데이터 압축 기반 저자식별: 빠른 압축 거리(FCD) 활용
본 논문은 텍스트에서 직접 사전을 추출한 후 사전 교집합을 이진 탐색으로 비교하는 Fast Compression Distance(FCD)를 이용해 저자 식별 및 표절 탐지를 수행한다. FCD는 기존 Normalized Compression Distance(NCD)보다 계산량이 적고, 언어별 전처리만으로 파라미터 없이 적용 가능하다. 영어, 이탈리아어, 독일어 등 5개 언어의 다중 데이터셋에서 실험한 결과, 최신 방법들과 동등하거나 더 높은 정확…
저자: Daniele Cerra, Mihai Datcu, Peter Reinartz
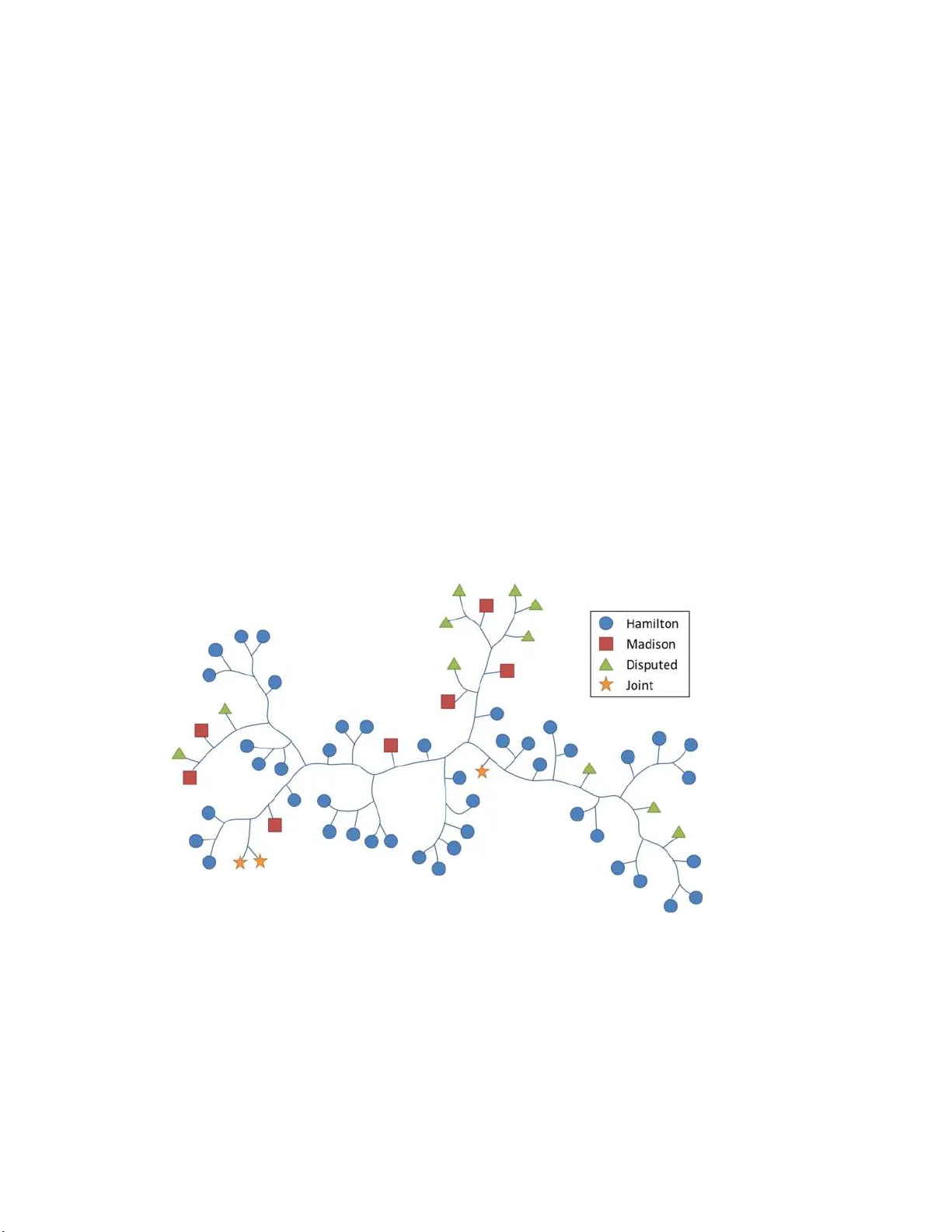
이 논문은 저자 식별과 표절 탐지를 위해 기존의 압축 기반 거리인 Normalized Compression Distance(NCD)의 한계를 극복한 Fast Compression Distance(FCD)를 제안한다. FCD는 텍스트를 단어 단위 토큰화한 뒤 LZW 압축 알고리즘을 변형해 각 문서마다 고유 사전을 생성한다. 사전은 중복 없는 단어 시퀀스로 구성되며, 알파벳 순으로 정렬해 이진 탐색을 통해 두 사전 간 교집합을 빠르게 계산한다. 거리값은 사전 크기 대비 교집합 비율로 정의되며, 이는 두 문서가 공유하는 패턴의 비율을 직접 측정한다.
FCD의 주요 장점은 다음과 같다. 첫째, 사전 생성은 각 문서당 한 번만 수행되므로 전체 쌍에 대해 압축을 반복하는 NCD에 비해 계산량이 크게 감소한다. 둘째, 사전 기반 비교는 압축기의 내부 제한(예: 블록 크기)으로 인한 정보 손실을 피하고, 모든 패턴을 활용할 수 있다. 셋째, 언어별 간단한 전처리(영어는 복수형 ‘s’ 제거, 이탈리아어는 마지막 모음 제거 등)만으로 파라미터 없이 적용 가능해 실용성이 높다.
논문은 세 개의 다국어 데이터셋에 대해 실험을 수행했다.
1. **Federalist Papers**(영어, 85문서)에서는 저자(알렉산더 해밀턴, 제임스 매디슨)와 논쟁 문서를 구분하기 위해 전체 거리 행렬을 만든 뒤 계층적 군집화를 적용했다. FCD 기반 군집은 논쟁 문서를 모두 매디슨 그룹에 정확히 배치했으며, NCD 기반 군집은 문서가 흩어지는 오류를 보였다.
2. **Liber Liber**(이탈리아어, 90문서, 11명 작가)에서는 각 문서를 질의로 사용해 가장 가까운 사전을 찾는 1‑대‑1 매칭 방식을 적용했다. FCD는 97.8%의 정확도로 저자를 맞혔으며, 기존의 Common N‑grams(CNG) 방법은 최고 90% 수준에 머물렀다. 또한 Ziv‑Merhav 거리, 상대 엔트로피, 알고리즘적 Kullback‑Leibler divergence 등 다른 압축 기반 거리와 비교했을 때, FCD는 정확도는 동등하거나 우수하면서도 실행 시간이 크게 단축되었다.
3. **German dataset**(독일어)에서도 동일한 절차를 적용했으며, 결과는 앞선 두 데이터셋과 일관되게 높은 정확도와 낮은 연산 시간을 보여준다.
성능 측면에서, NCD는 zlib 압축기로 전체 거리 행렬을 만드는 데 약 202초가 소요된 반면, FCD는 사전 추출 10초와 교집합 연산 25초로 총 35초에 불과했다. 이는 FCD가 NCD 대비 5~6배 빠른 속도를 의미한다. 또한, 사전 크기가 충분히 큰 경우(약 1000 토큰 이상) FCD는 안정적인 거리 측정을 제공하지만, 매우 짧은 텍스트에서는 사전이 충분히 형성되지 않아 정확도가 떨어지는 한계가 있다.
결론적으로, FCD는 (1) 파라미터 설정이 거의 필요 없고, (2) 언어별 간단한 전처리만으로 다양한 텍스트에 적용 가능하며, (3) 기존 압축 기반 거리보다 계산 효율이 뛰어나 실시간 혹은 대규모 텍스트 분석에 적합한 방법임을 입증한다. 향후 연구에서는 사전 생성 단계에 형태소 분석을 더 정교히 적용하거나, 짧은 텍스트에 대한 보강 기법을 도입해 적용 범위를 확대할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기