계층적 군집으로 탐구하는 대규모 고차원 데이터의 대칭과 패턴
본 논문은 계층적 군집(히에라키)과 초거리(ultrametric) 토폴로지를 중심으로, p‑adic 수 체계와 격자 이론을 결합해 데이터의 내재적 대칭을 밝혀낸다. 초거리 공간에서 모든 삼각형이 등변 또는 작은 밑변을 갖는 특성을 이용해 고차원·대용량 데이터의 구조를 효율적으로 파악하고, 화학 데이터베이스 매칭과 외환 시계열 분석 등 실제 사례를 통해 방법론의 실용성을 입증한다.
저자: ** 논문 본문에 저자 정보가 명시되지 않았으나, 주요 인용·언급으로 보아 Herbert A. Simon(노벨 경제학상 수상자)과 관련 연구자들의 사상·이론을 바탕으로 작성된 것으로 추정됩니다. **
본 논문은 데이터 분석·마이닝에서 ‘구조’를 대칭(symmetry)으로 정의하고, 이러한 대칭을 계층적 구조, 즉 초거리(ultrametric) 토폴로지를 통해 표현한다. 서론에서는 Herbert A. Simon의 “복잡성은 종종 계층으로 나타난다”는 견해를 인용하며, 계층이 데이터 해석의 핵심임을 강조한다.
2장에서는 초거리 공간의 정의와 성질을 상세히 설명한다. 초거리의 핵심인 강한 삼각 부등식은 모든 삼각형이 등변 또는 작은 밑변을 갖게 하며, 이는 데이터 포인트 간 거리 행렬을 특정 순열 후에 블록 대각 형태로 재구성할 수 있게 한다. 초거리 행렬의 두 가지 주요 성질(대각선 위의 원소가 비감소, 동일값 구간의 행·열 관계)을 제시하고, 이를 시각화와 클러스터링에 활용한다. 행·열 순열을 통한 시각화 기법은 특히 2‑mode 데이터(관측치×속성)에도 적용 가능하도록 확장된다.
3장에서는 일반화된 초거리와 격자 이론을 연결한다. 격자는 부분집합 간 포함 관계를 부분 순서(partial order)로 표현하며, 이는 계층적 트리와 동형이다. 화학 데이터베이스 매칭 사례를 통해, 격자 기반 초거리 알고리즘이 기존 최적화 기반 클러스터링보다 효율적으로 유사성을 탐색함을 보인다.
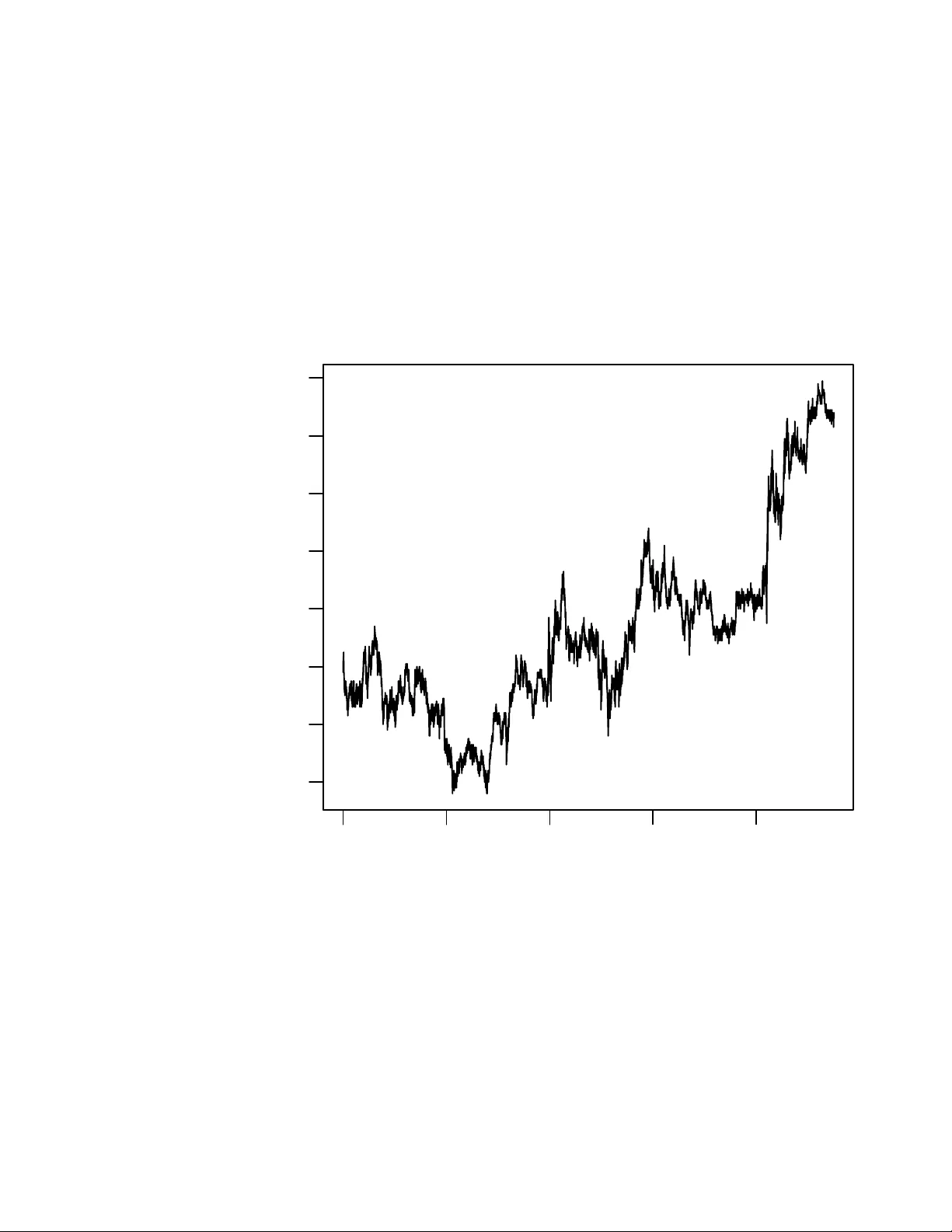
4장에서는 p‑adic 수 체계와 그 응용을 다룬다. p‑adic 수는 비아르키메데스적(norm) 구조를 제공하며, 이는 초거리와 자연스럽게 결합한다. 논문은 p‑adic 거리 정의를 가장 긴 공통 접두(prefix) 길이 기반으로 제시하고, 이를 이용해 DNA 서열을 초거리 트리로 변환한다. 또한, p‑adic 기반 Haar 웨이블릿 변환을 덴드로그램에 적용하여, 변환 계수를 이용한 노이즈 억제와 특징 추출 방법을 제시한다.
5장에서는 트리 자체가 갖는 대칭성을 탐구한다. 트리는 부분 순서이자 데이터의 임베딩 공간이며, 이를 이용해 Haar 웨이블릿 변환과 필터링을 수행한다. 변환 후의 계수는 데이터의 지역적·전역적 변동을 동시에 포착한다.
6장에서는 고차원·대용량 데이터에서 나타나는 특수한 대칭성을 논의한다. 고차원 데이터는 초거리 구조가 자연스럽게 희소성을 제공하고, 저차원 임베딩을 가능하게 한다. 외환(FX) 시계열 분석 사례에서는 가격 변동을 초거리 트리로 임베딩하고, 트리 기반 클러스터링을 통해 변동 구간을 자동 구분한다. 이는 전통적인 시계열 모델보다 적은 파라미터로 비선형 패턴을 포착한다는 장점을 가진다.
결론에서는 계층적 군집을 단순한 군집 기법이 아니라, 초거리 토폴로지, 격자 이론, p‑adic 수학과 결합한 통합 프레임워크로 제시한다. 이 프레임워크는 데이터의 대칭성을 명시적으로 드러내어, 고차원·대규모 데이터의 구조적 이해와 효율적 분석을 가능하게 한다. 또한, 화학·금융 등 다양한 분야에 적용 가능한 사례들을 제시함으로써, 계층적 군집의 실용적 가치를 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기