Feature and Variable Selection in Classification
The amount of information in the form of features and variables avail- able to machine learning algorithms is ever increasing. This can lead to classifiers that are prone to overfitting in high dimensions, high di- mensional models do not lend themse…
Authors: Aaron Karper
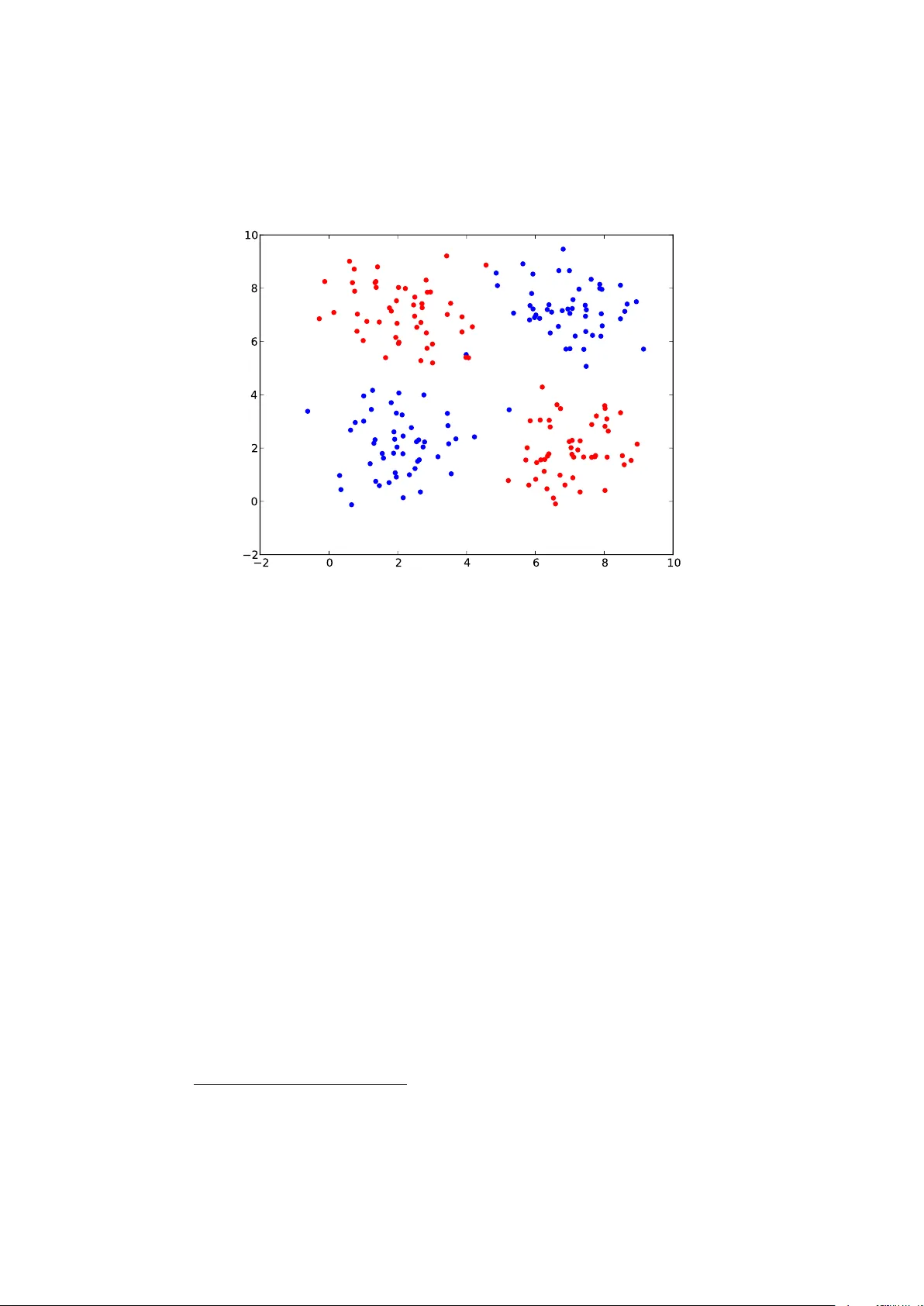
F eature and V ariable Selection in Classification Aaron Karp er August 27, 2018 Abstract The amount of information in the form of features and v ariables av ail- able to mac hine learning algorithms is ever increasing. This can lead to classifiers that are prone to o verfitting in high dimensions, high di- mensional mo dels do not lend themselves to interpretable results, and the CPU and memory resources necessary to run on high-dimensional datasets sev erly limit the applications of the approac hes. V ariable and feature selection aim to remedy this by finding a subset of features that in some wa y captures the information provided b est. In this paper w e present the general metho dology and highlight some sp ecific approaches. 1 In tro duction As mac hine learning as a field dev elops, it becomes clear that the issue of finding go od features is often more difficult than the task of using the features to create a classification mo del. Often more features are av ailable than can reasonably b e exp ected to b e used, b ecause using to o many features can lead to ov erfitting, hinders the interpretabilit y , and is computationally exp ensiv e. 1.1 Ov erfitting One of the reasons wh y more features can actually hinder accuracy is that the more features we hav e, the less can we dep end on measures of distance that man y classifiers (e.g. SVM, linear regression, k-means, gaussian mixture mo dels, . . . ) require. This is kno wn as the curse of dimensionality . Accuracy might also b e lost, b ecause we are prone to o verfit the mo del if it incorp orates all the features. Example. In a study of genetic cause of cancer, w e might end up with 15 participan ts with cancer and 15 without. Eac h participan t has 21’000 gene expressions. If we assume that any n um ber of genes in combination can cause cancer, ev en if we underestimate the n umber of p ossible genomes by assuming the expressions to b e binary , we end with 2 21 0 000 p ossible mo dels. In this h uge num ber of p ossible mo dels, there is b ound to b e one arbitrarily complex that fits the observ ation p erfectly , but has little to no predictiv e pow er [Russell et al., 1995, Chapter 18, Noise and Ov erfitting]. W ould we in some w ay limit the complexity of the mo del we fit, for example by discarding nearly all p ossible v ariables, we would attain b etter generalisation. 1 1.2 In terpretabilit y If we take a classification task and wan t to gain some information from the trained mo del, mo del complexit y can hinder any insigh ts. If we take up the gene example, a small model might actually show what proteins (pro duced by the culprit genes) cause the cancer and this might lead to a treatment. 1.3 Computational complexit y Often the solution to a problem needs to fulfil certain time constraints. If a rob ot takes more than a second to classify a ball flying at it, it will not b e able to catch it. If the problem is of a low er dimensionalit y , the computational complexit y go es do ws as well. Sometimes this is only relev ant for the prediciton phase of the learner, but if the training is to o complex, it might become infeasible. 1.4 Previous w ork This article is based on the work of [Guyon and Elisseeff, 2003], which giv es a broad introduction to feature selection and creation, but as ten years passed, the state-of-the-art mov ed on. The relev ance of feature selection can b e seen in [Zhou et al., 2005], where gene mutations of cancer patien ts are analysed and feature selection is used to conclude the mutations resp onsible. In [T orresani et al., 2008], the manifold of h uman p oses is mo delled using a dimensionalit y reduction technique, which will presen ted here in short. Kevin Murph y giv es an o v erview of modern tec hniques and their justification in [Murph y , 2012, p. 86ff] 1.5 Structure In this pap er we will first discuss the conclusions of Guy on and Elisseeff about the general approaches taken in feature selection in section 2, discuss the cre- ation of new features in section 3, and the wa ys to v alidate the model in section 4. Then we will contin ue b y showing some more recent dev elopmen ts in the field in section 5. 2 Classes of metho ds In [Guyon and Elisseeff, 2003], the authors identify four approaches to feature selection, each of which with its o wn strengths and weaknesses: Ranking orders the features according to some score. Filters build a feature set according to some heuristic. W rapp ers build a feature set according to the predictiv e pow er of the classifier Em b edded metho ds learn the classification mo del and the feature selection at the same time. 2 Figure 1: A ranking pro cedure would find that b oth features are equally useless to separate the data and would discard them. If taken together how ever the feature woul d separate the data very w ell. If the task is to predict as accurately as p ossible, an algorithm that has a safeguard against ov erfitting might be better than ranking. If a pip eline scenario is considered, something that treats the following phases as blac kb o x would b e more useful. If even the time to reduce the dimensionalit y is v aluable, a ranking w ould help. 2.1 Ranking V ariables get a score in the ranking approac h and the top n v ariables are se- lected. This has the adv antage that n is simple to control and that the selection runs in linear time. Example. In [Zhou et al., 2005], the authors try to find a discriminativ e subset of genes to find out whether a tumor is malignant or b enign 1 . In order to prune the feature base, they rank the v ariables according to the correlation to the classes and mak e a preliminary selection, which discards most of the genes in order to speed up the more sophisticated procedures to select the top 10 features. There is an inherrent problem with this approach ho w ever, called the xor problem[Russell et al., 1995]: 1 Acutally they classify the tumors into 3 to 5 classes. 3 It implicitly assumes that the features are uncorrelated and gives p oor results if they are not. On figure 2.1, we hav e t wo v ariables X and Y , with the ground truth roughly being Z = X > 5 xor Y > 5. Each v ariable tak en separately gives absolutely no information, if both v ariables were selected ho w ev er, it w ould b e a p erfectly discriminant feature. Since each on its o wn is useless, they would not rank high and would probably b e discarded by the ranking pro cedure, as seen in figure 2.1. Example. T ake as an example tw o genes X and Y , so that if one is m utated the tumor is malignan t, which w e denote by M , but if b oth mutate, the c hanges cancel each other out, so that no tumor grows. Each v ariable separately w ould b e useless, b ecause P ( M = tr ue | X = true ) = P ( Y = f al se ), but P ( M = tr ue | X = tr ue, Y = f alse ) = 1 – 2.2 Filters While ranking approaches ignore the v alue that a v ariable can hav e in connection with another, filters select a subset of features according to some determined criterion. This criterion is indep endent of the classifier that is used after the filtering step. On one hand this allo ws to only train the follo wing classifier once, whic h again might b e more cost-effective. On the other hand it also means that only some heuristics are av ailable of ho w w ell the classifier will do afterwards. Filtering methods t ypically try to reduce in-class v ariance and to bo ost in ter- class distance. An example of this approach is a filter that would maximize the correlation betw een the v ariable set and the classification, but minimize the correlation b etw een the v ariables themselves. This is under the heuristic, that v ariables, that correlate with each other don’t pro vide m uc h additional information compared to just taking one of them, which is not necessarily the case, as can b e seen on figure 2.2: If the v ariable is noisy , a second, correlated v ariable can b e used to get a b etter signal, as can be seen in figure 2.2. A problem with the filtering approach is that the performance of the classifier migh t not depend as m uc h as w e would hope on the pro xy measure that w e used to find the subset. In this scenario it might b e b etter to assess the accuracy of the classifier itself. 2.3 W rapp ers W rapp ers allow to lo ok at the classifier as a blackbox and therefore break the pip eline metaphor. They optimize some p erformance measure of the classifier as the ob jective function. While this gives sup erior results to the heuristics of filters, it also costs in computation time, since a classifier needs to b e trained eac h time – though shortcuts migh t be a v ailable depending on the classifier trained. W rapp ers are in large search procedures through feature subset space – the atomic movements are to add or to remo v e a certain feature. This means that man y com binatorical optimization procedures can b e applied, suc h as simu- lated annealing, branch-and-bound, etc. Since the subset space is 2 N , for N the n um b er of features, it is not feasible to p erform an exhaustiv e search, therefore greedy metho ds are applied: The start can either b e the full feature set, where w e try to reduce the num b er of features in an optimal wa y ( b ackwar d elimina- tion ) or we can start with no features and add them in a smart wa y ( forwar d 4 0 1 2 3 4 5 1 0 1 2 3 4 5 6 Figure 2: F eatures might be identically distributed, but using b oth can reduce v ariance and thus confusion b y a factor of √ n sele ction ). It is also p ossible to replace the least predictive feature from the set and replace it with the most predictiv e feature from the features that were not c hosen in this iteration. 2.4 Em b edded W rapp ers treated classifiers as a black b o x, therefore a com binatorical optimiza- tion was necessary with a training in each step of the search. If the classifier allo ws feature selection as a part of the learning step, the learning needs to b e done only once and often more efficiently . A simple wa y that allows this is to optimize in the classifier not only for the lik elihoo d of the data, but instead for the p osterior probability (MAP) for some prior on the mo del, that makes less complex mo dels more probable. An example for this can b e found in section 5.2. Somewhat similar is SVM with a ` 1 w eigth constrain t 2 . The 1:1 exchange means that non-discriminative v ariables will end up with a 0 w eigh t. It is also p ossible to take this a step further by optimizing for the num b er of v ariables directly , since l 0 ( w ) = lim p → 0 l p ( w ) is exactly the n umber of non-zero v ariables in the vector. 2 ` p ( w ) = k w k p = p p P | w i | p 5 3 F eature creation In the previous c hapter the distinction b et w een v ariables and features w as not necessary , since b oth could b e used as input to the classifier after feature selec- tion. In this section fe atur es is the vector offered to the classifier and variables is the vector handed to the feature creation step, i.e. the r aw inputs collected. F or muc h the same reasons that motiv ated feature selection, feature creation for a smaller num b er of features compared to the num ber of v ariables provided. Essen tially the information needs to b e compressed in some wa y to b e stored in few er v ariables. F ormally this can b e expressed b y mapping the high- dimensional space through the b ottlenec k, whic h we hop e results in recov ering the low dimensional concepts that created the high-dimensional representation in the first place. In any case it means that typical features are created, with a similar intuition to efficient co des in compression: If a simple feature o ccurs often, giving it a representation will reduce the loss more than representing a less common feature. In fact, compression algorithms can b e seen as a kind of feature creation[Argyriou et al., 2008]. This is also related to the idea of manifold learning: While the v ariable space is big, the actual space in that the v ariables v ary is muc h smaller – a manifold 3 of hidden v ariables embedded in the v ariable space. Example. In [T orresani et al., 2008] the human b ody is mo delled as a low dimensional mo del by pr ob abilistic princip al c omp onent analyis : It is assumed that the hidden v ariables are distributed as Gaussians in a lo w dimensional space that are then linearly mapp ed to the high dimensional space of positions of pixels in an image. This allo ws them to learn typic al p ositions that a h uman b ody can be in and with that trac k bo dy shapes in 3d ev en if neither the camera, nor the human are fixed. 4 V alidation metho ds The goal up to this p oint was to find a simple mo del, that p erforms w ell on our training set, but w e hop e that our model will p erform w ell in data, it has never seen b efore: minimizing the gener alization err or . This section is concerned with estimating this error. A typical approach is cr oss-validation : If w e hav e indep endent and identi- cally distributed datap oint, we can split the data and train the mo del on one part and measure its p erformance on the rest. But even if we assume that the data is identically distributed, it requires very careful curation of the data to ac hiev e indep endence: Example. Assume that w e tak e a corpus of historical b ooks and segmen t them. W e could no w cross-v alidate ov er all pixels, but this w ould b e anything but indep enden t. If we are able to train our model on half the pixels of a page and c hec k against the other half, we would naturally p erform quite well, since w e are actually able to learn the style of the page. If w e split page-wise, we can learn the sp ecific characteristics of the author. Only if w e split author-wise, we migh t hop e to hav e a resemblence of independence. 3 A manifold is the mathematical generalization of a surface or a curve in 3D space: Some- thing smooth that can be mapp ed from a low er dimensional space. 6 Another approac h is pr obing : instead of mo difying the data set and compar- ing to other data, we can mo dify the fe atur e sp ac e . W e add random v ariables, that hav e no predictive p ow er to the feature set. Now we can measure how w ell mo dels fare against pure chance 4 . Our p erformance measure is then the signal-to-noise ratio of our mo del. 5 Curren t examples 5.1 Nested subset metho ds In the nested subset metho ds the feature subset space is greedily examined b y estimating the exp ected gain of adding one feature in forward selection or the exp ected loss of remo ving one feature in backw ard selection. This estimation is called the obje ctive function . If it is p ossible to examine the ob jective function for a classifier directly , a better p erformance is gained by embedding the search pro cedure with it. If that is not p ossible, training and ev aluating the classifier is necessary in each step. Example. Consider a mo del of a linear predictor p ( y | x ) with M input v ariables needing to b e pruned to N input v ariables. This can b e mo deled by asserting that the real v ariables x ? i are tak en from R N , but a linear transformation A ∈ R N × M and a noise term n i = N (0 , σ 2 x ) is added: x i = A x ? i + n i In a classification task 5 , we can mo del y = Ber(sigm( w · x ? )). This can b e seen as a generalisation of PCA 6 to the case where the output v ariable is taken into account ([W est, 2003] and [Bair et al., 2006] dev elop the idea). Standard sup ervised PCA assumes that the output is distributed as a gaussian distribution, which is a dangerous simplification in the classification setting[Guo, 2008]. The pro cedure iterates ov er the eigenv ectors of the natural parameters of the join t distribution of the input and the output and adds them if they show an improv emen t to the current mo del in order to capture the influence of the input to the output optimally . If more than N v ariables are in the set, the one with the least fav orable score is dropp ed. The algorithms iterates some fixed n um b er of times o ver all features, so that hop efully the globally optimal feature subset is found. 5.2 Logistic regression using mo del complexit y regulari- sation In the pap er Gene sele ction using lo gistic r e gr essions b ase d on AIC, BIC and MDL criteria [Zhou et al., 2005] by Zhou, W ang, and Dougherty , the authors describ e the problem of classifying the gene expressions that determine whether a tumor is part of a certain class (think malign v ersus benign). Since the feature 4 This can take the form of a significance test. 5 The optimization a free interpretation of [Guo, 2008] 6 Principal component analysis reduces the dimensions of the input v ariables b y taking only the directions of the largest eigenv alues. 7 v ectors are h uge ( ≈ 21 0 000 genes/dimensions in man y expressions) and therefore the c hance of o verfittin g is high and the domain requires an in terpretable result, they discuss feature selection. F or this, they c ho ose an embedded metho d, namely a normalized form of logistic regression, which we will describ e in detail here: Logistic regression can b e understo o d as fitting p w ( x ) = 1 1 + e w · x = sigm( w · x ) with regard to the separation direction w , so that the confidence or in other w ords the probability p w ? ( x data ) is maximal. This corresp onds to the assumption, that the probability of eac h class is p ( c | w ) = Ber( c | sigm( w · x )) and can easily b e extended to incorp orate some prior on w , p ( c | w ) = Ber( c | sigm( w · x )) p ( w ) [Murphy , 2012, p. 245]. The pap er discusses the priors of the Ak aike information criterion (AIC), the Bay esian information criterion (BIC) and the minimum descriptor length (MDL): AIC The Ak aike information criterion p enaltizes degrees of freedom, the ` 0 norm, so that the function optimized in the mo del is log L ( w ) − ` 0 ( w ). This corresp onds to an exp onential distribution for p ( w ) ∝ exp( − ` 0 ( w )). This can b e interpreted as minimizing the v ariance of the mo dels, since the v ariance grows exp onen tially in the num b er of parameters. BIC The Ba yesian information criterion is similar, but takes the num b er of datap oin ts N in to accoun t: p ( w ) ∝ N − ` 0 ( w ) 2 . This has an in tuitiv e interpreta- tion if we assume that a v ariable is either ignored, in which case the sp ecific v alue does not matter, or tak en in to account, in whic h case the v alue influences the model. If w e assume a uniform distribution on all suc h models, the ones that ignore b ecome more probable, b ecause they accumulate the probability weigh t of all p ossible v alues. MDL The minim um descriptor length is related to the algorithmic probability and states that the space necessary to store the descriptor giv es the b est heuristic on ho w com plex the model is. This only implicitly causes v ariable selection. The appro ximation for this v alue can b e seen in the paper itself. Since the fitting is computationally expensive, the authors start with a simple ranking on the v ariables to discard all but the b est 5’000. They then rep eatedly fit the respective mo dels and collect the num ber of app earances of the v ariables to rank the b est 5, 10, or 15 genes. This step can b e seen as an additional ranking step, but this seems unnecessary , since the fitted mo del by construction w ould already ha v e selected the b est mo del. Even so they still manage to av oid o v erfitting and finding a viable subset of discriminative v ariables. 5.3 Auto enco ders as feature creation Auto encoders are deep neural netw orks 7 that find a fitting information b ottle- nec k (see 3) b y optimizing for the reconstruction of the signal using the inverse 7 Deep means multiple hidden layers. 8 1000 2000 30 500 1000 2000 500 Input R econstr uction Bottleneck Figure 3: An auto enco der net w ork transformation 8 . Deep netw orks are difficult to train, since they sho w many lo cal minima, man y of which show p o or p erformance [Murph y , 2012, p. 1000]. T o get around this, Hinton and Salakh utdino v [Hin ton and Salakhutdino v, 2006] prop ose pre- training the mo del as stack ed restricted Bolzmann mac hines b efore devising a global optimisation like sto chastical gradien t descen t. Restricted Bolzmann machines are easy to train and can b e understo o d as learning a probability distribution of the la y er b elow. Stac king them means extracting probable distributions of features, somewhat similar to a distribution of histograms as for example HoG or SIFT b eing representativ e to the visual form of an ob ject. It has long b een sp eculated that only low-lev el features could b e captured b y such a s etup, but [Le et al., 2011] show that, given enough resources, an auto encoder can learn high lev el concepts like recognizing a cat face without an y sup ervision on a 1 billion image training set. The impressiv e result b eats the state of the art in sup ervised learning by adding a simple logistic regression on top of the b ottleneck lay er. This implies that the features learned by the netw ork capture the concepts present in the image b etter than SIFT visual bag of words or other human created features and that it can learn a v ariety of concepts in parallel. F urther since the result of the single b est neuron is already very discriminative, it gives evidence for the p ossibilit y of a gr andmother neur on in the human brain – a neuron that recognizes exactly one ob ject, in this case the grandmother. Using this single feature w ould also tak e feature selection to the extreme, but without the b enefit of b eing more computationally adv antageous. 8 A truely inverse transformation is of course not possible. 9 5.4 Segmen tation in Computer Vision A domain that necessarily deals with a huge num b er of dimensions is computer vision. Ev en only considering V GA images, in whic h only the actual pixel v alues are taken into accoun t giv es 480 × 640 = 307 0 200 datap oin ts p er image. F or a segmentation task in do cument analysis, where pixels need to be clas- sified into regions like b order, image, and text, there is more to b e taken into accoun t than just the ra w pixel v alues in order to incorp orate spartial informa- tion, edges, etc. With up to 200 heterogeneous features to consider for each pixel, the ev aluation would tak e too long to be useful. This section differs from the previous t w o in that instead of reviewing a ready made solution to a problem, it shows the pro cess of pro ducing such a solution. The first thing to consider is whether or not w e hav e a strong prior of how man y features are useful. In the example of cancer detection, it was known that only a small num ber of mutation caused the tumor, so a mo del with a h undred genes could easily b e discarded. Unfortunately this is not the case for segmen tation, b ecause our features don’t hav e a causal connection to the true segmen tation. Finding go o d features for segmen tation requires finding a go o d pro xy feature set for the true segmentation. Next w e migh t consider the loss of missclassification: In a computer vision task, pixel missclassifications are to be expected and can b e smo othed ov er. Computational complexit y how ever can sev erely limit the p ossible applications of an algorithm. As [Russell et al., 1995] note, using a bigger dataset can b e more adv antageous than using the b est algorithm, so we would fa vour an efficien t pro cedure ov er a very accurate one, because it w ould allo w us to train on a bigger training set. Since the v ariables are lik ely to b e correlated, ranking will giv e bad results. T aking this into account, we would consider L 1 normalized linear classifiers, b ecause of the fast classification and training (the latter due to [Y uan et al., 2010], in which linear time training methods are compared). T aking linear regression could additionally b e adv anageous, since its soft classification would allo w for b etter joining of contin uous areas of the do cument. 6 Discussion and outlo ok Man y of the concepts presen ted in [Guy on and Elisseeff, 2003] still apply , ho w- ev er the examples fall short on statistical justification. Since then applications for v ariable and feature selection and feature creation were dev elop ed, some of whic h were driven by adv ances in computing p o w er, such as high-level feature extraction with auto enco ders, others were motiv ated by integrating prior as- sumptions ab out the sparcity of the mo del, such as the usage of probabilistic principal comp onen t analysis for shap e reconstruction. The goals of v ariable and feature selection – av oiding ov erfitting, inter- pretabilit y , and computational efficiency – are in our opinion problems b est tac kled by in tegrating them into the mo dels learned by the classifier and we exp ect the em b edded approach to be b est fit to ensure an optimal treatmen t of them. Since man y popular and efficient classifiers, such as supp ort v ector ma- c hines, linear regression, and neural netw orks, can b e extended to incorp orate 10 suc h constraints with relative ease, we exp ect the usage of ranking, filtering, and wrapping to b e more of a pragmatic first step, before sophisticated learners for sparse mo dels are emplo y ed. Adv ances in embedded approaches will make the p erformance and accuracy adv antages stand out ev en more. F eature creation to o has seen adv ances, especially in efficient generalisations of the principal comp onen t analysis algorithm, such as kernel PCA (1998) and sup ervised extensions. They predominan tly rely on the ba y esian formulation of the PCA problem and we exp ect this to drive more innov ation in the field, as can b e seen by the spin-off of reconstructing a shap e from 2D images using a ba y esian netw ork as discussed in [T orresani et al., 2008]. References [Argyriou et al., 2008] Argyriou, A., Evgeniou, T., and P on til, M. (2008). Con- v ex multi-task feature learning. Machine L e arning , 73(3):243–272. [Bair et al., 2006] Bair, E., Hastie, T., Paul, D., and Tibshirani, R. (2006). Prediction by sup ervised principal components. Journal of the A meric an Statistic al Asso ciation , 101(473). [Guo, 2008] Guo, Y. (2008). Sup ervised exp onen tial family principal comp o- nen t analysis via conv ex optimization. In A dvanc es in Neur al Information Pr o c essing Systems , pages 569–576. [Guy on and Elisseeff, 2003] Guy on, I. and Elisseeff, A. (2003). An introduction to v ariable and feature selection. The Journal of Machine L e arning R ese ar ch , 3:1157–1182. [Hin ton and Salakhutdino v, 2006] Hin ton, G. E. and Salakh utdinov, R. R. (2006). Reducing the dimensionality of data with neural netw orks. Scienc e , 313(5786):504–507. [Le et al., 2011] Le, Q. V., Ranzato, M., Monga, R., Devin, M., Chen, K., Corrado, G. S., Dean, J., and Ng, A. Y. (2011). Building high-level features using large scale unsup ervised learning. arXiv pr eprint arXiv:1112.6209 . [Murph y , 2012] Murph y , K. P . (2012). Machine le arning: a pr ob abilistic p er- sp e ctive . The MIT Press. [Russell et al., 1995] Russell, S. J., Norvig, P ., Canny , J. F., Malik, J. M., and Edw ards, D. D. (1995). Artificial intel ligenc e: a mo dern appr o ach , volume 74. Pren tice hall Englewoo d Cliffs. [T orresani et al., 2008] T orresani, L., Hertzmann, A., and Bregler, C. (2008). Nonrigid structure-from-motion: Estimating shap e and motion with hierar- c hical priors. Pattern Analysis and Machine Intel ligenc e, IEEE T r ansactions on , 30(5):878–892. [W est, 2003] W est, M. (2003). Bay esian factor regression mo dels in the ”large p, small n” paradigm. Bayesian statistics , 7(2003):723–732. 11 [Y uan et al., 2010] Y uan, G.-X., Chang, K.-W., Hsieh, C.-J., and Lin, C.-J. (2010). A comparison of optimization metho ds and softw are for large-scale l1- regularized linear clas sification. The Journal of Machine L e arning R ese ar ch , 9999:3183–3234. [Zhang et al., 2011] Zhang, X., Y u, Y., White, M., Huang, R., and Sc h uurmans, D. (2011). Con v ex sparse co ding, subspace learning, and semi-sup ervised extensions. In AAAI . [Zhou et al., 2005] Zhou, X., W ang, X., and Dougherty , E. R. (2005). Gene selection using logistic regressions based on aic, bic and mdl criteria. New Mathematics and Natur al Computation , 1(01):129–145. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment