자동인코더 기반 양언어 단어 표현 학습
이 논문은 단어 수준 정렬 없이 병렬 문장의 bag‑of‑words를 재구성하도록 학습한 자동인코더를 이용해 영어와 독일어 등 두 언어 사이의 단어 임베딩을 정렬한다. 두 가지 자동인코더 구조(이진 재구성 및 트리 기반 확률적 재구성)를 제안하고, 상관관계 정규화를 추가해 표현 품질을 향상시킨다. 학습된 임베딩을 tf‑idf 가중합으로 문서 벡터화하여 교차 언어 문서 분류에 적용했으며, 기존 최첨단 방법 대비 10~14%p의 성능 향상을 기록한…
저자: Sarath Ch, ar A P, Stanislas Lauly
본 논문은 병렬 코퍼스에서 문장 수준의 정렬만을 이용해 두 언어 사이의 단어 임베딩을 정렬하는 새로운 자동인코더 기반 방법을 제안한다. 기존 연구들은 대부분 GIZA++와 같은 도구를 사용해 얻은 단어‑레벨 정렬 정보를 필요로 했으며, 이는 정렬 과정에서 발생하는 오류와 높은 비용을 동반한다. 저자들은 이러한 제약을 없애기 위해, 각 언어의 문장을 bag‑of‑words 형태로 변환하고, 이를 자동인코더에 입력함으로써 양언어 임베딩을 동시에 학습한다.
### 1. 자동인코더 설계
- **인코더**: 입력 bag‑of‑words를 고정 차원 D의 임베딩 공간으로 매핑한다. 구체적으로, 각 단어 i에 대한 임베딩 벡터 w_i (D차원)를 행렬 W에 저장하고, 문장 x에 포함된 모든 단어의 임베딩을 합산(또는 평균)한 뒤 비선형 활성화 h(·)와 편향 c를 적용해 φ(x)=h(c+W·v(x))를 얻는다. 여기서 v(x) 는 단어 존재 여부를 나타내는 이진 벡터이다.
- **디코더**: 두 가지 변형이 제시된다.
1. **이진 재구성 디코더**: φ(x)를 다시 V 차원의 sigmoid 출력 b_v(x)=σ(V·φ(x)+b) 로 변환해 원래 이진 bag‑of‑words와 교차 엔트로피 손실을 최소화한다. 학습 효율을 위해 미니배치 내 여러 문장의 bag‑of‑words를 하나로 합쳐 한 번에 업데이트하는 merged mini‑batch 기법을 사용한다.
2. **트리 기반 확률 디코더**: 각 단어를 이진 트리의 리프에 배치하고, φ(x) 로부터 각 내부 노드의 좌·우 선택 확률을 로지스틱 회귀 형태로 예측한다. 단어의 재구성 확률은 해당 경로의 확률 곱으로 계산되며, 이는 O(log V) 연산으로 구현된다. 손실은 관측된 단어들의 다항 로그우도 –∑ log p(b_x = x_i|φ(x)) 로 정의된다.
### 2. 양언어 자동인코더
두 언어 X, Y 에 대해 각각 Wₓ, Wᵧ 를 학습한다. 동일한 인코더 구조와 공유된 편향 c 를 사용해 φₓ(x)와 φᵧ(y)를 얻고, 각 언어별 디코더 (bₓ,Vₓ), (bᵧ,Vᵧ) 로 다음 네 가지 재구성 작업을 동시에 학습한다.
1) x → y 재구성, 2) y → x 재구성, 3) x → x 자체 재구성, 4) y → y 자체 재구성.
이렇게 하면 두 언어의 문장 표현이 동일한 의미 공간에 매핑되며, 단어 임베딩 역시 자연스럽게 정렬된다.
### 3. 상관관계 정규화
인코더 출력 φₓ(x)와 φᵧ(y) 사이의 피어슨 상관관계를 최대화하는 정규화 항 –λ·cor(φₓ,φᵧ) 를 손실에 추가한다. λ는 손실 규모를 맞추기 위한 스케일 파라미터이며, 이 항은 특히 데이터가 부족한 저자원 언어에서 임베딩 정렬을 강화한다.
### 4. 문서 표현 및 교차 언어 분류
학습된 단어 임베딩 행렬을 이용해 문서 d 를 tf‑idf 가중합 ψ(d)=∑ tf‑idf(z_i)·W_{z_i} 로 벡터화한다. 이렇게 만든 문서 벡터는 한 언어에서 학습된 선형 분류기(예: SVM)를 다른 언어에 그대로 적용할 수 있게 해, 교차 언어 문서 분류 실험에 활용한다.
### 5. 실험 및 결과
- **데이터**: 영어‑독일어, 영어‑프랑스어 등 여러 언어쌍의 병렬 코퍼스를 사용했으며, 각 언어별 뉴스 기사와 감성 데이터셋을 교차 언어 분류에 적용하였다.
- **비교 모델**: Klementiev et al. (2012), Zou et al. (2013) 등 기존 단어 정렬 기반 방법과, MT 기반 파라미터 투사 방법을 포함하였다.
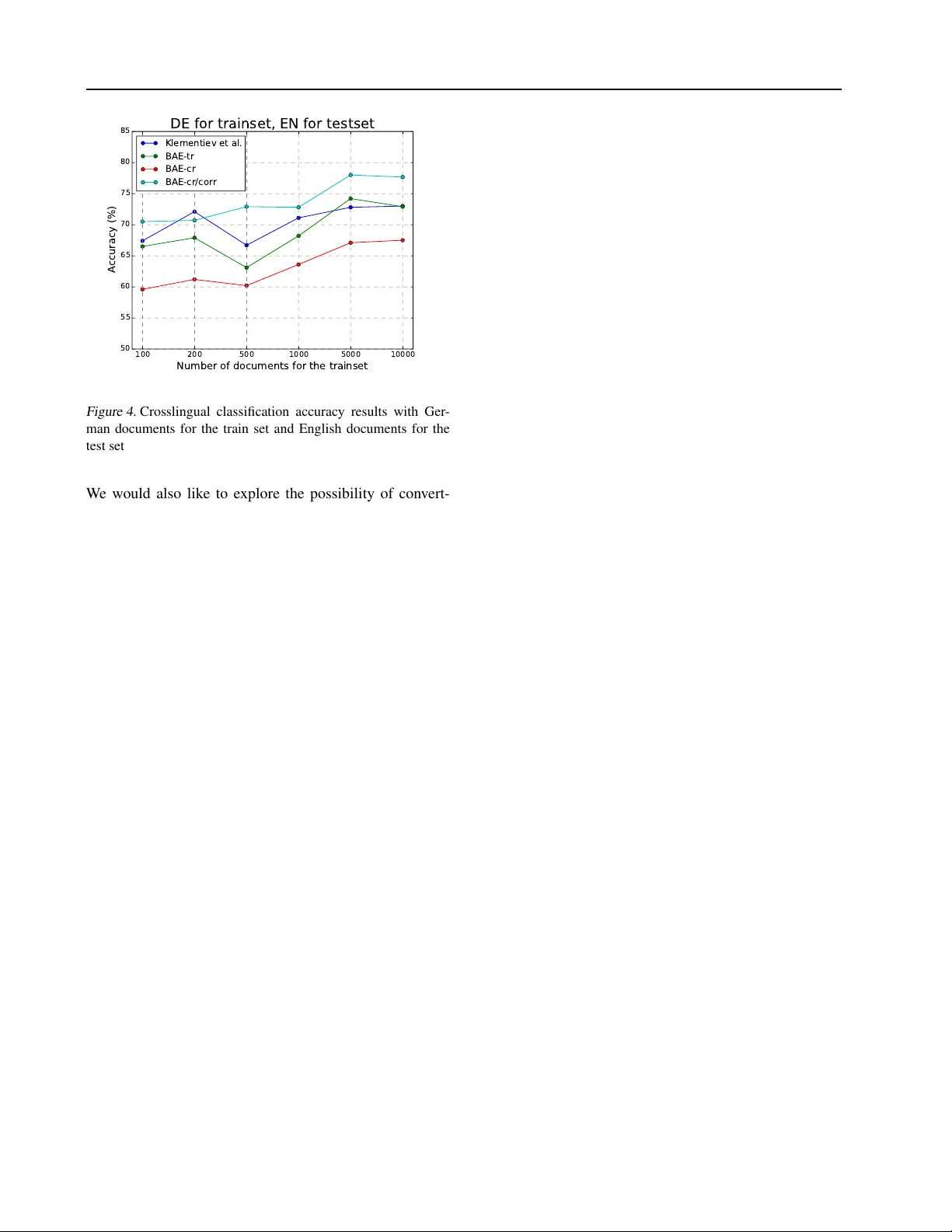
- **성능**: 제안된 자동인코더 모델은 특히 상관관계 정규화를 적용했을 때 10~14%p 정도의 정확도 향상을 보였으며, 일부 경우에는 기존 최첨단 모델을 능가했다. 또한, 트리 기반 디코더는 대규모 어휘에서도 효율적인 학습을 가능하게 하여 훈련 시간과 메모리 사용량을 크게 절감하였다.
### 6. 결론 및 의의
본 연구는 단어‑레벨 정렬 없이도 양언어 임베딩을 효과적으로 학습할 수 있음을 증명한다. 두 가지 디코더 설계와 상관관계 정규화는 고차원 희소 데이터 처리와 표현 정렬을 동시에 해결한다. 학습된 임베딩을 문서 수준으로 확장해 교차 언어 분류에 적용함으로써, 저자원 언어에 대한 NLP 시스템 구축 비용을 크게 낮출 수 있는 실용적인 방법을 제시한다. 향후 연구에서는 더 복잡한 문장 구조를 반영한 순차 모델과, 다언어(>2) 확장에 대한 탐색이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기