특징과 변수 선택을 통한 효율적인 분류
본 논문은 고차원 데이터에서 과적합, 해석성 저하, 연산 자원 소모 문제를 완화하기 위해 특징·변수 선택 기법을 체계적으로 정리한다. 주요 방법으로 순위 기반, 필터, 래퍼, 임베디드 접근을 소개하고 각각의 장·단점을 논의한다. 또한 특징 생성, 검증 기법 및 최신 사례(유전자 선택, 자동 인코더)까지 폭넓게 다루며, 실용적인 선택 전략을 제시한다.
저자: Aaron Karper
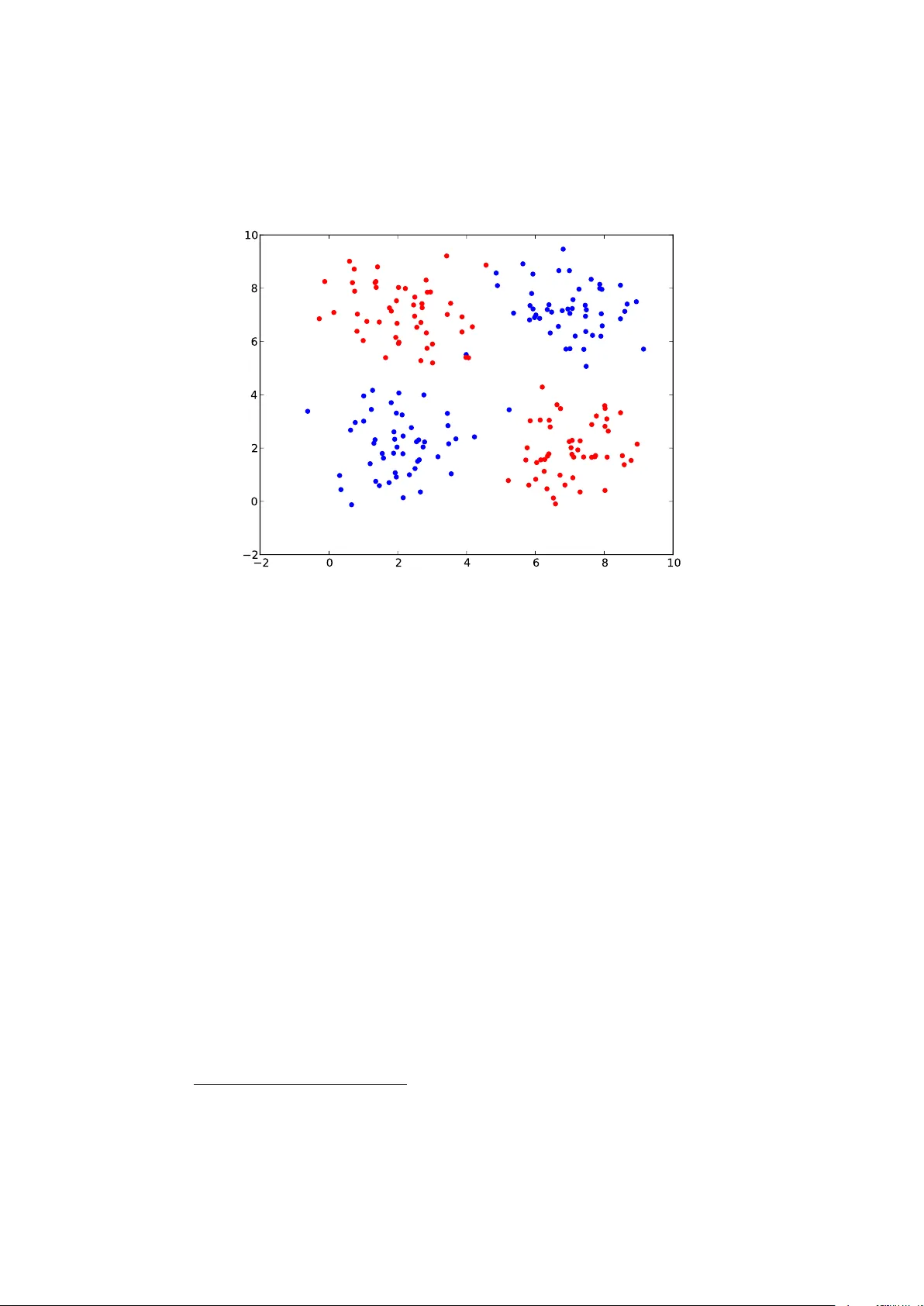
본 논문은 머신러닝에서 고차원 데이터가 초래하는 과적합, 해석성 저하, 계산·메모리 비용 증가 문제를 해결하기 위한 특징·변수 선택 기법을 포괄적으로 정리한다. 서론에서는 유전자 발현 데이터와 같이 변수 수가 샘플 수보다 훨씬 많은 경우, 모든 변수 조합을 고려하면 가능한 모델 수가 2^21000에 달해 무작위 모델이 학습 데이터를 완벽히 맞출 위험이 있음을 ‘xor 문제’와 함께 설명한다. 이러한 상황에서 변수 선택은 모델 복잡도를 줄이고 일반화 성능을 높이며, 해석 가능한 결과를 제공한다는 점을 강조한다.
이후 기존 연구(Guyon & Elisseeff, 2003; Zhou et al., 2005; Torresani et al., 2008; Murphy, 2012)를 소개하며, 특징 선택이 실제 적용 사례에서 어떻게 활용되는지를 보여준다.
다음 장에서는 특징 선택 방법을 네 가지 범주로 구분한다.
1. **순위(Ranking)** – 각 변수에 점수를 매겨 상위 n개를 선택한다. 구현이 간단하고 선형 시간에 수행 가능하지만, 변수 간 상호작용을 무시한다는 근본적인 한계가 있다. 논문은 X > 5 xor Y > 5 형태의 XOR 문제를 예시로 들어, 개별 변수는 무의미하지만 두 변수를 동시에 사용하면 완벽히 구분 가능함을 보여준다.
2. **필터(Filter)** – 변수와 클래스 간 상관, 변수 간 상관을 동시에 고려하는 휴리스틱을 사용한다. 필터는 학습 단계에서 한 번만 분류기를 훈련시키므로 비용이 낮지만, 선택 기준이 실제 분류 성능과 일치하지 않을 수 있다. 예시로, 노이즈 변수와 상관된 변수를 이용해 신호‑노이즈 비를 개선하는 경우를 제시한다.
3. **래퍼(Wrapper)** – 분류기를 블랙박스로 취급해, 특정 성능 지표(예: 정확도, F1-score)를 직접 최적화한다. 탐색 공간이 2^N으로 급격히 커지기 때문에 전진 선택·후진 제거와 같은 탐욕적 전략, 혹은 시뮬레이티드 어닐링, 브랜치‑앤‑바운드 등을 사용한다. 계산 비용이 크지만 실제 분류 성능을 직접 반영한다는 장점이 있다.
4. **임베디드(Embedded)** – 학습 과정 자체에 변수 선택 메커니즘을 내재시킨다. L1 정규화, MAP 추정, l_p(p→0) 규제 등을 통해 불필요한 가중치를 0으로 만들며, 학습이 한 번만 수행돼 효율적이다. 논문은 SVM의 1‑norm 제약과 로지스틱 회귀에 대한 베이지안 정보 기준(AIC, BIC, MDL) 적용 사례를 상세히 설명한다.
다음으로 **특징 생성(Feature Creation)**을 논한다. 여기서는 고차원 변수 공간을 저차원 잠재 공간으로 압축하는 방법으로, 압축 코딩, 매니폴드 학습, 확률적 주성분 분석(PPCA) 등을 소개한다. 특히 자동 인코더(Auto‑Encoder)를 예시로 들어, 입력을 병목 차원으로 압축하고 다시 복원함으로써 유용한 새로운 특징을 자동으로 학습한다는 점을 강조한다.
**검증(Validation)** 섹션에서는 모델 일반화 오차를 추정하기 위한 교차 검증의 중요성을 강조한다. 데이터 독립성을 확보하기 위해 샘플, 페이지, 저자 단위로 데이터를 나누는 전략을 제시하고, 무작위 변수를 추가해 신호‑노이즈 비를 측정하는 방법도 논한다.
**최근 사례**에서는 (1) **Nested Subset Methods** – 전진/후진 선택을 통해 목표 함수를 반복적으로 평가하며, 경우에 따라 PCA와 결합해 입력‑출력 공동 분포를 고려한 차원 축소를 수행한다. (2) **Logistic Regression with Model Complexity Regularization** – Zhou et al. (2005)의 논문을 인용해, 로지스틱 회귀에 AIC, BIC, MDL 기반의 사전분포를 적용해 변수 선택을 수행한다. 여기서 AIC는 L0 규제로 자유도를 벌점화하고, BIC는 데이터 수 N을 고려한 벌점을 부여하며, MDL은 모델 기술 길이를 최소화한다. (3) **Auto‑Encoders as Feature Creation** – Hinton과 Salakhutdinov의 자동 인코더 구조를 소개하고, 병목 차원을 통해 고차원 입력을 압축하면서도 재구성 오류를 최소화하는 방법을 설명한다.
전체적으로 논문은 특징·변수 선택의 이론적 배경, 주요 방법론, 검증 기법, 최신 적용 사례를 체계적으로 정리한다. 다만 실험적 비교가 부족하고, 각 방법의 구체적 구현 세부사항이 생략된 점은 향후 연구에서 보완될 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기