Authorship Analysis based on Data Compression
This paper proposes to perform authorship analysis using the Fast Compression Distance (FCD), a similarity measure based on compression with dictionaries directly extracted from the written texts. The FCD computes a similarity between two documents t…
Authors: Daniele Cerra, Mihai Datcu, Peter Reinartz
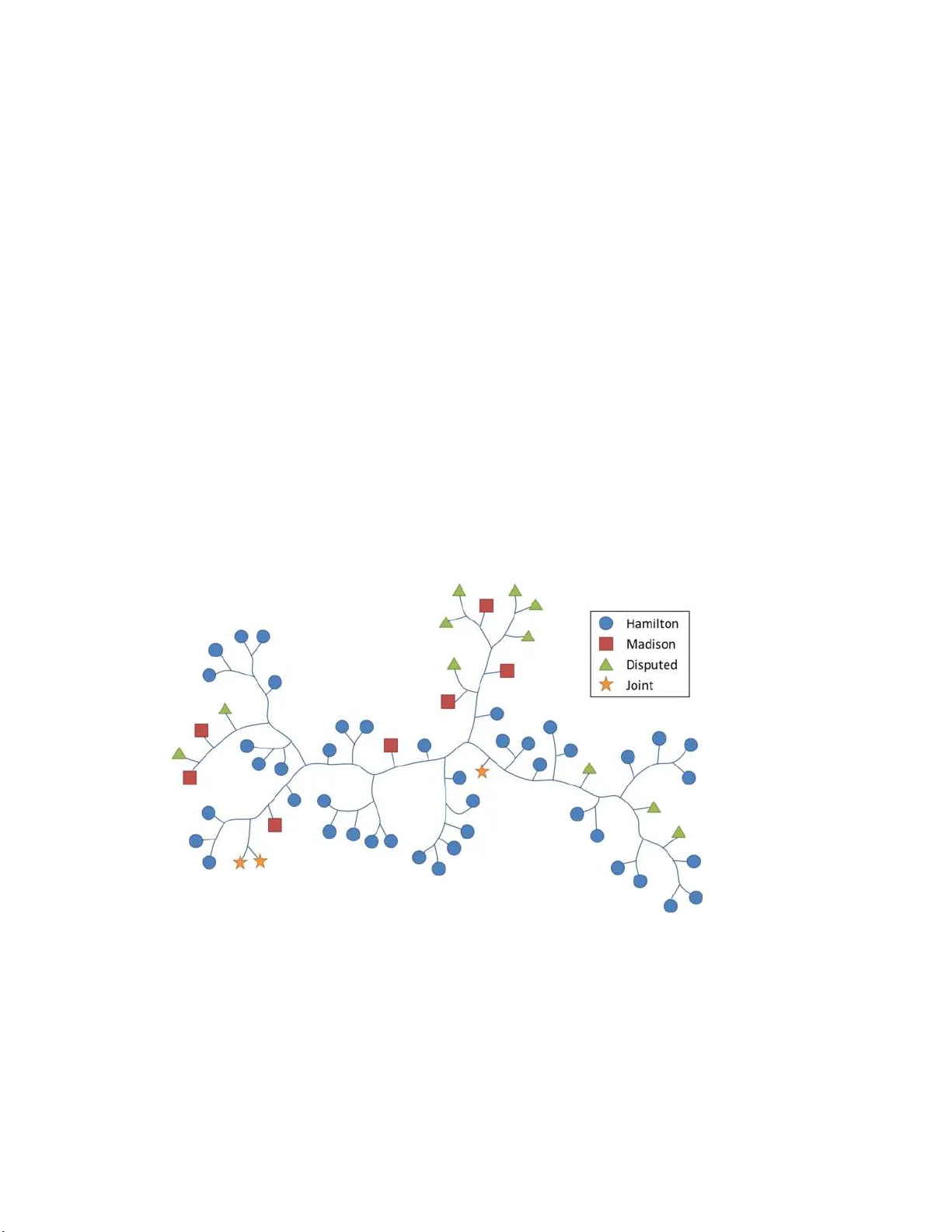
Authorship Analysis based on Data Compr ession 1 Daniele Cerra, Mihai Datcu, and P eter Reinartz 2 German A er osp ac e Center (DLR), Muenchner st r. 20, 82234 Wessling, Germany 3 Corr esp onding author’s email: daniele.c err a@d lr.de, 4 phone: +49 8153 28-1496 , fax: +49 8153 28-14 44. 5 Abstract 6 This pap er prop oses to p erform authorship analysis using the F ast Com- pression Distance (F CD), a similarit y measure based on compression with dictionaries directly extracted from the written texts. The FCD computes a similarit y b et w een tw o do cumen ts thro ug h an effectiv e binary searc h on the in tersection set betw een the tw o related dictionaries. In the rep orted exp eri- men ts the proposed metho d is applied to do cumen ts whic h are heterogeneous in st yle, written in fiv e differen t languag es and coming fr o m differen t histor- ical p erio ds. Results are compara ble to the state of the art and outp erform traditional compression-based metho ds. Keywor ds: Authorship Analysis, Data Compress ion, Similarit y Measure 7 1. In tr o duction 8 The task of automatically recognizing the author of a giv en text finds 9 sev eral uses in practical applications, ranging from authorship attribution to 10 plagiarism detection, and it is a c hallenging one (Sta matatos, 20 0 9). While 11 the structure of a do cumen t can b e easily inte rpreted b y a mac hine, the 12 Pr eprint submitte d to Pattern R e c o gnition L et ters F ebruary 17, 2014 description of the st yle of each author is in general sub jectiv e, and therefore 13 hard to deriv e in natural language; it is ev en harder to find a description 14 whic h enables a mac hine to automatically tell one author from the other. A 15 literature review on mo dern authorship attribution metho ds, usually coming 16 from the fields of mac hine learning and statistical analysis, is rep orted in 17 Stamatatos (2009); Jo c k ers and Witten (2010); Kopp el et al. (2009); Griev e 18 (2007); Juola (200 6). Among these, algorithms based on similarity measures 19 suc h as Benedetto et al. (2002) a nd Kopp el et al. (2011) are widely emplo ye d 20 and usually assign an anonymous text to the author of the most similar 21 do cumen t in the training data. 22 During the last decade, compression-based distance measures hav e b een 23 effectiv ely applied to cluster texts written b y differen t authors (Cilibrasi and Vit´ an yi , 24 2005) and to p erform plagiarism detection (Chen et al., 2004). Such univ er- 25 sal similarit y measures, of whic h the most w ell-know n is the Normalized 26 Compression Distance (NCD), emp lo y general compressors to estimate the 27 amoun t of shared informat ion b etw een t w o ob jects. Similar concepts are 28 also used b y metho ds using runlength histograms to retriev e and classify 29 do cumen ts (Gordo et al., 2 013). Exp eriments carried out in Oliv eira et al. 30 (2013) conclude that NCD- based metho ds fo r authorship ana lysis outp er- 31 form state-of- t he- a rt classification metho dologies suc h as Supp ort V ector 32 Mac hines. A study on larg er and mor e statistically meaningf ul datasets 33 sho ws NCD-metho ds to b e comp etitive with r esp ect to the state of the art 34 (de Graaff, 2012), w hile Stamatatos (2009) rep orts that compression-based 35 2 metho ds are effectiv e but hard to use in practice as they ar e ve ry slo w. 36 Indeed the univ ersalit y o f these measures comes at a price, as the com- 37 pression algorithm mus t b e run at least n 2 times on n ob jects to deriv e a 38 distance matrix, slo wing down the analysis. F urthermore, as these metho ds 39 are applied to raw data they cannot b e t uned to increase their p erformance 40 on a giv en data type. W e prop ose then to p erfo r m these ta sks using the F ast 41 Compression Distance (FCD) recen tly defined in Cerra and Datcu (2012), 42 whic h pro vides sup erior p erformances with a reduced computational com- 43 plexit y with resp ect to the NCD, and can b e tuned according to the kind 44 of data at hand. In the case of natural texts, o nly FCD’s general settings 45 should b e adjusted a ccording to the language of the dataset, thus ke eping 46 the desirable parameter-free approach typical of NCD. Applications to au- 47 thorship and plagiarism analysis are deriv ed b y extracting meaningful dictio- 48 naries directly from the strings represe nting the data instances and matc hing 49 them. The rep orted exp eriments sho w tha t improv emen ts ov er traditional 50 compression-based analysis can b e dramatic, a nd that the FCD could b e- 51 come a n imp ortant to ol of easy usage fo r the automated analysis of texts, as 52 satisfactory results are achiev ed skipping any parameters setting step. The 53 only exception is an optional text prepro cessing step whic h only needs to 54 b e set once for do cumen ts of a giv en language, a nd do es not dep end on the 55 sp ecific dataset. 56 The pap er is structured as follows . Section 2 in tro duces compression- 57 based similarit y measures and the F CD, whic h will b e v alidated in an arra y 58 3 of experimen ts rep orted in Section 3. W e conclude in Section 4. 59 2. F ast Compression Dist ance 60 Compression-based similarit y measures exploit general off-the-shelf com- 61 pressors to estimate the amount of information shared by an y t wo ob jects. 62 They hav e b een employ ed for clustering and classification on div erse data 63 t yp es suc h as texts and images (W at a nab e et al., 2002), with Keog h et al. 64 (2004) rep orting that they outp erform general distance measures . The most 65 widely kno wn and used of suc h not io ns is the Normalized Compression D is- 66 tance (NCD), define d for any tw o ob jects x and y as: 67 N C D ( x, y ) = C ( x, y ) − min C ( x ) , C ( y ) max C ( x ) , C ( y ) (1) where C ( x ) represen ts the size of x af t er b eing compressed by a com- 68 pressor (such as Gzip), and C ( x, y ) is the size of the compressed v ersion 69 of x app ended to y . If x = y , the NCD is approximately 0, as the full 70 string y can b e describ ed in terms of previous strings found in x ; if x and y 71 share no common information the NCD is 1 + e , where e is a small quantit y 72 (usually e < 0 . 1) due to imp erfections ch aracterizing real compressors. The 73 idea is that if x and y share common infor ma t ion they will compress b etter 74 together than separately , as the compressor will b e able to reuse recurring 75 patterns found in one of them t o more efficien tly compress the other. The 76 generalit y of NCD allo ws applying it to dive rse dataty p es, including na tu- 77 ral texts. Applications to authorship categorization ha ve b een presen t ed b y 78 4 Cilibrasi and Vit´ an yi (2005), while plagiarism detection o f studen ts assign- 79 men ts has b een succesfully carried out b y Chen et al. (2004). 80 A mo dified v ersion of NCD based on the extraction of dictionaries has 81 b een first defined by Macedonas et al. (2008). The adv an tages of using 82 dictionary-based metho ds hav e b een then studied b y Cerra and Datcu (2012), 83 in whic h the authors define a F ast Compression Distance (FCD), and succes- 84 fully apply it to image analysis. The algorithm can b e used for texts analysis 85 as follo ws. 86 First of all, all sp ecial ch aracters suc h as punctuatio n marks ar e r emov ed 87 from a string x , whic h is subsequen tly tok enized in a set of words W x . The 88 sequence of tok ens is analysed by the enco ding a lg orithm of the Lempel- 89 Ziv-W elc h (LZW) compressor (W elc h , 1984), with the difference that w ords 90 rather than c haracters are ta k en into accoun t. The algorithm initializes the 91 dictionary D ( x ) with all the w ords W x . Then the string x is scanned fo r 92 success ively longer sequences o f w o rds in D ( x ) un t il a mismatc h in D ( x ) ta kes 93 place; at this p oint the co de for the lo ng est pattern p in the dictionary is sent 94 to output, a nd the new string ( p + the la st w ord whic h caused a mismatc h) 95 is added to D ( x ). The last input word is then used as t he next starting 96 p oint: in this w a y , successiv ely longer sequence s of w ords are registered in 97 the dictionary and made a v ailable for subsequen t enco ding, with no rep eated 98 en tries in D ( x ). An example f or the enco ding of the string ”TO BE OR 99 NOT TO BE OR NOT TO BE O R WHA T” a f ter toke nizatio n is rep orted 100 in T able 1. It helps to remark that the output of the sim ulated compression 101 5 T able 1: LZW enco ding o f the tokens compo sing the str ing ”TO BE OR NOT TO BE O R NOT TO BE OR WHA T”. The compresso r tries to substitute pa ttern co des refer ring to sequences of words which o ccurred previously in the text. Curren t to k en Next tok en Output Added to Dictionary Null TO TO BE T O TO BE= < 1 > BE OR B E BE OR= < 2 > OR NOT O R OR NOT= < 3 > NOT TO N O T NOT TO= < 4 > TO BE OR < 1 > TO BE OR= < 5 > OR NOT TO < 3 > OR NOT TO= < 6 > TO BE OR WHA T < 5 > TO BE OR WHA T= < 7 > WHA T ♯ W H AT pro cess is not of in terest for us, a s the only thing that will b e used is the 102 dictionary . 103 The patt erns con tained in the dictiona r y D ( x ) a r e then sorted in ascend- 104 ing alphab etical order to enable the binary search of eac h pat t ern in time 105 O ( l og N ), where N is the n umber of en tries in D ( x ). The dictionary is finally 106 stored for future use: this pro cedure ma y b e carried out offline and has to b e 107 p erformed only once for eac h data instance. Whenev er a string x is c hec k ed 108 against a data ba se con taining n dictionaries, a dictionary D ( x ) is extracted 109 from x as describ ed a nd matched ag ainst each of the n dictionaries. The 110 F CD b etw een x and an ob ject y represen ted b y D ( y ) is defined as: 111 F C D ( x, y ) = | D ( x ) | − ∩ ( D ( x ) , D ( y )) | D ( x ) | (2) where | D ( x ) | and | D ( y ) | are the sizes of the relativ e dictionaries, repre- 112 sen ted by the n um b er of en tr ies they contain, and ∩ ( D ( x ) , D ( y )) is the num- 113 6 b er of patterns whic h are found in b oth dictionar ies. W e hav e F C D ( x, y ) = 0 114 iff all patterns in D ( x ) are con t a ined also in D ( y ), and F C D ( x, y ) = 1 if no 115 single pattern is shared b etw een the t w o ob jects. 116 The FC D allow s computing a compression-based distance b etw een t wo 117 ob jects in a faster w ay with r esp ect to NCD (up to one order o f magnitude), 118 as the dictionary for eac h ob ject mus t b e extracted only once and comput- 119 ing the in tersection b et w een t wo dictionaries D ( x ) and D ( y ) is faster tha n 120 compressing the concatenation of x app ended to y (Cerra and Da t cu, 2 0 12). 121 The F CD is also more a ccurate, as it o vercome s drawbac ks such as the lim- 122 ited size of the lo okup tables, whic h are emplo y ed b y r eal compressors f o r 123 efficiency constrain ts: this allow s exploiting all the patterns con ta ined in a 124 string. F urthermore, while the NCD is totally data-driv en, the FCD enables 125 a tok en-based analysis whic h allows prepro cessin g the data , b y decomp os- 126 ing the ob jects in to f ragmen ts which are seman tically relev an t for a giv en 127 data type or application. This constitutes a great adv an tage in the case of 128 plain texts, as the direct analysis of w or ds con tained in a do cumen t and 129 their concatenatio ns allows fo cusing on the relev an t info r mational conten t. 130 In pla in English, this means that the matching of substrings in w o r ds whic h 131 ma y ha ve no semantic relation b et w een them (e.g. ‘butter’ and ‘butterfly’) 132 is preve n ted. Additional impro v emen t s can b e made depending on the texts 133 language. F or the case of English texts, the subfix ‘s’ can b e remo v ed from 134 eac h tok en, while f rom do cuments in Italian it helps to remo ve the last v ow el 135 from eac h w or d: this a voids considering seman tically differen t plurals a nd 136 7 some v erbal forms. 137 A dra wback of the prop o sed metho d is that it cannot b e applied effectiv ely 138 to ve ry short texts. The algorithm needs to find reo ccurring w ord sequenc es 139 in order to extract dictionaries o f a relev an t size, whic h are needed in o r der 140 to find pat t erns shared with other dictionaries. Therefore, the compression 141 of the initia l part of a string is not effectiv e: we estimated empirically 1000 142 tok ens or w ords to b e a reasonable size for learning the mo del of a do cumen t 143 and to b e effectiv e in its compression. 144 3. Exp erimen t al Results 145 The F CD as describ ed in the previous section can be effectiv ely emplo y ed 146 in tasks lik e authorship and plagiarism analysis. W e rep ort in this section 147 exp eriments on four datasets written in English, Italia n, a nd G erman. 148 3.1. The F e der alist Pap ers 149 W e consider a dataset of English texts kno wn as F ederalist P a p ers, a col- 150 lection of 85 p olitical articles written by Alexander Hamilton, James Madi- 151 son and John Jay , published in 1787- 88 under the anonymous pseudon ym 152 ‘Publius’. This corpus is particularly interes ting, as Hamilton and Madison 153 claimed later the authorship o f their texts, but a num b er of essa ys (the o nes 154 n umbered 49-58 and 6 2-63) ha v e b een claimed b y b oth of them. This is a 155 classical dat a set employ ed in the early days of authorship attributio n liter- 156 ature, as the candidate authors are we ll-defined and the texts are uniform 157 8 Figure 1: Subset from a dictiona ry D ( x ) extracted from a sample text x b elonging to the F edera list dataset. 9 in thematics (Stamata tos, 2009). Seve ral studies agreed on assigning the 158 disputed w orks in their en tiret y to Madison, while P a p ers 18-20 ha v e gener- 159 ally b een found to be written jointly b y Hamilton and Madison as Hamilton 160 claimed, even though some researc hers tend to attr ibute them to Madison 161 alone (Jo c ke r s and Witten, 2010; Mey erson , 2008; Adair, 1974). 162 W e analyzed a dataset comp osed of a randomly selec ted n um b er of texts 163 of certain attribution by Hamilton and Madison, plus all the disputed and 164 join tly written essa ys. W e then computed a distance matrix related to the 165 described dataset according to the FC D distance, and p erformed on the 166 matrix a hierarc hical clustering whic h is by definition unsup ervised. A den- 167 drogram (binary tree) is heuristically deriv ed to represen t the distance ma- 168 trix in 2 dimensions thro ugh the applicatio n of genetic alg orithms (Cilibrasi , 169 2007; Cilibrasi and Vit´ an yi, 2005). Results are rep orted in Fig. 2, a nd 170 ha ve b een obta ined using the fr eely a v ailable to ol CompLearn av ailable at 171 Cilibrasi et al. (200 2). Eac h leaf represen ts a text, with the do cumen ts whic h 172 b eha v e more similarly in terms of distances from a ll the others app earing as 173 siblings. The ev aluation is done b y visually insp ecting if texts written by the 174 same authors are correctly clustered in some branc h of the tree, i.e. b y c heck - 175 ing how w ell the texts b y the t w o authors can b e isolated by ‘cutting’ the tree 176 at a conv enien t p o in t. The clustering ag rees with the general interpre tation of 177 the texts: all the disputed texts are clearly placed in the section of the tree 178 con taining Madison’s w orks. F urthermore, the three jointly written works 179 are clustered together and placed exactly b et wee n Hamilto n and Madison’s 180 10 essa ys. W e compare results with the hierar c hical clustering deriv ed from the 181 distance matrix obtained o n the basis of NCD distances (F ig. 3), run with 182 the default blocks ort compression algorithm prov ided b y CompLearn: in this 183 case t he misplacemen ts of the do cumen ts is eviden t, as disputed works are 184 in general closer to Madison t exts but are scattered throughout the tree. 185 3.2. The Lib er Lib er dataset 186 The rise of interest in compression-based metho ds is in part due to the 187 concept o f relativ e entrop y as describ ed in Benedetto et al. (2 0 02), whic h 188 quan tifies a distance b et ween t w o isolated strings relying o n information the- 189 oretical notions. In t his w ork the authors succe sfully p erform clustering and 190 classification o f do cumen ts: one of the considered problems is to automati- 191 cally recognize the author s of a collection comprising 90 texts of 11 know n 192 Italian author s spanning the cen turies XI I I-XX, av ailable at Onlus ( 2003). 193 Eac h t ext x w a s used as a query against the rest of the database, its clos- 194 est ob ject y minim izing the r elat ive en t r o p y D ( x, y ) w as retriev ed, and x 195 w as then assigned to the a uthor of y . In the follow ing exp erimen t the same 196 pro cedure as Benedetto et al. (2002) and a dataset as close as possible hav e 197 b een adopted, with eac h text x assigned to the author of the text y whic h 198 minimizes F C D ( x, y ). W e compare our results with the ones obta ined b y 199 the Common N-grams (CNG) metho d prop osed b y Ke ˇ selj et al. (2003) us- 200 ing the most relev an t 500 , 10 00 and 1500 3-gra ms in T able 2. The FCD 2 01 finds the correct a uthor in 97.8% of the cases, while the b est n-grams setting 202 11 Figure 2: Hierarchical clustering of the F ederalist dataset, derived by a full distance m atrix obtained on the basis of the FCD distance. 12 Figure 3: Hierarchical clustering of the F ederalis t da taset obtained o n the basis of the NCD distance. 13 yields an accuracy of 90%. F or F CD only tw o texts, L’Asino and D isc orsi 20 3 sopr a la prima de c a di Tito Livio , b o th by Niccol´ o Mac hiav elli, are incor- 204 rectly assigned respectiv ely to D an t e and Guicciardini, but these errors may 2 05 b e j ustified: the former is a po em strongly influenced b y D an te (Caesar, 206 1989), while the la t t er w as found similar to a collection of critical notes on 207 the v ery Disc orsi compiled by G uicciardini, who w as Mac hia v elli’s f riend 208 (Mac hiav elli et al., 2002). The N-grams-based metho d also assigns incor- 209 rectly G uicciardini’s notes and a Dante ’s p o em to Mac hiav elli, among others 210 misclassifications. 211 W e also compared our results with an a r ra y of other compression-based 212 similarit y measures (T able 3): our results outp erform b oth the Ziv-Merha v 213 distance (P ereira Coutinho and Figueiredo, 20 05) and the relativ e en trop y as 214 described in Benedetto et al. (200 2), while the algorithmic Kullback -Leibler 215 div ergence (Cerra and Datcu, 2011) obta ins the same results in a consider- 216 ably higher r unning time. Ac curacy fo r the NCD metho d using an array 2 17 of linear compressors rang ed from t he 93.3 % obtained using the bzip2 com- 218 pressor to the 96.6% obtained with t he blo c ksort compressor. Eve n tho ugh 219 accuracies are compara ble and the dataset ma y b e small to b e statistically 220 meaningful, another adv an tage of FCD ov er NCD is the decrease in compu- 221 tational complexit y . While for NCD it to ok 202 seconds to build a distance 222 matrix for the 9 0 pre-formatted texts using the zlib compressor (with no 223 appreciable v ariation when using other compressors), just 35 seconds w ere 224 needed on the same machine for the FCD: 1 0 to extract the dictionaries and 225 14 T able 2: Cla s sification results on the Liber Lib er datas et. Each text from the 11 au- thors is used to query the databa se, and it is consider ed to be wr itten by the author of the most s imilar r etrieved w o rk. The authors’ full names: Dante Alighieri, Gabr iele D’Ann unzio , Gra zia Deledda, An tonio F ogazzaro , F ra nc e sco Guicciardini, Niccol´ o Machi- av elli, Alessandro Manzoni, Luigi Pirandello , Emilio Sa lg ari, Italo Svevo, Giov anni V erga. The CNG method has b een tes ted using the rep or ted amounts of n-gra ms. Author T exts F CD CNG-500 CNG-1000 CNG-1500 Dan te Alighieri 8 8 6 5 7 D’Ann unzio 4 4 4 3 4 Deledda 15 15 15 15 14 F ogazzaro 5 5 4 5 5 Guicciardini 6 6 5 5 5 Mac hiav elli 12 10 8 10 9 Manzoni 4 4 4 4 4 Pirandello 11 11 5 10 8 Salgari 11 11 10 10 9 Sv ev o 5 5 4 5 5 V erga 9 9 6 9 8 T otal 90 88 71 81 78 Accuracy (%) 100 97.8 78.9 90 86.7 the rest to build the full distance matrix. 226 3.3. The P AN Bench mark Dataset 227 W e tested our algorithm on datasets from the t wo most recen t P AN CLEF 228 (2013) comp etitions, whic h provid e b enc hmark datasets for authorship attri- 229 bution. F rom P AN 2013 we selected the author iden tification task describ ed 230 in Juola a nd Stamatatos (2013). In this task 349 training texts are pro vided, 231 divided in 85 problems out of whic h 30 are in English, 3 0 in Greek and 25 232 in Spanish. F or each set of documents written by a single a ut ho r it mus t b e 233 determined if a questioned do cumen t was written b y t he same author or not. 234 Eac h text is approximately 1000 w ords long, whic h is close t o our empirical 235 15 T able 3: Accuracy a nd running time for differ ent compress io n-based metho ds applied to the Lib er Lib er data set. Metho d Accuracy (%) R unning Time (sec) F CD 97.8 35 Relativ e En tr op y 95.4 NA Ziv-Merha v 95.4 NA NCD (zlib) 94.4 202 NCD (bzip2) 93.3 198 NCD (blo c ksort) 96.7 208 Algorithmic KL 97.8 450 estimation of t he minimum size for FC D to find relev an t patt erns in a data 236 instance (Section 2). F or each problem, we consider an unkno wn text to b e 237 written by the same author of a given set of do cumen ts if the av erage FCD 2 38 distance to the la tter is smaller than the mean distance from all do cumen ts 239 of a giv en language. Compared to the p erformance of the 1 8 metho ds re- 240 p orted in Juola and Stamatatos (2013), the F CD finds the correct solution 241 in 72 . 9 % of the cases and yields the second b est results, ranking first for 242 the set o f English pr o blems and fif t h for b oth the Greek and Spanish sets 243 (T able 4 ), outp erforming among others t w o compression-based and sev eral 244 n-grams-based metho ds. It must b e stressed t ha t the FCD to ok a pproxi- 245 mately 38 seconds to pro cess the whole dataset, while the imp osters method 246 b y Seidman (2 013), which r ank ed first in t he comp etition fo r all problems 247 excluded the ones in Spanish, to ok more than 18 hours. F urtherm ore, the 248 latter metho d requires the setting of a threshold, while the F CD skips this 249 step. On the other hand, the con test participan ts had only a small subset of 250 the a v ailable ground truth to test their algorithms. 251 16 Figure 4: Hierarchical c lus tering of pages extra cted fr om Guttenberg PhD thesis . 17 T able 4: Author identification task o f the CLEF P AN 2 013 data set. The dataset contains 349 tr aining texts plus 85 test do cuments o f questio ned a utho r ship, with problems given in English, Gr eek a nd Spanish. The table re p o rts how the FCD ranks co mpared to 18 participants to the P AN 2013 contest. The fir st ranked submission for each problem is rep orted as ‘Best P AN’. T ask F CD Best P AN Rank Ov erall 72.9 % 75.3 % 2 English 83 % 80 % 1 Greek 63 % 83 % 5 Spanish 72 % 84 % 5 W e tested FC D also on the larg est closed-class classification problem 252 (task I) from the 2012 P AN comp etition: op en-class problems w ere no t 253 considered as t he simple classification a lg orithm adopted do es no t allow a 254 rejection class. Using a corpus of 1 4 t est a nd 28 training texts b elonging 255 to 14 differen t authors, t he F CD (using a simple nearest neigh b our classi- 256 fication criterion) assigns correctly 12 out of 14 do cumen ts to their correct 257 authors. Out of the 2 5 whic h to ok part to the comp etition, only 4 metho ds 258 submitted by three gr o ups (Sapk ota and Solorio, 2 012; T a ng uy et al., 201 2; 259 P op escu and Grozea, 2012) outp erformed our metho d (all of them with 13 260 do cumen ts corr ectly recognized). As a comparison, the NCD and trigrams- 261 based CNG ( using the most meaningful 1 000 trigrams p er do cumen t, as this 262 setting yields the b est results in T able 2) assigned 2 and 9 do cumen ts out 263 of 14 to the correct author, resp ectiv ely . The results in T ables 4 and 5 are 264 encouraging, sp ecially if w e consider that the F CD is a general metho d whic h 265 is not sp ecific for the described t a sks. 266 18 T able 5: Classificatio n r esults on ta sk I of the CLEF P AN 2012 dataset. The dataset contains 28 texts b e longing to 14 different authors for tra ining and 14 for testing. The bes t results obtained in the P AN 2012 contest a re repo rted as ‘Best’. Metho d F CD NCD CNG Best Correct (out of 14 ) 12 2 9 13 3.4. The Guttenb er g Case 267 In F ebruary 2011, evidence w as made public that the former German 268 minister Karl-Theo dor zu Gutten b erg had violated the academic co de by 2 69 cop ying sev eral passages of his PhD thesis without pro p erly referencing them. 270 This ev entually led to Gutten b erg losing his PhD title, resigning from b eing 271 minister, a nd b eing nic knamed Baron Cut-and-Paste, Zu Copy b erg a nd Zu 272 Go og leb erg b y the German media (BBC, 2011). Evidence o f the plagiarism 273 and a detailed list of the copied sections and of the differen t sources used b y 274 the minister is a v ailable at GuttenPlag (2011). 275 W e selected ra ndomly t wo sets of pages from this contro v ersial disserta- 276 tion, with the first con taining plag iarism instances, and the second material 277 originally written b y the ex-minister. Then w e p erformed a n unsup ervised 278 hierarc hical clustering on the distance matrix derive d from FCD distances as 279 described in Section 3.1. First attempts made by analyzing single pages fa iled 280 at separating the original pages in a satisfactory wa y , as t he compressor needs 281 a reasonable amount of data to b e able to cor r ectly identify shared patterns 282 b et ween the texts. W e selected then tw o-pages long excerpts from the thesis, 283 with the resulting clustering rep o rted in Fig . 4 sho wing a go o d separation of 284 the texts con taining plag ia rism instances (in red in the picture). The only 285 19 confusion comes from pag es star t ing at 41 with pages starting at 20 , in the 286 b ottom-left pa r t of the clustering. This is justified by the f act that page 41 287 refers to the works of Lo ew enstein, who happ ens to b e the same autho r from 288 whic h part of page 20 w as plag ia rized (Lo ew enstein, 1959 ) . Therefore, the 289 system considers pag e 20 to b e similar to the origina l st yle of the author at 290 page 41. 291 Ev en though the describ ed pro cedure is not able t o detect plagiarism, it 292 can find excerpts in a text whic h a re similar to a g iv en one. If instances o f 293 plagiarized text can b e identified, ob jects close to them in the hierarchical 294 clustering will b e ch aracterized by a similar st yle: therefore, this to ol could 295 b e helpful in iden tifying t exts whic h are most lik ely to ha ve b een copied from 296 similar sources. 297 4. Conclusions 298 This pap er ev alua tes t he p erformance of compression-based similarit y 299 measures on authorship and plagiarism analysis on natural texts. Instead of 300 the w ell- known Normalized Compression Distance (NCD), w e prop ose using 301 the dictionary-ba sed F a st Compression Distance (FCD), whic h decomp oses 302 the texts in sets of reo ccurring com binations of w o rds captured in a dictio- 303 nary , whic h describ e the text regularities, and are compared to estimate the 304 shared informat io n b et we en an y t w o do cumen ts. The rep ort ed exp erimen ts 305 sho w the unive r salit y and adaptability of these metho ds, whic h can b e ap- 306 plied without altering t he general w orkflow to do cumen ts written in English, 307 20 Italian, Greek, Spanish and German. The main a dv antage of the FC D with 308 resp ect to tradit io nal compression-based metho ds, apart from the reduced 309 computational complexit y , is t ha t it yields more accurate results. W e can 310 justify this with t w o remarks: firstly , the FCD should b e more robust since it 311 p erforms a w ord-based analysis, fo cusing exclu siv ely o n meaningful patterns 312 whic h b etter capture the information con tained in the do cumen ts; secondly , 313 the use of a full dictionar y allo ws discarding an y limitation that real compres- 314 sors ha v e concerning t he size of buffers and lo okup tables emplo yed, b eing 315 the size of the dictionaries b ounded only by the num b er of relev an t patterns 316 con tained in the ob jects. A t the same time, the data- driven approach t ypi- 317 cal of NCD is maintained. This a llo ws k eeping a n ob jectiv e, parameter-free 318 w orkflow for all the problems considered in the applications section, in whic h 319 promising results are presen ted on collections of texts in Italian, English, and 320 German. 321 References 322 Adair, D., 1974. F ame and the F ounding F athers. Indianap olis: Lib ert y F und. 32 3 BBC, 2011. German y’s Guttenberg ’delib erately’ plagiarised. 324 URL http://www. bbc.co.uk/ne ws/world- europe- 1 3310042 325 Benedetto, D ., Caglioti, E., Loreto, V., 2002. Language trees and zipping. 326 Ph ysical R eview Letters 88 (4), 48702. 327 Caesar, M., 1989. Dan te, the critical heritage, 1314-1 870. Routledge. 328 21 Cerra, D., Datcu, M., 201 1. Algorithmic relative complexit y . En tropy 13 (4), 329 902–914. 330 Cerra, D., D atcu, M., 20 12. A fa st compression-based similarity measure with 331 applications to con ten t- based image retriev al. Journal of Visual Commu - 332 nication and Image Represen tation 23 (2), 293 – 302. 333 Chen, X., F rancia, B., Li, M., McKinnon, B., Sek er, A., 2004. Shared infor- 334 mation and program plagiarism detection. IEEE T ransactions on Infor ma - 335 tion Theory 50 (7), 1545–1551. 336 Cilibrasi, R., 2007. Statistical inference through da t a compression. Lulu.com 337 Press. 338 Cilibrasi, R., Cruz, A., de Ro oij, S., K eijzer, M., 2 0 02. CompLearn. 339 URL http://www. complearn.or g 340 Cilibrasi, R., Vit´ an yi, P . M. B., 2005. Clustering b y compression. IEEE 341 T ransactions on Information Theory 51 (4), 1523–1545. 342 CLEF, 2013. P AN Lab 2012 & 2013: Uncov ering Plagiarism, Authorship, 343 and So cial Softw are Misuse . 344 URL http://pan. webis.de 345 de Graa ff, R., 2 0 12. Authorship attribution using compression distances. 346 Master thesis, Leiden Univ ersit y . 347 URL http://www.l iacs.nl/ass ets/Bachelorscripties/2012- 18RamondeGra aff.pdf 348 22 Gordo, A., P erronnin, F., V alv en y , E., 20 13. Large-scale do cumen t image 349 retriev al a nd classification with runlength histograms and binary em b ed- 350 dings. P att ern Recognition 46 (7), 1898 – 19 0 5. 351 URL http://www.s ciencedirec t.com/science/article/pii/S00 31320312005304 352 Griev e, J., 2007. Q ua n titat iv e authorship att r ibutio n: An ev aluation of tec h- 353 niques. Literary and Linguistic Computing 22 (3), 251–270. 354 URL http://llc. oxfordjourna ls.org/cgi/doi/10.1093/llc/fqm020 355 GuttenPlag, 2011. Collab orative do cumen ta tion of plag iarism. 356 h ttp:// de.guttenplag.wikia.com . 357 Jo c k ers, M. L., Witten, D. M., 2010 . A comparativ e study of machine learning 358 metho ds fo r authorship attribution. Literary and Linguistic Computing 359 25 (2), 215–223. 360 Juola, P ., Stamatat o s, E., 201 3 . Ov erview o f the Author Iden tification T ask 361 at P AN 2013. 362 URL http://www.c lef- initiative.eu/documents/71612/3095ffc3- 376b- 40eb- af10- 8251c 363 Juola, P ., 2 0 06. Authorship attribution. F ound. T rends Inf. Retr. 1 (3), 233– 36 4 334. 365 URL http://dx.d oi.org/10.15 61/1500000005 366 Keogh, E., Lo nardi, S., Ratana mahatana, C., 2004. T o wards parameter-free 367 data mining. In: Pro ceedings o f the tenth A CM SIGKDD international 368 conference on Kno wledge discov ery and data mining. A CM, pp. 206–2 1 5. 369 23 Ke ˇ s elj, V., Peng, F., Cercone, N., Thomas, C., 2003. N-gram-based author 370 profiles for authorship attribution. In: Pro ceedings of the Conference P a - 371 cific Asso ciatio n fo r Computational Linguistics, P A CLING. V ol. 3. pp. 372 255–264. 373 Kopp el, M., Sc hler, J., Argamon, S., Ja nuary 2009 . Computational methods 374 in authorship attribution. J. Am. So c. Inf. Sci. T ec hnol. 60 (1), 9–26. 375 URL http://dx.d oi.org/10.10 02/asi.v60:1 376 Kopp el, M., Sc hler, J., Argamon, S., 2 011. Authorship attribution in the 377 wild. Language Resources and Ev aluation 45, 83–94, 10.100 7 /s10579-0 09- 378 9111-2. 379 URL http://dx.d oi.org/10.10 07/s10579- 009- 9111- 2 380 Lo ew enstein, K., 1959. V erfassungsrec h t und v erfassungspraxis der v ere- 381 inigten staaten. Enzyklopaedie der Rec hts - und Staatswissensc haft. 382 Macedonas, A., Besiris, D ., Economou, G., F ot op oulos, S., 2008 . Dictionary 383 based color image retriev al. Journal of Visual Comm unication a nd Image 384 Represen tation 19 (7), 464–470. 385 Mac hiav elli, N., A tkinson, J., Sices, D., 2002. The Sw eetness of P ow er: 386 Mac hiav elli’s Discourses & Guicciardini’s Conside rations. No r thern Illinois 387 Univ ersit y Press. 388 Mey erson, M., 2008 . Lib erty’s blueprin t: ho w Madison a nd Hamilton wrote 389 24 The F ederalist P ap ers, defined the Constitution, and made democracy safe 390 for the w orld. Basic Bo o ks. 391 Oliv eira, W., Justino, E., Olive ira, L. S., 2013. Comparing compression 392 mo dels for a ut ho rship attribution. F orensic Science International 228 (1- 393 3), 100 – 104. 3 94 URL http://www.s ciencedirec t.com/science/article/pii/S03 79073813000923 395 Onlus, L. L., 2 0 03. the Lib er Lib er dataset. h tt p:/ /www.liberlib er.it. 396 P ereira Coutinho, D., Fig ueiredo, M., 2005. Info r ma t ion Theoretic T ext Clas- 397 sification using the Ziv-Merhav Metho d. Pattern Recognition and Image 398 Analysis 3523, 355–362. 399 P op escu, M., Gro zea, C., 2012. Kernel metho ds and string k ernels for au- 400 thorship analysis. In: F orner, P ., Karlgren, J., W omser-Hack er, C. (Eds.), 401 CLEF (Online W orking Notes/Labs/W orkshop). 402 URL http://dblp .uni- trier.de/db/conf/clef/clef2012w.html 403 Sapk ota, U., Solorio, T., 2012. Sub-profiling b y linguistic dimensions to solv e 404 the authorship attribution task. In: F orner, P ., K arlgren, J., W omser- 405 Hac k er, C. (Eds.), CLEF (Online W orking Notes/Labs/W orkshop). 406 URL http://dblp .uni- trier.de/db/conf/clef/clef2012w.html 407 Seidman, U., 2013. Autho r ship V erification Using the Imp ostors Method. 408 Noteb o o k for P AN at CLEF 2013 409 URL http://www.c lef- initiative.eu/documents/71612/7a4e6a71- 46e9- 4bb1- ab66- 8ea9c 410 25 Stamatatos, E., 200 9. A surve y of mo dern authorship att r ibution metho ds. 411 J. Am. So c. Inf. Sci. 60 (3), 53 8–556. 412 T anguy , L., Sa jous, F., Calderone, B., Hathout, N., 2012. Authorship at- 413 tribution: Using rich linguistic features when training data is scarce. In: 414 F orner, P ., Karlgren, J., W omser-Hac k er, C. (Eds.), CLEF (Online W ork- 415 ing Notes/Labs/W orkshop). 416 URL http://dblp .uni- trier.de/db/conf/clef/clef2012w.html 417 W atanab e, T., Suga w ar a , K., Sugihara , H., 2002 . A new pattern represen ta- 418 tion sc heme using data compression. IEEE T ransactions on P attern Anal- 419 ysis and Mac hine In telligence 24 (5), 579–590. 420 W elc h, T., 19 8 4. T ec hnique for high-p erfo rmance data compression. IEEE 421 Computer 17 (6), 8–19. 422 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment