Communication Communities in MOOCs
Massive Open Online Courses (MOOCs) bring together thousands of people from different geographies and demographic backgrounds -- but to date, little is known about how they learn or communicate. We introduce a new content-analysed MOOC dataset and us…
Authors: Nabeel Gillani, Rebecca Eynon, Michael Osborne
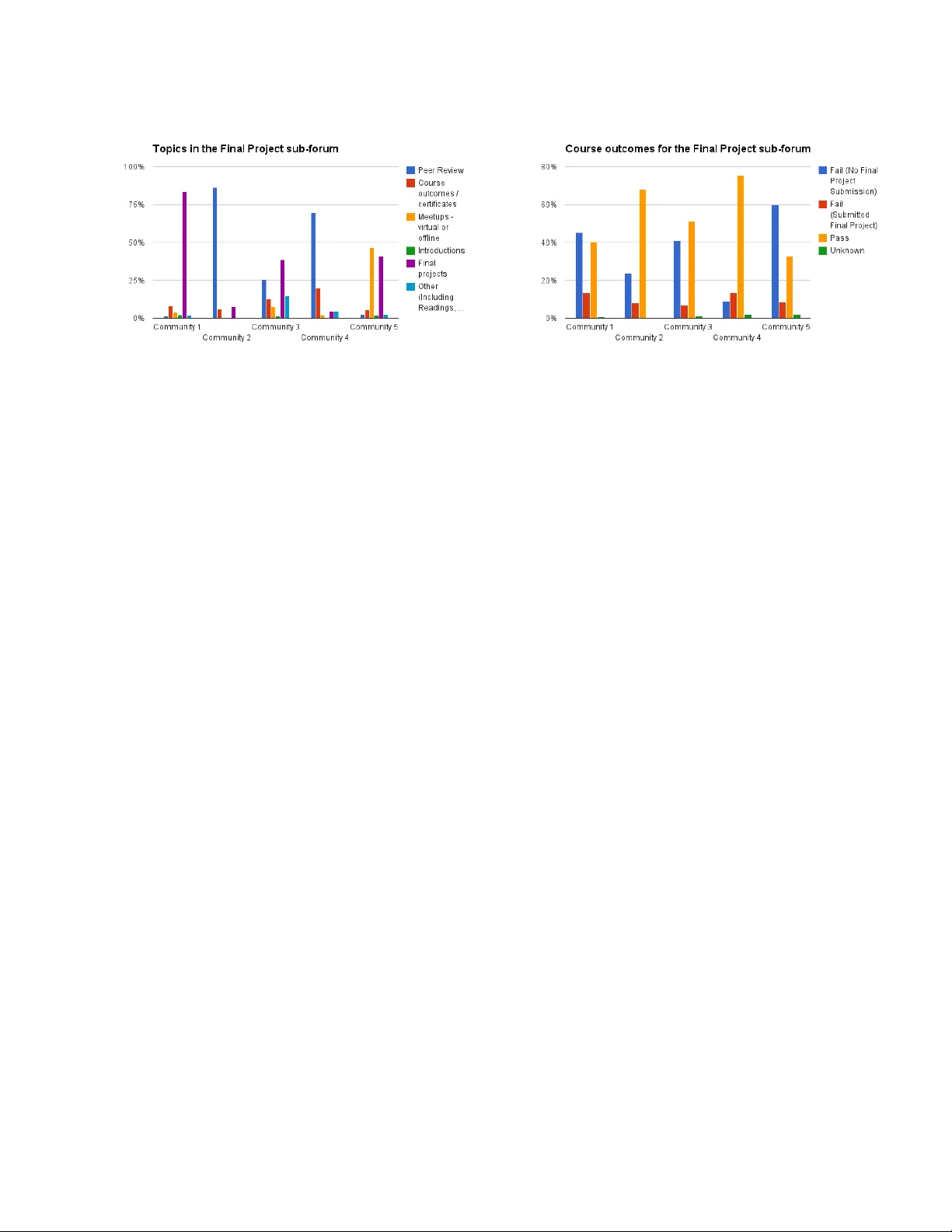
Comm unication Comm unities in MOOCs Nab eel Gillani, Mic hael Osb orne, Stephen Rob erts Mac hine Learning Researc h Group Departmen t of Engineering Science Univ ersity of Oxford { nab eel, mosb, sjrob } @robots.ox.ac.uk Reb ecca Eynon, Isis Hjorth Oxford Internet Institute Departmen t of Education Univ ersity of Oxford { reb ecca.eynon, isis.hjorth } @oii.ox.ac.uk Abstract Massiv e Op en Online Courses (MOOCs) bring together thousands of p eople from dif- feren t geographies and demographic back- grounds – but to date, little is known about ho w they learn or communicate. W e intro- duce a new conten t-analysed MOOC dataset and use Bay esian Non-negative Matrix F ac- torization (BNMF) to extract comm unities of learners based on the nature of their on- line forum p osts. W e see that BNMF yields a sup erior probabilistic generative mo del for online discussions when compared to other mo dels, and that the communities it learns are differentiated by their comp osite stu- den ts’ demographic and course p erformance indicators. These findings suggest that com- putationally efficient probabilistic generative mo delling of MOOCs can reveal imp ortan t insigh ts for educational researchers and prac- titioners and help to develop more intelligen t and resp onsive online learning environmen ts. 1 In tro duction There has b een no shortage of polarised media hype around Massiv ely Op en Online Courses (MOOCs) – and y et, grounded research on their p edagogical effec- tiv eness and p otential is in its infancy . Researc h in online education is not new: prop onen ts hav e lauded its p otential and critics ha ve w arned of an imminen t “mec hanization of education” since the p opularization of the internet nearly tw o decades ago (Nob el, 1998). Moreo ver, m uc h education literature has fo cused on the w ay learners use online discussion forums, draw- ing up on so cial constructivist (Vygotsky , 1978) con- ceptions of kno wledge creation and sharing. The rise of MOOCs has provided a new opp ortunity to explore, among other things, ho w communication unfolds in a global, semi-synchronous classro om. Still, early researc h efforts ha ve tak en only a cursory look at the nature of this comm unication, for example, detect- ing and mo delling the prev alence of chatter irrelev an t to the course (Brinton et al., 2013) and, in some cases, exploring the frequency of w ords used b y those that pass or fail (Anderson et al., 2014). Other studies in online education more broadly hav e leveraged so- cial netw ork analysis of fine-grained digital trace data to understand the nature of information cascades be- t ween groups of students (V aquero and Cebrian, 2013). In order for educators to supp ort dialogue and inter- action that enables learning in online settings, a theo- retically and practically sound effort is needed to un- derstand the differen t c haracteristics – and emergen t comm unities – of learners that comm unicate with one another. F ortunately , the problem of inferring com- m unities, or more generally , latent features in datasets has b een s tudied across domains (e.g., Holmes et al., 2012). Indeed, some researc hers hav e begun to explore ho w laten t feature mo dels lik e the mixed-membership sto c hastic block mo del (Airoldi et al., 2008) can be used to explain forum participation and drop out rates (Rose, 2013). In these first attempts to mak e sense of the nature of interaction and learning in MOOC fo- rums, the sheer volu me of thousands of discussion fo- rum p osts has preven ted latent feature analysis from mo delling the c ontent and c ontext of posts – attributes that must b e considered in order to truly understand ho w people comm unicate and in teract in global-scale learning settings. Our efforts aim to contr ibute to the expanding b o dy of literature on MOOCs and the Machine Learning comm unity b y 1) in tro ducing a new con tent-analysed dataset of MOOC forum data; 2) leveraging and v al- idating Bay esian Non-negativ e Matrix F actorization as a robust probablistic generativ e mo del for online discussions; 3) illustrating how the to ols of Machine Learning can not only reveal imp ortan t insights into the nature of discussion in MOOCs, but ho w these to ols may b e lev eraged to design more suitable and effectiv e online learning en vironments. 2 Dataset and Laten t F eature Mo dels 2.1 Con tent Analysis of F orum Data Our primary research ob jectiv e was to lev erage Ma- c hine Learning to infer differen t groups of forum par- ticipan ts based on the con ten t of their discussions, and to explore these groups with resp ect to user-sp ecific digital trace data (suc h as their geographies and course outcomes) captured in the online course environmen t. W e analysed data from a business strategy MOOC of- fered on the Coursera platform in Spring 2013. Nearly 90,000 studen ts registered for the course, whic h lasted for six w eeks and assessed studen ts through a com- bination of weekly quizzes and a final pro ject. The online discussion forum was comprised of a num b er of sub-forums, whic h in turn had their own sub-forums or user-generated discussion threads that contained p osts or commen ts. There w ere ov er 15,600 p osts or com- men ts in the discussion forum, generated by nearly 4,500 learners. Over 15,000 learners viewed at least one discussion thread in b oth instances, contributing to 181,911 total discussion thread views. W e conducted qualitativ e con tent analysis on nearly 6,500 p osts from this course – to our kno wledge, an un- preceden ted undertaking to date in MOOC researc h. Con tent analyses ha ve sometimes bee n used in online learning research, y et at m uch smaller scales than pre- sen ted here (e.g. De W eav er et al. 2006). The con tent analysis sc heme for the present study was developed based on b oth existing academic literature and pre- liminary observ ations of online course discussions. W e selected five dimensions to capture key aspects of in teraction and learning processes. The first dimension (learning) was used to collect data about the exten t to whic h knowledge construction o ccurred through dis- cussions, categorising each p ost using one of nine cate- gories, ranging from no learning, through to four t yp es of sharing and comparing of information, to more ad- v anced stages of kno wledge construction suc h as nego- tiation of meaning (Gunaw ardena et al., 1997). The second dimension iden tified communicativ e in tent in the forums, selecting from five categories: argumen- tativ e, resp onsiv e, informativ e, elicitative and imper- ativ e (Clark et al., 2007; Erkens et al., 2008). The third dimension – affect – gauged levels and relativ e distributions of emotion in discourse, using five co des: p ositiv e / negative activ ating, p ositiv e / negativ e de- activ ating, and neutral (P ekrun et al., 2002). Based on our own observ ations of the forums, we also developed t wo more dimensions: one related to topic, which had 11 categories that reflected all course related topics (e.g. cases, quizzes, readings, arrange offline meet-ups, in tro ductions); and the other a rating of relev ance of the p ost to its con taining thread and sub-forum. Rele- v ance w as rated on a three p oint scale: high relev ance, lo w relev ance and no relev ance. F or simplicity (given the size of the dataset), the unit of analysis selected w as the p ost. The qualitativ e anal- ysis softw are NVivo w as used for lab elling conten t. Co ding w as conducted b y four individuals who trained together o ver the course of t wo sessions and pilot tested the instrument together to enhance reliabilit y . 2.2 Inferring Laten t F eatures W e are in terested in probabilistic generativ e mo dels to infer hidden features in con tent-analysed MOOC fo- rum data for three reasons: 1) in a principled Ba y esian setting, they enable the use of tools – e.g. priors and lik eliho o ds – that are intuitiv ely appropriate and fit- ting for the sp ecific data at hand; 2) they do not require tuning resolution parameters or other v alues that go v ern the existence of communities (unlik e man y mo dularit y algorithms – e.g., Newman and Girv an, 2003); 3) they enable the sim ulation of clustered data, whic h, in the con text of online education, ma y b e particularly relev ant to inform pedagogical practices, course design, and implementation. One of the most widely-used latent feature mo dels is Laten t Dirichlet Allo cation (LDA – Blei et al., 2003), a generativ e mo del for inferring the hidden topics in a corpus of documents (e.g., articles in a newspap er). A key attribute of LDA is that it represen ts a do c- umen t’s soft topic distribution . Blei et al. prop osed v ariational inference for LD A, although subsequent ex- tensions hav e prop osed both collapsed and uncollapsed Gibbs samplers (e.g., Xiao and Stib or, 2010). The Mixed Membership Sto chastic Blo c k (MMB – Airoldi et al., 2008) is another generativ e pro cess that mo dels the soft-membership of items within a set of comm u- nities (or “blo c ks”), further representing how differen t comm unities in teract with one another. The original MMB paper prop osed a v ariational inference scheme based off of the one used for LD A, citing Mark ov Chain Mon te Carlo (MCMC) metho ds as impractical giv en the large n umber of v ariables that would need to b e sampled. In the Bay esian nonparametrics literature, the Indian Buffet Pro cess (IBP – Griffiths and Gharamani, 2005) is p erhaps the most prominen t infinite latent feature mo del, sp ecifying a prior distribution ov er binary ma- trices that denote the latent features characterizing a particular dataset. Similar to LD A and MMB, the IBP enables an observ ation to b e c haracterized by m ultiple features – but it treats the num b er of latent features as an additional v ariable to b e learned as a part of in- ference. Unfortunately , given the large (exponentially- sized) supp ort ov er the distribution of p ossible binary matrices for an y fixed n umber of features, the IBP has prov en intractable for large-scale datasets. The dev elopment of v ariational inference schemes and effi- cien t sampling procedures (Doshi-V elez, 2009) ov er the past few years ha ve enabled inference for simple con- jugate (often linear-Gaussian) mo dels with thousands of data p oin ts. Recen t explorations hav e rev ealed ho w inference in the IBP can b e scaled via submo d- ular optimization (Reed and Ghahramani, 2013), al- though again, b y exploiting the structure of the linear- Gaussian likelihoo d model. While some hav e proposed models and inference sc hemes for the IBP with a Poisson likelihoo d (Gupta et al., 2012; Titsias, 2007), others ha ve turned aw ay from nonparametric mo dels in fav our of greater sim- plicit y and computational efficiency . Non-negativ e Matrix F actorization (Lee and Seung, 1999) is one such metho d used to pro duce a parts-based representation of an N × D data matrix X, i.e. X ≈ WH, where W and H are N × K and K × D matrices, resp ectiv ely . A Bay esian extension to NMF (BNMF) was prop osed b y (Sc hmidt et al., 2008), whic h placed exponential priors on a Gaussian data lik eliho o d mo del, present- ing a Gibbs sampler (Geman and Geman, 1984) for inference. While some of BNMF’s applications hav e adopted fully Bay esian inference pro cedures, others ha ve hav e pursued maximum likelihoo d or maximum a-p osteriori (MAP) estimates, often for computational efficiency . 3 Ba y esian Non-negativ e Matrix F actorization In this work, we apply BNMF for communit y detec- tion, as prop osed b y (Psorakis et al. 2011a) for so cial net works, to understand ho w latent communities can b e inferred among MOOC users based on the conten t of their forum posts. The model informs a b elief ab out eac h individual’s communit y mem b ership b y present- ing a membership distribution o ver possible communi- ties. 3.1 Probabilistic Generativ e Mo del Our data can b e represented as an N × D matrix C where eac h row represents a learner n that has posted at least once in the course’s online forums and eac h col- umn d represen ts a particular conten t lab el for each of the five dimensions describ ed in the previous section (for example, one category in the Kno wledge Construc- tion dimension is “statem en t of observ ation or opin- ion”). Each en try of C, c nd , is 1 if learner n has made at least one post assigned a conten t label of d , and 0 otherwise. Hence, C is a binary matrix (our conten t analysis sc heme allo wed each p ost to b e lab elled with only one category per dimension – how ev er, users with m ultiple p osts may be c haracterized by man y different categories). C depicts a bipartite le arner-to-c ate gory netw ork. Giv en our interest in uncov ering laten t groups of learn- ers based on the category lab els of their p osts, we adopt the conv en tion from (Psorakis et al. 2011b) and compute a standard w eigh ted one-mo de pro jec- tion of C on to the set of no des represen ting learners, i.e. { n i } N i =1 . The resultant N × N matrix X has en tries x ij = P D d =1 c id c j d , i.e., the total num b er of shared categories across all p osts made by learners i and j . It is imp ortant to note that connections b e- t ween learners i and j in this adjacency matrix do not necessarily depict comm unication betw een them; instead, they indicate similar discussion contributions as defined by the conten t category lab els assigned to their p osts. W e assume that the pairwise similarities describ ed b y X are drawn from a P oisson distribution with rate ˆ X = WH, i.e. x ij ∼ P oisson( P K k =1 w ik h kj ), where the inner rank K denotes the unkno wn num ber of comm unities and each element k for a particular ro w i of W and column j of H indicates the extent to which a single comm unity contributes to ˆ x i,j . In other words, the exp ected num ber of categories that t wo individuals i , j share across their p osts, ˆ x i,j , is a result of the degree to whic h they produce similar discussion conten t. T o ad- dress the fact that the num b er of comm unities K is not initially kno wn, we place automatic r elevanc e determi- nation (MacKay , 1995) priors β k on the laten t v ari- ables w ik and h kj , similar to (T an and F` ev otte, 2009), whic h helps ensure that irrelev ant comm unities do not con tribute to explaining the similarities enco ded in X. The join t distribution ov er all the mo del v ariables is giv en b y: p (X,W,H, β ) = p (X | W,H) p (W | β ) p (H | β ) p ( β ) (1) And the posterior distribution ov er the mo del param- eters given the data X is: p (W,H, β | X) = p (X | W,H) p (W | β ) p (H | β ) p ( β ) p (X) (2) 3.2 Inference and Cluster Assignmen t Our ob jective is to maximize the model posterior giv en the data X, which is equiv alen t to minimising the neg- ativ e log posterior (i.e., the n umerator of equation (2)) since p (X) is not a random quan tity . Like (Psorakis et al. 2011a), we represent the negative log p osterior as an energy function U: U = – log p (X | W,H) – log p (W | β ) – log p (H | β ) – log p ( β ) (3) The first term of U is the log-likelihoo d of the data, p (X | W,H) = p (X | ˆ X ), whic h represen ts the probability of observing similar pos t conten t b et ween t wo users i and j represen ted by x ij , giv en an expected (or Poisson rate) of ˆ x ij . The negative log-lik eliho o d is given b y: – log p (X | ˆ X) = – P N i =1 P N j =1 log p ( x ij | ˆ x ij ) = P N i =1 P N j =1 x ij log x ij ˆ x ij + ˆ x ij − x ij + 1 2 log (2 πx ij ) + const. (4) F ollo wing (T an and F ` evotte, 2009; Psorakis et al. 2011a), we place indep enden t half-normal priors o ver the columns of W and rows of H with zero mean and precision (inv erse v ariance) parameters β ∈ R K = [ β 1 ,..., β K ]. The negative log priors are: – log p (W | β ) = – P N i =1 P K k =1 log HN ( w ik ; 0 , β − 1 k ) = P N i =1 P K k =1 ( 1 2 β k w 2 ik ) − N 2 log β k + const. (5) – log p (H | β ) = – P K k =1 P N i =1 log HN ( h ki ; 0 , β − 1 k ) = P K k =1 P N i =1 ( 1 2 β k h 2 ki ) − N 2 log β k + const. (6) Eac h β k con trols the imp ortance of communit y k in explaining the observed in teractions; large v alues of β k denote that the elements of column k of W and row k of H lie close to zero and therefore represen t irrelev ant comm unities. F urther to (Psorakis et al. 2011a), we assume the β k are indep enden t and place a standard Gamma distribution ov er them, yielding the following negativ e log hyper-priors: - log p ( β ) = – P K k =1 log G ( β k | a, b ) = P K k =1 ( β k b − ( a − 1) log β k ) + const. (7) The ob jective function U of Eq. (3) can be expressed as the sum of Equations (4), (5), (6), and (7). T o opti- mize for W, X, and β , w e use the fast fixed-p oin t algo- rithm presented in (T an and F` ev otte, 2009; Psorakis et al., 2011a) with algorithmic complexity O( N K ), whic h inv olves consecutive up dates of W, H, β un til con vergence (e.g. a maximum n umber of iterations) CD-BNMF (X; K 0 ; a ; b ) 1 for i = 1 to n iter do 2 H ← ( H W > 1+ β H )W > ( X WH ) 3 W ← ( W 1H > 1+ W β )( X WH )H > 4 β k ← N + a − 1 1 2 ( P i w 2 ik + P j h 2 kj )+ b 5 end for 6 K ∗ ← # nonz ero col umns of W or r ows of H 7 return W ∗ ∈ R N × K ∗ + , H ∗ ∈ R K ∗ × N + Figure 1: Comm unity Detection using Ba yesian NMF. has b een satisfied. The pseudo co de for this pro cedure is presented in Figure 1. In the case of our application, W ∗ = H > ∗ since X is sym- metric. Each elemen t w ∗ ik , or h ∗ ki denotes the de gr e e of p articip ation of individual i in cluster k while eac h nor- malized row of W ∗ (or column of H ∗ ) expresses each no de’s soft-memb ership distribution o ver the p ossible clusters. This soft-mem b ership provides more context to our b elief about a no de’s cluster mem b ership, whic h w e can mo del and explore explicitly if desired. 4 Results 4.1 Mo del Benc hmarking In order to ev aluate the BNMF mo del and inference sc heme’s abilit y to represent the data, we computed the negativ e log likelihoo d (NLL) and ro ot mean- squared error (RMSE) of held-out test data against the nonparametric linear P oisson gamma mo del (LPGM) of (Gupta et al., 2012). The LPGM is a latent feature mo del that treats the n umber of hidden clusters as a v ariable to b e learned during inference, leveraging an Indian Buffet Pro cess prior ov er a infinite-dimensional binary hidden feature matrix. The LPGM mo del spec- ifies: X = (Z ◦ F)T + E Here, X is the N × D matrix of observ ations; Z is the N × K binary latent feature matrix with entry i, k = 1 iff feature k is represented in datum (i.e., learner) i ; T is a non-negativ e K × D matrix illus- trating the represenation of each dimension d ∈ D in feature k ∈ K ; F is an N × K non-negativ e matrix indicating the strength of participation of i in feature k ; E is the reconstruction error with rate λ such that E ij ∼ Poisson( λ ); and ◦ is the Hadamard element-wise pro duct op erator. Giv en the scalabilit y issues of the IBP , w e ev aluated b oth BNMF and LPGM on 20 randomly-selected 50 BNMF LPGM Pred-Avg Pred-0 RMSE 0.4647 1.2199 0.9330 1.5823 NLL 251.97 355.22 324.74 – T able 1: RMSE and NLL results for the BNMF, LPGM, Pred-Avg, and Pred-0 mo dels. Bold v alues indicate the strongest predictiv e performance on held- out test data. × 50 subsets of real-world data b y comparing the ro ot mean squared error (RMSE) and negativ e log lik eliho o d (NLL) of held-out test data. Eac h 50 × 50 subset w as determined by randomly sampling the ro ws and corresp onding columns of real-w orld con ten t- analysed data, and for eac h row, 10% of entries were randomly selected for hold-out, with the remainder used for training. Inference on the infinite mo del was p erformed via 5000 iterations of Gibbs sampling, with no samples discarded for burn-in. F or comparison pur- p oses, we computed the RMSE and NLL of a na ¨ ıv e mo del (Pred-Avg) that predicts the arithmetic mean of the training data for eac h held-out data p oint, as w ell as the RMSE for a na ¨ ıv e benchmark (Pred-0) that alw ays predicts 0 for all held-out data (b ecause of the 0 prediction, computing the NLL for this na ¨ ıve model w ould inv olv e rep eatedly ev aluating a Poisson likeli- ho od with rate λ = 0, ultimately yielding ∞ ). T able 1 summarizes the results, whic h reveal that the pro- p osed BNMF mo del and inference sc heme has greater predictiv e accuracy than its nonparametric IBP coun- terpart (confined to a finite num ber of sampling iter- ations) and b oth na ¨ ıve approaches 1 . Moreov er, giv en its computational tractability (taking seconds to run on the full dataset, versus days for the LPGM), BNMF offers a fav ourable generative mo del for extracting la- ten t features from online discussion forum data. 4.2 Exploring Extracted Comm unities Studen ts in the business strategy course were en- couraged to interact through its online discussion forum, which was segmen ted into multiple sub- forums. Tw o sub-forums aimed at promoting learner engagemen t and interactions w ere conten t-analysed and explored for laten t features: Cases and Final Pro jects. The Cases sub-forum facilitated weekly dis- cussions ab out a real company and its business chal- lenges/opp ortunities (for example, in week 1, the se- lected compan y was Go ogle, and one of the questions w as “Do y ou think Go ogle’s industry is a comp et- 1 the v alues presented in the table are generated by tak- ing the arithmetic mean of the RMSE and NLL, computed for eac h of the 20 differen t subsets, with different data held- out for each subset. itiv e market, in the technical sense? Do es Google ha ve a sustainable competitive adv antage in in ternet searc h?”). The Final Pro ject sub-forum facilitated questions, debates, and team formation for the final strategic analysis assignmen t. The remaining sub- forums w ere: Questions for Professor, T echnical F eed- bac k, Course Material F eedback, Readings, Lectures, and Study Groups. Since participation in m ultiple sub-forums w as mini- mal (in most cases, no more than 10% of participan ts in one sub-forum participated in another), w e explored the latent features of comm unication and the c harac- teristics of these underlying communities in both sub- forums indep endently of one another. Learners were assigned to inferred communities by computing maximum a-posteriori (MAP) estimates for W and H as describ ed in section 2 and greedily assign- ing each learner i to the comm unity k ∗ i to which it “most” b elongs, i.e. k ∗ i = argmax k ∈ K w ik . In repeated executions of the BNMF pro cedure, differen t comm u- nit y assignments w ere computed for some learners due to random initializations of W and H as w ell as n umer- ical precision issues that affected the group allo cation step. T o mitigate this, we ran the algorithm 100 times and used the factor matrices with the highest data lik eliho o d to compute the final allocations. Our analysis of extracted communities sough t to un- derstand the demographics, course outcomes, broader forum b ehaviours and types of p osts for eac h of its constituen t learners. 4.2.1 Cases sub-forum The Cases sub-forum had 1387 unique participan ts that created nearly 4,100 p osts or comments. W e used BNMF to detect laten t comm unities based on the learning and dialogue acts reflected in these p osts, as this particular sub-forum w as set up for participan ts to practice the to ols and frameworks they learned in the course, and so, the learning and dialogue dimen- sions were selected to reveal the w ays in whic h p eople used the forums to engage with one another and con- struct knowledge. F our learner comm unities emerged, con taining 238, 118, 500, and 531 p eople, resp ectiv ely . W e describ e these comm unities as committed crowd engagers, discussion initiators, strategists, and indi- viduals, resp ectively . Comm unity 1 (committed cro wd engagers) . P articipants in this group tended to engage with oth- ers in the forum. Of all the groups they contributed the most resp onsive dialogue acts at 43% of total p osts, and the second highest n umber of informa- tiv e (8%) and elecitive (5%) statements. In terms of learning, they tended to achiev e quite similar lev els of higher-order knowledge construction to groups 2 and 3. These participants read and posted the most of all four groups. 45% of the group’s participants passed the course – significan tly more than an y other group (p < 0.05 2 ). Interestingly , mem b ers of this group were lik ely to b e from W estern continen ts, with a larger prop ortion of Europ eans (26.1%), alb eit only signifi- can tly greater than the other groups at the p < 0.1 level. Nearly 31% had at least a Master’s degree – similar to group 3. It is reasonable to suggest that this group found the forums an imp ortan t part of their learning and used it as they sough t to formally pass the course. Comm unity 2 (discussion initiators) . Most no- table for this group was its level of elicitativ e dialogue acts – which characterized ov er 48% of its participan ts’ p osts. Morever, 24% of their posts did not in volv e learning, a significan tly greater proportion than the other groups (p < 0.07 compared to group 1; p ≈ 0 com- pared to groups 3 and 4). Still, members of this group had a larger prop ortion of p osts reflecting higher-order learning than the other groups (8.0%). In terestingly , this group had a significantly lo wer pass rate than groups 1 and 3 (25%, p < 0.05), but this could b e ex- plained to a large exten t by the high num ber of people who did not submit a final pro ject (67%, similar to group 4). Members of this group viewed few er discus- sion threads and contributed few er posts than groups 1 and 3. Geographically sp eaking, a significantly higher prop ortion of this group’s mem b ers w ere located in Asia in comparison to the other three (31%, p < 0.01). This could suggest that geography pla yed an imp or- tan t role in motiv ating discussion. Indeed, the more elicitativ e nature of dialogue in this group may suggest cultural differences in interpretations of, or resp onses to, v arious conv ersation topics. Comm unity 3 (strategists) . In many w ays, p eople in this group were similar to group 1. They had sim- ilar lev els of higher-order learning and tended to b e resp onsiv e to others’ comments. How ev er, they had a greater prop ortion of argumentativ e statemen ts (55%) and rarely had p osts that reflected no learning (1.6%). P eople in this group w ere second most likely to pass the exam (36.2%) and second most likely to try to pass, but ultimately fail (6.4%). They tended to b e similarly educated to those in group 1 – with nearly 30% receiving at least a Master’s degree. They view ed and contributed to the forums the second most num- b er of times, but this was still significantly less than group 1 (p ≈ 0). Com bined, these characteristics sug- gest that studen ts in group 3 w ere more strategic in their approaches, using the Cases sub-forum only as needed to ac hieve their learning goals. 2 W e used the nonparametric Krusk al-W allis one-wa y analysis of v ariance to test for statistical significance. Comm unity 4 (individualists) . P eople in group 4 w ere highly distinctive in their large prop ortion of ar- gumen tative statements (85%). They had a smaller prop ortion of posts featuring higher-order learning (3.7%) compared to groups 1 - 3. They read and p osted in the forums less than any other group (significan t at p ≈ 0 compared to groups 1 and 3). They w ere the most lik ely to not submit a final pro ject (68%) a similar n umber to group 2. Of all the groups, participants in this group had the smallest prop ortion of p eople attain at least a Master’s degree (23.2%, p < 0.05 compared to groups 1 and 3). These indicators may suggest a num- b er of p ossibilities: that mem b ers of this group were the most likely to drop out of the course of all four groups, may hav e had limited exp erience of using fo- rums to construct their kno wledge, or simply preferred to learn individually . Figure 2 shows the dialogue acts and geographic lo ca- tions of the members of each group. 4.2.2 Final Pro ject sub-forum The Final Pro jects sub-forum had 1256 unique partic- ipan ts creating nearly 2,400 p osts or commen ts. W e selected the comm unication and topic lab els as inputs in to BNMF b ecause of the nature of the sub-forum: it w as a place for participan ts to find others to discuss their individual final pro jects with prior to the submis- sion. Therefore, how p eople engaged with each other and the topics of their engagements were central to this setting. W e detected 5 comm unities with 296, 50, 611, 45, and 237 individuals, which w e c haracterised as: in- strumen tal help seek ers, careful assessors, communit y builders, fo cused ac hievers, and pro ject supp ort seek- ers, resp ectively . 3 Comm unity 1 (instrumental help seekers) . P ar- ticipan ts in this group had a high prop ortion of elici- tativ e dialogue acts (64%) and primarily discussed the final pro ject (83%). On a verage, they posted more than groups 2 and 4 and their amount of views of the forum w ere relativ ely low (similar to groups 4 and 5). The prop ortion of p eople who passed w as signifi- can tly low er than in groups 2, 3 and 4 (41%, p < 0.01). P eople in this group w ere also more likely to submit and fail the final pro ject than clusters 3 and 5 (14%, p ≤ 0.05). There w ere fewer people with p ostgradu- ate qualifications compared to groups 3 and 5 (20%, p < 0.01). These trends suggest that members of this comm unity sought help by asking questions and dis- cussing the final pro ject with their peers, but still did not pass the course. 3 17 individuals were assigned to their own groups; for the purp oses of analysis, we only in v estigated clusters with at least tw o members. (a) (b) Figure 2: Plot (a) illustrates the dialogue acts represen ted in the posts made by learners b elonging to each comm unity , and plot (b) depicts their geographic lo cations. The geographies of some learners are “unknown” due to tec hnical errors in data collection in the online learning environmen t. Comm unity 2 (careful assessors) . P articipants in this group had the highest prop ortion of elicitative di- alogue acts out of all of the groups (71%), but in con- trast to group 1, the focus of their posts was about the p eer review pro cess (87%). They viewed more p osts on av erage than groups 1, 4, and 5, but only groups 4 posted fewer comments on av erage. Th us, it seems that participan ts in this group used the forums to lo ok for answers to questions they had ab out peer review, and only p osted again if necessary . Lik e group 4, a high proportion of learners passed the course, com- pared to groups 1, 3, and 5 (p < 0.05). These patterns suggest that this group needed to know more ab out the p eer assessmen t pro cess, but that its members were v ery strategic in their use of this sub-forum to obtain necessary information. Comm unity 3 (comm unity builders) . P artici- pan ts in this group were distinctiv e in the prop ortion of p osts that were resp onsive to others (55%). In contrast to the other groups, the focus of their discussions were spread across final pro jects and p eer review. Interest- ingly this group seemed the most engaged of groups in the forum, being the most lik ely to view and p ost in this sub-forum of all participants in other groups (p < 0.05, p < 0.001, resp ectively). Likewise, the a v erage length of p osts submitted by supp orters (712 words) w as mark edly higher than in an y other group (Group 1 had the 2nd highest av erage of 382 w ords – p < 0.001). Their pass rate (51%) was higher than clusters 1 and 5 (p < 0.01), but low er than 2 and 4 (p < 0.05), partly due to the high prop ortion of learners (41%) that did not submit a final pro ject. This suggests that participan ts in group 3 were more interested in exc hanging ideas with others as opposed to receiving formal ackno wl- edgemen t or recognition for passing the course. Comm unity 4 (fo cused achiev ers) . Participan ts in this group were distinctive as they had a higher pro- p ortion of argumentativ e dialogue acts (68%). While most focus was on p eer review (70%), many p osts also discussed course outcomes and certificates (20%). They had the highest proportion of p osts that evi- denced some form of learning (32%). They p osted the least (on av erage, 2.5 times), and had the smallest a verage p ost size (146 w ords) and n umber of thread views views (38), b oth statistically significant only when compared to group 3 (p < 0.05). Interestingly , they had the highest prop ortion of participants sub- mit a final pro ject and pass the course (76%, p < 0.01 compared to groups 1, 3, and 5), yet a similar propor- tion to group 1 who submitted but still failed (13%). F urthermore, they comprised a group that show ed the most emotion in their p osts (20%) of all the groups. These patterns suggest a very fo cused group of par- ticipan ts who only used the forums when necessary to ac hieve their goals – and to express b oth joy and un- happiness with their own course outcomes. Comm unity 5 (pro ject supp ort seek ers) . P ar- ticipan ts in this group were similar to those in group 1, although they were distinguished b y a high prop or- tion of imp erative dialogue acts (50%) and organizing virtual meet-ups (45%). The a verage num ber of dis- cussion thread views was relativ ely low (40 - similar to groups 1 and 4); moreov er, participan ts made p osts more often than groups 2 and 4, alb eit not with sta- tistical significance. This pattern suggests that par- ticipan ts in this group were seeking supp ort and op- p ortunities for collaboration on the final pro ject. In- terestingly , this w as the only group where significan t differences were found in geographic region: there were more p eople from South America in this group com- pared to 3 (p < 0.01), whic h ma y indicate a wish for p eople from the same part of the world to collabo- rate. While this group had a higher num ber of partic- ipan ts with p ostgraduate degrees than group 1 (29%, p < 0.05), they had the low est pass rate out of all other groups (32%, p < 0.05), partly explained b y having the highest prop ortion of participants who did not submit a final pro ject (57%, p < 0.05). Figure 3 sho ws the discussion topics and course out- comes of the members of each group. 5 Discussion Using BNMF to extract laten t features from the dataset and subsequently exploring the comp osition of these features reveals that the different sub-forums in MOOCs offer participants different wa ys to engage with course con tent – and each other. In our analysis, w e see that the cases sub-forum is actively facilitating sub ject sp ecific learning to some degree, and the final pro jects sub-forum is more geared tow ards so cial, in- strumen tal and practical asp ects of the learning pro- cess. The distinctiv ely different interaction patterns that characterize the groups in each sub-forum indi- cate that learners hav e very different needs and ex- p ectations of the discussion forums, and these needs m ust b e considered in order to truly understand ho w to supp ort learning in massiv e open online courses. The differen t profiles or comm unities iden tified in eac h of the forums relate v ery well to existing educational researc h. Discussion forums encourage participants to enhance their understanding through discussing sp e- cific questions with others. P articipants can, to a large exten t, choose for themselves ho w m uch they wish to use the forums to construct knowledge together, i.e. adopting a more so cio-cultural approach to learning, or use the forums as a w ay to reflect on their o wn ideas, more in-line with cognitiv e and so cial construc- tivist approach to learning (Stahl, 2006). In the four comm unities observ ed within the Cases sub-forum, we see this from the most individual learners (individual- ists) to the most collab orativ e (committed crowd en- gagers). Similarly , in the Final Pro jects sub-forum, w e see p eople leveraging the cro wd in different wa ys to supp ort their information-seeking and help-seeking b eha viours. Groups 1 (instrumental help seek ers) and 5 (pro ject supp ort seekers) in particular turn to the cro wd for support. Learners in Group 3 (comm unity builders) use the forum to enhance their o wn exp ertise and identit y b y exc hanging ideas with others. Those in group 2 (careful assessors) view the forum as a more in- formational – effectiv ely , a text-based – resource. The sheer scale of the forums and confusion ab out exp ec- tations may hav e encouraged learners to engage in a m ultitude of w ays – producing an eclectic mix of learn- ing theories in action. It is not p ossible to use the data and corresp onding results to make judgements ab out whic h of our pro- files lead to the most p ositiv e learning outcomes, as traditional educational outcomes may not necessarily b e used to understand MOOCs (Kizilcec et al., 2013). Y et, it is clear that different groups ma y need v arying kinds of support in order to help them achiev e their learning goals (ho wev er they define them). F or example, the individualists in the Cases forum ma y simply prefer to learn individually and just use the group as a wa y to present their ideas to the world, or they may hav e had challenges in engaging fully within the forums. If it is the latter, then this group requires additional supp ort in order to learn through discus- sions. The fact that this group has a lo wer prop ortion of p ostgraduate qualifications relative to other groups and lo wer pass rates may warran t further exploration. Similarly , in the Final Pro jects forum the instrumen- tal help seekers asked man y questions about the final pro jects, y et giv en the relatively low prop ortion of p eo- ple who passed, it appears that these requests for help w ere unrequited. Thus, clearer information – or wa ys of accessing information about assessmen ts – w ould b e b eneficial for this group. There are a n um b er of cultural trends that emerge from the data that warran t further consideration. F or example, in the Cases sub-forum, group 2 (discussion initiators) contained a relatively high prop ortion of p eople from Asia. This suggests that people in the same regions tend to communicate with one another in a similar fashion. In the same vein, a relativ ely high proportion of group 5 (pro ject support seekers) in the Final Pro jects sub-forum – who used the dis- cussion space to seek groups for the final assignment – w ere from South America. While these con tinental regions are massiv e in their own right, geographic dis- crepancies in the inferred communities further suggest the p otential influence of cultural differences, p ersp ec- tiv es, and preferences in educational con texts. Ex- ploring these influences ma y enable researc hers and practitioners to b etter facilitate local connections and meet-ups in the otherwise global-scale online learning setting. Finally , it is imp ortant to note the flexibility and p o- ten tial for practical implemen tation afforded by our computational toolset of c hoice. BNMF’s specifica- tion of a robust probabilistic generative mo del capa- ble of representing the conten t-lab elled data well, as v alidated against the LPGM and other b enchmarks, (a) (b) Figure 3: Plot (a) illustrates the discussion topoics represen ted in the p osts made b y learners b elonging to eac h comm unity , and plot (b) depicts their course outcomes. The outcomes of some learners are “unknown” due to tec hnical errors in data collection in the online learning en vironment. mak es it a prime candidate to serve as a communit y de- tection (and p erhaps, simulation) tool geared tow ards detecting posting behaviours and laten t learner groups in online courses. Coupled with its low computational o verhead, it is possible that in future learning plat- forms, algorithms like BNMF could run on cloud-based services in real-time during a course to deliv er v alu- able insigh ts to course staff and students, ultimately impro ving learning exp eriences and outcomes. 6 Conclusion This paper demonstrates ho w laten t feature models can reveal underlying structures in the conten t of dis- cussions in massiv e open online courses. W e in tro- duced a new con tent-analysed set of MOOC forum data and used Bay esian Non-negative Matrix F actor- ization with a computationally efficie n t and highly scalable inference scheme to cluster users based on the learning, dialogue acts, affect, topic, and local rele- v ance of their p osts. By exploring the underlying user groups in tw o sub-forums with relativ ely high levels of engagemen t and interaction, w e uncov ered statisti- cally significant differences in the demographics, p ost con tent, course outcomes, and engagemen t of learners within each group – enabling the creation of learner profiles that c haracterise discussion forum use. These findings are not only important because of their impli- cations for the Education communit y , but also b ecause they demonstrate how principled probabilistic gener- ativ e modelling and inference can enable the Machine Learning comm unity to explore, and mo del, n uanced, large-scale learner data from MOOCs. The ability to dev elop strong generativ e mo dels and computation- ally efficient inference sc hemes for educational data promises to adv ance insights in online learning that can help impro ve course design and p edagogical prac- tices. These scalable and robust mo dels will b e cru- cial inputs into the learning platforms of the future, equipp ed to cater to the needs of a diverse, global b o dy of lifelong learners. Ac knowledgemen ts The authors w ould like to thank the MOOC Research Initiativ e for enabling this interdisciplinary work, as w ell as the Universit y of Virginia and Coursera for their support in accessing relev ant datasets. Thanks also to Chris Davies and Bav Radia in Oxford’s De- partmen t of Education for their help in conten t anal- ysis, and T aha Y asseri, Ioannis Psorakis, Rory Beard, T om Gunther, and Chris Lloyd for their insigh ts. Fi- nally , thanks to Sunil Gupta at the Universit y of Deakin for sharing co de for the LPGM. References A. Anderson, D. Huttenlo c her, J. Kleinberg, J. Lesk ov ec (2014). Engaging with Massive Open Online Courses. Pr o c e e dings of the 14th International World Wide Web Confer enc e Committe e . Seoul, Korea. B. De W eav er, T. Schellens, M. V alck e, and H. V an Keer (2006) Con tent analysis sc hemes to analyze tran- scripts of online asynchronous discussion groups: A review. Computers and Educ ation , 46(1): 6-28. C. G. Brinton, M. Chiang, S. Jain, H. Lam, Z. Liu, F. M. F. W ong (2013). Learning ab out social learn- ing in MOOCs: F rom statistical analysis to generativ e mo del. C. N. Guna wardena, C. A. Lo we, and T. Anderson (1997). Analysis of a Global Online Debate and the Dev elopment of an Interaction Analysis Mo del for Ex- amining Social Construction of Kno wledge in Com- puter Conferencing. Journal of Educ ational Comput- ing R ese ar ch , 17(4): 397431. C. Reed and Z. Ghahramani (2013). Scaling the In- dian Buffet Pro cess via Submodular Maximization. C. Rose (2013). Enabling Resilien t Massiv e Scale Op en Online Learning Communities through Mo dels of So cial Emergence. MOOC R ese ar ch Initiative Con- fer enc e , Arlington, TX. D. B. Clark, V. Sampson, A. W einberger, and G. Erk ens (2007). Analytic F rameworks for Assessing Dialogic Argumentation in Online Learning Environ- men ts. Educ ational Psycholo gy R eview , 19(3): 343374. D. Blei, A. Ng, M. Jordan (2003). Latent Dirichlet Allo cation. Journal of Machine L e arning R ese ar ch , 3: 993-1022. D. D. Lee, H. S. Seung (1999). Learning the parts of ob jects by non-negativ e matrix factorization. Natur e , 401: 788-791. doi:10.1038/44565. D. F. Nob el (1998). Digital diploma mills: the au- tomation of higher education. Scienc e as Cultur e , 7(3): 355-368. D. J. C. Mack ay (1995). Probable netw orks and plau- sible predictions a review of practical Bay esian mo dels for sup ervised neural net works. Network: Computa- tion in Neur al Systems , 6(3):469505. E. Airoldi, D. M. Blei, S. E. F einberg, E. P . Xing (2008). Mixed Mem b ership Sto chastic Blo c kmo dels. Journal of Machine L e arning R ese ar ch , 9: 1981-2014. F. Doshi-V elez (2009). The Indian Buffet Pr o c ess: Sc alable Infer enc e and Extensions (Master’s Disserta- tion). Univ ersity of Cambridge, Cambridge, UK. G. Erkens, and J. Janssen (2008). Automatic co ding of dialogue acts in collab oration proto cols. International Journal of Computer-Supp orte d Col lab or ative L e arn- ing , 3(4): 447470. doi:10.1007/s11412-008-9052-6 G. Stahl, T. Koschmann and D. Suthers (2006). Computer-supp orted collab orative learning: An his- torical p ersp ective. In R. K. Sawy er, ed. Cambridge handb o ok of the le arning scienc es . Cambridge, UK: Cam bridge Univ ersity Press, 409-426. H. Xiao, T. Stib or (2010). Efficien t Collapsed Gibbs Sampling F or Laten t Diric hlet Allocation. Journal of Machine L e arning R ese ar ch , 13: 63-78. I. Holmes, K. Harris, C. Quince (2012) Dirichlet Multi- nomial Mixtures: Generative Mo dels for Microbial Metagenomics. PLoS ONE 7(2): e30126. I. Psorakis, S. Rob erts, M. Eb den, B. Sheldon (2011a). Ov erlapping Communit y Detection using Nonnegativ e Matrix F actorization. Physic al R eview E , 83, 066114. I. Psorakis, S. Rob erts, I. Rezek and B. Sheldon (2011b). Inferring so cial net work structure in ecologi- cal systems from spatio-temporal data streams. Jour- nal of the R oyal So ciety Interfac e , 9(76): 3055-3066. L. V aquero and M. Cebrian (2013). The ric h club phe- nomenon in the classro om. Natur e: Scientific R ep orts , pp. 1-8. L. Vygotsky (1978). Mind in So ciety . Harv ard Uni- v ersity Press, Cambridge, MA. M. E. J. Newman, M. Girv an (2003). Finding and ev al- uating communit y structure in net works. arXiv:cond- mat/0308217v1. M. K. Titsias (2007). The Infinite Gamma-Poisson F eature Model. A dvanc es in Neur al Information Pr o- c essing Systems 20 , 1513-1520. V ancouver, B.C. M. N. Sc hmidt, O. Winther, L. K. Hansen (2009). Ba yesian Non-negativ e Matrix F actorization. Indep en- dent Comp onent A nalysis and Signal Sep ar ation L e c- tur e Notes in Computer Scienc e , 5441: 540-547. R. Kizilcec, C. Piece, Schneider, E. (2013). Decon- structing Disengagemen t: Analyzing Learner Subp op- ulations in Massive Op en Online Courses. The 3r d Pr o c e e dings of the L e arning A nalytics and Know le dge Confer enc e , Leuven, Belgium. R. P ekrun, T. Goetz, W. Titz, and R. P . Perry (2002). Academic Emotions in Studen ts Self-Regulated Learn- ing and Achiev ement: A Program of Qualitative and Quantitativ e Researc h. Educ ational Psycholo gist , 37(2), 91105. S. Geman and D. Geman (1984). Stochastic Relax- ation, Gibbs Distributions, and the Ba yesian Restora- tion of Images. IEEE T r ansactions on Pattern Analy- sis and Machine Intel ligenc e , 6(6): 721-741. S. K. Gupta, D. Ph ung, S. V enk atesh (2012). A Non- parametric Ba y esian P oisson Gamma Model for Coun t Data. Pr o c e e dings of 21st International Confer enc e on Pattern R e c o gnition , 1815-1818. Tsubk a Science City , Japan. T. Griffiths and Z. Ghahramani (2005). Infinite latent feature mo dels and the Indian buffet pro cess. T e ch- nic al R ep ort 2005-001, Gatsby Computational Neur o- scienc e Unit . V. T an and C. F ` evotte (2009). Automatic rele- v ance determination in nonnegative matrix factoriza- tion. SP ARS09 - Signal Pr o c essing with A daptive Sp arse Structur e d R epr esentations , 119.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment