that MT A generalizes many estimators of interest, suc h as estimators that regularize single-task estimates of the mean to the po oled mean or the av erage of means. ^ Y = W ¹ Y ^ Y = W ¹ Y r i g h t s t o c h a s t i c W ^ Y = W ¹ Y W = ( I + ¡ L ( A ) ) ¡ 1 d i a g o n a l ¡ w i t h ¡ t t ¸ 0 A r s ¸ 0 ^ Y t = 1 ° ¹ Y t + P T r = 1 ® r ¹ Y r P T r = 1 ® r = 1 ¡ 1 ° 0 < 1 ° · 1 ® r ¸ 0 Figure 3: An illustration of the set membership prop erties of v arious estimators of the type ˆ Y = W ¯ Y . Sp ecifically , the prop osition will establish that familiar regularized estimates of µ can b e rewritten in MT A form for sp ecific c hoices of (or assumptions ab out) A , γ , and Σ. Note that the cov ariance Σ is also a “choice” be cause some classic estimators assume Σ = I . First, recall the MT A solution: Y ∗ = I + γ T Σ L − 1 ¯ Y . In the following sections we refer to matrices of MT A form . In the most general case, this form is ( I + Γ L ( A )) − 1 , (11) 14 Mul ti-T ask A veraging where A is a matrix with all non-negativ e entries, and Γ is a diagonal matrix with all non-negativ e entries. Prop osition 2 The set of estimators W ¯ Y wher e W is of MT A form as p er (11) is strictly lar ger than the set of estimators that r e gularize the single-task estimates as fol lows: ˆ Y t = 1 γ ¯ y t + T X r =1 α r ¯ Y r , wher e P T r =1 α r = 1 − 1 γ , 0 < 1 γ ≤ 1 , and α r ≥ 0 , ∀ r . Corollary 3 Estimators which r e gularize the single task estimate towar ds the p o ole d me an such that they c an b e written ˇ Y t = λ ¯ Y t + 1 − λ P T r =1 N r T X s =1 N s X i =1 Y si , for λ ∈ (0 , 1] c an also b e written in MT A form as ˇ Y = I + 1 − λ λ N T 1 L ( 1N T ) − 1 ¯ Y , wher e N is a T by 1 ve ctor with N t as its t th entry, with c orr esp onding choic es if A and Γ obtaine d by visual p attern matching to (11). Corollary 4 Estimators which r e gularize the single task estimate towar ds the aver age of me ans (AM) such that they c an b e written ˘ Y t = λ ¯ Y t + 1 − λ T T X t =1 ¯ Y t , for λ ∈ (0 , 1] , c an also b e written in MT A form as ˘ Y = I + 1 − λ λT L ( 11 T ) − 1 ¯ Y , with c orr esp onding choic es if A and Γ obtaine d by visual matching to (11). Note that the proof of prop osition in the app endix uses MT A form with asymmetric similarit y matrix A = 1 α T . And, indeed, there is nothing ab out the MT A solution that requires A to be symmetric. Initially , we constrained A to b e symmetric b ecause of the form of the regularizer in the ob jective (1): 1 2 T X r =1 T X s =1 A rs ( ˆ Y r − ˆ Y s ) 2 = ˆ Y T L (( A + A T ) / 2) ˆ Y T . 15 Feldman et al. Ho wev er, for asymmetric A one can simply write the regularizer in matrix form ˆ Y T L ( A ) ˆ Y T , ev en though this regularizer with asymmetric A has a less-than-intuitiv e sum form: ˆ Y T L ( A ) ˆ Y = ˆ Y T L (( A + A T ) / 2) ˆ Y + 1 2 ˆ Y T D ( A ) ˆ Y − 1 2 ˆ Y T D ( A T ) ˆ Y = 1 2 T X r =1 T X s =1 A rs ( ˆ Y r − ˆ Y s ) 2 + 1 2 T X r =1 T X s =1 A rs ! ˆ Y 2 r − 1 2 T X r =1 T X s =1 A sr ! ˆ Y 2 r . 4.8 Ba yesian Interpretation of MT A The MT A estimates from (1) can b e in terpreted as jointly maximizing the likelihoo d of T Gaussian distributions with a joint Gaussian Marko v random field (GMRF) prior (Rue and Held, 2005) on the solution. In MT A, the precision matrix Σ − 1 is L , the graph Laplacian of the similarity matrix, and is thus positive semi-definite (and not strictly positive definite); GMRFs with PSD inv erse cov ariances are called intrinsic GMRFs (IGMRFs). GMRFs and IGMRFs are commonly used in graphical mo dels, wherein the sparsity structure of the precision matrix (whic h corresp onds to conditional indep endence b et ween v ariables) is exploited for computational tractability . Because MT A allows for arbitrary but non-negativ e similarities b etw een any tw o tasks, the precision matrix do es not (in general) ha ve zeros on the off-diagonal, and it is not ob vious how additional sparsit y structure of L w ould b e of help computationally . 5. Sim ulations As we hav e shown in the previous section, MT A is a theoretically ric h form ulation. In the next tw o sections w e test the usefulness of constant MT A and minimax MT A given data. First, we test estimators using simulations so that comparisons to ground truth can b e made. The simulated data was generated from either a Gaussian or uniform hierarc hical pro cess with many sources of randomness (detailed b elow), in an attempt to imitate the uncertain ty of real applications, and thereb y determine if these are goo d general-purp ose estimators. The rep orted results demonstrate that MT A w orks well when a v eraged ov er man y different dra ws of means, v ariances, and num b ers of samples. Sim ulations are run for T = { 2 , 5 , 25 , 500 } tasks, and parameters were set so that the v ariances of the distribution of the true means are the same in b oth uniform and Gaussian sim ulations. Sim ulation results are reported in Figures 4 and 5 for the Gaussian exp eri- men ts, and Figures 6 and 7 for the uniform exp eriments. The Gaussian simulations were run as follows: 1. Fix σ 2 µ , the v ariance of the distribution from whic h { µ t } are drawn. 2. F or t = 1 , . . . , T : (a) Draw the mean of the t th distribution µ t from a Gaussian with mean 0 and v ariance σ 2 µ . 16 Mul ti-T ask A veraging (b) Draw the v ariance of the t th distribution σ 2 t ∼ Gamma(0 . 9 , 1 . 0) + 0 . 1 5 . (c) Draw the n umber of samples to b e dra wn from the t th distribution N t from an in teger uniform distribution in the range of 2 to 100. (d) Draw N t samples y ti ∼ N ( µ t , σ 2 t ). The uniform simulations w ere run as follo ws: 1. Fix σ 2 µ , the v ariance of the distribution from whic h { µ t } are drawn. 2. F or t = 1 , . . . , T : (a) Draw the mean of the t th distribution µ t from a uniform distribution with mean 0 and v ariance σ 2 µ . (b) Draw the v ariance of the t th distribution σ 2 t ∼ U (0 . 1 , 2 . 0). (c) Draw the n umber of samples to b e dra wn from the t th distribution N t from an in teger uniform distribution in the range of 2 to 100. (d) Draw N t samples y ti ∼ U [ µ t − p 3 σ 2 t , µ t + p 3 σ 2 t ]. W e compared constan t MT A and minimax MT A to single-task sample av erages and to the James-Stein estimator given in (4) (mo dified to with T instead of the effectiv e di- mension). W e also compared to a randomized 5-fold 50/50 cross-v alidated (CV) v ersion of James-Stein, constant MT A, and minimax MT A. F or the cross-v alidated versions, w e randomly subsampled N t / 2 samples and c hose the v alue of γ for constan t/minimax MT A or λ for James-Stein that resulted in the lo w est a verage left-out risk compared to the sample mean estimated with al l N t samples. In the optimal versions of constant/minimax MT A γ w as set to 1, as this w as the case during deriv ation. Note that the James-Stein form ulation with a cross-v alidated regularization parameter λ is simply a con vex regularization tow ards the av erage of the sample means: λ ¯ y t + (1 − λ ) ¯ ¯ y . W e used the follo wing parameters for CV: γ ∈ { 2 − 5 , 2 − 4 , . . . , 2 5 } for the MT A estimators and a comparable set of λ spanning (0 , 1) by the transformation λ = γ γ +1 . Ev en when cross- v alidating, an adv antage of using the proposed constan t MT A or minimax MT A is that these estimators pro vide a data-adaptive scale for γ , where γ = 1 sets the regularization parameter to b e a ∗ T or 1 T ( b u − b l ) 2 , resp ectively . 5. The 0 . 1 is added to ensure that v ariance is nev er zero. 17 Feldman et al. Gaussian , T = 2 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Single−Task James−Stein MTA, constant MTA, minimax James−Stein (CV) MTA, constant (CV) MTA, minimax (CV) T = 5 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Figure 4: Gaussian exp erimen t results for T = { 2 , 5 } . The y-axis is av erage (ov er 10000 random draws) p ercen t change in risk vs. single-task, suc h that − 50% means the estimator has half the risk of single-task. Note: for T = 2 the James-Stein estimator reduces to single-task, and so the cyan and black lines ov erlap. Similarly , for T = 2, constant MT A and minimax MT A are identical, and so the blue and green lines ov erlap. 18 Mul ti-T ask A veraging Gaussian , T = 25 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Single−Task James−Stein MTA, constant MTA, minimax James−Stein (CV) MTA, constant (CV) MTA, minimax (CV) T = 500 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Figure 5: Gaussian exp erimen t results for T = { 25 , 500 } . The y-axis is av erage (o ver 10000 random dra ws) p ercen t change in risk vs. single-task, suc h that − 50% means the estimator has half the risk of single-task. 19 Feldman et al. Uniform , T = 2 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Single−Task James−Stein MTA, constant MTA, minimax James−Stein (CV) MTA, constant (CV) MTA, minimax (CV) T = 5 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Figure 6: Uniform exp eriment results for T = { 2 , 5 } . The y-axis is a verage (o ver 10000 random draws) p ercen t change in risk vs. single-task, suc h that − 50% means the estimator has half the risk of single-task. Note: for T = 2 the James-Stein estimator reduces to single-task, and so the cyan and black lines ov erlap. Similarly , for T = 2, constant MT A and minimax MT A are identical, and so the blue and green lines ov erlap. 20 Mul ti-T ask A veraging Uniform , T = 25 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Single−Task James−Stein MTA, constant MTA, minimax James−Stein (CV) MTA, constant (CV) MTA, minimax (CV) T = 500 0 0.5 1 1.5 2 2.5 3 −50 −40 −30 −20 −10 0 10 σ µ 2 (variance of the means) % change vs. single−task Figure 7: Uniform experiment results for for T = { 25 , 500 } . The y-axis is a verage (ov er 10000 random dra ws) percent change in risk vs. single-task, suc h that − 50% means the estimator has half the risk of single-task. 21 Feldman et al. Some observ ations from Figures 4-7: • F urther to the right on the x-axis the means are more lik ely to be further apart, and m ulti-task approaches help less on av erage. • F or T = 2, the James-Stein estimator reduces to the single-task estimator. The MT A estimators pro vide a gain while the means are close with high probabilit y (that is, when σ 2 µ < 1) but deteriorate quickly thereafter. • F or T = 5, constan t MT A dominates in the Gaussian case, but in the uniform case do es worse than single-task when the means are far apart. Note that for all T > 2 minimax MT A almost alw ays outperforms James-Stein and alw ays outperforms single- task, which is to b e exp ected as it w as designed conserv atively . • F or T = 25 and T = 500, we see the trend that all estimators b enefit from an increase in the num b er of tasks. The difference b etw een T = 25 p erformance and T = 500 p erformance is minor, indicating that b enefit from further tasks lev els off early on. • F or constan t MT A, cross-v alidation is alwa ys w orse than the estimated optimal reg- ularization, while the opp osite is true for minimax MT A. This is to b e exp ected, as minimax estimators are not designed to minimizes the av erage risk, which is what we rep ort and the metric optimized during cross-v alidation. • Since b oth constan t MT A and minimax MT A use a similarit y matrix of all ones scaled b y a constan t (alb eit it a differen t one for constan t MT A and minimax MT A), cross- v alidating ov er a set of p ossible γ should result in similar p erformance, and this can b e seen in the Figures (i.e. the green and blue dotted lines are sup erimp osed). In summary , when the tasks are close to each other compared to their v ariances, constan t MT A is the b est estimator to use by a wide margin. When the tasks are farther apart, minimax MT A pro vides a win o ver b oth James-Stein and sample av erages. 5.1 Oracle P erformance T o illustrate the b est achiev able p erformance with MT A, Figure 8 shows the effect of using the true “oracle” means and v ariances for the calculation of optimal pairwise similarities. This experiment separates separates how w ell the MT A form ulation can do from the issue of estimating the optimal similarity matrix from the data. W e use the pairwise oracle matrix A 6 : A orcl rs = 2 ( µ r − µ s ) 2 , whic h consistently bested oracle constan t MT A and oracle minimax MT A. The plot repro- duces the results from the T = 5 Gaussian simulation (excluding cross-v alidation results), and includes the p erformance of oracle pairwise MT A. Oracle MT A is ov er 30% b etter than constan t MT A, indicating that practical estimates of the similarit y , while improving on single-task estimation, are highly suboptimal compared to p ossible MT A p erformance. 6. After exp erimentation, we found that this similarity matrix ga ve us the b est oracle p erformance. Note that an estimated optimal similarity ˆ A rs = 2 ( ¯ y r − ¯ y s ) 2 almost alw ays do es worse than constant MT A and minimax MT A. 22 Mul ti-T ask A veraging 0 0.5 1 1.5 2 2.5 3 −80 −60 −40 −20 0 σ µ 2 (variance of the means) % change vs. single−task Single−Task James−Stein MTA, constant MTA, minimax MTA, oracle Figure 8: Average (ov er 10000 random draws) p ercent change in risk vs. single-task with T = 5 for the Gaussian sim ulation. Oracle MT A uses the true means and v ariance to specify the w eight matrix W . 6. Applications W e presen t three applications with real data. The first t wo applications parallel the simu- lations: estimating expected v alues of final grades and sales of related pro ducts. The third application uses MT A for m ulti-task kernel density estimation, highligh ting the applicability of MT A to an y algorithm that uses sample av erages. 6.1 MT A for Grade Estimation The goal of this application is to predict the final class grades { µ t } T t =1 for all T studen ts, giv en only eac h student’s N homework grades { y ti } N i =1 (in this application N t = N for all t as every studen t had b een assigned the same num b er of homeworks). The final class grades include homeworks, pro jects, labs, quizzes, midterms, and the final exam, but only the homew ork grades are used to predict the final grade. The 16 anonymized datasets w ere pro vided by instructors at the Universit y of W ashington Department of Electrical Engineering. Some experimental details: • Each of the 16 datasets (classes) constitutes a single exp eriment, and the students in that class are treated as the tasks. • All the grades ha ve b een normalized to b e b etw een 0 and 100. 23 Feldman et al. • Homeworks that w ere never handed in w ere assigned 0 p oints. • The num b er of students across the 16 classes is betw een T = 16 and T = 149. • Cross-v alidation parameters were chosen by training on N / 2 of the homew ork grades and v alidating on the sample mean of all N given grades. Again, we used randomized 5-fold 50/50 cross-v alidation. • F or eac h class, a single p o oled v ariance estimate was used for all tasks (that is, stu- den ts). In other words σ 2 t = σ 2 , for all t . • The estimator marked “one-task’ is just a constan t p o oled mean for all tasks: ˆ y pl t = 1 T N T X t =1 N X i =1 y ti . • F or each class of students, the error measuremen t for estimator ˆ y is the risk (av erage of squared errors) across all T students: 1 T T X t =1 ( µ t − ˆ y t ) 2 . This error metric was computed for eac h class (dataset) separately , and the percent c hange in a verage risk vs. single-task are rep orted in T able 2. Some observ ations: • Constant MT A (without CV) has the lo west percent c hange av eraged across all classes. • The James-Stein estimator has the b est p ercen t c hange from single-task on 7 of the 16 classes. • The cross-v alidated versions of estimators do w orse than their estimated optimal coun- terparts. • F or classes 5 and 8, only minimax MT A with estimated similarity do es b etter than the single-task estimate ¯ y . This is rare, but not imp ossible; a few of the students happened to hav e a low a verage homew ork grade and an ev en low er final grade, which resulted in an outsized contribution to the risk. The exp ectation is ov er random samples used to form the estimate, and here the particular realizations of the all the grades were p o or. Also, the mo del that homew ork grades are dra wn iid from a distribution with the final grade as the mean is only a model 7 . • Minimax MT A w as nev er worse than single-task, robustly pro viding relativ ely small gains, as designed. 7. “All mo dels are wrong, but some are useful.” –George E. P . Box 24 Mul ti-T ask A veraging T able 2: P ercent change in risk vs. single-task for the grade estimation application (low er is b etter). ‘JS’ denotes James-Stein, ‘MT A ˆ a ∗ ’ and ‘MT A mm’ denote constan t MT A and minimax MT A, resp ectively , ‘CV’ denotes cross-v alidation, and ‘STD’ denotes standard deviation. Lo wer is b etter. Class One-T ask JS JS MT A MT A MT A MT A Size ˆ a ∗ ˆ a ∗ mm mm CV CV CV 16 26 . 3 0 . 7 0 . 2 0 . 6 0 . 1 0 0 . 1 29 − 6 . 8 − 11 . 0 − 13 . 4 − 10 . 8 − 5 . 9 − 1 . 7 − 6 . 4 36 − 28 . 3 − 17 . 4 − 12 . 4 − 16 . 0 − 9 . 1 − 2 . 8 − 10 . 0 39 42 . 0 − 5 . 8 − 2 . 3 − 5 . 6 − 0 . 9 − 0 . 9 − 0 . 9 44 3 . 0 − 47 . 6 − 47 . 3 − 42 . 7 − 42 . 7 − 7 . 0 − 41 . 1 47 − 12 . 8 − 8 . 0 − 5 . 2 − 7 . 1 − 4 . 1 − 0 . 7 − 2 . 6 48 − 21 . 0 − 20 . 5 − 13 . 7 − 18 . 5 − 5 . 8 − 2 . 5 − 4 . 9 50 63 . 5 63 . 5 16 . 3 9 . 3 9 . 3 − 4 . 4 14 . 8 50 3 . 7 − 33 . 6 − 19 . 1 − 29 . 7 − 10 . 1 − 3 . 2 − 11 . 6 57 23 . 3 − 3 . 8 − 4 . 1 − 3 . 6 − 2 . 1 − 0 . 4 − 1 . 4 58 − 0 . 2 − 16 . 3 − 5 . 9 − 15 . 6 − 4 . 4 − 2 . 8 − 5 . 4 68 − 16 . 9 − 45 . 5 − 38 . 5 − 39 . 0 − 27 . 7 − 6 . 1 − 31 . 1 69 − 14 . 7 − 41 . 0 − 42 . 4 − 39 . 8 − 39 . 8 − 4 . 5 − 35 . 7 72 34 . 6 − 32 . 9 − 29 . 4 − 29 . 0 − 18 . 3 − 4 . 0 − 14 . 1 110 5 . 7 − 14 . 8 − 11 . 5 − 13 . 4 − 7 . 7 − 1 . 2 − 8 . 6 149 − 16 . 6 − 11 . 7 − 11 . 8 − 10 . 1 − 5 . 9 − 0 . 8 − 5 . 8 5 . 3 − 15 . 4 − 15 . 0 − 16 . 9 − 10 . 9 − 2 . 7 − 10 . 3 25 . 9 25 . 9 16 . 9 15 . 2 14 . 3 2 . 1 14 . 4 • The James-Stein estimator is also a minimax estimator, but its p erformance is as highly v ariable as the one-task estimator. This is b ecause of the p ositive-part aspect of the JS estimator – when the p ositiv e-part b oundary is triggered, JS rev erts to the one-task estimator. • Surprisingly , the one-task estimator, whic h p o ols all studen ts’ scores to estimate a sin- gle grade, do es b etter than single-task for half of the classes, and is the best p erformer for 4 out of 16. When the one-task estimator outp erforms single-task, w e hypothesize that individual homew ork grades are p o or estimates of final grades. F urther, when the one-task estimator is the best estimator, we h yp othesize that the assumed mo del is wrong. That is, the homew ork grades are not iid dra ws from the “true” distribution of grades, and, in fact, in those case the homework grades of any individual studen t pro vide little information ab out the final grade. This may occur if the instructor c hose to put a small weigh t on the homework grades, or if the tests and labs required a different skill set from the homework. 25 Feldman et al. 6.2 Application: Estimating Pro duct Sales W e no w consider tw o m ulti-task problems using sales data from Artifact Puzzles. F or b oth problems, we mo del the giv en samples as b eing drawn iid from eac h task. The first problem estimates the impact of a particular puzzle on rep eat business: “Es- timate ho w m uch any customer will sp end on a given order, if on their last order they purc hased the t th puzzle, for eac h of T = 77 puzzles.” The samples were the amoun ts differen t customers had sp ent on orders after buying each of the t puzzles during a given time p erio d, and ranged from 0 for customers that had not re-ordered in the sp ecified time p erio d, to 480. The num b er of samples for each puzzle ranged from N t = 8 to N t = 348. The second problem estimates the monetary v alue of a particular customer : “Estimate ho w muc h the t th customer will sp end on a given order, for each of T = 477 customers.” The samples w ere the order amounts for each of the T customers. Order amounts v aried from 15 to 480. The num b er of samples for each customer ranged from N t = 2 to N t = 17. W e hav e only samples, no ground truth, so to compare the estimators we treat the single-task means computed from all of the samples as the ground truth, and compare to estimates computed from a uniformly randomly c hosen 50% of the samples. Results in T able 3 are av eraged ov er 1000 random draws of the 50% used for estimation. Again, we used 5-fold cross-v alidation with the same parameter c hoices as in the simulations section. W e b olded those en tries that w ere the best or not statistically significantly better than the b est according to t wo one-sided Wilco xon rank statistical significance tests. Some observ ations: • One-task is a v ery p o or estimator for all of the experiments in this section. • Using cross-v alidation with the tw o minimax estimators (James-Stein and minimax MT A) statistically significan tly outperformed their estimated optimal counterparts. This is consistent with the sim ulation results. • Constant MT A provided comparable p erformance to the cross-v alidated estimators. It w as the best or not statistically significan tally b etter than the b est of all the other non-CV estimators. 6.3 Densit y Estimation for T errorism Risk Assessment In this section w e present multi-task kernel density estimation (MT-KDE), a v arian t of MT A. MT A can be used whenev er av erages are tak en. Recall that for standard single-task k ernel density estimation (KDE) (Silverman, 1986), a set of random samples x i ∈ R d , i ∈ { 1 , . . . , N } are assumed to b e iid from an unknown distribution p X , and the problem is to estimate the density for a query sample, z ∈ R d . Giv en a kernel function K ( x i , x j ), the un-normalized single-task KDE estimate is ˆ p ( z ) = 1 N N X i =1 K ( x i , z ) , whic h is just a sample av erage. 26 Mul ti-T ask A veraging T able 3: P ercent c hange in av erage risk for puzzle and customer data (first tw o columns, lo wer is b etter), and mean recipro cal rank for terrorist data (last column, higher is b etter). Estimator Puzzles Customers Suicide Bombings T = 77 T = 477 T = 7 Single-T ask 0 0 0.15 One-T ask 181.7 109.2 0.13 James-Stein -6.9 -14.0 0.15 James-Stein CV -21.2 -31.0 0.19 Constan t MT A -17.5 - 32.3 0.19 Constan t MT A CV - 21.7 -30.9 0.19 Minimax MT A -8.4 -3.0 0.19 Minimax MT A CV -19.8 -25.0 0.19 Exp ert MT A - - 0.19 Exp ert MT A CV - - 0.19 When m ultiple k ernel densities { ˆ p t ( z ) } T t =1 are estimated for the same domain, w e replace the multiple sample a verages with MT A estimates, which we refer to as m ulti-task k ernel densit y estimation (MT-KDE). W e compared KDE and MT-KDE on a problem of estimating the probability of terror- ist even ts in Jerusalem using the Nav al Researc h Laboratory’s Adv ersarial Modeling and Exploitation Database (NRL AMX-DB). The NRL AMX-DB com bined multiple open pri- mary sources 8 to create a ric h representation of the geospatial features of urban Jerusalem and the surrounding region, and accurately geo co ded lo cations of terrorist attacks. Densit y estimation mo dels are used to analyze the b eha vior of suc h violen t agen ts, and to allo cate securit y and medical resources. In related w ork, (Brown et al., 2004) also used a Gaussian k ernel density estimate to assess risk from past terrorism even ts. The goal in this application is to estimate a risk density for 40,000 geographical locations (samples) in a 20km × 20km area of in terest in Jerusalem. Each geographical lo cation is represen ted by a d = 76-dimensional feature vector. Each of the 76 features is the distance in kilometers to the nearest instance of some geographic lo cation of in terest, such as the nearest mark et or bus stop. Lo cations of past even ts are known for 17 suicide b ombings. All the even ts are attributed to one of sev en terrorist groups. The density estimates for these seven groups are exp ected to b e related, and are treated as T = 7 tasks. The k ernel K was taken to b e a Gaussian k ernel with iden tity co v ariance; the bandwidth w as set to 1. In addition to constan t A and minimax A , w e also obtained a side-information 8. Primary sources included the NRL Israel Suicide T errorism Database (ISD) cross referenced with op en sources (including the Israel Ministry of F oreign Affairs, BBC, CPOST, Daily T elegraph, Asso ciated Press, Ha’aretz Daily , Jerusalem Post, Israel National News), as well as the Universit y of New Hav en Institute for the Study of Violent Groups, the Universit y of Maryland Global T errorism Database, and the National Counter T errorism Cen ter W orldwide Incident T racking System. 27 Feldman et al. T able 4: Hafez’s Similarity Matrix A AAMB Hamas PIJ PFLP F atah F orce17 Unkno wn AAMB 0 .2 .2 .6 .8 .8 .6 Hamas .2 0 .8 .2 .2 .2 .4 PIJ .2 .8 0 .2 .2 .2 .4 PFLP .6 .2 .2 0 .6 .6 .5 F atah .8 .2 .2 .6 0 1 .6 F orce17 .8 .2 .2 .6 1 0 .6 Unkno wn .6 .4 .4 .5 .6 .6 0 A from terrorism expert Mohammed M. Hafez of the Na v al P ostgraduate School; he assessed the similarit y b etw een the seven groups during the Second Intifada (the time p erio d of the data), providing similarities betw een 0 and 1. The similarities are shown in T able 4. The KDE estimates were computed separately for each grid p oin t and eac h task. The MT-KDE estimates were obtained for one grid p oin t at a time, but for all of the tasks sim ultaneously . In other words, the regularization w as p erformed only across tasks, and not across grid p oints. Lea ve-one-out cross v alidation w as used to assess KDE and MT-KDE for this problem, as follows. After computing the KDE and MT-KDE density estimates using all but one of the training examples { x ti } for each task, w e sort the resulting 40,000 estimated probabilities for each of the sev en tasks, and extract the rank of the left-out known ev ent. The mean recipro cal rank (MRR) metric is reported in T able 3. Ideally , the MRR of the left-out ev ents w ould b e as close to 1 as p ossible, and indicating that the lo cation of the left-out even t is at high-risk. The results sho w that the MRR for MT-KDE are low er or not w orse than those for KDE for b oth problems; there are, how ever, to o few samples to v erify statistical significance of these results. Also, note that the solution of p o oling all of the training data into one big task gives inferior p erformance, and we susp ect that this is b ecause each terrorist group has its o wn target preferences. 7. Summary Though p erhaps unin tuitive, we sho wed that b oth in theory and in practice estimating m ultiple unr elate d means in a join t MTL fashion can impro ve the ov erall risk, ev en more so than the classic, battle-tested James-Stein estimator. Averaging is common, and MT A has potentially broad applicabilit y as a sub comp onent to man y algorithms, suc h as k-means clustering, kernel density estimation, or non-lo cal means denoising. Ac kno wledgments W e thank Peter Sado wski, and Carol Chang, Brian Sandb erg, and Ruth Willis of the Nav al Researc h Lab for the terrorist ev ent dataset and helpful discussions. W e thank Mohammed M. Hafez of the Na v al Postgraduate Sc ho ol for the matrix of similarities of the terrorist 28 Mul ti-T ask A veraging groups. This w ork was funded b y a United States PECASE Aw ard and b y the United States Office of Nav al Research. App endix A: MT A Closed-form Solution When all A rs are non-negativ e, the differentiable MT A ob jective is conv ex, and a admits closed-form solution. First, w e rewrite the ob jective in (1) in matrix notation: 1 T T X t =1 1 σ 2 t N t X i =1 ( y ti − ˆ y t ) 2 + γ T 2 T X r =1 T X s =1 A rs ( ˆ y r − ˆ y s ) 2 = 1 T T X t =1 1 σ 2 t N t X i =1 ( y ti − ˆ y t ) 2 + γ T 2 ˆ y T L ˆ y = 1 T T X t =1 1 σ 2 t N t X i =1 y 2 ti + ˆ y 2 t − 2 y ti ˆ y t + γ T 2 ˆ y T L ˆ y = 1 T T X t =1 1 σ 2 t N t X i =1 y 2 ti + 1 σ 2 t ˆ y 2 t N t X i =1 1 − 2 1 σ 2 t ˆ y t N t X i =1 y ti ! + γ T 2 ˆ y T L ˆ y = 1 T T X t =1 1 σ 2 t N t X i =1 y 2 ti + N t σ 2 t ˆ y 2 t − 2 N t σ 2 t ˆ y t ¯ y t ! + γ T 2 ˆ y T L ˆ y = 1 T T X t =1 1 σ 2 t N t X i =1 y 2 ti + ˆ y T Σ − 1 ˆ y − 2 ˆ y T Σ − 1 ¯ y ! + γ T 2 ˆ y T L ˆ y , where L = D − ( A + A T ) / 2 is the graph Laplacian matrix ( A + A T ) / 2, Σ is a diagonal matrix with Σ tt = σ 2 t N t , and ˆ y and ¯ y are column vectors with t th en tries ˆ y t and ¯ y t , resp ectively . Note that the ( t, t )th en try of the matrix Σ is the v ariance of ¯ y . Note further that the Laplacian is of the symmetrized ( A + A T ) / 2 and not of A . F or simplicit y of notation, w e assume from now on that A is symmetric. If, in practice, an asymmetric A is provided, it can simply b e symmetrized. T o find the closed-form solution, we no w take the partial deriv ative of the ab o ve ob jective w.r.t. ˆ y and equate to zero, obtaining 0 = 1 T 2Σ − 1 y ∗ − 2Σ − 1 ¯ y + 2 γ T 2 Ly ∗ (12) = y ∗ − ¯ y + γ T Σ Ly ∗ ⇔ ¯ y = I + γ T Σ L y ∗ , whic h yields the follo wing optimal closed-form solution for y ∗ : y ∗ = I + γ T Σ L − 1 ¯ y , (13) as long as the in verse exists, whic h we will pro ve in App endix B. 29 Feldman et al. App endix B: Pro of of Lemma 1 Assumptions: γ ≥ 0, 0 ≤ A rs < ∞ for all r, s and 0 < σ 2 t N t < ∞ for all t . Lemma 1 The MT A solution matrix W = I + γ T Σ L − 1 . Pro of Let B = W − 1 = I + γ T Σ L . The ( t, s )th entry of B is B ts = ( 1 + γ σ 2 t T N t P s 6 = t A ts if t = s − γ σ 2 t T N t A ts if t 6 = s, The Gershgorin disk (Horn and Johnson, 1990) D ( B tt , R t ) is the closed disk in C with cen ter B tt and radius R t = X s 6 = t | B ts | = γ σ 2 t T N t X s 6 = t A ts = B tt − 1 . One kno ws that B tt ≥ 1 for non-negativ e A and when γ σ 2 t T N t ≥ 0, as assumed in the lemma statemen t. Also, it is clear that B tt > R t for all t . Therefore, ev ery Gershgorin disk is con- tained within the p ositive half-plane of C , and, b y the Gershgorin Circle Theorem (Horn and Johnson, 1990), the real part of every eigenv alue of matrix B is p ositive. Its determi- nan t is therefore p ositiv e, and the matrix B is inv ertible: W = B − 1 . App endix C: Pro of of Theorem 2 Assumptions: γ ≥ 0, 0 ≤ A rs < ∞ for all r, s and 0 < σ 2 t N t < ∞ for all t . Before proving Theorem 2, w e will need to prov e tw o more lemmas. Lemma 5 W has al l non-ne gative entries. Pro of By insp ection it is clear that W − 1 = I + γ T Σ L is a Z-matrix , defined to be a matrix with non-positive off-diagonal en tries (Berman and Plemmons, 1979). If W − 1 is a Z-matrix, then the follo wing tw o statemen ts are true and equiv alent: “the real part of eac h eigen v alue of W − 1 is p ositive” and “ W exists and W ≥ 0 (element wise)” (Chapter 6, Theorem 2.3, G 20 and N 38 , (Berman and Plemmons, 1979)). It has already b een prov en in Lemma 1 that the real part of every eigen v alue of W − 1 is p ositive. Therefore, W exists and is element-wise non-negativ e. Lemma 6 The r ows of W sum to 1, i.e. W 1 = 1 . 30 Mul ti-T ask A veraging Pro of As prov ed in Lemma 1, W exists. Therefore, one can write: W 1 = 1 ⇔ 1 = W − 1 1 = I + γ T Σ L 1 = I 1 + γ T Σ L 1 = 1 + γ T Σ 0 = 1 , where the the third equality is true b ecause the graph Laplacian has rows that sum to zero. The rows of W therefore sum to 1. Theorem The MT A solution matrix W = I + γ T Σ L − 1 is right-sto chastic. Pro of W e kno w that W exists (from Lemma 1), is en try-wise non-negative (from Lemma 2), and has rows that sum to 1 (from Lemma 3). App endix D: Constan t MT A Deriv ation F or the case when T > 2, analytically sp ecifying a general similarit y matrix A that minimizes the risk is intractable. T o address this limitation for arbitrary T , w e constrain the similarit y matrix to b e the constan t matrix A = a 11 T , resulting in the follo wing weigh t matrix: I + γ T Σ L ( a 11 T ) − 1 . (14) F or a general, asymmetric A there are T ( T − 1) parameters to estimate. F or the constant A = a 11 T only a needs to b e estimated ( γ is set to 1 w.l.o.g.). It turns out, ho wev er, that finding a ∗ for arbitrary T b y minimizing the risk of the estimator ˆ y = W cnst ¯ y is not tractable, but b ecomes tractable for a simplified v ersion of (16) where the trace of the co v ariance replaces the full co v ariance. Th us we find a ∗ as follows a ∗ = arg min a R µ, I + γ T tr (Σ) T L ( a 11 T ) − 1 ¯ Y ! . (15) and then plug this a ∗ in to (16) to obtain “constant MT A”. W cnst = I + γ T Σ L ( a ∗ 11 T ) − 1 . (16) 31 Feldman et al. First, we simplify W cnst using the Sherman-Morrison formula: I + 1 T Σ L ( a 11 T ) − 1 = I + a T Σ L ( T I − 11 T ) − 1 = I + a Σ − a T Σ 11 T − 1 = ( I + a Σ) − 1 + ( I + a Σ) − 1 a T Σ 11 T ( I + a Σ) − 1 1 − a T 1 T ( I + a Σ) − 1 Σ 1 , (17) and set Σ = tr (Σ) T I to get W smpl : W smpl = 1 1 + a tr (Σ) T I + 1 1+ a tr (Σ) T a T tr (Σ) T 11 T 1 1+ a tr (Σ) T 1 − a T 1 T 1 1+ a tr (Σ) T tr (Σ) T 1 = 1 a tr (Σ) T + 1 I + a tr (Σ) T a tr (Σ) T +1 1 T 11 T 1 1+ a tr (Σ) T 1 − a tr (Σ) T 1+ a tr (Σ) T = 1 a tr (Σ) T + 1 I + a tr (Σ) T a tr (Σ) T + 1 1 T 11 T = 1 a tr (Σ) T + 1 I + a tr (Σ) T 2 11 T . 32 Mul ti-T ask A veraging The risk of y ∗ = W smpl ¯ y is R ( µ, Y ∗ ) = tr ( W smpl Σ( W smpl ) T ) + µ T ( W smpl − I ) T ( W smpl − I ) µ = tr 1 a tr (Σ) T + 1 I + a tr (Σ) T 2 11 T Σ I 1 a tr (Σ) T + 1 I + a tr (Σ) T 2 11 T T ! + µ T 1 a tr (Σ) T + 1 I + a tr (Σ) T 2 11 T − I ! T 1 a tr (Σ) T + 1 I + a tr (Σ) T 2 11 T − I ! µ = 1 ( a tr (Σ) T + 1) 2 tr I + a tr (Σ) T 2 11 T Σ I + a tr (Σ) T 2 11 T + µ T − a tr (Σ) T a tr (Σ) T + 1 I + a tr (Σ) T a tr (Σ) T + 1 1 T 11 T ! T − a tr (Σ) T a tr (Σ) T + 1 I + a tr (Σ) T a tr (Σ) T + 1 1 T 11 T ! µ = 1 ( a tr (Σ) T + 1) 2 tr Σ + 2 a tr (Σ) T 2 11 T Σ + a 2 tr (Σ) 2 T 4 11 T Σ 11 T + ( a tr (Σ) T ) 2 ( a tr (Σ) T + 1) 2 µ T L 1 T 11 T T L 1 T 11 T µ = tr (Σ) T ( a tr (Σ) T + 1) 2 T + 2 a tr (Σ) T + a tr (Σ) T 2 ! + ( a tr (Σ) T ) 2 ( a tr (Σ) T + 1) 2 µ T L 1 T 11 T T L 1 T 11 T µ T o find the minimum, we tak e the partial deriv ative w.r.t. a and set it equal to zero. Again noting that L 1 T 11 T T L 1 T 11 T = L 1 T 11 T , and omitting some tedious algebra, ∂ ∂ a ∗ R ( µ, Y ∗ ) = 0 = 2 tr (Σ) T ( − T + 1 + a ∗ µ T L 1 T 11 T µ ) ( a ∗ tr (Σ) T + 1) 3 ⇔ a ∗ = T − 1 µ T L 1 T 11 T T L 1 T 11 T T µ = T − 1 µ T L 1 T 11 T µ = 2 1 T ( T − 1) P T r =1 P T s =1 ( µ r − µ s ) 2 . App endix E: Minimax MT A Deriv ation First, some definitions are in order. 33 Feldman et al. • An estimator Y M of µ which minimizes the maxim um risk inf ˆ Y sup µ R ( µ, ˆ Y ) = sup µ R ( µ, Y M ) , is called a minimax estimator. • The aver age risk for estimator ˆ Y is r ( π , ˆ Y ) = Z R ( µ, ˆ Y ) π ( µ ) dµ, (18) where π is a prior on µ . • The estimator that minimizes the av erage risk is called the Bayes estimator and is written Y π = arg min ˆ Y r ( π , ˆ Y ) . • The Bayes risk is the risk of the Ba yes estimator and is written r ( π , Y π ) = Z R ( µ, Y π ) π ( µ ) dµ. (19) • A prior distribution π is le ast favor able if r ( π , Y π ) ≥ r ( π 0 , Y 0 π ) for all priors π 0 . T o find a minimax MT A, we will need the following theorem and corollary (Theorem 1.4, Chapter 5 (Lehmann and Casella, 1998)). Theorem Supp ose that π is a distribution on the sp ac e of µ such that r ( π , Y π ) = sup µ R ( µ, Y π ) . Then: 1. Y π is minimax. 2. If Y π is the unique Bayes solution w.r.t. π (i.e. if it is the only minimizer of (19)), then it is the unique minimax estimator. 3. The prior π is le ast favor able. Corollary If a Bayes estimator Y π has c onstant risk, then it is minimax. The first step in finding a minimax solution for the T = 2 case is sp ecifying a constraint set for µ o ver whic h a least fav orable prior (LFP) can be found. If no constrain t set is 34 Mul ti-T ask A veraging used, µ t = ∞ is the worst case, and leads to a LFP that puts all of its mass on that p oin t. W e will use one of the simplest constrain t sets, and constrain eac h µ t to b e in the interv al µ ∈ [ b l , b u ] T , where b l ∈ R and b u ∈ R . T o find the LFP w e must find the µ that mak es the risk as large as possible. F or T = 2 and right-stochastic W , we ha ve that the µ -dependent term in the (9) can b e written as ( W − I ) T ( W − I ) = ( W 2 12 + W 2 21 ) L ( 11 T ), and therefore µ T ( W − I ) T ( W − I ) µ = ( W 2 12 + W 2 21 )( µ 1 − µ 2 ) 2 , whic h is clearly maximized b y either µ 1 = b u , µ 2 = b l or µ 1 = b l , µ 2 = b u . Therefore the LFP is p ( µ ) = 1 2 , if µ = ( b l , b u ) 1 2 , if µ = ( b u , b l ) 0 , otherwise. The next step is to guess a minimax weigh t matrix W M and show that the estimator Y M = W M ¯ Y (i) has constan t risk and (ii) is a Bay es solution. According to the corollary , if b oth (i) and (ii) hold for the guessed W M , then W M ¯ Y is minimax. F or the T = 2 case, w e guess W M to b e W ∗ = I + 2 T ( b l − b u ) 2 Σ L ( 11 T ) − 1 , whic h is just W cnst with a = 2 ( b l − b u ) 2 . This choice of W is not a function of µ and th us w e ha ve shown that (i) the Bay es risk w.r.t the LFP is constant for all µ . What remains to sho w is (ii) W M is indeed the Bay es solution, i.e. it is minimizer of the Ba yes risk: 1 2 [ b l b u ]( W − I ) T ( W − I ) b l b u + tr ( W Σ W T ) + 1 2 [ b u b l ]( W − I ) T ( W − I ) b u b l + tr ( W Σ W T ) . (20) Note that this expression is the sum of t wo con vex risks. W e already know (see (7) on page 4 of the NIPS paper) that for T = 2 the minimizer of the risk [ µ 1 µ 2 ]( W − I ) T ( W − I ) µ 1 µ 2 + tr ( W Σ W T ) is W ∗ = I + 2 T ( µ 1 − µ 2 ) 2 Σ L ( 11 T ) − 1 . Thus, the minimizer of [ b l b u ]( W − I ) T ( W − I ) b l b u + tr ( W Σ W T ) is W 1 = I + 2 T ( b l − b u ) 2 Σ L ( 11 T ) − 1 , and the minimizer of [ b u b l ]( W − I ) T ( W − I ) b u b l + tr ( W Σ W T ) 35 Feldman et al. is W 2 = I + 2 T ( b u − b l ) 2 Σ L ( 11 T ) − 1 . Clearly W 1 = W 2 whic h means that the t wo risks in (20) are both minimized by the same weigh t matrix W 1 , and th us their sum is also minimized by W 1 . Therefore W M = I + 2 T ( b u − b l ) 2 Σ L ( 11 T ) − 1 (21) as was to b e sho wn. One can conclude that W M is minimax ov er all estimators of the form W = I + γ T Σ L − 1 for T = 2 using the interv al constraint set. App endix F: Pro of of Prop osition 2 Prop osition 2 The set of estimators W ¯ Y wher e W is of MT A form as p er (11) is strictly lar ger than the set of estimators that r e gularize the single-task estimates as fol lows: ˆ Y t = 1 γ ¯ y t + T X r =1 α r ¯ Y r , wher e P T r =1 α r = 1 − 1 γ , 0 < 1 γ ≤ 1, and α r ≥ 0, ∀ r . Pro of First we will sho w that estimators ˆ Y t can b e written in MT A form. Rewriting ˆ Y in matrix notation: ˆ Y t = 1 γ ¯ Y t + T X t =1 α t ¯ Y t ⇔ ˆ Y = 1 γ I + 1 α T ¯ Y . The goal now is to sho w that ( 1 γ I + 1 α T ) − 1 has MT A form. Using the Sherman-Morrison form ula, we get 1 γ I + 1 α T − 1 = γ I − γ 2 1 α T 1 + γ α T 1 = γ I − γ 1 α T = I + ( γ − 1) I − γ 1 α T = I + γ 1 − 1 γ I − γ 1 α T = I + γ L ( 1 α T ) , whic h is a matrix of MT A form with appropriate choices of γ , Σ, and A (obtained by visual pattern matching). Th us, estimators ˆ Y t can b e written in MT A form: ˆ Y = ( I + γ L ( 1 α T )) − 1 . (22) By insp ection of (11), it is clear that not all matrices of the form ( I + Γ L ( A )) − 1 can b e written as (22). This implies that matrices of MT A form are strictly more general than matrices of the form in (22). 36 Mul ti-T ask A veraging References J. Ab ernethy , F. Bach, T. Evgeniou, and J.-P . V ert. A new approac h to collaborative filtering: Op erator estimation with sp ectral regularization. Journal Machine L e arning R ese ar ch , 10, 2009. A. Argyriou, C. A. Micc helli, M. Pon til, and Y. Ying. A sp ectral regularization framework for multi-task structure learning. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , 2007. A. Argyriou, T. Evgeniou, and M. Pon til. Conv ex m ulti-task feature learning. Machine L e arning , 73(3):243–272, 2008. A. Banerjee, S. Merugu, I. S. Dhillon, and J. Ghosh. Clustering with Bregman divergences. Journal Machine L e arning R ese ar ch , 6:1705–1749, Decem b er 2005. M. Belkin, P . Niyogi, and V. Sindhw ani. Manifold regularization: A geometric framework for learning from lab eled and unlab eled examples. Journal Machine L e arning R ese ar ch , 7:2399–2434, 2006. A. Berman and R. J. Plemmons. Nonne gative Matric es in the Mathematic al Scienc es . Academic Press, 1979. M. E. Bo ck. Minimax estimators of the mean of a m ultiv ariate normal distribution. The A nnals of Statistics , 3(1), 1975. E. V. Bonilla, K. M. A. Chai, and C. K. I. Williams. Multi-task Gaussian pro cess prediction. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) . MIT Press, 2008. D. Brown, J. Dalton, and H. Hoyle. Spatial forecast metho ds for terrorist even ts in urban en vironments. L e ctur e Notes in Computer Scienc e , 3073:426–435, 2004. G. Casella. An introduction to empirical Bay es data analysis. The Americ an Statistician , pages 83–87, 1985. P . Cheb otarev and E. Shamis. The matrix-forest theorem and measuring relations in small so cial groups. Computing R ese ar ch R ep ository , abs/math/0602070, 2006. F. R. K. Chung. Sp e ctr al Gr aph The ory . 2004. B. Efron and C. N. Morris. Stein’s paradox in statistics. Scientific A meric an , 236(5): 119–127, 1977. F. F ouss, L. Y en, A. Pirotte, and M. Saerens. An experimental inv estigation of graph k ernels on a collab orative recommendation task. In ICDM , pages 863–868, 2006. T. Has tie, R. Tibshirani, and J. F riedman. The Elements of Statistic al L e arning . Springer- V erlag, New Y ork, 2001. R. A. Horn and C. R. Johnson. Matrix A nalysis . Cambridge Universit y Press, 1990. Corrected reprint of the 1985 original. 37 Feldman et al. L. Jacob, F. Bac h, and J.-P . V ert. Clustered multi-task learning: A conv ex form ulation. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , pages 745–752, 2008. W. James and C. Stein. Estimation with quadratic loss. Pr o c. F ourth Berkeley Symp osium on Mathematic al Statistics and Pr ob ability , pages 361–379, 1961. T. Kato, H. Kashima, M. Sugiyama, and K. Asai. Multi-task learning via conic program- ming. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , pages 737–744. 2008. E. L. Lehmann and G. Casella. The ory of Point Estimation . Springer, New Y ork, 1998. C. A. Micc helli and M. P ontil. Kernels for multi–task learning. In A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , 2004. J. P . Romano and A. F. Siegel. Counter examples in Pr ob ability and Statistics . Chapman and Hall, Belmont, CA USA, 1986. H. Rue and L. Held. Gaussian Markov R andom Fields: The ory and Applic ations , v olume 104 of Mono gr aphs on Statistics and Applie d Pr ob ability . Chapman & Hall, London, 2005. M. Saerens, F. F ouss, L. Y en, and P . Dup ont. The principal components analysis of a graph, and its relationships to sp ectral clustering. In In Pr o c. Eur. Conf. Machine L e arning , pages 371–383. Springer-V erlag, 2004. D. Sheldon. Graphical m ulti-task learning, 2008. Adv ances in Neural Information Pro cessing Systems (NIPS) W orkshops. Jac k Sherman and Winifried J. Morrison. Adjustment of an Inv erse Matrix Corresp onding to a Change in One Elemen t of a Giv en Matrix. Ann. Math. Stat. , 21:124–127, 1950. B. W. Silverman. Density Estimation for Statistics and Data Analysis . Chapman and Hall, New Y ork, 1986. A. J. Smola and I. R. Kondor. Kernels and regularization on graphs. In Pr o c e e dings of the A nnual Confer enc e on Computational L e arning The ory , 2003. C. Stein. Inadmissibility of the usual estimator for the mean of a m ultiv ariate distribution. Pr o c. Thir d Berkeley Symp osium on Mathematic al Statistics and Pr ob ability , pages 197– 206, 1956. U. v. Luxburg. A tutorial on sp ectral clustering. Computing R ese ar ch R ep ository , abs/0711.0189, 2007. Y. Xue, X. Liao, L. Carin, and B. Krishnapuram. Multi-task learning for classification with Diric hlet pro cess priors. Journal Machine L e arning R ese ar ch , 8:35–63, 2007. Y. Y a jima and T.-F. Kuo. Efficient formulations for 1-SVM and their application to rec- ommendation tasks. JCP , 1(3):27–34, 2006. 38 Mul ti-T ask A veraging Y. Zhang and D.-Y. Y eung. A conv ex formulation for learning task relationships. In Pr o c. of the 26th Confer enc e on Unc ertainty in Artificial Intel ligenc e (UAI) , 2010. X. Zhu. Semi-sup ervised learning literature survey , 2006. X. Zhu and J. Laffert y . Harmonic mixtures: com bining mixture mo dels and graph-based metho ds for inductive and scalable semi-sup ervised learning. In In Pr o c. Int. Conf. Machine L e arning , pages 1052–1059. A CM Press, 2005. 39
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment