대규모 어휘 음성 인식을 위한 LSTM 기반 순환 신경망 구조
본 논문은 기존 LSTM 구조의 파라미터 효율성을 개선한 두 가지 새로운 아키텍처를 제안하고, 이를 구글 영어 보이스 서치 데이터(약 1900시간)에서 대규모 어휘 음성 인식 과제에 적용한다. 실험 결과, 제안된 LSTM‑Projection 모델은 동일 파라미터 규모의 DNN·RNN을 능가하며, 특히 8000개의 컨텍스트 종속 상태를 가진 경우에도 높은 프레임 정확도와 낮은 단어 오류율을 달성한다.
저자: Hac{s}im Sak, Andrew Senior, Franc{c}oise Beaufays
본 논문은 장기 의존성을 학습할 수 있는 LSTM(Long Short‑Term Memory) 구조를 기반으로, 대규모 어휘 음성 인식 시스템에 적용 가능한 효율적인 아키텍처를 설계하고 실험적으로 검증한다. 서론에서는 피드포워드 신경망(FFNN)과 달리 순환 신경망(RNN)이 시간적 컨텍스트를 동적으로 활용할 수 있다는 점을 강조하고, 기존 RNN이 겪는 소멸·폭발 기울기 문제를 해결하기 위해 LSTM이 도입되었지만, 파라미터 수와 계산 복잡도가 급증해 대규모 음성 인식에 적용하기 어려웠던 배경을 제시한다.
그 후, 표준 LSTM 구조의 파라미터 수를 식 (W = nc·nc·4 + ni·nc·4 + nc·no + nc·3) 로 정리하고, 특히 출력 차원(no)이 크고 메모리 셀 수(nc)도 많아질 경우 학습 비용이 O(nc·(nc+no)) 로 급증함을 지적한다. 이를 해결하기 위해 두 가지 변형을 제안한다. 첫 번째는 ‘재귀 투영층(recurrent projection layer)’을 도입해, 셀 출력(m_t)을 저차원 r 차원으로 투영하고, 이 투영된 벡터를 재귀 연결에 사용한다. 이 구조는 파라미터 수를 nc·nr·4 + ni·nc·4 + nr·no + nc·nr + nc·3 로 감소시킨다. 두 번째 변형은 첫 번째 구조에 ‘비재귀 투영층(non‑recurrent projection layer)’을 추가해, 출력층과 직접 연결되는 고차원 p 차원을 별도로 두어, 재귀 연결 파라미터는 그대로 유지하면서 출력 표현력을 강화한다. 수식 (7)~(15)에서 각 게이트와 셀 업데이트가 어떻게 투영층을 통해 이루어지는지 상세히 제시한다.
학습 구현에서는 GPU 대신 멀티코어 CPU를 선택했으며, Eigen 라이브러리와 SIMD 명령어를 활용해 행렬 연산을 최적화한다. 비동기식 SGD(ASGD)를 24개의 스레드에서 동시에 수행하고, 각 스레드는 4~8개의 서브시퀀스를 병렬 처리한다. BPTT는 고정된 20 프레임 길이(T_bptt) 로 제한해 메모리 사용을 최소화하면서도 충분한 시간 의존성을 학습한다. 이러한 설계는 대규모 클러스터 환경에서도 손쉽게 확장 가능하도록 한다.
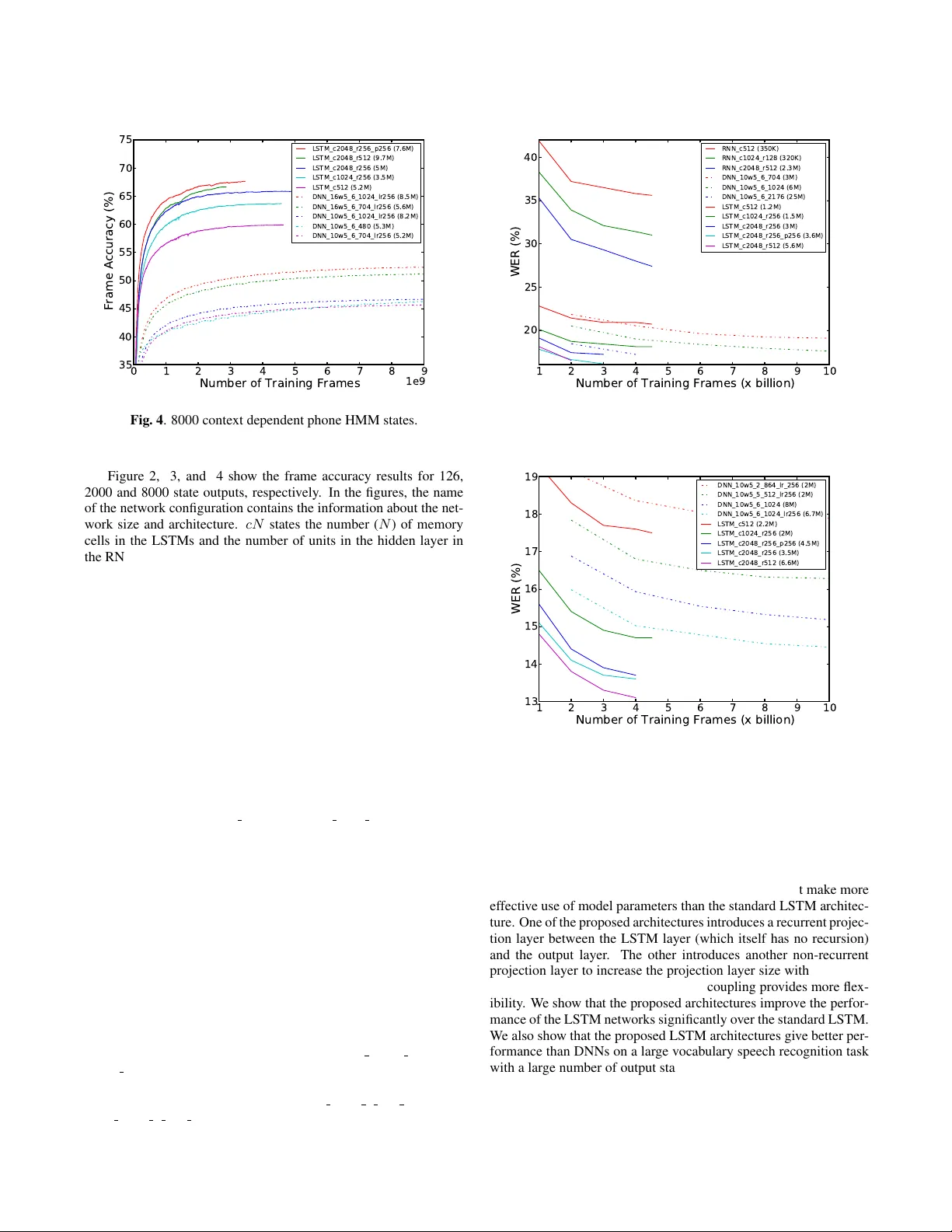
실험은 구글 영어 보이스 서치 데이터(약 1900시간, 3백만 발화)를 사용했으며, 40 차원 로그‑필터뱅크 특징을 25 ms 프레임으로 추출한다. 라벨은 90 M 파라미터 FFNN으로 14 247개의 컨텍스트 종속(CD) 상태를 정의하고, 이를 126(컨텍스트 독립), 2 000, 8 000개의 상태 집합으로 축소해 각각 실험한다. DNN은 6층, 1024~2176 유닛, 저차원 투영(256) 등을 포함한 다양한 규모로 학습했으며, RNN은 표준 구조와 재귀 투영 구조를 비교했다. LSTM은 제안된 두 변형을 포함해 다양한 셀 수(c)와 투영 차원(r, p) 조합으로 실험했다.
프레임 정확도(FR)와 단어 오류율(WER) 결과는 다음과 같다. 그림 2~4에서 126, 2 000, 8 000 상태에 대해 LSTM‑c2048‑r512(5.6 M 파라미터)와 LSTM‑c2048‑r256‑p256(3.6 M 파라미터) 모델이 DNN‑10w5‑6‑2176(25 M 파라미터)보다 3~5% 높은 FR을 보였으며, 학습 수렴 속도도 빠르다. 특히 8 000 상태 실험에서 LSTM‑c2048‑r256‑p256은 DNN 대비 WER을 0.9%p 감소시켰다. RNN은 초기 학습 시 폭발 기울기 문제로 불안정했으며, 제한된 파라미터(350 K)에서도 LSTM·DNN에 비해 현저히 낮은 성능을 기록했다. LSTM‑c512(1.2 M 파라미터)와 같은 소형 모델도 DNN 대비 일정 수준 이상의 FR과 WER 개선을 달성했다.
결론적으로, 재귀 투영층과 비재귀 투영층을 결합한 LSTM 구조는 파라미터 효율성을 크게 향상시키면서도 대규모 어휘 음성 인식에서 기존 DNN·RNN을 능가하는 성능을 보여준다. 또한 CPU 기반 멀티코어 구현과 ASGD를 통한 학습 전략은 대규모 데이터와 모델을 다루는 실무 환경에 적합하다. 향후 연구에서는 더 깊은 LSTM 스택, CTC·트랜스듀서와 같은 시퀀스‑투‑시퀀스 학습 기법과의 결합, 그리고 실시간 인식 시스템에의 적용을 통해 성능과 효율성을 더욱 확대할 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기