An Autoencoder Approach to Learning Bilingual Word Representations
Cross-language learning allows us to use training data from one language to build models for a different language. Many approaches to bilingual learning require that we have word-level alignment of sentences from parallel corpora. In this work we exp…
Authors: Sarath Ch, ar A P, Stanislas Lauly
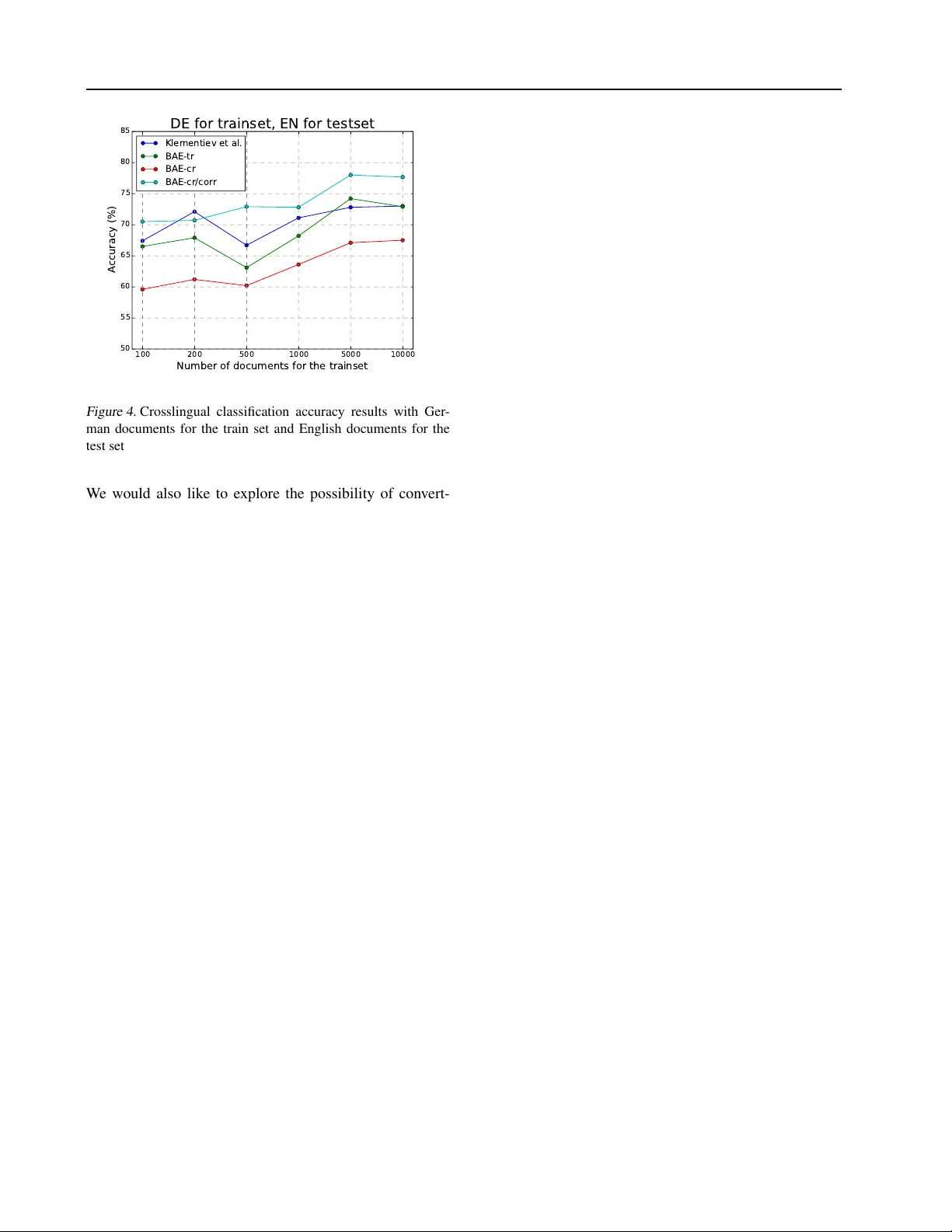
An A utoencoder A ppr oach to Learning Bilingual W ord Repr esentations Sarath Chandar A P ∗ A P S A R A T H C H A N DA R @ G M A I L . C O M Indian Institute of T echnology Madras, India. Stanislas Lauly ∗ S TAN I S L A S . L A U L Y @ U S H E R B R O O K E . C A Univ ersit ´ e de Sherbrooke, Canada. Hugo Larochelle H U G O . L A RO C H E L L E @ U S H E R B R O O K E . C A Univ ersit ´ e de Sherbrooke, Canada. Mitesh M. Khapra M I K H A P R A @ I N . I B M . C O M IBM Research India. Balaraman Ravindran R A V I @ C S E . I I T M . A C . I N Indian Institute of T echnology Madras, India. V ikas Raykar V I R A Y K A R @ I N . I B M . C O M IBM Research India. Amrita Saha A M R S A H A 4 @ I N . I B M . C O M IBM Research India. ∗ Both authors contributed equally . Abstract Cross-language learning allows us to use training data from one language to build models for a dif- ferent language. Many approaches to bilingual learning require that we have word-le vel align- ment of sentences from parallel corpora. In this work we explore the use of autoencoder-based methods for cross-language learning of v ectorial word representations that are aligned between two languages, while not relying on word-lev el alignments. W e show that by simply learning to reconstruct the bag-of-words representations of aligned sentences, within and between lan- guages, we can in fact learn high-quality rep- resentations and do without word alignments. Since training autoencoders on word observa- tions presents certain computational issues, we propose and compare different variations adapted to this setting. W e also propose an explicit corre- lation maximizing regularizer that leads to signif- icant improvement in the performance. W e em- pirically in vestigate the success of our approach on the problem of cross-language test classifica- tion, where a classifier trained on a giv en lan- guage (e.g., English) must learn to generalize to a different language (e.g., German). These e xperi- ments demonstrate that our approaches are com- petitiv e with the state-of-the-art, achieving up to 10-14 percentage point improvements over the best reported results on this task. 1. Introduction Languages such as English, which have plenty of anno- tated resources at their disposal hav e better Natural Lan- guage Processing (NLP) capabilities than other languages that are not so fortunate in terms of annotated resources. For example, high quality POS taggers ( T outanova et al. , 2003 ), parsers ( Socher et al. , 2013 ), sentiment analyzers ( Liu , 2012 ) are already av ailable for English but this is not the case for many other languages such as Hindi, Marathi, Bodo, Farsi, Urdu, etc . This situation was acceptable in the past when only a few languages dominated the digital content av ailable online and elsewhere. Howe ver , the ev er increasing number of languages on the web today has made it important to accurately process natural language data in such lesser-fortunate languages also. An obvious solution An A utoencoder A pproach to Lear ning Bilingual W ord Representations to this problem is to improv e the annotated in ventory of these languages but the in volved cost, time and effort act as a natural deterrent to this. Another option is to exploit the unlabeled data av ailable in a language. In this context, vectorial text representations hav e proven useful for multiple NLP tasks ( T urian et al. , 2010 ; Collobert et al. , 2011 ). It’ s been sho wn that meaning- ful representations, capturing syntactic and semantic sim- ilarity , can be learned from unlabeled data. Along with a (usually smaller) set of labeled data, these representations allow to exploit unlabeled data and improve the general- ization performance on some giv en task, even allowing to generalize out of the vocab ulary observed in the labeled data only (thereby , partly alleviating the problem of data sparsity). While the majority of previous work on vectorial text rep- resentations has concentrated on the monolingual case, re- cent work has started looking at learning word and doc- ument representations that are aligned across languages ( Klementiev et al. , 2012 ; Zou et al. , 2013 ; Mikolo v et al. , 2013 ). Such aligned representations can potentially allow the use of resources from a resource fortunate language to dev elop NLP capabilities in a resource deprived language ( Y arowsky and Ngai , 2001 ; Das and Petrov , 2011 ; Mihal- cea et al. , 2007 ; W an , 2009 ; Pad ´ o and Lapata , 2009 ). For example, if a common representation model is learned for representing English and German documents, then a classi- fier trained on annotated English documents can be used to classify German documents (provided we use the learned common representation model for representing documents in both languages). Such reuse of resources across languages has been tried in the past by projecting parameters learned from the anno- tated data of one language to another language ( Y aro wsky and Ngai , 2001 ; Das and Petrov , 2011 ; Mihalcea et al. , 2007 ; W an , 2009 ; Pad ´ o and Lapata , 2009 ) These projec- tions are enabled by a bilingual resource such as a Machine T ranslation (MT) system. Recent attempts at learning com- mon bilingual representations ( Klementiev et al. , 2012 ; Zou et al. , 2013 ; Mikolo v et al. , 2013 ) aim to eliminate the need of such a MT system. Such bilingual representations hav e been applied to a variety of problems, including cross- language document classification ( Klementie v et al. , 2012 ) and phrase-based machine translation ( Zou et al. , 2013 ). A common property of these approaches is that a wor d-level alignment of translated sentences is lev eraged, e.g. , to de- riv e a re gularization term relating word embeddings across languages ( Klementie v et al. , 2012 ; Zou et al. , 2013 ). Such methods not only eliminate the need for an MT system but also outperform MT based projection approaches. In this paper , we experiment with a method to learn bilin- gual word representations that does without word-to-wor d alignment of bilingual corpora during training. Unlike pre- vious approaches ( Klementiev et al. , 2012 ), we only re- quire aligned sentences and do not rely on word-lev el align- ments (e.g., extracted using GIZA++, as is usual), which simplifies the learning procedure. T o do so, we propose a bilingual autoencoder model, that learns hidden encoder representations of paired bag-of-words sentences which are not only informative of the original bag-of-words but also predictiv e of each other . W ord representations can then eas- ily be extracted from the encoder and used in the context of a supervised NLP task. Specifically , we demonstrate the quality of these representations for the task of cross- language document classification, where a labeled data set can be av ailable in one language, but not in another one. As we’ll see, our approach is able to reach state-of-the-art performance, achie ving up to 10-14 percentage point im- prov ements over the best pre viously reported results. 2. A utoencoder for Bags-of-W ords Let x be the bag-of-words representation of a sentence. Specifically , each x i is a word index from a fixed vocab- ulary of V words. As this is a bag-of-words, the order of the words within x does not correspond to the word order in the original sentence. W e wish to learn a D -dimensional vectorial representation of our words from a training set of sentence bag-of-words { x ( t ) } T t =1 . W e propose to achiev e this by using an autoencoder model that encodes an input bag-of-words x with a sum of the rep- resentations (embeddings) of the words present in x , fol- lowed by a nonlinearity . Specifically , let matrix W be the D × V matrix whose columns are the vector representa- tions for each word. The encoder’ s computation will in- volv e summing ov er the columns of W for each word in the bag-of-word. W e will note this encoder function φ ( x ) . Then, using a decoder , the autoencoder will be trained to optimize a loss function that measures how predictive of the original bag-of-words the encoder representation φ ( x ) is. There are different variations we can consider , in the de- sign of the encoder/decoder and the choice of loss function. One must be careful howe ver , as certain choices can be in- appropriate for training on word observations, which are intrinsically sparse and high-dimensional. In this paper , we explore and compare two different approaches, described in the next two sub-sections. 2.1. Binary bag-of-words r econstruction training with merged mini-batches In the first approach, we start from the conv entional autoen- coder architecture, which minimizes a cross-entropy loss that compares a binary vector observation with a decoder An A utoencoder A pproach to Lear ning Bilingual W ord Representations reconstruction. W e thus conv ert the bag-of-words x into a fixed-size but sparse binary v ector v ( x ) , which is such that v ( x ) x i is 1 if word x i is present in x or otherwise 0. From this representation, we obtain an encoder representa- tion by multiplying v ( x ) with the word representation ma- trix W φ ( x ) = h ( c + Wv ( x )) (1) where h ( · ) is an element-wise non-linearity such as the sig- moid or hyperbolic tangent, and c is a D -dimensional bias vector . Encoding thus in volv es summing the word repre- sentation of the words present at least once in the bag-of- word. T o produce a reconstruction, we parametrize the decoder using the following non-linear form: b v ( x ) = sigm( V φ ( x ) + b ) (2) where V = W T and b is the bias vector of the reconstruc- tion layer and sigm( a ) = 1 / (1 + exp( − a )) is the sigmoid non-linearity . Then, the reconstruction is compared to the original binary bag-of-words as follo ws: ` ( v ( x )) = − V X i =1 v ( x ) i log( b v ( x ) i )+(1 − v ( x ) i ) log(1 − b v ( x ) i ) . (3) T raining then proceeds by optimizing the sum of recon- struction cross-entropies across the training set, e.g . , using stochastic or mini-batch gradient descent. Note that, since the binary bag-of-words are very high- dimensional (the dimensionality corresponds to the size of the vocab ulary , which is typically large), the above train- ing procedure which aims at reconstructing the complete binary bag-of-word, will be slow . Since we will later be training on millions of sentences, training on each individ- ual sentence bag-of-words will be expensi ve. Thus, we propose a simple trick, which exploits the bag- of-words structure of the input. Assuming we are perform- ing mini-batch training (where a mini-batch contains a list of bag-of-words), we simply propose to merge the bags- of-words of the mini-batch into a single bag-of-word, and rev ert back to stochastic gradient descent. The resulting ef- fect is that each update is as ef ficient as in stochastic gradi- ent descent, but the number of updates per training epoch is divided by the mini-batch size. As we’ll see in the experi- mental section, we’ ve found this trick to still produces good word representations, while sufficiently reducing training time. W e note that, additionally , we could ha ve used the stochas- tic approach proposed by Dauphin et al. ( 2011 ) for re- constructing binary bag-of-words representations of doc- uments, to further improve the efficienc y of training. They use importance sampling to av oid reconstructing the whole V -dimensional input vector . 2.2. T ree-based decoder training The previous autoencoder architecture worked with a bi- nary vectorial representation of the input bag-of-word. In the second autoencoder architecture we in vestig ated, we considered an architecture that instead works with the bag (unordered list) representation more directly . Firstly , the encoder representation will now in volv e a sum of the representation of all words, reflecting the relative fre- quency of each word: φ ( x ) = h c + | x | X i =1 W · ,x i . (4) Notice that this implies that the scaling of the pre-activ ation (the input to the nonlinearity) can vary between bags-of- words, depending on how many words it contains. Thus, we’ll optionally consider using the av erage of the repre- sentations, as opposed to the sum (this choice is cross- validated in our e xperiments). Moreov er , decoder training will assume that, from the de- coder’ s output, we can obtain a probability distribution over any word b x observ ed at the reconstruction output layer p ( b x | φ ( x )) . Then, we can treat the input bag-of-words as a | x | -trials multinomial sample from that distribution and use as the reconstruction loss its negati ve log-lik elihood: ` ( x ) = V X i =1 − log p ( b x = x i | φ ( x )) . (5) W e now must ensure that the decoder can compute p ( b x = x i | φ ( x )) efficiently from φ ( x ) . Specifically , we’ d like to av oid a procedure scaling linearly with the vocab ulary size V , since V will be very large in practice. This pre- cludes an y procedure that would compute the numerator of p ( b x = w | φ ( x )) for each possible word w separately and normalize so it sums to one. W e instead opt for an approach borro wed from the w ork on neural network language models ( Morin and Bengio , 2005 ; Mnih and Hinton , 2009 ). Specifically , we use a probabilis- tic tree decomposition of p ( b x = x i | φ ( x )) . Let’ s assume each word has been placed at the leaf of a binary tree. W e can then treat the sampling of a word as a stochastic path from the root of the tree to one of the leav es. W e denote as l ( x ) the sequence of internal nodes in the path from the root to a given word x , with l ( x ) 1 always corre- sponding to the root. W e will denote as π ( x ) the vector of associated left/right branching choices on that path, where π ( x ) k = 0 means the path branches left at internal node An A utoencoder A pproach to Lear ning Bilingual W ord Representations l ( x ) k and branches right if π ( x ) k = 1 otherwise. Then, the probability p ( b x = x | φ ( x )) of reconstructing a certain word x observed in the bag-of-words is computed as p ( b x | φ ( x )) = | π ( ˆ x ) | Y k =1 p ( π ( b x ) k | φ ( x )) (6) where p ( π ( b x ) k | φ ( x )) is output by the decoder . By using a full binary tree of words, the number of different decoder outputs required to compute p ( b x | φ ( x )) will be logarithmic in the vocabulary size V . Since there are | x | words in the bag-of-words, at most O ( | x | log V ) outputs are required from the decoder . This is of course a worst case scenario, since words will share internal nodes between their paths, for which the decoder output can be computed just once. As for organizing words into a tree, as in Larochelle and Lauly ( 2012 ) we used a random assignment of words to the leav es of the full binary tree, which we hav e found to w ork well in practice. Finally , we need to choose a parametrized form for the de- coder . W e choose the following non-linear form: p ( π ( b x ) k = 1 | φ ( x )) = sigm( b l ( ˆ x i ) k + V l ( ˆ x i ) k , · φ ( x )) (7) where b is a ( V -1)-dimensional bias vector and V is a ( V − 1) × D matrix. Each left/right branching probability is thus modeled with a logistic regression model applied on the encoder representation of the input bag-of-words φ ( x ) . 3. Bilingual autoencoders Let’ s now assume that for each sentence bag-of-words x in some source language X , we have an associated bag- of-words y for the same sentence translated in some target language Y by a human expert. Assuming we hav e a training set of such ( x , y ) pairs, we’ d like to use it to learn representations in both languages that are aligned, such that pairs of translated words ha ve similar representations. T o achie ve this, we propose to augment the re gular autoen- coder proposed in Section 2 so that, from the sentence rep- resentation in a given language, a reconstruction can be attempted of the original sentence in the other language. Specifically , we now define language specific word repre- sentation matrices W x and W y , corresponding to the lan- guages of the words in x and y respectively . Let V X and V Y also be the number of words in the vocab ulary of both languages, which can be different. The word representa- tions howe ver are of the same size D in both languages. For the binary reconstruction autoencoder, the bag-of-words representations extracted by the encoder becomes φ ( x ) = h c + W X v ( x ) , φ ( y ) = h c + W Y v ( y ) and are similarly extended for the tree-based autoencoder . Notice that we share the bias c before the nonlinearity across encoders, to encourage the encoders in both lan- guages to produce representations on the same scale. From the sentence in either languages, we want to be able to perform a reconstruction of the original sentence in any of the languages. In particular , given a representation in any language, we’ d like a decoder that can perform a re- construction in language X and another decoder that can reconstruct in language Y . Again, we use decoders of the form proposed in either Section 2.1 or 2.2 (see Figures 1 and 2 ), but let the decoders of each language have their own parameters ( b X , V X ) and ( b Y , V Y ) . This encoder/decoder decomposition structure allows us to learn a mapping within each language and across the lan- guages. Specifically , for a given pair ( x , y ) , we can train the model to (1) construct y from x (loss ` ( x , y ) ), (2) con- struct x from y (loss ` ( y , x ) ), (3) reconstruct x from itself (loss ` ( x ) ) and (4) reconstruct y from itself (loss ` ( y ) ). W e follow this approach in our experiments and optimize the sum of the corresponding 4 losses during training. 3.1. Cross-lingual corr elation regularization The bilingual encoder proposed above can be further en- riched by ensuring that the embeddings learned for a giv en pair ( x , y ) are highly correlated. W e achie ve this by adding a correlation term to the objective function. Specifically , we could optimize ` ( x , y ) + ` ( y , x ) − λ · cor ( φ ( x ) , φ ( y )) (8) where cor ( φ ( x ) , φ ( y )) is the correlation between the en- coder representations learned for x and y and λ is a scaling factor which ensures that the three terms in the loss func- tion hav e the same range. Note that this approach could be used for either the binary bag-of-words or the tree-based reconstruction autoencoders. 3.2. Document repr esentations Once we learn the language specific word representation matrices W x and W y as described abov e, we can use them to construct document representations, by using their columns as vector representations for words in both lan- guages. Now , giv en a document d written in language Z ∈ {X , Y } and containing m words, z 1 , z 2 , . . . , z m , we represent it as the tf-idf weighted sum of its words’ repre- sentations: ψ ( d ) = m X i =1 tf-idf ( z i ) · W Z .,z i (9) W e use the document representations thus obtained to train An A utoencoder A pproach to Lear ning Bilingual W ord Representations Figure 1. Illustration of a binary reconstruction error based bilin- gual autoencoder that learns to reconstruct the binary bag-of- words of the English sentence “ the dog barked ” from its French translation “ le chien a japp ´ e ”. our document classifiers, in the cross-lingual document classification task described in Section 5 . 4. Related W ork Recent work that has considered the problem of learning bilingual representations of words usually has relied on word-le vel alignments. Klementiev et al. ( 2012 ) propose to train simultaneously tw o neural network languages mod- els, along with a regularization term that encourages pairs of frequently aligned words to have similar word embed- dings. Zou et al. ( 2013 ) use a similar approach, with a different form for the regularizer and neural network lan- guage models as in ( Collobert et al. , 2011 ). In our work, we specifically in vestigate whether a method that does not rely on word-le vel alignments can learn comparably useful multilingual embeddings in the context of document clas- sification. Looking more generally at neural networks that learn mul- tilingual representations of words or phrases, we mention the work of Gao et al. ( 2013 ) which showed that a use- ful linear mapping between separately trained monolingual skip-gram language models could be learned. They too howe ver rely on the specification of pairs of words in the two languages to align. Mikolov et al. ( 2013 ) also propose a method for training a neural network to learn useful repre- sentations of phrases (i.e. short segments of words), in the context of a phrase-based translation model. In this case, phrase-lev el alignments (usually extracted from word-le vel alignments) are required. v 1 v 2 v 3 ṽ 1 the dog barked v 4 le chien jappé a ṽ 2 ṽ 3 Figure 2. Illustration of a tree-based bilingual autoencoder that learns to construct the bag-of-words of the English sentence “ the dog barked ” from its French translation “ le chien a japp ´ e ”. The horizontal blue line across the input-to-hidden connections high- lights the fact that these connections share the same parameters (similarly for the hidden-to-output connections). 5. Experiments The techniques proposed in this paper enable us to learn bilingual embeddings which capture cross-language simi- larity between words. W e propose to ev aluate the quality of these embeddings by using them for the task of cross- language document classification. W e follo w the same setup as used by Klementie v et al. ( 2012 ) and compare with their method. The set up is as follo ws. A labeled data set of documents in some language X is av ailable to train a clas- sifier , howe ver we are interested in classifying documents in a different language Y at test time. T o achiev e this, we lev erage some bilingual corpora, which importantly is not labeled with any document-le vel categories. This bilingual corpora is used instead to learn document representations in both languages X and Y that are encouraged to be in vari- ant to translations from one language to another . The hope is thus that we can successfully apply the classifier trained on document representations for language X directly to the document representations for language Y . W e use English (EN) and German (DE) as the language pair for all our ex- periments. 5.1. Data For learning the bilingual embeddings, we used the En- glish German section of the Europarl corpus ( K oehn , 2005 ) which contains roughly 2 million parallel sentences. As mentioned earlier, unlike Klementiev et al. ( 2012 ), we do not use any word alignments between these parallel sen- tences. W e use the same pre-processing as used by Kle- An A utoencoder A pproach to Lear ning Bilingual W ord Representations mentiev et al. ( 2012 ). Specifically , we tokenize the sen- tences using NL TK ( Bird Steven and Klein , 2009 ), remove punctuations and lowercase all words. W e do not remove stopwords (similar to Klementiev et al. ( 2012 )). Note that Klementiev et al. ( 2012 ) use the word-aligned Europarl corpus to first learn an interaction matrix between the words in the two languages. This interaction matrix is then used in a multitask learning setup to induce bilin- gual embeddings from English and German sections of the Reuters RCV1/RCV2 corpora. Note that these documents are not parallel. Each document is assigned one or more categories from a pre-defined hierarchy of topics. Fol- lowing Klementiev et al. ( 2012 ), we consider only those documents which were assigned exactly one of the 4 top lev el categories in the topic hierarchy . These topics are CCA T (Corporate/Industrial), ECA T (Economics), GCA T (Gov ernment/Social) and MCA T (Markets). The number of such documents sampled by Klementie v et al. ( 2012 ) for English and German is 34,000 and 42,753 respectiv ely . In contrast to Klementie v et al. ( 2012 ), we do not require a two stage approach (of learning an interaction matrix and then inducing bilingual embeddings). W e directly learn the embeddings from the Europarl corpus which is parallel. Further , in addition to the Europarl corpus, we also consid- ered feeding the same RCV1/RCV2 documents (34000 EN and 42,753 DE) to the autoencoders. These non-parallel documents are used only to reinforce the monolingual em- beddings (by reconstructing x from x or y from y ). So, in effect, we use the same amount of data as that used by Klementiev et al. ( 2012 ) but our model/training procedure is completely different. Next for the cross language classification experiments, we again follo w the same setup as used by Klementie v et al. ( 2012 ). Specifically , we use 10,000 single-topic documents for training and 5000 single-topic documents for testing in each language. These documents are also pre-processed using a similar procedure as that used for the Europarl cor - pus. 5.2. Cross language classification Our ov erall procedure for cross language classification can be summarized as follows: • T rain bilingual word representations W x and W y on sentence pairs extracted from Europarl-v7 for lan- guages X and Y . Optionally , we also use the mono- lingual documents from RCV1/RCV2 to reinforce the monolingual embeddings (this choice is cross- validated, as described in Section 5.3 ). • T rain document classifier on the Reuters training set for language X , where documents are represented us- ing the word representations W x . • Use the classifier trained in the previous step on the Reuters test set for language Y , using the word repre- sentations W y to represent the documents. As in Klementiev et al. ( 2012 ) we used an averaged percep- tron to train a multi-class classifier for 10 epochs, for all the experiments ( Klementiev et al. ( 2012 ) report that the results were not sensitive to the number of epochs). The English and German vocab ularies contained 43,614 and 50,110 words, respectively . Each document is represented with the tf-idf weighted linear combination of its word’ s embeddings, as described in Section 3.2 , where only the words belonging to the abov e vocab ulary are considered. 5.3. Different models f or learning embeddings From the different autoencoder architectures and the op- tional correlation-based regularization term proposed ear- lier , we trained 3 different models for learning bilingual embeddings. Each of these models is described below . • B AE-tr: uses tree-based decoder training (see Section 2.2 ). • B AE-cr: uses reconstruction error based decoder training (see Section 2.1 ). • B AE-cr/corr: uses reconstruction error based decoder training (see Section 2.1 ), but unlike B AE-cr it uses the correlation based regularization term (see Section 3.1 ). As we’ll see, B AE-cr is our worse performing model, thus this experiment will allow us to observe whether the corre- lation regularization can play an important role in improv- ing the quality of the representations. All of the abov e models were trained for up to 20 epochs using the same data as described earlier . All results are for word embeddings of size D = 40 , as in Klementiev et al. ( 2012 ). Further , to speed up the training for B AE- cr and B AE-cr/corr we merged mini-batches of 5 adjacent sentence pairs into a single training instance, as described in Section 2.1 . Other hyperparameters were selected using a train- ing/validation set split of 80% and 20% and using the per- formance on the validation set of an averaged perceptron trained on the smaller training set portion (notice that this corresponds to a monolingual classification experiment, since the general assumption is that no labeled data is av ail- able in the test set language). 6. Results and Discussions Before discussing the results of cross language classifica- tion, we would first like to give a qualitative feel for the An A utoencoder A pproach to Lear ning Bilingual W ord Representations T able 1. Example English words along with 10 closest words both in English (en) and German (de), using the Euclidean distance between the embeddings learned by B AE-cr/corr january president said en de en de en de january januar president pr ¨ asident said gesagt march m ¨ arz i pr ¨ asidentin told sagte october oktober mr pr ¨ asidenten say sehr july juli presidents herr believ e heute december dezember thank ich saying sagen 1999 jahres president-in-office ratspr ¨ asident wish heutigen june juni report danken shall letzte month 1999 v oted danke again hier year jahr colleagues bericht agree sagten september jahresende ladies k ollegen very will oil microsoft market en de en de en de oil ¨ ol microsoft microsoft market markt supply boden cds cds markets marktes supplies befindet insider warner single m ¨ arkte gas ger ¨ at ibm tageszeitungen commercial binnenmarkt fuel erd ¨ ol acquisitions ibm competition m ¨ arkten mineral infolge shareholding handelskammer competiti ve handel petroleum abh ¨ angig warner exchange business ¨ offnung crude folge online veranstalter goods binnenmarktes materials ganze shareholder gesch ¨ aftsf ¨ uhrer sector bereich causing nahe otc aktiengesellschaften model gleichzeitig embeddings learned by our method. For this, we perform a small e xperiment where we select a fe w English words and list the top 10 English and German words which are most similar to these words (in terms of the Euclidean distance between their embeddings as learned by B AE-cr/corr). T a- ble 1 sho ws the result of this e xperiment. For example, T a- ble 1 shows that in all the cases the German word which is closest to a gi ven English word is actually the trans- lation of that English word. Also, notice that the model is able to capture semantic similarity between words by embedding semantically similar words (such as, (january , mar ch) , (gesagt, sagte) , (market, commer cial) , etc. ) close to each other . The results of this experiment suggest that these bilingual embeddings should be useful for any cross language classification task as indeed shown by the results presented in the next section. The supplementary material also includes a 2D visualization of the word embeddings in both languages, generated using the t-SNE dimensionality reduction algorithm ( van der Maaten and Hinton , 2008 ). 6.1. Comparison of the performance of differ ent models W e now present the cross language classification results ob- tained by using the embeddings produced by each of the 3 models described abov e. W e also compare our models with the follo wing approaches, for which the results are reported in Klementiev et al. ( 2012 ): • Klementie v et al. : This model uses w ord embeddings learned by a multitask neural network language model with a regularization term that encourages pairs of fre- quently aligned words to hav e similar word embed- dings. From these embeddings, document representa- tions are computed as described in Section 3.2 . • MT : Here, test documents are translated to the lan- guage of the training documents using a Machine T ranslation (MT) system. MOSES 1 , a standard phrase-based MT system, using default parameters and a 5-gram language model was trained on the Eu- roparl v7 corpus (same as the one used for inducing our bilingual embeddings). • Majority Class: Every test document is simply as- signed the Majority class prev alent in the training data. T able 2 summarizes the results obtained using 1K training data with dif ferent models. W e report results in both direc- 1 http://www.statmt.org/moses/ An A utoencoder A pproach to Lear ning Bilingual W ord Representations T able 2. Classification Accuracy for training on English and Ger- man with 1000 labeled examples EN → DE DE → EN B AE-tr 80.2 68.2 B AE-cr 78.2 63.6 B AE-cr/corr 91.8 72.8 Klementiev et al. 77.6 71.1 MT 68.1 67.4 Majority Class 46.8 46.8 tions, i.e. , EN-DE and DE-EN. Between B AE-tr and BAE- cr , we observe that B AE-tr provides better performance and is comparable to the embeddings learned by the neural net- work language model of Klementiev et al. ( 2012 ) which, unlike BAE-tr , relies on word-le vel alignments. W e also observe that the use of the correlation re gularization is very beneficial. Indeed, it is able to improv e the performance of B AE-cr and make it the best performing method, with more than 10% in accuracy over other methods for the EN to DE task. 6.2. Effect of varying training size Next, we ev aluate the ef fect of varying the amount of su- pervised training data for training the classifier , with either B AE-tr , BAE-cr/corr or Klementiev et al. ( 2012 ) embed- digns. W e experiment with training sizes of 100, 200, 500, 1000, 5000 and 10000. These results for EN-DE and DE- EN are summarized in Figure 3 and Figure 4 respectively . W e observe that B AE-cr/corr clearly outperforms the other models at almost all data sizes. More importantly , it per - forms remarkably well at very low data sizes ( t =100) which suggests that it indeed learns very meaningful embeddings which can generalize well ev en at lo w data sizes. 6.3. Effect of coarser alignments The excellent performance of B AE-cr/corr suggests that merging mini-batches into single bags-of-words does not significantly impact the quality of the word embeddings. In other words, not only we do not need to rely on word- lev el alignments, but exact sentence-lev el alignment is also not essential to reach good performances. It is thus natu- ral to ask the effect of using e ven coarser lev el alignments. W e check this by varying the size of the merged mini- batches from 5, 25 to 50, for both B AE-cr/corr and B AE-tr . The cross language classification results obtained by using these coarser alignments are summarized in T able 3 . Surprisingly , the performance of BAE-tr does not signif- icantly decrease, by using merged mini-batches of size 5 (in fact, the performance ev en improves for the EN to DE task). Howe ver , with larger mini-batches, the performance 100 200 500 1000 5000 10000 Number of documents for the trainset 60 65 70 75 80 85 90 95 Accuracy (%) EN for trainset, DE for testset Klementiev et al. BAE-tr BAE-cr BAE-cr/corr Figure 3. Crosslingual classification accuracy results with English documents for the train set and German documents for the test set T able 3. Classification Accuracy for training on English and Ger- man with coarser alignments for 1000 labeled examples Sent. per doc EN → DE DE → EN B AE-tr 5 84.0 67.7 B AE-tr 25 83.0 63.4 B AE-tr 50 75.9 68.6 B AE-cr/corr 5 91.75 72.78 B AE-cr/corr 25 88.0 64.5 B AE-cr/corr 50 90.2 49.2 can deteriorate, as is observed on the DE to EN task, for the B AE-cr/corr embeddings. 7. Conclusion and Future W ork W e presented evidence that meaningful bilingual word rep- resentations could be learned without relying on word-le vel alignments and can e ven be successful on fairly coarse sentence-lev el alignments. In particular , we showed that ev en though our model does not use word lev el alignments, it is able to outperform a state of the art word representa- tion learning method that exploits word-lev el alignments. In addition, it also outperforms a strong Machine T ransla- tion based baseline. W e observed that using a correlation based regularization term leads to better bilingual embed- dings which are highly correlated and hence perform better for cross language classification tasks. As future w ork we would like to inv estigate extensions of our bag-of- words bilingual autoencoder to bags-of-n- grams, where the model would also ha ve to learn represen- tations for short phrases. Such a model should be particu- larly useful in the context of a machine translation system. An A utoencoder A pproach to Lear ning Bilingual W ord Representations 100 200 500 1000 5000 10000 Number of documents for the trainset 50 55 60 65 70 75 80 85 Accuracy (%) DE for trainset, EN for testset Klementiev et al. BAE-tr BAE-cr BAE-cr/corr Figure 4. Crosslingual classification accuracy results with Ger- man documents for the train set and English documents for the test set W e would also like to explore the possibility of conv ert- ing our bilingual model to a multilingual model which can learn common representations for multiple languages gi ven different amounts of parallel data between these languages. References Kristina T outanov a, Dan Klein, Christopher D. Manning, and Y oram Singer . Feature-rich part-of-speech tagging with a cyclic dependency network. In Pr oceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language T echnolo gy - V olume 1 , N AA CL ’03, pages 173–180, 2003. Richard Socher , John Bauer , Christopher D. Manning, and Ng Andrew Y . Parsing with compositional vector gram- mars. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pages 455–465, Sofia, Bulgaria, August 2013. Association for Computational Linguistics. Bing Liu. Sentiment Analysis and Opinion Mining . Synthe- sis Lectures on Human Language T echnologies. Morgan & Claypool Publishers, 2012. Joseph T urian, Lev Ratinov , and Y oshua Bengio. W ord representations: A simple and general method for semi- supervised learning. In Pr oceedings of the 48th Annual Meeting of the Association for Computational Linguis- tics (ACL2010) , pages 384–394. Association for Com- putational Linguistics, 2010. Ronan Collobert, Jason W eston, L ´ eon Bottou, Michael Karlen, K oray Kavukcuoglu, and Pa vel Kuksa. Natural Language Processing (Almost) from Scratch. J ournal of Machine Learning Resear ch , 12:2493–2537, 2011. Alexandre Klementiev , Iv an T itov , and Binod Bhattarai. Inducing Crosslingual Distrib uted Representations of W ords. In Pr oceedings of the International Confer ence on Computational Linguistics (COLING) , 2012. W ill Y . Zou, Richard Socher , Daniel Cer , and Christo- pher D. Manning. Bilingual W ord Embeddings for Phrase-Based Machine Translation. In Conference on Empirical Methods in Natural Language Pr ocessing (EMNLP 2013) , 2013. T omas Mikolov , Quoc Le, and Ilya Sutskev er . Exploiting Similarities among Languages for Machine T ranslation. T echnical report, arXiv , 2013. David Y aro wsky and Grace Ngai. Inducing multilin- gual pos taggers and np bracketers via robust projec- tion across aligned corpora. In Pr oceedings of the sec- ond meeting of the North American Chapter of the As- sociation for Computational Linguistics on Language technologies , pages 1–8, Pittsburgh, Pennsylvania, 2001. doi: http://dx.doi.org/10.3115/1073336.1073362. Dipanjan Das and Slav Petrov . Unsupervised part-of- speech tagging with bilingual graph-based projections. In Proceedings of the 49th Annual Meeting of the Associ- ation for Computational Linguistics: Human Language T ec hnologies , pages 600–609, Portland, Oregon, USA, June 2011. Rada Mihalcea, Carmen Banea, and Janyce W iebe. Learn- ing multilingual subjective language via cross-lingual projections. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics , pages 976–983, Prague, Czech Republic, June 2007. Associa- tion for Computational Linguistics. Xiaojun W an. Co-training for cross-lingual sentiment clas- sification. In Pr oceedings of the Joint Confer ence of the 47th Annual Meeting of the A CL and the 4th Interna- tional Joint Conference on Natural Language Pr ocess- ing of the AFNLP , pages 235–243, Suntec, Singapore, August 2009. Sebastian Pad ´ o and Mirella Lapata. Cross-lingual annota- tion projection for semantic roles. Journal of Artificial Intelligence Resear ch (J AIR) , 36:307–340, 2009. Y ann Dauphin, Xavier Glorot, and Y oshua Bengio. Large- Scale Learning of Embeddings with Reconstruction Sampling. In Pr oceedings of the 28th International Con- fer ence on Machine Learning (ICML 2011) , pages 945– 952. Omnipress, 2011. An A utoencoder A pproach to Lear ning Bilingual W ord Representations Frederic Morin and Y oshua Bengio. Hierarchical Proba- bilistic Neural Network Language Model. In Pr oceed- ings of the 10th International W orkshop on Artificial In- telligence and Statistics (AIST ATS 2005) , pages 246– 252. Society for Artificial Intelligence and Statistics, 2005. Andriy Mnih and Geoffre y E Hinton. A Scalable Hierarchi- cal Distributed Language Model. In Advances in Neural Information Pr ocessing Systems 21 (NIPS 2008) , pages 1081–1088, 2009. Hugo Larochelle and Stanislas Lauly . A Neural Autore- gressiv e T opic Model. In Advances in Neural Informa- tion Pr ocessing Systems 25 (NIPS 25) , 2012. Jianfeng Gao, Xiaodong He, W en-tau Y ih, and Li Deng. Learning Semantic Representations for the Phrase T ranslation Model. T echnical report, Microsoft Re- search, 2013. Philipp Koehn. Europarl: A parallel corpus for statistical machine translation. In MT Summit , 2005. Edward Loper Bird Stev en and Ewan Klein. Natur al Lan- guage Pr ocessing with Python . O’Reilly Media Inc., 2009. Laurens van der Maaten and Geoffre y E Hinton. V i- sualizing Data using t-SNE. Journal of Machine Learning Researc h , 9:2579–2605, 2008. URL http://www.jmlr.org/papers/volume9/ vandermaaten08a/vandermaaten08a.pdf .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment