MOOC 포럼 커뮤니티 분석 베이지안 비음수 행렬 분해 활용
본 논문은 Coursera의 비즈니스 전략 MOOC 포럼 데이터를 대상으로, 5가지 내용 차원을 라벨링한 후 베이지안 비음수 행렬 분해(BNMF)를 이용해 학습자들의 잠재적 커뮤니티를 추출한다. BNMF 모델은 포괄적인 확률 생성 모델로서, 기존 인도 버퍼 프로세스 기반 모델(LPGM)보다 RMSE와 NLL 지표에서 우수한 성능을 보였다. 발견된 커뮤니티는 학습 성취도, 지리적 분포, 감정 표현 등 인구통계적 특성과 강하게 연관되어 있어, 대규…
저자: Nabeel Gillani, Rebecca Eynon, Michael Osborne
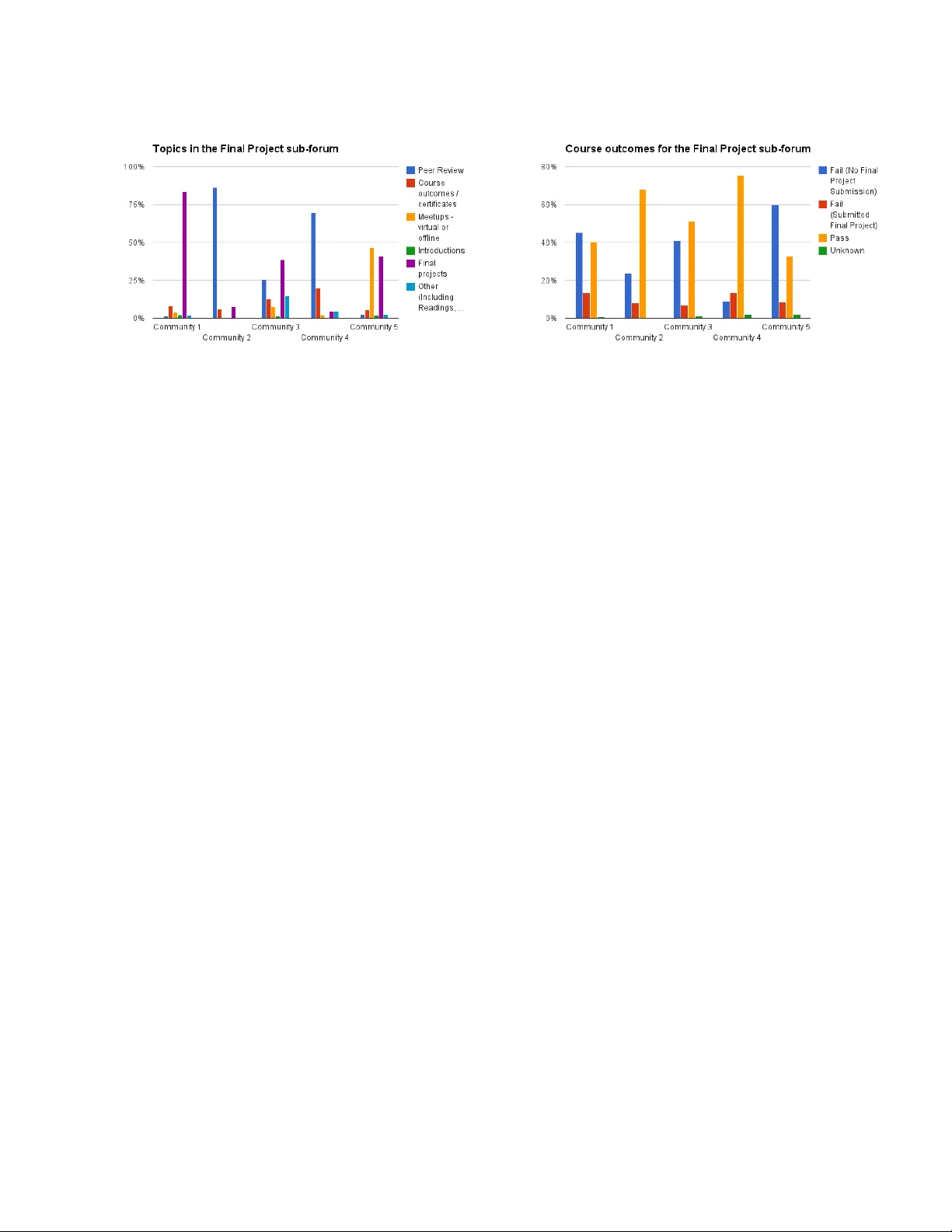
본 연구는 대규모 온라인 교육 플랫폼인 Coursera에서 제공한 2013년 봄 학기 비즈니스 전략 MOOC를 대상으로, 학습자 간의 커뮤니케이션 패턴과 학습 행동을 정량적으로 분석하고자 한다. 전체 등록자는 약 90,000명이며, 실제 포럼에 글을 올린 학습자는 4,500명, 총 게시물 수는 15,600개, 조회수는 181,911회에 달한다. 연구진은 이 중 6,500개의 게시물을 무작위 추출해 정성적 내용 분석을 수행했으며, 기존 교육학·컴퓨터 과학 문헌을 바탕으로 다섯 가지 차원을 설계하였다.
1. **학습 차원** – 지식 구축 수준을 9단계로 구분(관찰·의견 제시부터 의미 협상까지).
2. **커뮤니케이션 차원** – 논증적, 반응적, 정보제공, 질문형, 명령형 등 5가지 유형.
3. **감정 차원** – 긍정·부정·활성·비활성·중립의 5가지 코드.
4. **주제 차원** – 강의 내용, 퀴즈, 사례, 오프라인 모임 등 11가지 카테고리.
5. **관련성 차원** – 게시물이 스레드와 서브포럼에 얼마나 부합하는지를 고·중·저 3단계로 평가.
각 게시물은 위 차원 중 하나씩 라벨링되며, 학습자는 자신이 작성한 모든 게시물의 라벨을 집합으로 갖는다. 이렇게 구성된 라벨링 결과를 이진 행렬 C(N×D)로 표현한다. 여기서 N은 포럼에 최소 한 번 이상 글을 올린 학습자 수(≈4,500명), D는 라벨 총합(≈33)이다.
다음으로, C를 이용해 학습자‑학습자 유사도 행렬 X(N×N)를 만든다. xᵢⱼ=∑₍d₎cᵢd·cⱼd 로 정의되며, 이는 두 학습자가 공유한 라벨의 개수를 의미한다. 이 행렬은 실제 대화 빈도가 아니라 내용적 유사성을 반영한다는 점에서 기존 소셜 네트워크 분석과 차별화된다.
본 논문은 이러한 유사도 행렬을 확률 생성 모델인 베이지안 비음수 행렬 분해(BNMF)로 모델링한다. 기본 가정은 xᵢⱼ가 포아송 분포를 따르며, 평균 ˆxᵢⱼ=∑₍k₎wᵢₖ·hₖⱼ 로 표현된다. 여기서 W(N×K)와 H(K×N)은 각각 학습자와 커뮤니티의 잠재 기여도를 나타낸다. K는 사전에 지정되지 않은 잠재 커뮤니티 수이며, 자동 차원 선택을 위해 각 wᵢₖ, hₖⱼ에 반정규 사전분포를, 하이퍼파라미터 βₖ에 감마 사전분포를 부여한다. βₖ가 클수록 해당 커뮤니티는 거의 사용되지 않음으로 자동 억제된다.
추론은 고정점 알고리즘을 사용해 W, H, β를 교대로 업데이트한다. 업데이트 식은 기존 문헌(Psorakis et al., 2011)과 동일하며, 복잡도는 O(NK)로 대규모 데이터에 적합하다. 수렴 후 0이 아닌 열/행만 남겨 실제 사용된 커뮤니티 수 K*를 도출한다.
모델 성능을 검증하기 위해, 연구진은 20개의 무작위 50×50 서브셋을 생성하고, 각 서브셋의 10% 데이터를 hold‑out했다. 평가 지표는 RMSE와 음의 로그우도(NLL)이며, 비교 모델로는 인도 버퍼 프로세스 기반 비파라메트릭 라인포이슨 감마 모델(LPGM), 평균 예측(Pred‑Avg), 영 예측(Pred‑0)을 사용했다. 결과는 BNMF가 RMSE 0.4647, NLL 251.97로 가장 낮은 오류를 기록했으며, LPGM은 RMSE 0.9330, NLL 324.74로 뒤처졌다. 이는 BNMF가 희소 이진 유사도 행렬을 효과적으로 압축하면서도 의미 있는 잠재 구조를 포착함을 보여준다.
커뮤니티 해석 단계에서는 W의 행별 소프트 멤버십을 기반으로 학습자를 군집화하고, 각 군집의 인구통계적 특성(지역, 연령, 성별) 및 코스 성과(주간 퀴즈 점수, 최종 프로젝트 등)와 연관시켰다. 주요 발견은 다음과 같다.
- **고성취 커뮤니티**: 북미·유럽 학습자들이 주를 이루며, ‘학습’ 차원에서 높은 수준(의미 협상)과 긍정적 감정 라벨을 많이 사용하고, 퀴즈 점수와 최종 프로젝트 점수가 평균보다 높았다.
- **질문 중심 커뮤니티**: 아시아·아프리카 학습자들이 많이 포함되었으며, ‘elicitative’(질문) 라벨과 중간 수준의 감정 라벨이 주를 이루었다. 이들은 코스 완주율이 낮고, 포럼 활동이 주로 질문과 답변에 국한되었다.
- **소셜·네트워킹 커뮤니티**: 라틴아메리카 학습자들이 활발히 ‘informative’와 ‘responsive’ 라벨을 사용했으며, 주제 차원에서 오프라인 모임 및 사례 토론에 집중했다. 이들의 학습 성취는 평균 수준이었지만, 포럼 참여도가 가장 높았다.
이러한 차별적 특성은 교육 설계자가 학습자 유형별 맞춤형 피드백, 토론 촉진 전략, 학습 경로 설계 등에 활용할 수 있는 실질적 근거를 제공한다. 예를 들어, 질문 중심 커뮤니티에 대해선 자동화된 튜터링 시스템이나 동료 멘토링을 도입해 완주율을 높일 수 있고, 고성취 커뮤니티에는 심화 토론 공간을 제공해 학습 동기를 유지하도록 할 수 있다.
결론적으로, 베이지안 비음수 행렬 분해는 대규모 MOOC 포럼 데이터와 같이 고차원, 희소, 이진 형태의 콘텐츠 라벨링을 다루기에 적합한 확률 생성 모델이며, 기존 비베이지안 혹은 무한 잠재 특성 모델보다 계산 효율성과 해석 가능성 모두에서 우수함을 입증한다. 향후 연구에서는 시간적 동역학을 포함한 동적 BNMF 모델을 적용하거나, 텍스트 기반 토픽 모델링과 결합해 보다 정교한 학습자 행동 예측 모델을 구축할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기